【python】Pandas库用法详解!_pythonpandas库用法-程序员宅基地
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
一.pandas模块的安装
使用pip接口进行安装
pip install pandaspip接口详细说明可以看:【python】之pip,Python 包管理工具详解!_pip 包管理_彭彭能呀的博客-程序员宅基地
二、使用步骤
pandas的数据结构:
(1)Series:类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型,由索引(index)和列组成。
(2)DataFrame:是一个表格型的数据结构,每列可以是不同的值类型(数值,字符串,布尔型值),DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典。
1.先来看看Series:
import pandas as pd ###导入pandas模块
pd.series(data,index,dtype,name,copy)参数说明:
data:一组数据(ndarray类型)
index:数据索引标签,如果不指定,默认从0开始
dtype:数据类型,默认会自己判断
name:设置名称
copy:拷贝数据,默认伟False
(1)获取一列数据
import pandas as pd
x = [3,4,5,6,7,8,9]
pd.Series(x)输出:
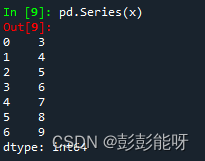
从0开始排列,dtype类型为int64。
(2)设置索引
import pandas as pd
x = [3,4,5,6]
pd.Series(x,index=['a','b','c','d'])输出如下:
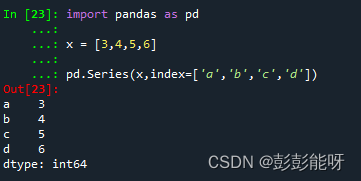
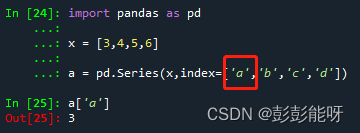
如上图1,设置索引对应列表数据,如图2直接获取a的值。
2. 接下来了解下DataFrame类型:
import pandas as pd
pd.DataFrame( data, index, columns, dtype, copy)
参数说明:
data:一组数据(ndarray、series, map, lists, dict 等类型)
index:数据索引标签,如果不指定,默认从0开始
columns:列索引
dtype:数据类型,默认会自己判断
copy:拷贝数据,默认伟False
(1).获取一组数据
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)输出:
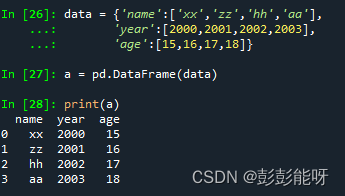
输出表格型的数据结构。
(2).设置行、列索引
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1输出:
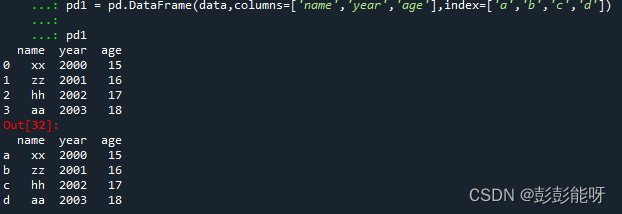
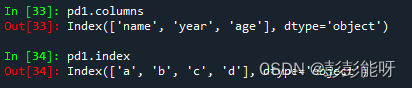
(3). 获取指定列信息
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1
pd1[['year']]输出:
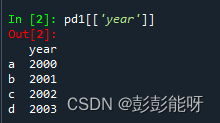
(4).切片行数据
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1
pd1[:2]输出: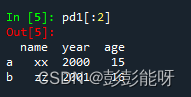
(5).条件筛选,获取满足条件的行数据
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1
pd1[pd1['age']>15]输出:
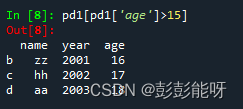
筛选出年龄大于15的同学
(6).先筛选行,在筛选列
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1
pd1[:2][['name','year']]输出:

(7).删除指定行
import pandas as pd
data = {'name':['xx','zz','hh','aa'],
'year':[2000,2001,2002,2003],
'age':[15,16,17,18]}
a = pd.DataFrame(data)
print(a)
pd1 = pd.DataFrame(data,columns=['name','year','age'],index=['a','b','c','d'])
pd1
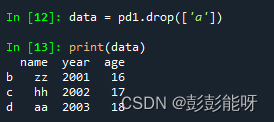
data = pd1.drop(['a'])
print(data)输出:
3.pandas文件读取和储存
pandas支持的常用文件类型包括:HDF5,CSV,SQL,XLS,JSON等
(1)读取CSV文件数据
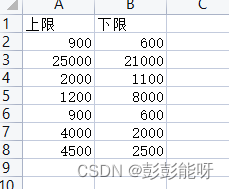
import pandas as pd
data = pd.read_csv(r"....\test.csv",encoding='gbk')
print(data)输出:
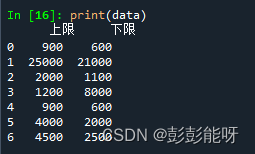
(2)读取指定列数据
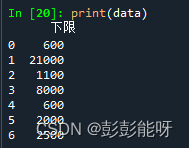
import pandas as pd
data = pd.read_csv(r"...\test.csv",usecols=['下限'],encoding='gbk')
print(data)输出:
先写这么多....
@Neng
智能推荐
.net引用DLL出错_.net 发布分程序值 使用dll方法,报错-程序员宅基地
文章浏览阅读747次。最近把WIN7 32位换成64位,重新运行以前编译的程序时报错:“System.Runtime.InteropServices.SEHException”类型的未知错误检查后发现程序是在调用DLL一个函数时报错不得其解,执行另一函数时又报了“Error Loading MIDAS.DLL”,感觉有戏于是下了64位的MIDAS.DLL,放在C:\Windows\SysWOW6_.net 发布分程序值 使用dll方法,报错
DevExpress关于正版和非正版的运行以及发布的问题_devexpress23.2激活-程序员宅基地
文章浏览阅读283次。DevExpress关于正版和非正版的运行以及发布的问题。_devexpress23.2激活
Sql server 使用DBCC Shrinkfile 收缩日志文件-程序员宅基地
文章浏览阅读795次。Sql server 使用DBCC Shrinkfile 收缩日志文件_dbcc shrinkfile 收缩日志
生产计划管理软件有哪些?哪个好_生产计划执行管理有什么目的和意义-程序员宅基地
文章浏览阅读3.6k次。生产计划管理软件有哪些?哪个好?生产计划管理,一般是指企业对生产活动的计划、组织和控制工作。生产计划管理软件可提高生产效率、提升品质、降低成本等。对企业管理意义深远。生产计划管理软件介绍:MES制造执行系统MES系统是一套面向制造企业车间执行层的生产信息化管理系统。是生产工业常见的生产管理软件,他可以为企业提供包括制造数据管理、计划生产调度管理、库存管理以及质量管理,同时还有人力资源管理..._生产计划执行管理有什么目的和意义
vue播放flv格式视频_vue flv-程序员宅基地
文章浏览阅读4.7k次,点赞3次,收藏11次。vue播放flv视频_vue flv
JPBC库的使用实例——BLS签名_it.unisa.dia.gas.jpbc.element-程序员宅基地
文章浏览阅读1.5k次。这里展示了一个简单的对JPBC库的调用的实例。可以参考JPBC库的官方文档进行学习:http://gas.dia.unisa.it/projects/jpbc/docs/ecpg.html#TypeAimport it.unisa.dia.gas.jpbc.Element;import it.unisa.dia.gas.jpbc.Field;import it.unisa.dia.gas.jpbc.Pairing;import it.unisa.dia.gas.jpbc.PairingParam_it.unisa.dia.gas.jpbc.element
随便推点
分布式复制块设备DRBD_分布式块设备-程序员宅基地
文章浏览阅读192次。DRBD(Distributed Replicated Block Device,分布式复制块设备)是一个用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。DRBD是镜像块设备,是按数据位镜像成一样的数据块。个人理解为分布式RAID(磁盘阵列)解决方案。..._分布式块设备
VS 2019 创建QT窗口、按钮、文本框、输入框、信号和槽_vs窗体设计中添加文字框-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏20次。VS 2019 创建QT窗口、按钮、文本框、输入框、信号和槽_vs窗体设计中添加文字框
浅谈nacos脑裂-程序员宅基地
文章浏览阅读1.4k次。nacos 默认采集临时节点ephemeral,满足CAP中 AP原则,各节点是pear to pear 模式,相互直接无感知,因此对于一个集群来说,只要leader存活,即使其他所有follower全部down了,也能正常对外提供服务,基于此,nacos是可能产生脑裂的。follower无法与leader通信,因此会触发新的选举,投票满足过半数原则,因此能正常选举新的leader,且能正常对外提供服务;此时因为leader是状态正常,且与应用之间通信是正常的,因此仍能正常对外提供服务;_nacos脑裂
使用LL库开发STM32:UART进阶使用(DMA循环接收 + UART空闲中断)_stm32 ll uart-程序员宅基地
文章浏览阅读5.1k次,点赞10次,收藏20次。文章目录目的发送处理问题与解决方法个人常用处理方式数据接收与解析总结目的发送处理问题与解决方法个人常用处理方式数据接收与解析总结_stm32 ll uart
Android UI线程和非UI线程_android在ui线程-程序员宅基地
文章浏览阅读3.7k次,点赞2次,收藏9次。UI线程及Android的单线程模型原则 当应用启动,系统会创建一个主线程(main thread)。 这个主线程负责向UI组件分发事件(包括绘制事件),也是在这个主线程里,你的应用和Android的UI组件(components from the Android UI toolkit (components from the android.widget andandroid.vie_android在ui线程
C++:opencv 人脸检测_c++ opencv十字检测-程序员宅基地
文章浏览阅读2.1k次,点赞3次,收藏19次。C++:opencv 人脸检测问题描述:要求输入一张图片;输出圈出人脸的图片;vs2015; opencv3.4.6;效果输入:输出:代码实现:#include "opencv2/objdetect.hpp"#include "opencv2/highgui.hpp"#include "opencv2/imgproc.hpp"#include <iostrea..._c++ opencv十字检测