P-R曲线与ROC曲线使用总结_p-r曲线平滑-程序员宅基地
技术标签: 二分类模型评估 ROC曲线 学习笔记 不平衡分类问题评估 人工智能 P-R曲线
P-R曲线与ROC曲线总结
作者:jliang
1.P-R曲线
1)实际预测时二分类的四种情况

- 真阳性/真正类(True Positive,TP):预测为正类,实际是正类;
- 假阳性/假正类(False Positive,FP):预测为正类,实际是负类;误报,给出的匹配是不正确的;
- 真阴性/真负类(True Negative,TN):预测为负类,实际是负类;
- 假阴性/假负类(False Negative,FN):预测为负类,实际为正类;漏报,没有正确找到的匹配的数目。
2)相关指标
- 查准率/精确率(Precision):
 (即真正类占被预测为正类的所有样本的比例)
(即真正类占被预测为正类的所有样本的比例) - 查全率(Recall),灵敏度(Sensitivity),真阳性率(True Positive Rate,TPR):
 (即真正类占所有真实正类的比例)
(即真正类占所有真实正类的比例) - 真阴性率(True Negative Rate,TNR),特异度(Specificity):
 (即真负类占所有真实负类的比例)
(即真负类占所有真实负类的比例) - 假阴性率(False Negatice Rate,FNR),漏诊率( = 1 - 灵敏度):
 (即假正类占所有真实正类的比例)
(即假正类占所有真实正类的比例) - 假阳性率(False Positice Rate,FPR),误诊率( = 1 - 特异度):
 (即假负类占所有真实负类的比例)
(即假负类占所有真实负类的比例) - 阳性似然比 = 真阳性率 / 假阳性率 = 灵敏度 / (1 - 特异度)
- 阴性似然比 = 假阴性率 / 真阴性率 = (1 - 灵敏度) / 特异度
- Youden指数 = 灵敏度 + 特异度 - 1 = 真阳性率 - 假阳性率
3)P-R曲线就是精确率precision vs 召回率recall 曲线,以recall作为横坐标轴,precision作为纵坐标轴。
(1)算法对样本进行分类时,都会有置信度,即表示该样本是正样本的概率,比如99%的概率认为样本A是正例,1%的概率认为样本B是正例。通过选择合适的阈值,比如50%,对样本进行划分,概率大于50%的就认为是正例,小于50%的就是负例。
(2)通过置信度就可以对所有样本进行排序,再逐个样本的选择阈值,在该样本之前的都属于正例,该样本之后的都属于负例。每一个样本作为划分阈值时,都可以计算对应的precision和recall,那么就可以以此绘制曲线。
4)P-R曲线的特性
(1)根据逐个样本作为阈值划分点的方法,可以推敲出
- recall值是递增的(但并非严格递增),随着划分点左移,正例被判别为正例的越来越多,不会减少。
- 而精确率precision并非递减,二是有可能振荡的,虽然正例被判为正例的变多,但负例被判为正例的也变多了,因此precision会振荡,但整体趋势是下降。
(2)P-R曲线肯定会经过(0,0)点
- 比如讲所有的样本全部判为负例,则TP=0,那么P=R=0,因此会经过(0,0)点,但随着阈值点左移,precision初始很接近1,recall很接近0,因此有可能从(0,0)上升的线和坐标重合,不易区分。
(3)曲线最终不会到(1,0)点
- 很多P-R曲线的终点看着都是(1,0)点,这可能是因为负例远远多于正例。
(4)较合理的P-R曲线应该是(曲线一开始被从(0,0)拉升到(0,1),并且前面的都预测对了,全是正例,因此precision一直是1。

2.AUC曲线
1)ROC曲线动机
(1)对于0,1两类分类问题,一些分类器得到的结果往往不是0,1这样的标签,如神经网络,得到诸如0.5,0,8这样的分类结果。这时,我们人为取一个阈值,比如0.4,那么小于0.4的为0类,大于等于0.4的为1类,可以得到一个分类结果。同样,这个阈值我们可以取0.1,0.2等等。取不同的阈值,得到的最后的分类情况也就不同。
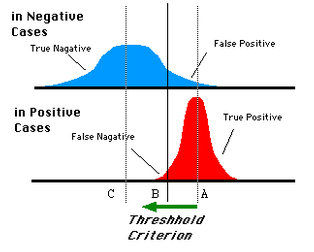
- 蓝色表示原始为负类分类得到的统计图,红色表示原始为正类得到的统计图。
- 我们取一条直线,直线左边分为负类,直线右边分为正类,这条直线也就是我们所取的阈值。阈值不同,可以得到不同的结果,但是由分类器决定的统计图始终是不变的。
- 这时候就需要一个独立于阈值,只与分类器有关的评价指标,来衡量特定分类器的好坏。
(2)ROC曲线的动机:在类不平衡的情况下,如正样本有90个,负样本有10个,直接把所有样本分类为正样本,得到识别率为90%,但这显然是没有意义的,这就是ROC曲线的动机。
2)ROC曲线:接收者操作特征曲线(receiver operating characteristic curve),是反映敏感性和特异性连续变量的综合指标,roc曲线上每个点反映着对同一信号刺激的感受性。

(1)横轴FPR:1-TNR,1-Specificity,FPR越大,预测正类中实际负类越多。
(2)纵轴TPR:Sensitivity(正类覆盖率),TPR越大,预测正类中实际正类越多。
(3)理想目标:TPR=1,FPR=0,即图中(0,1)点,故ROC曲线越靠拢(0,1)点,越偏离45度对角线越好,Sensitivity、Specificity越大效果越好。
(4)如上,是三条ROC曲线,在0.23处取一条直线。那么,在同样的低FPR=0.23的情况下,红色分类器得到更高的PTR。也就表明,ROC越往上,分类器效果越好。我们用一个标量值AUC来量化他。
3)如何画roc曲线
(1)假设已经得出一系列样本被划分为正类的概率,然后按照大小排序,下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。

(2)接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:

(3)当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
4)AUC
(1)AUC (Area Under Curve) 被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围一般在0.5和1之间。
- AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
(2)使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
(3)AUC的面积可以这样算:![]()
(4)AUC的物理意义:假设分类器的输出是样本属于正类的socre(置信度),则AUC的物理意义为,任取一对(正、负)样本,正样本的score大于负样本的score的概率。
5)ACU的计算
(1)方法一:AUC为ROC曲线下的面积,那我们直接计算面积可得。面积为一个个小的梯形面积之和,计算的精度与阈值的精度有关。
- 测试样本是有限时得到的AUC曲线必然是一个阶梯状的,计算的AUC也就是这些阶梯下面的面积之和。我们先把score排序(假设score越大,此样本属于正类的概率越大),然后一边扫描就可以得到我们想要的AUC。
- 这么做有个缺点,就是当多个测试样本的score相等的时候,我们调整一下阈值,得到的不是曲线一个阶梯往上或者往右的延展,而是斜着向上形成一个梯形。此 时,我们就需要计算这个梯形的面积。用这种方法计算AUC实际上是比较麻烦的。
(2)方法二:根据AUC的物理意义,我们计算正样本score大于负样本的score的概率。取N*M(N为正样本数,M为负样本数)个二元组,比较score,最后得到AUC。时间复杂度为O(N*M)。
- 在有限样本中我们常用的得到概率的办法就是通过频率来估计之。这种估计随着样本规模的扩大而逐渐逼近真实值。这 和上面的方法中,样本数越多,计算的AUC越准确类似,也和计算积分的时候,小区间划分的越细,计算的越准确是同样的道理。
- 具体来说就是统计一下所有的 M×N(M为正类样本的数目,N为负类样本的数目)个正负样本对中,有多少个组中的正样本的score大于负样本的score。当二元组中正负样本的 score相等的时候,按照0.5计算。然后除以MN。实现这个方法的复杂度为O(n^2)。n为样本数(即n=M+N)
(3)方法三:实际上和上述第二种方法是一样的,但是复杂度减小了。
- 它也是首先对score从大到小排序,然后令最大score对应的sample 的rank为n,第二大score对应sample的rank为n-1,以此类推。
- 然后把所有的正类样本的rank相加,再减去M-1种两个正样本组合的情况。得到的就是所有的样本中有多少对正类样本的score大于负类样本的score。然后再除以M×N。时间复杂度为O(N+M)。

3.P-R曲线与AUC曲线对比
1)ROC曲线和PR(Precision - Recall)曲线皆为类别不平衡问题中常用的评估方法,二者既有相同也有不同点。
2)ROC曲线的优点

(1)兼顾正例和负例的权衡。因为TPR聚焦于正例,FPR聚焦于与负例,使其成为一个比较均衡的评估方法。
(2)ROC曲线选用的两个指标,![]() ,
,![]() ,都不依赖于具体的类别分布。
,都不依赖于具体的类别分布。
- 注意TPR用到的TP和FN同属P列,FPR用到的FP和TN同属N列,所以即使P或N的整体数量发生了改变,也不会影响到另一列。
- 也就是说,即使正例与负例的比例发生了很大变化,ROC曲线也不会产生大的变化,而像Precision使用的TP和FP就分属两列,则易受类别分布改变的影响。
(3)举了个例子,负例增加了10倍,ROC曲线没有改变,而PR曲线则变了很多。作者认为这是ROC曲线的优点,即具有鲁棒性,在类别分布发生明显改变的情况下依然能客观地识别出较好的分类器。

3)ROC曲线的缺点
(1)上文提到ROC曲线的优点是不会随着类别分布的改变而改变,但这在某种程度上也是其缺点。因为负例N增加了很多,而曲线却没变,这等于产生了大量FP。像信息检索中如果主要关心正例的预测准确性的话,这就不可接受了。
(2)在类别不平衡的背景下,负例的数目众多致使FPR的增长不明显,导致ROC曲线呈现一个过分乐观的效果估计。
- ROC曲线的横轴采用FPR,根据,当负例N的数量远超正例P时,FP的大幅增长只能换来FPR的微小改变。结果是虽然大量负例被错判成正例,在ROC曲线上却无法直观地看出来。(当然也可以只分析ROC曲线左边一小段)
- 举个例子,假设一个数据集有正例20,负例10000,开始时有20个负例被错判,FPR=20/(20+9980)=0.002,接着又有20个负例错判,FPR2=40/(40+9960)=0.004,在ROC曲线上这个变化是很细微的。而与此同时Precision则从原来的0.5下降到了0.33,在PR曲线上将会是一个大幅下降。
4)使用场景
(1)ROC曲线由于兼顾正例与负例,所以适用于评估分类器的整体性能,相比而言PR曲线完全聚焦于正例。
(2)如果有多份数据且存在不同的类别分布,比如信用卡欺诈问题中每个月正例和负例的比例可能都不相同,这时候如果只想单纯地比较分类器的性能且剔除类别分布改变的影响,则ROC曲线比较适合,因为类别分布改变可能使得PR曲线发生变化时好时坏,这种时候难以进行模型比较;反之,如果想测试不同类别分布下对分类器的性能的影响,则PR曲线比较适合。
(3)如果想要评估在相同的类别分布下正例的预测情况,则宜选PR曲线。
(4)类别不平衡问题中,ROC曲线通常会给出一个乐观的效果估计,所以大部分时候还是PR曲线更好。
5)最后可以根据具体的应用,在曲线上找到最优的点,得到相对应的precision,recall,f1 score等指标,去调整模型的阈值,从而得到一个符合具体应用的模型。
参考文献
[1]. 模型评估与选择(中篇)-ROC曲线与AUC曲线. https://blog.csdn.net/qq_37059483/article/details/78595695
[2]. 机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率. https://www.jianshu.com/p/c61ae11cc5f6
[3]. AUC,ROC我看到的最透彻的讲解. https://blog.csdn.net/u013385925/article/details/80385873
[4]. 机器学习之类别不平衡问题 (2) —— ROC和PR曲线. https://www.imooc.com/article/48072
智能推荐
解决electron+vue项目起始加载慢的问题_electron vue项目打开慢-程序员宅基地
文章浏览阅读461次。_electron vue项目打开慢
linux下编译GDAL外加扩展格式支持(五)--完-程序员宅基地
文章浏览阅读229次。接1、2、3、4篇。10、安装mysql支持安装fedora15或者16系统时若选择安装mysql数据库,则必须自行安装mysql开发包。因为自带默认数据库不会安装这个包。否则会遇到mysql错误:ogr_mysql.h:34:23: fatal error: my_global.h: No such file or directory#问题原因:找不到mysql头文件..._linux gdal netcdf5
Linux tc qdisc 模拟网络丢包延时-程序员宅基地
文章浏览阅读1.2k次。Linux tc qdisc 模拟网络丢包延时_tc qdisc
linux64bit 安装 jdk 1.7-程序员宅基地
文章浏览阅读336次。linux64bit 安装 jdk 1.7下载地址 : https://edelivery.oracle.com/otn-pub/java/jdk/7u21-b11/jdk-7u21-linux-x64.rpm0. 卸载rpm版的jdk: #rpm -qa|grep jdk 显示:jdk-1.6.0_10-fcs 卸载:#rpm -e --nodep..._liunx64位得jdk1.7
【Linux笔记】-----Nginx/LVS/HAProxy负载均衡的优缺点_中间件应用场景nginx lvs proxy-程序员宅基地
文章浏览阅读552次。开始听到负载均衡的时候,我第一反应想到的是链路负载均衡,在此之前主要是在学习网络方面知识,像在NA、NP阶段实验做链路负载均衡时常会遇到,后来还接触到SLB负载分担技术,这都是在链路基础上实现的。 其实负载均衡可以分为硬件实现负载均衡和软件实现负载均衡。 硬件实现负载均衡:常见F5和Array负载均衡器,配套专业维护服务,但是成本昂贵。 软件实现负载均衡:常见开源免费的负载均衡软件有Ngin..._中间件应用场景nginx lvs proxy
多维时序 | MATLAB实现CNN-LSTM多变量时序预测_cnn可以进行多步预测-程序员宅基地
文章浏览阅读4.7k次。多维时序 | MATLAB实现CNN-LSTM多变量时序预测目录多维时序 | MATLAB实现CNN-LSTM多变量多步预测基本介绍模型特点程序设计学习总结参考资料基本介绍本次运行测试环境MATLAB2020b,MATLAB实现CNN-LSTM多变量多步预测。模型特点深度学习使用分布式的分层特征表示方法自动提取数据中的从最低层到最高层固有的抽象特征和隐藏不变结构. 为了充分利用单个模型的优点并提高预测性能, 现已提出了许多组合模型。CNN 是多层前馈神经网络, 已被证明在提取隐藏_cnn可以进行多步预测
随便推点
【9.3】用户和组的管理、密码_polkitd:input 用户和组-程序员宅基地
文章浏览阅读219次。3.1 用户配置文件和密码配置文件3.2 用户组管理3.3 用户管理3.4 usermod命令3.5 用户密码管理3.6 mkpasswd命令_polkitd:input 用户和组
pca算法python代码_三种方法实现PCA算法(Python)-程序员宅基地
文章浏览阅读670次。主成分分析,即Principal Component Analysis(PCA),是多元统计中的重要内容,也广泛应用于机器学习和其它领域。它的主要作用是对高维数据进行降维。PCA把原先的n个特征用数目更少的k个特征取代,新特征是旧特征的线性组合,这些线性组合最大化样本方差,尽量使新的k个特征互不相关。关于PCA的更多介绍,请参考:https://en.wikipedia.org/wiki/Prin..._inprementation python code of pca
内存地址Linux下内存分配与映射之一-程序员宅基地
文章浏览阅读35次。发一下牢骚和主题无关:地址类型:32位的cpu,共4G间空,其中0-3G属于用户间空地址,3G-4G是内核间空地址。用户虚拟地址:用户间空程序的地址物理地址:cpu与内存之间的用使地址总线地址:外围总线和内存之间的用使地址内核逻辑地址:内存的分部或全体射映,大多数情况下,它与物理地址仅差一个偏移量。如Kmalloc分..._linux 内存条与内存地址
自动化测试介绍_自动化测试中baw库指的什么-程序员宅基地
文章浏览阅读1.3k次,点赞2次,收藏16次。什么是自动化测试? 做测试好几年了,真正学习和实践自动化测试一年,自我感觉这一个年中收获许多。一直想动笔写一篇文章分享自动化测试实践中的一些经验。终于决定花点时间来做这件事儿。 首先理清自动化测试的概念,广义上来讲,自动化包括一切通过工具(程序)的方式来代替或辅助手工测试的行为都可以看做自动化,包括性能测试工具(loadrunner、jmeter),或自己所写的一段程序,用于_自动化测试中baw库指的什么
a0图框标题栏尺寸_a0图纸尺寸(a0图纸标题栏尺寸标准国标)-程序员宅基地
文章浏览阅读1.6w次。A0纸指的是一平方米大小的白银比例长方形纸(长为1189mm宽为841mm)。A0=1189mm*841mm A1=841mm*594mm 相当于1/2张A0纸 A2=594mm*420mm 相当于1/4.A1图纸大小尺寸:841mm*594mm 即长为841mm,宽为594mm 过去是以多少"开"(例如8开或16开等)来表示纸张的大小,我国采用国际标准,规定以 A0、A1、A2、.GB/T 14..._a0图纸尺寸
TreeTable的简单实现_treetable canvas-程序员宅基地
文章浏览阅读966次。最终效果图:UI说明:针对table本身进行增强的tree table组件。 tree的数据来源是单元格内a元素的自定义属性:level和type。具体代码如下:Java代码 DepartmentEmployeeIDposi_treetable canvas