深度学习之CNN深度卷积神经网络-ResNet(进阶)_deep residual network pdf-程序员宅基地
1.简介
深度残差网络(deep residual network)是2015年微软何凯明团队发表的一篇名为:《Deep Residual Learning for Image Recognition》的论文中提出的一种全新的网络结构,其核心模块是残差块residual block。正是由于残差块结构的出现使得深度神经网络模型的层数可以不断加深到100层、1000层甚至更深,从而使得该团队在当年的ILSVRC 2015分类竞赛中取得卓越成绩,也深刻地影响了以后的很多深度神经网络的结构设计。
残差网络的成功不仅表现在其在ILSVRC 2015竞赛中的卓越效果,更是因为残差块skip connection/shorcut这样优秀的思想和设计,使得卷积网络随着层数加深而导致的模型退化问题能被够大幅解决,使模型深度提高一个数量级,到达上百、上千层。下面来学习一下该论文的技术原理。
1.1网络加深的后果
在残差块这样的结构引入之前,如果一个神经网络模型的深度太深,可能会带来梯度消失和梯度爆炸的问题(如下图),随着一些正则化方法的应用可以缓解此问题,但是随着layer深度的继续加深,又带来了模型退化这样的问题。而添加了带shortcut的残差块结构之后,使得整个深度神经网络的层数可以大幅增加,变得更【深】,从而有时会带来更好的训练效果。
1.2 网络模型的退化
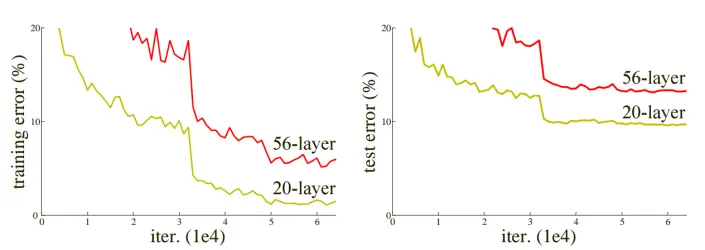
下图为CIFER10在20层和56层普通网络结构下测试和训练过程中的损失。可见,仅仅简单地加深网络,并没有带来精度的提升,相反会导致网络模型的退化。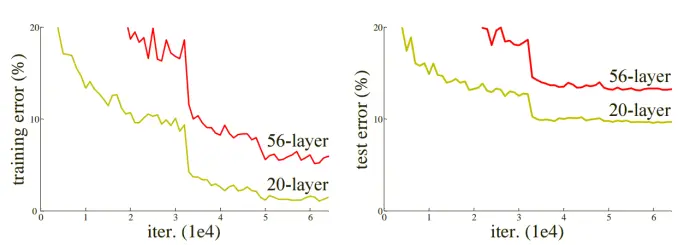
那么,这里就有一个问题,为什么加深网络会带来退化问题?即使新增的这些layer什么都没学习,保持恒等输出(所有的weight都设为1),那么按理说网络的精度也应该 = 原有未加深时的水平,如果新增的layer学习到了有用特征,那么必然加深过后的模型精度会 > 未加深的原网络。看起来对于网络的精度加深后都应该 >= 加深前才对啊 ?
实际上,让新增的layer保持什么都不学习的恒等状态,恰恰很困难,因为在训练过程中每一层layer都通过线性修正单元relu处理,而这样的处理方式必然带来特征的信息损失(不论是有效特征or冗余特征)。所以上述假设的前提是不成立的,简单的堆叠layer必然会带来退化问题。
1.3 退化问题的解决
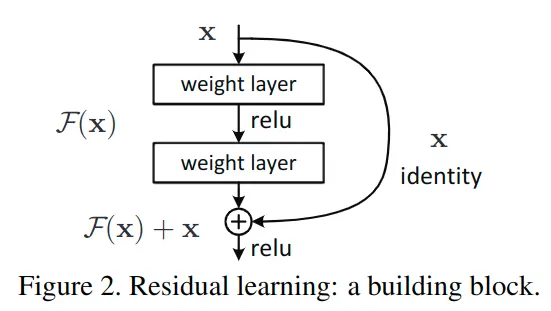
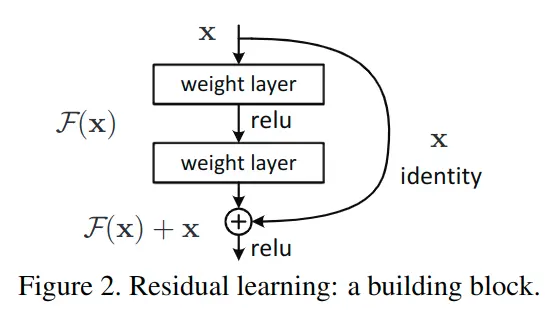
到此,何凯明团队创新地提出了残差块的构想,通过shortcut/skip connection这样的方式(最初出现在highway network中),绕过这些新增的layer,既然保持新增layer的identity恒等性很困难,那就直接绕过它们,通过shortcut通路来保持恒等。如图2所示:
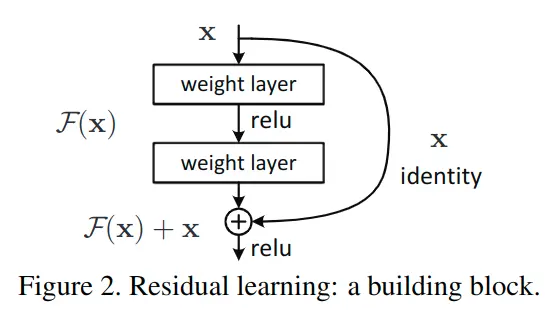
到这里,算是【曲线救国】了,虽然新增的F(x)不容易保持恒等,但让其尽量靠近0,还是相对容易做到的,这种训练方式称为 残差学习,这种结构块也称为Residual Block残差块。正是残差结构的出现,使得残差网络能很好的加深网络层数,同时解决退化问题。
1.4 资源下载
【2015】【ResNet】1512.03385v1.pdf
训练代码(官方实现):https://github.com/facebookarchive/fb.resnet.torch
2.Abstract
Abstract
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers—8×deeper than VGG nets [41] but still having lower complexity. An ensemble of these residual nets achieves 3.57% erroron the ImageNet testset. This result won the 1st place on theILSVRC 2015 classification task. We also present analysison CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importancefor many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deepresidual nets are foundations of our submissions to ILSVRC& COCO 2015 competitions1, where we also won the 1stplaces on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation
翻译
更深的神经网络更难训练。 我们提出了一种残差的学习框架,以简化比之前使用的网络还要深入的网络结构的训练。 我们通过改变一些层的输入来调整了这些层的结构以构造成残差函数来进行学习。我们提供了全面的经验证据,表明这些残差网络更易于优化,并且可以通过深度的增加而提升准确性。 在ImageNet数据集上,我们评估深度最大为152层的残差网络-比VGG网络[41]深8倍,但复杂度仍然较低。 这些残差网络整体在ImageNet测试集上实现了3.57%的误差。 该结果在ILSVRC 2015分类任务中获得第一名。 我们还将介绍具有100和1000层的基于CIFAR-10的分析。
表征深度对于许多视觉识别任务至关重要。 仅由于我们更深的网络结构,我们在COCO对象检测数据集上获得了28%的相对改进。 深度残差网络是我们提交ILSVRC&COCO 2015竞赛夺冠的基础,在该竞赛中,我们还获得了ImageNet检测,ImageNet本地化,COCO检测和COCO分割等任务的第一名
3.网络结构
3.1 示意图
3.2 残差块
4.论文解读
1.介绍
论文中Introduction部分的内容及思想,主要内容为残差学习和残差块提出的原因,解决的问题,在竞赛中取得的佳绩等。(以下大多数内容和1.简介中的类似)
深度神经网络模型随着深度加深,精度和表现都会提高。但是随着深度逐渐加深也会带来其他问题,首当其冲的是梯度消失和梯度爆炸,但是随着标准初始化和中间的正则化层解决了此问题,使得数十层的网络可以在随机梯度下降SGD过程中进行反向传播和收敛。然而,随着网络深度的进一步加深,模型的准确性达到饱和然后迅速下降,而且这种退化并不是由于过拟合所导致。如图所示:
在本文中,我们通过引入深度残差学习框架解决降级问题,而不是希望每个堆叠的层都直接适合所需的基础映射,而是明确让这些层适合残差映射。 形式上,将所需的基础映射表示为H(x),我们让堆叠的非线性层(图中的weight layer)适合F(x) := H(x) - x的另一个映射。 原始映射将重铸为F(x) + x。 我们假设与优化原始,未引用的映射相比,更容易优化残留映射。 极端地,如果identity特征映射是最佳的,则将残差推为零比通过用一叠非线性层拟合特征映射要容易。
针对上述构想,作者团队在ImageNet上做了全面实验并证明:
- 1.随着网络层数的增加,普通网络结构的训练误差相比残差网络更高
- 2.深度残差网络可以更容易地通过增加深度来提高网络精度,而且结果比浅层网络好很多。
作者团队在在CIFAR-10数据集成功训练了深度超过100层以上的模型,也得到了同样的结论。并实验了1000层以上模型的训练。在ImageNet的分类数据集上,残差网络在测试集上取得了3.57%的top-5错误率从而获得ILSVRC2015分类挑战赛的冠军,同时152层的网络深度刷新了记录且其参数量比VGGNet还少。
除此之外,通过极深的残差网络,其团队在ILSVRC和COCO 2015中的各项细分比赛中都获得了冠军,如:ImageNet目标检测、定位;COCO目标检测、分割。这些证据表明残差学习的原则是通用的,在多项任务中都有着出色的泛化能力。
2.相关工作
残差表示
主要内容是从图像检索和分类的角度,残差矢量计算的对比和优化,从理论上给出证据表面残差方案使得训练时的模型收敛速度加快。以下是原论文翻译:
在图像识别中,VLAD [18]是通过相对于字典的残差矢量进行编码的表示,Fisher Vector [30]可以表示为VLAD的概率版本[18]。 它们都是用于图像检索和分类的有效的浅层表示[4,48]。 对于向量量化,编码残差向量[17]比编码原始向量更有效。在低级视觉和计算机图形学中,为求解偏微分方程(PDE),广泛使用的Multigrid方法[3]将系统引申出多个规模的子问题,其中每个子问题负责在较粗和较精scale之间的残差解决方案。 Multigrid的替代方法是以分层为基础的预处理[45,46],它依赖于代表两种scale之间的残差向量的变量。 已经证明[3、45、46],这些方案的收敛速度比那些对残差本质尚未涉及的标准方案快得多。 这些方法表明,良好的重构或预处理可以简化优化过程。
shortcut连接
这一小节主要是进行了shortcut理论和实践的溯源,还有同highway network中shortcut功能区别的对比。以下部分是原论文翻译:
关于shortcut连接的实践和理论[2,34,49]已有很长时间的研究。 训练多层感知器(MLP)的早期实践是添加从网络输入连接到输出的线性层(如:Pattern recognition and neural networks. Cambridgeuniversity press, 1996)。 在GoogLeNet等网络中,一些中间层直接连接到辅助分类器,以解决消失/爆炸梯度。 文献[39,38,31,47]提出了通过shortcut连接实现对层响应,梯度和传播误差进行居中的方法。 在GoogLeNet中,“Inception”层由shortcut分支和一些更深的分支组成。
与我们同期的工作,“highway networks” [42、43]中,shortcut连接作为门功能[15]而呈现。这些门(gates)是带参的且依赖数据的,正与我们shortcut带参且有恒等性相反。当shortcut门“关闭”时(接近0),highway networks中的层表现出非残差功能;相反我们的表达式却永远在进行残差的学习。我们的shortcut永远不会关闭,所有信息始终通过其传递,同时残差函数也始终在进行学习。此外,highway networks并没有证明,随着深度增加,准确性有了明显提升。
3.深度残差学习
3.2 shortcut恒等映射
在残差网络中,对每一个堆叠层都采用残差学习,一个堆叠层形如图2所示的一个残差块。
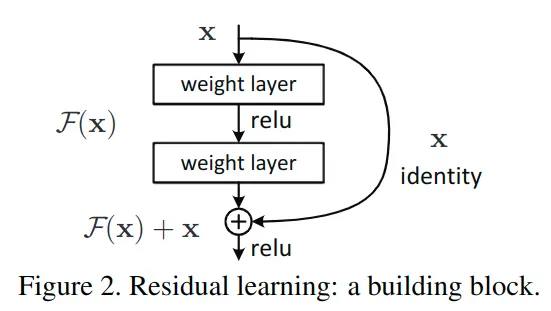
这里x和y分别为输入输出;即代表需要进行残差学习的函数。以图2展示的残差块为例,残差函数可以表示为:(激活函数为ReLU,且省略了bias)作者指出,这个公式并没有引入额外参数,也没有增加计算复杂度。
x和F(x)计算时尺寸必须相等,为此我们可以在必要时通过矩阵Ws来改变输入x的维度:
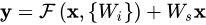
在残差块中堆叠的layer数量至少为2,因为如果只增加了1层,整个表达式便退化成了线性方程,而这就失去作用了。为了简单起见,表达式看上去只适合全连接层,其实可也以表示卷积层,F(x,{Wi})可以表示多个卷积层。在两个feature maps之间,元素之间的相加是在通道维上逐个进行的。
3.3 网络结构
作者及其团队已经测试过各种普通/残差网络,并观测到一致的现象,这里仅举ImageNet中的两个模型作为说明。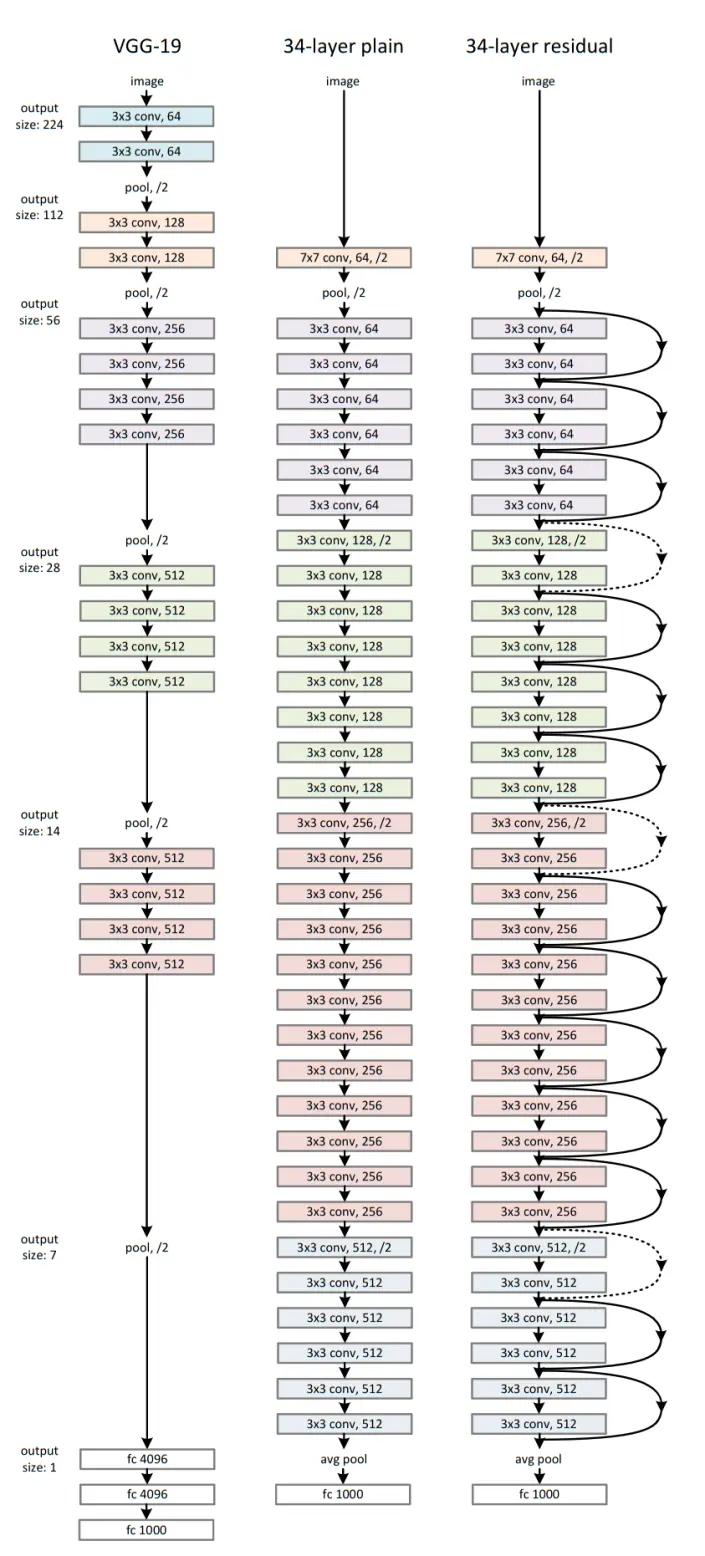
普通网络
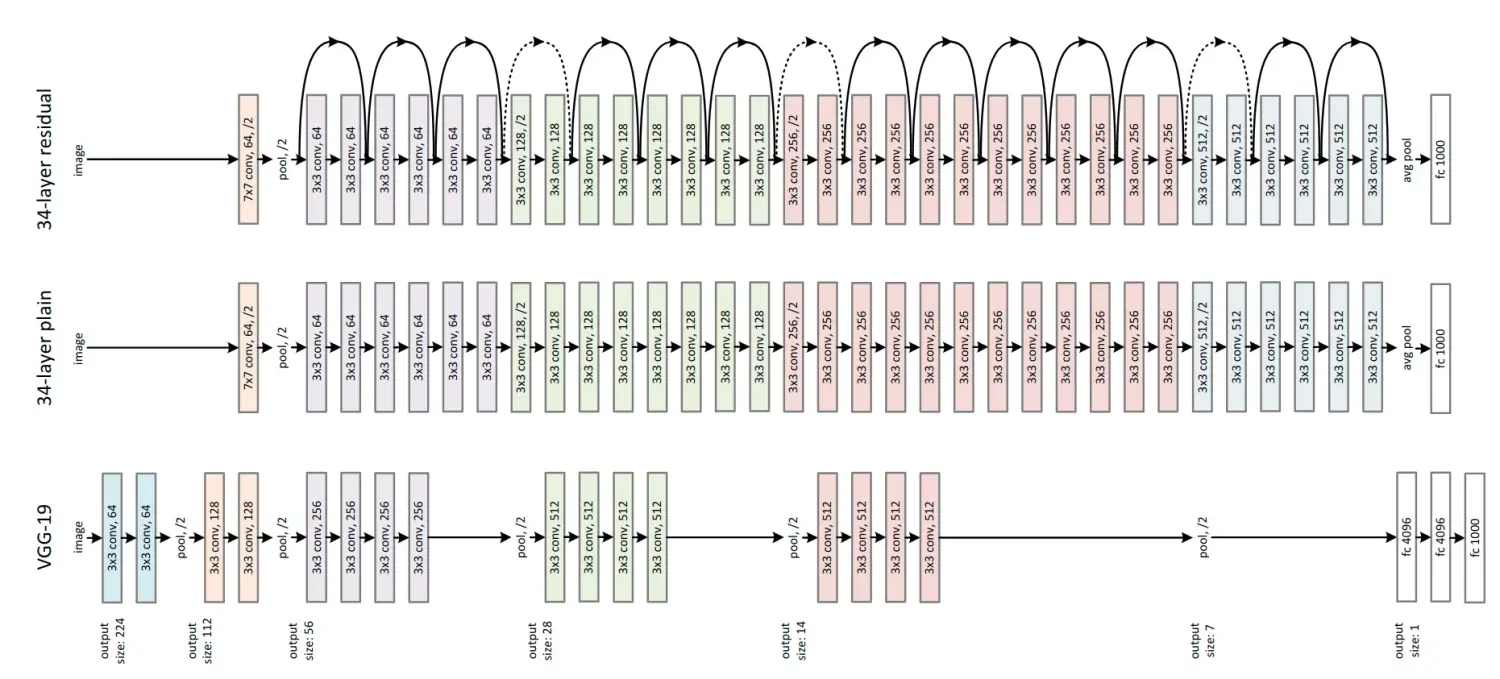
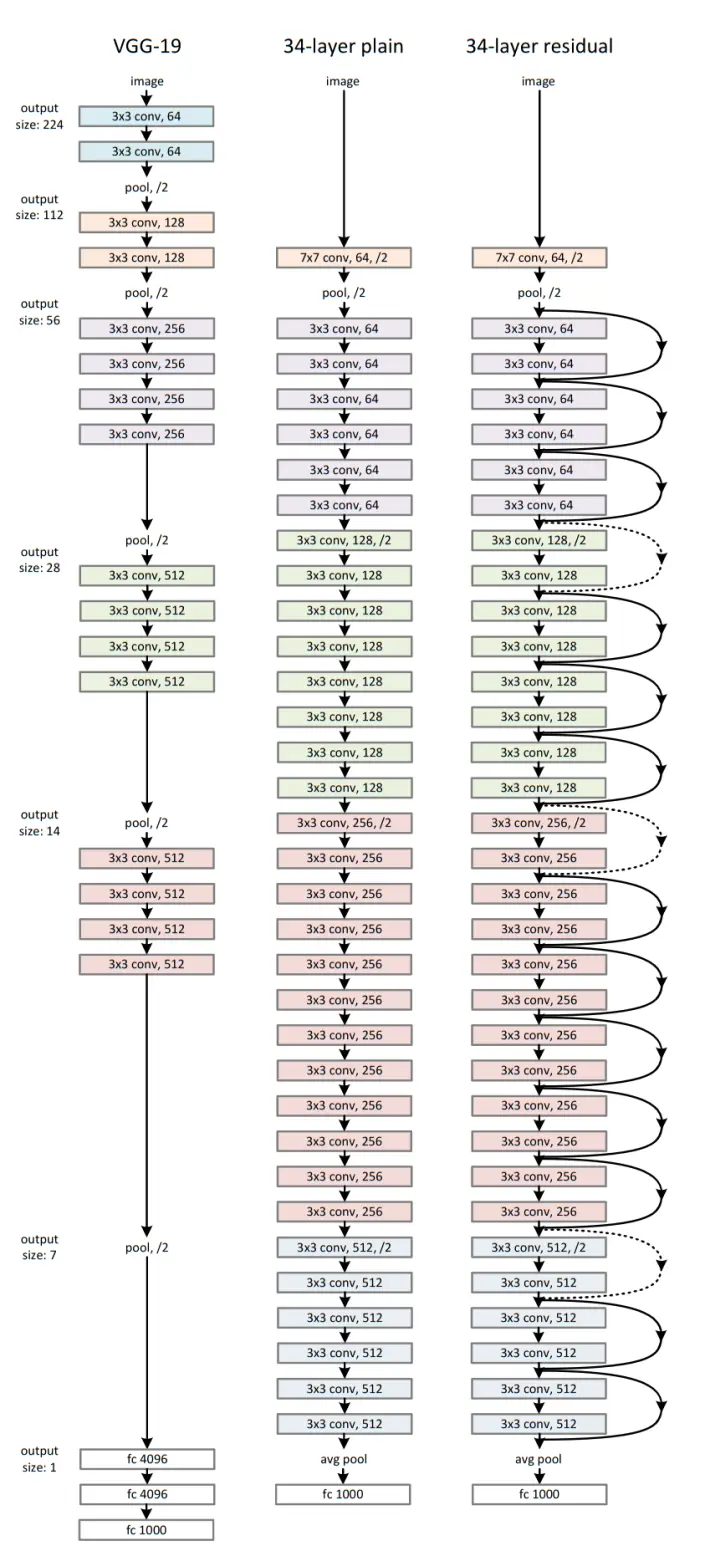
上图中间的是34层的基准普通网络,包含34个带权层(conv+fc)。其设计参考了VGG-19,卷积层的filter尺寸多为3×3,并遵循两个设计原则:1.如果输出的特征图尺寸减半,则filter数量加倍 2.如果输出的特征图尺寸不变,filter数量也不变。stride保持为2,网络结束之前会经过全局平均池化层,再连接一个1000路的softmax分类。
论文指出残差网络比VGG网络有着更少的过滤器和更低的复杂度,34层的基准网络有36亿个FLOP(乘加),而VGG-19有196亿个FLOP,仅占其18%。
残差网络
上图最右边是在中间普通网络基础上,增加了shortcut,使其变为了残差网络。这里有两种shortcut,实线shortcut和虚线shortcut(投影projection)。当输入和输出维度相同时,使用实线shortcut,当维度增加时使用虚线shortcut。当维度改变使用虚线shortcut时,我们为了匹配维度有2种做法:
- (A) shortcut任执行恒等映射,增加额外的0项来增加维度
- (B)使用等式
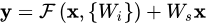
中的方式,通过1×1卷积来改变维度
3.4 实现
对ImageNet的残差网络实现参照了VGGNet及其在ImageNet中的实现。
图像resize,并水平翻转,随机剪裁减去RGB均值像素,颜色增强等处理;
BN批量正则化;
batch size设为256;
随机梯度下降SGD;
初始学习率为0.1当loss稳定后除以10;
weight decay设为0.0001;
动量0.9;
值得注意的是,在该实现中并没有使用Dropout方法。
4.实验
4.1 ImageNet分类
作者在ImageNet2012分类数据集评估了残差网络,128万张训练图,5万张验证图,1000个分类,在测试服务器上通过10万张测试图评估得到了top-1和top-5错误率。
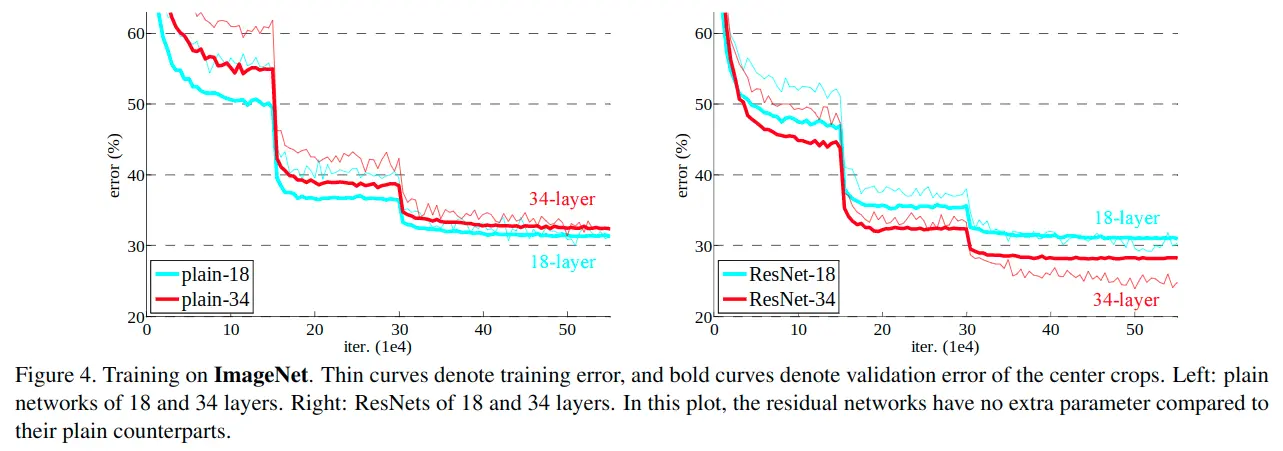
普通网络
上图左边可看出,在普通网络的对比中,34层的比18层误差大,存在模型退化现象。
残差网络
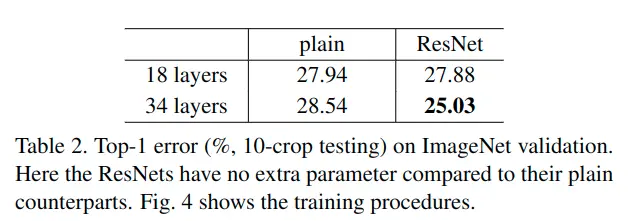
通过对比左右两幅图+table2可以发现:当模型深度不是很深时(18)层,普通网络和ResNet网络的准确率差不多,表示通过一些初始化和正则化方法,可以降低普通卷积神经网络的过拟合;但当层数不断加深,就不可避免地出现模型退化现象,而此时ResNet可以在此情况下很好地解决退化问题。
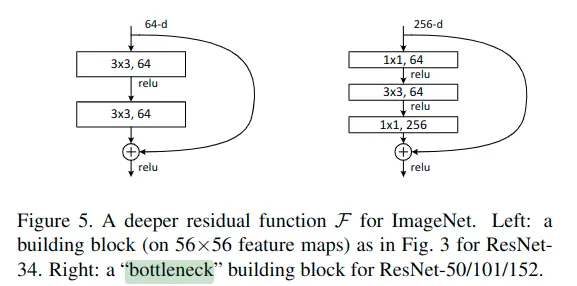
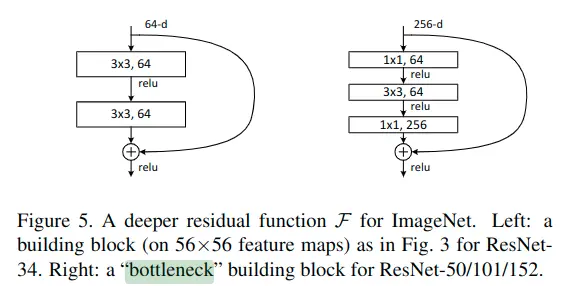
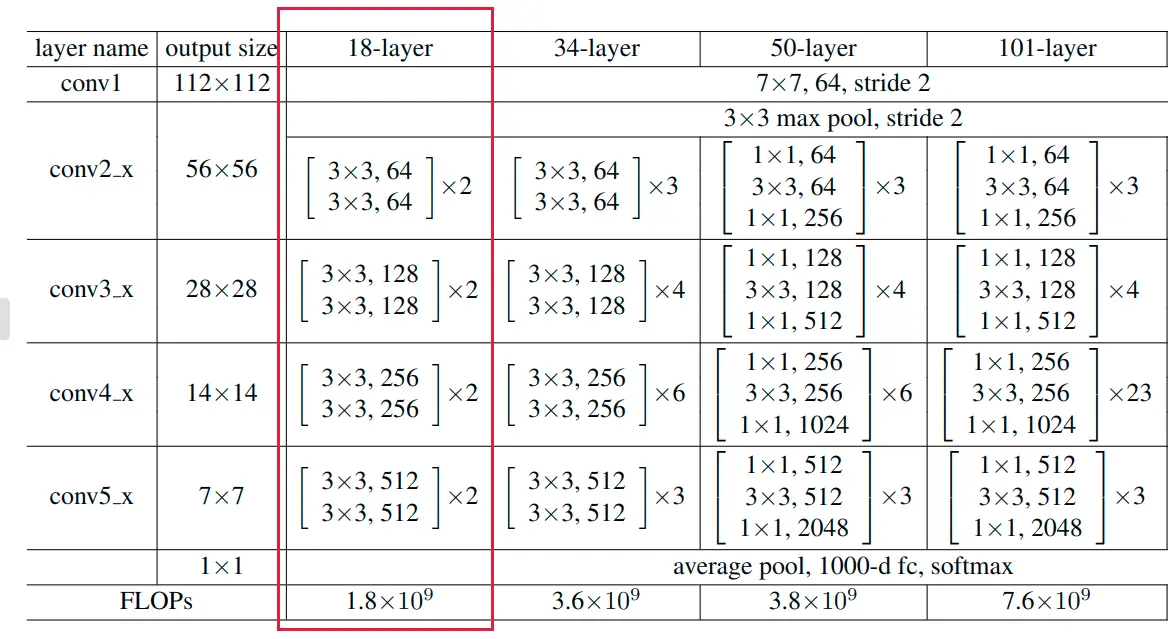
作者团队不仅实验了34层的ResNet更实验了多种残差块,多种深度的残差网络,结构如下:
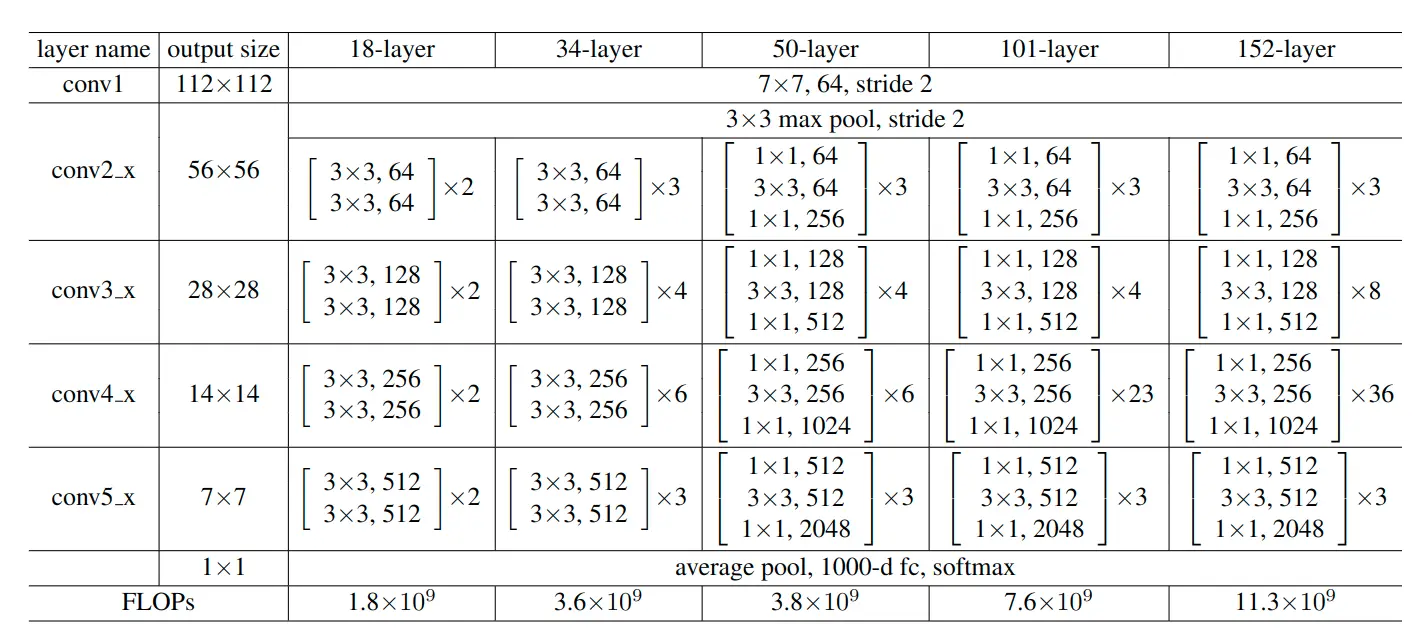
其中,以50层layer中的残差块为例,由于其输入输出尺寸不同,需要1×1卷积进行维度转换,这种残差block表现出上窄下宽的形状,被称为“瓶颈”残差块。具体如下图:
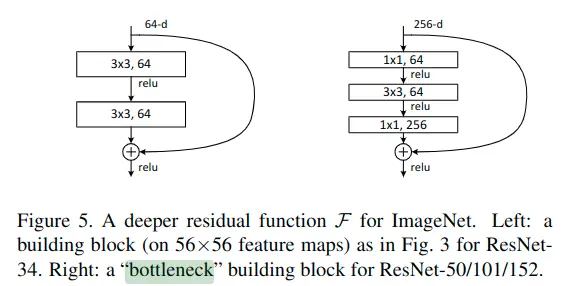
不同深度ResNet的对比
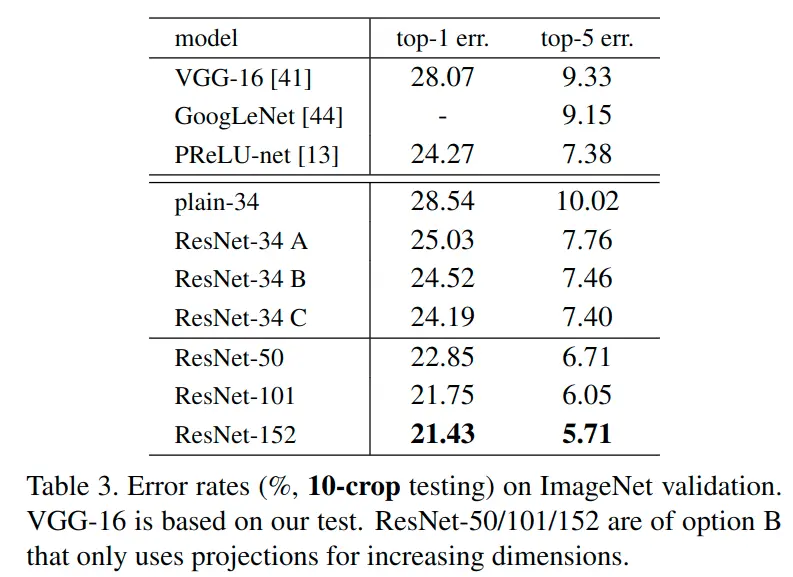
可以看见,在ResNet网络中,并没有看到模型退化的现象,反而随着layer深度加深,网络的精度越高。
各种经典网络对比
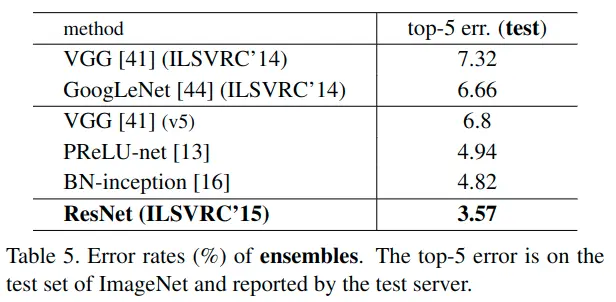
5.代码实现
这里使用tensorflow2.0实现ResNet-18网络结构,完整训练可参考:残差网络(ResNet)。我们先看一下ResNet-18的网络结构:
ResNet的前两层跟之前介绍的GoogLeNet中的一样:在输出通道数为64、步幅为2的7×7卷积层后接步幅为2的3×3的最大池化层。不同之处在于ResNet每个卷积层后增加的批量归一化层。然后接了4种类型的共计8个残差块,每种类型的2个残差块形成一个堆叠。最后加了全局平均池化和1000路的softmax输出。
5.1定义残差块
残差块沿用了VGG的3×3的卷积核尺寸,且有两种结构:初入 = 输出;输入!=输出。针对输入和输出shape不一样的情况,需要增加一个1×1卷积变换维度。残差块内的卷积层经过卷积后接BN批量归一化层,然后经过ReLU激活。
定义残差块实现类Residual:
import tensorflow as tf
from tensorflow.keras import layers,activations
class Residual(tf.keras.Model):
def __init__(self, num_channels, use_1x1conv=False, strides=1, **kwargs):
super(Residual, self).__init__(**kwargs)
self.conv1 = layers.Conv2D(num_channels,
padding='same',
kernel_size=3,
strides=strides)
self.conv2 = layers.Conv2D(num_channels, kernel_size=3,padding='same')
# 如果需要变换维度,则增加1×1卷积层
if use_1x1conv:
self.conv3 = layers.Conv2D(num_channels,
kernel_size=1,
strides=strides)
else:
self.conv3 = None
self.bn1 = layers.BatchNormalization()
self.bn2 = layers.BatchNormalization()
def call(self, X):
Y = activations.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return activations.relu(Y + X)
5.2定义残差块stack
ResNet-18总计4个残差块stack,每个stack包含两个残差块。下面定义残差块stack
class ResnetBlock(tf.keras.layers.Layer):
def __init__(self,num_channels, num_residuals, first_block=False,**kwargs):
super(ResnetBlock, self).__init__(**kwargs)
self.listLayers=[]
for i in range(num_residuals):
if i == 0 and not first_block:
self.listLayers.append(Residual(num_channels, use_1x1conv=True, strides=2))
else:
self.listLayers.append(Residual(num_channels))
def call(self, X):
for layer in self.listLayers.layers:
X = layer(X)
return X
5.3定义ResNet
class ResNet(tf.keras.Model):
def __init__(self,num_blocks,**kwargs):
super(ResNet, self).__init__(**kwargs)
self.conv=layers.Conv2D(64, kernel_size=7, strides=2, padding='same')
self.bn=layers.BatchNormalization()
self.relu=layers.Activation('relu')
self.mp=layers.MaxPool2D(pool_size=3, strides=2, padding='same')
self.resnet_block1=ResnetBlock(64,num_blocks[0], first_block=True)
self.resnet_block2=ResnetBlock(128,num_blocks[1])
self.resnet_block3=ResnetBlock(256,num_blocks[2])
self.resnet_block4=ResnetBlock(512,num_blocks[3])
self.gap=layers.GlobalAvgPool2D()
self.fc=layers.Dense(units=1000,activation=tf.keras.activations.softmax)
def call(self, x):
x=self.conv(x)
x=self.bn(x)
x=self.relu(x)
x=self.mp(x)
x=self.resnet_block1(x)
x=self.resnet_block2(x)
x=self.resnet_block3(x)
x=self.resnet_block4(x)
x=self.gap(x)
x=self.fc(x)
return x
mynet=ResNet([2,2,2,2])
# 观察ResNet网络的输出
X = tf.random.uniform(shape=(1, 224, 224 , 3))
for layer in mynet.layers:
X = layer(X)
print(layer.name, 'output shape:\t', X.shape)
输出:
conv2d output shape: (1, 112, 112, 64)
batch_normalization output shape: (1, 112, 112, 64)
activation output shape: (1, 112, 112, 64)
max_pooling2d output shape: (1, 56, 56, 64)
resnet_block output shape: (1, 56, 56, 64)
resnet_block_1 output shape: (1, 28, 28, 128)
resnet_block_2 output shape: (1, 14, 14, 256)
resnet_block_3 output shape: (1, 7, 7, 512)
global_average_pooling2d output shape: (1, 512)
dense output shape: (1, 1000)
6.总结
残差网络的出现使人们摆脱了【深度】的束缚,大幅改善了深度神经网络中的模型退化问题,使网络层数从数十层跃升至几百上千层,大幅提高了模型精度,通用性强适合各种类型的数据集和任务。残差块和shortcut这种优秀的设计也极大影响了后面的网络结构发展。
智能推荐
分布式光纤传感器的全球与中国市场2022-2028年:技术、参与者、趋势、市场规模及占有率研究报告_预计2026年中国分布式传感器市场规模有多大-程序员宅基地
文章浏览阅读3.2k次。本文研究全球与中国市场分布式光纤传感器的发展现状及未来发展趋势,分别从生产和消费的角度分析分布式光纤传感器的主要生产地区、主要消费地区以及主要的生产商。重点分析全球与中国市场的主要厂商产品特点、产品规格、不同规格产品的价格、产量、产值及全球和中国市场主要生产商的市场份额。主要生产商包括:FISO TechnologiesBrugg KabelSensor HighwayOmnisensAFL GlobalQinetiQ GroupLockheed MartinOSENSA Innovati_预计2026年中国分布式传感器市场规模有多大
07_08 常用组合逻辑电路结构——为IC设计的延时估计铺垫_基4布斯算法代码-程序员宅基地
文章浏览阅读1.1k次,点赞2次,收藏12次。常用组合逻辑电路结构——为IC设计的延时估计铺垫学习目的:估计模块间的delay,确保写的代码的timing 综合能给到多少HZ,以满足需求!_基4布斯算法代码
OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版-程序员宅基地
文章浏览阅读3.3k次,点赞3次,收藏5次。OpenAI Manager助手(基于SpringBoot和Vue)_chatgpt网页版
关于美国计算机奥赛USACO,你想知道的都在这_usaco可以多次提交吗-程序员宅基地
文章浏览阅读2.2k次。USACO自1992年举办,到目前为止已经举办了27届,目的是为了帮助美国信息学国家队选拔IOI的队员,目前逐渐发展为全球热门的线上赛事,成为美国大学申请条件下,含金量相当高的官方竞赛。USACO的比赛成绩可以助力计算机专业留学,越来越多的学生进入了康奈尔,麻省理工,普林斯顿,哈佛和耶鲁等大学,这些同学的共同点是他们都参加了美国计算机科学竞赛(USACO),并且取得过非常好的成绩。适合参赛人群USACO适合国内在读学生有意向申请美国大学的或者想锻炼自己编程能力的同学,高三学生也可以参加12月的第_usaco可以多次提交吗
MySQL存储过程和自定义函数_mysql自定义函数和存储过程-程序员宅基地
文章浏览阅读394次。1.1 存储程序1.2 创建存储过程1.3 创建自定义函数1.3.1 示例1.4 自定义函数和存储过程的区别1.5 变量的使用1.6 定义条件和处理程序1.6.1 定义条件1.6.1.1 示例1.6.2 定义处理程序1.6.2.1 示例1.7 光标的使用1.7.1 声明光标1.7.2 打开光标1.7.3 使用光标1.7.4 关闭光标1.8 流程控制的使用1.8.1 IF语句1.8.2 CASE语句1.8.3 LOOP语句1.8.4 LEAVE语句1.8.5 ITERATE语句1.8.6 REPEAT语句。_mysql自定义函数和存储过程
半导体基础知识与PN结_本征半导体电流为0-程序员宅基地
文章浏览阅读188次。半导体二极管——集成电路最小组成单元。_本征半导体电流为0
随便推点
【Unity3d Shader】水面和岩浆效果_unity 岩浆shader-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏18次。游戏水面特效实现方式太多。咱们这边介绍的是一最简单的UV动画(无顶点位移),整个mesh由4个顶点构成。实现了水面效果(左图),不动代码稍微修改下参数和贴图可以实现岩浆效果(右图)。有要思路是1,uv按时间去做正弦波移动2,在1的基础上加个凹凸图混合uv3,在1、2的基础上加个水流方向4,加上对雾效的支持,如没必要请自行删除雾效代码(把包含fog的几行代码删除)S..._unity 岩浆shader
广义线性模型——Logistic回归模型(1)_广义线性回归模型-程序员宅基地
文章浏览阅读5k次。广义线性模型是线性模型的扩展,它通过连接函数建立响应变量的数学期望值与线性组合的预测变量之间的关系。广义线性模型拟合的形式为:其中g(μY)是条件均值的函数(称为连接函数)。另外,你可放松Y为正态分布的假设,改为Y 服从指数分布族中的一种分布即可。设定好连接函数和概率分布后,便可以通过最大似然估计的多次迭代推导出各参数值。在大部分情况下,线性模型就可以通过一系列连续型或类别型预测变量来预测正态分布的响应变量的工作。但是,有时候我们要进行非正态因变量的分析,例如:(1)类别型.._广义线性回归模型
HTML+CSS大作业 环境网页设计与实现(垃圾分类) web前端开发技术 web课程设计 网页规划与设计_垃圾分类网页设计目标怎么写-程序员宅基地
文章浏览阅读69次。环境保护、 保护地球、 校园环保、垃圾分类、绿色家园、等网站的设计与制作。 总结了一些学生网页制作的经验:一般的网页需要融入以下知识点:div+css布局、浮动、定位、高级css、表格、表单及验证、js轮播图、音频 视频 Flash的应用、ul li、下拉导航栏、鼠标划过效果等知识点,网页的风格主题也很全面:如爱好、风景、校园、美食、动漫、游戏、咖啡、音乐、家乡、电影、名人、商城以及个人主页等主题,学生、新手可参考下方页面的布局和设计和HTML源码(有用点赞△) 一套A+的网_垃圾分类网页设计目标怎么写
C# .Net 发布后,把dll全部放在一个文件夹中,让软件目录更整洁_.net dll 全局目录-程序员宅基地
文章浏览阅读614次,点赞7次,收藏11次。之前找到一个修改 exe 中 DLL地址 的方法, 不太好使,虽然能正确启动, 但无法改变 exe 的工作目录,这就影响了.Net 中很多获取 exe 执行目录来拼接的地址 ( 相对路径 ),比如 wwwroot 和 代码中相对目录还有一些复制到目录的普通文件 等等,它们的地址都会指向原来 exe 的目录, 而不是自定义的 “lib” 目录,根本原因就是没有修改 exe 的工作目录这次来搞一个启动程序,把 .net 的所有东西都放在一个文件夹,在文件夹同级的目录制作一个 exe._.net dll 全局目录
BRIEF特征点描述算法_breif description calculation 特征点-程序员宅基地
文章浏览阅读1.5k次。本文为转载,原博客地址:http://blog.csdn.net/hujingshuang/article/details/46910259简介 BRIEF是2010年的一篇名为《BRIEF:Binary Robust Independent Elementary Features》的文章中提出,BRIEF是对已检测到的特征点进行描述,它是一种二进制编码的描述子,摈弃了利用区域灰度..._breif description calculation 特征点
房屋租赁管理系统的设计和实现,SpringBoot计算机毕业设计论文_基于spring boot的房屋租赁系统论文-程序员宅基地
文章浏览阅读4.1k次,点赞21次,收藏79次。本文是《基于SpringBoot的房屋租赁管理系统》的配套原创说明文档,可以给应届毕业生提供格式撰写参考,也可以给开发类似系统的朋友们提供功能业务设计思路。_基于spring boot的房屋租赁系统论文