当分割一切遇见图像修复!Inpaint Anything来了!单击实现物体移除、内容填补、场景替换...-程序员宅基地
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:机器之心
这次,强大的「分割一切」模型——Segment Anything Model,在图像修补任务上碰撞出了火花。
4 月初,Meta 发布了史上首个图像分割基础模型--SAM(Segment Anything Model)[1]。作为分割模型,SAM 的能力强大,操作使用方式也十分友好,比如用户简单地点击来选择对应物体,物体就会立即被分割出来,且分割结果十分精准。截至 4 月 15 号,SAM 的 GitHub 仓库的 Star 数高达 26k。

如何利用好如此强大的「分割一切」模型,并拓展到更加有实际需求的应用场景至关重要。例如,当 SAM 遇上实用的图像修补(Image Inpainting)任务会碰撞出什么样的火花?
来自中国科学技术大学和东方理工高等研究院的研究团队给出了令人惊艳的答案。基于 SAM,他们提出「修补一切」(Inpaint Anything,简称 IA)模型。区别于传统图像修补模型,IA 模型无需精细化操作生成掩码,支持了一键点击标记选定对象,IA 即可实现移除一切物体(Remove Anything)、填补一切内容(Fill Anything)、替换一切场景(Replace Anything),涵盖了包括目标移除、目标填充、背景替换等在内的多种典型图像修补应用场景。

论文链接:http://arxiv.org/abs/2304.06790
代码库链接:https://github.com/geekyutao/Inpaint-Anything
方法介绍
尽管当前图像修补系统取得了重大进展,但它们在选择掩码图和填补空洞方面仍然面临困难。基于 SAM,研究者首次尝试无需掩码(Mask-Free)图像修复,并构建了「点击再填充」(Clicking and Filling) 的图像修补新范式,他们将其称为修补一切 (Inpaint Anything)(IA)。IA 背后的核心思想是结合不同模型的优势,以建立一个功能强大且用户友好的图像修复系统。
IA 拥有三个主要功能:(i) 移除一切(Remove Anything):用户只需点击一下想要移除的物体,IA 将无痕地移除该物体,实现高效「魔法消除」;(ii) 填补一切(Fill Anything):同时,用户还可以进一步通过文本提示(Text Prompt)告诉 IA 想要在物体内填充什么,IA 随即通过驱动已嵌入的 AIGC(AI-Generated Content)模型(如 Stable Diffusion [2])生成相应的内容填充物体,实现随心「内容创作」;(iii) 替换一切(Replace Anything):用户也可以通过点击选择需要保留的物体对象,并用文本提示告诉 IA 想要把物体的背景替换成什么,即可将物体背景替换为指定内容,实现生动「环境转换」。IA 的整体框架如下图所示:
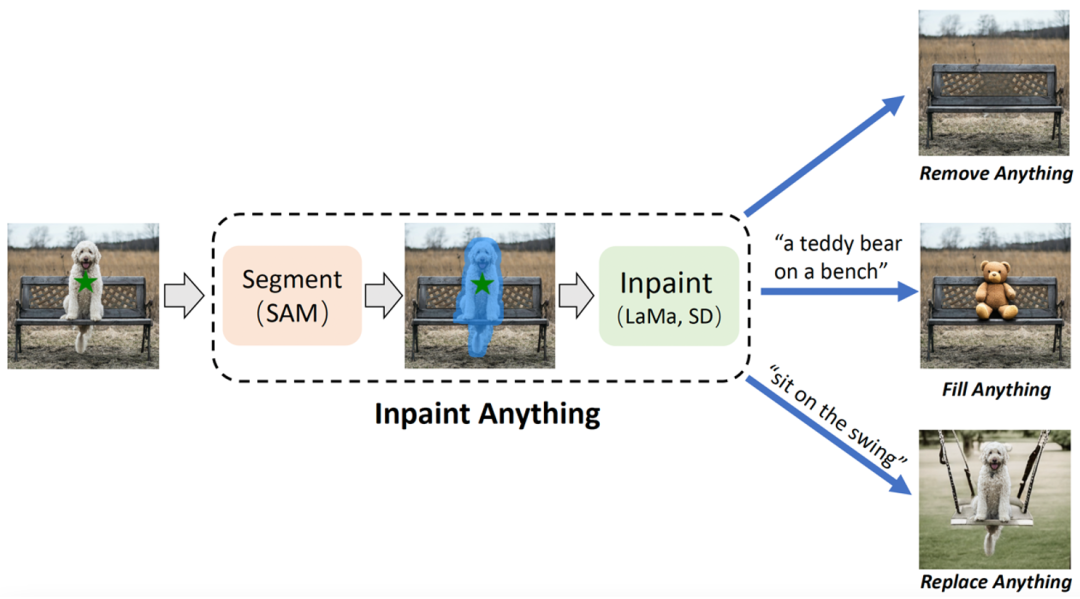
Inpaint Anything(IA)示意图。用户可以通过单击来选择图像中的任何物体。借助强大的视觉模型,如 SAM [1]、LaMa [3] 和 Stable Diffusion (SD) [3],IA 能够平滑移除选定物体(即 Remove Anything)。进一步地,通过向 IA 输入文本提示,用户可以用任何想要的内容填充物体(即 Fill Anything)或者任意替换对象的物体(即 Replace Anything)。
移除一切

移除一切(Remove Anything)示意图
「移除一切」步骤如下:
第 1 步:用户点击想要移除的物体;
第 2 步:SAM 将该物体分割出来;
第 3 步:图像修补模型(LaMa)填补该物体。
填补一切

填补一切(Fill Anything)示意图,图中使用的文本提示:a teddy bear on a bench
「填补一切」步骤如下:
第 1 步:用户点击想要移除的物体;
第 2 步:SAM 将该物体分割出来;
第 3 步:用户通过文本示意想要填充的内容;
第 4 步:基于文本提示的图像修补模型(Stable Diffusion)根据用户提供的文本对物体进行填充。
替换一切

替换一切(Replace Anything)示意图,图中使用的文本提示:a man in office
「填补一切」步骤如下:
第 1 步:用户点击想要移除的物体;
第 2 步:SAM 将该物体分割出来;
第 3 步:用户通过文本示意想要替换的背景;
第 4 步:基于文本提示的图像修补模型(Stable Diffusion)根据用户提供的文本对物体的背景进行替换。
模型结果
研究者随后在 COCO 数据集 [4]、LaMa 测试数据集 [3] 和他们自己用手机拍摄的 2K 高清图像上对 Inpaint Anything 进行测试。值得注意的是,研究者的模型还支持 2K 高清图和任意长宽比,这使得 IA 系统在各种集成环境和现有框架中都能够实现高效的迁移应用。
移除一切实验结果





填充一切实验结果

文本提示:a camera lens in the hand

文本提示:an aircraft carrier on the sea

文本提示:a sports car on a road

文本提示:a Picasso painting on the wall
替换一切实验结果

文本提示:sit on the swing

文本提示:breakfast

文本提示:a bus, on the center of a country road, summer

文本提示:crossroad in the city
总结
研究者建立这样一个有趣的项目,来展示充分利用现有大型人工智能模型所能获得的强大能力,并揭示「可组合人工智能」(Composable AI)的无限潜力。项目所提出的 Inpaint Anything (IA) 是一种多功能的图像修补系统,融合了物体移除、内容填补、场景替换等功能(更多的功能正在路上敬请期待)。
IA 结合了 SAM、图像修补模型(例如 LaMa)和 AIGC 模型(例如 Stable Diffusion)等视觉基础模型,实现了对用户操作友好的无掩码化图像修复,同时支持「点击删除,提示填充」的等「傻瓜式」人性化操作。此外,IA 还可以处理具有任意长宽比和 2K 高清分辨率的图像,且不受图像原始内容限制。
目前,项目已经完全开源。最后,欢迎大家分享和推广 Inpaint Anything (IA) ,也很期待看见更多基于 IA 所拓展的新项目。未来,研究者将进一步挖掘 Inpaint Anything (IA) 的潜力 以支持更多实用的新功能,如细粒度图像抠图、编辑等,并将其应用到更多现实应用中。
参考文献
[1] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao,Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023.
[2] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition, pages 10684–10695, 2022.
[3] Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2149–2159, 2022.
[4] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference,
Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
图像分割交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-图像分割 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()
智能推荐
一个ngrok如何穿透多个端口?_ngrok多个端口-程序员宅基地
文章浏览阅读2.7k次,点赞2次,收藏4次。如何不充钱就可以穿透多个端口?./ngrok authtoken 授权码之前这个操作的生成的yml文件中修改 端口可添加多个addr:port端口可随意配置_ngrok多个端口
C语言 char转uint8_t-程序员宅基地
文章浏览阅读5.9k次。char转uint8_t:static int char2uint(char *input, uint8_t *output){ for(int i = 0; i < 24; i++) { output[i] &= 0x00; for (int j = 1; j >= 0; j--) { char hb = input[i*2 + 1 - j]; if (hb >= '0' &..._char转uint8_t
android 陀螺仪简单使用,判读手机是否静止状态_安卓陀螺仪多少才算静止-程序员宅基地
文章浏览阅读6.5k次,点赞5次,收藏13次。陀螺仪允许您在任何给定时刻确定Android设备的角速度。简单来说,它告诉您设备绕X,Y和Z轴旋转的速度有多快。最近,即使是预算手机正在制造,陀螺仪内置,增强现实和虚拟现实应用程序变得如此受欢迎。通过使用陀螺仪,您可以开发可以响应设备方向的微小更改的应用程序。创建陀螺仪对象和管理器manager// Register it, specifying the polling interv..._安卓陀螺仪多少才算静止
lib静态库逆向分析_libtersafe-程序员宅基地
文章浏览阅读4.7k次,点赞3次,收藏16次。当我们要分析一个lib库里的代码时,首先需要判断这是一个静态库还是一个导入库。库类型判断lib文件其实是一个压缩文件。我们可以直接使用7z打开lib文件,以查看里面的内容。如果里面的内容是obj文件,表明是静态库。如果里面的内容是dll文件,表明是导入库。导入库里面是不包含代码的,代码包含在对应的dll文件中。从lib中提取obj静态库是一个或者多个obj文件的打包,这里有两个方法从中提取obj:Microsoft 库管理器 7z解压Microsoft 库管理器(li_libtersafe
Linux的网络适配器_linux 查询网络适配器-程序员宅基地
文章浏览阅读5.3k次,点赞3次,收藏3次。了解一下,省的脑壳痛 桥接模式对应的虚拟网络名称“VMnet0” 桥接模式下,虚拟机通过主机的网卡进行通信,若物理主机有多块网卡(有线的和无线网卡),应选择桥结哪块物理网卡桥接模式下,虚拟机和物理主机同等地位,可以通过物理主机的网卡访问外网(局域网),一个局域网的其他计算机可以访问虚拟机。为虚拟机设置一个与物理网卡在同个网段的IP,则虚拟机就可以与物理主机以及局域..._linux 查询网络适配器
【1+X Web前端等级考证 】 | Web前端开发中级理论 (附答案)_1+xweb前端开发中级-程序员宅基地
文章浏览阅读3.4w次,点赞77次,收藏438次。# 前言2020 12月 1+X Web 前端开发中级 模拟题大致就更这么多,我的重心不在这里,就不花太多时间在这里面了。但是,说说1+X Web前端开发等级考证这个证书,总有人跑到网上问:这个证书有没有用? 这个证书含金量高不高?# 关于考不考因为这个是工信部从2019年才开始实施试点的,目前还在各大院校试点中,就目前情况来看,知名度并不是很高,有没有用现在无法一锤定音,看它以后办的怎么样把,软考以前也是慢慢地才知名起来。能考就考吧,据所知,大部分学校报考,基本不用交什么报考费(小部分学校,个别除._1+xweb前端开发中级
随便推点
项目组织战略管理及组织结构_项目组织的具体形态的是战略管理层-程序员宅基地
文章浏览阅读1.7k次。组织战略是组织实施各级项目管理,包括项目组合管理、项目集管理和项目管理的基础。只有从组织战略的高度来思考,思考各个层次项目管理在组织中的位置,才能够理解各级项目管理在组织战略实施中的作用。同时战略管理也为项目管理提供了具体的目标和依据,各级项目管理都需要与组织的战略保持一致。..._项目组织的具体形态的是战略管理层
图像质量评价及色彩处理_图像颜色质量评价-程序员宅基地
文章浏览阅读1k次。目录基本统计量色彩空间变换亮度变换函数白平衡图像过曝的评价指标多视影像因曝光条件不一而导致色彩差异,人眼可以快速区分影像质量,如何利用图像信息辅助算法判断影像优劣。基本统计量灰度均值方差梯度均值方差梯度幅值直方图图像熵p·log(p)色彩空间变换RGB转单通道灰度图像 mean = 225.7 stddev = 47.5mean = 158.5 stddev = 33.2转灰度梯度域gradMean = -0.0008297 / -0.000157461gr_图像颜色质量评价
MATLAB运用规则,利用辛普森规则进行数值积分-程序员宅基地
文章浏览阅读1.4k次。Simpson's rule for numerical integrationZ = SIMPS(Y) computes an approximation of the integral of Y via the Simpson's method (with unit spacing). To compute the integral for spacing different from one..._matlab利用幸普生计算积分
【AI之路】使用huggingface_hub优雅解决huggingface大模型下载问题-程序员宅基地
文章浏览阅读1.2w次,点赞28次,收藏61次。Hugging face 资源很不错,可是国内下载速度很慢,动则GB的大模型,下载很容易超时,经常下载不成功。很是影响玩AI的信心。经过多次测试,终于搞定了下载,即使超时也可以继续下载。真正实现下载无忧!究竟如何实现?且看本文分解。_huggingface_hub
mysql数据库查看编码,mysql数据库修改编码_查看数据库编码-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏7次。其中 `DEFAULT CHARSET` 和 `COLLATE` 分别指定了表的默认编码和排序规则。其中 `DEFAULT CHARACTER SET` 指定了数据库的默认编码。其中 `Collation` 列指定了字段的排序规则,这也是字段的默认编码。此命令将更改表的默认编码和排序规则。此命令将更改字段的编码和排序规则。此命令将更改数据库的默认编码。_查看数据库编码
机器学习(十八):Bagging和随机森林_bagging数据集-程序员宅基地
文章浏览阅读1.3k次,点赞7次,收藏24次。本文深入探讨了集成学习及其在随机森林中的应用。对集成学习的基本概念、优势以及为何它有效做了阐述。随机森林,作为一个集成学习方法,与Bagging有紧密联系,其核心思想和实现过程均在文中进行了说明。还详细展示了如何在Sklearn中利用随机森林进行建模,并对其关键参数进行了解读,希望能帮助大家更有效地运用随机森林进行数据建模。_bagging数据集