非支配排序遗传算法(NSGA,NSGA-II )-程序员宅基地
技术标签: 算法
非支配排序遗传算法(NSGA,NSGA-II )
一、非支配排序遗传算法(NSGA)
1995年,Srinivas和Deb提出了非支配排序遗传算法(Non-dominated Sorting Genetic Algorithms,NSGA)。这是一种基于Pareto最优概念的遗传算法。
1、基本原理
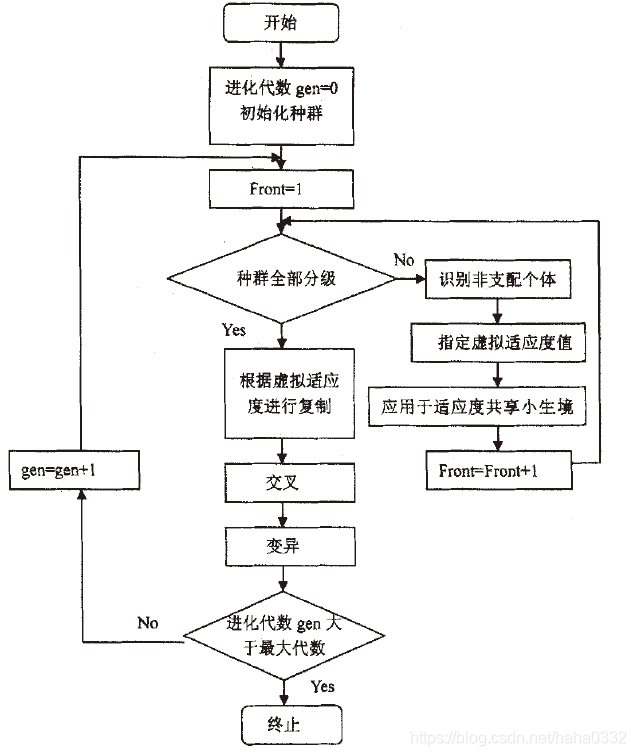
NSGA与简单的遗传算法的主要区别在于:该算法在选择算子执行之前根据个体之间的支配关系进行了分层。其选择算子、交叉算子和变异算子与简单遗传算法没有区别。
在选择操作执行之前,种群根据个体之间的支配与非支配关系进行排序:
首先,找出该种群中的所有非支配个体,并赋予他们一个共享的虚拟适应度值。得到第一个非支配最优层;
然后,忽略这组己分层的个体,对种群中的其它个体继续按照支配与非支配关系进行分层,并赋予它们一个新的虚拟适应度值,该值要小于上一层的值,对剩下的个体继续上述操作,直到种群中的所有个体都被分层。
算法根据适应度共享对虚拟适应值重新指定:
比如指定第一层个体的虚拟适应值为1,第二层个体的虚拟适应值应该相应减少,可取为0.9,依此类推。这样,可使虚拟适应值规范化。保持优良个体适应度的优势,以获得更多的复制机会,同时也维持了种群的多样性。
2、算法流程
NSGA采用的非支配分层方法,可以使好的个体有更大的机会遗传到下一代;适应度共享策略则使得准Pamto面上的个体均匀分布,保持了群体多样性,克服了超级个体的过度繁殖,防止了早熟收敛。算法流程如图所示:
3、算法缺陷
非支配排序遗传算法(NSGA)在许多问题上得到了应用。但NSGA仍存在一些问题:
-
计算复杂度较高,为
(m为目标函数个数,N为种群大小),所以当种群较大时,计算相当耗时。
-
没有精英策略;精英策略可以加速算法的执行速度,而且也能在一定程度上确保已经找到的满意解不被丢失。
-
需要指定共享半径
。
二、带精英策略的非支配排序的遗传算法(NSGA-II)
2000年,Deb又提出NSGA的改进算法一带精英策略的非支配排序遗传算法(NSGA-II),针对以上的缺陷通过以下三个方面进行了改进:
-
提出了快速非支配排序法,降低了算法的计算复杂度。由原来的
,其中,m为目标函数个数,N为种群大小。
-
提出了拥挤度和拥挤度比较算子,代替了需要指定共享半径的适应度共享策略,并在快速排序后的同级比较中作为胜出标准,使准Pareto域中的个体能扩展到整个Pareto域,并均匀分布,保持了种群的多样性。
-
引入精英策略,扩大采样空间。将父代种群与其产生的子代种群组合,共同竞争产生下一代种群,有利于保持父代中的优良个体进入下一代,并通过对种群中所有个体的分层存放,使得最佳个体不会丢失,迅速提高种群水平。
1、基本原理
1.1 快速支配排序法
NSGA-II对第一代算法中非支配排序方法进行了改进:对于每个个体 i 都设有以下两个参数 n(i) 和 S(i),
n(i) 为在种群中支配个体 i 的解个体的数量。(别的解支配个体 i 的数量)
S(i) 为被个体 i 所支配的解个体的集合。(个体 i 支配别的解的集合)
-
首先,找到种群中所有 n(i)=0 的个体(种群中所有不被其他个体至配的个体 i),将它们存入当前集合F(1);(找到种群中所有未被其他解支配的个体)
-
然后对于当前集合 F(1) 中的每个个体 j,考察它所支配的个体集 S(j),将集合 S(j) 中的每个个体 k 的 n(k) 减去1,即支配个体 k 的解个体数减1(因为支配个体 k 的个体 j 已经存入当前集 F(1) );(对其他解除去被第一层支配的数量,即减一)
-
如 n(k)-1=0则将个体 k 存入另一个集H。最后,将 F(1) 作为第一级非支配个体集合,并赋予该集合内个体一个相同的非支配序 i(rank),然后继续对 H 作上述分级操作并赋予相应的非支配序,直到所有的个体都被分级。其计算复杂度为
1.2确定拥挤度
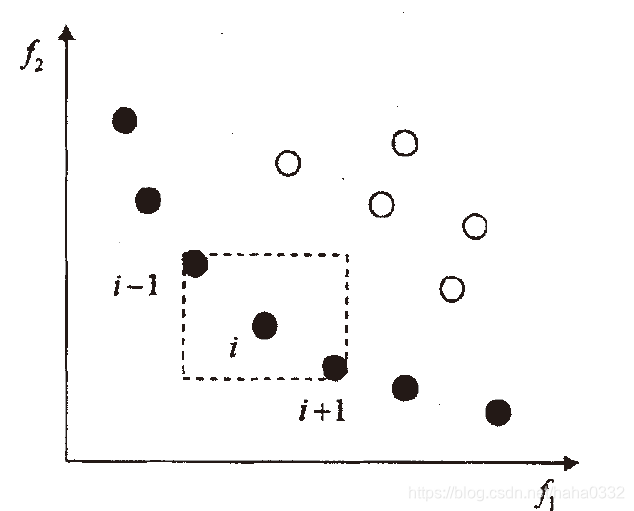
在原来的NSGA中,我们采用共享函数以确保种群的多样性,但这需要由决策者指定共享半径的值。为了解决这个问题,我们提出了拥挤度概念:在种群中的给定点的周围个体的密度,用 表示,它指出了在个体 i 周围包含个体 i 本身但不包含其他个体的长方形(以同一支配层的最近邻点作为顶点的长方形)
如图所示:
拥挤度比较算子:
从图中我们可以看出值较小时表示该个体周围比较拥挤。为了维持种群的多样性,我们需要一个比较拥挤度的算予以确保算法能够收敛到一个均匀分布的Pareto面上。
由于经过了排序和拥挤度的计算,群体中每个个体 i 都得到两个属性:非支配序 i(rank) 和拥挤度 ,则定义偏序关系:当满足条件 i(rank) <
,或满足 i(rank) =
且
>
时,定义
,也就是说:如果两个个体的非支配排序不同,取排序号较小的个体(分层排序时,先被分离出来的个体);如果两个个体在同一级,取周围较不拥挤的个体。
2、算法流程
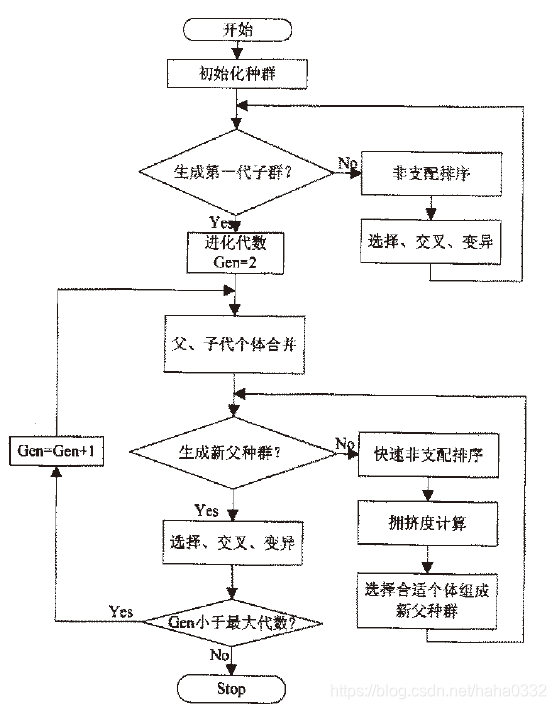
首先,随机初始化一个父代种群P(0),并将所有个体按非支配关系排序且指定一个适应度值,如:可以指定适应度值等于其非支配序 i(rank),则1是最佳适应度值。然后,采用选择、交叉、变异算子产生下一代种群Q(0),大小为N。
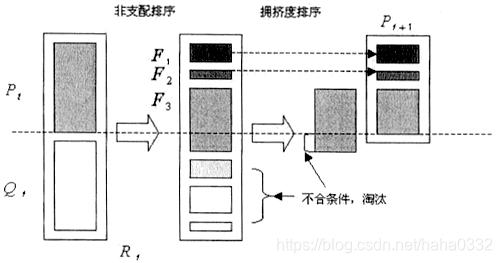
如图,首先将第 t 代产生的新种群Q(t)与父代P(t)合并组成R(t),种群大小为2N。然后R(t)。进行非支配排序,产生一系列非支配集 F(t) 并计算拥挤度。由于子代和父代个体都包含在 R(t) 中,则经过非支配排序以后的非支配集 F(1) 中包含的个体是 R(t) 中最好的,所以先将 F(1) 放入新的父代种群 P(t+1) 中。如果 F(1) 的大小小于N,则继续向 P(t+1) 中填充下一级非支配集 F(2),直到添加 F(3) 时,种群的大小超出N,对 F(3) 中的个体进行拥挤度排序(sort(F(3),)),取前个个体,使 P(t+1) 个体数量达到N。然后通过遗传算子(选择、交叉、变异)产生新的子代种群 Q(t+1)。
算法的整体复杂性为,由算法的非支配排序部分决定。
3、代码举例
import geatpy as ea
import numpy as np
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self):
name = 'NSGA2算法' # 初始化name(函数名称,可以随意设置)
M = 2 # 优化目标个数(两个x)
maxormins = [1] * M # 初始化maxormins(目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标)
Dim = 1 # 初始化Dim(决策变量维数)
varTypes = [0] # 初始化varTypes(决策变量的类型,0:实数;1:整数)
lb = [-10] # 决策变量下界(自定义个上下界搜索)
ub = [10] # 决策变量上界
lbin = [1] # 决策变量下边界(0表示不包含该变量的下边界,1表示包含)
ubin = [1] # 决策变量上边界(0表示不包含该变量的上边界,1表示包含)
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
def evalVars(self, Vars): # 目标函数
f1 = Vars ** 2 # 第一个目标函数
f2 = (Vars - 2) ** 2 # 第二个目标函数
ObjV = np.hstack([f1, f2]) # 计算目标函数值矩阵
CV = -Vars ** 2 + 2.5 * Vars - 1.5 # 构建违反约束程度矩阵(需要转换为小于,反转一下)
return ObjV, CV
# 实例化问题对象
problem = MyProblem()
# 构建算法
algorithm = ea.moea_NSGA2_templet(problem,
# RI编码,种群个体50
ea.Population(Encoding='RI', NIND=50),
MAXGEN=200, # 最大进化代数
logTras=1) # 表示每隔多少代记录一次日志信息,0表示不记录。
# 求解
res = ea.optimize(algorithm, seed=1, verbose=False, drawing=1, outputMsg=True, drawLog=False, saveFlag=False, dirName='result')
4、帕累托最优解
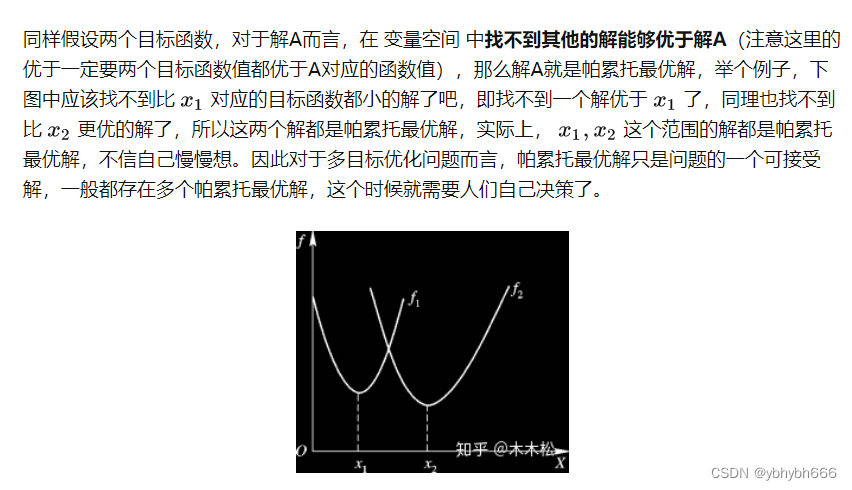
parero寻优类似于推荐系统,简单来说就是系统没有决定权,只有建议权。所以系统会推荐一系列在当前评价函数下性能相似的解。这个时候就需要决策者使用决定权从这些解中选择一个。如果是理论问题的话,最简单的就是随机选一个,反正都一样。但是到了实际问题,那就得具体问题具体分析了。比如,一次期末考试,考数学,语文和英语(三个评价函数),那么系统就会推荐你这三科分别的第一(parero 最优),然后让你从中间选一个最好的,你会怎么选?如果你是个普通老师,你会选总分最高的。但是如果你是一个数学竞赛的老师,你会选一个数学最高的那个。归根到底,还是那句话,具体问题具体分析。
————————————————
资料来源:CSDN博主「蓝色蛋黄包」的原创文章
原文链接:https://blog.csdn.net/haha0332/article/details/88672634
智能推荐
CSS背景特殊属性值-程序员宅基地
文章浏览阅读52次。CSS代码示例-背景附着属性(background-attachment)-[背景图固定不动,不跟随滚动条滚动]:<html><head><title>背景附着属性 background-attachment</title><style type="text/css">body {background-image:url(../image..._背景附着方式的属性值
Python-第一阶段-第二章 字面量-程序员宅基地
文章浏览阅读863次,点赞24次,收藏18次。Python字面量
《算法导论》第2章 算法基础(插入排序、归并排序、复杂度计算)_61,55,97,30,38,58两轮选择递增排序法-程序员宅基地
文章浏览阅读1k次。(最近在自己学习《算法导论》一本书,之前本来喜欢手写笔记,但是随即发现自己总是把笔记弄丢,所以打算做一个电子版的笔记)(另外书中用的都是伪代码,笔记中如果需要尝试的地方都是python代码)2.1 插入排序 基本思想:将待排序的数列看成两个部分(以从小到大为例),前一半是排序完成的,后一半是乱序的,对于乱序的第一个,开始和前一半里最大的数字、第二大的数字……依次比较,等到合适的位置就将它放进去。然后比对过的数字向后移动一位,相应的排序完成的长度加一,没有排序的减一。如:5 |..._61,55,97,30,38,58两轮选择递增排序法
把这份关于Android Binder原理一系列笔记研究完,进大厂是个“加分项”(2)-程序员宅基地
文章浏览阅读674次,点赞21次,收藏21次。可以看出,笔者的工作学习模式便是由以下。
Vue实战(三):实现树形表格_vue树形表格组件-程序员宅基地
文章浏览阅读1.1k次。实现树形表格_vue树形表格组件
Linux平台下很实用的44个Linux命令-程序员宅基地
文章浏览阅读237次。Linux平台下很实用的44个Linux命令大家好,今天再继续和大家说下基础的命令,实在是不知道基础的东西还有什么是应该和大家讲的了,要是再开基础的东西,我觉得就得和大家说交换机和路由器什么的了。今天和大家说一下linux运维其实一般来说,能精通100+的命令,就是一个合格的运维人员了,意思就是你的基础已经差不多了。但是在实际运维工作中需要经常运用到的一些命令,今天就和大家简单的说一下,因
随便推点
2023年Java华为OD真题机考题库大全-带答案(持续更新)_华为od机试题-程序员宅基地
文章浏览阅读1.2w次,点赞16次,收藏149次。2023年华为OD真题目前华为社招大多数是OD招聘,17级以下都为OD模式,OD模式也是华为提出的一种新的用工形式,定级是13-17级,属于华为储备人才,每年都会从OD项目挑优秀员工转为正编。D1-D5对应薪资10K-35K左右,年终奖2-4个月,周六加班双倍工资,下个月发。入职OD会有一定薪资上涨,之后每年一次加薪,OD转华为一次加薪。等不到转正机会,相对于内部员工来说,容易被裁,不稳定,可能接触不到核心项目,功能。具体转条件:连续N个季度绩效为A,部门有转正名额,排队。_华为od机试题
python selenium自动化之chrome与chromedriver版本兼容问题_chrome版本122.0.6261.112和chromdriver 107.0.5304.62兼容-程序员宅基地
文章浏览阅读2.7k次,点赞3次,收藏10次。在我们使用python+selenium来驱动chrome浏览器时,需要有chromedriver的支持,但是chrome浏览器更新比较频繁,而chrome浏览器和chromedriver则需要保持版本一致(版本一般相差1以内),此时我们就需要手动下载chromedriver来匹配此时的浏览器,但是生产环境操作比较麻烦。此时,我们就想是不是有一个程序来代替我们完成这个工作呢?思路比较当前的chrome浏览器版本号与chromedriver浏览号如果不匹配,则下载一个新的chromedriver替换掉_chrome版本122.0.6261.112和chromdriver 107.0.5304.62兼容吗
测试人员如何规划自己的职业生涯,分享我这些年的测开的总结给大家参考~_测开个人成长计划-程序员宅基地
文章浏览阅读2.7k次,点赞2次,收藏11次。负责开发项目的技术方法。我的一位同事曾经很认真地问过我一个问题,他说他现在从事软件测试工作已经4年了,但是他不知道现在的工作和自己在工作3年时有什么不同,他想旁观者清,也许我能回答他的问题。随着互联网的飞快发展,IT行业出现了日新月异的变化,新的技术会不断出现,你熟练掌握的软件测试技术很快就过时了。至于第三点说的实践和思考就是你对自己学到的东西的一个掌握的程度的检验了,只有实践了你才能知道,这个知识点你到底学会了没有,会了之后有没有什么其他的理解,这个就是需要自己去思考了 ,这种东西都是别人教不了你的!_测开个人成长计划
MATLAB代码:多微网电能互补与需求响应的微网双层优化模型——动态定价与能量管理_配电网和微电网的matlab模型-程序员宅基地
文章浏览阅读734次,点赞21次,收藏13次。主要内容:代码主要做的是考虑多微网电能互补共享的微网双层优化模型,同时优化配电网运营商的动态电价以及微网用户的能量管理策略,在上层,目标函数为配电网运营商的收益最大化,决策变量为配电网运营商的交易电价;主要内容:代码主要做的是考虑多微网电能互补共享的微网双层优化模型,同时优化配电网运营商的动态电价以及微网用户的能量管理策略,在上层,目标函数为配电网运营商的收益最大化,决策变量为配电网运营商的交易电价;最后,我们输出最终的结果,包括最优的用电费用、配网运营商的收益以及每个微网的用电费用分配情况。_配电网和微电网的matlab模型
基于双极性SPWM调制的三相电压型桥式逆变电路原理解析-程序员宅基地
文章浏览阅读378次,点赞3次,收藏3次。首先介绍了逆变电路的基本原理和应用领域,然后详细分析了双极性SPWM调制方式的工作原理和优势。本文通过对三相电压型桥式逆变电路和双极性SPWM调制方式的技术分析,深入探讨了其在电力系统中的应用和性能评估。双极性SPWM调制方式是SPWM调制方式的一种改进形式,它能够更好地抑制谐波,提高逆变电路的输出质量。面对电力系统的不断发展和需求的变化,逆变电路和SPWM调制方式也在不断演进。为了评估三相电压型桥式逆变电路和双极性SPWM调制方式的性能,本节将详细分析其输出波形的失真程度、功率损耗和效率等关键指标。
用cmake 编译 xcode用的clucene静态库(一)_clucene-config.h-程序员宅基地
文章浏览阅读4.5k次。第一步、下载源代码 http://sourceforge.net/projects/clucene/ 第二步、下载cmakehttp://www.cmake.org/cmake/resources/software.html 编译第一步,打开在应用程序中的cmake GUI程序,设置好源代码路径,和输出路径,如图: 第二步,点击Configure,在_clucene-config.h