删除异常值方法总结_python删除异常值-程序员宅基地
技术标签: python 机器学习 # python # 机器学习 # 统计学
推荐资料:14种异常检测方法总结
前提:
import pandas as pd
import numpy as np
import os
import seaborn as sns
from pyod.models.mad import MAD
from pyod.models.knn import KNN
from pyod.models.lof import LOF
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
1.IQR
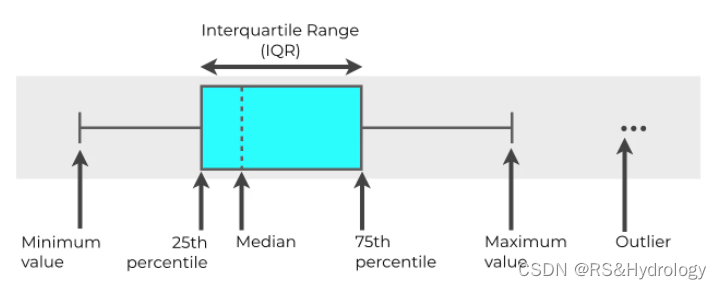
python基于IQR删除异常值:
df = pd.read_excel('./7.xlsx')
def fit_model(model, data, column='Area'):
# fit the model and predict it
df = data.copy()
data_to_predict = data[column].to_numpy().reshape(-1, 1)
predictions = model.fit_predict(data_to_predict)
df['Predictions'] = predictions
return df
def plot_anomalies(df, x='Date', y='Area'):
# categories will be having values from 0 to n
# for each values in 0 to n it is mapped in colormap
categories = df['Predictions'].to_numpy()
colormap = np.array(['g', 'r'])
f = plt.figure(figsize=(12/2.54, 6/2.54))
f = plt.scatter(df[x], df[y], c=colormap[categories])
f = plt.xlabel(x)
f = plt.ylabel(y)
f = plt.xticks(rotation=0)
plt.show()
#IQR
def find_anomalies(value, lower_threshold, upper_threshold):
if value < lower_threshold or value > upper_threshold:
return 1
else: return 0
def area_anomaly_detector(data, column='Area', threshold=1.1):
df = data.copy()
quartiles = dict(data[column].quantile([.25, .50, .75]))
quartile_3, quartile_1 = quartiles[0.75], quartiles[0.25]
area = quartile_3 - quartile_1
lower_threshold = quartile_1 - (threshold * area)
upper_threshold = quartile_3 + (threshold * area)
print(f"Lower threshold: {lower_threshold}, \nUpper threshold: {upper_threshold}\n")
df['Predictions'] = data[column].apply(find_anomalies, args=(lower_threshold, upper_threshold))
return df
area_df = area_anomaly_detector(df)
plot_anomalies(area_df)
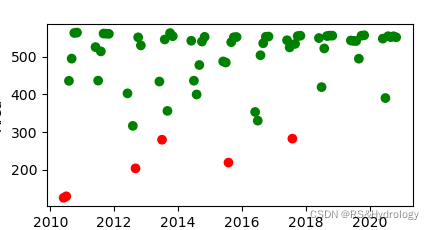
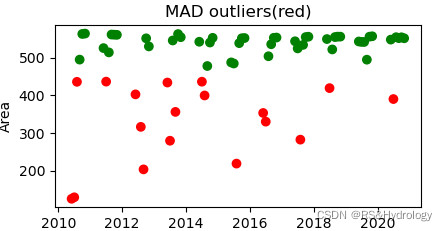
(红色为异常值)
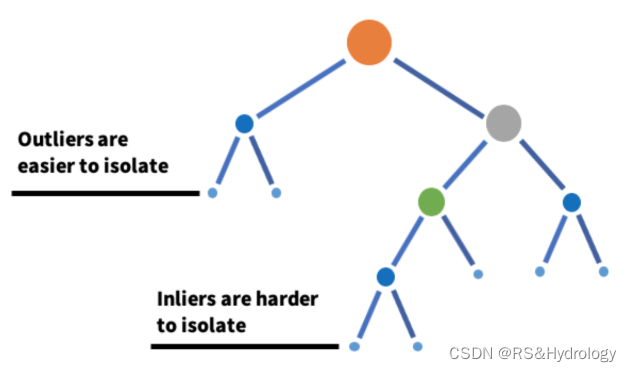
2.Isolation Forest(隔离森林算法)
- 孤立森林是基于决策树的算法。从给定的特征集合中随机选择特征,然后在特征的最大值和最小值间随机选择一个分割值,来隔离离群值。这种特征的随机划分会使异常数据点在树中生成的路径更短,从而将它们和其他数据分开。
- 在高维数据集中执行离群值检测的一种有效方法是使用随机森林。
- 属于无监督学习算法。
模型参数: - 评估器数量:n_estimators 表示集成的基评估器或树的数量,即孤立森林中树的数量。这是一个可调的整数参数,默认值是 100;
- 最大样本:max_samples 是训练每个基评估器的样本的数量。如果 max_samples
比样本量更大,那么会用所用样本训练所有树。max_samples 的默认值是『auto』。如果值为『auto』的话,那么
max_samples=min(256, n_samples); - 数据污染问题:算法对这个参数非常敏感,它指的是数据集中离群值的期望比例,根据样本得分拟合定义阈值时使用。默认值是『auto』。如果取『auto』值,则根据孤立森林的原始论文定义阈值;
- 最大特征:所有基评估器都不是用数据集中所有特征训练的。这是从所有特征中提出的、用于训练每个基评估器或树的特征数量。该参数的默认值是 1。
model=IsolationForest(n_estimators=50, max_samples='auto', contamination=float(0.1),max_features=1.0)
model.fit(df[['area']])
算法实现:
直接调用包: from sklearn.ensemble import IsolationForest
iso_forest = IsolationForest(n_estimators=125)
iso_df = fit_model(iso_forest, df)
iso_df['Predictions'] = iso_df['Predictions'].map(lambda x: 1 if x==-1 else 0)
plot_anomalies(iso_df)

3.MAD(Median Absolute Deviation)
中位数绝对偏差是每个观测值与这些观测值中位数之间的差值。
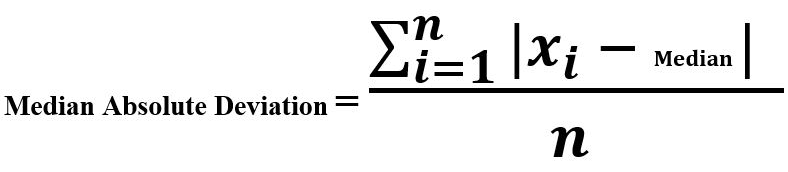
算法实现:调用from pyod.models.mad import MAD
#MAD
#threshold : float, optional (default=3.5)
# The modified z-score to use as a threshold. Observations with
# a modified z-score (based on the median absolute deviation) greater
# than this value will be classified as outliers.
mad_model = MAD()
mad_df = fit_model(mad_model, df)
plot_anomalies(mad_df)
Z-score分布图
What is a Modified Z-Score? (Definition & Example):https://www.statology.org/modified-z-score/
(1) 在统计学中,z分数表示一个值离均值有多少个标准差。公式为:
Z-Score = (xi – μ) / σ
- xi: A single data value;
- μ: The mean of the dataset;
- σ: The standard deviation of the dataset.
(2) z分数通常用于检测数据集中的异常值。例如,z分数小于-3或大于3的观察结果通常被认为是离群值。然而,z分数可能会受到异常大或小的数据值的影响,所以需要修正的Z值:
Modified z-score = 0.6745(xi – x̃) / MAD
- x̃: The median of the dataset;
- MAD: The median absolute deviation of the dataset;
Iglewicz和Hoaglin建议,修改后的z值小于-3.5或大于3.5的值被标记为潜在的离群值。
修改后的z-score更稳健,因为它使用中值来计算z-score,而不是已知的受异常值影响的平均值。
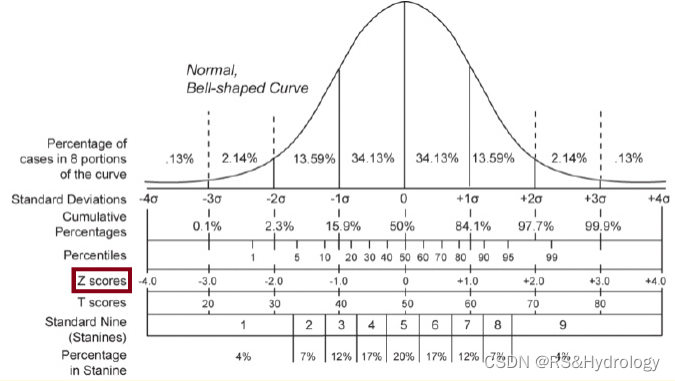
(转载自wikipedia)
更新:整体代码
#test
df = pd.read_excel(r'./1.xlsx')
filter_data = df[(df['1']==0)]
# print(filter_data)
#filter data by MAD
#threshold : float, optional (default=3.5)
# The modified z-score to use as a threshold. Observations with
# a modified z-score (based on the median absolute deviation) greater
# than this value will be classified as outliers.
def fit_model(model, data, column='Area'):
# fit the model and predict it
df = data.copy()
data_to_predict = data[column].to_numpy().reshape(-1, 1)
predictions = model.fit_predict(data_to_predict)
df['Predictions1'] = predictions
return df
def plot_anomalies(df, x='Date', y='Area'):
# categories will be having values from 0 to n
# for each values in 0 to n it is mapped in colormap
categories = df['Predictions1'].to_numpy()
colormap = np.array(['g', 'r'])
f = plt.figure(figsize=(12/2.54, 6/2.54))
f = plt.scatter(df[x], df[y], c=colormap[categories])
f = plt.xlabel(x)
f = plt.ylabel(y)
f = plt.xticks(rotation=0)
plt.show()
mad_model = MAD()
mad_df = fit_model(mad_model, df)
plot_anomalies(mad_df)
MAD算法:
def _mad(self, X):
"""
Apply the robust median absolute deviation (MAD)
to measure the distances of data points from the median.
Returns
-------
numpy array containing modified Z-scores of the observations.
The greater the score, the greater the outlierness.
"""
obs = np.reshape(X, (-1, 1))
# `self.median` will be None only before `fit()` is called
self.median = np.nanmedian(obs) if self.median is None else self.median
diff = np.abs(obs - self.median)
self.median_diff = np.median(diff) if self.median_diff is None else self.median_diff
return np.nan_to_num(np.ravel(0.6745 * diff / self.median_diff))
R语言中实现MAD算法:
mad(x, center = median(x), constant = 1.4826, na.rm = FALSE,
low = FALSE, high = FALSE)
参数说明:https://www.math.ucla.edu/~anderson/rw1001/library/base/html/mad.html

总结:
PyOD是一个全面的、可扩展的Python工具包,可以用来检测异常值。可以直接调用里面的模型。
PyOD网址:https://github.com/yzhao062/pyod
使用方法:如调用MAD模型
# train the MAD detector
from pyod.models.mad import MAD
clf = MAD()
clf.fit(X_train)
# get outlier scores
y_train_scores = clf.decision_scores_ # raw outlier scores on the train data
y_test_scores = clf.decision_function(X_test) # predict raw outlier scores on test
参考资料:
A walkthrough of Univariate Anomaly Detection in Python(很好学习资料):https://www.analyticsvidhya.com/blog/2021/06/univariate-anomaly-detection-a-walkthrough-in-python/
隔离森林算法:https://blog.csdn.net/ChenVast/article/details/82863750
异常值检测总结pyod包:https://blog.csdn.net/weixin_43822124/article/details/112523303
更新20220729
1.参考资料:异常检测专题(2)- 统计学方法 https://zhuanlan.zhihu.com/p/343748853
这里提到一种非参数方法,基于直方图的算法,Histogram-based Outlier Score (HBOS)。
它的思路是假定每个维度之间相互独立,分别计算每个维度的概率密度,最后合并成总体的概率密度,再根据概率密度计算异常分数值。
优点:HBOS方法的优势是计算速度较快,对大数据集友好。
缺点:但是异常识别的效果一般,且针对特征间比较独立的场景。
总之,HBOS在全局异常检测问题上表现良好,但不能检测局部异常值。但是HBOS比标准算法快得多,尤其是在大数据集上。
公式:
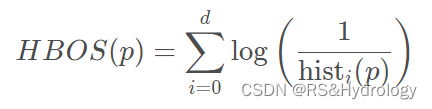
2.几种过滤数据的方法:http://cms.dt.uh.edu/faculty/delavinae/F03/3309/Ch03bHandout.PDF

图片截取自:http://cms.dt.uh.edu/faculty/delavinae/F03/3309/Ch03bHandout.PDF

智能推荐
java垃圾分类系统(ssm)-程序员宅基地
文章浏览阅读878次,点赞19次,收藏20次。随着社会经济的快速发展与人口的持续增长,城市生活垃圾的产生量日益增多,垃圾处理问题成为摆在各大城市面前的一大难题。传统的混合收集、集中填埋或焚烧的处理方式不仅耗费大量的土地资源,而且容易造成环境污染和资源的浪费。垃圾分类作为解决这一问题的有效手段,通过将生活垃圾按照其性质分为可回收物、有害垃圾、湿垃圾(厨余垃圾)和干垃圾等类别进行分别处理,可以显著提高资源的回收利用率,减少对环境的污染。然而,由于公众环保意识的不足、分类系统的不完善以及相关设施的缺乏,导致垃圾分类工作难以有效推行。
[linux基础]基于fdisk磁盘分盘与挂载_fdisk新建分区挂载-程序员宅基地
文章浏览阅读189次。你可以按回车键使用默认的值,或按照需求指定分区的大小,可以根据p显示的分区表,选择上一个分区的end+1作为分区的start,大小计算一般是 1G = (1 * 1024 * 1024 * 1024) / 512,也可以选择使用**+1G**,end输入数值或者+1G都可。可以看到已经挂载的mmcblk0p1占未挂载的mmcblk0的7.2G(未挂载29.8-7.2G)在创建新分区后,你可以使用以下命令重新加载分区表,使新分区生效。根据提示输入分区类型,通常选择主分区(输入。接下来要输入命令自定义分区。_fdisk新建分区挂载
生成式AI时代,AI副业变现资源汇总-程序员宅基地
文章浏览阅读1k次,点赞23次,收藏24次。这是一个ai副业赚钱资讯信息的大合集,将在全网搜索并整理ai副业赚钱的相关方法、技术、工具、以及一些可以赚钱的平台和渠道。期望能在AI时代,打破信息茧房,让大家都能在这个时代利用AI智能化做副业,赚取工作之余的额外收益。
《穿越火线》几次体验良好的游戏优化方案_cf优化-程序员宅基地
文章浏览阅读1k次。穿越火线几次体验良好的游戏优化方案。_cf优化
蓝桥杯python部分题目和答案分享(个人做法)易懂(4) [十题]_蓝桥杯python往届考题及答案-程序员宅基地
文章浏览阅读452次。蓝桥杯python部分题目和答案分享(个人做法)易懂(4) [十题]第三十一题:寻找2020,第三十二题:杨辉三角形,第三十三题:叶节点数,第三十四题:音节判断,第三十五题:预测身高,第三十六题:约数个数,第三十七题:求最大质因数(分解),第三十八题:饮料换购,第三十九题:刷题统计(统计刷题多少天完成),第四十题:天干地支_蓝桥杯python往届考题及答案
C++入门(2)_c++ 2鈥榟3-程序员宅基地
文章浏览阅读60次。引用与指针不同:1.不存在空引用。引用必须连接到一块合法的内存。2.一旦引用被初始化为一个对象,就不能被指向到另一个对象。指针可以在任何时候指向到另一个对象。3.引用必须在创建时被初始化。指针可以在任何时间被初始化。日期与时间C++ 程序中引用 头文件四个与时间相关的类型:clock_t、time_t、size_t 和 tm。类型 clock_t、size_t 和 time_t ..._c++ 2鈥榟3
随便推点
Ubuntu完整卸载postgresql_ubuntu22.04 卸载postgresql-程序员宅基地
文章浏览阅读2.1w次,点赞2次,收藏30次。删除相关的安装sudo apt-get --purge remove postgresql\*删除配置及文相关件sudo rm -r /etc/postgresql/sudo rm -r /etc/postgresql-common/sudo rm -r /var/lib/postgresql/删除用户和所在组sudo userdel -r postgressudo groupdel_ubuntu22.04 卸载postgresql
Ubuntu16.04下Caffe环境搭建的坑之import caffe 报错AttributeError: ‘numpy.ufunc’ object has no attribute‘module’_object has no attribute 'module-程序员宅基地
文章浏览阅读2.6k次。Ubuntu16.04系统下Caffe环境搭建的坑之import caffe 报错:AttributeError: ‘numpy.ufunc’ object has no attribute ‘module’这个错误是numpy版本不兼容的原因。我之前安装的是numpy1.1.6,一直报上面的错。然后找了几十篇博客才发现是numpy版本的原因。我建议安装numpy1.11.0。解决步骤:1...._object has no attribute 'module
Java复习——多线程_java多线程复习-程序员宅基地
文章浏览阅读181次。Java多线程和四种线程实现方式_java多线程复习
18. 离职原因:让 BOSS 学习“滚动加载”这一名词_滚动加载 python flask-程序员宅基地
文章浏览阅读1.4w次,点赞2次,收藏3次。本案例最后一个步骤时补齐JS代码,经过反复测试 ,插件的引入和使用需要在 DOM 对象之后,代码如下。_滚动加载 python flask
IDEA项目目录结构视图无法显示--原理剖析及解决方案_idea 视图选不了项目了-程序员宅基地
文章浏览阅读1.5k次,点赞14次,收藏14次。项目成功建立后,关闭IDEA,再次打开项目,发现项目的目录结构视图“莫名消失”?如图所示。_idea 视图选不了项目了
盛世长缨rt8188gu安装网卡驱动(Ubuntu)_盛世长缨无线网卡驱动下载-程序员宅基地
文章浏览阅读9.2k次,点赞2次,收藏17次。盛世长缨rt8188gu安装网卡驱动(Ubuntu)文章目录盛世长缨rt8188gu安装网卡驱动(Ubuntu)1.硬件说明(Ubuntu18.04下安装)2.安装步骤学习记录如上1.硬件说明(Ubuntu18.04下安装)使用的无线网卡如下,为盛世长缨150M迷你版:2.安装步骤代码如下:sudo apt install git//安装gitsudo apt upgrade cd ~ git clone https://github.com/McMCCRU/rtl8188gu.g_盛世长缨无线网卡驱动下载