【没有哪个港口是永远的停留~ 论文解读】L2-Softmax_卷积模型rx101-程序员宅基地
技术标签: 论文研究、复现、总结
论文地址:L2-constrained Softmax Loss for Discriminative Face Verification
摘要
- 成就:具体来说,我们在具有挑战性的IJB-A数据集上实现了最先进的结果,在FA=0.0001下实现了0.909的TA此外,我们在LFW数据集上获得了最先进的性能,准确率为99.78%,在YTF数据集上获得了96.08%
- 提出问题:而softmax损失函数,对正对具有较高的相似性评分,对负对具有较低的相似性评分,从而导致性能差距。
- 解决问题:我们在特征描述符中添加了一个L2约束,限制它们位于固定半径的超球面上。
Introduction
现状:无约束环境下的人脸验证是一个具有挑战性的问题。 尽管最近的人脸验证系统在像LFW这样的有计划的数据集表现优异,但是在视点、分辨率、遮挡和图像质量极不相同的人脸上,仍然很难达到类似的精度。
猜想:训练集中的数据质量不平衡是造成这种性能差距的原因之一。 现有的人脸识别训练数据集包含大量的高质量和正面人脸,而 无约束和困难的面孔很少有。
softmax loss优缺点:容易实现,批次大小没有任何限制,并且收敛速度快。但是,没有任何度量学习。
L2范数:如图1,我们观察到,使用Softmax损失学习的特征的L2范数是关于面部[23]质量的信息。 优质正面脸的特点是有一个高的L2范数,而模糊的脸与 极端姿态具有低L2-范数

Related Work
- 在第一种方法中,将对人脸图像输入到训练算法中,以学习 feature 。正对更接近,负对相距很远。例如: contrastive loss、FaceNet
- 分类网络,提取中间的 feature 层
- center loss
- feature normalization 提高性能 例如:SphereFace。DeepVisage:批处理归一化技术在应用Softmax损失之前对特征描述符进行规范化。
流程:

用Softmax损失函数对网络进行训练,由方程(1)给出:

测试的时候,采用L2-distance,或余弦(2)做相似度判断,结果是一样的

这个流程有两个主要问题:首先,对人脸验证任务的训练和测试步骤进行解耦。 使用Softmax损失的训练不一定能确保正对 在归一化或角空间中,负对要更近,负对要远距离分离。其次,Softmax分类器在 困难 或 极端样本结果不好。
提出假设:在数据质量不平衡的典型训练批次中,通过增加L2范数,使Softmax损失减轻重视简单样本的特征,忽略困难样本。
实验:为了验证这一理论,我们在IJB-A数据集上进行了一个简单的实验。网络采用Face RestNet。就是图1,高L2-norm好,低L2-norm不好
做法:为了解决这些问题,我们强制每个人脸图像的特征的L2范数。最终的特征都分布在球面上。
优点:使正对的余弦相似度最大化,使负对的余弦相似度最小化,从而增强了特征的验证信号。 其次,这是 由于所有的人脸特征都具有相同的L2范数,所以Softmax损失能够更好地模拟极端和困难的人脸
Proposed Method
L2-softmax loss 表示:

验证:
- 数据集:MNIST
- 网络:LeNet,feature=2维。类数=10。我们添加一个L2-norm layer 和 scale layer 到 feature 层
- 结果:图3


L2-norm实现:(scalar parameter (α) 参与训练)

参数α的变化:
标度参数α在决定L2-Softmax损失的性能中起着至关重要的作用。
有两种方法来执行L2约束:
- 1)在整个训练过程中保持α固定,
- 2)通过 让网络α学习参数。
第二种方法比较好,比Softmax损失有所改善。 但是,网络学习到的α参数很高,导致了减轻了 L2约束。 该Softmax分类器旨在增加特征范数以最小化总体损失,增加α参数,使其更自由地适合于简单的样本。 因此,由网络学习的α构成参数的上界。 通过将α固定在较低的恒定值上,获得了更好的性能。
另一方面,α值很低,训练不收敛。 例如,α=1在LFW[14]数据集上的性能非常差,准确率达到86.37%。小半径(α)的超球具有有限的比表面积,所以比较难
在这里,我们在α上制定了一个理论下界。


实践
网络结构:用于实验[33]Face-Resnet体系结构。 C表示卷积层,激活函数PRELU[11],P表示最大池化层。 每个池层后面都有一组残差连接。 在完全连接层(FC)之后,我们添加了一个L2-Normalize层和尺度层,然后是Softmax损失。

数据集:在这一部分中,我们实验验证了L2-softmax损失对人脸识别的有效性。
我们从MS-Celeb-1M[9]数据集中形成了两个训练数据集子集:
- 1)MS-smallcont 获得50万张人脸图像,人数为13403人,
- 2)MSlarge包含370万张,人数为58207人。
数据清洗:聚类方法进行数据清洗
实验baseline
我们对具有Softmax损失以及L2-Softmax损失的Face-Resnet网络进行了各种α的训练。
- 在MS-small的训练中学习率为0.1开始,降低0.1, 6K和24K迭代,最多可达28K迭代。
- 对于MS-large的训练,我们使用相同的学习速率,但在50K和80K迭代之后,它会减少到最多100K迭代。 256的批次大小。
- 在两个TITANX GPU上,Softmax和L2-softmax损失函数消耗相同数量的训练时间,MS-small的训练时间约为9小时,MS-large的训练集为32小时。
- [25]中提到的人脸检测和对齐算法
实验一:小数据集
在这里,我们比较了在MS-small 上训练的网络,使用我们提出的L2-softmax损失,与训练的有传统的softmax损失。

看图说话:
- 图7显示了规则的softmax损失达到精度为98.1%,而所提出的L2-Softmax损失达到99.28%的最佳精度,从而使误差降低了62%以上%。
- 当α低于某一阈值时,性能较差,且α高于阈值时稳定。 这种行为与4.3节中提出的理论分析是一致的。
- 从图中可以看出,L2-Softmax在α>12中的性能更好,它接近它的下界,用方程9计算C=13403,概率分数为0.9。

实验二:大数据集
我们在MS-large数据集上为这个实验训练网络。
看图说话:
- 与小训练集相似,L2-softmax损失明显改善基线,将误差降低60%,精度达到99.6%。
- 与小集合训练不同,理论下界已经不好使了。
参与训练的结果表现得也不错


实验三:使用不同的网络
网络使用:All-In-One Face[25] 而不是 ResNet
随着尺度参数α的性能变化与Face-Resnet相似,表明最优尺度参数不依赖于网络的选择

与其他辅助loss配合
与softmax损失类似,L2-softmax损失可以与中心损失、对比损失、三重态损失等辅助损失耦合。
实验四:L2-softmax+中心损失
进一步提高性能。 在这里,我们研究与中心损失耦合时,L2-Softmax损失的变化。 我们使用MS-小数据集来训练网络。
表4:Softmax损失表现最差。 中心损失在与Softmax损失一起训练时显著提高了性能,与L2-Softmax损失相当。 中心损耗与L2-Softmax损失给出了99.33%的精度的最佳性能。

实验五:与当前其他损失比较

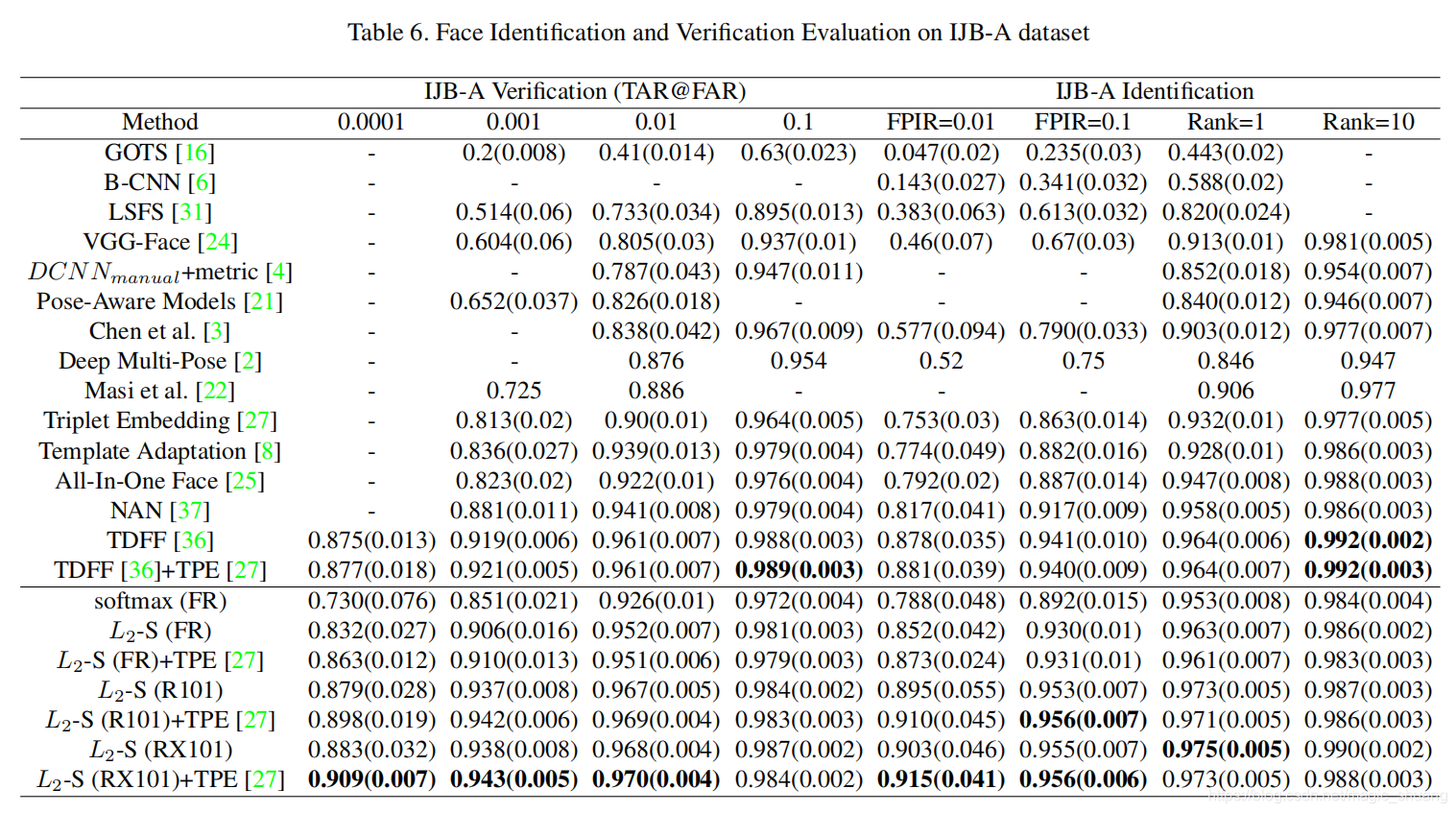
- 我们使用L2-softmax训练Face-Resnet(FR),以及使用MS-large进行常规Softmax损失。
- ResNet-101(R101)[12]和ResNeXt-101(RX101)[35]深网络,MS-large与L2-softmax损失。 R101和RX101模型都是在Image Net[26]数据集上预先训练的参数初始化的。feature = 512-d。 缩放参数保持固定,值为α=50
- YTF[34]数据集包含3425个视频,1595个不同的人,平均长度为181.3帧每个视频。
- IJB-A数据集[16]包含500人,共有25,813幅图像,包括5,399幅静止图像和20,414个视频帧。 它包含具有极端观点、分辨率和光照的面孔 这使得它比常用的LFW数据集更具挑战性。
- 我们使用Triplet Probabilistic Embedding (TPE)[27]使用IJB-A的训练分割来学习128维嵌入。实现了0.909@FAR=0.0001的记录TAR。 据我们所知,我们是第一个在IJB-A上超过[email protected]的TAR。 我们的方法表现得更好 其他大多数度量中的现有方法也是如此。 在LFW[14]、YTF[34]和IJB-A[16]数据集上的结果清楚地表明了所提出的L2-softmax损失的有效性。
智能推荐
2023年值得关注的几个跨境电商平台!_2023哪些跨境平台值得做-程序员宅基地
文章浏览阅读1.5k次。2022年即将过去了,2023年您打算做什么呢?不少小伙伴打算做跨境电商了,目前也正在学习当中,这里就告诉大家一下2023年值得关注的几个跨境电商平台吧!_2023哪些跨境平台值得做
深度学习 - 10.TF x Keras 基于 CNN 与 RNN 的文本序列 - 温度预测问题-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏31次。一.引言上一篇文章基础文本处理 processing && embedding介绍了常用的文本处理方法,趁热打铁了解一下处理连续文本的 demo 流程。二.数据信息与获取下面例子将用到气象记录站的天气时间序列,数据集中每10分钟记录14个不同的指标,包含气压,温度,湿度,风向等等环境相关的特征,这里采用 2009-2016 年的数据作为备选。1.源数据获取通过本地 terminal 输入如下命令,即可在对应 Downloads 文件夹下获取到原始数据。 ..
python获取视频帧率,总帧数,python ffmpeg获取视频信息ffmpeg.prob,python opencv获取视频信息cap.get(cv2.CAP_PROP_FRAME_WIDTH)-程序员宅基地
文章浏览阅读2.3w次,点赞9次,收藏59次。文章目录1,效果2,ffmpeg获取视频信息2,opencv获取视频信息1,效果2,ffmpeg获取视频信息其中key:‘streams’对应的值是一个list,list中有两个dict类型的值,分别表示视频中视频流和音频流的相关信息。key:‘format’对应的值是一个dict,其中包含了视频的相关的格式信息、视频时长信息、文件大小信息等。import ffmpegde..._cap.get(cv2.cap_prop_frame_width)
Bitmap.createBitmap java.lang.IllegalArgumentException: width and height must be > 0 问题解决-程序员宅基地
文章浏览阅读3.6k次。java.lang.IllegalArgumentException: width and height must be > 0 在postraotate之前需要设置转换矩形区域旋转时要判断旋转角度是否大于0,否则不做旋转。缺一报错Matrix mt = new Matrix(); float delta = angle - lastAngle;_java.lang.illegalargumentexception: width and height must be > 0
linux缺页异常处理--用户空间_linux 缺页异常 匿名-程序员宅基地
文章浏览阅读1.1w次,点赞2次,收藏22次。用户空间的缺页异常可以分为两种情况--1.触发异常的线性地址处于用户空间的vma中,但还未分配物理页,如果访问权限OK的话内核就给进程分配相应的物理页了2.触发异常的线性地址不处于用户空间的vma中,这种情况得判断是不是因为用户进程的栈空间消耗完而触发的缺页异常,如果是的话则在用户空间对栈区域进行扩展,并且分配相应的物理页,如果不是则作为一次非法地址访问来处理,内核将终结进程下面来看d_linux 缺页异常 匿名
【MFC】多文档窗口实现现实多个不同的view窗口_mfc多文档生成多个子窗口-程序员宅基地
文章浏览阅读1.6k次。在InitInstance函数中添加多个文档模板m_pTemplateSchematicView = new CMultiDocTemplate(IDR_CTEMATYPE, RUNTIME_CLASS(CCTEMADoc), RUNTIME_CLASS(CChildFrame), // 自定义 MDI 子框架 RUNTIME_CLASS(CCTEMAView)); if (!m_pTemplateSchematicView) re..._mfc多文档生成多个子窗口
随便推点
git reset 和 git revert_git revert和reset-程序员宅基地
文章浏览阅读1.4w次,点赞26次,收藏74次。一、问题描述在利用github实现多人合作程序开发的过程中,我们有时会出现错误提交的情况,此时我们希望能撤销提交操作,让程序回到提交前的样子,本文总结了两种解决方法:回退(reset)、反做(revert)。二、背景知识git的版本管理,及HEAD的理解使用git的每次提交,Git都会自动把它们串成一条时间线,这条时间线就是一个分支。如果没有新建分支,那么只有一条时间线,即只有一个分支,在Git里,这个分支叫主分支,即master分支。有一个HEAD指针指向当前分支(只有一个分支的情况下会指向ma_git revert和reset
ROS2+NAV2如何快捷的在docker中使用主机的CAN_ros2 nav2 docker arm 部署-程序员宅基地
文章浏览阅读384次。2.基于镜像创建新容器:注意为了保证和旧容器其它配置全部一样,创建时,需要保留旧的配置和旧容器创建是一样(包括挂载的目录、关键变量等),然后修改或者增加自己需要加的改动。其中old_container_id为老的容器ID,new_image为镜像名,v1为标签。如果容器已经创建,忘记指定--network=host了,又不想删除老容器,想仍然用这个容器里面的各种配置,可以考虑创建一份这个容器的镜像,基于这个镜像,指定--network=host,创建新的容器。_ros2 nav2 docker arm 部署
# Android 设置PNG图片的 打印分辨率 dpi (pHYs)_phys dpi-程序员宅基地
文章浏览阅读3k次。Android 设置PNG图片的打印分辨率dpi(pHYs)1.了解png的原文件数据,头文件IHDR,控制物理密度的pHYs,关于png的头文件IHDR:https://blog.csdn.net/satanzw/article/details/38757121png图片都是以固定标识89 50 4E 47 0D 0A 1A 0A开始,然后接着IHDR例如一张png从头开始为:..._phys dpi
uniapp 解决app头部导航和手机顶部状态栏叠加问题及样式拼接写法_app顶部状态栏与头部重叠-程序员宅基地
文章浏览阅读3.8k次。app开发,手机顶部状态栏会和app头部导航叠加在一起解决方法:拿到顶部状态栏的高度,再给头部导航加个padding-top在app.vue里拿到状态栏的高度并存放在globalData里onLaunch() { const that = this; uni.getSystemInfo({ success(res) { that.globalData.statusBarHeight = res.statusBarHeight; } })},globalData:{ statu_app顶部状态栏与头部重叠
优雅的反转链表你知道吗-程序员宅基地
文章浏览阅读252次,点赞9次,收藏3次。重复将首节点的下一个节点调整到最前面,如链表1->2->3->4,调整过程为2->1->3->4,3->2->1->4,4->3->2->1。致力于C、C++、Java、Kotlin、Android、Shell、JavaScript、TypeScript、Python等编程技术的技巧经验分享。将原链表的元素从头到尾入栈后,从栈顶到栈底的元素的顺序即为原链表反转后的顺序。您的支持是我们为您提供帮助的最大动力。使链表从尾节点开始指向前一个节点。
Derby对应用开发的支持-程序员宅基地
文章浏览阅读138次。出处:blog.csdn.net 作者:eye_of_back 更新时间:2007-08-21 原文 一,derby是什么 Derby是什么,即使你说不上来,想必你也早就听说过了,当然了,如果没有听说过,也没有关系,因为下面就要和你说一下Derby。 Derby是一款轻量级的关系型数据库,它的出现要感谢的人很多,其中一位是IBM,它把Cloudscape源码开源,并捐献给了Ap..._derby插件版本一定要匹配吗