大数据离线集群数据迁移实战项目_大数据整体集群迁移-程序员宅基地
有赞大数据离线集群迁移实战
一、背景
有赞是一家商家服务公司,向商家提供强大的基于社交网络的,全渠道经营的 SaaS 系统和一体化新零售解决方案。随着近年来社交电商的火爆,有赞大数据集群一直处于快速增长的状态。在 2019 年下半年,原有云厂商的机房已经不能满足未来几年的持续扩容的需要,同时考虑到提升机器扩容的效率(减少等待机器到位的时间)以及支持弹性伸缩容的能力,我们决定将大数据离线 Hadoop 集群整体迁移到其他云厂商。
在迁移前我们的离线集群规模已经达到 200+ 物理机器,每天 40000+ 调度任务,本次迁移的目标如下:
- 将 Hadoop 上的数据从原有机房在有限时间内全量迁移到新的机房
- 如果全量迁移数据期间有新增或者更新的数据,需要识别出来并增量迁移
- 对迁移前后的数据,要能对比验证一致性(不能出现数据缺失、脏数据等情况)
- 迁移期间(可能持续几个月),保证上层运行任务的成功和结果数据的正确
有赞大数据离线平台技术架构
上文说了 Hadoop 集群迁移的背景和目的,我们回过头来再看下目前有赞大数据离线平台整体的技术架构,如图1.1所示,从低往上看依次包括:
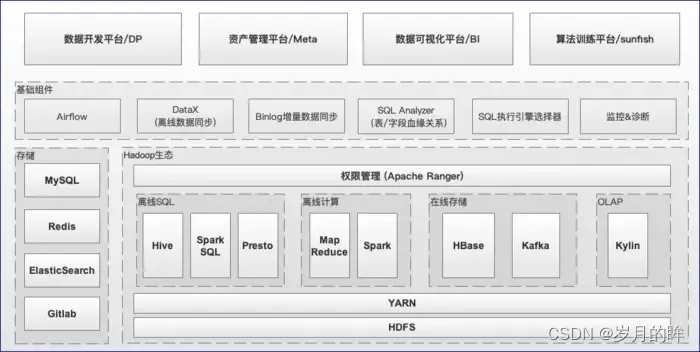
图1.1 有赞大数据离线平台的技术架构
- Hadoop 生态相关基础设施,包括 HDFS、YARN、Spark、Hive、Presto、HBase、Kafka、Kylin等
- 基础组件,包括 Airflow (调度)、DataX (离线数据同步)、基于binlog的增量数据同步、SQL解析/执行引擎选择服务、监控&诊断等
- 平台层面,包括: 数据开发平台(下文简称DP)、资产管理平台、数据可视化平台、算法训练平台等
本次迁移会涉及到从底层基础设施到上层平台各个层面的工作。
二、方案调研
在开始迁移之前,我们调研了业界在迁移 Hadoop 集群时,常用的几种方案:
2.1 单集群
两个机房公用一个 Hadoop 集群(同一个Active NameNode,DataNode节点进行双机房部署),具体来讲有两种实现方式:
- (记为方案A) 新机房DataNode节点逐步扩容,老机房DataNode节点逐步缩容,缩容之后通过 HDFS 原生工具 Balancer 实现 HDFS Block 副本的动态均衡,最后将Active NameNode切换到新机房部署,完成迁移。这种方式最为简单,但是存在跨机房拉取 Shuffle 数据、HDFS 文件读取等导致的专线带宽耗尽的风险,如图2.1所示
- (记为方案B) 方案 A 由于两个机房之间有大量的网络传输,实际跨机房专线带宽较少情况下一般不会采纳,另外一种带宽更加友好的方案是:
- 通过Hadoop 的 Rack Awareness 来实现 HDFS Block N副本双机房按比例分布(通过调整 HDFS 数据块副本放置策略,比如常用3副本,两个机房比例为1:2)
- 通过工具(需要自研)来保证 HDFS Block 副本按比例在两个机房间的分布(思路是:通过 NameNode 拉取 FSImage,读取每个 HDFS Block 副本的机房分布情况,然后在预定限速下,实现副本的均衡)
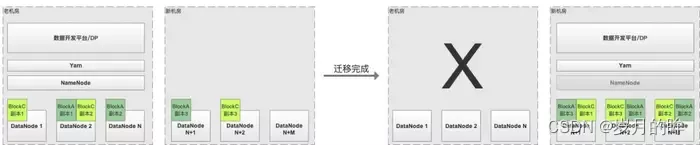
图2.1 单集群迁移方案
优点:
- 对用户透明,基本无需业务方投入
- 数据一致性好
- 相比多集群,机器成本比较低
缺点:
- 需要比较大的跨机房专线带宽,保证每天增量数据的同步和 Shuffle 数据拉取的需要
- 需要改造基础组件(Hadoop/Spark)来支持本机房优先读写、在限速下实现跨机房副本按比例分布等
- 最后在完成迁移之前,需要集中进行 Namenode、ResourceManager 等切换,有变更风险
2.2 多集群
在新机房搭建一套新的 Hadoop 集群,第一次将全量 HDFS 数据通过 Distcp 拷贝到新集群,之后保证增量的数据拷贝直至两边的数据完全一致,完成切换并把老的集群下线,如图2.2所示。
这种场景也有两种不同的实施方式:
- (记为方案C) 两边 HDFS 数据完全一致后,一键全部切换(比如通过在DP上配置改成指向新集群),优点是用户基本无感知,缺点也比较明显,一键迁移的风险极大(怎么保证两边完全一致、怎么快速识别&快速回滚)
- (记为方案D) 按照DP上的任务血缘关系,分层(比如按照数据仓库分层依次迁移 ODS / DW / DM 层数据)、分不同业务线迁移,优点是风险较低(分治)且可控,缺点是用户感知较为明显

图2.2 多集群迁移方案
优点:
- 跨机房专线带宽要求不高(第一次全量同步期间不跑任务,后续增量数据同步,两边双跑任务不存在跨机房 Shuffle 问题)
- 风险可控,可以分阶段(ODS / DW / DM)依次迁移,每个阶段可以验证数据一致性后再开始下一阶段的迁移
- 不需要改造基础组件(Hadoop/Spark)
缺点:
- 对用户不透明,需要业务方配合
- 在平台层需要提供工具,来实现低成本迁移、数据一致性校验等
2.3 方案评估
从用户感知透明度来考虑,我们肯定会优先考虑单集群方案,因为单集群在迁移过程中,能做到基本对用户无感知的状态,但是考虑到如下几个方面的因素,我们最终还是选择了多集群方案:
- (主因)跨机房的专线带宽大小不足。上述单集群的方案 A 在 Shuffle 过程中需要大量的带宽使用;方案 B 虽然带宽更加可控些,但副本跨机房复制还是需要不少带宽,同时前期的基础设施改造成本较大
- (次因)平台上的任务类型众多,之前也没系统性梳理过,透明的一键迁移可能会产生稳定性问题,同时较难做回滚操作
因此我们通过评估,最终采用了方案 D。
三、实施过程
在方案确定后,我们便开始了有条不紊的迁移工作,整体的流程如图3.1所示
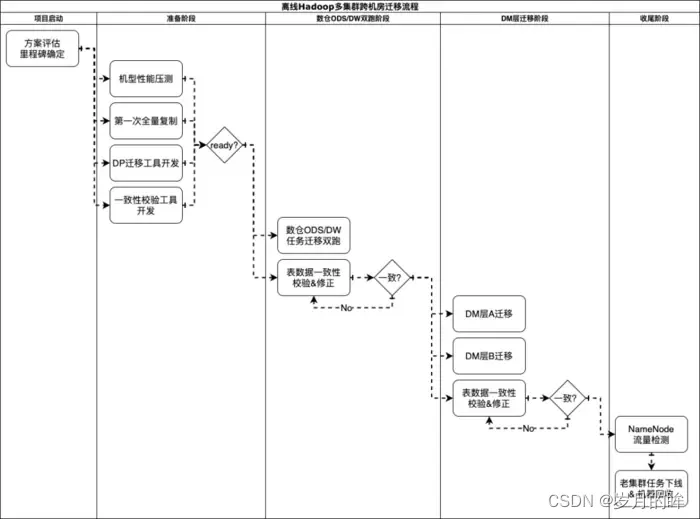
图3.1 离线Hadoop多集群跨机房迁移流程图
上述迁移流程中,核心要解决几个问题:
- 第一次全量Hadoop数据复制到新集群,如何保证过程的可控(有限时间内完成、限速、数据一致、识别更新数据)?(工具保证)
- 离线任务的迁移,如何做到较低的迁移成本,且保障迁移期间任务代码、数据完全一致?(平台保证)
- 完全迁移的条件怎么确定?如何降低整体的风险?(重要考虑点)
3.1 Hadoop 全量数据复制
首先我们在新机房搭建了一套 Hadoop 集群,在进行了性能压测和容量评估后,使用DistCp工具在老集群资源相对空闲的时间段做了 HDFS 数据的全量复制,此次复制 HDFS 数据时新集群只开启了单副本,整个全量同步持续了两周。基于 DistCp 本身的特性(带宽限制:-bandwidth / 基于修改时间和大小的比较和更新:-update)较好的满足全量数据复制以及后续的增量更新的需求。
3.2 离线任务的迁移
目前有赞所有的大数据离线任务都是通过 DP 平台来开发和调度的,由于底层采用了两套 Hadoop 集群的方案,所以迁移的核心工作变成了怎么把 DP 平台上任务迁移到新集群。
3.2.1 DP 平台介绍
有赞的 DP 平台是提供用户大数据离线开发所需的环境、工具以及数据的一站式平台(更详细的介绍请参考另一篇博客),目前支持的任务主要包括:
- 离线导入任务( MySQL 全量/增量导入到 Hive)
- 基于binlog的增量导入 (数据流:binlog -> Canal -> NSQ -> Flume -> HDFS -> Hive)
- 导出任务(Hive -> MySQL、Hive -> ElasticSearch、Hive -> HBase 等)
- Hive SQL、Spark SQL 任务
- Spark Jar、MapReduce 任务
- 其他:比如脚本任务
本次由于采用多集群跨机房迁移方案(两个 Hadoop 集群),因此需要在新旧两个机房搭建两套 DP 平台,同时由于迁移周期比较长(几个月)且用户迁移的时间节奏不一样,因此会出现部分任务先迁完,部分任务还在双跑,还有一些任务没开始迁移的情况。
3.2.2 DP 任务状态一致性保证
在新旧两套 DP 平台都允许用户创建和更新任务的前提下,如何保证两边任务状态一致呢(任务状态不限于MySQL的数据、Gitlab的调度文件等,因此不能简单使用MySQL自带的主从复制功能)?我们采取的方案是通过事件机制来实现任务操作时间的重放,展开来讲:
- 用户在老 DP 产生的操作(包括新建/更新任务配置、任务测试/发布/暂停等),通过事件总线产生事件消息发送到 Kafka,新系统通过订阅 Kafka 消息来实现事件的回放,如图 3.2 所示。
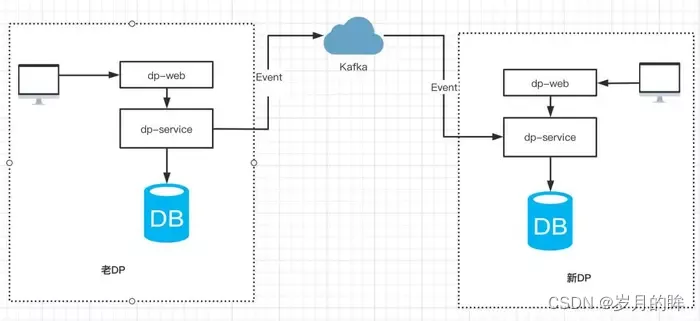
图3.2 通过事件机制,来保证两个平台之间的任务状态一致
3.2.3 DP 任务迁移状态机设计
DP 底层的改造对用户来说是透明的,最终暴露给用户的仅是一个迁移界面,每个工作流的迁移动作由用户来触发。工作流的迁移分为两个阶段:双跑和全部迁移,状态流转如图 3.3 所示
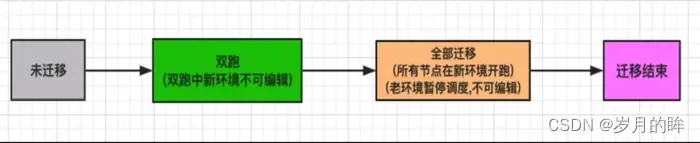
图 3.3 工作流迁移状态流转
双跑
工作流的初始状态为未迁移,然后用户点击迁移按钮,会弹出迁移界面,如图 3.4 所示,用户可以指定工作流的任意子任务的运行方式,主要选项如下:
- 两边都跑:任务在新老环境都进行调度
- 老环境跑:任务只在老环境进行调度
- 新环境跑:任务只在新环境进行调度
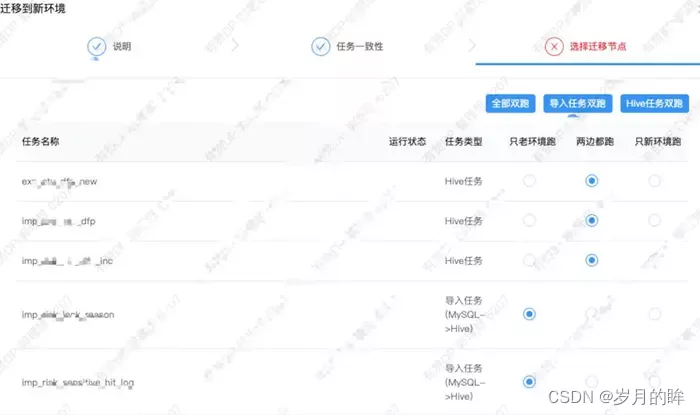
图 3.4 工作流点击迁移时,弹框提示选择子任务需要运行的方式
不同类型的子任务建议的运行方式如下:
- 导入任务 (MySQL -> Hive):通常是双跑,也就是两个集群在调度期间都会从业务方的 MySQL 拉取数据(由于拉取的是 Slave 库,且全量拉取的一般是数据量不太大的表)
- Hive、SparkSQL 任务:通常也是双跑,双跑时新老集群都会进行计算。
- MapReduce、Spark Jar 任务:需要业务方自行判断:任务的输出是否是幂等的、代码中是否配置了指向老集群的地址信息等
- 导出任务:一般而言无法双跑,如果两个环境的任务同时向同一个 MySQL表(或者 同一个ElasticSearch 索引)写入/更新数据,容易造成数据不一致,建议在验证了上游 Hive 表数据在两个集群一致性后进行切换(只在新环境跑)。
- 同时处于用户容易误操作导致问题的考虑,DP 平台在用户设置任务运行方式后,进行必要的规则校验:
- 如果任务状态是双跑,则任务依赖的上游必须处于双跑的状态,否则进行报错。
- 如果任务是第一次双跑,会使用 Distcp 将其产出的 Hive 表同步到新集群,基于 Distcp 本身的特性,实际上只同步了在第一次同步之后的增量/修改数据。
- 如果工作流要全部迁移(老环境不跑了),则工作流的下游必须已经全部迁移完。
双跑期间的数据流向如下图 3.5 所示:

图 3.5 DP 任务双跑期间数据流向
迁移过程中工作流操作的限制规则
由于某个工作流迁移的持续时间可能会比较长(比如DW层任务需要等到所有DM层任务全部迁移完),因此我们既要保证在迁移期间工作流可以继续开发,同时也要做好预防误操作的限制,具体规则如下:
- 迁移中的工作流在老环境可以进行修改和发布的,新环境则禁止
- 工作流在老环境修改发布后,会将修改的元数据同步到新环境,同时对新环境中的工作流进行发布。
- 工作流全部迁移,需要所有的下游已经完成全部迁移。
3.3 有序推动业务方迁移
工具都已经开发好了,接下来就是推动 DP 上的业务方进行迁移,DP 上任务数量大、种类多、依赖复杂,推动业务方需要一定的策略和顺序。有赞的数据仓库设计是有一定规范的,所以我们可以按照任务依赖的上下游关系进行推动:
- 导入任务( MySQL 全量/增量导入 Hive) 一般属于数据仓库的 ODS 层,可以进行全量双跑。
- 数仓中间层任务主要是 Hive / Spark SQL 任务,也可以全量双跑,在验证了新老集群的 Hive 表一致性后,开始推动数仓业务方进行迁移。
- 数仓业务方的任务一般是 Hive / Spark SQL 任务和导出任务,先将自己的 Hive 任务双跑,验证数据一致性没有问题后,用户可以选择对工作流进行全部迁移,此操作将整个工作流在新环境开始调度,老环境暂停调度。
- 数仓业务方的工作流全部迁移完成后,将导入任务和数仓中间层任务统一在老环境暂停调度。
- 其他任务主要是 MapReduce、Spark Jar、脚本任务,需要责任人自行评估。
3.4 过程保障
工具已经开发好,迁移计划也已经确定,是不是可以让业务进行迁移了呢?慢着,我们还少了一个很重要的环节,如何保证迁移的稳定呢?在迁移期间一旦出现 bug 那必将是一个很严重的故障。因此如何保证迁移的稳定性也是需要着重考虑的,经过仔细思考我们发现问题可以分为三类,迁移工具的稳定,数据一致性和快速回滚。
迁移工具稳定
- 新 DP 的元数据同步不及时或出现 Bug,导致新老环境元数据不一致,最终跑出来的数据必定天差地别。
- 应对措施:通过离线任务比对两套 DP 中的元数据,如果出现不一致,及时报警。
- 工作流在老 DP 修改发布后,新 DP 工作流没发布成功,导致两边调度的 airflow 脚本不一致。
- 应对措施:通过离线任务来比对 airflow 的脚本,如果出现不一致,及时报警。
- 全部迁移后老环境 DP 没有暂定调度,导致导出任务生成脏数据。
- 应对措施:定时检测全部迁移的工作流是否暂停调度。
- 用户设置的运行状态和实际 airflow 脚本的运行状态不一致,比如用户期望新环境空跑,但由于程序 bug 导致新环境没有空跑。
- 应对措施:通过离线任务来比对 airflow 的脚本运行状态和数据库设置的状态。
Hive 表数据一致性
Hive 表数据一致性指的是,双跑任务产出的 Hive 表数据,如何检查数据一致性以及识别出来不一致的数据的内容,具体方案如下(如图3.6所示):
- 双跑的任务在每次调度运行完成后,我们会上报 <任务T、产出的表A> 信息,用于数据质量校验(DQC),等两个集群产出的表A都准备好了,就触发数据一致性对比
- 根据 <表名、表唯一键K> 参数提交一个 MapReduce Job,由于我们的 Hive 表格式都是以 Orc格式存储,提交的 MapReduce Job 在 MapTask 中会读取表的任意一个 Orc 文件并得到 Orc Struct 信息,根据用户指定的表唯一键,来作为 Shuffle Key,这样新老表的同一条记录就会在同一个 ReduceTask 中处理,计算得到数据是否相同,如果不同则打印出差异的数据
- 表数据比对不一致的结果会发送给表的负责人,及时发现和定位问题
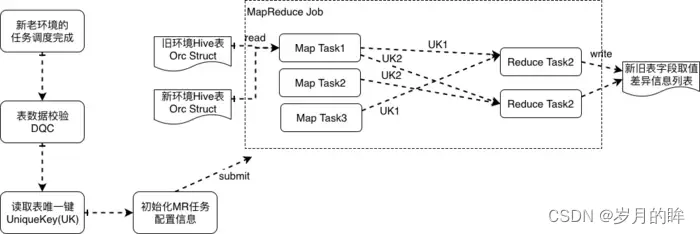
图 3.6 Hive表新老集群数据一致性校验方案
四、迁移过程中的问题总结
- 使用 DistCp 同步 HDFS 数据时漏配参数(-p),导致 HDFS 文件 owner 信息不一致。
- 使用 DistCp 同步 HDFS 数据时覆盖了 HBase 的 clusterId,导致 Hbase 两个集群之间同步数据时发生问题。
- 在迁移开始后,新集群的 Hive 表通过 export import 表结构来创建,再使用 DistCp 同步表的数据。导致 Hive meta 信息丢失了 totalSize 属性,造成了 Spark SQL 由于读取不到文件大小信息无法做 broadcast join,解决方案是在 DistCp 同步表数据之后,执行 Hive 命令 ANALYZE TABLE TABLE_NAME COMPUTE STATISTICS 来生成表相关属性。
- 迁移期间由于在夜间启动了大量的 MapReduce 任务,进行 Hive 表数据比对,占用太多离线集群的计算资源,导致任务出现了延迟,最后将数据比对任务放在资源相对空闲的时间段。
- 工作流之间存在循环依赖,导致双跑-全部迁移的流程走不下去,所以数仓建设的规范很重要,解决方案就是要么让用户对任务重新组织,来重构工作流的依赖关系,要么两个工作流双跑后,一起全部迁移。
- 迁移期间在部分下游已经全部迁移的情况下,上游出现了问题需要重刷所有下游,由于只操作了老 DP,导致新环境没有重刷,使迁移到新环境的下游任务受到了影响。
- MapReduce 和 Spark Jar 类型的任务无法通过代码来检测生成的上下游依赖关系,导致这类任务只能由用户自己来判断,存在一定的风险,后续会要求用户对这类任务也配上依赖的 Hive 表和产出的 Hive 表。
五、总结与展望
本次的大数据离线集群跨机房迁移工作,时间跨度近6个月(包括4个月的准备工作和2个月的迁移),涉及PB+的数据量和4万日均调度任务。虽然整个过程比较复杂(体现在涉及的组件众多、任务种类和实现复杂、时间跨度长和参与人员众多),但通过前期的充分调研和探讨、中期的良好迁移工具设计、后期的可控推进和问题修复,我们做到了整体比较平稳的推进和落地。同时针对迁移过程中遇到的问题,在后续的类似工作中我们可以做的更好:
- 做好平台的治理,比如代码不能对当前环境配置有耦合
- 完善迁移工具,尽量让上层用户无感知
- 单 Hadoop 集群方案的能力储备,主要解决跨机房带宽的受控使用
六、元数据迁移工具hive-tools
hive-tools 项目介绍
Github地址:https://github.com/NetEase/hive-tools
在网易集团内部有大大小小几百套 hive 集群,为了满足网易猛犸大数据平台的元数据统一管理的需求,我们需要将多个分别独立的 hive 集群的元数据信息进行合并,但是不需要移动 HDFS 中的数据文件,比如可以将 hive2、hive3、hive4 的元数据全部合并到 hive1 的元数据 Mysql 中,然后就可以在 hive1 中处理 hive2、hive3、hive4 中的数据。
我们首先想到的是 hive 中有自带的 EXPORT 命令,可以把指定库表的数据和元数据导出到本地或者 HDFS 目录中,再通过 IMPORT 命令将元数据和数据文件导入新的 hive 仓库中,但是存在以下问题不符合我们的场景
- 我们不需要重现导入数据;
- 我们的每个 hive 中的表的数量多达上十万,分区数量几千万,无法指定 IMPORT 命令中的分区名;
- 经过测试 IMPORT 命令执行效率也很低,在偶发性导入失败后,无法回滚已经导入的部分元数据,只能手工在 hive 中执行 drop table 操作,但是我们线上的 hive 配置是开启了删除表同时删除数据,这是无法接受的;
于是我们便考虑自己开发一个 hive 元数据迁移合并工具,满足我们的以下需求:
- 可以将一个 hive 集群中的元数据全部迁移到目标 hive 集群中,不移动数据;
- 在迁移失败的情况下,可以回退到元数据导入之前的状态;
- 可以停止源 hive 服务,但不能停止目标 hive 的服务下,进行元数据迁移;
- 迁移过程控制在十分钟之内,以减少对迁移方的业务影响;
元数据合并的难点
hive 的元数据信息(metastore)一般是通过 Mysql 数据库进行存储的,在 hive-1.2.1 版本中元数据信息有 54 张表进行了存储,比如存储了数据库名称的表 DBS、存储表名称的表 TBLS 、分区信息的 PARTITIONS 等等。
元数据表依赖关系非常复杂

元数据信息的这 54 张表通过 ID 号形成的很强的主外健依赖关系,例如
DBS表中的DB_ID字段被 20 多张表作为外健进行了引用;TBLS表中的TBL_ID字段被 20 多张表作为外健进行了引用;TBLS表中的DB_ID字段是DBS表的外健、SD_ID字段是SDS表的外健;PARTITIONS表中的TBL_ID字段是TBLS表的外健、SD_ID字段是SDS表的外健;DATABASE_PARAMS表中的DB_ID字段是DBS表的外健;
这样的嵌套让表与表之间的关系表现为 [DBS]=>[TBLS]=>[PARTITIONS]=>[PARTITION_KEY_VALS],像这样具有 5 层以上嵌套关系的有4-5 套,这为元数据合并带来了如下问题。
- 源 hive 中的所有表的主键 ID 必须修改,否则会和目标 hive2 中的主键 ID 冲突,导致失败;
- 源 hive 中所有表的主键 ID 修改后,但必须依然保持源 hive1 中自身的主外健依赖关系,也就是说所有的关联表的主外健 ID 都必须进行完全一致性的修改,比如 DBS 中的 ID 从 1 变成 100,那么 TBLS、PARTITIONS 等所有子表中的 DB_ID 也需要需要从 1 变成 100;
- 按照表的依赖关系,我们必须首先导入主表,再导入子表,再导入子子表 …,否则也无法正确导入;
修改元数据的主外健 ID
我们使用了一个巧妙的方法来解决 ID 修改的问题:
- 从目标 hive 中查询出所有表的最大 ID 号,将每个表的 ID 号加上源 hive 中所有对应表的 ID 号码,形成导入后新生成出的 ID 号,公式是:新表ID = 源表ID + 目标表 ID,因为所有的表都使用了相同的逻辑,通过这个方法我们的程序就不需要维护父子表之间主外健的 ID 号。
- 唯一可能会存在问题的是,在线导入过程中,目标 hive 新创建了 DB,导致 DB_ID 冲突的问题,为此,我们在每次导入 hive 增加一个跳号,公式变为:新表ID = 源表ID + 目标表 ID + 跳号值(100)
数据库操作
我们使用了 mybatis 进行了源和目标这 2 个 Mysql 的数据库操作,从源 Mysql 中按照上面的逻辑关系取出元数据修改主外健的 ID 号再插入到目标 Mysql 数据库中。
- 由于 mybatis 进行数据库操作的时候,需要通过表的 bean 对象进行操作,54 张表全部手工敲出来又累又容易出错,应该想办法偷懒,于是我们使用了
druid解析 hive 的建表语句,再通过codemodel自动生成出了对应每个表的 54 个 JAVA 类对象。参见代码:com.netease.hivetools.apps.SchemaToMetaBean
元数据迁移操作步骤
-
第一步:备份元数据迁移前的目标和源数据库
-
第二步:将源数据库的元数据导入到临时数据库 exchange_db 中,需要一个临时数据库是因为源数据库的 hive 集群仍然在提供在线服务,元数据表的 ID 流水号仍然在变化,hive-tools 工具只支持目的数据库是在线状态;
-
通过临时数据库 exchange_db 能够删除多余 hive db 的目的,还能够通过固定的数据库名称,规范整个元数据迁移操作流程,减低因为手工修改执行命令参数导致出错的概率
-
在 hive-tools.properties 文件中配置源和目的数据库的 JDBC 配置项
# exchange_db exchange_db.jdbc.driverClassName=com.mysql.jdbc.Driver exchange_db.jdbc.url=jdbc:mysql://10.172.121.126:3306/hivecluster1?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true exchange_db.jdbc.username=src_hive exchange_db.jdbc.password=abcdefg # dest_hive dest_hive.jdbc.driverClassName=com.mysql.jdbc.Driver dest_hive.jdbc.url=jdbc:mysql://10.172.121.126:3306/hivecluster1?useUnicode=true&characterEncoding=utf8&autoReconnect=true&allowMultiQueries=true dest_hive.jdbc.username=dest_hive dest_hive.jdbc.password=abcdefg -
执行元数据迁移命令
export SOURCE_NAME=exchange_db export DEST_NAME=dest_hive /home/hadoop/java-current/jre/bin/java -cp "./hive-tools-current.jar" com.netease.hivetools.apps.MetaDataMerge --s=$SOURCE_NAME --d=$DEST_NAME -
hive-tools 会在迁移元数据之前首先检查源和目的元数据库中重名的 hive db,终止元数据迁移操作并给出提示
-
执行删除重名数据库命令
# 修改脚本中的 DEL_DB(多个库之间用逗号分割,default必须删除)参数和 DEL_TBL(为空则删除所有表) export SOURCE=exchange_db export DEL_DB=default,nisp_nhids,real,azkaban_autotest_db export DEL_TBL= ~/java-current/jre/bin/java -cp "./hive-tools-current.jar" com.netease.hivetools.apps.DelMetaData --s=$SOURCE --d=$DEL_DB --t=$DEL_TBL -
再次执行执行元数据迁移命令
-
检查元数据迁移命令窗口日志或文件日志,如果发现元数据合并出错,通过对目的数据库进行执行删除指定 hive db 的命令,将迁移过去的元数据进行删除,如果没有错误,通过 hive 客户端检查目的数据库中是否能够正常使用新迁移过来的元数据
-
严格按照我们的元数据迁移流程已经在网易集团内部通过 hive-tools 已经成功迁移合并了大量的 hive 元数据库,几乎没有出现过问题
compile
mvn clean compile package -Dmaven.test.skip=true
history
Release Notes - Hive-tools - Version 0.1.4
-
[hive-tools-0.1.5]
MetaDataMerge add update SEQUENCE_TABLE NO -
[hive-tools-0.1.4]
MetastoreChangelog -z=zkHost -c=changelog -d=database -t=table
thrift -gen java src/main/thrift/MetastoreUpdater.thrift -
[hive-tools-0.1.3]
- delete database metedata database_name/table_name support % wildcard
-
[hive-tools-0.1.2]
- hdfs proxy user test
-
[hive-tools-0.1.1]
- delete database metedata
-
[hive-tools-0.1.0]
- hive meta schema convert to java bean
- multiple hive meta merge
智能推荐
全程带阻:记一次授权网络攻防演练(下)_获取据点 攻防沙盘演练-程序员宅基地
文章浏览阅读905次。*本文作者:yangyangwithgnu,本文属 FreeBuf 原创奖励计划,未经许可禁止转载。在一次漏洞赏金活动中,挖掘到一个不标准的命令注入漏洞,我无法用命令分隔符、命令替换符注入新命令让系统执行,所以,从”型态”上讲,它不算是命令注入漏洞;但我又可以借助目标环境让载荷到达系统命令行,实现读写文件、执行新命令,所以,”神态”来看,..._获取据点 攻防沙盘演练
GWT编写hello world-程序员宅基地
文章浏览阅读170次。GWT是Google Web Toolkit的缩写.是google为了开发ajax而做的一个框架.采用的概念是用java开发程序之后,用GWT转换成js和html.debug之类的也可以在java的IDE中调试。为java程序员开发ajax提供也方便。也给那些熟练c/s开发b/s人带来了惊喜。本文主要介绍用gwt编写一个hello world!准备工作:eclipse3.2 gwt安装GW..._gwt hello world
uni-app介绍_uniapp-程序员宅基地
文章浏览阅读7.1k次。Uni-app的特点是使用Vue.js作为开发语言,可以在不同的移动端平台上共享组件库和业务逻辑代码,大大提高了开发效率和代码重用率。pages.json :文件用来对 uni-app 进行全局配置,决定页面文件的路径、窗口样式、原生的导航栏、底部的原生tabbar 等。App.vue:是我们的跟组件,所有页面都是在App.vue下进行切换的,是页面入口文件,可以调用应用的生命周期函数。manifest.json :文件是应用的配置文件,用于指定应用的名称、图标、权限等。pages:所有的页面存放目录。_uniapp
【idea】idea 常用快捷键(每个都有操作演示)_idea快捷键大全最新-程序员宅基地
文章浏览阅读8.4k次,点赞16次,收藏80次。以下的效果演示图,是关于快速移动光标、快速选择文字的功能,前期用了一点时间记这些快捷键,但时间久了,就像你去打一个字一样,不会去想这个字的拼音是什么了,换回来的是减少了来回切换鼠标、键盘的频率,个人觉得还是很值得一用的。Undo 操作可以撤销你的修改,如果你想反撤销,即还想要撤销前的内容,就要用到与 Undo 相反的功能 Redo 了,关键字:Redo、快捷键:Ctrl + Shift + Z。设置好书签后,按 Ctrl + 你设置的数字 就可以跳转了,注意数字是主键盘区的,不是右侧数字键区的。_idea快捷键大全最新
Subject_suhject-程序员宅基地
文章浏览阅读2.7w次。N.作为名词,是常见的“主题,题目,话题,学科,课程”, “绘画,摄影,被描绘对象,题材”,臣民(君主制)等adj. 可能受。。。影响,受……支配,取决于……Subject to ……E.G.:Flights are subject to delay because of the fog.取决于;视…而定:The article is ready to publish, subject to your approval.V.使臣服; 使顺从; (尤指)压服;The Roman Empire _suhject
远程连接服务器软件——十大常见的服务器管理软件-程序员宅基地
文章浏览阅读1.2w次。**1、远程桌面连接**远程桌面连接(以前称为“终端服务客户端”)主要是用于对远程托管的服务器进行远程管理,使用非常方便,如同操作本地电脑一样方便,而远程桌面连接工具,我个人喜好IIS7。IIS7远程桌面管理工具(3389、vps、服务器批量管理、批量远程工具) 是一款绿色小巧,功能实用的远程桌面管理工具,其界面简洁,操作便捷,能够同时远程操作多台服务器,并且多台服务器间可以自由切换,适用于网...
随便推点
PANET_roi xform-程序员宅基地
文章浏览阅读276次。`class mask_rcnn_fcn_head_v1upXconvs_gn_adp_ff(nn.Module):“”“v1upXconvs design: X * (conv 3x3), convT 2x2, with GroupNorm”""def init(self, dim_in, roi_xform_func, spatial_scale, num_convs):super()...._roi xform
UIPageControl_deferscurrentpagedisplay-程序员宅基地
文章浏览阅读495次。UIPageControl 在页面下方显示一系列点,每个点对应一个页面UIPageControl : UIControl numberOfPages; // 用于设置总共有的页数,默认0 NSInteger currentPage; // 设置当前页,默认0 hidesForSinglePage; // bool值,如果只有一页是否隐藏指_deferscurrentpagedisplay
MyEclipse集成安装svn的方法总结_myeclipse 集成安装svn-程序员宅基地
文章浏览阅读415次。方法一:在线安装 1.打开Help---MyEclipse Configuration Center。切换到SoftWare标签页。 2.点击Add Site 打开对话框,在对话框Name输入Svn,URL中输入:http://subclipse.tigris.org/update_1.6.x3.在左边栏中找到Personal Site中找到SVN展开。将Core SVNKit_myeclipse 集成安装svn
wireshark安装及使用入门_1. wireshark的安装与使用 (1) 将实验文件wireshark-win64-3.2.2.-程序员宅基地
文章浏览阅读2.6k次,点赞2次,收藏25次。Wireshark是一个网络封包分析软件。网络封包分析软件的功能是撷取网络封包,并尽可能显示出最为详细的网络封包资料。Wireshark使用WinPCAP作为接口,直接与网卡进行数据报文交换。网络管理员使用Wireshark来检测网络问题,网络安全工程师使用Wireshark来检查资讯安全相关问题,开发者使用Wireshark来为新的通讯协定除错,普通使用者使用Wireshark来学习网络协定的相关知识。当然,有的人也会“居心叵测”的用它来寻找一些敏感信息……这儿就不多赘述了。如何安装选择自己电脑_1. wireshark的安装与使用 (1) 将实验文件wireshark-win64-3.2.2.exe复制到物理机
Web开发—简单的点餐管理系统_1+xweb前端 点餐系统-程序员宅基地
文章浏览阅读5.4k次,点赞6次,收藏81次。本系统由bootstrap,eclipse和Mysql共同开发完成。其主要功能根据角色大致可分为基于用户的登录注册,浏览菜品,添加修改购物车,查看以下单的订单信息,留言评论并查看所有人评论,查看并修改个人信息及密码等基于管理员的有添加和修改菜品,查看所有用户订单信息,查看并管理所有用户的评论,查看所用用户信息,管理个人管理员信息等1.数据库作为一个点餐管理系统,大致建表如图列数据这里贴出用户表的和购物车表的用户表购物车表2.前端前端重要运用bootstr..._1+xweb前端 点餐系统
HashMap的容量(capacity)和大小(size)浅谈,打印hashMap的容量(capacity)方法_map的capacity-程序员宅基地
文章浏览阅读2.9k次。hashMap 默认容量(capacity)是16当size的值超过75%的时候,就会进行扩容,capacity翻倍写了个小程序验证,代码如下:import java.lang.reflect.Method;import java.util.HashMap;import java.util.Map;public class HashMapTest { publ..._map的capacity