Jmeter压测工具使用手册(完整版)_jmeter做http文件上传压测-程序员宅基地
技术标签: 指引文章 jmeter并发压测指引
一、jemter简介
jmeter是apache公司基于java开发的一款开源压力测试工具,体积小,功能全,使用方便,是一个比较轻量级的测试工具,使用起来非常简 单。因为jmeter是java开发的,所以运行的时候必须先要安装jdk才可以。jmeter是免安装的,拿到安装包之后直接解压就可以使用,同时它在 linux/windows/macos上都可以使用。
jmeter可以做接口测试和压力测试。其中接口测试的简单操作包括做http脚本(发get/post请求、加cookie、加header、加权 限认证、上传文件)、做webservice脚本、参数化、断言、关联(正则表达式提取器和处理json-json path extractor)和jmeter操作数据库等等。
二、jmeter-4.0安装
(一)、首先检查机子上是否有安装jdk
检查方式,在cmd中输入java -version,出现如下信息,即已经安装好jdk
若未安装jdk,则看如下步骤
步骤一:
1、下载jdk,到官网下载jdk,地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
2、安装jdk,下载完成后,双击安装
步骤二:配置jdk环境变量
右键计算机属性->高级系统设置->系统属性->高级->环境变量->添加如下的系统变量:
变量名:【JAVA_HOME】
变量值:【D:\Program Files\Java\jdk1.8.0_92】【jdk安装路径】
变量名:【path】
变量值:【\;%JAVA_HOME%\bin;】
变量名:【CLASSPATH】
变量值:【.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;】
步骤三:在cmd中输入java -version,检查是否显示jdk信息,确定是否安装成功
(二)、安装Jmeter
步骤一:安装Jmeter
1、下载Jmeter
官网地址:http://jmeter.apache.org/download_jmeter.cgi

2、解压Jmeter安装包
步骤二:配置Jmeter环境变量
按下面变量名和变量值配置Jmeter系统环境变量:
【变量名】JMETER_HOME
【变量值】D:\Program Files\jmeter\apache-jmeter-4.0(jmeter解压路径)
【变量名】CLASSPATH
【变量值】%JMETER_HOME\lib\ext\ApacheJMeter_core.jar;%JMETER_HOME%\lib\jorphan.jar;%JMETER_HOME%\lib\logkit-2.0.jar;
步骤三:启动Jmeter
双击Jmeter解压路径(apache-jmeter-4.0\bin)的bin下面的jmeter.bat,如下图


三、jmter的用法
创建线程计划和线程组

- 设置线程数 ,如图所示

线程组:测试里每个任务都要线程去处理,所有我们后来的任务必须在线程组下面创建。可以在“Test Plan(鼠标右击) -> 添加 ->Threads(Users) -> 线程组”来建立它,然后在线程组面板里有几个输入栏:线程数、Ramp-Up Period(in seconds)、循环次数,其中Ramp-Up Period(in seconds)表示在这时间内创建完所有的线程。如有8个线程,Ramp-Up = 200秒,那么线程的启动时间间隔为200/8=25秒,这样的好处是:一开始不会对服务器有太大的负载。
Number of Threads(users): 一个用户占一个线程, 100个线程就是模拟100个用户
Ramp-Up Period(in seconds): 设置线程需要多长时间全部启动。如果线程数为200 ,准备时长为10 ,那么需要1秒钟启动20个线程。也就是每秒钟启动20个线程。
Loop Count: 每个线程发送请求的次数。如果线程数为200 ,循环次数为10 ,那么每个线程发送10次请求。总请求数为200*10=2000 。如果勾选了“永远”,那么所有线程
会一直发送请求,直到选择停止运行脚本。
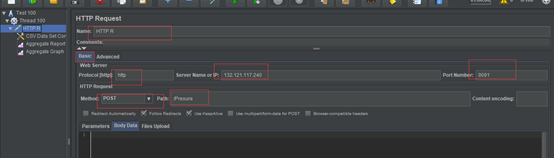
- 添加请求,如图

设置请求方法,如图所示

请求报文的路径,也可以直接把要输入的内容到第4请求方法中


选取监听的方式

聚合报告界面

图形展示的设置的

表格展示

同时设true和线程的调度器的执行限制时间才能在规定的时间有效,如图

或

四、jmeter指标说明(注:其中)
1、表格显示,属性说明
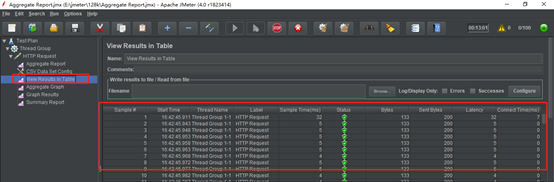
Sample:每个请求的序号
Start Time:每个请求开始时间
Thread Name:每个线程的名称
Label:Http请求名称
Sample Time:每个请求所花时间,单位毫秒
Status:请求状态,如果为勾则表示成功,如果为叉表示失败。
Bytes:请求的字节数
样本数目:也就是上面所说的请求个数,成功的情况下等于你设定的并发数目乘以循环次数
平均:每个线程请求的平均时间
最新样本:表示服务器响应最后一个请求的时间
偏离:服务器响应时间变化、离散程度测量值的大小,或者,换句话说,就是数据的分布
2、聚合报告显示属性说明
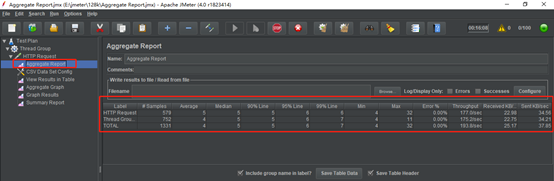
Label:每个JMeter的element的Name值。例如HTTP Request的Name
#Samples:样本数量。多少个请求
Average:平均响应时间(单位:)。默认是单个Request的平均响应时间,当使用了TransactionController时,也可以以Transaction为单位显示平均响应时间
Median:中位数,也就是50%用户的响应时间
90%Line:90%用户的响应时间
95%Line:95%用户的响应时间
99%Line:99%用户的响应时间
注:为什么要有*%用户响应时间?因为在评估一次测试的结果时,仅仅有平均事物响应时间是不够的。假如有一次测试,总共有100个请求被响应,其中最小响应时间为0.02秒,最大响应时间为110秒,平均事务响应时间为4.7秒,你会不会想到最小和最大响应时间如此大的偏差是否会导致平均值本身并不可信?
我们可以在95 th之后继续添加96/ 97/ 98/ 99/ 99.9/ 99.99 th,并利用Excel的图表功能画一条曲线,来更加清晰表现出系统响应时间的分布情况。这时候你也许会发现,那个最大值的出现几率只不过是千分之一甚至万分之一,而且99%的用户请求的响应时间都是在性能需求所定义的范围之内的;如下图则是最低响应时间的值出现几率是很小的,实际99%的用户请求响应时间都要20000+。
Min:最小响应时间
Max:最大响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量。默认情况下标示每秒完成的请求数(具体单位如下图)
KB/sec:每秒从服务器端接收到的数据量。
3.Summary Report界面,属性说明
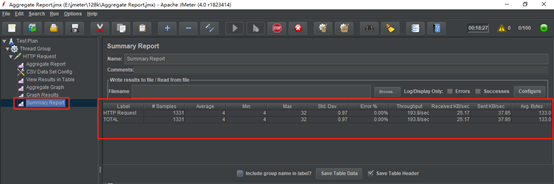
所有数据写入一个文件:保存测试结果到本地。
文件名:指定保存结果。
仅日志错误:仅保存日志中报错的部分。
Successes:保存日志中成功的部分。
Configure:设置结果属性,即保存哪些结果字段到文件。一般保存必要的字段 信息即可,保存的越多,对负载机的IO会产生影响。
Label:取样器名称(或者是事务名)。
#Samples:取样器运行次数(提交了多少笔业务)。
Average:请求(事务)的平均响应时间,单位为毫秒。
Min:请求的最小响应时间,单位为毫秒。
Max:请求的最大响应时间,单位为毫秒。
Std.Dev:响应时间的标准方差。
Error%:事务错误率。
Throughput:吞吐率(TPS)。
KB/sec:每秒数据包流量,单位是KB。
Avg.Bytes:平均数据流量,单位是Byte。
一般分五个步骤:
(1)添加线程组
(2)添加http请求
(3)在http请求中写入接入url、路径、请求方式和参数
(4)添加查看结果树
- 调用接口、查看返回值
1.1、jmeter 发get请求

jmeter 发post请求

jmeter 添加cookie
需要在线程组里添加配置元件—HTTP Cookie 管理器


jmeter 添加header
需要在线程组里面添加配置元件—HTTP信息头管理器


jmeter 上传文件

- jmeter 参数化
入参经常变化的话,则可以设置成一个变量,方便统一修改管理;如果入参要求随机或可多种选择,则通过函数生成器或者读取文件形成一个变量。所以参数化有三种方式:用户定义的变量、函数生成器、读取文件。
- 用户定义的变量
需要添加配置元件-用户定义的变量。


- 函数生成器
需要用到函数助手功能,可以调用函数生成一些有规则的数据。常用的几个函数有_uuid、_random、_time。_uuid会生成一个随机唯一 的id,比如在避免java请求重发造成未处理数据太多的情况,接口请求可加一个唯一的请求id唯一的响应id进行一一对应;随机数_random,可以 在你指定的一个范围里取随机值;取当前时间_time,一些时间类的入参可以使用,如{__time(,)} 是生成精确到毫秒的时间戳、{__time(/1000,)}是生成精确到秒的时间戳、${__time(yyyy-MM-dd HH:mm:ss,)} 是生成精确到秒的当前时间。

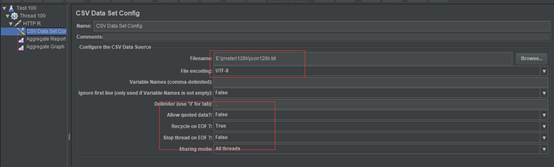
从文件读取
需要在线程组里面添加配置元件-CSV Data Set Config
其中Recycle on EOF:设置True后,允许循环取值
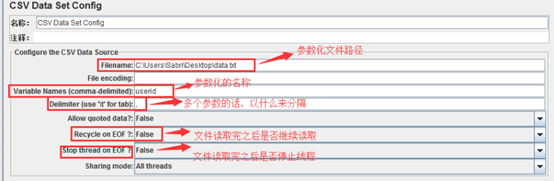
具体的例子如下所示:



jmeter 断言
jmeter断言用来检测响应返回的结果和我们预期的是否一致。若针对整个线程组的话,则在线程组下添加断言-响应断言;若只是针对某个请求的话,则在请求下添加断言-响应断言。


4、jmeter关联
接口请求之间存在参数调用,为了保存这个参数,建立jmeter关联。比如登陆接口和购买商品接口,购买商品接口就需要登陆接口返回的token等登陆信息,jmeter关联就可以保存这个token信息,方便购买商品接口使用。
jmeter关联可以通过二种方式来完成,获取到返回结果中指定的值。它们分别是正则表达式提取器、 json path extractor。
(1)正则表达式提取器
若想获取的返回值未匹配到,可以把正则表达式两边匹配的数据扩大点。

a. 关于正则表达式
():括起来的部分就是要提取的。
.:匹配除换行外的任何字符串。
+:代表+号前面的字符必须至少出现一次(一次或多次)。
?:代表?前面的字符最多可以出现一次,在找到第一个匹配项后停止(0次或1次)。
:代表号前面的字符可以不出现,也可以出现一次或者多次(0次、1次或者多次)
(.*):贪婪模式,匹配尽可能多的字符
(.*?)或(.+?):匹配尽可能少的字符,一旦匹配到第一个就不往下走了。
b. 关于模板
若想提取多个值的话,比如是a和b这两个值,则可以写成:$1$$2$。无论要提取多少个值,引用名称就是一个的,比如名称为id,${id_go}:获取整个字符串ab,${id_g1}:获取的是a,${id_g2}:获取的是b。
下面有一个具体的实例,如下图所示:


- json path extractor
jmeter通过安装json path extractor插件来处理json串,提取json串中的字段值。插件的下载地址:https://jmeter-plugins.org/?search=jpgc-json,下载完成,解压后,直接把lib文件夹放到jmeter相应目录下面。特别说明:jmeter 2.xx左右的版本尝试过无法使用该插件,在jmeter 3.xx左右的版本装完插件后能正常使用。
需要在请求下创建后置处理器-jp@gc-JSON Path Extractor,具体的实例如下所示:



jmeter 操作数据库
操作数据库基本有四个步骤:
(1)导入mysql的jdbc的jar包
(2)创建数据库的连接配置,线程组里添加配置元件-JDBC Connection Configuration
(3)线程组里添加jdbc request,写sql语句
(4)添加察看结果树,点击启动按钮,就能看到执行的SQL。具体的实例如下截图所示




特别说明:
jmeter还可以操作oracle、postgreSQL、msSQL、mongodb等等数据库,同时不同的数据库,JDBC Connection Configuration填写的Database url格式和JDBC Driver驱动名称也不相同。jmeter数据库驱动列表如下表所示:
| 数据库 |
驱动 |
数据库url |
|
| mysql |
com.mysql.jdbc.Driver |
jdbc:mysql://host:port/{dbname}?allowMultiQueries=true |
|
| oracle |
org.postgresql.Driver |
dbc:postgresql:{dbname} |
|
基本分为五个步骤:(1)先需要通过soapui工具获取到webservice接口的请求地址、请求报文和请求soapaction。 (2)jmeter新建一个线程组 (3)线程组下建立SOAP/XML-RPC Request,写入请求url、请求报文、请求soapaction。(3)启动jmeter,调用接口,通过察看结果树查看返回值。
soapui获取信息的实例如下图所示:

soapui提交完后,点击raw,可看到soapation,有些接口若没返回soapation,则jmeter里也就不用填。

jmeter-webservice脚本实例如下图所示:

六、附加信息
1、jmeter在linux下进行压力测试
1.1、jmeter 在linux安装
简单说下,就是要先安装jdk,同时再配置环境变量,最后再上传jmeter压缩的安装包,在linux下解压完安装包就可以使用了。jmeter在linux运行
进入jmeter下的bin目录下运行脚本,未配置jmeter环境变量的条件下,运行的命令:
./jmeter -n -t a.jmx -l res.jtl
其中a.jmx是准备好的jmeter脚本,res.jtl是测试结果文件,测试结果文件可以导入到jmeter察看结果树下查看。
七、压力测试
1、压力测试场景
压力测试分两种场景:
一种是单场景,压一个接口的;
第二种是混合场景,多个有关联的接口。压测时间,一般场景都运行10-15分钟。如果是疲劳测试,可以压一个小时、一天或一周,根据实际情况来定。
压测前要明确压测功能和压测指标,一般需要确定的几个问题:
-
- 固定接口参数进行压测还是进行接口参数随机化压测?
- 要求支持多少并发数?
- TPS(每秒钟处理事务数)目标多少?响应时间要达到多少?
2.4、压服务器名称还是压服务器IP,一般都是压测指定的服务器
3、压测设置
-
- 线程数:并发数量,能跑多少量。具体说是一次存在多少用户同时访问
- Rame-Up Period(in seconds):表示JMeter每隔多少秒发动并发。理解成准备时长:设置虚拟用户数需要多长时间全部启动。如果线程数是20,准备时长为10,那么需要10秒钟启动20个数量,也就是每秒钟启动2个线程。
- 循环次数:这个设置不会改变并发数,可以延长并发时间。总请求数=线程数*循环次数
- 调度器:设置压测的启动时间、结束时间、持续时间和启动延迟时间。
运行完后,聚合报告会显示压测的结果。主要观察Samples、Average、error、Throughput。
-
- Samples:表示一共发出的请求数
- Average:平均响应时间,默认情况下是单个Request的平均响应时间(ms)
- Error%:测试出现的错误请求数量百分比。若出现错误就要看服务端的日志,配合开发查找定位原因
4.4、Throughput:简称tps,吞吐量,默认情况下表示每秒处理的请求数,也就是指服务器处理能力,tps越高说明服务器处理能力越好。
有错误率同开发确认,确定是否允许错误的发生或者错误率允许在多大的范围内;
5.1、Throughput吞吐量每秒请求的数大于并发数,则可以慢慢的往上面增加;
若在压测的机器性能很好的情况下,出现吞吐量小于并发数,说明并发数不能再增加了,可以慢慢的往下减,找到最佳的并发数;压测结束,登陆相应的web服务器查看CPU等性能指标,进行数据的分析;
5.2、最大的tps:不断的增加并发数,加到tps达到一定值开始出现下降,那么那个值就是最大的tps。
5.3、最大的并发数:最大的并发数和最大的tps是不同的概率,一般不断增加并发数,达到一个值后,服务器出现请求超时,则可认为该值为最大的并发数。
5.4、压测过程出现性能瓶颈,若压力机任务管理器查看到的cpu、网络和cpu都正常,未达到90%以上,则可以说明服务器有问题,压力机没有问题。
5.5、影响性能考虑点包括:数据库、应用程序、中间件(tomact、Nginx)、网络和操作系统等方面。
智能推荐
torch.where() RuntimeError: expected scalar type int but found float/double-程序员宅基地
文章浏览阅读521次。这个问题大多数是由于使用老版本torch导致的,github上有说这是某个版本的bug,再后续工作中已经进行了修复,要是非要使用该版本torch的话,我使用了一个比较笨拙的方法,写一个where代替torch.where()这个版本是xy不需要同维度的,不过肯定没有torch写的快,不过能运行了。这是复现muzic中的getmusic时遇到并解决的问题。_runtimeerror: expected scalar type int but found float
2024最新计算机毕业设计选题大全-程序员宅基地
文章浏览阅读1.6k次,点赞12次,收藏7次。大家好!大四的同学们毕业设计即将开始了,你们做好准备了吗?学长给大家精心整理了最新的计算机毕业设计选题,希望能为你们提供帮助。如果在选题过程中有任何疑问,都可以随时问我,我会尽力帮助大家。在选择毕业设计选题时,有几个要点需要考虑。首先,选题应与计算机专业密切相关,并且符合当前行业的发展趋势。选择与专业紧密结合的选题,可以使你们更好地运用所学知识,并为未来的职业发展奠定基础。要考虑选题的实际可行性和创新性。选题应具备一定的实践意义和应用前景,能够解决实际问题或改善现有技术。
dcn网络与公网_电信运营商DCN网络的演变与规划方法(The evolution and plan method of DCN)...-程序员宅基地
文章浏览阅读3.4k次。摘要:随着电信业务的发展和电信企业经营方式的转变,DCN网络的定位发生了重大的演变。本文基于这种变化,重点讨论DCN网络的规划方法和运维管理方法。Digest: With the development oftelecommunication bussiness and the change of management of telecomcarrier , DCN’s role will cha..._电信dcn
动手深度学习矩阵求导_向量变元是什么-程序员宅基地
文章浏览阅读442次。深度学习一部分矩阵求导知识的搬运总结_向量变元是什么
月薪已炒到15w?真心建议大家冲一冲数据新兴领域,人才缺口极大!-程序员宅基地
文章浏览阅读8次。近期,裁员的公司越来越多今天想和大家聊聊职场人的新出路。作为席卷全球的新概念ESG已然成为当前各个行业关注的最热风口目前,国内官方发布了一项ESG新证书含金量五颗星、中文ESG证书、完整ESG考试体系、名师主讲...而ESG又是与人力资源直接相关甚至在行业圈内成为大佬们的热门话题...当前行业下行,裁员的公司也越来越多大家还是冲一冲这个新兴领域01 ESG为什么重要?在双碳的大背景下,ESG已然成...
对比传统运营模式,为什么越拉越多的企业选择上云?_系统上云的前后对比-程序员宅基地
文章浏览阅读356次。云计算快速渗透到众多的行业,使中小企业受益于技术变革。最近微软SMB的一项研究发现,到今年年底,78%的中小企业将以某种方式使用云。企业希望投入少、收益高,来取得更大的发展机会。云计算将中小企业信息化的成本大幅降低,它们不必再建本地互联网基础设施,节省时间和资金,降低了企业经营风险。科技创新已成时代的潮流,中小企业上云是创新前提。云平台稳定、安全、便捷的IT环境,提升企业经营效率的同时,也为企业..._系统上云的前后对比
随便推点
在LaTeX中使用.bib文件统一管理参考文献_egbib-程序员宅基地
文章浏览阅读913次。在LaTeX中,可在.tex文件的同一级目录下创建egbib.bib文件,所有的参考文件信息可以统一写在egbib.bib文件中,然后在.tex文件的\end{document}前加入如下几行代码:{\small\bibliographystyle{IEEEtran}\bibliography{egbib}}即可在文章中用~\cite{}宏命令便捷的插入文内引用,且文章的Reference部分会自动排序、编号。..._egbib
Unity Shader - Predefined Shader preprocessor macros 着色器预处理宏-程序员宅基地
文章浏览阅读950次。目录:Unity Shader - 知识点目录(先占位,后续持续更新)原文:Predefined Shader preprocessor macros版本:2019.1Predefined Shader preprocessor macros着色器预处理宏Unity 编译 shader programs 期间的一些预处理宏。(本篇的宏介绍随便看看就好,要想深入了解,还是直接看Unity...
大数据平台,从“治理”数据谈起-程序员宅基地
文章浏览阅读195次。本文目录:一、大数据时代还需要数据治理吗?二、如何面向用户开展大数据治理?三、面向用户的自服务大数据治理架构四、总结一、大数据时代还需要数据治理吗?数据平台发展过程中随处可见的数据问题大数据不是凭空而来,1981年第一个数据仓库诞生,到现在已经有了近40年的历史,相对数据仓库来说我还是个年轻人。而国内企业数据平台的建设大概从90年代末就开始了,从第一代架构出现到..._数据治理从0搭建
大学抢课python脚本_用彪悍的Python写了一个自动选课的脚本 | 学步园-程序员宅基地
文章浏览阅读2.2k次,点赞4次,收藏12次。高手请一笑而过。物理实验课别人已经做过3、4个了,自己一个还没做呢。不是咱不想做,而是咱不想起那么早,并且仅有的一次起得早,但是哈工大的服务器竟然超负荷,不停刷新还是不行,不禁感慨这才是真正的“万马争过独木桥“啊!服务器不给力啊……好了,废话少说。其实,我的想法很简单。写一个三重循环,不停地提交,直到所有的数据都accepted。其中最关键的是提交最后一个页面,因为提交用户名和密码后不需要再访问其..._哈尔滨工业大学抢课脚本
english_html_study english html-程序员宅基地
文章浏览阅读4.9k次。一些别人收集的英文站点 http://www.lifeinchina.cn (nice) http://www.huaren.us/ (nice) http://www.hindu.com (okay) http://www.italki.com www.talkdatalk.com (transfer)http://www.en8848.com.cn/yingyu/index._study english html
Cortex-M3双堆栈MSP和PSP_stm32 msp psp-程序员宅基地
文章浏览阅读5.5k次,点赞19次,收藏78次。什么是栈?在谈M3堆栈之前我们先回忆一下数据结构中的栈。栈是一种先进后出的数据结构(类似于枪支的弹夹,先放入的子弹最后打出,后放入的子弹先打出)。M3内核的堆栈也不例外,也是先进后出的。栈的作用?局部变量内存的开销,函数的调用都离不开栈。了解了栈的概念和基本作用后我们来看M3的双堆栈栈cortex-M3内核使用了双堆栈,即MSP和PSP,这极大的方便了OS的设计。MSP的含义是Main..._stm32 msp psp