【精选】基于生成式对抗网络深度学习的单幅图像去雨系统-程序员宅基地
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着计算机视觉技术的迅猛发展,户外视觉系统开始广泛应用于军事、交通及安全监控等领域[1]。但是,这些户外计算机系统容易受到恶劣天气的干扰,主要表现为在各类恶劣天气下户外系统采集到的图像容易背景模糊,丢失一些重要的细节,继而显著降低计算机户外视觉系统的性能,包括自动驾驶、物体检测和视频监控。雨作为现实生活中非常普遍的天气,不仅影响人类的视觉,而且还会严重影响户外视觉系统的准确性。特别是在大雨中,来自各个方向的雨水累积,使背景图像模糊,重要的细节信息被雨痕遮挡,这种影响显著制约了依赖于特征提取、视觉建模的户外计算机系统的功能。因此,去除图像中的雨水并从雨图像中恢复背景具有极高的实用价值与研究意义。
早期,大多数研究工作主要集中在利用视频上多个连续帧中的时间相关性去除视频中的雨痕,试图通过利用连续帧之间的亮度域中的时间相关性来解决问题。然而,去除单幅图像中的雨痕具有更大的实用性。当只有单个图像可用时,例如从数码相机或照相手机拍摄的图像或从因特网上下载的图像﹐需要使用基于单幅图像的雨痕去除方法时,由于缺乏时间域信息,先前的视频去雨方法无法去除单幅图像中的雨痕。因此,基于单幅图像去雨方法的研究具有更大的挑战性与实用性。
通常,基于单幅图像去除雨水方法可以分为两类:模型驱动和数据驱动。模型驱动的方法通过使用手工图像特征来描述雨痕的物理特征或者探索先验知识来约束图像去雨的问题。然而这些方法固定了雨痕的先验假设,只能去除特定形状、尺度和密度的雨痕。近年来,得益于深度神经网络理论的发展与计算性能的提高,数据驱动的方法已经广泛应用于图像去雨任务中。这些方法主要使用合成数据集以监督的方式进行训练。存在的这些使用监督方式的深度神经网络产生的限制主要总结为如下两个方面:
(1)由于合成数据集与现实场景下的雨图像之间的雨痕分布存在一定的间隙,人工合成雨痕通常与实际的雨痕形状不同,这会导致使用监督方式的图像去雨方法具有有限的能力来从现实的雨天图像中检测并去除雨痕。
(2)雨的模式和风格是多种多样的,这使得仅用一个全监督的网络模型难以对待所有场景。例如,在合成大雨中训练的模型不能直接应用于小雨的场景。
(3)这些方法通常使用卷积神经网络作为封装的端到端映射模块,没有深入神经网络设计的合理性,难以实现更有效的去除雨痕。
2.图片演示



3.视频演示
基于生成式对抗网络深度学习的单幅图像去雨系统_哔哩哔哩_bilibili
4.雨图像的物理模型
雨是一种自然的天气现象,当雨滴下落的速度较快时,拍摄的图像中一般会呈现出雨痕的形状。在图像去雨方法研究中,通常使用到的物理模型为将雨图像视为背景图像和雨痕图像的线性叠加,公式如下所示:
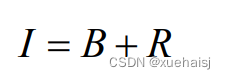
其中Ⅰ表示受雨水影响的雨图像,B和R分别代表雨图像中的雨痕和背景。由公式(2.1)可以看出,图像去雨任务可以被看做从雨图像中分离出两个分量的问题。
现有的图像去雨合成数据集
图像去雨的工作是一项重要的图像处理任务,主要目标是将受雨水影响退化的图像复原成高质量的干净背景图像。通过雨图像的物理模型可以把这项工作看作是信号分离的问题。由于低级图像处理任务中的输入图像都没有相对应的标签背景图像。因此研究人员想利用深度学习来解决这项工作,需要手工制作大量的数据集。这些数据集通常是先选取一堆干净无雨的背景图像,然后在这些背景图像上通过使用图像处理软件添加各种方向、密度的雨痕得到与背景图像相对应的雨图像。比较常见的图像去雨合成数据集如下所示:
(1)DDN-Data[17],由于很难从现实生活中获取大量的干净背景/雨图像对,研究人员使用Photoshop[1]合成了雨图像。首先从UCID数据集[2]、BSD数据集[33]和Google图像搜索中手机了1000张干净的背景图像以合成雨图像。然后在每个干净的背景图像上生成14张不同雨痕方向和大小的雨图像。因此该数据集一共包含14000对干净背景/雨图像,其中12600对干净背景/雨图像作为训练集,另外1400对干净背景/雨图像作为测试集。该数据集相对其他合成的雨图像数据集较大,具有各种方向的雨痕。该数据集的样本图像展示如图所示。

(2) Rain100L[18],一共包含2000对干净背景/雨图像对,其中1800对干净背景/雨图像作为训练集,200对干净背景/雨图像作为测试集。该数据集仅包含一种类型的雨痕,雨痕相对较少。合成的方式主要包括两种要求,其一,使用Photoshop逼真渲染,其二,模拟的雨痕沿着变化不大的方向。该数据集的样本图像如图所示。

(3) Rain100H[18],和Rain100L数据同时公布出来,同样的一共包含2000对干净背景/雨图像对,其中1800对干净背景/雨图像作为训练集,200对干净背景/雨图像作为测试集。该数据集合成的每张雨图像具有5种不同的雨痕方向。相对于Rain100L数据集,该数据集具有一定的挑战性。该数据集的样本图像如图所示。

(4)DIDMDN-Data[19],该数据集考虑到了不同的雨图像具有不同的雨痕密度等级这一情况,将雨图像的密度等级标签加入到合成数据集中。该数据集一共有13200对干净背景/雨图像对,其中训练集包括12000对干净背景/雨图像对,测试集包括1200对干净背景/雨图像对。训练集中的雨图像包含3个雨痕密度标签,分别为大雨、中雨和小雨,并且每一个密度级别包含4000对干净背景/雨图像对。与之前的合成数据集合成方法类似,该数据集也是使用Photoshop,主要修改了合成方法[31]中第3步引入的噪声级别,以生成不同的雨密度图像,其中,中,小雨和大雨条件分别对应于5%35%,35%65%和65%~95%的噪声水平。该数据集的样本图像如图所示。

5.核心代码讲解
5.1 Base.py
下面是封装为类后的代码:
class RainRemovalModel(object):
def __init__(self, config):
self.config = config
self.gpuid = config.gpuid
self.mode = config.mode
self.pretrained_weights = config.pretrained_weights
self.criterionMSE = nn.MSELoss()
self.criterionL1 = nn.L1Loss()
self.criterionBCE = nn.BCELoss()
self.criterionGAN = GANLoss(use_lsgan=False).to(self.gpuid)
self.parallel = config.parallel
self.ckpt_dir = config.check_point_dir
self.model_name = 'HeavyRain-stage%s-%s' % (self.config.training_stage, str(datetime.date.today()))
self.best_valid_acc = 0
self.logs_dir = '.
该程序文件名为Base.py,是一个基础类文件。该类包含了一些通用的方法和属性,用于支持其他类的实现。
该文件的主要内容如下:
- 导入了一些必要的库和模块,如torch、torchvision、numpy等。
- 定义了一个名为Base的类,该类继承自object类。
- 在类的构造函数中,初始化了一些基本参数和变量,如配置信息、GPU ID、模式、预训练权重、损失函数等。
- 定义了一些用于创建模型、初始化权重、重置参数等方法。
- 定义了一些用于加载数据、保存模型、加载模型、验证模型、测试模型等方法。
- 定义了一些用于处理图像、计算准确率等辅助方法。
总体来说,该文件是一个基础类文件,提供了一些通用的方法和属性,用于支持其他类的实现。
5.2 fit.py
class MultiScaleRecurrentModule(nn.Module):
def __init__(self):
super(MultiScaleRecurrentModule, self).__init__()
# 雨滴去除分支
self.rain_removal_branch = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
# 背景恢复分支
self.background_recovery_branch = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(64, 3, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
def forward(self, x):
x = self.rain_removal_branch(x)
x = self.background_recovery_branch(x)
return x
class RainRemovalNetwork(nn.Module):
def __init__(self):
super(RainRemovalNetwork, self).__init__()
self.multi_scale_recurrent = MultiScaleRecurrentModule()
def forward(self, x):
x = self.multi_scale_recurrent(x)
return x
这个程序文件名为fit.py,它定义了一个雨滴去除网络的模型。该模型包含了三个子模块:MultiScaleRecurrentModule、PhysicalSimilarityDivergenceModule和ConvolutionalCrossAttentionModule。每个子模块都有自己的前向传播函数。
MultiScaleRecurrentModule是一个多尺度循环模块,它包含了两个分支:雨滴去除分支和背景恢复分支。雨滴去除分支通过两个卷积层对输入进行处理,然后通过ReLU激活函数进行非线性变换。背景恢复分支也是通过两个卷积层对输入进行处理,然后通过ReLU激活函数进行非线性变换。
PhysicalSimilarityDivergenceModule是一个物理相似度分歧模块,它包含了两个分支:相似度分支和分歧分支。相似度分支通过两个卷积层对输入进行处理,然后通过ReLU激活函数进行非线性变换。分歧分支也是通过两个卷积层对输入进行处理,然后通过ReLU激活函数进行非线性变换。
ConvolutionalCrossAttentionModule是一个卷积交叉注意力模块,它包含了一个卷积分支和一个多头注意力分支。卷积分支通过一个卷积层对输入进行处理。多头注意力分支使用卷积分支的输出作为查询、键和值,然后通过多头注意力机制对输入进行加权。
RainRemovalNetwork是一个雨滴去除网络,它包含了上述三个子模块。在前向传播过程中,输入先经过MultiScaleRecurrentModule进行处理,然后经过PhysicalSimilarityDivergenceModule进行处理,最后经过ConvolutionalCrossAttentionModule进行处理。最终的输出就是去除了雨滴的图像。
5.3 helper.py
class RainHazeImageDataset(Dataset):
def __init__(self, root_dir, mode, aug=False, transform=None):
self.root_dir = root_dir
self.mode = mode
self.aug = aug
self.transform = transform
self.path = os.path.join(self.root_dir, (mode + '_s_rain.txt'))
self.in
这个程序文件是一个辅助文件,包含了两个数据集类RainHazeImageDataset和FogImageDataset,以及一些辅助函数。
RainHazeImageDataset类是一个数据集类,用于加载雨滴和雾霾图像数据集。在初始化时,它会读取整个数据集的图像路径,并提供了一些方法来获取图像
5.4 model.py
class DecompModel(nn.Module):
def __init__(self):
super(DecompModel, self).__init__()
self.rainnet = RainNet(33, 1)
self.fognet = FogNet(33)
self.radiux = [2, 4, 8, 16, 32]
self.eps_list = [0.001, 0.0001]
self.ref = RefUNet(3, 3)
self.eps = 0.001
self.gf = None
self.relu = nn.ReLU()
self.tanh = nn.Tanh()
def forward(self, x):
lf, hf = self.decomposition(x)
trans, atm, A = self.fognet(torch.cat([x, lf], dim=1))
streak = self.rainnet(torch.cat([x, hf], dim=1))
streak = streak.repeat(1, 3, 1, 1)
dehaze = (x - (1 - trans) * atm) / (trans + self.eps) - streak
clean = self.relu(self.ref(dehaze, A))
return streak, trans, atm, clean # trans, atm, clean
def forward_test(self, x, A, mode='A'):
if mode=='run':
lf, hf = self.decomposition(x)
trans, atm, _ = self.fognet(torch.cat([x, lf], dim=1))
streak = self.rainnet(torch.cat([x, hf], dim=1))
streak = streak.repeat(1, 3, 1, 1)
#dehaze = (x - 0.7*streak - (1 - trans) * atm) / (trans + self.eps)
dehaze = (x - (1 - trans) * atm) / (trans + self.eps) - streak
clean = self.relu(self.ref(dehaze, A))
return streak, trans, atm, clean # trans, atm, clean
else:
Amean = self.predict_atm(x)
return Amean
def predict_atm(self, x):
_, c, h, w = x.size()
lf, hf = self.decomposition(x)
sum_A = torch.zeros(1,3,1,1, dtype=torch.float32).cuda()
count = 0
ph = 256
pw = 256
rows = int(np.ceil(float(h)/float(ph)))
cols = int(np.ceil(float(w)/float(pw)))
for i in range(rows):
for j in range(cols):
ratey = 1
ratex = 1
if (i+1)*256 > h:
dy = h - 256
ratey = h - i*256
else:
dy = i * 256
if (j+1) * 256 > w:
dx = w - 256
ratex = w - j*256
else:
dx = j * 256
_, _, A = self.fognet(torch.cat([x, lf], dim=1), dx, dy)
sum_A = sum_A + A * ratey * ratex
count+=1 * ratey * ratex
return sum_A/count
def decomposition(self, x):
LF_list = []
HF_list = []
res = get_residue(x)
res = res.repeat(1, 3, 1, 1)
for radius in self.radiux:
for eps in self.eps_list:
self.gf = GuidedFilter(radius, eps)
LF = self.gf(res, x)
LF_list.append(LF)
HF_list.append(x - LF)
LF = torch.cat(LF_list, dim=1)
HF = torch.cat(HF_list, dim=1)
return LF, HF
class FogNet(nn.Module):
def __init__(self, input_nc):
super(FogNet, self).__init__()
self.atmconv1x1 = nn.Conv2d(input_nc, input_nc, kernel_size=1, stride=1, padding=0)
self.atmnet = define_D(input_nc, 64, 'n_estimator', n_layers_D=5, norm='batch', use_sigmoid=True, gpu_ids=[])
self.transnet = TransUNet(input_nc, 1)
self.htanh = nn.Hardtanh(0, 1)
self.relu1 = ReLU1()
self.relu = nn.ReLU()
def forward(self, x, dx=0, dy=0):
_, c, h, w = x.size()
A = self.relu(self.atmnet(self.atmconv1x1(x[:, :, dy:dy+256, dx:dx+256])))
trans = self.relu(self.transnet(x))
atm = A.repeat(1, 1, h, w)
trans = trans.repeat(1, 3, 1, 1)
return trans, atm, A
class TransUNet(nn.Module):
def __init__(self, in_channel, n_classes):
super(TransUNet, self).__init__()
self.conv1x1 = nn.Conv2d(in_channel, in_channel, kernel_size=1, stride=1, padding=0)
self.inc = inconv(in_channel, 64)
self.image_size = 256
self.down1 = down(64, 128) # 112x112 | 256x256 | 512x512
self.down2 = down(128, 256) # 56x56 | 128x128 | 256x256
self.down3 = down(256, 512) # 28x28 | 64x64 | 128x128
self.down4 = down(512, 512) # 14x14 | 32x32 | 64x64
self.up1 = up(1024, 256)
self.up2 = up(512, 128)
self.up3 = up(256, 64)
self.up4 = up(128, 64)
self.outc = outconv(64, n_classes)
self.relu = nn.ReLU()
self.tanh = nn.Tanh()
def forward(self, x):
x = self.conv1x1(x)
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
# decoder
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
x = self.relu(self.outc(x))
return x
class GlobalLocalUnet(nn.Module):
def __init__(self, in_channel, n_classes):
super(GlobalLocalUnet, self).__init__()
self.inc = inconv(in_channel, 64)
self.image_size = 256
self.down1 = down(64, 128) # 112x112 | 256x256 | 512x512
self.down2 = down(128, 256) # 56x56 | 128x128 | 256x256
self.down3 = down(256, 512) # 28x28 | 64x64 | 128x128
self.down4 = down(512, 512) # 14x14 | 32x32 | 64x64
self.down5 = down(512, 512) # 32x32
self.up1 = up(1024, 512)
self.up2 =
该程序文件是一个神经网络模型的定义文件。该模型主要包括以下几个部分:
-
DecompModel:该类是整个模型的主体,包含了雨滴去除网络(RainNet)、雾霾去除网络(FogNet)、参考图像生成网络(RefUNet)等子网络。该类的forward方法定义了整个模型的前向传播过程。
-
FogNet:该类是雾霾去除网络,包含了大气光估计网络(atmnet)和透射率估计网络(transnet)。该类的forward方法定义了雾霾去除网络的前向传播过程。
-
TransUNet:该类是透射率估计网络,是一个U-Net结构的网络。该类的forward方法定义了透射率估计网络的前向传播过程。
-
GlobalLocalUnet:该类是参考图像生成网络,是一个U-Net结构的网络。该类的forward方法定义了参考图像生成网络的前向传播过程。
除了以上几个类,还有一些辅助函数和辅助网络的定义。整个模型的主要功能是对输入图像进行雨滴去除、雾霾去除和参考图像生成等处理,输出去雨图像、透射率、大气光和去雾图像等结果。
5.5 networks.py
class GANLoss(nn.Module):
def __init__(self, use_lsgan=True, target_real_label=1.0, target_fake_label=0.0):
super(GANLoss, self).__init__()
self.register_buffer('real_label', torch.tensor(target_real_label))
self.register_buffer('fake_label', torch.tensor(target_fake_label))
if use_lsgan:
self.loss = nn.MSELoss()
else:
self.loss = nn.BCELoss()
def get_target_tensor(self, input, target_is_real):
if target_is_real:
target_tensor = self.real_label
else:
target_tensor = self.fake_label
return target_tensor.expand_as(input)
def __call__(self, input, target_is_real):
target_tensor = self.get_target_tensor(input, target_is_real)
return self.loss(input, target_tensor)
class ResnetGenerator(nn.Module):
def __init__(self, input_nc, output_nc, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False, n_blocks=6, padding_type='reflect'):
assert(n_blocks >= 0)
super(ResnetGenerator, self).__init__()
self.input_nc = input_nc
self.output_nc = output_nc
self.ngf = ngf
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
model = [nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0,
bias=use_bias),
norm_layer(ngf),
nn.ReLU(True)]
n_downsampling = 2
for i in range(n_downsampling):
mult = 2**i
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3,
stride=2, padding=1, bias=use_bias),
norm_layer(ngf * mult * 2),
nn.ReLU(True)]
mult = 2**n_downsampling
for i in range(n_blocks):
model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout, use_bias=use_bias)]
for i in range(n_downsampling):
mult = 2**(n_downsampling - i)
model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2),
kernel_size=3, stride=2,
padding=1, output_padding=1,
bias=use_bias),
norm_layer(int(ngf * mult / 2)),
nn.ReLU(True)]
model += [nn.ReflectionPad2d(3)]
model += [nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
model += [nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, input):
return self.model(input)
class ResnetBlock(nn.Module):
def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias):
super(ResnetBlock, self).__init__()
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, use_dropout, use_bias)
def build_conv_block(self, dim, padding_type, norm_layer, use_dropout, use_bias):
conv_block = []
p = 0
if padding_type == 'reflect':
conv_block += [nn.ReflectionPad2d(1)]
elif padding_type == 'replicate':
conv_block += [nn.ReplicationPad2d(1)]
elif padding_type == 'zero':
p = 1
else:
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias),
norm_layer(dim),
nn.ReLU(True)]
if use_dropout:
conv_block += [nn.Dropout(0.5)]
p = 0
if padding_type == 'reflect':
conv_block += [nn.ReflectionPad2d(1)]
elif padding_type == 'replicate':
conv_block += [nn.ReplicationPad2d(1)]
elif padding_type == 'zero':
p = 1
else:
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias),
norm_layer(dim)]
return nn.Sequential(*conv_block)
该程序文件定义了一些用于构建神经网络的辅助函数和类。其中包括:
get_norm_layer函数:根据给定的归一化类型返回相应的归一化层。get_scheduler函数:根据给定的优化器和参数返回相应的学习率调度器。init_weights函数:对网络的权重进行初始化。init_net函数:初始化网络并将其移动到GPU上(如果有)。define_G函数:定义生成器网络。define_D函数:定义判别器网络。GANLoss类:定义GAN损失函数。ResnetGenerator类:定义一个由Resnet块组成的生成器网络。ResnetBlock类:定义一个Resnet块。
这些函数和类可以用于构建和训练神经网络模型。
6.系统整体结构
整体功能和构架概括:
该程序是一个基于生成式对抗网络深度学习的单幅图像去雨系统。它包含了多个文件,每个文件负责不同的功能模块。主要的功能模块包括基础类、模型定义、辅助函数、网络构建、训练和测试等。
下面是每个文件的功能整理:
| 文件名 | 功能 |
|---|---|
| Base.py | 提供通用的方法和属性,支持其他类的实现 |
| fit.py | 定义了一个雨滴去除网络的模型 |
| helper.py | 包含了数据集类和一些辅助函数 |
| model.py | 定义了整个模型的神经网络结构 |
| networks.py | 定义了构建神经网络的辅助函数和类 |
| train.py | 用于训练和测试模型的脚本 |
| ui.py | 用户界面的实现 |
| unet_parts.py | 定义了U-Net网络的部分组件 |
7.生成式对抗网络简介
生成式对抗网络
在这一部分,我们首先描述基于对抗网络的生成模型。生成式对抗网络(GAN)是强大的生成模型,在许多计算机视觉任务中(例如图像复原和图像到图像的转换)以及自然语言处理任务(例如语音合成和跨语言学习)获得了巨大的成功。生成式对抗网络(GAN)的模型架构在文献中所示,将模型转换为两个相互竞争的网络之间的博弈:生成器网络在给定一些输入噪声情况下生成合成数据,鉴别器网络努力将生成器的输出与真实数据区分开。
GAN在图像生成领域取得成功最主要的原因是引入了对抗损失,对抗损失函数如下所示。
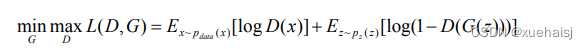
其中,x表示真实数据,z表示随机噪声数据,x ~ Paaa(x)表示从真实数据的分布中选择x,z~p:(z)表示从随机噪声中选择z,G(z)表示输入噪声经过生成器网络生成的图像,D()表示输入为真实的可能性。GAN是通过最小化数据生成分布Pan(x)与模型数据分布p:(z)之间的JS散度来训练的,通过最小化生成器网络G(z)和鉴别器网络D(x)之间的对抗损失来学习一个映射函数G:z→x 。生成器的学习通过使用源噪声信号z,最小化对抗损失生成与真实数据x难以区分的样本去建模数据分布p.a(x)。鉴别器的学习通过最大化对抗损失来区分真实数据x与生成的数据G(z)。
条件生成式对抗网络
与生成式对抗网络(GAN)学习从随机噪声向量到输出图像的映射不同,条件生成式对抗网网络(cGAN[52])学习在附加信息条件下从随机噪声向量到输出图像的映射。cGAN 能够进行图像到图像的转换,因为它可以以输入图像为条件并生成相应的输出图像。文献[53提出的pix2pix模型是使用cGAN的通用图像到图像转换算法,它可以针对各种问题产生合理的结果,给定一个包含成对的相关图像的训练集,pix2pix可以通过监督的方式学习将一种类型的图像转换为另一种类型的图像。同样在图像去雨领域中,Zhang 等人提出了一种基于cGAN的图像去雨算法。
条件生成式对抗网络(cGAN)的网络模型在文献[26]中所示。与原始生成式对抗网络不同的是,cGAN中的生成器与鉴别器的输入层都添加了附加信息y 。
条件生成式对抗网络通过最下化条件对抗损失来使生成器G学习x →y的映射函数,该条件对抗损失函数如下式所示。
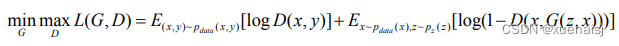
其中,(x,y)表示成对的输入图像与标签,(xr,y)~ Paaa(x,y)表示从成对的输入分布中选择(x, y)。cGAN通过附加条件信息y最小化生成器网络和鉴别器网络之间的条件对抗损失来学习一个映射函数G:x →y 。生成器的学习通过使用源噪声信号z和条件信息y映射到数据空间。鉴别器通过最大化对抗损失来判别真实的成对数据(x,y)与生成的成对数据(x,G(z,*))。往往在cGAN模型中还会添加一个绝对误差损失来约束生成的图像,该损失如下式所示。
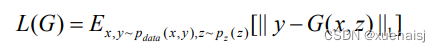
循环生成式对抗网络
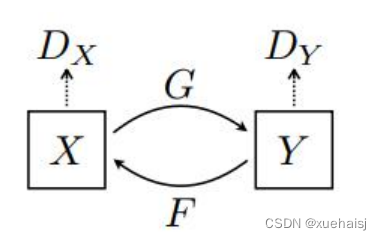
与基于条件生成式对抗网络(cGAN[52])的 pix2pix模型不同的是,循环生成式对抗网络(CycleGAN)旨在使用未成对的数据下学习图像到图像的转换。在CycleGAN中,一共由两个条件生成器相互学习两个域的映射。CycleGAN的模型架构如图3.1所示,一共由两个生成器和两个鉴别器,包含两个生成器的映射函数G:X→Y和F:Y→X和相关对抗的鉴别器Dy和Dx 。对于生成器G的映射函数G:X→¥和它的鉴别器Dy,他们的对抗损失函数如下所示。
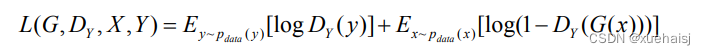
其中,生成器G试图生成相似于来自域Y的图像G(x),鉴别器D,旨在区分生成后的图像G(x)和真实样本y。训练网络时,生成器需最小化该目标函数,相反的鉴别器需要最大化此目标函数[53]。对于生成器F的映射函数F:Y→x,引入了一个相似的对抗损失。
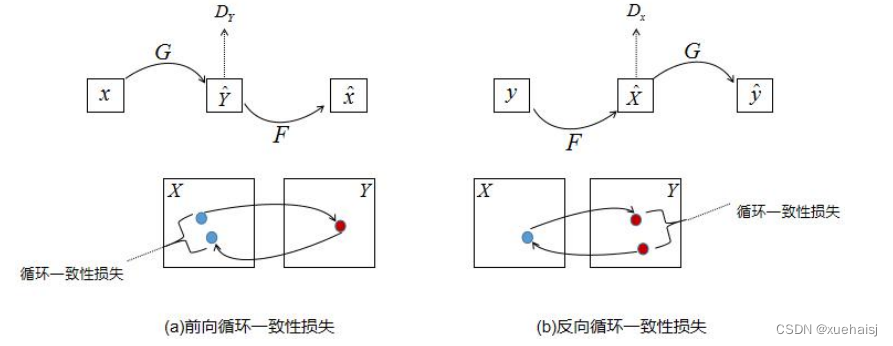
在条件生成式对抗网络中,条件对抗损失可以学习生成器G和生成器F的映射,但是当映射空间足够大时,网络可以将同一组输入图像映射到目标域的任何随机排列图像中,其中任何获悉的映射都可以产生与目标分布匹配的输出分布。因此,仅使用对抗损失不能保证学习的函数可以将单个输入映射到期望的输出。为了进一步减少可能的映射函数空间,如下图所示,CycleGAN认为学习的映射函数应该是循环一致的。对于来自域X的的每一张图像x(如图所示),前向循环一致应该把x转换到原始图像。
8.模型架构
为了在图像去雨任务中能够使用未成对的数据训练网络,本文提出了一个基于循环生成式对抗网络的新的框架。在图像去雨任务中,给定两个图像域分别为雨图像域Ⅰ和干净背景图像域B,如果只使用循环生成式对抗网络的方法,需要学习两个映射,分别为前向生成器G的映射G:I→B和反向生成器F的映射F:B →Ⅰ。由于循环一致性损失的存在,前向映射与反向映射是一对一的关系,即一张雨图像在前向生成器中可以映射成一张干净背景图像,一张干净背景图像在反向生成器中也只可以映射成一张雨图像,这与实际情况相违背。在图像去雨任务中,一张干净背景图像应该可以在反向生成器中生成多张不同的雨图像。因此图像去雨任务中的前向映射与反向映射是一对多的关系。基于以上考虑,本文添加了雨痕的学习过程,这样可以在反向映射时利用学习到的雨痕信息将干净的背景图像生成不同的雨图像。雨痕的学习主要是通过添加一个雨痕生成器完成。本文提出了基于分解的循环生成式对抗网络(DCycleGAN)的图像去雨方法,首先在前向映射中对输入的雨图像分解为前景和背景,继而可以利用前景图像得到雨痕掩码信息,能够对雨图像中的雨痕区域进行定位。然后将得到的雨痕掩码保存在队列数据结构中,由于队列结构具有先进先出的特点,在训练过程中随着迭代次数的增加,刚开始保存的学习的较差的雨痕掩码会被丢弃,随着时间的推移学习的较好的雨痕掩码会被保存在队列中。最后,在从干净背景图像到雨图像的学习过程中,我们将队列中的雨痕掩码与干净背景图像通过拼接操作结合来生成雨痕,这样通过随机的从队列中选取雨痕掩码就会生成不同的雨图像。本文从原理上解决了基于循环生成式对抗网络(CycleGAN)只能学习两个图像域的一对一映射,不能处理图像去雨任务的问题。提出的基于分解的循环生成式对抗网络(DCycleGAN)的图像去雨方法的模型架构如下图所示。
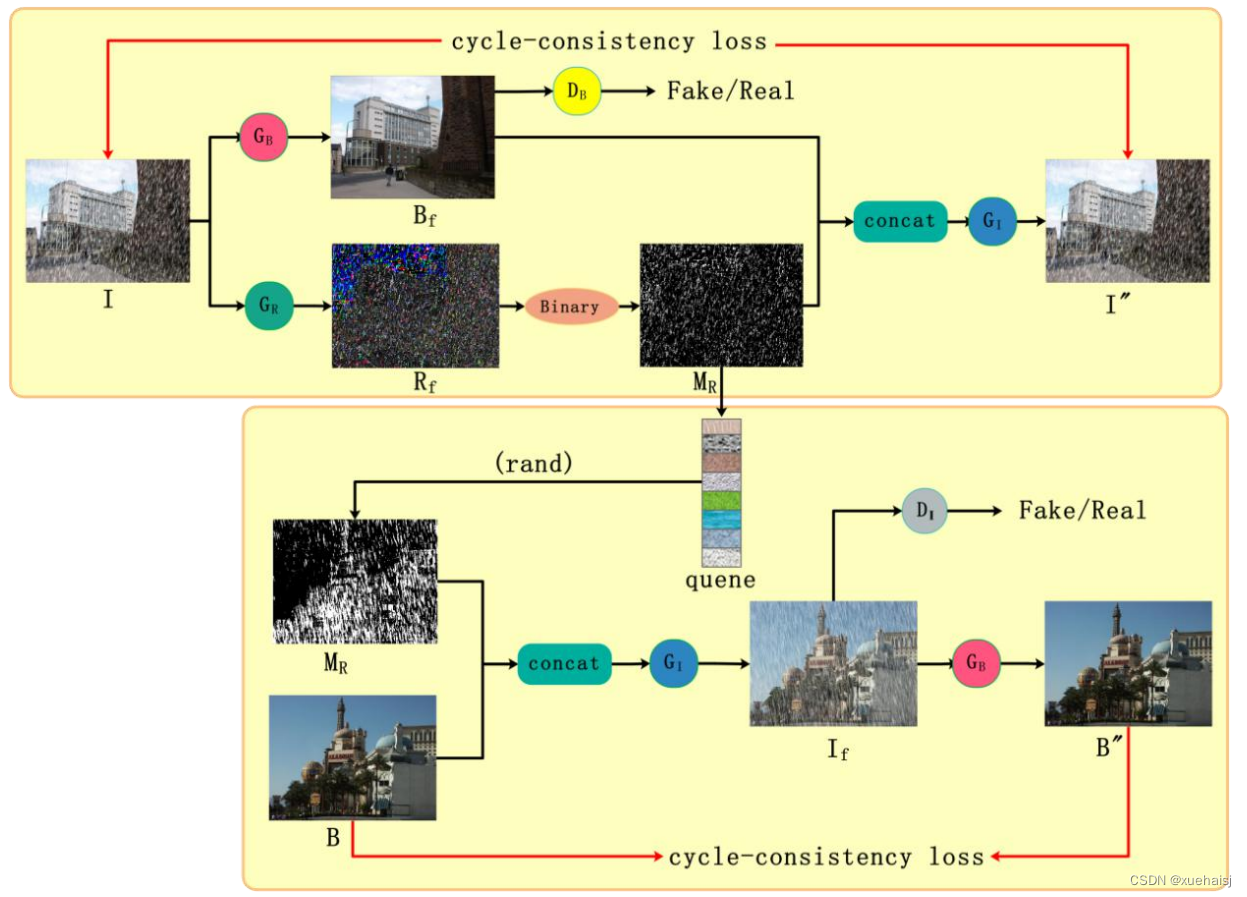
其中,Ⅰ和B分别表示输入的未成对的雨图像和干净背景图像,G表示生成器,它学习雨图像到干净背景图像的映射函数,B,表示生成器G。生成的图像,D。是确定生成的图像是否是真实的干净背景图像的鉴别器,G表示生成器,它学习雨图像到雨痕图像的映射函数,R,表示生成器G生成的图像,Binary表示使用自适应阈值操作[56],M ,表示生成的图像R,经过二值化得到的雨痕掩码,concat表示特征通道的拼接操作,G,表示生成器,它学习干净图像到雨图像的映射函数,quene表示队列数据结构,保存着雨痕掩码信息,rand表示从队列中随机取出的操作,D,是确定生成的无雨图像是否是真实的无雨图像的鉴别器,B和T分别表示经过各自的反向生成器生成的重建图像。
网络结构
我们设计的网络结构与原始的循环生成式对抗网络(CycleGAN)的模型结构类似,除了在生成器上作了一些修改,而鉴别器和CycleGAN中的鉴别器一样。如图所示,生成器G,和生成器G将雨图像作为输入,所以这两个生成器的输入层有3个输入通道,但是生成器G,采用无雨图像和雨痕掩码拼接的方式作为该生成器的输入,所以该生成器的输入层有4个通道。受ResNet的启发,所有的生成器都产生一个残差图像和输入图像相加得到生成的图像。最后,我们增加了填充(padding〉操作来确保我们的模型可以直接测试更多尺寸的图像。
我们设计的生成器网络结构如下图3.4所示,其中除了输入和输出层外,其他各种颜色块表示卷积操作。在生成器G和生成器G中,输入通道我们设置为3,在生成器G,中我们设置输入通道为4,除了输入通道数不一样外,这三个生成器的网络结构都一样。输入层紧接的橙色块的卷积层是提取特征层,其中的K7S1P3表示卷积核(kernel)大小为7,步长(stride)为1,填充(padding)为3,输出通道设置为64.接下来两个绿色块是下采样层,输出通道分别设置为128,256。接下来的蓝色模块是特征转换层,其中每两个蓝色块组成一个残差块,一共包含9个残差块,我们设置的输出通道为512。接下来的两个黄色块是上采样层,这里上采样的操作我们使用反卷积[58]实施,输出通道分别设置为256,128。接下来的橙色块的卷积的输出通道我们设置为3。其中所有的卷积层后我们都使用修正线性单元(ReLU[59]))激活函数与批量归一化操作。
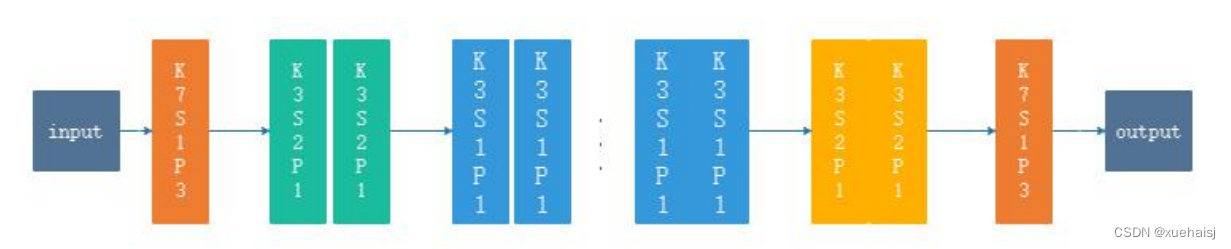
参数设置
由于计算显存的限制以及数据增广的需求﹐我们通过随机裁剪的操作将网络的输入图像尺寸限制为256*256。我们使用标准偏差为0.02,均值为0的高斯分布来初始化所有网络的参数,并且将小批量(mini-batch)设置为1。我们使用Adam[60]解法器来优化最终的损失函数,其中第一动量值设置为0.5,第二动量值设置为0.999,并且将初始化学习率设置为0.0002,学习率随着迭代次数的增加,线性递减至0。最后,我们使用Pytorch框架实现整个模型。
9.训练结果分析
评估指标
我们使用峰值信噪比(PSNR[61])和结构相似性(SSIM[62])两个指标来评估图像去雨算法在合成数据集上测试的性能。
其中峰值信噪比(PSNR)的数学公式如下所示,
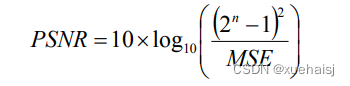
MSE指的是输入图像和真值图像之间的均方误差。
结构相似性(SSIM)的数学公式如下所示,
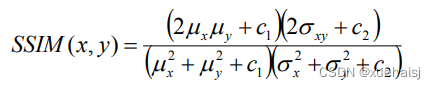
其中u、是x的平均值,u,是y的平均值,o,是x的方差,o,是y的方差,o.,是x和y的协方差。c, =(k,L),c, =(k,L)是用来维持稳定的常数,L是像素值的动态范围。k =0.01,k, =0.03。
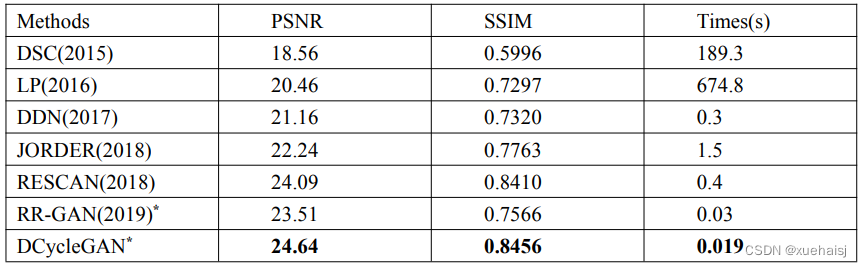
我们的方法与六个最新的图像去雨算法做出比较,包括基于判别式稀疏编码的DSC[11],基于块先验利用高斯混合模型求解的LP[13],基于残差网络(ResNet>利用残差信息的深度细节网络的DDN[16],考察了雨痕累积情况的联合雨痕检测与去除的JORDER[17],结合空洞卷积和挤压激发( Sequeeze-and-Excitation)模块多阶段去雨的RESCAN[51],最新的使用未成对数据训练的图像去雨方法RR-GAN[43]。其中方法DSC和方法LP属于传统方法的范畴,后面4种方法都是基于深度学习的方法,特别的方法RR-GAN也是使用未成对数据训练的模型。
结果比较
在RAIN800测试集上,我们提出的方法和其他图像去雨算法在定性和定量上都作出了比较。不同的图像去雨算法的定量结果位于表中,可以看出我们的提出的 DCycleGAN在 PSNR和SSIM两个指标上都获得了最佳结果,并且在执行速度上也优于其他的方法。
10.系统整合
下图[完整源码&数据集&环境部署视频教程&自定义UI界面]

智能推荐
React学习记录-程序员宅基地
文章浏览阅读936次,点赞22次,收藏26次。React核心基础
Linux查磁盘大小命令,linux系统查看磁盘空间的命令是什么-程序员宅基地
文章浏览阅读2k次。linux系统查看磁盘空间的命令是【df -hl】,该命令可以查看磁盘剩余空间大小。如果要查看每个根路径的分区大小,可以使用【df -h】命令。df命令以磁盘分区为单位查看文件系统。本文操作环境:red hat enterprise linux 6.1系统、thinkpad t480电脑。(学习视频分享:linux视频教程)Linux 查看磁盘空间可以使用 df 和 du 命令。df命令df 以磁..._df -hl
Office & delphi_range[char(96 + acolumn) + inttostr(65536)].end[xl-程序员宅基地
文章浏览阅读923次。uses ComObj;var ExcelApp: OleVariant;implementationprocedure TForm1.Button1Click(Sender: TObject);const // SheetType xlChart = -4109; xlWorksheet = -4167; // WBATemplate xlWBATWorksheet = -4167_range[char(96 + acolumn) + inttostr(65536)].end[xlup]
若依 quartz 定时任务中 service mapper无法注入解决办法_ruoyi-quartz无法引入ruoyi-admin的service-程序员宅基地
文章浏览阅读2.3k次。上图为任务代码,在任务具体执行的方法中使用,一定要写在方法内使用SpringContextUtil.getBean()方法实例化Spring service类下边是ruoyi-quartz模块中util/SpringContextUtil.java(已改写)import org.springframework.beans.BeansException;import org.springframework.context.ApplicationContext;import org.s..._ruoyi-quartz无法引入ruoyi-admin的service
CentOS7配置yum源-程序员宅基地
文章浏览阅读2w次,点赞10次,收藏77次。yum,全称“Yellow dog Updater, Modified”,是一个专门为了解决包的依赖关系而存在的软件包管理器。可以这么说,yum 是改进型的 RPM 软件管理器,它很好的解决了 RPM 所面临的软件包依赖问题。yum 在服务器端存有所有的 RPM 包,并将各个包之间的依赖关系记录在文件中,当管理员使用 yum 安装 RPM 包时,yum 会先从服务器端下载包的依赖性文件,通过分析此文件从服务器端一次性下载所有相关的 RPM 包并进行安装。_centos7配置yum源
智能科学毕设分享(算法) 基于深度学习的抽烟行为检测算法实现(源码分享)-程序员宅基地
文章浏览阅读828次,点赞21次,收藏8次。今天学长向大家分享一个毕业设计项目毕业设计 基于深度学习的抽烟行为检测算法实现(源码分享)毕业设计 深度学习的抽烟行为检测算法实现通过目前应用比较广泛的 Web 开发平台,将模型训练完成的算法模型部署,部署于 Web 平台。并且利用目前流行的前后端技术在该平台进行整合实现运营车辆驾驶员吸烟行为检测系统,方便用户使用。本系统是一种运营车辆驾驶员吸烟行为检测系统,为了降低误检率,对驾驶员视频中的吸烟烟雾和香烟目标分别进行检测,若同时检测到则判定该驾驶员存在吸烟行为。进行流程化处理,以满足用户的需要。
随便推点
STM32单片机示例:多个定时器同步触发启动_stm32 定时器同步-程序员宅基地
文章浏览阅读3.7k次,点赞3次,收藏14次。多个定时器同步触发启动是一种比较实用的功能,这里将对此做个示例说明。_stm32 定时器同步
android launcher分析和修改10,Android Launcher分析和修改9——Launcher启动APP流程(转载)...-程序员宅基地
文章浏览阅读348次。出处 : http://www.cnblogs.com/mythou/p/3187881.html本来想分析AppsCustomizePagedView类,不过今天突然接到一个临时任务。客户反馈说机器界面的图标很难点击启动程序,经常点击了没有反应,Boss说要优先解决这问题。没办法,只能看看是怎么回事。今天分析一下Launcher启动APP的过程。从用户点击到程序启动的流程,下面针对WorkSpa..._回调bubbletextview
Ubuntu 12 最快的两个源 个人感觉 163与cn99最快 ubuntu安装源下包过慢_un.12.cc-程序员宅基地
文章浏览阅读6.2k次。Ubuntu 12 最快的两个源 个人感觉 163与cn99最快 ubuntu下包过慢 1、首先备份Ubuntu 12.04源列表 sudo cp /etc/apt/sources.list /etc/apt/sources.list.backup (备份下当前的源列表,有备无患嘛) 2、修改更新源 sudo gedit /etc/apt/sources.list (打开Ubuntu 12_un.12.cc
vue动态路由(权限设置)_vue动态路由权限-程序员宅基地
文章浏览阅读5.8k次,点赞6次,收藏86次。1.思路(1)动态添加路由肯定用的是addRouter,在哪用?(2)vuex当中获取到菜单,怎样展示到界面2.不管其他先试一下addRouter找到router/index.js文件,内容如下,这是我自己先配置的登录路由现在先不管请求到的菜单是什么样,先写一个固定的菜单通过addRouter添加添加以前注意:addRoutes()添加的是数组在export defult router的上一行图中17行写下以下代码var addRoute=[ { path:"/", name:"_vue动态路由权限
JSTL 之变量赋值标签-程序员宅基地
文章浏览阅读8.9k次。 关键词: JSTL 之变量赋值标签 /* * Author Yachun Miao * Created 11-Dec-06 */关于JSP核心库的set标签赋值变量,有两种方式: 1.日期" />2. 有种需求要把ApplicationResources_zh_CN.prope
VGA带音频转HDMI转换芯片|VGA转HDMI 转换器方案|VGA转HDMI1.4转换器芯片介绍_vga转hdmi带音频转换器,转接头拆解-程序员宅基地
文章浏览阅读3.1k次,点赞3次,收藏2次。1.1ZY5621概述ZY5621是VGA音频到HDMI转换器芯片,它符合HDMI1.4 DV1.0规范。ZY5621也是一款先进的高速转换器,集成了MCU和VGA EDID芯片。它还包含VGA输入指示和仅音频到HDMI功能。进一步降低系统制造成本,简化系统板上的布线。ZY5621方案设计简单,且可以完美还原输入端口的信号,此方案设计广泛应用于投影仪、教育多媒体、视频会议、视频展台、工业级主板显示、手持便携设备、转换盒、转换线材等产品设计上面。1.2 ZY5621 特性内置MCU嵌入式VGA_vga转hdmi带音频转换器,转接头拆解