深度学习与智能故障诊断学习笔记(三)——RNN与LSTM推导详解_深度学习 故障诊断-程序员宅基地
1.RNN
1.1网络结构
标准神经网络的输入输出在不同例子中可能有不同的长度,在学习中并不共享从不同位置上学到的特征。因为标准神经网络的训练集是稳定的,即所有的特征域表达的内容是同一性质的,一旦交换位置,就需要重新学习。故障诊断和健康管理属于带有时间序列的任务场景,在进行学习时参数量巨大,标准神经网络无法体现出时序上的前因后果,所以引入循环神经网络。如图所示为RNN循环神经网络的单元。
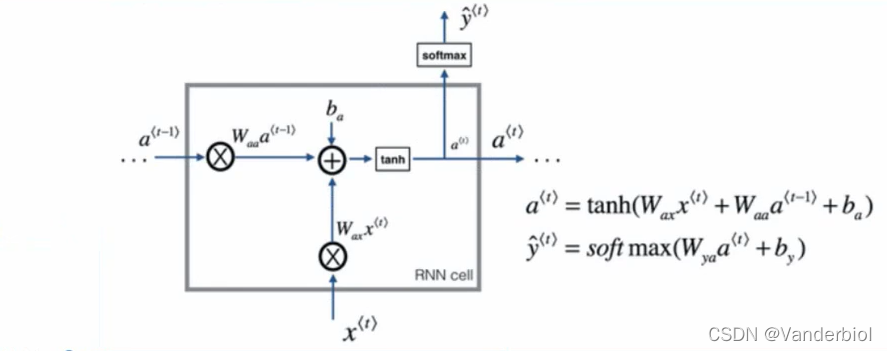
其中为当前输入,
为前一个状态,b为偏置项,tanh为激活函数,用于学习非线性部分。当前输入和前一个状态分别乘以对应权重并相加,在加上偏置项,乘激活函数得到当前状态
,此状态在下一个神经元学习时又作为
进行运算,由此实现时序关联。输出
的激活函数根据任务类型来选择,若是多分类可以选择softmax,若二分类则可直接选择sigmod。
(注:输出并非每个神经元都必须有,RNN可以是多输入多输出,也可以是多输入单输出,仅在学习完成后输出)
1.2RNN网络特点
RNN网络为串联结构,可以体现出“前因后果”,后面结果的生成要参考前面的信息,且所有特征共享一套参数。这使得RNN在面对不同的输入(两个方面),可以学习到不同的相应结果,并极大的减少了训练参数量。
(RNN输入和输出数据在不同场景中可以有不同的长度)
1.3损失函数
单个时间步的损失函数可根据多分类和二分类进行自定义
整个序列的损失函数是将所有单步损失函数相加,如式。
![]()
1.4传播过程
前向传播如图一所示。
反向传播
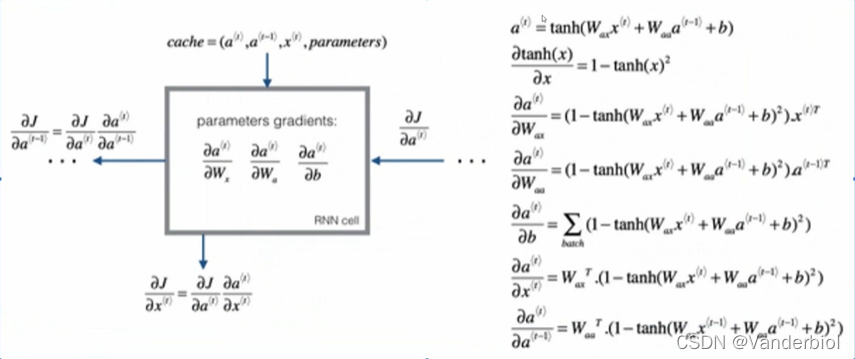
(图源自吴恩达老师课件)
求解梯度即复合函数求导,按照链式法则进行求导。
反向传播具体过程需要按照损失函数来具体求解,但上式对所有RNN模型都适用。
1.5缺点
当序列太长时,容易产生梯度消失,参数更新只能捕捉到局部以来关系,没法再捕捉序列之间长期的关联或依赖关系。
如图为RNN连接,输入x,输出o(简单线性输出),权重w,s为生成状态。
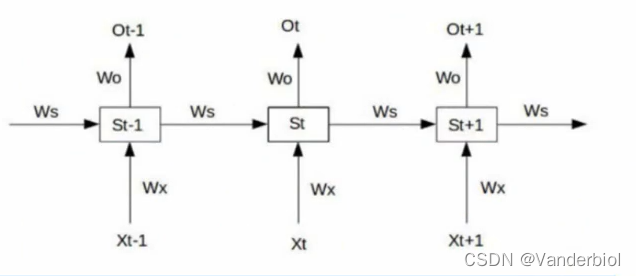
根据前向传播可得:
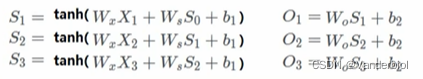
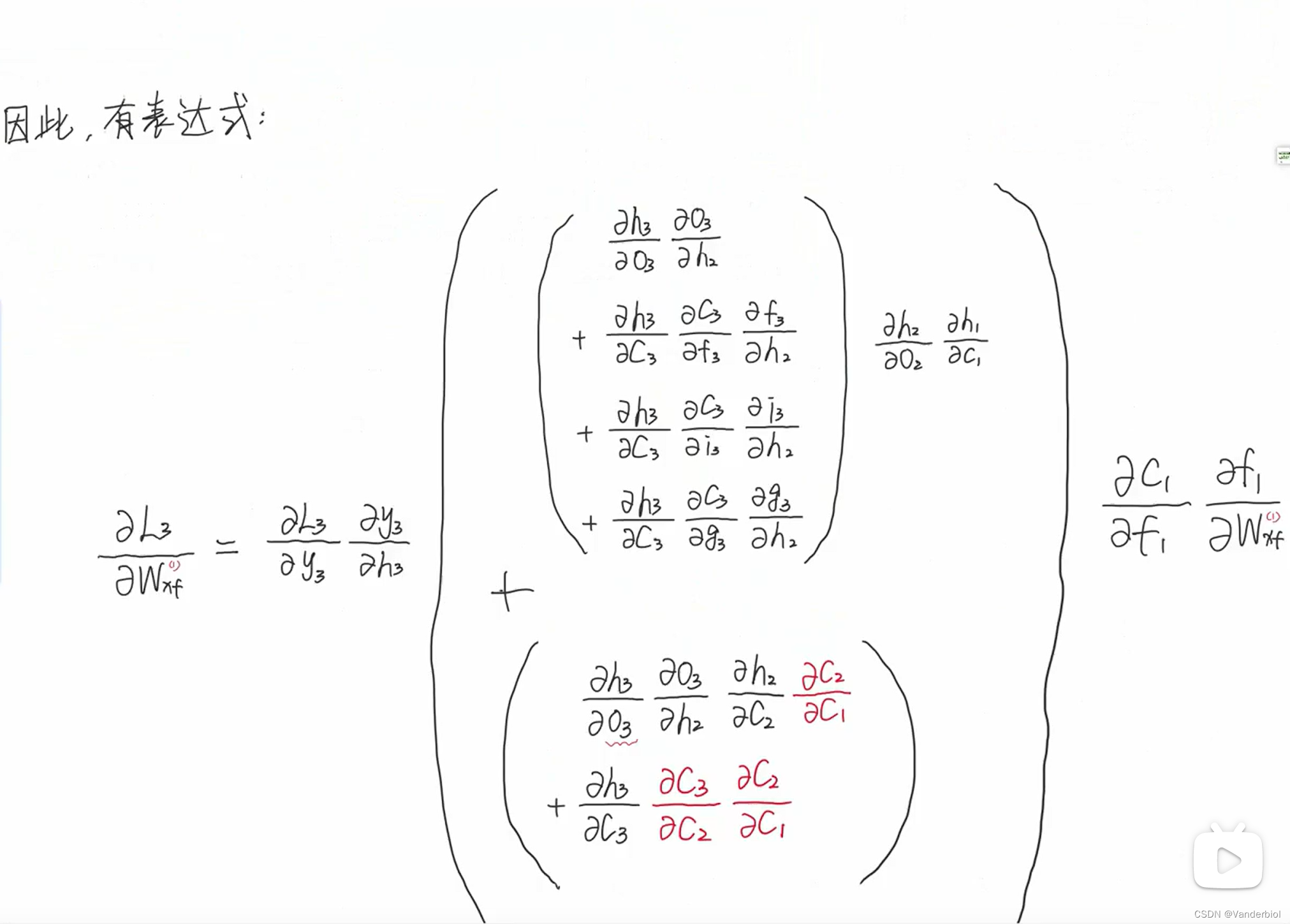
假设使用平方误差作为损失函数,对单个时间点进行求梯度,假设再t=3时刻,损失函数为L3 = 。然后根据网络参数Wx,Ws,Wo,b1,b2等求梯度。
Wo:
![]()
Wx(具体求解过程在下边):
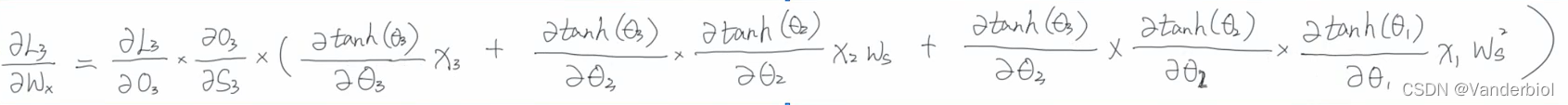
经整理可得:
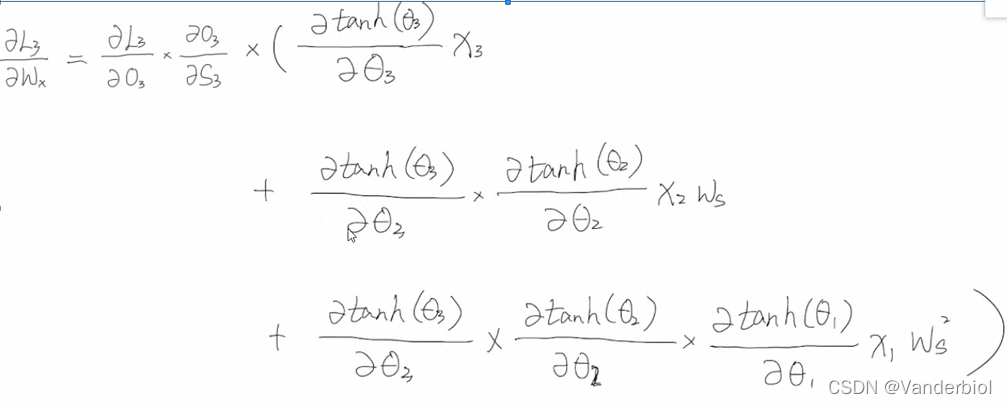
具体求解过程:
首先,所求目标为L3对Wx的偏导,通过链式法则进行展开。对比前向传播公式图可知,O3中并不能直接对Wx求偏导,而是包含在S3中,所以要展开成如下形式。
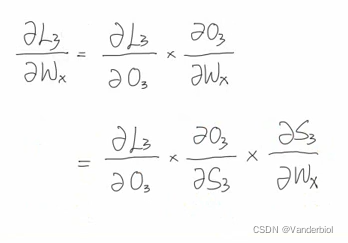
但在S3中又包含S2,S2中包含Wx和S1,S1中又包含Wx,嵌套了很多层,为了方便表示,我们用3来表示S3括号中的内容。进一步简化可得:

由S3演变为S2,同理可递推求出和
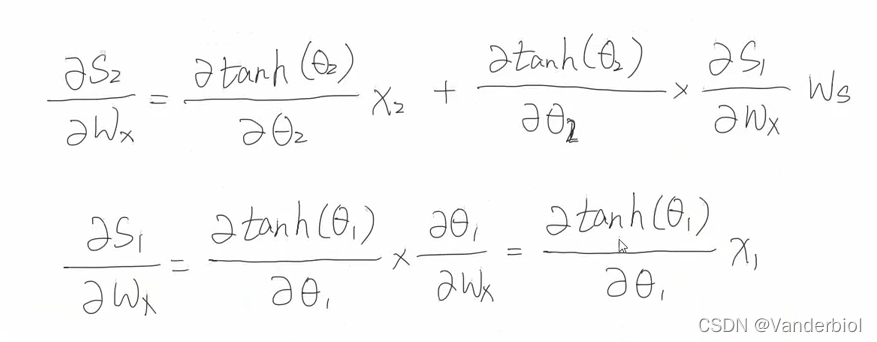
再将所求出结果回代到公式中,可以得出
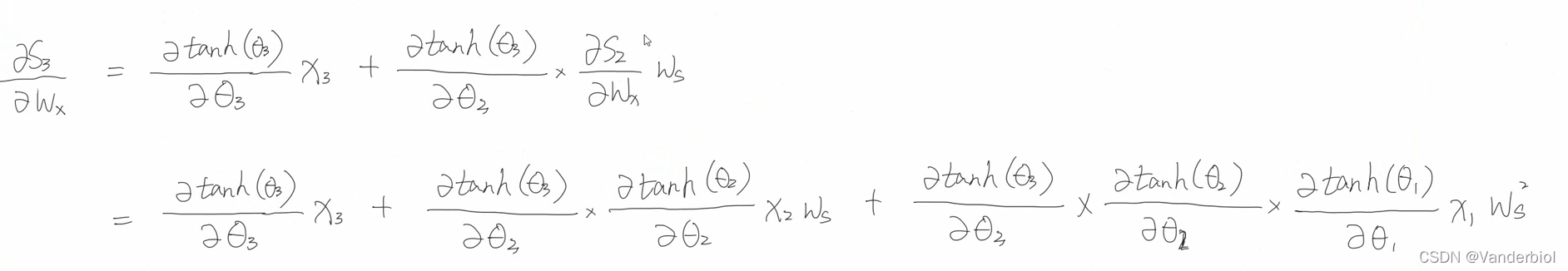
再回带至

由该式可以看出,梯度的更新同时依赖于x3,x2,x1包括其梯度值。将该式处理为
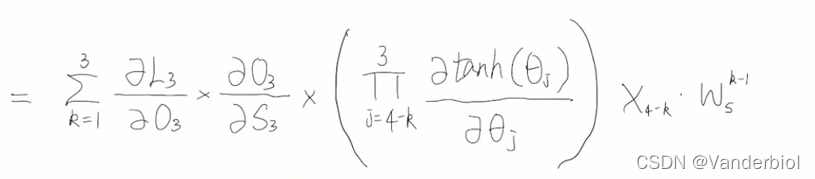
此为t=3时刻的梯度公式,推广至任意时刻的梯度公式为:

此式括号中的项为求导的连乘,此处求出的导数是介于0-1之间的,有一定的机率导致梯度消失(但非主要原因)。造成梯度消失和梯度爆炸的主要原因是最后一项:当Ws很小的时候,它的k-1的次方会无限接近于0,而当Ws大于1时,它的k-1次方会很大。
如下为t=20时梯度更新计算的结果:
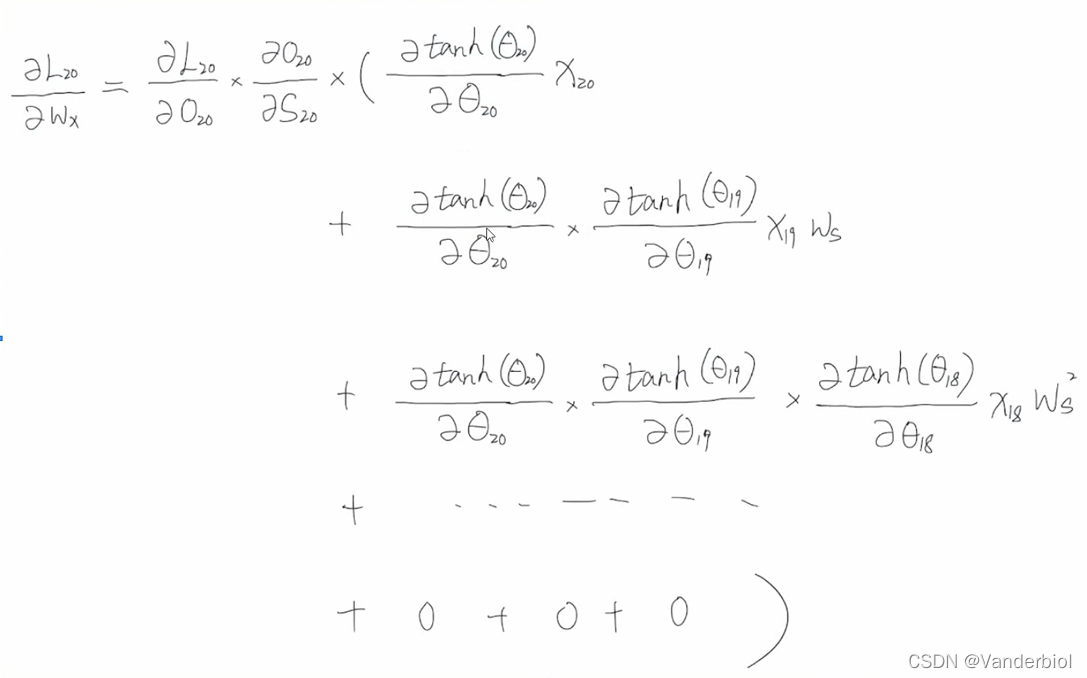
从式中可以看出,t=3的节点由于连乘过多导致梯度消失,无法将信息传给t=20,因此t=20的更新无法引入t=3时的信息,认为t=20节点跟t=3的节点无关联。
对于梯度爆炸和梯度消失,可以通过梯度修剪来解决。相对于梯度爆炸,梯度消失更难解决。而LSTM很好的解决了这些问题。
2.LSTM
2.1设计思路
RNN是想把所有信息都记住,不管是有用的信息还是没用的信息。而LSTM设计了一个记忆细胞,具备选择性记忆功能,可以选择记忆重要信息,过滤掉噪声信息,减轻记忆负担。
2.2整体结构
如图为LSTM与RNN结构对比
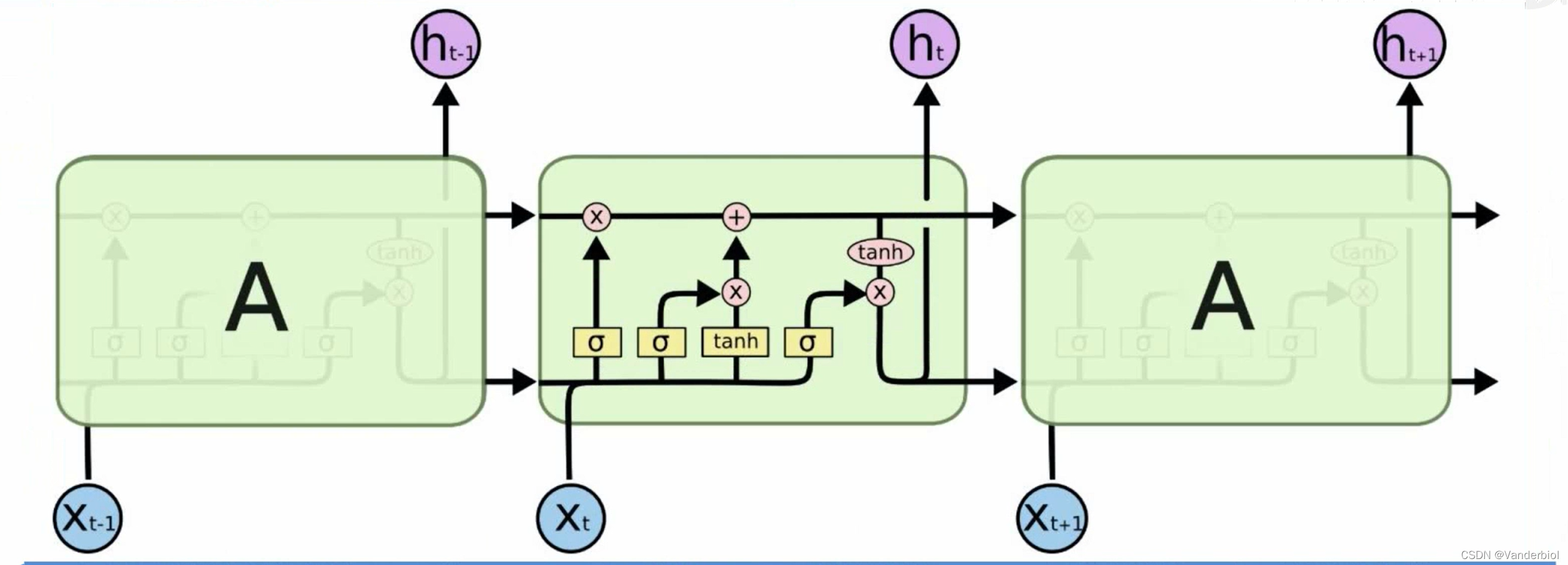
LSTM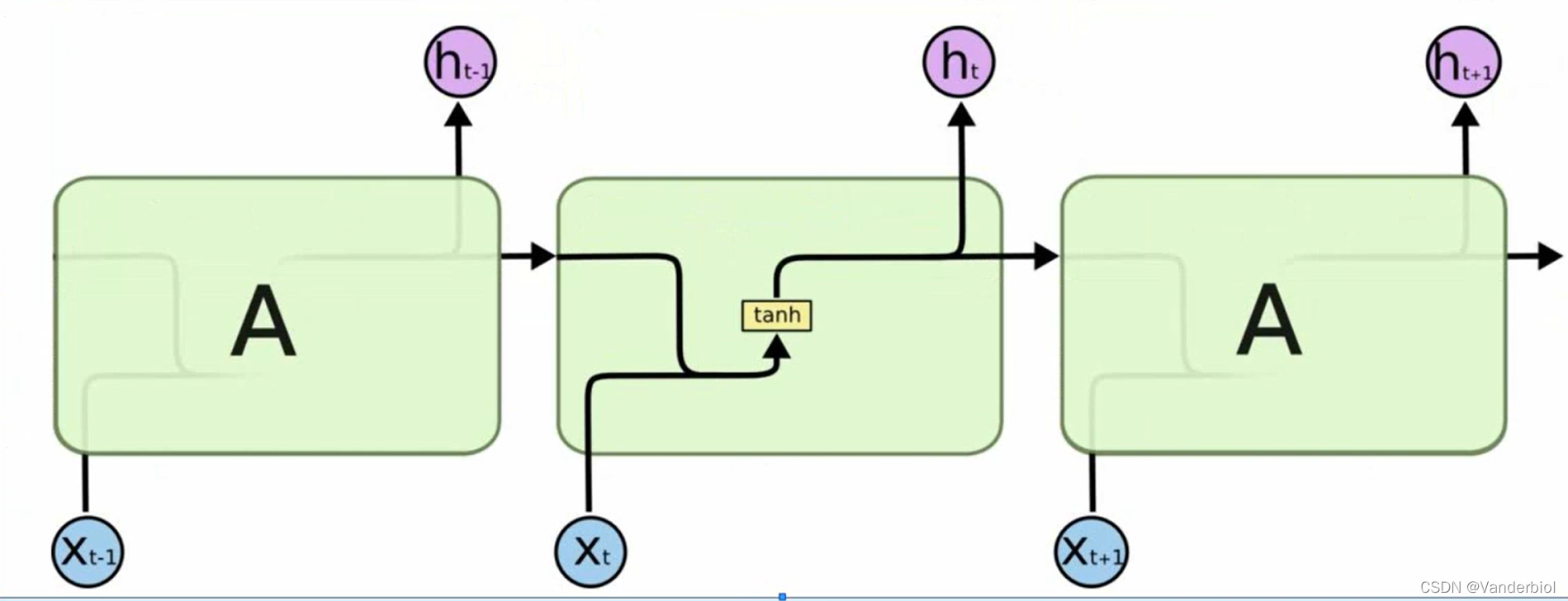
RNN
2.3单元结构
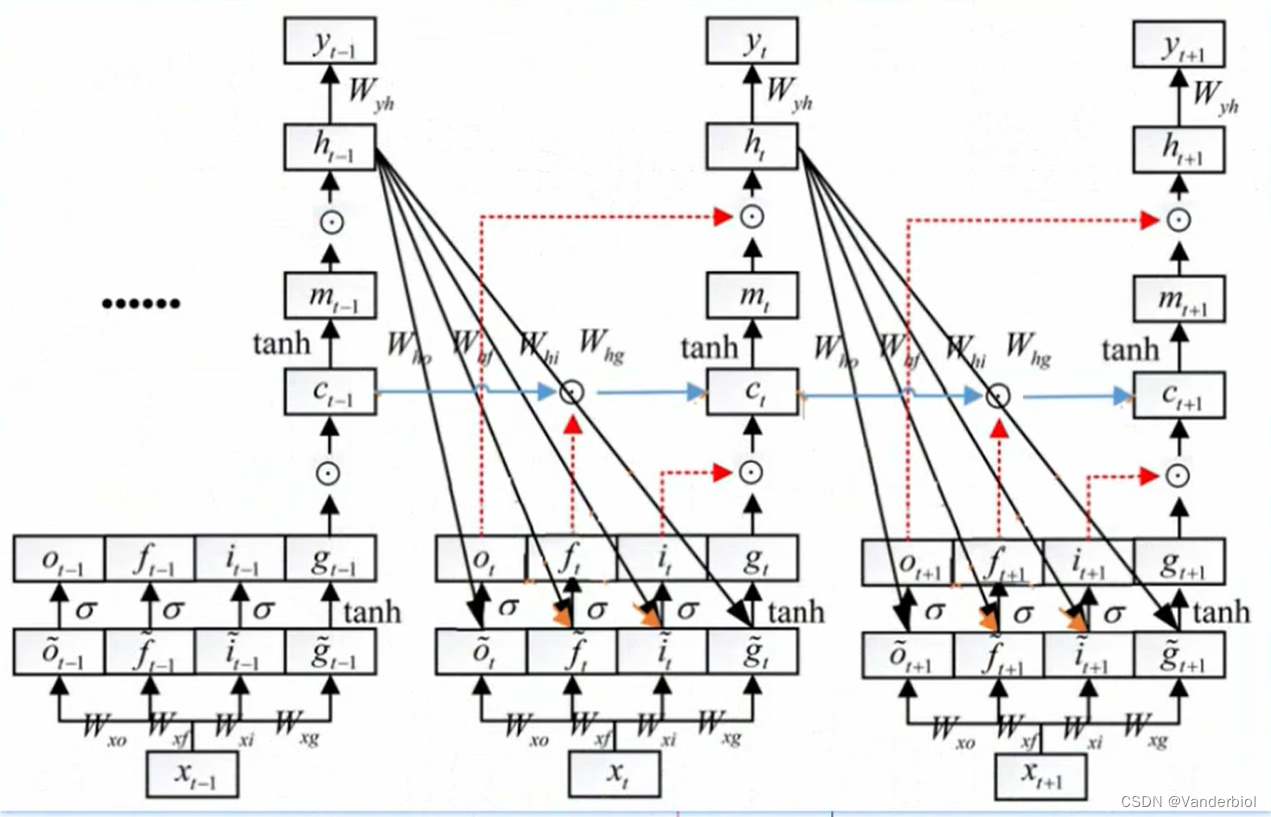
在LSTM每个时间步中,都有一个记忆细胞,这个东西给予了LSTM选择记忆功能,使得LSTM有能力自由选择每个时间步里面记忆的内容。
下图中Ct-1为上一个记忆细胞,ht-1为上一个时间点的状态,经过该单元,输出一个新的记忆细胞和一个新的状态。在单元中有三个,
被称为门单元,它的输出值介于0-1之间。ft为遗忘门,it为更新门,Ot为输出门。
门是一种选择性地让信息通过的方法。它们由sigmoid神经网络层和逐点乘法运算组成。Sigmoid层输出0到1之间的数字,描述每个组件应允许通过多少。值为零表示“不让任何内容通过”,而值为 1 表示“允许所有信息通过”
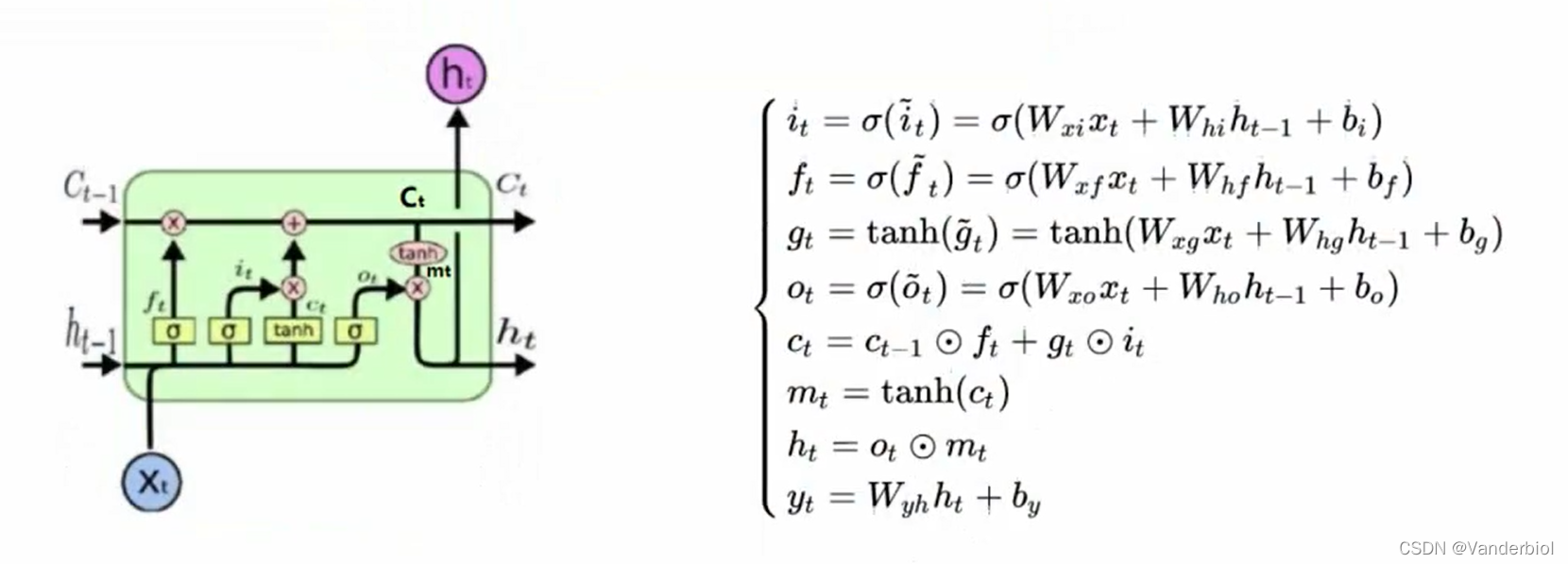
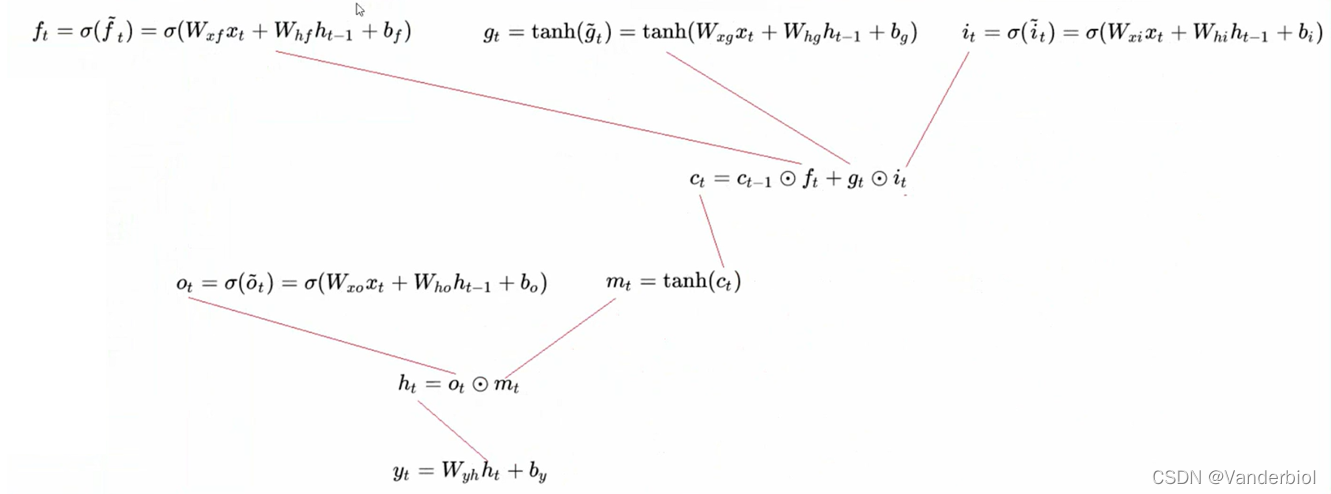
公式所示为前向传播,Ct与Ct-1,ht-1,xt等参数都有关,其中Wxf,Whf,Wxi分别代表相应权重。在单元结构图中可以看出ft与Ct-1进行×运算(对应元素相乘),gt与it进行×运算,两者相加为新生成的ct。
2.4 缓解梯度爆炸和梯度消失
此过程为公式推导(以求Wxf为例)。

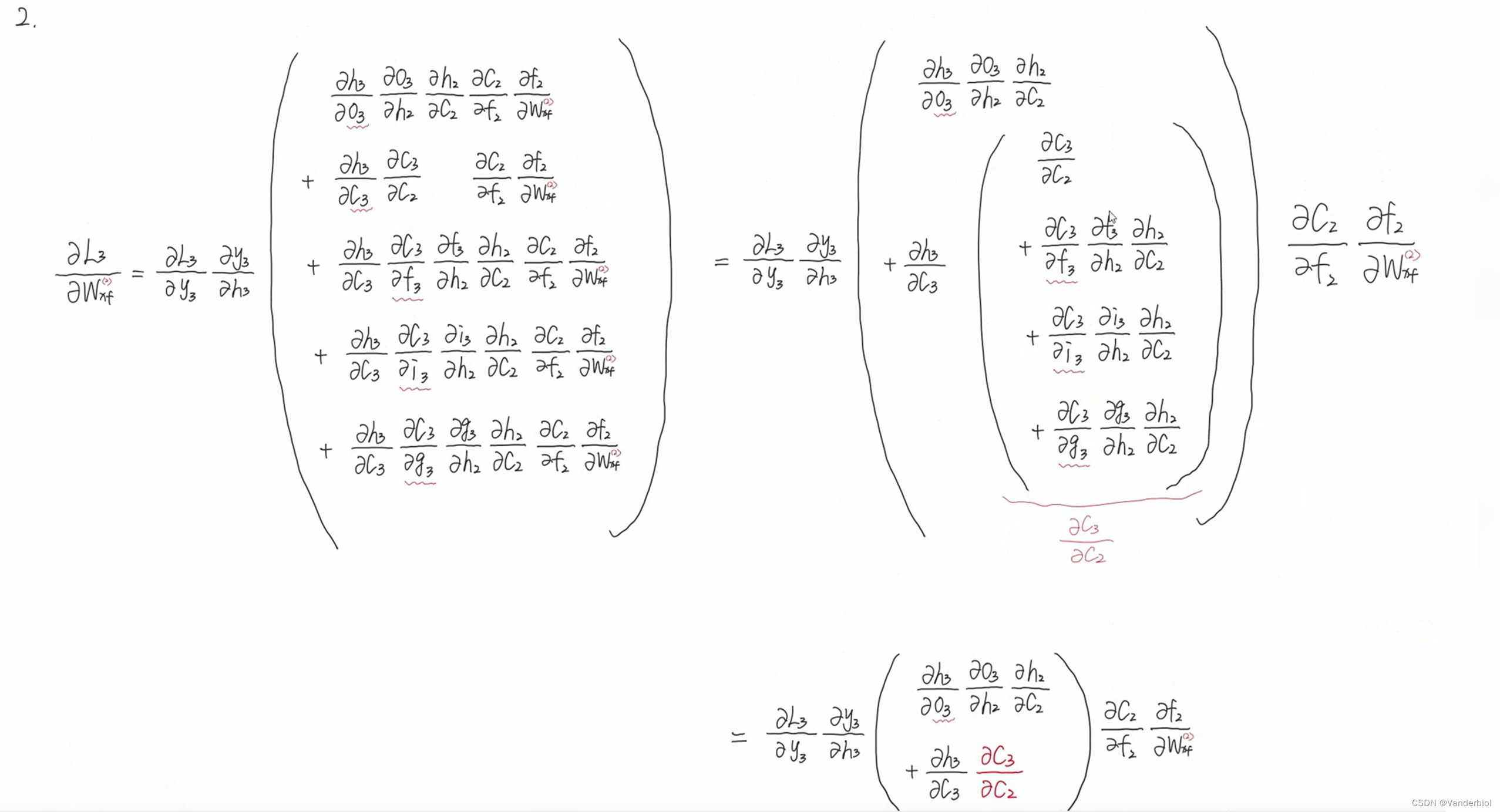
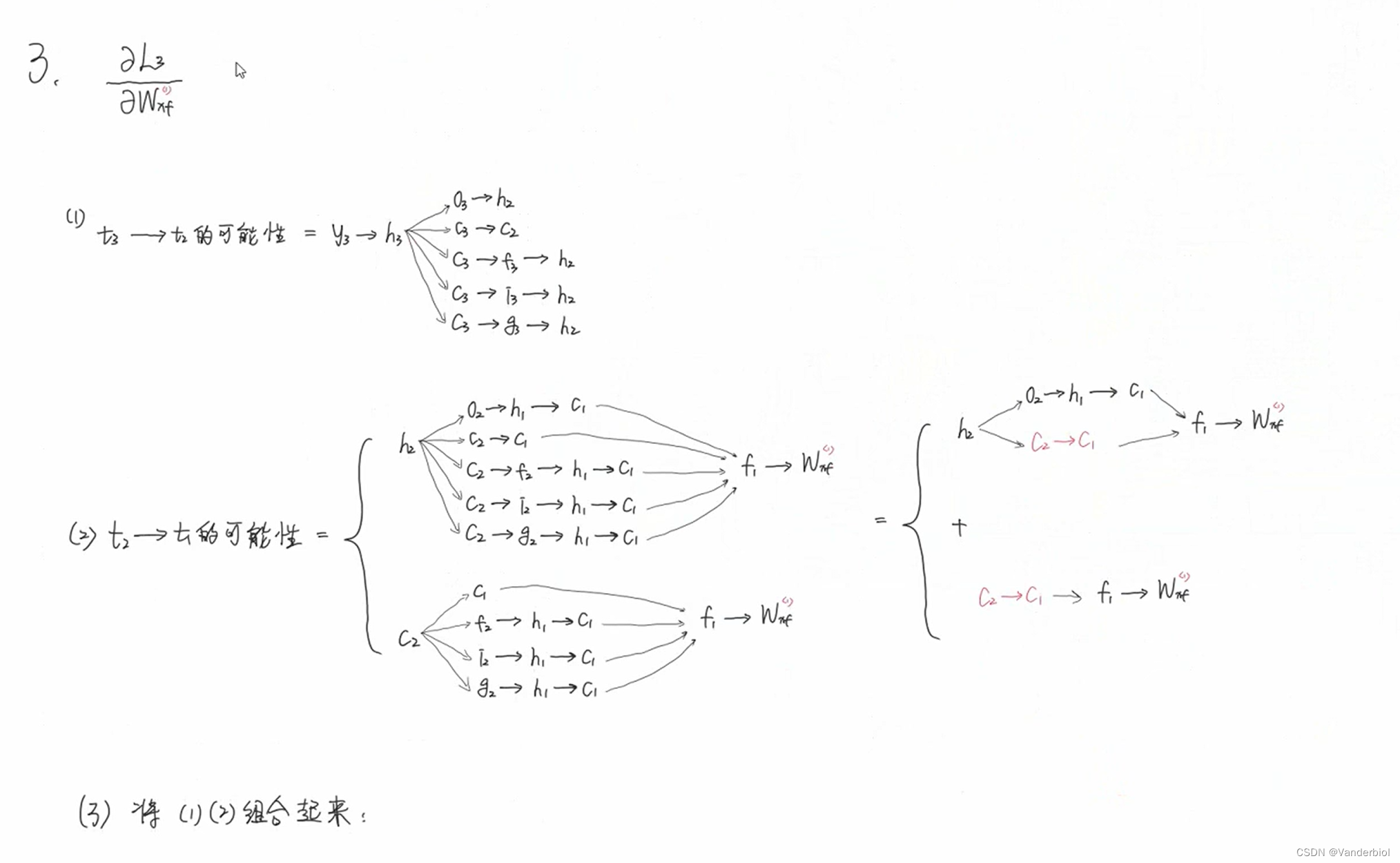
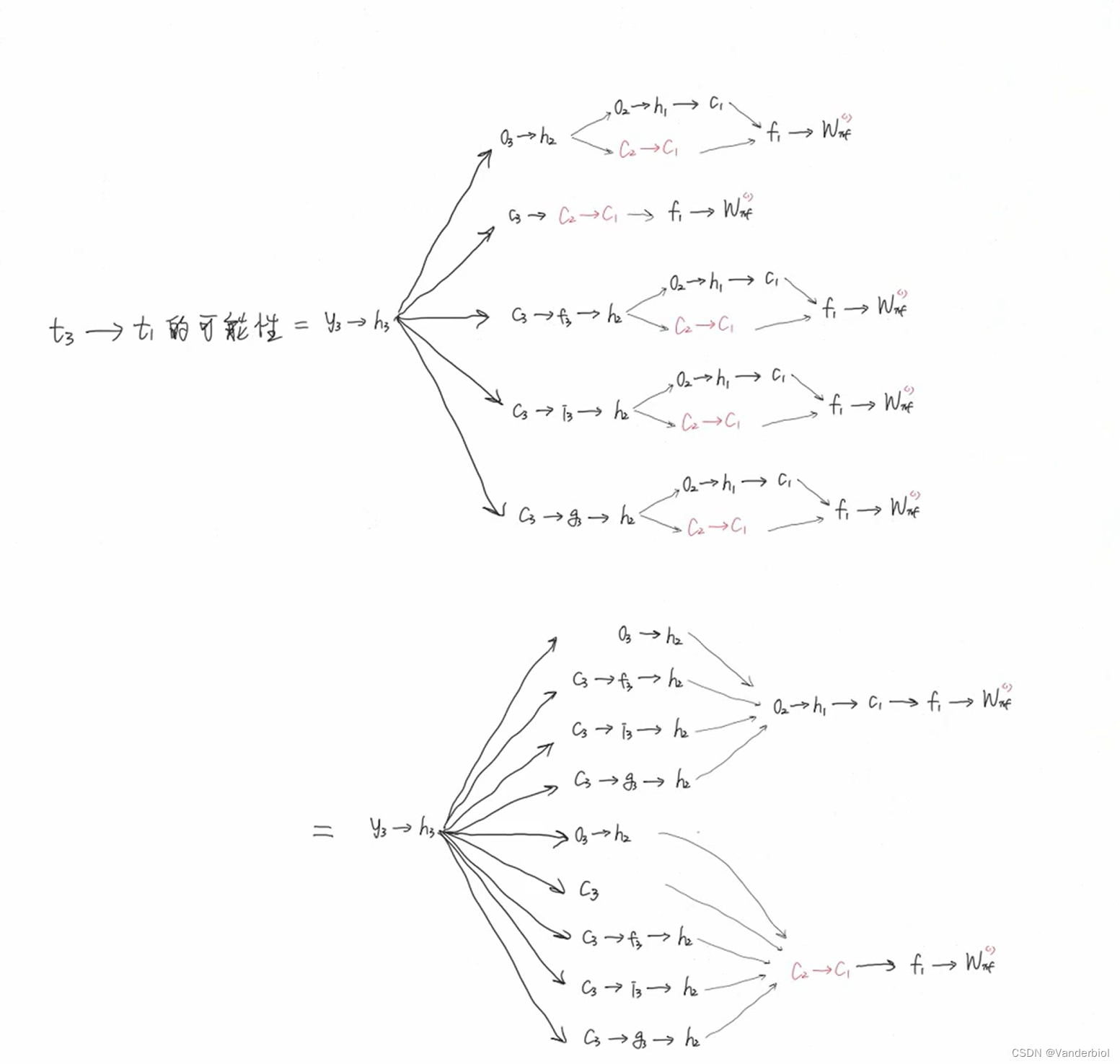
通过调节Whf,Whi,Whg的值,可以灵活控制Ct对Ct-1的偏导值,当要从n时刻长期记忆某个东西到m时刻时,该路径上的![]()
从而大大缓解了梯度消失和梯度爆炸。
(B站搜索老弓的学习日记,本篇博客为RNN与LSTM的学习笔记)
智能推荐
数据库Mysql+SSM技术开发,SSM 泰州市二手房交易平台系统--03401(上万套实战教程手把手教学,免费领取源码)-程序员宅基地
文章浏览阅读162次。关注●点赞收藏并私信博主,免费领取项目源码哦~总体设计主要包括系统总体结构设计、系统数据结构设计、系统功能设计和系统安全设计等;详细设计主要包括模块实现的关键代码,系统数据库访问和主要功能模块的具体实现等。最后对系统进行功能测试,并对测试结果进行分析总结,及时改进系统中存在的不足,为以后的系统维护提供了方便,也为今后开发类似系统提供了借鉴和帮助。
【部署网站】使用nginx+tomcat部署博客网站_用nignx发布网站和用tomcat部署-程序员宅基地
文章浏览阅读3.1k次,点赞3次,收藏16次。一、什么是静态网站、动态网站?静态网站没有采用任何程序开发,是纯粹使用html语言写出的网站,网页文件名以html或htm结尾。原则上不会受到攻击入侵,但是也无法在网络上实时更新内容,就纯粹的是制作好的页面。动态网站目前的主要开发语言有ASP,JSP,PHP,ASP.NET在制作好之后,都有一个网站管理后台,当以管理员身份登陆时,可以对网站的内容进行增删操作,直接在网上进行这些操作,虽然它可以随时更新,但是速度较慢。并且需要区分的是,动态网站的动态指的是动态实时更新而非网站有动态画面。区分静态网站和动_用nignx发布网站和用tomcat部署
android 实现定时任务,Android 实现定时任务的五种方式的讲解-程序员宅基地
文章浏览阅读3.9k次。1、普通线程sleep的方式,可用于一般的轮询Pollingnew Thread(new Runnable() { @Override public void run() { while (true) { //todo ..._android 定时20个小时
Dr_can模型预测控制笔记与代码实现-程序员宅基地
文章浏览阅读2.7w次,点赞206次,收藏552次。因而我们引入模型预测控制(Model PredictiveControl)的概念,对于一般的离散化系统(因为实际计算机实现的控制系统都是离散的系统,连续系统离散化的方法在此不述)。在k时刻,我们可以测量或估计出系统的当前状态y(k),再通过计算得到的u(k),u(k+1),u(k+2)...u(k+j)得到系统未来状态的估计值y(k+1),y(k+2)...y(k+j);我们将预测估计的部分称为预测区间(Predictive Horizon),将控制估计的部分称为控制区间(Control Horizon)_dr_can
由浅入深!小程序FMP优化实录,已拿offer入职_小程序fmp是指的什么(1)-程序员宅基地
文章浏览阅读569次,点赞25次,收藏12次。其实很简单就下面这张图,含概了Android所有需要学的知识点,一共8大板块:架构师筑基必备技能Android框架体系架构(高级UI+FrameWork源码)360°Androidapp全方位性能调优设计思想解读开源框架NDK模块开发移动架构师专题项目实战环节移动架构师不可不学习微信小程序混合开发的flutterAndroid学习的资料我呢,把上面八大板块的分支都系统的做了一份学习系统的资料和视频,大概就下面这些,我就不全部写出来了,不然太长了影响大家的阅读。
计算带余除法(四种方法)_带余除法怎么写编程-程序员宅基地
文章浏览阅读387次,点赞12次,收藏4次。给定两个整数a和b (0 < a,b < 10,000),计算a除以b的整数商和余数。一行,包括两个整数a和b,依次为被除数和除数(不为零),中间用空格隔开。一行,包含两个整数,依次为整数商和余数,中间用一个空格隔开。示例:输入:15 2,输出:7 1_带余除法怎么写编程
随便推点
数字化转型背景下的金融交易业务中台实践-程序员宅基地
文章浏览阅读140次。引言:目前金融业IT系统大多由业务部门或渠道进行竖井式建设,这种模式的好处是系统专业性强,但同时也给运营及IT管理部门带来分散性阵痛。那么如何在强监管与统一风控的形势下,实现统一管控、快速响应、应需而变、按期交付?中台架构就是在这种背景下应运而生。本文主要以某城商行基于BIIP实施的交易中台的实践案例展开分享,一起和大家探讨企业数字化转型中的背景、技术..._运营转型 业务中台
AWG标准_awg官方规范-程序员宅基地
文章浏览阅读1.5k次。AWG 直径 面积 铜阻抗 (inch) (mm) (kcmil) (mm²) (Ω/km) (Ω/kFT) 0000 (4/0) 0.46 11.684 212 107 0.1608 0.04901 000 (3/0) 0.4096 10.404 168 85 0.202..._awg官方规范
图像修复论文Residual Non-local Attention Networks for Image Restoration阅读笔记-程序员宅基地
文章浏览阅读2.8k次。论文来源:ICLR2019论文链接:pdf (openreview.net)_residual non-local attention networks for image restoration
表达式计算。问题描述:编写程序,计算并输出如下表达式的值:y=其中a,x,y均为float类型,取值为3.1415926。输出结果要求保留小数点后3位。_serialprintln(a)的结果为-程序员宅基地
文章浏览阅读153次。【代码】表达式计算。问题描述:编写程序,计算并输出如下表达式的值:y=其中a,x,y均为float类型,取值为3.1415926。输出结果要求保留小数点后3位。_serialprintln(a)的结果为
android 自定义Toast 吐司-程序员宅基地
文章浏览阅读274次,点赞3次,收藏8次。【Android 详细知识点思维脑图(技能树)】其实Android开发的知识点就那么多,面试问来问去还是那么点东西。所以面试没有其他的诀窍,只看你对这些知识点准备的充分程度。so,出去面试时先看看自己复习到了哪个阶段就好。虽然 Android 没有前几年火热了,已经过去了会四大组件就能找到高薪职位的时代了。这只能说明 Android 中级以下的岗位饱和了,现在高级工程师还是比较缺少的,很多高级职位给的薪资真的特别高(钱多也不一定能找到合适的),所以努力让自己成为高级工程师才是最重要的。
FP-Growth算法之FP-tree的构造(python)_利用fpgrowth算法对其构造一个fptree,树的最大高度-程序员宅基地
文章浏览阅读7.4k次。前言:关于 FP-Growth 算法介绍请见:FP-Growth算法的介绍。 本文主要介绍 FP-tree 的构造算法,关于伪代码请查看上面的文章。上接:FP-Growth算法python实现;下接:FP-Growth算法之频繁项集的挖掘(python)。 正文:tree_builder.py\color{aqua}{tree\_builder.py}文件:#coding=utf-8import_利用fpgrowth算法对其构造一个fptree,树的最大高度