ZooKeeper实际应用案例-开发实战_zookeeper实战-程序员宅基地
技术标签: 项目应用 java zookeeper 代码 原创ZooKeeper轻松学系列教程 案例
博主:爱码叔
个人博客站点: icodebook
公众号:爱码叔漫画软件设计(搜:爱码叔)
专注于软件设计与架构、技术管理。擅长用通俗易懂的语言讲解技术。对技术管理工作有自己的一定见解。文章会第一时间首发在个站上,欢迎大家关注访问!
本原创入门教程,涵盖ZooKeeper核心内容,通过实例和大量图表,结合实战,帮助学习者理解和运用,任何问题欢迎留言。
欢迎在我个人网站查看全集《ZooKeeper入门实战教程》
目录:
前面几章,我们学习了zookeeper的概念和使用,并且分析了curator通过zookeeper实现分布式锁的源代码,我们已经熟知zookeeper协调分布式系统的方式,相信大家一定会思考自己的项目场景中是否有zookeeper的用武之地。没错,我们学习的最终目的是要去应用它。本章,我通过实际工作中的一个例子,讲解zookeeper是如何帮我解决分布式问题,以此引导大家发现自己系统中可以应用zookeeper的场景。真正把zookeeper使用起来!
--------------------------------------------------------------------------------------------------
项目背景介绍
首先给大家介绍一下本文描述项目的情况。这是一个检索网站,它让你能在几千万份复杂文档数据中检索出你所需要的文档数据。为了加快检索速度,项目的数据分布在100台机器的内存里,我们称之为数据服务器。除了数据,这100台机器上均部署着检索程序。这些server之外,还有数台给前端提供接口的搜索server,这些机器属一个集群,我们称之为检索服务器。当搜索请求过来时,他们负责把搜索请求转发到那100台机器,待所有机器返回结果后进行合并,最终返回给前端页面。结构如下图:

面临问题
网站上线之初,由于数据只有几百万,所以数据服务器只有10多台。是一个规模比较小的分布式系统,当时没有做分布式系统的协调,也能正常工作,偶尔出问题,马上解决。但是到了近期,机器增长到100台,网站几乎每天都会出现问题,导致整个分布式系统挂掉。问题原因如下:
数据服务器之前没有做分布式协调。对于检索服务器来说,并不知道哪些数据服务器还存活,所以检索服务器每次检索,都会等待100台机器返回结果。但假如100台数据服务中某一台死掉了,检索服务器也会长时间等待他的返回。这导致了检索服务器积累了大量的请求,最终被压垮。当所有的检索服务器都被压垮时,那么网站也就彻底不可用了。

问题的本质为检索服务器维护的数据服务器列表是静态不变的,不能感知数据服务器的上下线。
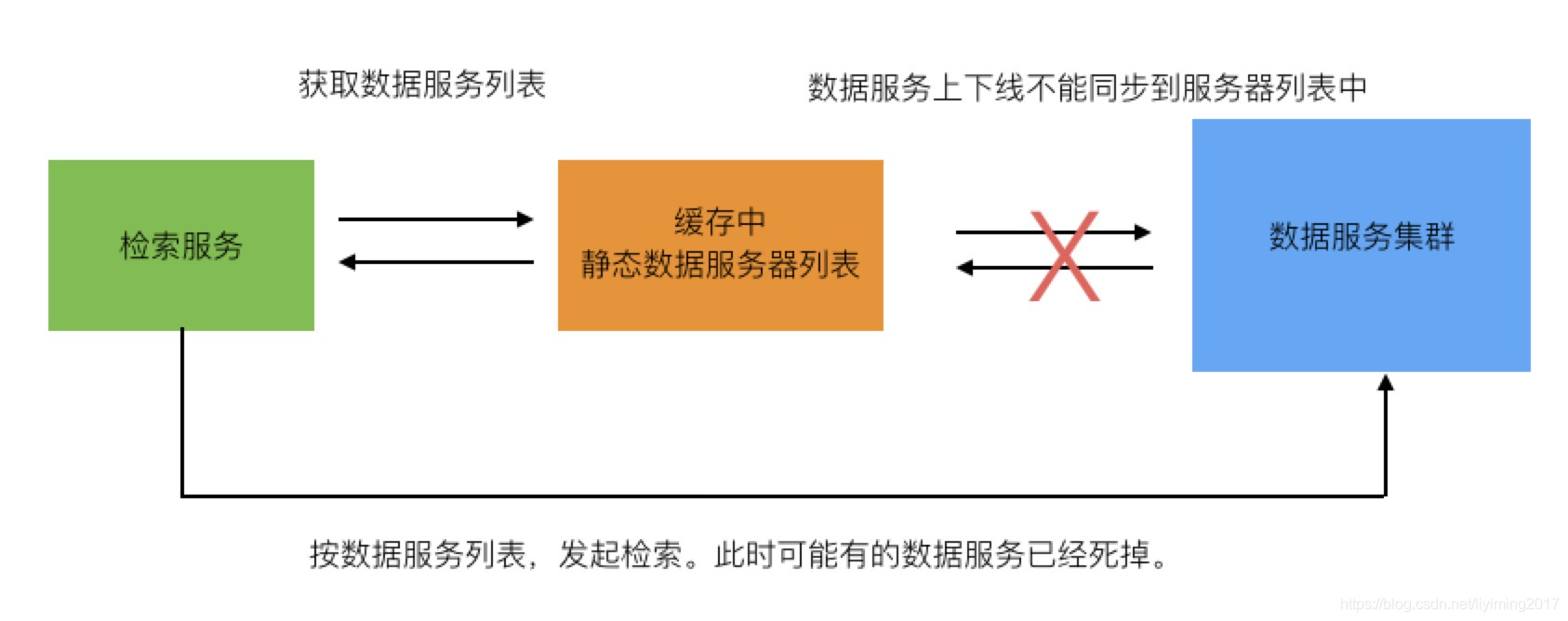
在10台数据服务器的时候,某一台机器出问题的概率很小。但当增长到100台服务器时,出问题的概率变成了10倍。所以才会导致网站几乎每天都要死掉一次。
由于一台机器的问题,导致100台机器的分布式系统不可用,这是极其不合理,也是无法忍受的。
之前此项目的数据和检索不由我负责。了解到此问题的时候,我觉得这个问题得立刻解决,否则不但用户体验差,而且开发和运维也要每天疲于系统维护,浪费了大量资源,但由于还有很多新的需求在开发,原来的团队也没时间去处理。今年我有机会来解决这个问题,当时正好刚刚研究完zookeeper,立刻想到这正是采用zookeeper的典型场景。
如何解决
我直接说方案,程序分为数据服务器和检索服务器两部分。
数据服务器:
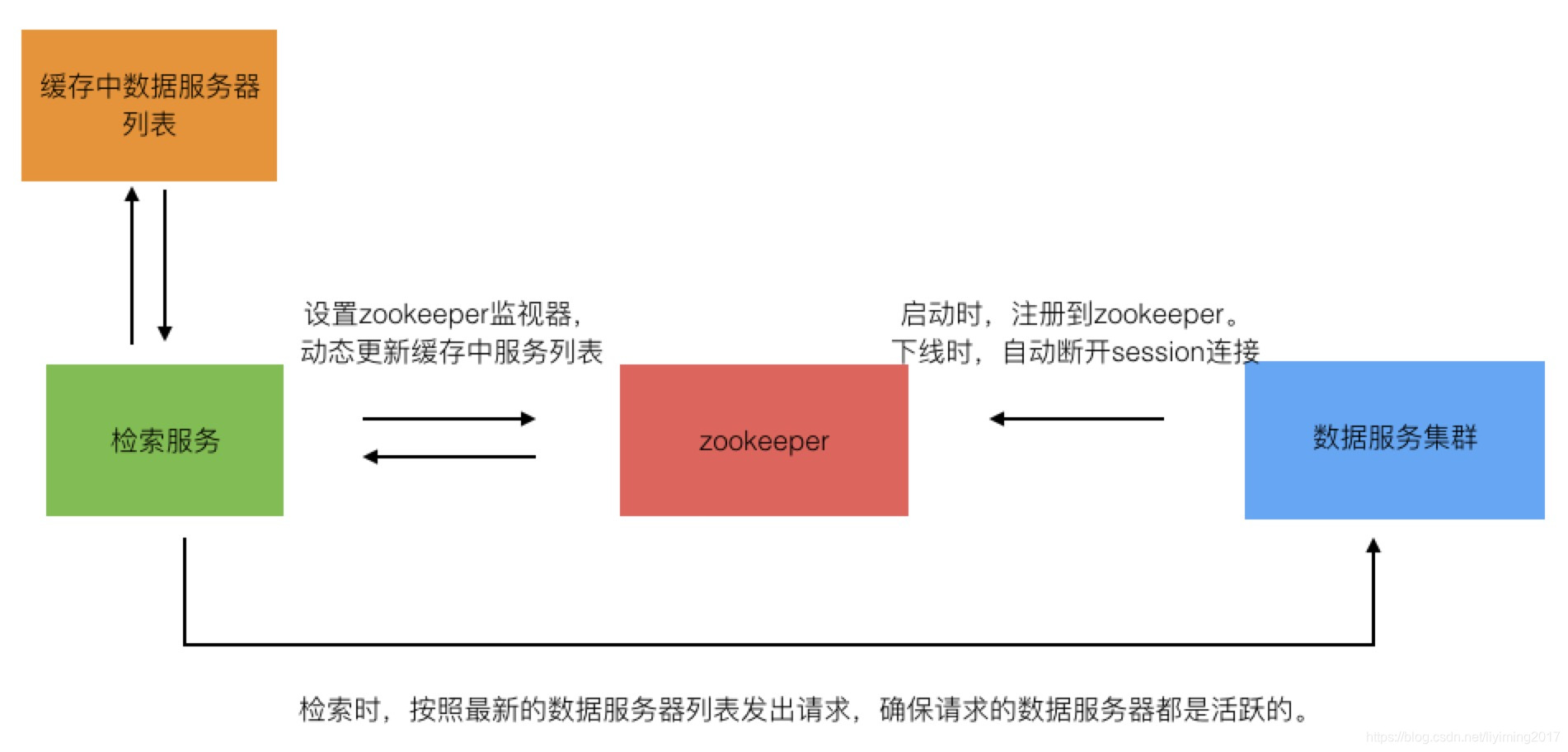
1、每台数据服务器启动时候以临时节点的形式把自己注册到zookeeper的某节点下,如/data_servers。这样当某数据服务器死掉时,session断开链接,该节点被删除。
检索服务器:
1、启动时,加载/data_servers下所有子节点数据,获取了目前所有能提供服务的数据服务器列表,并且加载到内存中。
2、启动时,同时监听/data_servers节点,当新的数据server上线或者某个server下线时,获得通知,然后重新加载/data_servers下所有子节点数据,刷新内存中数据服务器列表。
通过以上方案,做到数据服务器上下线时,检索服务器能够动态感知。检索服务器在检索前,从内存中取得的数据服务器列表将是最新的、可用的。即使在刷新时间差内取到了掉线的数据服务器也没关系,最多影响本次查询,而不会拖垮整个集群。见下图:
代码讲解
捋清思路后,其实代码就比较简单了。数据服务器只需要启动的时候写zookeeper临时节点就好了,同时写入自己服务器的相关信息,比如ip、port之类。检索无服务器端会稍微复杂点,不过此处场景和zookeeper官方给的例子十分符合,所以我直接参考官方例子进行修改,实现起来也很简单。关于官方例子我写过两篇博文,可以参考学习:
- zookeeper官方例子翻译:ZooKeeper官方文档-Java客户端开发例子翻译_爱码叔(稀有气体)的博客-程序员宅基地
- zookeeper官方例子解读:ZooKeeper官方Java例子解读_爱码叔(稀有气体)的博客-程序员宅基地
数据服务器
数据服务器程序十分简单,只会做一件事情:启动的时候,把自己以临时节点的形式注册到zookeeper。一旦服务器挂掉,zookeeper自动删除临时znode。
我们创建ServiceRegister.java实现Runnable,数据服务启动的时候,单独线程运行此代码,实现注册到zookeeper逻辑。维系和zookeeper的链接。
检索服务器
检索服务器,代码设计完全采用官方案例,所以详细的代码解读请参考上面提到的两篇文章,这里只做下简述。
代码有两个类DataMonitor和LoadSaidsExecutor。LoadSaidsExecutor是启动入口,他来启动DataMonitor监控zookeeper节点变化。DataMonitor负责监控,初次启动和发现变化时,调用LoadSaidsExecutor的方法来加载最新的数据服务器列表信息。
DataMonitor和LoadSaidsExecutor的工作流程如下:
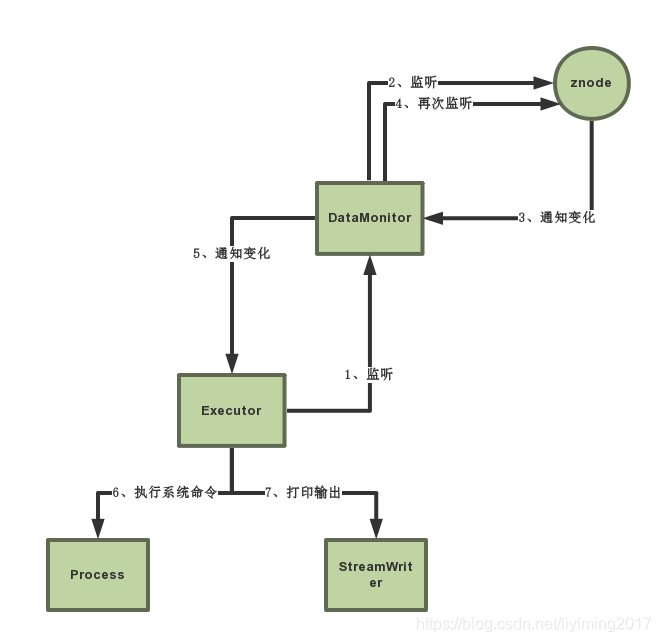
- Excutor把自己注册为DataMonitor的监听
- DataMonitor实现watcher接口,并监听znode
- znode变化时,触发DataMonitor的监听回调
- 回调中通过ZooKeeper.exist() 再次监听znode
- 上一步exist的回调方法中,调用监听自己的Executor,执行业务逻辑6
- Executor启新的线程加载数据服务器信息到内存中
注意:图为以前文章配图。图里应该把6,7步改为文字描述的第6步。
检索服务启动的时候,单独线程运行LoadSaIdsExecutor。LoadSaIdsExecutor会阻塞线程,转为事件驱动。
总结
我们通过一个例子,展示了zookeeper在实际系统中的应用,通过zookeeper解决了分布式系统的问题。其实以上代码还有很大的优化空间。我能想到如下两点:
1、数据服务器会假死或者变慢,但和zk链接还在,并不会从zk中删除,但已经拖慢了集群的速度。解决此问题,我们可以在数据服务器中加入定时任务,通过定时跑真实业务查询,监控服务器状态,一旦达到设定的红线阈值,强制下线,而不是等到server彻底死掉。
2、检索服务器每个server都监控zookeeper同一个节点,在节点变化时会出现羊群效应。当然,检索服务器如果数量不多还好。其实检索服务器应该通过zookeeper做一个leader选举,只由leader去监控zookeeper节点变化,更新redis中的数据服务器列表缓存即可。
附:完整代码
数据服务端代码
ServiceRegister.java
public class ServiceRegister implements Runnable{
private ZooKeeper zk;
private static final String ZNODE = "/sas";
private static final String SA_NODE_PREFIX = "sa_";
private String hostName="localhost:2181";
public void setHostName(String hostName) {
this.hostName = hostName;
}
public ServiceRegister() throws IOException {
zk = new ZooKeeper(hostName, 10000,null);
}
@Override
public void run() {
try {
createSaNode();
synchronized (this) {
wait();
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//测试用
public static void main(String[] args){
try {
new ServiceRegister().run();
} catch (IOException e) {
e.printStackTrace();
}
}
//创建子节点
private String createSaNode() throws KeeperException, InterruptedException {
// 如果根节点不存在,则创建根节点
Stat stat = zk.exists(ZNODE, false);
if (stat == null) {
zk.create(ZNODE, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
String hostName = System.getenv("HOSTNAME");
// 创建EPHEMERAL_SEQUENTIAL类型节点
String saPath = zk.create(ZNODE + "/" + SA_NODE_PREFIX,
hostName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL);
return saPath;
}
}检索服务端代码
DataMonitor.java
public class DataMonitor implements Watcher, AsyncCallback.ChildrenCallback {
ZooKeeper zk;
String znode;
Watcher chainedWatcher;
boolean dead;
DataMonitorListener listener;
List<String> prevSaIds;
public DataMonitor(ZooKeeper zk, String znode, Watcher chainedWatcher,
DataMonitorListener listener) {
this.zk = zk;
this.znode = znode;
this.chainedWatcher = chainedWatcher;
this.listener = listener;
// 这是整个监控的真正开始,通过获取children节点开始。设置了本对象为监控对象,回调对象也是本对象。以后均是事件驱动。
zk.getChildren(znode, true, this, null);
}
/**
* 其他和monitor产生交互的类,需要实现此listener
*/
public interface DataMonitorListener {
/**
* The existence status of the node has changed.
*/
void changed(List<String> saIds);
/**
* The ZooKeeper session is no longer valid.
*
* @param rc
* the ZooKeeper reason code
*/
void closing(int rc);
}
/*
*监控/saids的回调函数。除了处理异常外。
*如果发生变化,和构造函数中一样,通过getChildren,再次监控,并处理children节点变化后的业务
*/
public void process(WatchedEvent event) {
String path = event.getPath();
if (event.getType() == Event.EventType.None) {
// We are are being told that the state of the
// connection has changed
switch (event.getState()) {
case SyncConnected:
// In this particular example we don't need to do anything
// here - watches are automatically re-registered with
// server and any watches triggered while the client was
// disconnected will be delivered (in order of course)
break;
case Expired:
// It's all over
dead = true;
listener.closing(Code.SESSIONEXPIRED.intValue());
break;
}
} else {
if (path != null && path.equals(znode)) {
// Something has changed on the node, let's find out
zk.getChildren(znode, true, this, null);
}
}
if (chainedWatcher != null) {
chainedWatcher.process(event);
}
}
//拿到Children节点后的回调函数。
@Override
public void processResult(int rc, String path, Object ctx, List<String> children) {
boolean exists;
switch (rc) {
case Code.Ok:
exists = true;
break;
case Code.NoNode:
exists = false;
break;
case Code.SessionExpired:
case Code.NoAuth:
dead = true;
listener.closing(rc);
return;
default:
// Retry errors
zk.getChildren(znode, true, this, null);
return;
}
List<String> saIds = null;
//如果存在,再次查询到最新children,此时仅查询,不要设置监控了
if (exists) {
try {
saIds = zk.getChildren(znode,null);
} catch (KeeperException e) {
// We don't need to worry about recovering now. The watch
// callbacks will kick off any exception handling
e.printStackTrace();
} catch (InterruptedException e) {
return;
}
}
//拿到最新saids后,通过listener(executor),加载Saids。
if ((saIds == null && saIds != prevSaIds)
|| (saIds != null && !saIds.equals(prevSaIds))) {
listener.changed(saIds);
prevSaIds = saIds;
}
}
}LoadSaIdsExecutor.java
public class LoadSaIdsExecutor
implements Watcher, Runnable, DataMonitor.DataMonitorListener
{
private DataMonitor dm;
private ZooKeeper zk;
private static final String znode = "/sas";
private String hostName="localhost:2181";
public void setHostName(String hostName) {
this.hostName = hostName;
}
/*
*初始化zookeeper及DataMonitor
* 自己作为zookeeper的监控者,监控和zookeeper连接的变化
* 自己作为DataMonitor的listener。当dm监控到变化时会调用executor执行业务操作
*/
public LoadSaIdsExecutor() throws KeeperException, IOException {
zk = new ZooKeeper(hostName, 300000, this);
dm = new DataMonitor(zk, znode, null, this);
}
/**
* 入口方法,测试用。
*/
public static void main(String[] args) {
try {
new LoadSaIdsExecutor().run();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 作为单独线程运行
*/
public void run() {
try {
synchronized (this) {
while (!dm.dead) {
wait();
}
}
} catch (InterruptedException e) {
}
}
/*
*作为zookeeper监控者的回调,直接传递事件给monitor的回调函数统一处理
*/
@Override
public void process(WatchedEvent event) {
dm.process(event);
}
/*
*当关闭时,让线程线继续走完
*/
public void closing(int rc) {
synchronized (this) {
notifyAll();
}
}
/*
*监控到/saids变化后的处理类
*/
static class SaIdsLoader extends Thread {
List<String> saIds = null;
//构造对象后直接启动线程
public SaIdsLoader(List<String> saIds){
this.saIds = saIds;
start();
}
public void run() {
System.out.println("------------加载开始------------");
//业务处理的地方
if(saIds!=null){
saIds.forEach(id->{
System.out.println(id);
});
}
System.out.println("------------加载结束------------");
}
}
/*
*作为listener对外暴露的方法,在节点/saids变化时被调用。
*/
@Override
public void changed(List<String> data) {
new SaIdsLoader(data);
}
}智能推荐
2024最新计算机毕业设计选题大全-程序员宅基地
文章浏览阅读1.6k次,点赞12次,收藏7次。大家好!大四的同学们毕业设计即将开始了,你们做好准备了吗?学长给大家精心整理了最新的计算机毕业设计选题,希望能为你们提供帮助。如果在选题过程中有任何疑问,都可以随时问我,我会尽力帮助大家。在选择毕业设计选题时,有几个要点需要考虑。首先,选题应与计算机专业密切相关,并且符合当前行业的发展趋势。选择与专业紧密结合的选题,可以使你们更好地运用所学知识,并为未来的职业发展奠定基础。要考虑选题的实际可行性和创新性。选题应具备一定的实践意义和应用前景,能够解决实际问题或改善现有技术。
dcn网络与公网_电信运营商DCN网络的演变与规划方法(The evolution and plan method of DCN)...-程序员宅基地
文章浏览阅读3.4k次。摘要:随着电信业务的发展和电信企业经营方式的转变,DCN网络的定位发生了重大的演变。本文基于这种变化,重点讨论DCN网络的规划方法和运维管理方法。Digest: With the development oftelecommunication bussiness and the change of management of telecomcarrier , DCN’s role will cha..._电信dcn
动手深度学习矩阵求导_向量变元是什么-程序员宅基地
文章浏览阅读442次。深度学习一部分矩阵求导知识的搬运总结_向量变元是什么
月薪已炒到15w?真心建议大家冲一冲数据新兴领域,人才缺口极大!-程序员宅基地
文章浏览阅读8次。近期,裁员的公司越来越多今天想和大家聊聊职场人的新出路。作为席卷全球的新概念ESG已然成为当前各个行业关注的最热风口目前,国内官方发布了一项ESG新证书含金量五颗星、中文ESG证书、完整ESG考试体系、名师主讲...而ESG又是与人力资源直接相关甚至在行业圈内成为大佬们的热门话题...当前行业下行,裁员的公司也越来越多大家还是冲一冲这个新兴领域01 ESG为什么重要?在双碳的大背景下,ESG已然成...
对比传统运营模式,为什么越拉越多的企业选择上云?_系统上云的前后对比-程序员宅基地
文章浏览阅读356次。云计算快速渗透到众多的行业,使中小企业受益于技术变革。最近微软SMB的一项研究发现,到今年年底,78%的中小企业将以某种方式使用云。企业希望投入少、收益高,来取得更大的发展机会。云计算将中小企业信息化的成本大幅降低,它们不必再建本地互联网基础设施,节省时间和资金,降低了企业经营风险。科技创新已成时代的潮流,中小企业上云是创新前提。云平台稳定、安全、便捷的IT环境,提升企业经营效率的同时,也为企业..._系统上云的前后对比
esxi网卡直通后虚拟机无网_esxi虚拟机无法联网-程序员宅基地
文章浏览阅读899次。出现选网卡的时候无法选中,这里应该是一个bug。3.保存退出,重启虚拟机即可。1.先随便选择一个网卡。2.勾先取消再重新勾选。_esxi虚拟机无法联网
随便推点
在LaTeX中使用.bib文件统一管理参考文献_egbib-程序员宅基地
文章浏览阅读913次。在LaTeX中,可在.tex文件的同一级目录下创建egbib.bib文件,所有的参考文件信息可以统一写在egbib.bib文件中,然后在.tex文件的\end{document}前加入如下几行代码:{\small\bibliographystyle{IEEEtran}\bibliography{egbib}}即可在文章中用~\cite{}宏命令便捷的插入文内引用,且文章的Reference部分会自动排序、编号。..._egbib
Unity Shader - Predefined Shader preprocessor macros 着色器预处理宏-程序员宅基地
文章浏览阅读950次。目录:Unity Shader - 知识点目录(先占位,后续持续更新)原文:Predefined Shader preprocessor macros版本:2019.1Predefined Shader preprocessor macros着色器预处理宏Unity 编译 shader programs 期间的一些预处理宏。(本篇的宏介绍随便看看就好,要想深入了解,还是直接看Unity...
大数据平台,从“治理”数据谈起-程序员宅基地
文章浏览阅读195次。本文目录:一、大数据时代还需要数据治理吗?二、如何面向用户开展大数据治理?三、面向用户的自服务大数据治理架构四、总结一、大数据时代还需要数据治理吗?数据平台发展过程中随处可见的数据问题大数据不是凭空而来,1981年第一个数据仓库诞生,到现在已经有了近40年的历史,相对数据仓库来说我还是个年轻人。而国内企业数据平台的建设大概从90年代末就开始了,从第一代架构出现到..._数据治理从0搭建
大学抢课python脚本_用彪悍的Python写了一个自动选课的脚本 | 学步园-程序员宅基地
文章浏览阅读2.2k次,点赞4次,收藏12次。高手请一笑而过。物理实验课别人已经做过3、4个了,自己一个还没做呢。不是咱不想做,而是咱不想起那么早,并且仅有的一次起得早,但是哈工大的服务器竟然超负荷,不停刷新还是不行,不禁感慨这才是真正的“万马争过独木桥“啊!服务器不给力啊……好了,废话少说。其实,我的想法很简单。写一个三重循环,不停地提交,直到所有的数据都accepted。其中最关键的是提交最后一个页面,因为提交用户名和密码后不需要再访问其..._哈尔滨工业大学抢课脚本
english_html_study english html-程序员宅基地
文章浏览阅读4.9k次。一些别人收集的英文站点 http://www.lifeinchina.cn (nice) http://www.huaren.us/ (nice) http://www.hindu.com (okay) http://www.italki.com www.talkdatalk.com (transfer)http://www.en8848.com.cn/yingyu/index._study english html
Cortex-M3双堆栈MSP和PSP_stm32 msp psp-程序员宅基地
文章浏览阅读5.5k次,点赞19次,收藏78次。什么是栈?在谈M3堆栈之前我们先回忆一下数据结构中的栈。栈是一种先进后出的数据结构(类似于枪支的弹夹,先放入的子弹最后打出,后放入的子弹先打出)。M3内核的堆栈也不例外,也是先进后出的。栈的作用?局部变量内存的开销,函数的调用都离不开栈。了解了栈的概念和基本作用后我们来看M3的双堆栈栈cortex-M3内核使用了双堆栈,即MSP和PSP,这极大的方便了OS的设计。MSP的含义是Main..._stm32 msp psp