Kubernetes Pod自动扩容和缩容 基于自定义指标_the kubernetes api could not find version "v2beta2-程序员宅基地
技术标签: kubernetes
[root@master ~]# kubectl get hpa -o yaml
apiVersion: v1
items:
- apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
annotations:这两个版本的区别是 autoscaling/v1支持了 :
- Resource Metrics(资源指标)
- Custom Metrics(自定义指标)
要使用自定义指标,也就是用户提供的指标,去参考着并且扩容,这个时候就需要用到其v2版本。
而在 autoscaling/v2beta2的版本中额外增加了External Metrics(扩展指标)的支持。
(基于Prometheus来获取资源指标,基于微软云服务获取指标等)
目前最成熟的就是Prometheus adapter,现在很多都是基于其实现hpa扩展。
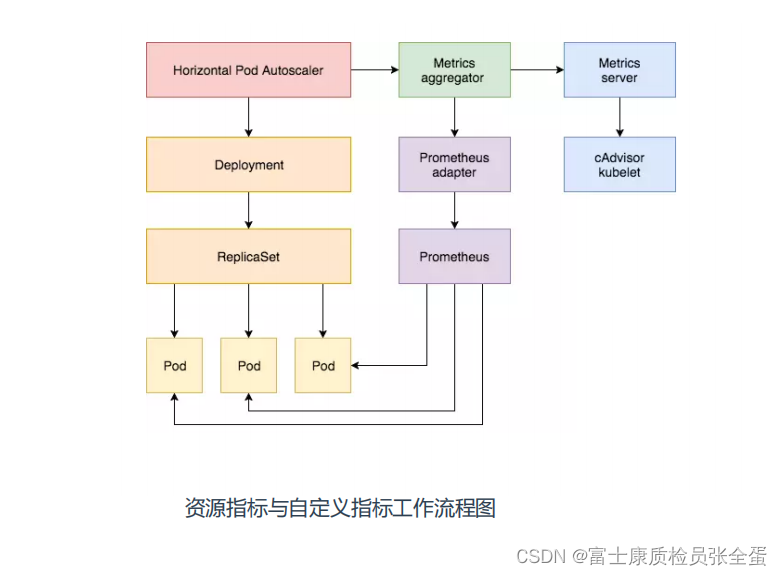
和之前的HPA扩容类似。
之前基于cpu实现HPA扩容:metrics server从kubelet cadvisor里面获取数据,获取完数据注册到api server的聚合层里面,hpa请求的是聚合层。(图最右边的步骤)
同理现在要基于自定义的指标,就图上面中间的步骤,基于自定义指标,那么指标就需要用户来提供,通过应用程序来提供,也就是要从pod当中获取应用程序暴露出来的指标,暴露出来的数据由Prometheus采集到,Prometheus adapater充当适配器,即中间转换器的作用,因为hpa是不能直接识别Prometheus当中的数据的,要想获取Prometheus当中的数据就需要一定的转换,这个转换就需要使用Prometheus adapter去做的。
prometheus adapter注册到聚合层,api server代理当中,所以当你访问custom.metrics.k8s.io API这个接口的时候会帮你转发到prometheus adapter当中,就类似于metric server,然后从Prometheus当中去查询数据,再去响应给hpa,hap拿到指标数据就开始对比的你阈值,是不是触发了,触发了就扩容。
示例
假设我们有一个网站,想基于每秒接收到的HTTP请求对其Pod进行自动缩放,实现HPA大概步骤:
制作好demo
先模拟自己开发一个网站,采用Python Flask Web框架,写两个页面:
- / 首页
- /metrics 指标
可以看到制作镜像和启动容器是没有问题的
[root@master metrics-app]# ls
Dockerfile main.py metrics-flask-app.yaml
[root@master metrics-app]# docker run -itd metrics-flask-app:latest
[root@master metrics-app]# docker logs 51d5afe9d7f8
* Serving Flask app 'main' (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on all addresses (0.0.0.0)
WARNING: This is a development server. Do not use it in a production deployment.
* Running on http://127.0.0.1:80
* Running on http://172.17.0.2:80 (Press CTRL+C to quit)访问该服务的接口,有两个,一个是正常提供的服务hello world,另外一个是暴露的指标接口,这个指标是由prometheus 客户端去组织的。
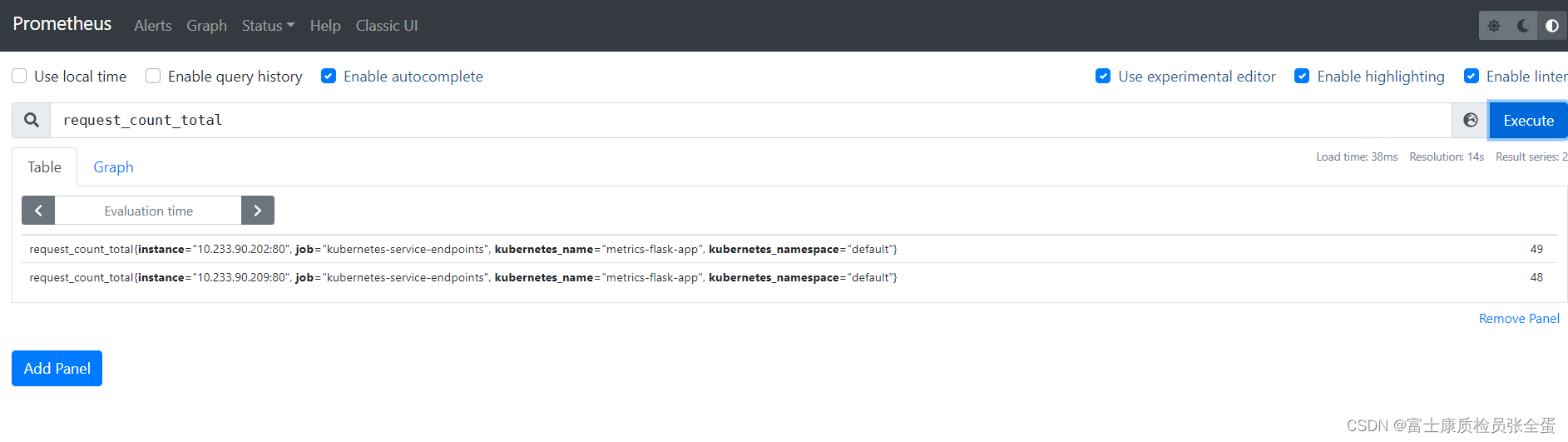
下面是基于request_count_total 2.0这个指标去扩容的。这个是记录访问这个接口的次数
[root@master metrics-app]# docker inspect 51d5afe9d7f8 | grep IPAddress
"SecondaryIPAddresses": null,
"IPAddress": "172.17.0.2",
"IPAddress": "172.17.0.2",
[root@master metrics-app]# curl 172.17.0.2
Hello World[root@master metrics-app]# curl 172.17.0.2/metrics
# HELP request_count_total 缁..HTTP璇锋?
# TYPE request_count_total counter
request_count_total 2.0
# HELP request_count_created 缁..HTTP璇锋?
# TYPE request_count_created gauge
request_count_created 1.6555203522592156e+09部署
[root@master metrics-app]# cat metrics-flask-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-flask-app
spec:
replicas: 3
selector:
matchLabels:
app: flask-app
template:
metadata:
labels:
app: flask-app
# 澹版.Prometheus?..
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "/metrics"
spec:
containers:
- image: lizhenliang/metrics-flask-app
name: web
---
apiVersion: v1
kind: Service
metadata:
name: metrics-flask-app
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: flask-app这里加了一个注解,这个注解就声明了让Prometheus去采集,这里采用了pod的服务发现
apiVersion: v1
kind: Service
metadata:
name: metrics-flask-app
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "/metrics" 在访问的时候pod是轮询的方式,代理到后面某些pod,所以每个pod当中的请求总数是不一样的。
Prometheus监控 对应用暴露指标
Endpoints: 10.233.90.202:80,10.233.90.209:80,10.233.96.110:80
可以看到指标都被统计到了,次数也在里面
Prometheus Adapter
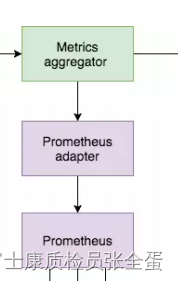
需要adapter从里面去查询指标,并且可以以metrics aggregator的方式去获取到指标。metrics aggregator充当着和metrics server的功能。
spec:
service:
name: prometheus-adapter
namespace: "kube-system"
group: custom.metrics.k8s.io可以看到使用的是这个接口custom.metrics.k8s.io
Adapter作用是用于k8s与Prometheus进行通讯,充当两者之间的翻译器。
不管是metrics server还是metrics aggreator都是一个注册在k8s当中的一个接口,接口代理到prometheus adapter,然后它向prometheus去查询数据。查询完数据返回给接口,最后给到hpa。
所以prometheus adapter是k8s和prometheus之间的桥梁,metrics aggreator接口是不支持直接从prometheus当中拿数据的。因为hpa metrics的数据接口它是不支持从prometheus当中获取数据。
[root@master prometheus_adapter]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
prometheus-adapter-7f94cc997d-xk9w8 1/1 Running 0 12m验证是否正常工作
(1)验证是否正常注册到api server
[root@master prometheus_adapter]# kubectl get apiservices |grep custom
v1beta1.custom.metrics.k8s.io kube-system/prometheus-adapter True 13mv1beta1.custom.metrics.k8s.io 这个是它的接口,访问不同的接口,会代理到后面不同的服务。
(2)调用其api,看看是否能够返回监控的数据
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1"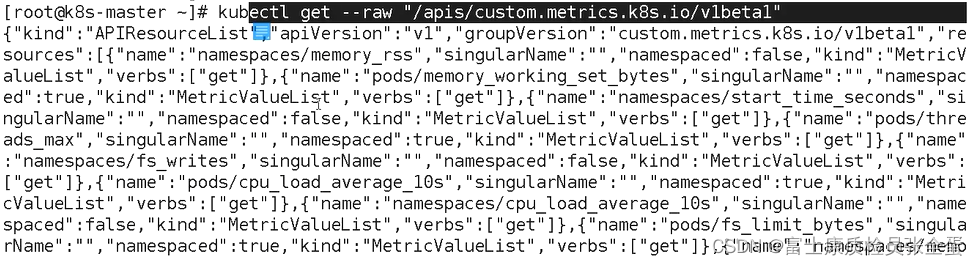
为指定HPA配置Prometheus Adapter
虽然充当了翻译器的角色,建立了k8s和Prometheus的一个桥梁,但是你得和他说明需要针对哪个应用去实现这么一个翻译,这个要明确告诉adapter的,而不是默认将Prometheus当中所有的数据都帮你去翻译。
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-adapter
labels:
app: prometheus-adapter
chart: prometheus-adapter-2.5.1
release: prometheus-adapter
heritage: Helm
namespace: kube-system
data:
config.yaml: |
rules:
- seriesQuery: 'request_count_total{app="flask-app"}'
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
matches: "request_count_total"
as: "qps"
metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)'- seriesQuery:Prometheus查询语句,查询应用系列指标。(做hpa的指标,范围越小越好,精确到某个应用)
- resources:Kubernetes资源标签映射到Prometheus标签。(这块配置是将namespace pod以标签的形式发在seriesQuery要查询的指标里面,这样更加精确)
- name:将Prometheus指标名称在自定义指标API中重命名, matches正则匹配,as指定新名称。
- metricsQuery:一个Go模板,对调用自定义指标API转换为 Prometheus查询语句
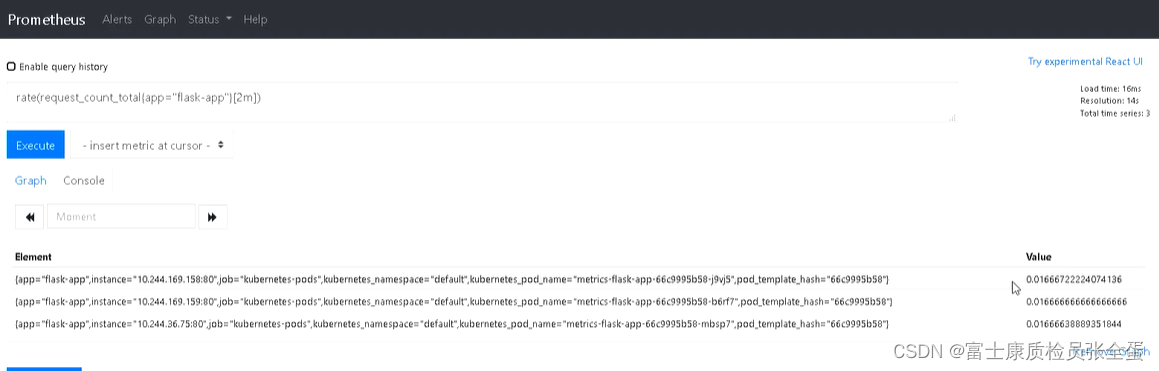
sum(rate(request_count_total{app="flask-app", kubernetes_namespace="default",
求出了速率再加上sum那么就是每秒所有的请求数,即qps。最后查询语句如下:
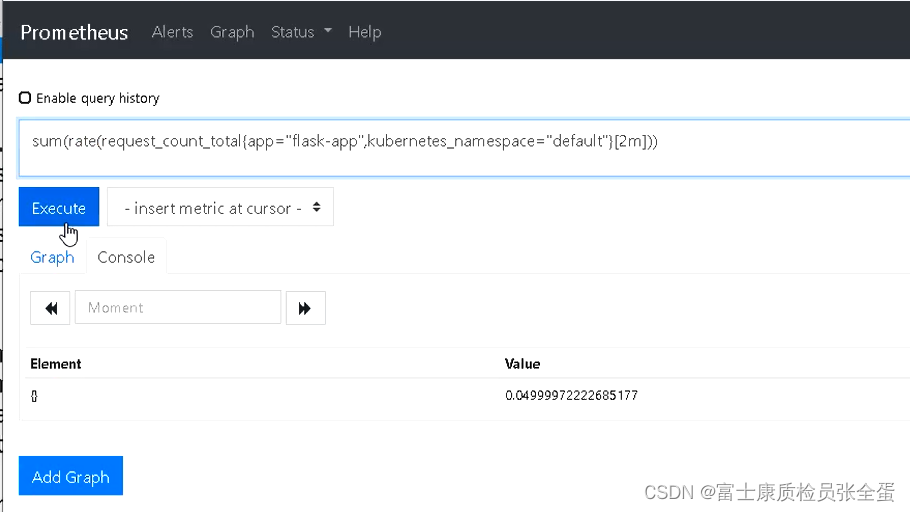 由于HTTP请求统计是累计的,对HPA自动缩放不是特别有用,因此将其转为速率指标。
由于HTTP请求统计是累计的,对HPA自动缩放不是特别有用,因此将其转为速率指标。

向自定义指标API访问:
创建HPA
这个使用的是v2版本
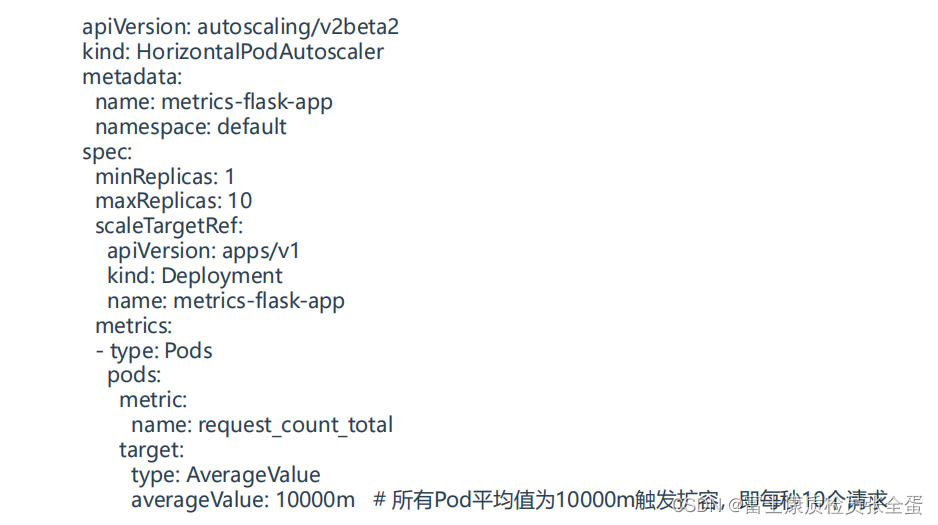
name这个地方改为qps
average value 指的是平均值,会采集所有pod的指标,拿到这个值求一个平均,然后再去对比这个阈值。
你可以定义任意的指标,只要能够被Prometheus采集到,同时指标的值是动态变化的根据实际负载,这个值可以反应负载的变化,最后决定需不需要扩容。或者500类的错误指标都行。
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象