Spring源码解析-@ComponentScan注解-程序员宅基地
Spring死磕系列-@ComponentScan注解
一、ComponentScan注解定义
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Repeatable(ComponentScans.class)
public @interface ComponentScan {
/**basePackages属性的别名*/
@AliasFor("basePackages")
String[] value() default {
};
/**指定要扫描的包路径*/
@AliasFor("value")
String[] basePackages() default {
};
/**指定这些类所在的包路径*/
Class<?>[] basePackageClasses() default {
};
/**自定义bean名称生成器,给bean创建一个名字*/
Class<? extends BeanNameGenerator> nameGenerator() default BeanNameGenerator.class;
/**
* The {@link ScopeMetadataResolver} to be used for resolving the scope of detected components.
*/
Class<? extends ScopeMetadataResolver> scopeResolver() default AnnotationScopeMetadataResolver.class;
/**
* Indicates whether proxies should be generated for detected components, which may be
* necessary when using scopes in a proxy-style fashion.
* <p>The default is defer to the default behavior of the component scanner used to
* execute the actual scan.
* <p>Note that setting this attribute overrides any value set for {@link #scopeResolver}.
* @see ClassPathBeanDefinitionScanner#setScopedProxyMode(ScopedProxyMode)
*/
ScopedProxyMode scopedProxy() default ScopedProxyMode.DEFAULT;
/**可以忽略该属性,官方都推荐使用includeFilters和excludeFilters*/
String resourcePattern() default ClassPathScanningCandidateComponentProvider.DEFAULT_RESOURCE_PATTERN;
/**是否使用默认的过滤器,后面会讲到*/
boolean useDefaultFilters() default true;
/**指定include过滤器,满足其中一个才有可能成为候选bean*/
Filter[] includeFilters() default {
};
/**指定exclude过滤器,满足其中一个直接被丢弃*/
Filter[] excludeFilters() default {
};
/**该bean是否需要懒初始化 @since 4.1*/
boolean lazyInit() default false;
// 定义过滤器
@Retention(RetentionPolicy.RUNTIME)
@Target({
})
@interface Filter {
/**指定过滤类型,总共有5种ANNOTATION、ASSIGNABLE_TYPE、ASPECTJ、REGEX、CUSTOM*/
FilterType type() default FilterType.ANNOTATION;
/**classes的别名*/
@AliasFor("classes")
Class<?>[] value() default {
};
/**
* The class or classes to use as the filter.
* <p>The following table explains how the classes will be interpreted
* based on the configured value of the {@link #type} attribute.
* <table border="1">
* <tr><th>{@code FilterType}</th><th>Class Interpreted As</th></tr>
* <tr><td>{@link FilterType#ANNOTATION ANNOTATION}</td>
* <td>the annotation itself</td></tr>
* <tr><td>{@link FilterType#ASSIGNABLE_TYPE ASSIGNABLE_TYPE}</td>
* <td>the type that detected components should be assignable to</td></tr>
* <tr><td>{@link FilterType#CUSTOM CUSTOM}</td>
* <td>an implementation of {@link TypeFilter}</td></tr>
* </table>
* <p>When multiple classes are specified, <em>OR</em> logic is applied
* — for example, "include types annotated with {@code @Foo} OR {@code @Bar}".
* <p>Custom {@link TypeFilter TypeFilters} may optionally implement any of the
* following {@link org.springframework.beans.factory.Aware Aware} interfaces, and
* their respective methods will be called prior to {@link TypeFilter#match match}:
* <ul>
* <li>{@link org.springframework.context.EnvironmentAware EnvironmentAware}</li>
* <li>{@link org.springframework.beans.factory.BeanFactoryAware BeanFactoryAware}
* <li>{@link org.springframework.beans.factory.BeanClassLoaderAware BeanClassLoaderAware}
* <li>{@link org.springframework.context.ResourceLoaderAware ResourceLoaderAware}
* </ul>
* <p>Specifying zero classes is permitted but will have no effect on component
* scanning.
* @since 4.2
* @see #value
* @see #type
*/
@AliasFor("value")
Class<?>[] classes() default {
};
/**
* The pattern (or patterns) to use for the filter, as an alternative
* to specifying a Class {@link #value}.
* <p>If {@link #type} is set to {@link FilterType#ASPECTJ ASPECTJ},
* this is an AspectJ type pattern expression. If {@link #type} is
* set to {@link FilterType#REGEX REGEX}, this is a regex pattern
* for the fully-qualified class names to match.
* @see #type
* @see #classes
*/
String[] pattern() default {
};
}
}
一、 ComponentScan注解处理
protected final SourceClass doProcessConfigurationClass(
ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)
throws IOException {
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass, filter);
}
// Process any @PropertySource annotations
// 省略处理@PropertySource逻辑
// Process any @ComponentScan annotations
// 1. 收集该配置类上所有ComponentScans和ComponentScan注解信息并封装成AnnotationAttributes集合
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
// 2. 如果该配置类上存在Conditional注解,会进行条件判断是否跳过处理
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// 3. 进行包扫描,并将结果封装成Set<BeanDefinitionHolder>
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// 4. 检查扫描出来的bean是否还有ConfigurationClass,如果有,递归处理
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// Process any @Import annotations
// 省略处理@Import逻辑
// Process any @ImportResource annotations
// 省略处理@ImportResource逻辑
// Process individual @Bean methods
// 省略处理@Bean方法逻辑
// Process default methods on interfaces
// 省略处理接口中定义的default methods
// Process superclass, if any
// 省略处理父类逻辑
// No superclass -> processing is complete
return null;
}
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, final String declaringClass) {
// 1. 创建ClassPathBeanDefinitionScanner对象, 该对象能扫描classpath下指定的路径并解析成BeanDefinition
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
// 2. 下面是对ComponentScan注解属性的解析工作
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
// 如果指定了BeanNameGenerator则使用指定的,否则使用默认的AnnotationBeanNameGenerator
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
// 从@ComponentScan注解属性中解析resourcePattern、includeFilters、
// excludeFilters、lazyInit并对ClassPathBeanDefinitionScanner做一下基础设置(这部分代码省略自行查看)
Set<String> basePackages = new LinkedHashSet<>();
// 直接指定要扫描的包路径(包括子包)
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
// 解析包路径中存在的占位符
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
// 指定要扫描的类所在包路径(包括子包)
basePackages.add(ClassUtils.getPackageName(clazz));
}
// 如果没有指定basePackages和basePackageClasses属性,则取@ComponentScan注解所在类的包路径(默认)
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
// 这个TypeFilter是为了过滤掉@ComponentScan所在的类,因为该类正在被处理
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
// 3. 万事具备,开始扫描每个包路径
return scanner.doScan(StringUtils.toStringArray(basePackages));
}
上面代码首先创建了一个ClassPathBeanDefinitionScanner对象,然后解析每个@ComponentScan注解属性并对ClassPathBeanDefinitionScanner对象进行一些基本设置,这些设置会在后面进行包扫描的时候使用。最后通过ClassPathBeanDefinitionScanner#scan方法扫描包路径收集BeanDefinition并返回,你可能会发现返回的是BeanDefinitionHolder集合,其实BeanDefinitionHolder是对BeanDefinition的扩展
BeanDefinitionHolder类

Spring中bean除了有一个BeanDefinition外,每个bean 有一个自己的“大名”,还可以有一堆自己的“小名”,BeanDefinitionHolder只提供了getter方法,所有的属性都是通过构造器注入的。
Scanner类层次结构图
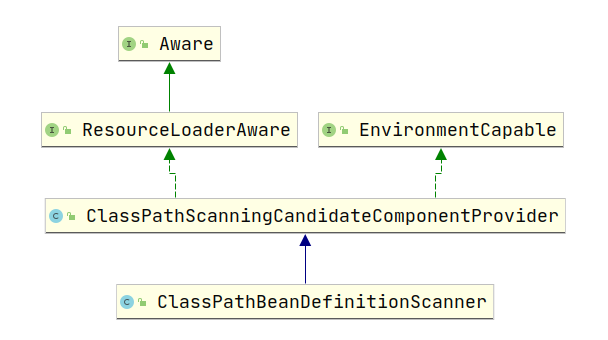
上面是ClassPathBeanDefinitionScanner的类层次结构图,通过上面代码的跟踪以及这两个类的名字我们可以大致猜出这两个类主要是负责扫描包路径下的所有.class文件最后解析封装成BeanDefinition的。牵扯到扫描.class文件就需要资源的加载所以实现了
ResourceLoaderAware接口,在解析过程中可能会用到环境变量的解析所以实现了EnviromentCapable接口,下面我们分别看一下这两个类提供了什么功能。
ClassPathScanningCandidateComponentProvider类

我们知道该类是扫描指定包下所有.class文件的,可所有的.class都是我们想要的吗?肯定不是,大多数是我们只想要其中一部分,另一部分不要,因此ClassPathScanningCandidateComponentProvider定义了两个过滤器列表
private final List<TypeFilter> includeFilters = new LinkedList<>();
private final List<TypeFilter> excludeFilters = new LinkedList<>();
这两个成员变量默认是new了一个空的列表,里面内容从哪里来?哪些类我们想要哪些不想要肯定只有我们自己知道,从上面@ComponentScan解析过程中我们知道会解析该注解的includeFilters和excludeFilters属性,其实就是我们在使用该注解时设置的过滤器经过解析最终保存在上面定义的两个列表中,在进行包路径扫描过程中会使用这两个列表进行筛选,将符合要求的封装成BeanDefinition。你这时可能会想到我在使用@ComponentScan注解时也没有指定这两个过滤器呀!(的确是,大多数情况我们是不指定过滤器的)所以当我们没有指定时,贴心的Spring团队给我默认指定了一个。
protected void registerDefaultFilters() {
// 只要带有@Component注解的就满足
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
// 还支持JSR-250提供的@ManagedBean注解
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
}
catch (ClassNotFoundException ex) {
}
try {
// 还支持JSR-330提供的@Named注解
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
}
catch (ClassNotFoundException ex) {
}
}
通过上面的分析是不是恍然大悟,原来我们在代码中经常使用的@Controller、@Service、@Repository、@Component被自动扫描由Spring管理了,原来是默认给我们提供了一个过滤器。除此之外,还支持java官方提供的两个注解@ManagedBean和@Named,这个感兴趣可以自己验证。下面我们看看
ClassPathScanningCandidateComponentProvider提供的主要方法。
findCandidateComponents方法
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
return scanCandidateComponents(basePackage);
}
}
scanCandidateComponents方法
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// 1. 将包路径解析成可加载的类路径
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 2. 将每个类文件使用Resource类进行表示
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
for (Resource resource : resources) {
if (resource.isReadable()) {
try {
// 3. 通过Resource对象创建MetadataReader对象
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 4. 判断是否是我们需要的候选bean
if (isCandidateComponent(metadataReader)) {
// 5. 满足候选bean条件创建ScannedGenericBeanDefinition对象
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
// 6. 再次判断时候是我们需要的候选bean ??? 为啥还要判断
if (isCandidateComponent(sbd)) {
// 7. 经过各种难关,过关斩将,最终成为真正符合要求的候选bean
candidates.add(sbd);
}
}
}
}
}
}
// 8. 最终返回BeanDefinition列表
return candidates;
}
看了上面的代码很多人可能和我一样的困惑,为啥要进行两次判断,为了解开谜团,我们还是的进方法一探究竟。先看第4步的判断条件
isCandidateComponent方法1
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {
// 终于瞅见了我们聊了很长时间的过滤器了
for (TypeFilter tf : this.excludeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
return false;
}
}
for (TypeFilter tf : this.includeFilters) {
if (tf.match(metadataReader, getMetadataReaderFactory())) {
// 注意:这块还要进行Condition的判断
return isConditionMatch(metadataReader);
}
}
return false;
}
我们终于瞅见了前面说的两个过滤列表了,可以知道内部的过滤策略是:先走excludeFilters如果存在不满足的就直接返回false不往下走了,经过所有的excludeFilters的筛选没有被淘汰,这还没完,还要再经过includeFilters的筛选,要是被includeFilters选中,最后还要通过Condition的条件,满足上面所有条件才能算真正的候选bean(这么一看,成为一个候选bean也不容易)。大致总结一下,没有被excludeFilters淘汰且要同时满足includeFilters和Condition条件。
上面才是第4步判断的条件,我们再看看第6步又做了什么判断
isCandidateComponent方法2
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {
AnnotationMetadata metadata = beanDefinition.getMetadata();
return (metadata.isIndependent() && (metadata.isConcrete() ||
(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}
可以看出要么满足或运算的左边,要么满足或运算的右边。左边:顶级类或者静态内部类且都是具体的实现类(非抽象类或接口),右边:是抽象类且必须有@Lookup注释的方法。
通过上面的分析我们已经知道Scanner是如何经过各种筛选,最终筛选出我们想要的候选bean的。下面我们瞅瞅它的子类ClassPathBeanDefinitionScanner对父类做了哪些扩展。
ClassPathBeanDefinitionScanner类
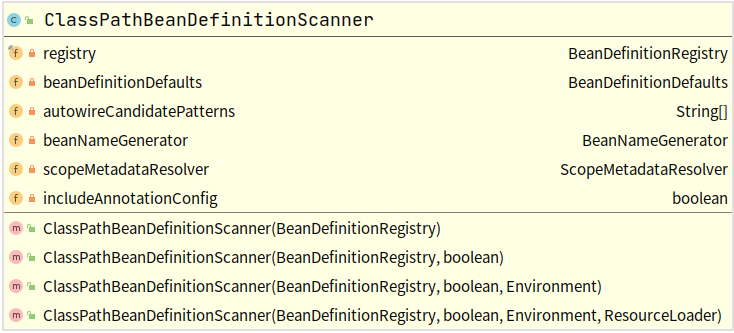
老套路,还是根据构造器和成员变量猜,然后通过读代码进行验证。我们已经知道父类可以将包路径下面的.class经过层层筛选,选择出候选bean封装成BeanDefinition返回。在类层次结构时说过,这两个类主要是获取候选bean的,现在发现活都让父类干完了,那子类能干点什么呢?通过构造器我们发现都有BeanDefinitionRegistry这个对象,这个对象提供了给容器中增删改查BeanDefinition的功能,所以我们猜测它主要就是将父类返回的BeanDefinition列表注册到容器中,而且还有一个
BeanNameGenerator对象,如果不注册bean,要这个对象也没有啥用。下面我们就看一下里面的主要方法。
doScan方法
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 1. 调用父类方法获取获选bean
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
for (BeanDefinition candidate : candidates) {
// 2. 解析bean的scope并设置
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
// 3. 如果是AbstractBeanDefinition实例,进行一些处理
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
if (candidate instanceof AnnotatedBeanDefinition) {
// 4. 如果是AnnotatedBeanDefinition实例,进行一些处理
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 5. 检查是否该bean已经被注册过了,通过判断容器中是否已经存在该beanName
if (checkCandidate(beanName, candidate)) {
// 没有注册过的BeanDefinition才会走到这,并将其封装成BeanDefinitionHolder对象
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
// 6.
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 7. 向容器中注册bean
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
// 8. 返回封装的BeanDefinitionHolder列表
return beanDefinitions;
}
postProcessBeanDefinition方法(第3步)
protected void postProcessBeanDefinition(AbstractBeanDefinition beanDefinition, String beanName) {
// 给BeanDefinition一些默认的设置
beanDefinition.applyDefaults(this.beanDefinitionDefaults);
if (this.autowireCandidatePatterns != null) {
beanDefinition.setAutowireCandidate(PatternMatchUtils.simpleMatch(this.autowireCandidatePatterns, beanName));
}
}
BeanDefinitionDefaults类定义
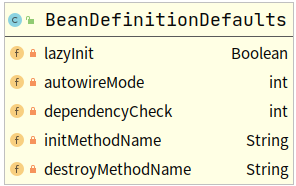
AnnotationConfigUtils#processCommonDefinitionAnnotations(第4步)
public static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd) {
processCommonDefinitionAnnotations(abd, abd.getMetadata());
}
调用重载的方法
static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd, AnnotatedTypeMetadata metadata) {
AnnotationAttributes lazy = attributesFor(metadata, Lazy.class);
if (lazy != null) {
abd.setLazyInit(lazy.getBoolean("value"));
}
else if (abd.getMetadata() != metadata) {
lazy = attributesFor(abd.getMetadata(), Lazy.class);
if (lazy != null) {
abd.setLazyInit(lazy.getBoolean("value"));
}
}
if (metadata.isAnnotated(Primary.class.getName())) {
abd.setPrimary(true);
}
AnnotationAttributes dependsOn = attributesFor(metadata, DependsOn.class);
if (dependsOn != null) {
abd.setDependsOn(dependsOn.getStringArray("value"));
}
AnnotationAttributes role = attributesFor(metadata, Role.class);
if (role != null) {
abd.setRole(role.getNumber("value").intValue());
}
AnnotationAttributes description = attributesFor(metadata, Description.class);
if (description != null) {
abd.setDescription(description.getString("value"));
}
}
我们发现就是对可能在bean上出现的所有注解@Lazy、@Primary、@DependsOn、@Role、@Description进行解析,如果存在就对该BeanDefinition进行相应的设置
checkCandidate(第5步)
protected boolean checkCandidate(String beanName, BeanDefinition beanDefinition) throws IllegalStateException {
// 检查容器中是否已经注册过该BeanDefinition,如果没有,则直接返回
// 注意:这块是通过bean的“大名”来判断是否注册过
if (!this.registry.containsBeanDefinition(beanName)) {
return true;
}
// 走到这,说明容器中已经注册过该BeanDefinition,获取注册过的BeanDefinition
BeanDefinition existingDef = this.registry.getBeanDefinition(beanName);
BeanDefinition originatingDef = existingDef.getOriginatingBeanDefinition();
if (originatingDef != null) {
existingDef = originatingDef;
}
// 判断相同名字的两个bean是否兼容,如果不兼容会抛一个异常
if (isCompatible(beanDefinition, existingDef)) {
return false;
}
throw new ConflictingBeanDefinitionException("Annotation-specified bean name '" + beanName +
"' for bean class [" + beanDefinition.getBeanClassName() + "] conflicts with existing, " +
"non-compatible bean definition of same name and class [" + existingDef.getBeanClassName() + "]");
}
applyScopedProxyMode(第6步)
先欠这 这块还没有搞明白 和代理有关
registerBeanDefinition(第7步)
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// 通过“大名”注册BeanDefinition
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// 而且还注册bean的“小名”
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
智能推荐
JavaScript学习笔记_curry函数未定义-程序员宅基地
文章浏览阅读343次。五种原始的变量类型1.Undefined--未定义类型 例:var v;2.String -- ' '或" "3.Boolean4.Number5.Null--空类型 例: var v=null;Number中:NaN -- not a number非数本身是一个数字,但是它和任何数字都不相等,代表非数,它和自己都不相等判断是不是NaN不能用=_curry函数未定义
兑换码编码方案实践_优惠券编码规则-程序员宅基地
文章浏览阅读1.2w次,点赞2次,收藏17次。兑换码编码设计当前各个业务系统,只要涉及到产品销售,就离不开大大小小的运营活动需求,其中最普遍的就是兑换码需求,无论是线下活动或者是线上活动,都能起到良好的宣传效果。兑换码:由一系列字符组成,每一个兑换码对应系统中的一组信息,可以是优惠信息(优惠券),也可以是相关奖品信息。在实际的运营活动中,要求兑换码是唯一的,每一个兑换码对应一个优惠信息,而且需求量往往比较大(实际上的需求只有预期_优惠券编码规则
c语言周林答案,C语言程序设计实训教程教学课件作者周林ch04结构化程序设计课件.ppt...-程序员宅基地
文章浏览阅读45次。C语言程序设计实训教程教学课件作者周林ch04结构化程序设计课件.ppt* * 4.1 选择结构程序设计 4.2 循环结构程序设计 4.3 辅助控制语句 第四章 结构化程序设计 4.1 选择结构程序设计 在现实生活中,需要进行判断和选择的情况是很多的: 如果你在家,我去拜访你 如果考试不及格,要补考 如果遇到红灯,要停车等待 第四章 结构化程序设计 在现实生活中,需要进行判断和选择的情况..._在现实生活中遇到过条件判断的问
幻数使用说明_ioctl-number.txt幻数说明-程序员宅基地
文章浏览阅读999次。幻数使用说明 在驱动程序中实现的ioctl函数体内,实际上是有一个switch{case}结构,每一个case对应一个命令码,做出一些相应的操作。怎么实现这些操作,这是每一个程序员自己的事情。 因为设备都是特定的,这里也没法说。关键在于怎样组织命令码,因为在ioctl中命令码是唯一联系用户程序命令和驱动程序支持的途径 。 命令码的组织是有一些讲究的,因为我们一定要做到命令和设备是一一对应的,利_ioctl-number.txt幻数说明
ORB-SLAM3 + VScode:检测到 #include 错误。请更新 includePath。已为此翻译单元禁用波浪曲线_orb-slam3 include <system.h> 报错-程序员宅基地
文章浏览阅读399次。键盘按下“Shift+Ctrl+p” 输入: C++Configurations,选择JSON界面做如下改动:1.首先把 “/usr/include”,放在最前2.查看C++路径,终端输入gcc -v -E -x c++ - /usr/include/c++/5 /usr/include/x86_64-linux-gnu/c++/5 /usr/include/c++/5/backward /usr/lib/gcc/x86_64-linux-gnu/5/include /usr/local/_orb-slam3 include 报错
「Sqlserver」数据分析师有理由爱Sqlserver之十-Sqlserver自动化篇-程序员宅基地
文章浏览阅读129次。本系列的最后一篇,因未有精力写更多的入门教程,上篇已经抛出书单,有兴趣的朋友可阅读好书来成长,此系列主讲有理由爱Sqlserver的论证性文章,希望读者们看完后,可自行做出判断,Sqlserver是否真的合适自己,目的已达成。渴望自动化及使用场景笔者所最能接触到的群体为Excel、PowerBI用户群体,在Excel中,我们知道可以使用VBA、VSTO来给Excel带来自动化操作..._sqlsever 数据分析
随便推点
智慧校园智慧教育大数据平台(教育大脑)项目建设方案PPT_高校智慧大脑-程序员宅基地
文章浏览阅读294次,点赞6次,收藏4次。教育智脑)建立学校的全连接中台,对学校运营过程中的数据进行处理和标准化管理,挖掘数据的价值。能:一、原先孤立的系统聚合到一个统一的平台,实现单点登录,统一身份认证,方便管理;三、数据共享,盘活了教育大数据资源,通过对外提供数。的方式构建教育的通用服务能力平台,支撑教育核心服务能力的沉淀和共享。物联网将学校的各要素(人、机、料、法、环、测)全面互联,数据实时。智慧校园解决方案,赋能教学、管理和服务升级,智慧教育体系,该数据平台具有以下几大功。教育大数据平台底座:教育智脑。教育大数据平台,以中国联通。_高校智慧大脑
编程5大算法总结--概念加实例_算法概念实例-程序员宅基地
文章浏览阅读9.5k次,点赞2次,收藏27次。分治法,动态规划法,贪心算法这三者之间有类似之处,比如都需要将问题划分为一个个子问题,然后通过解决这些子问题来解决最终问题。但其实这三者之间的区别还是蛮大的。贪心是则可看成是链式结构回溯和分支界限为穷举式的搜索,其思想的差异是深度优先和广度优先一:分治算法一、基本概念在计算机科学中,分治法是一种很重要的算法。字面上的解释是“分而治之”,就是把一个复杂的问题分成两_算法概念实例
随笔—醒悟篇之考研调剂_考研调剂抑郁-程序员宅基地
文章浏览阅读5.6k次。考研篇emmmmm,这是我随笔篇章的第二更,原本计划是在中秋放假期间写好的,但是放假的时候被安排写一下单例模式,做了俩机试题目,还刷了下PAT的东西,emmmmm,最主要的还是因为我浪的很开心,没空出时间来写写东西。 距离我考研结束已经快两年了,距离今年的考研还有90天左右。 趁着这个机会回忆一下青春,这一篇会写的比较有趣,好玩,纯粹是为了记录一下当年考研中发生的有趣的事。 首先介绍..._考研调剂抑郁
SpringMVC_class org.springframework.web.filter.characterenco-程序员宅基地
文章浏览阅读438次。SpringMVC文章目录SpringMVC1、SpringMVC简介1.1 什么是MVC1.2 什么是SpringMVC1.3 SpringMVC的特点2、HelloWorld2.1 开发环境2.2 创建maven工程a>添加web模块b>打包方式:warc>引入依赖2.3 配置web.xml2.4 创建请求控制器2.5 创建SpringMVC的配置文件2.6 测试Helloworld2.7 总结3、@RequestMapping注解3.1 @RequestMapping注解的功能3._class org.springframework.web.filter.characterencodingfilter is not a jakart
gdb: Don‘t know how to run. Try “help target“._don't know how to run. try "help target".-程序员宅基地
文章浏览阅读4.9k次。gdb 远程调试的一个问题:Don't know how to run. Try "help target".它在抱怨不知道怎么跑,目标是什么. 你需要为它指定target remote 或target extended-remote例如:target extended-remote 192.168.1.136:1234指明target 是某IP的某端口完整示例如下:targ..._don't know how to run. try "help target".
c语言程序设计教程 郭浩志,C语言程序设计教程答案杨路明郭浩志-程序员宅基地
文章浏览阅读85次。习题 11、算法描述主要是用两种基本方法:第一是自然语言描述,第二是使用专用工具进行算法描述2、c 语言程序的结构如下:1、c 语言程序由函数组成,每个程序必须具有一个 main 函数作为程序的主控函数。2、“/*“与“*/“之间的内容构成 c 语言程序的注释部分。3、用预处理命令#include 可以包含有关文件的信息。4、大小写字母在 c 语言中是有区别的。5、除 main 函数和标准库函数以..._c语言语法0x1e