五.Elasticsearch教程 - 查询优化 - 手工控制搜索结果精准度_operator": "and-程序员宅基地
技术标签: ElasticSearch java elasticsearch 数据库 es 大数据
注:version:elasticsearch-7.11.2
造测试数据:
#新建mapping映射
PUT /developer
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"index": true,
"store": true
},
"gender": {
"type": "integer",
"index": true,
"store": true
},
"age": {
"type": "integer",
"index": true,
"store": true
},
"remark": {
"type": "text",
"index": true,
"store": true,
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
},
"address": {
"type": "text",
"index": true,
"store": true,
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
},
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
#添加两条数据
POST _bulk
{"create":{"_index":"developer","_type":"_doc","_id":1}}
{"id":1,"name":"李雷","age":18,"gender":1,"remark":"是一个初级程序员","address": "浙江省杭州市西湖区"}
{"create":{"_index":"developer","_type":"_doc","_id":2}}
{"id":2,"name":"韩梅","age":17,"gender":0,"remark":"是一个女程序员","address": "安徽省合肥市蜀山区"}remark分词结果:
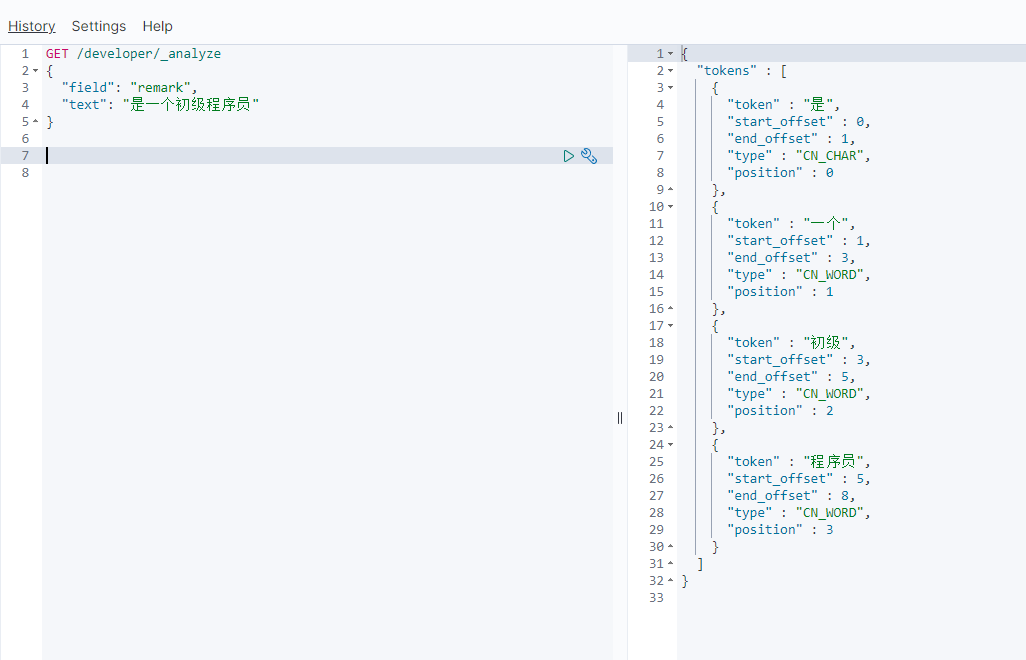
1.operator用法
GET /developer/_search
{
"query":{
"match": {
"remark": {
"query": "初级程序员",
"operator": "and"
}
}
}
}
"初级程序员"会被分词为"初级"和"程序员"。使用"operator": "and",就必须同时满足“初级”和“程序员”两个词。如果不写的话默认是"operator": "or"
2.minimum_should_match用法
minimum_should_match 用来控制最小匹配数量,可以是数字或百分比(例: 75%)。
GET /developer/_search
{
"query":{
"match": {
"remark": {
"query": "一个初级程序员",
"minimum_should_match": "3"
}
}
}
}
上图中的分词,可以匹配到3个词,分别是"一个"、"初级"、"程序员"。minimum_should_match 设置小于3的值都可以匹配到结果
搭配组合查询使用:
GET developer/_doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"remark": "一个"
}
},
{
"match": {
"remark": "初级"
}
},
{
"match": {
"remark": "女"
}
},
{
"match": {
"remark": "程序员"
}
}
],
"minimum_should_match": 3
}
}
}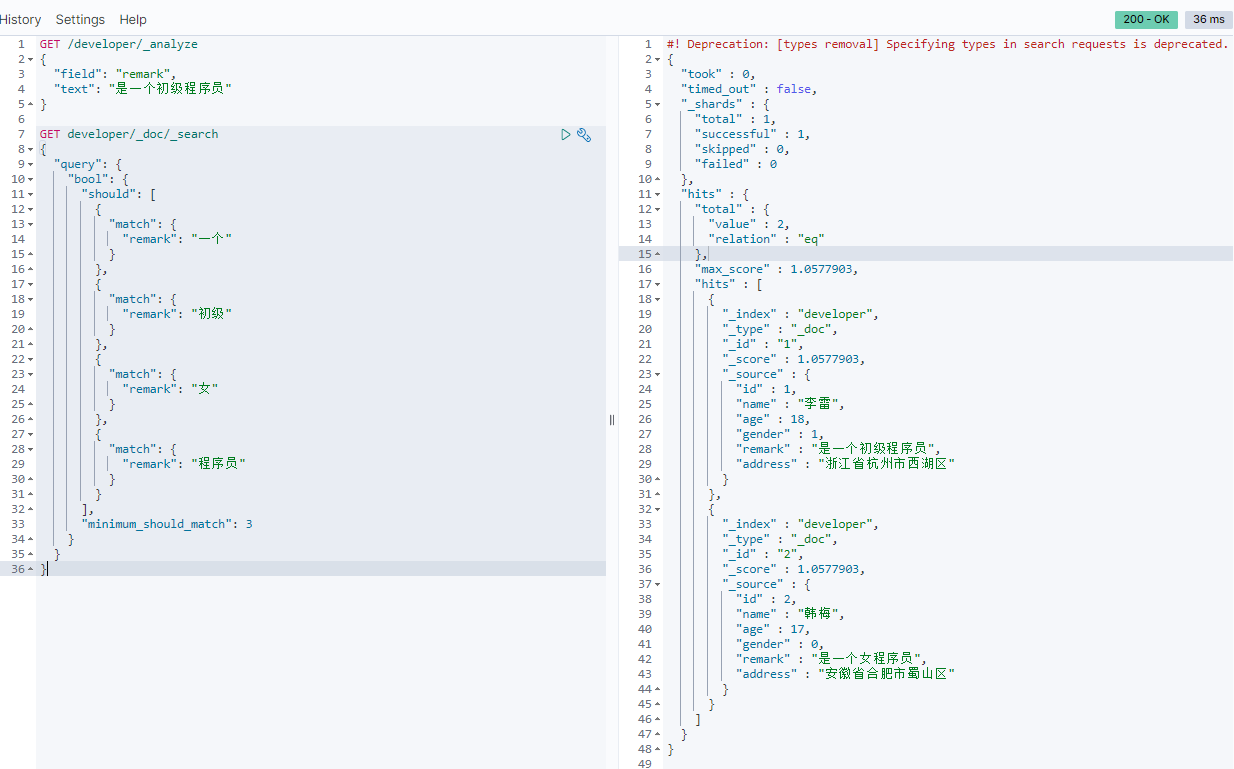
上图至少满足3个条件,所以把添加的两条数据都查询出来了。
3.match 的底层转换
在ES中,执行match搜索的时候,ES底层通常都会对搜索条件进行底层转换,把叶子查询转换为组合查询,来实现最终的搜索结果。例如:
1).operator为 or 时的拆分
原查询语句(没写operator时默认为or):
GET developer/_doc/_search
{
"query": {
"match": {
"remark":"初级程序员"
}
}
}由叶子查询转换为组合查询:
GET developer/_doc/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"remark": "初级"
}
},
{
"term": {
"remark": "程序员"
}
}
]
}
}
}2).operator为 and 时的拆分
原查询:
GET developer/_doc/_search
{
"query": {
"match": {
"remark": {
"query": "初级程序员",
"operator": "and"
}
}
}
}由叶子查询转换为组合查询:
GET developer/_doc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"remark": "初级"
}
},
{
"term": {
"remark": "程序员"
}
}
]
}
}
}建议,如果不怕麻烦,尽量使用转换后的语法执行搜索,效率更高。如果开发周期短,工作量大,使用简化的写法。
4.boost权重控制
GET developer/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"remark": "程序员"
}
}
],
"should": [
{
"match": {
"address": {
"query": "安徽省",
"boost": 2
}
}
},
{
"match": {
"address": {
"query": "浙江省",
"boost": 1
}
}
}
]
}
}
}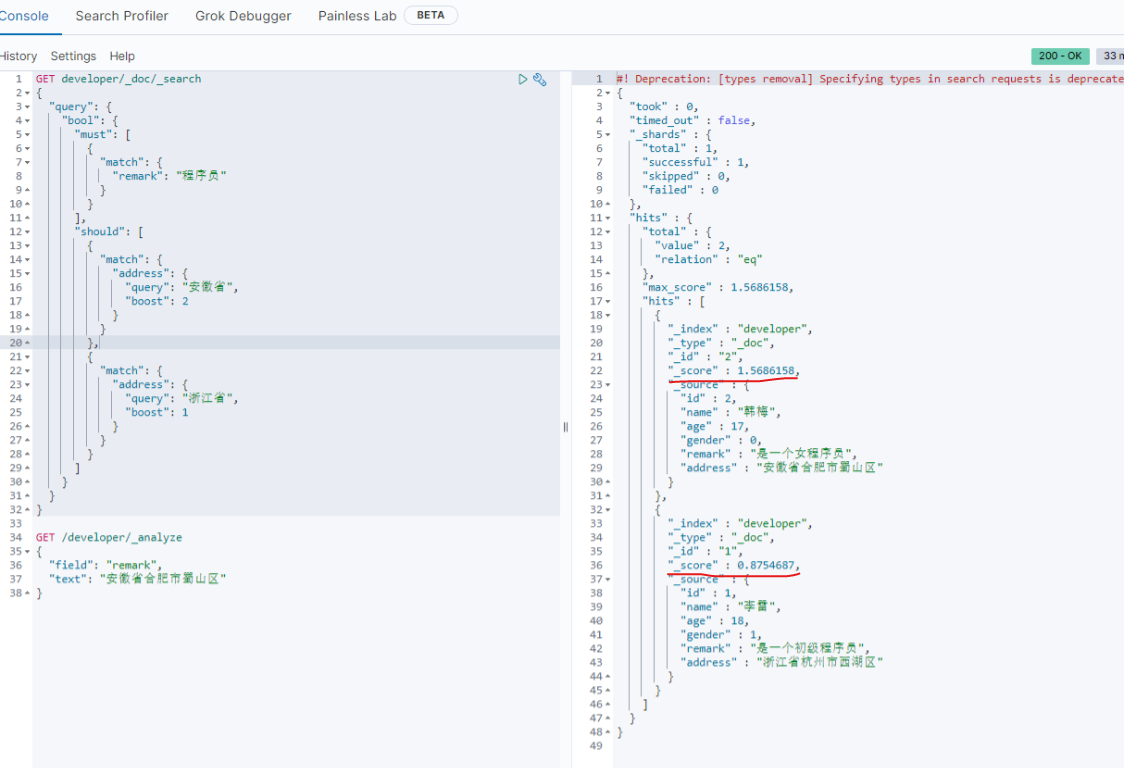
安徽省 和 浙江省 给的权重比例是2:1,查询结果 _score 分值安徽省更大,排在前面。
5.基于dis_max实现best fields策略进行多字段搜索
best fields策略: 搜索的document中的某一个field,尽可能多的匹配搜索条件。与之相反的是,尽可能多的字段匹配到搜索条件(most fields策略)。如百度搜索使用这种策略。
优点:精确匹配的数据可以尽可能的排列在最前端,且可以通过minimum_should_match来去除长尾数据,避免长尾数据字段对排序结果的影响。
长尾数据比如说我们搜索4个关键词,但很多文档只匹配1个,也显示出来了,这些文档其实不是我们想要的
缺点:相对排序不均匀。
dis_max语法: 直接获取搜索的多条件中的,单条件query相关度分数最高的数据,以这个数据做相关度排序。
GET /developer/_doc/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"remark": "女"
}
},
{
"match": {
"remark": "初级程序员"
}
}
]
}
}
}
以上查询的 queries 有 2 个条件,
"remark": "女" 匹配到一文档
"remark": "初级程序员" 匹配到两个文档
使用 "remark": "初级程序员" 查询的分值最高,那么"初级程序员"这条数据的分值更多,排序靠前。
6.基于tie_breaker参数优化dis_max搜索效果
dis_max 是将多个搜索query条件中相关度分数最高的用于结果排序,忽略其他query分数,在某些情况下,可能还需要其他query条件中的相关度介入最终的结果排序,这个时候可以使用 tie_breaker 参数来优化dis_max搜索。
tie_breaker 参数代表的含义是:将其他query搜索条件的相关度分数乘以参数值,再参与到结果排序中。如果不定义此参数,相当于参数值为0。所以其他query条件的相关度分数被忽略。
GET /developer/_doc/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"remark": "女"
}
},
{
"match": {
"remark": "初级程序员"
}
}
],
"tie_breaker":0.5
}
}
}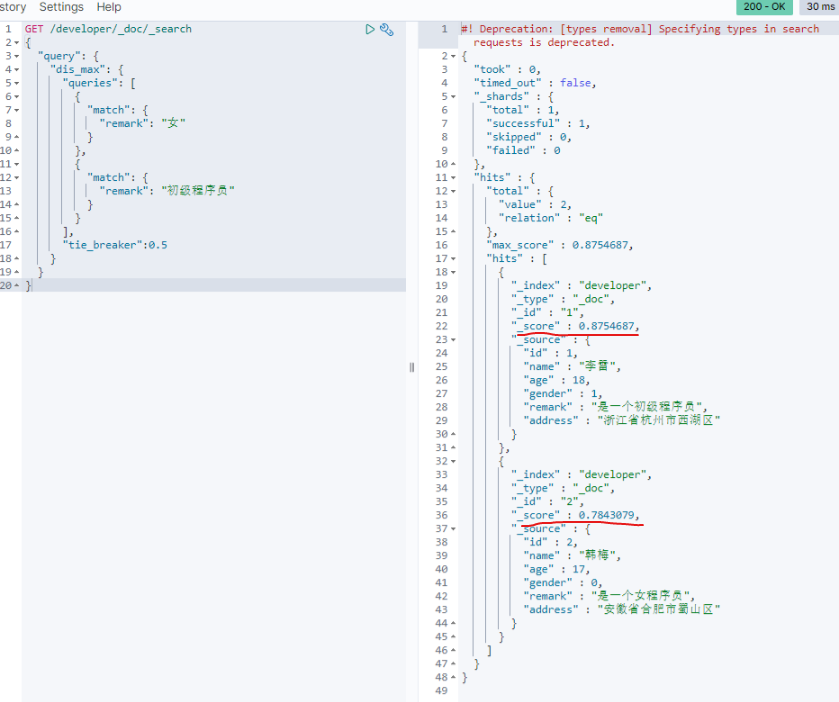
相比较下"韩梅"的分值有所增加
7.multi_match实现字段加权重查询
使用multi_match语法为:其中type常用的有 best_fields 和 most_fields。^n 代表权重,相当于 "boost":n
GET /developer/_doc/_search
{
"query": {
"multi_match": {
"query": "李雷一个程序员",
"fields": ["name", "remark^2"],
"type": "best_fields",
"tie_breaker": 0.5,
"minimum_should_match": 2
}
}
}minimum_should_match是针对分词后,每个条件的匹配个数的。比如这里分词为"李雷"、"一个"、"程序员"一共3个,那么name必须匹配其中两个,或者remark必须匹配其中两个
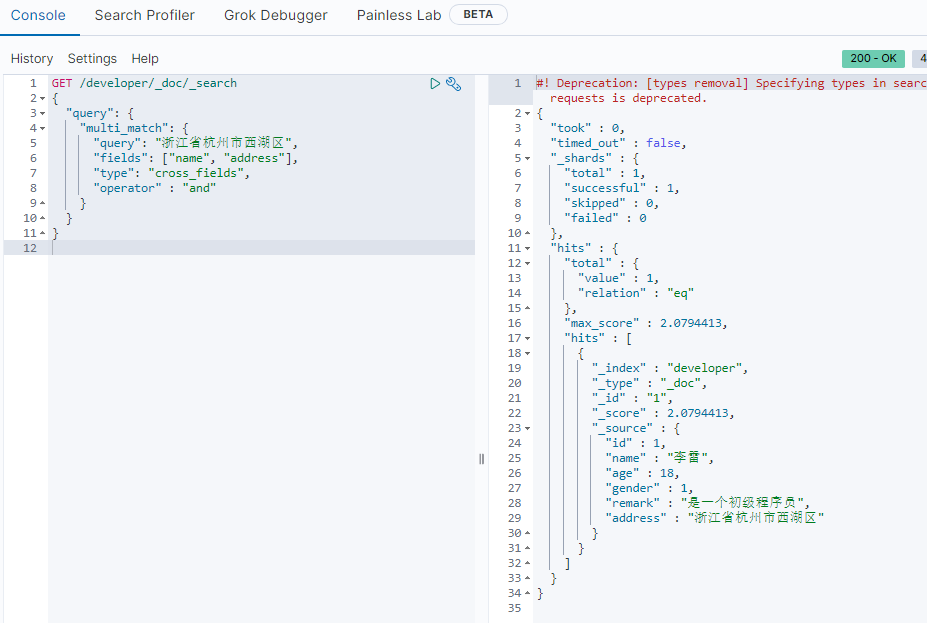
8.cross fields搜索
cross fields搜索:在多个fields中搜索唯一标识的数据。例如在多个字段中搜索人名、地址。
实现这种搜索,一般都是使用most fields搜索策略。因为这就不是一个field的问题。
Cross fields搜索策略,是从多个字段中搜索条件数据。默认情况下,和most fields搜索的逻辑是一致的,计算相关度分数是和best fields策略一致的。一般来说,如果使用cross fields搜索策略,那么都会携带一个额外的参数operator。用来标记搜索条件如何在多个字段中匹配。
most field策略缺点:most fields策略是尽可能匹配更多的字段,所以会导致精确搜索结果排序问题。又因为cross fields搜索,不能使用minimum_should_match来去除长尾数据。所以在使用most fields和cross fields策略搜索数据的时候,都有不同的缺陷。所以商业项目开发中,都推荐使用best fields策略实现搜索。
GET /developer/_doc/_search
{
"query": {
"multi_match": {
"query": "浙江省杭州市西湖区",
"fields": ["name", "address"],
"type": "cross_fields",
"operator" : "and"
}
}
}
9.copy_to组合fields
在搜索地址的时候,需要同时在省、市、街道、3个字段同时搜索,怎么做呢?
第一种方法可以使用 multi_match ,上面有写过实例。
此处讲第二种方法,使用 copy_to 组合 fields
copy_to : 就是将多个字段,复制到一个字段中,实现一个多字段组合。copy_to可以解决cross fields搜索问题,在商业项目中,也用于解决搜索条件默认字段问题。
如果需要使用copy_to语法,则需要在定义index的时候,手工指定mapping映射策略。
copy_to语法:
PUT /address/_mapping
{
"properties": {
"provice": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "address"
},
"city": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "address"
},
"street": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "address"
},
"address": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}以上mapping会把provice、city、street三个字段的值,会自动复制到address字段中,实现一个字段的组合。那么在搜索地址的时候,就可以在address字段中做条件匹配,从而避免most fields策略导致的问题。在维护数据的时候,不需对address字段特殊的维护。因为address字段是一个组合字段,是由ES自动维护的。类似java代码中的推导属性。在存储的时候,未必存在,但是在逻辑上是一定存在的,因为address是由3个物理存在的属性province、city、street组成的。
10.match phrase 短语匹配
match phrase:短语匹配。代表搜索条件不可分割。
造测试数据:
#新建索引
PUT /test_match_phrase
#为索引添加映射
PUT /test_match_phrase/_mappings
{
"properties": {
"remark":{
"type": "text",
"analyzer": "standard"
}
}
}
#添加两条测试数据
POST /_bulk
{"create":{"_index": "test_match_phrase", "_type":"_doc", "_id": 1}}
{"id":1,"remark": "Hellow world"}
{"create":{"_index": "test_match_phrase", "_type":"_doc", "_id": 2}}
{"id":2,"remark": "Hellow daliu, I love the world"}# Hellow world 短语匹配
GET /test_match_phrase/_search
{
"query": {
"match_phrase": {
"remark": "Hellow world"
}
}
}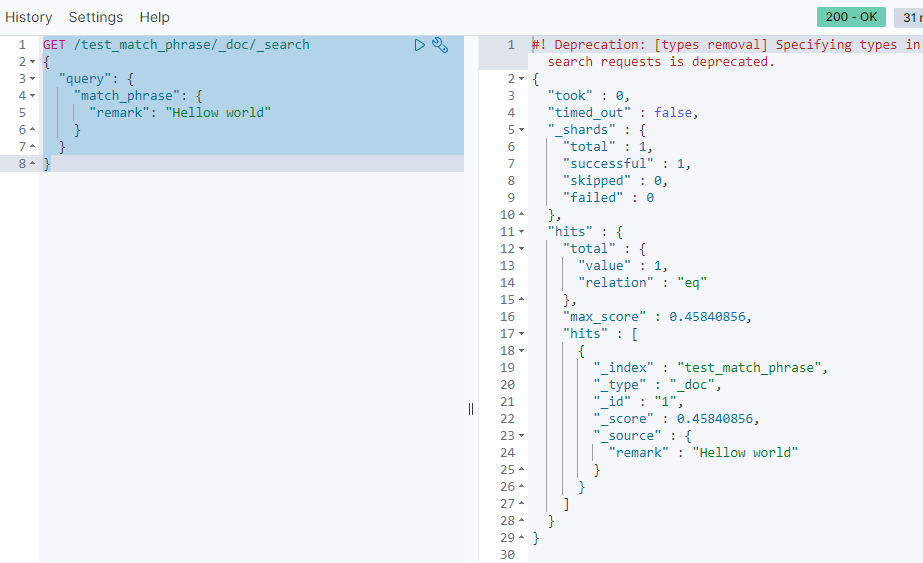
如上图这样只能匹配到 id=1 的文档。
match phrase原理
1.文档在建立的时候会进行分词,并建立倒排索引,分词结果如下:
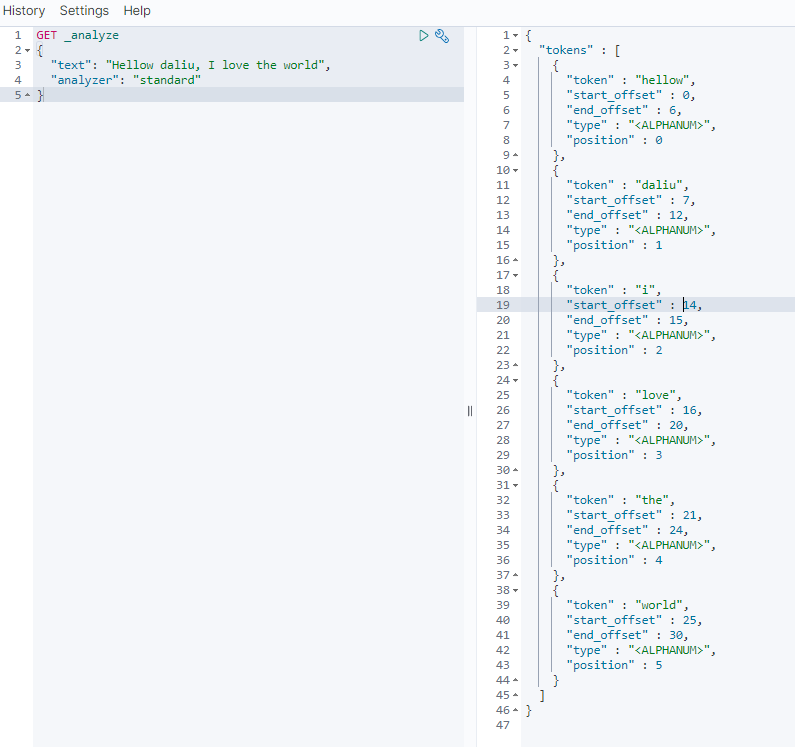
position:以词为单位,代表这个词在整个数据中的下标。
倒排索引建立如下:(word记录分词,index 记录分词所在的文档id)
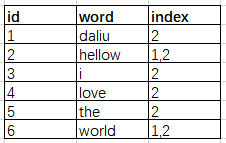
2.将搜索条件 "Hellow world" 分词为 "Hellow" 和 "world",然后在倒排索引中进行检索,匹配到文档id包含[1,2] 的两个文档,然后分别在这两个文档中检查"Hellow"和"world"的position是否连续,如果是连续的则代表成功,否则失败。此例中文档id=1的那个文档的position是连续的,所以返回了文档id=1的那条数据。
match phrase搜索参数:slop
slop代表match phrase短语搜索的时候,单词最多移动多少次,可以实现数据匹配。在所有匹配结果中,多个单词距离越近,相关度评分越高,排序越靠前。
这种使用slop参数的match phrase搜索,就称为近似匹配(proximity search)
上面的查询语句加上slop参数:
GET /test_match_phrase/_search
{
"query": {
"match_phrase": {
"remark": {
"query": "Hellow world",
"slop": 4
}
}
}
}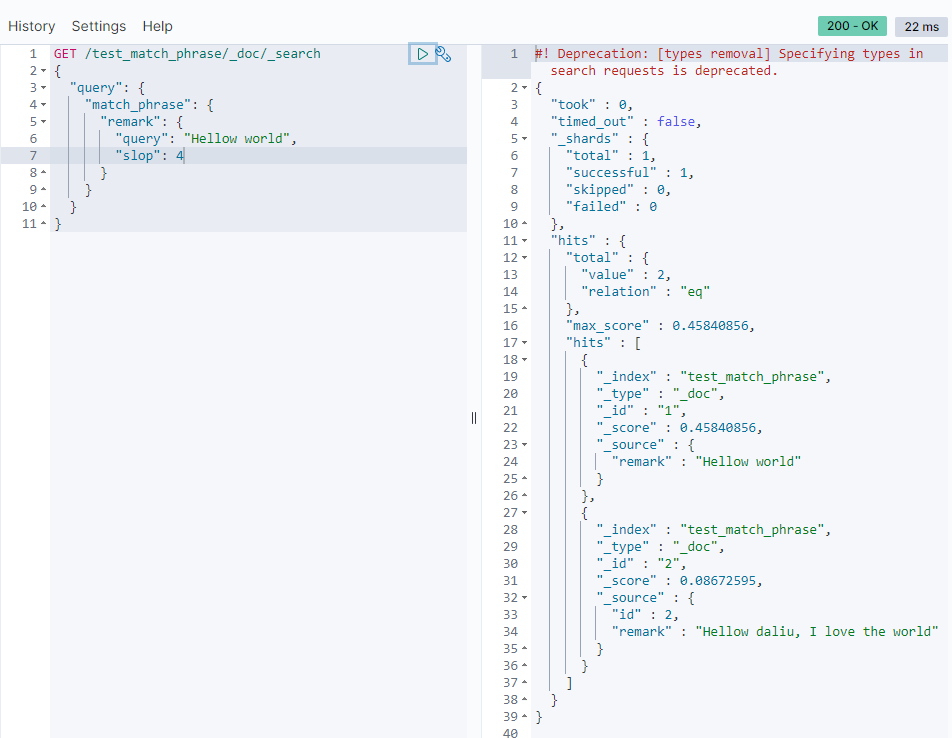
如上图,加上slop:4的参数就可以匹配到id=2的文档
上面的 slop:4 代表可以移动4次。
原理:
搜索条件"Hellow world"被分词为"Hellow"和"world"两个,在倒排索引中匹配到文档[1,2]后,在这两个文档中检查position,在index=2的文档中会根据slop参数执行单词的移动。
如下:
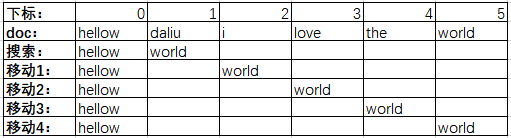
移动4的时候匹配成功
11.前缀搜索 prefix search
GET /developer/_search
{
"query": {
"prefix": {
"address": {
"value": "浙江省"
}
}
}
}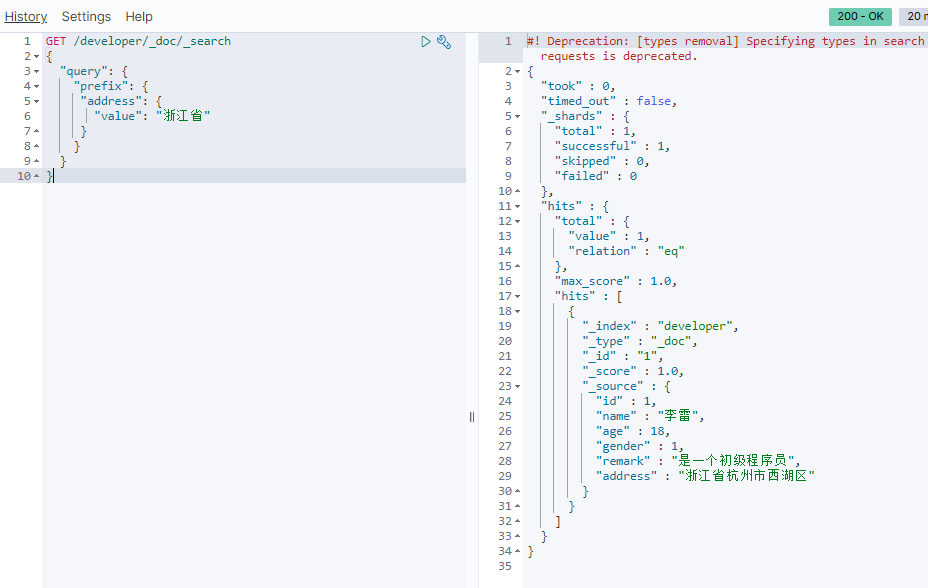
前缀搜索效率比较低。前缀搜索不会计算相关度分数。前缀越短,效率越低。如果使用前缀搜索,建议使用长前缀。因为前缀搜索需要扫描完整的索引内容,所以前缀越长,相对效率越高。
12.通配符搜索 wildcard search
ES中也有通配符。但是和java还有数据库不太一样。通配符可以在倒排索引中使用,也可以在keyword类型字段中使用。
常用通配符:
? - 一个任意字符
* - 0~n个任意字符
GET /test_match_phrase/_search
{
"query": {
"wildcard": {
"remark": "*da*"
}
}
}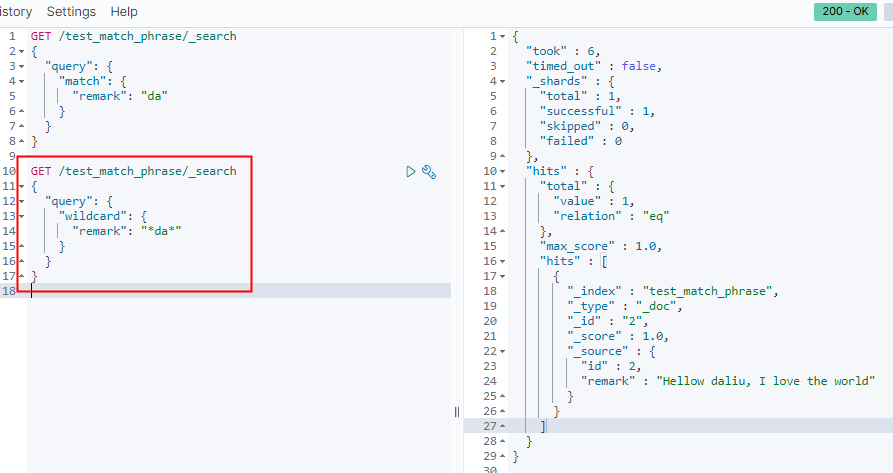
使用通配符模糊匹配,即使在分词匹配不到的时候也能搜索到结果
性能也很低,也是需要扫描完整的索引。不推荐使用。
13.正则搜索 regexp
ES支持正则表达式。可以在倒排索引或keyword类型字段中使用。
常用符号:
[] :范围,如 [0-9]是0~9的范围数字
. : 一个字符
+ :前面的表达式可以出现多次。
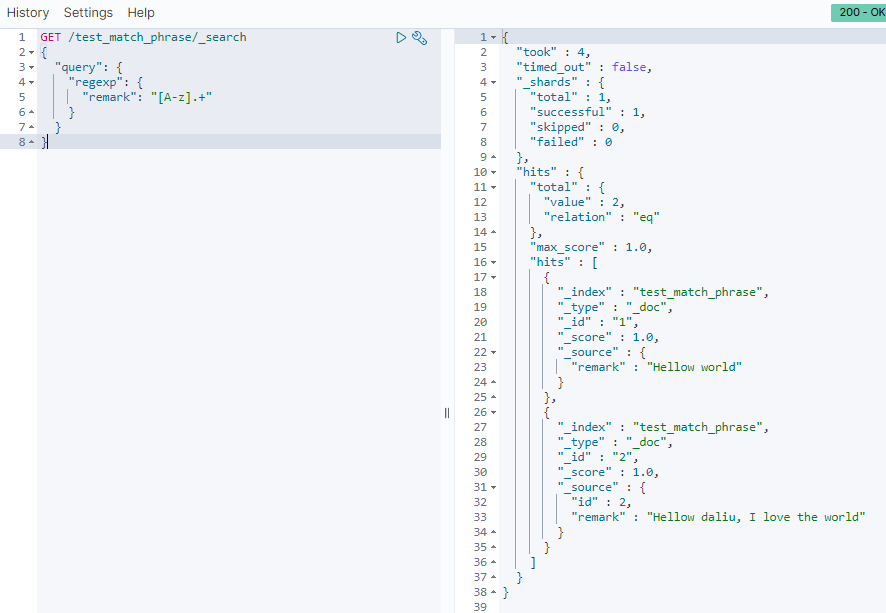
GET /test_match_phrase/_search
{
"query": {
"regexp": {
"remark": "[A-z].+"
}
}
}
14.搜索推荐 match_phrase_prefix
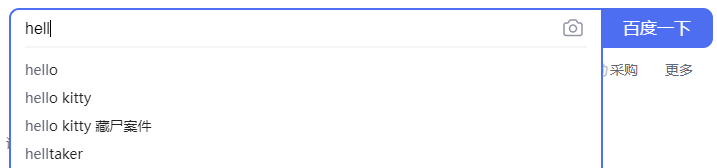
实现类似百度的这种效果。
match_phrase_prefix 的作用正如其名,就是 match_phrase + prefix
不但可以前缀匹配,而且可以移动词匹配
GET /test_match_phrase/_search
{
"query": {
"match_phrase_prefix": {
"remark": {
"query": "Hellow w",
"slop" : 4,
"max_expansions": 10
}
}
}
}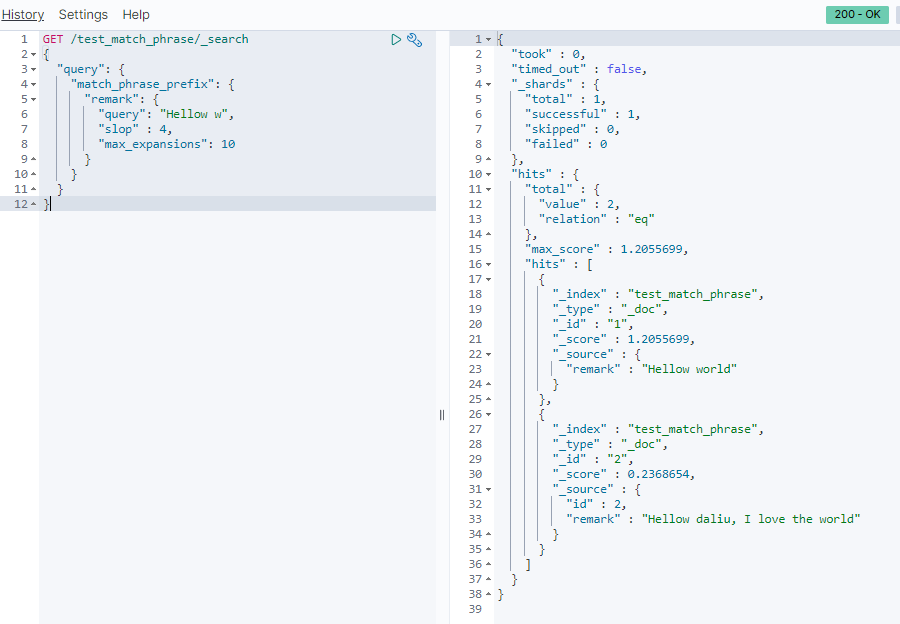
slop: 如同match_phrase一样,指定最大分词位数。
max_expansions: 指定prefix最多匹配多少个term(单词)。
这种语法的限制是,只有最后一个term会执行前缀搜索。
执行性能很差,毕竟最后一个term是需要扫描所有符合slop要求的倒排索引的term。
因为效率较低,如果必须使用,则一定要使用参数max_expansions。
15.模糊搜索技术 fuzzy
搜索的时候可能输入错误,例如 "hellow world" 输入成了 "hellow word"。fuzzy可以让这种拼写错误也能查询数据(在英文中很有效,在中文中几乎无效)
GET /test_match_phrase/_search
{
"query": {
"fuzzy": {
"remark": {
"value": "word",
"fuzziness":2
}
}
}
}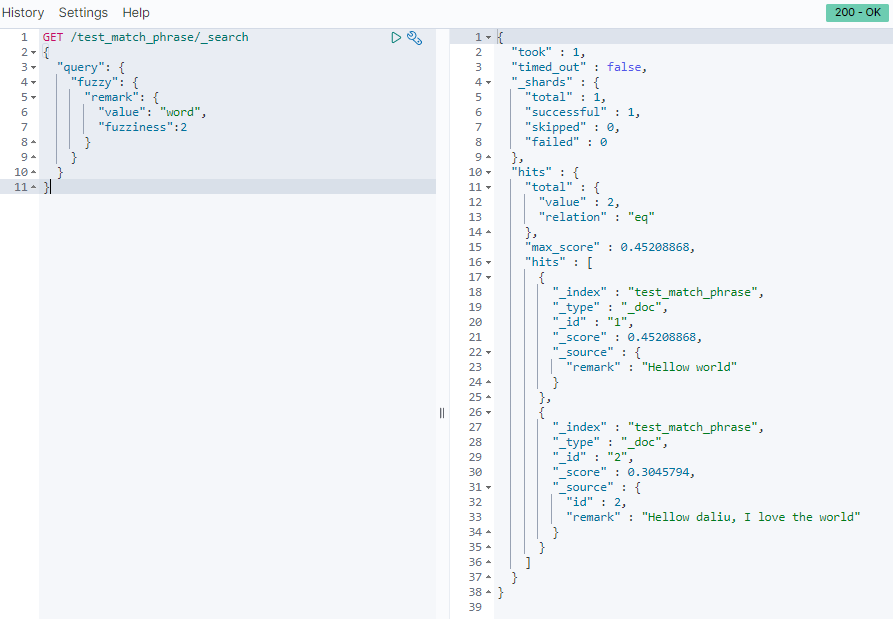
fuzziness:允许字母误差个数。代表value的值word可以修改多少个字母来进行拼写错误的纠正(修改字母的数量包含字母变更,增加或减少字母),例如本例中的 world 去掉 l 就能匹配上,所以fuzziness = 1的时候也能查询出结果
智能推荐
使用nginx解决浏览器跨域问题_nginx不停的xhr-程序员宅基地
文章浏览阅读1k次。通过使用ajax方法跨域请求是浏览器所不允许的,浏览器出于安全考虑是禁止的。警告信息如下:不过jQuery对跨域问题也有解决方案,使用jsonp的方式解决,方法如下:$.ajax({ async:false, url: 'http://www.mysite.com/demo.do', // 跨域URL ty..._nginx不停的xhr
在 Oracle 中配置 extproc 以访问 ST_Geometry-程序员宅基地
文章浏览阅读2k次。关于在 Oracle 中配置 extproc 以访问 ST_Geometry,也就是我们所说的 使用空间SQL 的方法,官方文档链接如下。http://desktop.arcgis.com/zh-cn/arcmap/latest/manage-data/gdbs-in-oracle/configure-oracle-extproc.htm其实简单总结一下,主要就分为以下几个步骤。..._extproc
Linux C++ gbk转为utf-8_linux c++ gbk->utf8-程序员宅基地
文章浏览阅读1.5w次。linux下没有上面的两个函数,需要使用函数 mbstowcs和wcstombsmbstowcs将多字节编码转换为宽字节编码wcstombs将宽字节编码转换为多字节编码这两个函数,转换过程中受到系统编码类型的影响,需要通过设置来设定转换前和转换后的编码类型。通过函数setlocale进行系统编码的设置。linux下输入命名locale -a查看系统支持的编码_linux c++ gbk->utf8
IMP-00009: 导出文件异常结束-程序员宅基地
文章浏览阅读750次。今天准备从生产库向测试库进行数据导入,结果在imp导入的时候遇到“ IMP-00009:导出文件异常结束” 错误,google一下,发现可能有如下原因导致imp的数据太大,没有写buffer和commit两个数据库字符集不同从低版本exp的dmp文件,向高版本imp导出的dmp文件出错传输dmp文件时,文件损坏解决办法:imp时指定..._imp-00009导出文件异常结束
python程序员需要深入掌握的技能_Python用数据说明程序员需要掌握的技能-程序员宅基地
文章浏览阅读143次。当下是一个大数据的时代,各个行业都离不开数据的支持。因此,网络爬虫就应运而生。网络爬虫当下最为火热的是Python,Python开发爬虫相对简单,而且功能库相当完善,力压众多开发语言。本次教程我们爬取前程无忧的招聘信息来分析Python程序员需要掌握那些编程技术。首先在谷歌浏览器打开前程无忧的首页,按F12打开浏览器的开发者工具。浏览器开发者工具是用于捕捉网站的请求信息,通过分析请求信息可以了解请..._初级python程序员能力要求
Spring @Service生成bean名称的规则(当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致)_@service beanname-程序员宅基地
文章浏览阅读7.6k次,点赞2次,收藏6次。@Service标注的bean,类名:ABDemoService查看源码后发现,原来是经过一个特殊处理:当类的名字是以两个或以上的大写字母开头的话,bean的名字会与类名保持一致public class AnnotationBeanNameGenerator implements BeanNameGenerator { private static final String C..._@service beanname
随便推点
二叉树的各种创建方法_二叉树的建立-程序员宅基地
文章浏览阅读6.9w次,点赞73次,收藏463次。1.前序创建#include<stdio.h>#include<string.h>#include<stdlib.h>#include<malloc.h>#include<iostream>#include<stack>#include<queue>using namespace std;typed_二叉树的建立
解决asp.net导出excel时中文文件名乱码_asp.net utf8 导出中文字符乱码-程序员宅基地
文章浏览阅读7.1k次。在Asp.net上使用Excel导出功能,如果文件名出现中文,便会以乱码视之。 解决方法: fileName = HttpUtility.UrlEncode(fileName, System.Text.Encoding.UTF8);_asp.net utf8 导出中文字符乱码
笔记-编译原理-实验一-词法分析器设计_对pl/0作以下修改扩充。增加单词-程序员宅基地
文章浏览阅读2.1k次,点赞4次,收藏23次。第一次实验 词法分析实验报告设计思想词法分析的主要任务是根据文法的词汇表以及对应约定的编码进行一定的识别,找出文件中所有的合法的单词,并给出一定的信息作为最后的结果,用于后续语法分析程序的使用;本实验针对 PL/0 语言 的文法、词汇表编写一个词法分析程序,对于每个单词根据词汇表输出: (单词种类, 单词的值) 二元对。词汇表:种别编码单词符号助记符0beginb..._对pl/0作以下修改扩充。增加单词
android adb shell 权限,android adb shell权限被拒绝-程序员宅基地
文章浏览阅读773次。我在使用adb.exe时遇到了麻烦.我想使用与bash相同的adb.exe shell提示符,所以我决定更改默认的bash二进制文件(当然二进制文件是交叉编译的,一切都很完美)更改bash二进制文件遵循以下顺序> adb remount> adb push bash / system / bin /> adb shell> cd / system / bin> chm..._adb shell mv 权限
投影仪-相机标定_相机-投影仪标定-程序员宅基地
文章浏览阅读6.8k次,点赞12次,收藏125次。1. 单目相机标定引言相机标定已经研究多年,标定的算法可以分为基于摄影测量的标定和自标定。其中,应用最为广泛的还是张正友标定法。这是一种简单灵活、高鲁棒性、低成本的相机标定算法。仅需要一台相机和一块平面标定板构建相机标定系统,在标定过程中,相机拍摄多个角度下(至少两个角度,推荐10~20个角度)的标定板图像(相机和标定板都可以移动),即可对相机的内外参数进行标定。下面介绍张氏标定法(以下也这么称呼)的原理。原理相机模型和单应矩阵相机标定,就是对相机的内外参数进行计算的过程,从而得到物体到图像的投影_相机-投影仪标定
Wayland架构、渲染、硬件支持-程序员宅基地
文章浏览阅读2.2k次。文章目录Wayland 架构Wayland 渲染Wayland的 硬件支持简 述: 翻译一篇关于和 wayland 有关的技术文章, 其英文标题为Wayland Architecture .Wayland 架构若是想要更好的理解 Wayland 架构及其与 X (X11 or X Window System) 结构;一种很好的方法是将事件从输入设备就开始跟踪, 查看期间所有的屏幕上出现的变化。这就是我们现在对 X 的理解。 内核是从一个输入设备中获取一个事件,并通过 evdev 输入_wayland