LoRA学习笔记_全量更新 lora-程序员宅基地
Background
- 全参微调
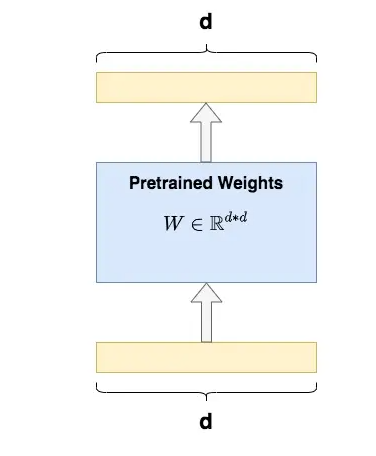
全量微调指的是,在下游任务的训练中,对预训练模型的每一个参数都做更新。例如图中,给出了Transformer的Q/K/V矩阵的全量微调示例,对每个矩阵来说,在微调时,其d*d个参数,都必须参与更新。
- 全量微调的显著缺点是,训练代价昂贵。例如GPT3的参数量有175B,我等单卡贵族只能望而却步,更不要提在微调中发现有bug时的覆水难收。同时,由于模型在预训练阶段已经吃了足够多的数据,收获了足够的经验。
- 因此我只要想办法给模型增加一个额外知识模块,让这个小模块去适配我的下游任务,模型主体保持不变(freeze)即可。
- 局部微调办法
Adapter Tuning:
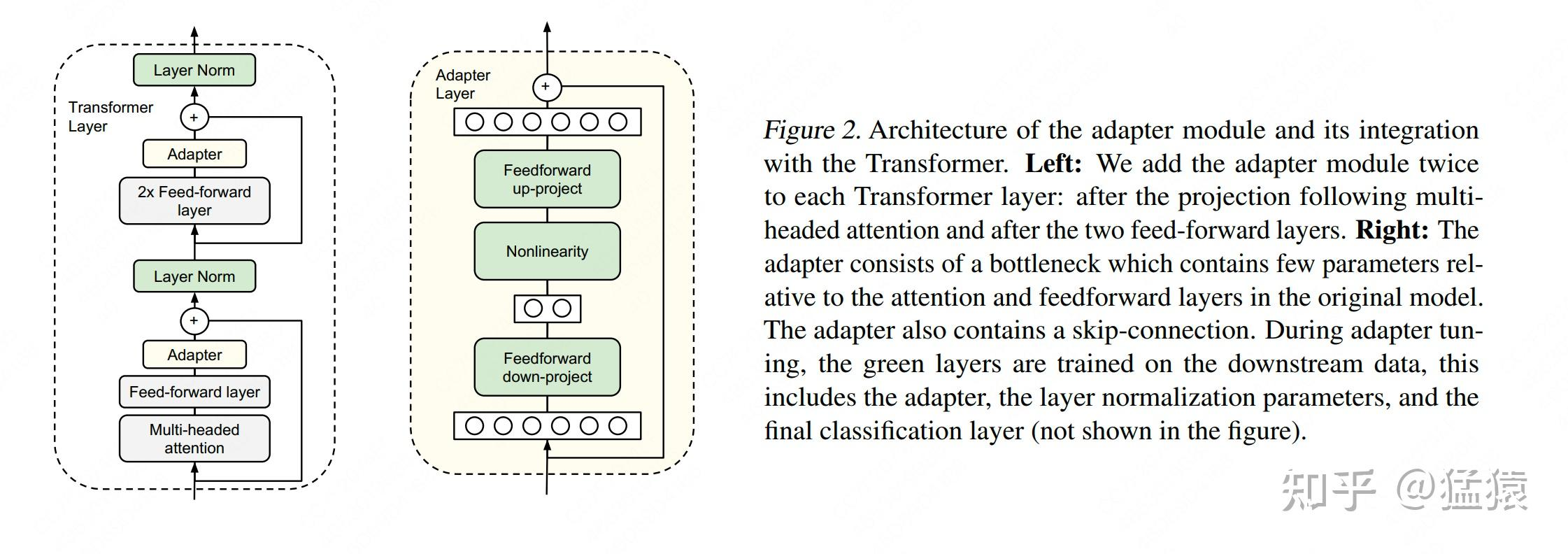
- 图例中的左边是一层Transformer Layer结构,其中的Adapter就是我们说的“额外知识模块”;右边是Adatper的具体结构。在微调时,除了Adapter的部分,其余的参数都是被冻住的(freeze),这样我们就能有效降低训练的代价。
但这样的设计架构存在一个显著劣势:添加了Adapter后,模型整体的层数变深,会增加训练速度和推理速度,原因是:
- 需要耗费额外的运算量在Adapter上
- 当我们采用并行训练时(例如Transformer架构常用的张量模型并行),Adapter层会产生额外的通讯量,增加通讯时间
Prefix Tuning

通过对输入数据增加前缀(prefix)来做微调。当然,prefix也可以不止加载输入层,还可以加在Transformer Layer输出的中间层。
对于GPT这样的生成式模型,在输入序列的最前面加入prefix token,图例中加入2个prefix token,在实际应用中,prefix token的个数是个超参,可以根据模型实际微调效果进行调整。
对于BART这样的Encoder-Decoder架构模型,则在x和y的前面同时添加prefix token。在后续微调中,我们只需要冻住模型其余部分,单独训练prefix token相关的参数即可,每个下游任务都可以单独训练一套prefix token。
- 那么prefix的含义是什么呢?
prefix的作用是引导模型提取x相关的信息,进而更好地生成y。
例如,我们要做一个summarization的任务,那么经过微调后,prefix就能领悟到当前要做的是个“总结形式”的任务,然后引导模型去x中提炼关键信息;
如果我们要做一个情感分类的任务,prefix就能引导模型去提炼出x中和情感相关的语义信息,以此类推。这样的解释可能不那么严谨,但大家可以大致体会一下prefix的作用。
Prefix Tuning虽然看起来方便,但也存在以下两个显著劣势;
较难训练,且模型的效果并不严格随prefix参数量的增加而上升,这点在原始论文中也有指出会使得输入层有效信息长度减少。为了节省计算量和显存,我们一般会固定输入数据长度。增加了prefix之后,留给原始文字数据的空间就少了,因此可能会降低原始文字中prompt的表达能力。
LoRA
全参数微调太贵,Adapter Tuning存在训练和推理延迟,Prefix Tuning难训且会减少原始训练数据中的有效文字长度,那是否有一种微调办法,能改善这些不足呢?
- 在这样动机的驱动下,作者提出了LoRA(Low-Rank Adaptation,低秩适配器)这样一种微调方法。
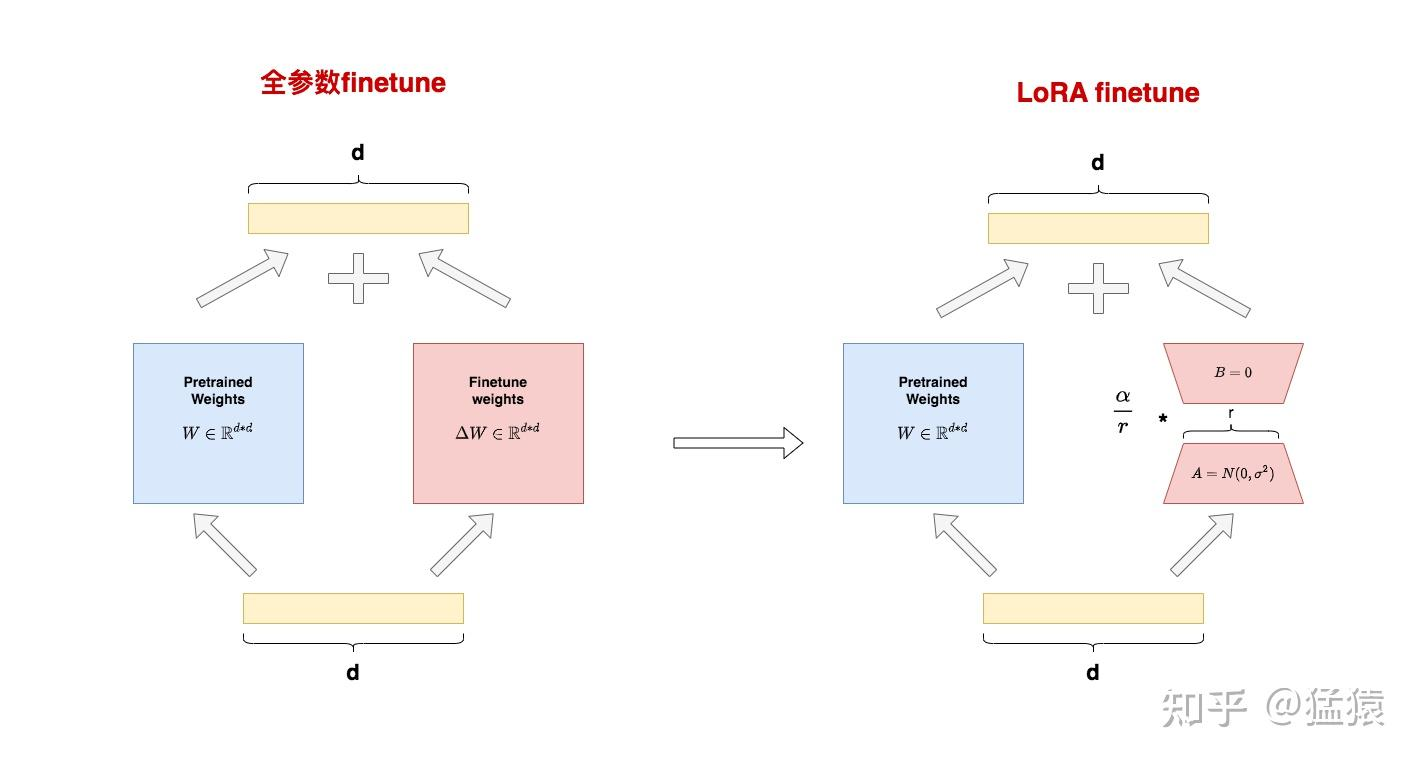

核心思想 - SVD


- 小小的总结一下:W矩阵SVD分解(近似1),然后取三个分解矩阵的top r行(近似2)= W最重要的特征
SVD Code
import torch
import numpy as np
torch.manual_seed(0)
# ------------------------------------
# n:输入数据维度
# m:输出数据维度
# ------------------------------------
n = 10
m = 10
# ------------------------------------
# 随机初始化权重W
# 之所以这样初始化,是为了让W不要满秩,
# 这样才有低秩分解的意义
# ------------------------------------
nr = 10
mr = 2
W = torch.randn(nr,mr)@torch.randn(mr,nr)
# ------------------------------------
# 随机初始化输入数据x
# ------------------------------------
x = torch.randn(n)
# ------------------------------------
# 计算Wx
# ------------------------------------
y = W@x
print("原始权重W计算出的y值为:\n", y)
# ------------------------------------
# 计算W的秩
# ------------------------------------
r= np.linalg.matrix_rank(W)
print("W的秩为: ", r)
# ------------------------------------
# 对W做SVD分解
# ------------------------------------
U, S, V = torch.svd(W)
# ------------------------------------
# 根据SVD分解结果,
# 计算低秩矩阵A和B
# ------------------------------------
U_r = U[:, :r]
S_r = torch.diag(S[:r])
V_r = V[:,:r].t()
B = U_r@S_r # shape = (d, r)
A = V_r # shape = (r, d)
# ------------------------------------
# 计算y_prime = BAx
# ------------------------------------
y_prime = B@A@x
print("SVD分解W后计算出的y值为:\n", y)
print("原始权重W的参数量为: ", W.shape[0]*W.shape[1])
print("低秩适配后权重B和A的参数量为: ", A.shape[0]*A.shape[1] + B.shape[0]*B.shape[1])
- 输出的结果不变,参数量减小很多
原始权重W计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
W的秩为: 2
SVD分解W后计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
原始权重W的参数量为: 100
低秩适配后权重B和A的参数量为: 40
很有意思的自相矛盾

超参数 α \alpha α

实验验证:
尽管理论上我们可以在模型的任意一层嵌入低秩适配器(比如Embedding, Attention,MLP等),但LoRA中只选咋在Attention层嵌入,并做了相关实验

LoRA使用
LoRA源码
class LoRALayer():
def __init__(
self,
r: int, # 矩阵的秩
lora_alpha: int, # 超参数a
lora_dropout: float,
merge_weights: bool,
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
self.merged = False
self.merge_weights = merge_weights
Embedding层
class Embedding(nn.Embedding, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
num_embeddings: int,
embedding_dim: int,
r: int = 0,
lora_alpha: int = 1,
merge_weights: bool = True,
**kwargs
):
nn.Embedding.__init__(self, num_embeddings, embedding_dim, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=0,
merge_weights=merge_weights)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, num_embeddings)))
self.lora_B = nn.Parameter(self.weight.new_zeros((embedding_dim, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
def reset_parameters(self):
nn.Embedding.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.zeros_(self.lora_A)
nn.init.normal_(self.lora_B)
def train(self, mode: bool = True):
nn.Embedding.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += (self.lora_B @ self.lora_A).transpose(0, 1) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
if self.r > 0 and not self.merged:
result = nn.Embedding.forward(self, x)
after_A = F.embedding(
x, self.lora_A.transpose(0, 1), self.padding_idx, self.max_norm,
self.norm_type, self.scale_grad_by_freq, self.sparse
)
result += (after_A @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return nn.Embedding.forward(self, x)
Linear层实现
class Linear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(self.weight.new_zeros((r, in_features)))
self.lora_B = nn.Parameter(self.weight.new_zeros((out_features, r)))
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode: bool = True):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
nn.Linear.train(self, mode)
if mode:
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= T(self.lora_B @ self.lora_A) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += T(self.lora_B @ self.lora_A) * self.scaling
self.merged = True
def forward(self, x: torch.Tensor):
def T(w):
return w.transpose(0, 1) if self.fan_in_fan_out else w
if self.r > 0 and not self.merged:
result = F.linear(x, T(self.weight), bias=self.bias)
result += (self.lora_dropout(x) @ self.lora_A.transpose(0, 1) @ self.lora_B.transpose(0, 1)) * self.scaling
return result
else:
return F.linear(x, T(self.weight), bias=self.bias)
class MergedLinear(nn.Linear, LoRALayer):
# LoRA implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.,
enable_lora: List[bool] = [False],
fan_in_fan_out: bool = False,
merge_weights: bool = True,
**kwargs
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout,
merge_weights=merge_weights)
assert out_features % len(enable_lora) == 0, \
'The length of enable_lora must divide out_features'
self.enable_lora = enable_lora
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0 and any(enable_lora):
self.lora_A = nn.Parameter(
self.weight.new_zeros((r * sum(enable_lora), in_features)))
self.lora_B = nn.Parameter(
self.weight.new_zeros((out_features // len(enable_lora) * sum(enable_lora), r))
) # weights for Conv1D with groups=sum(enable_lora)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
# Compute the indices
self.lora_ind = self.weight.new_zeros(
(out_features, ), dtype=torch.bool
).view(len(enable_lora), -1)
self.lora_ind[enable_lora, :] = True
self.lora_ind = self.lora_ind.view(-1)
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.transpose(0, 1)
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def zero_pad(self, x):
result = x.new_zeros((len(self.lora_ind), *x.shape[1:]))
result[self.lora_ind] = x
return result
卷积层
class ConvLoRA(nn.Module, LoRALayer):
def __init__(self, conv_module, in_channels, out_channels, kernel_size, r=0, lora_alpha=1, lora_dropout=0., merge_weights=True, **kwargs):
super(ConvLoRA, self).__init__()
self.conv = conv_module(in_channels, out_channels, kernel_size, **kwargs)
LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
assert isinstance(kernel_size, int)
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Parameter(
self.conv.weight.new_zeros((r * kernel_size, in_channels * kernel_size))
)
self.lora_B = nn.Parameter(
self.conv.weight.new_zeros((out_channels//self.conv.groups*kernel_size, r*kernel_size))
)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.conv.weight.requires_grad = False
self.reset_parameters()
self.merged = False
def reset_parameters(self):
self.conv.reset_parameters()
if hasattr(self, 'lora_A'):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
nn.init.zeros_(self.lora_B)
def train(self, mode=True):
super(ConvLoRA, self).train(mode)
if mode:
if self.merge_weights and self.merged:
if self.r > 0:
# Make sure that the weights are not merged
self.conv.weight.data -= (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = False
else:
if self.merge_weights and not self.merged:
if self.r > 0:
# Merge the weights and mark it
self.conv.weight.data += (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling
self.merged = True
def forward(self, x):
if self.r > 0 and not self.merged:
return self.conv._conv_forward(
x,
self.conv.weight + (self.lora_B @ self.lora_A).view(self.conv.weight.shape) * self.scaling,
self.conv.bias
)
return self.conv(x)
class Conv2d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv2d, self).__init__(nn.Conv2d, *args, **kwargs)
class Conv1d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv1d, self).__init__(nn.Conv1d, *args, **kwargs)
# Can Extend to other ones like this
class Conv3d(ConvLoRA):
def __init__(self, *args, **kwargs):
super(Conv3d, self).__init__(nn.Conv3d, *args, **kwargs)
QLoRA
四个改进:
- NormalFloat 4 bit:分数位量化,归一化到【-1,1】和模型的权重区间对齐,标准化
- 二次量化:对量化常量二次量化,减少空间占有
- Paged Parameter:内存页优化,使用不连续的内存空间存储KV cache,减少缓存
- 加入了更多的adapter层,每一个FFN layer都加了
智能推荐
【史上最易懂】马尔科夫链-蒙特卡洛方法:基于马尔科夫链的采样方法,从概率分布中随机抽取样本,从而得到分布的近似_马尔科夫链期望怎么求-程序员宅基地
文章浏览阅读1.3k次,点赞40次,收藏19次。虽然你不能直接计算每个房间的人数,但通过马尔科夫链的蒙特卡洛方法,你可以从任意状态(房间)开始采样,并最终收敛到目标分布(人数分布)。然后,根据一个规则(假设转移概率是基于房间的人数,人数较多的房间具有较高的转移概率),你随机选择一个相邻的房间作为下一个状态。比如在巨大城堡,里面有很多房间,找到每个房间里的人数分布情况(每个房间被访问的次数),但是你不能一次进入所有的房间并计数。但是,当你重复这个过程很多次时,你会发现你更有可能停留在人数更多的房间,而在人数较少的房间停留的次数较少。_马尔科夫链期望怎么求
linux以root登陆命令,su命令和sudo命令,以及限制root用户登录-程序员宅基地
文章浏览阅读3.9k次。一、su命令su命令用于切换当前用户身份到其他用户身份,变更时须输入所要变更的用户帐号与密码。命令su的格式为:su [-] username1、后面可以跟 ‘-‘ 也可以不跟,普通用户su不加username时就是切换到root用户,当然root用户同样可以su到普通用户。 ‘-‘ 这个字符的作用是,加上后会初始化当前用户的各种环境变量。下面看下加‘-’和不加‘-’的区别:root用户切换到普通..._限制su root登陆
精通VC与Matlab联合编程(六)_精通vc和matlab联合编程 六-程序员宅基地
文章浏览阅读1.2k次。精通VC与Matlab联合编程(六)作者:邓科下载源代码浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程浅析VC与MATLAB联合编程 Matlab C/C++函数库是Matlab扩展功能重要的组成部分,包含了大量的用C/C++语言重新编写的Matlab函数,主要包括初等数学函数、线形代数函数、矩阵操作函数、数值计算函数_精通vc和matlab联合编程 六
Asp.Net MVC2中扩展ModelMetadata的DescriptionAttribute。-程序员宅基地
文章浏览阅读128次。在MVC2中默认并没有实现DescriptionAttribute(虽然可以找到这个属性,通过阅读MVC源码,发现并没有实现方法),这很不方便,特别是我们使用EditorForModel的时候,我们需要对字段进行简要的介绍,下面来扩展这个属性。新建类 DescriptionMetadataProvider然后重写DataAnnotationsModelMetadataPro..._asp.net mvc 模型description
领域模型架构 eShopOnWeb项目分析 上-程序员宅基地
文章浏览阅读1.3k次。一.概述 本篇继续探讨web应用架构,讲基于DDD风格下最初的领域模型架构,不同于DDD风格下CQRS架构,二者架构主要区别是领域层的变化。 架构的演变是从领域模型到C..._eshoponweb
Springboot中使用kafka_springboot kafka-程序员宅基地
文章浏览阅读2.6w次,点赞23次,收藏85次。首先说明,本人之前没用过zookeeper、kafka等,尚硅谷十几个小时的教程实在没有耐心看,现在我也不知道分区、副本之类的概念。用kafka只是听说他比RabbitMQ快,我也是昨天晚上刚使用,下文中若有讲错的地方或者我的理解与它的本质有偏差的地方请包涵。此文背景的环境是windows,linux流程也差不多。 官网下载kafka,选择Binary downloads Apache Kafka 解压在D盘下或者什么地方,注意不要放在桌面等绝对路径太长的地方 打开conf_springboot kafka
随便推点
VS2008+水晶报表 发布后可能无法打印的解决办法_水晶报表 不能打印-程序员宅基地
文章浏览阅读1k次。编好水晶报表代码,用的是ActiveX模式,在本机运行,第一次运行提示安装ActiveX控件,安装后,一切正常,能正常打印,但发布到网站那边运行,可能是一闪而过,连提示安装ActiveX控件也没有,甚至相关的功能图标都不能正常显示,再点"打印图标"也是没反应解决方法是: 1.先下载"PrintControl.cab" http://support.businessobjects.c_水晶报表 不能打印
一. UC/OS-Ⅱ简介_ucos-程序员宅基地
文章浏览阅读1.3k次。绝大部分UC/OS-II的源码是用移植性很强的ANSI C写的。也就是说某产品可以只使用很少几个UC/OS-II调用,而另一个产品则使用了几乎所有UC/OS-II的功能,这样可以减少产品中的UC/OS-II所需的存储器空间(RAM和ROM)。UC/OS-II是为嵌入式应用而设计的,这就意味着,只要用户有固化手段(C编译、连接、下载和固化), UC/OS-II可以嵌入到用户的产品中成为产品的一部分。1998年uC/OS-II,目前的版本uC/OS -II V2.61,2.72。1.UC/OS-Ⅱ简介。_ucos
python自动化运维要学什么,python自动化运维项目_运维学python该学些什么-程序员宅基地
文章浏览阅读614次,点赞22次,收藏11次。大家好,本文将围绕python自动化运维需要掌握的技能展开说明,python自动化运维从入门到精通是一个很多人都想弄明白的事情,想搞清楚python自动化运维快速入门 pdf需要先了解以下几个事情。这篇文章主要介绍了一个有趣的事情,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获,下面让小编带着大家一起了解一下。_运维学python该学些什么
解决IISASP调用XmlHTTP出现msxml3.dll (0x80070005) 拒绝访问的错误-程序员宅基地
文章浏览阅读524次。2019独角兽企业重金招聘Python工程师标准>>> ..._hotfix for msxml 4.0 service pack 2 - kb832414
python和易语言的脚本哪门更实用?_易语言还是python适合辅助-程序员宅基地
文章浏览阅读546次。python和易语言的脚本哪门更实用?_易语言还是python适合辅助
redis watch使用场景_详解redis中的锁以及使用场景-程序员宅基地
文章浏览阅读134次。详解redis中的锁以及使用场景,指令,事务,分布式,命令,时间详解redis中的锁以及使用场景易采站长站,站长之家为您整理了详解redis中的锁以及使用场景的相关内容。分布式锁什么是分布式锁?分布式锁是控制分布式系统之间同步访问共享资源的一种方式。为什么要使用分布式锁? 为了保证共享资源的数据一致性。什么场景下使用分布式锁? 数据重要且要保证一致性如何实现分布式锁?主要介绍使用redis来实..._redis setnx watch