基于深度学习的三维重建(一):三维重建简介、patchmatchNet环境部署、用colmap如何测试自己的数据集-程序员宅基地
技术标签: slam c++ 计算机视觉 深度学习 人工智能 基于深度学习的三维重建
目录
3.传统MVS的局限性和为什么基于深度学习的MVS性能好于传统三维重建
1.什么是三维重建
用相机拍摄真实世界的物体、场景,并通过计算机视觉技术进行处理,从而得到物体的三维模型。英文术语:3D Reconstruction。
涉及的主要技术有:多视图立体几何、深度图估计、点云处理、网格重建和优化、纹理贴图、马尔科夫随机场、图割等。
是增强现实(AR)、混合现实(MR)、机器人导航、自动驾驶等领域的核心技术之一。

2.MVS是什么
用RGB-D信息重建3D几何的模型,输入的话是一系列的RGB-D照片,这些照片会有一些重合部分,我们计算这些照片的位姿信息(每个拍摄的相机角度的位置),我们就知道了每帧间的位置关系,然后对它进行一个3D模型的重建,最后将材质信息给它贴上去(纹理贴图,将RGB-D信息贴到几何模型上)。
这里的位姿信息获得是通过SLAM或者SFM来做的,我们就可以得到它的深度图进行点云融合等操作。
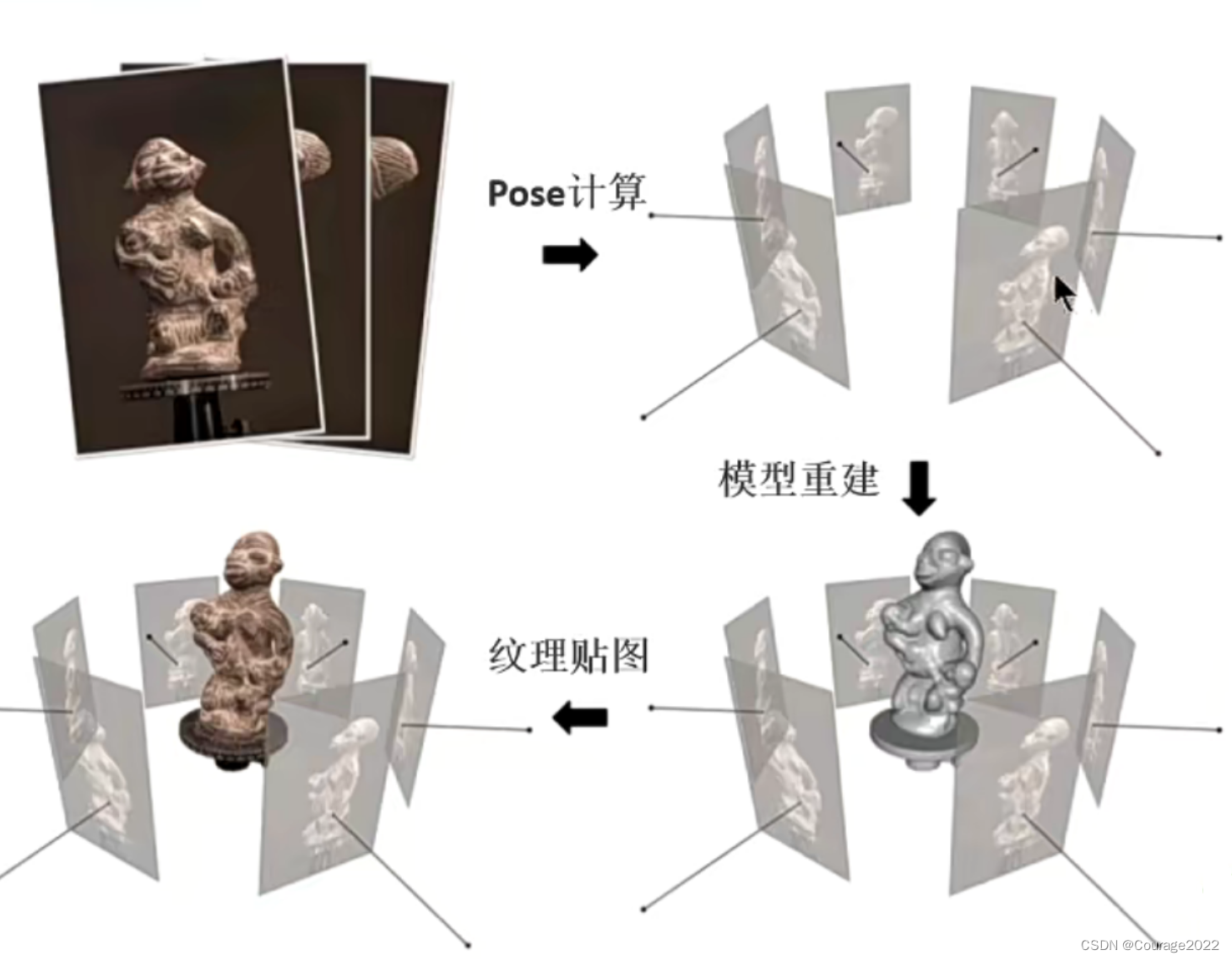
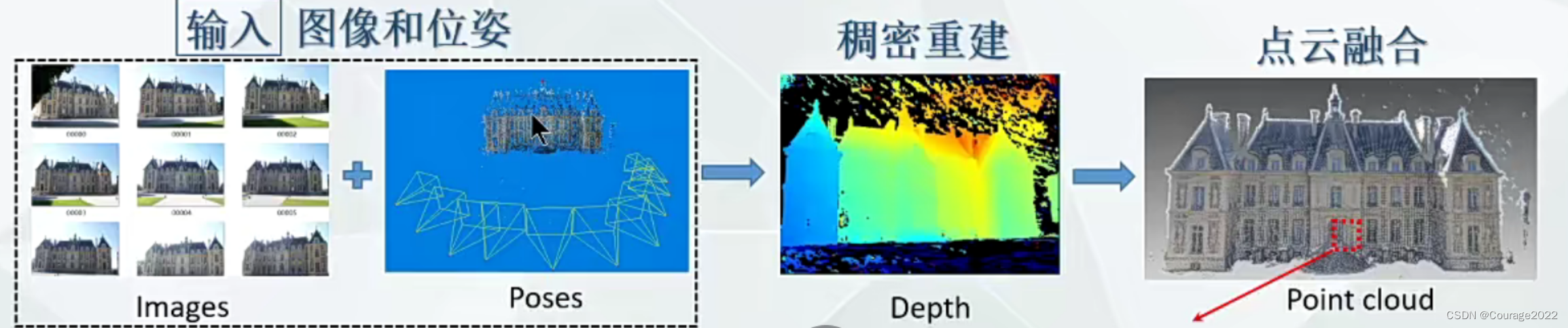
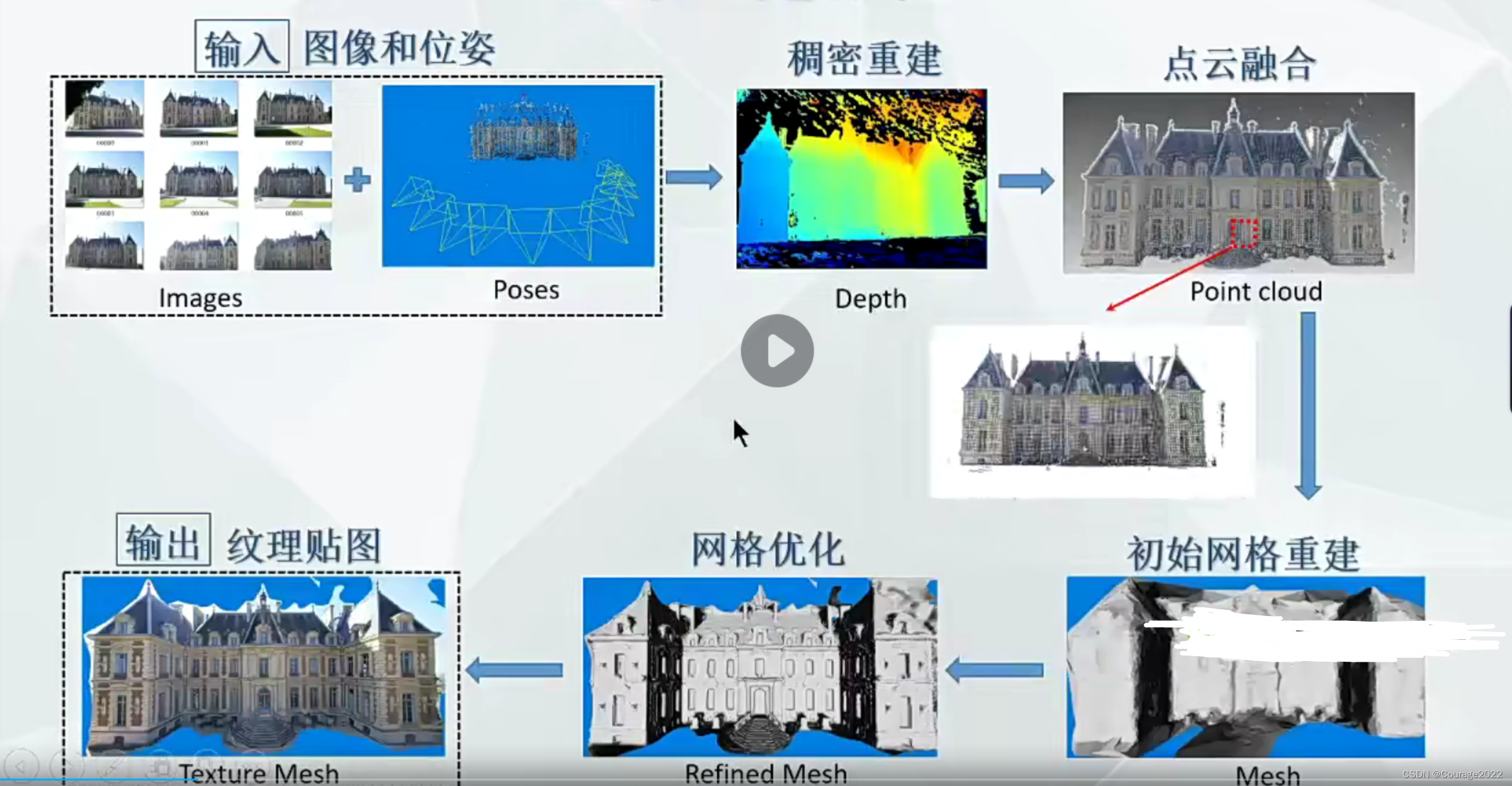
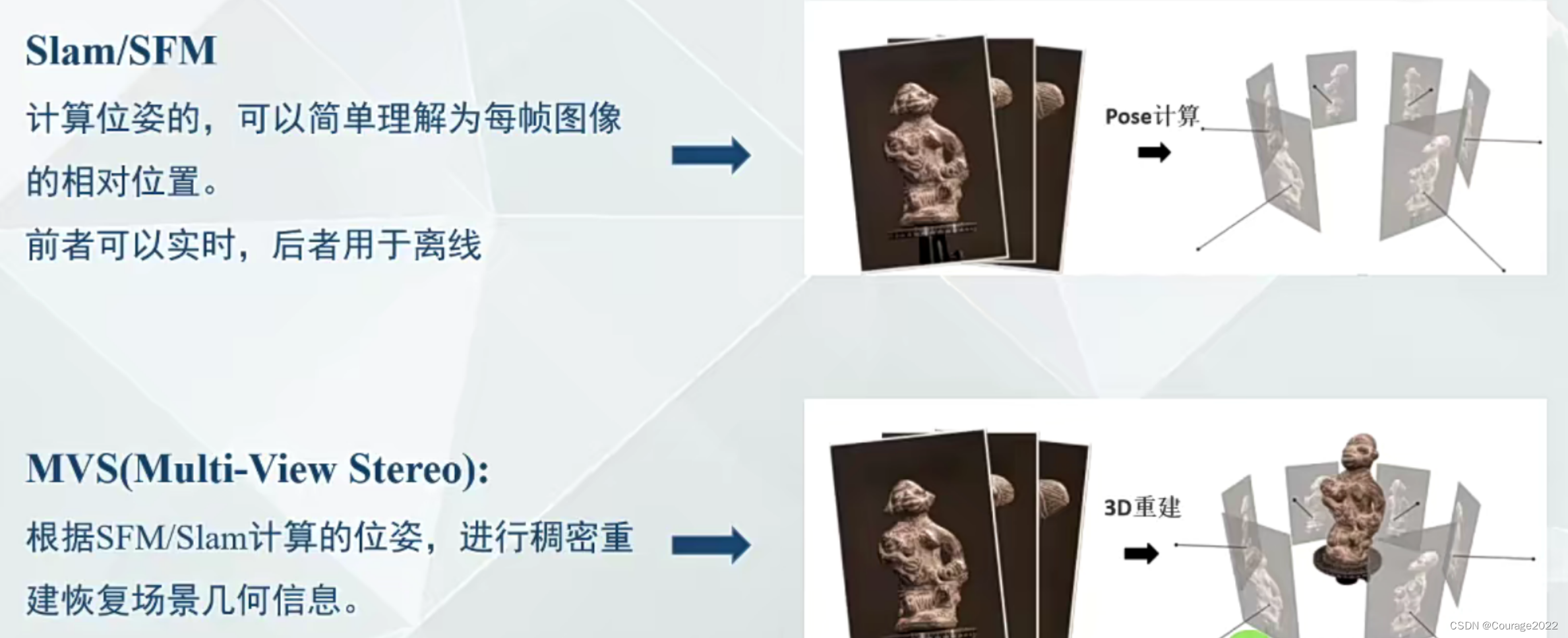
3.传统MVS的局限性和为什么基于深度学习的MVS性能好于传统三维重建
MVS重建我们是基于RGB-D信息做的,也就是说我们恢复3D信息是通过立体匹配等方法进行深度恢复,如果RGB信息出现大面积的单色情况(如下图)没有纹理信息的或者是透明的重复纹理的,那么我们很难进行特征点匹配,也就没有办法通过立体匹配进行深度恢复了,最终导致失败。
在深度学习中,我们通过大量的数据学习一些信息规律和信息。
但其也有一定的缺点,比如依赖显存和内存,依赖大数据,难以重建高分辨率的模型。




4.基础概念
①深度图(depth)/视差图(disparity)
a.深度图:场景中每个点到相机的距离
b.视差图:同一个场景在两个相机下成像的像素的位置偏差dis
c.两者关系:,是三维信息的一种表示方式。
深度图存储的就是相机坐标系下的
值
②三维点云:
a.三维点云是某个坐标系下的点的数据集。
b.包含了丰富的信息,包括三维坐标XYZ、颜色RGB等信息。③三维网格:
由物体的邻接点云构成的多边形组成的,通常由三角形、四边形或者其它的简单凸多边形组成。
④纹理贴图模型:
带有颜色信息的三维网格模型。
所有的颜色信息存储在一张纹理图上,显示时根据每个网格的纹理坐标和对应的纹理图进行渲染得到高分辨率的彩色模型。⑤相机模型:
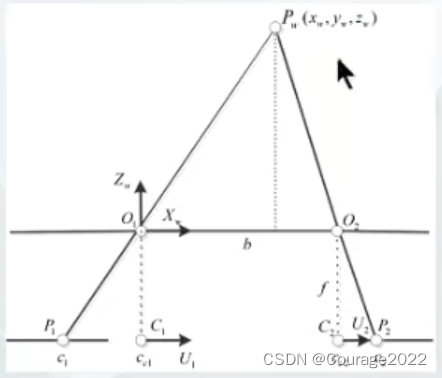

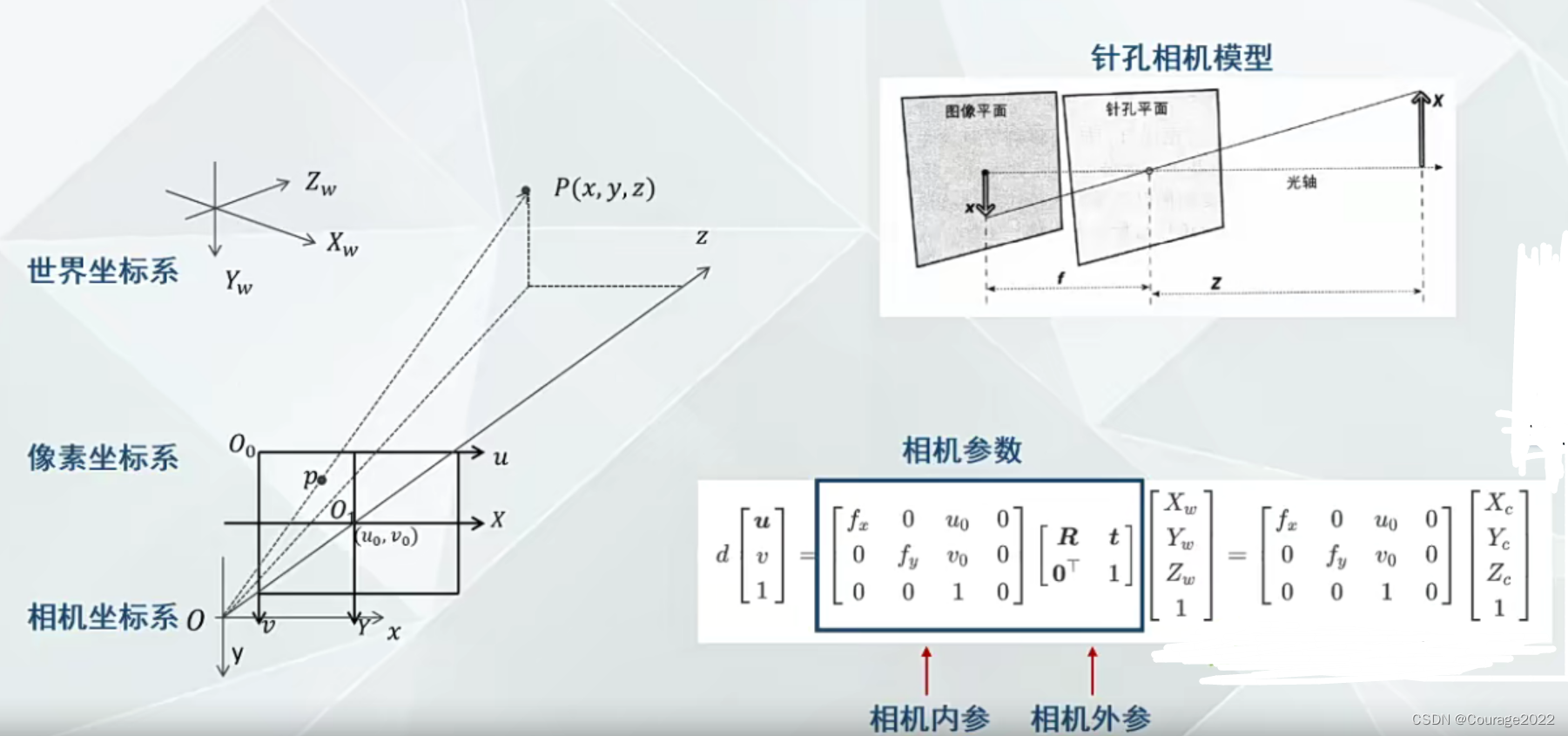
5. patchmatchNet环境配置
利用Anaconda配置虚拟环境,python版本为3.8。如果有GPU的话cuda推荐版本为11.3,我是3080显卡,安装的cuda版本为11.3,pytorch版本为1.11.0,可顺利跑通!
下载patchmatchNet源码:
PatchNet Git地址
https://github.com/FangjinhuaWang/PatchmatchNet
里面有个requirements.txt
一键安装:pip install -r requirements.txt
到这里我们就安装成功了,测试一下:
先0下载数据集:
下载DTU数据集 dtu.zip,在项目文件夹新建data文件夹,解压到data文件夹中。
在代码路径下打开终端,激活conda环境,运行eval.sh,如果没有gpu,运行eval_cpu.sh。
运行结果保存在当前目录下./outputs下。
如果显卡性能不好或者CPU跑性能过慢的话,我们可以改变默认的分辨率大小,在eval.py中,main函数中,img_wh = (800,600),可以改为原来的一半。同时也要改dataset/dtu_yao_eval.py文件,MvsDataset类中更改图像分辨率。
最终重建的结果如下,效果还是不错滴!
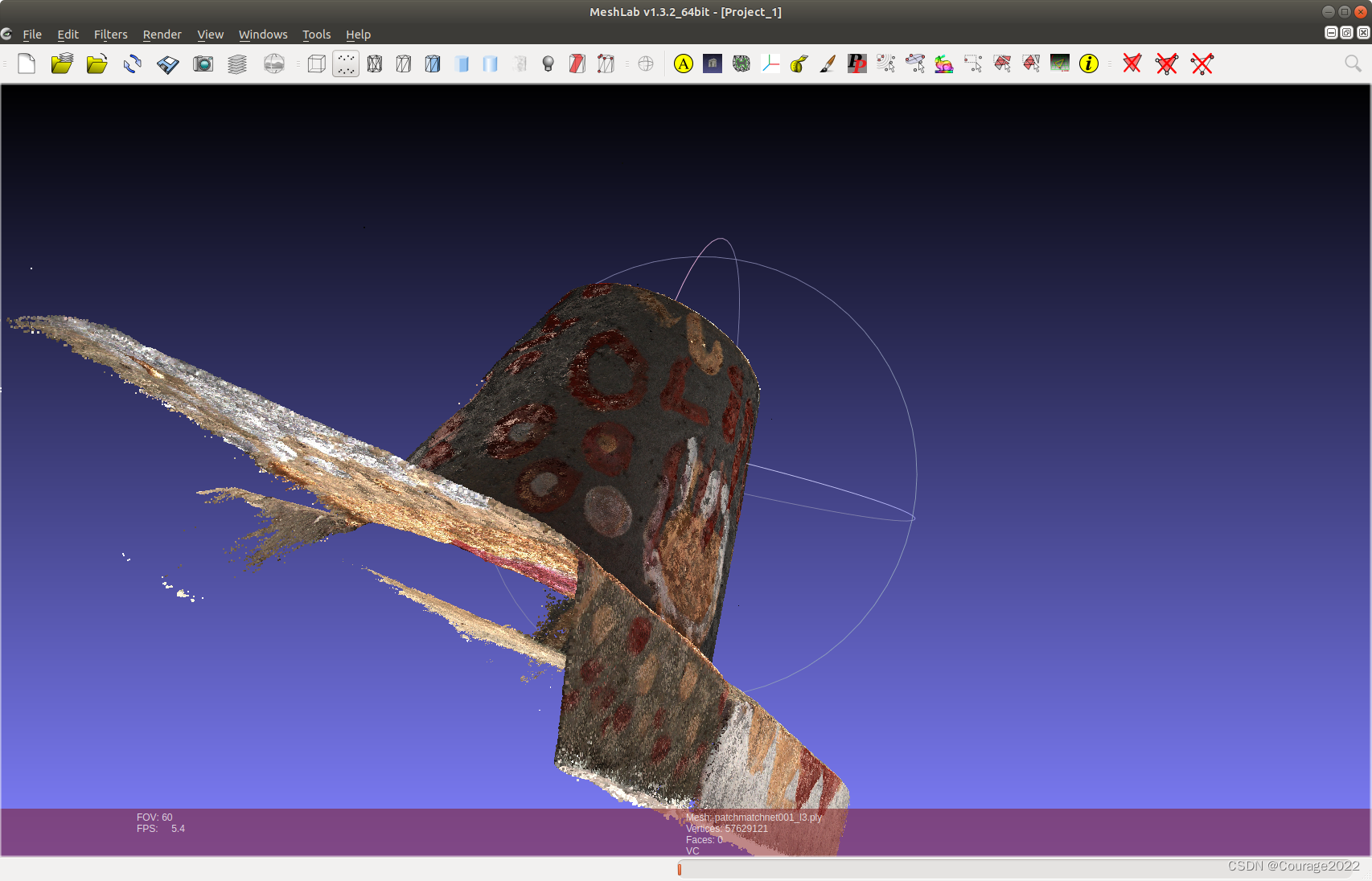
6.如何测试自己的数据集(位姿计算)
6.1 colmap导出位姿
比如我们用手机拍摄了一组照片,要对其进行三维重建,应该怎么做呢?
我们上面说到,输入到patchmatchNet网络中的参数是一组照片以及它们的深度信息(位姿+深度范围或者稀疏点云),因此我们主要做的就是数据格式的转换。
第一步就是位姿的计算,无论是sfm或者SLAM除了输出位姿(R,t)以外都会有稀疏点的输出,并且告诉哪些稀疏点会被哪些相机和关键帧看到,我们就是用这些信息完成重建。
一、数据:
数据要求:图的质量要好不能模糊遮挡、帧之间要有大量的重合区域。(弱纹理,高反光效果不好)
二、位姿计算:使用colmap计算位姿,也可以使用别的比如OpenMVG,Slam这些需要自己写转换脚本参考colmap_input.py。colmap git链接
双击:
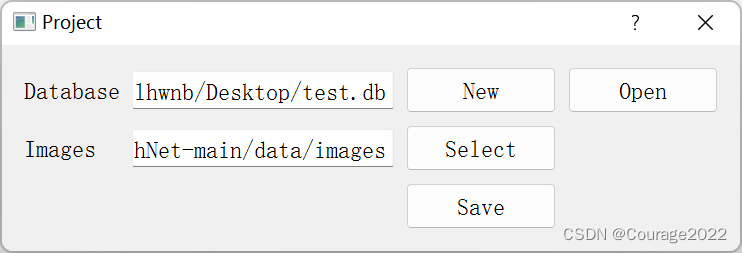
新建一个工程:
Database是新建的数据库名称,Images是包含图片的文件夹。
可以看到桌面已经有这个工程了。
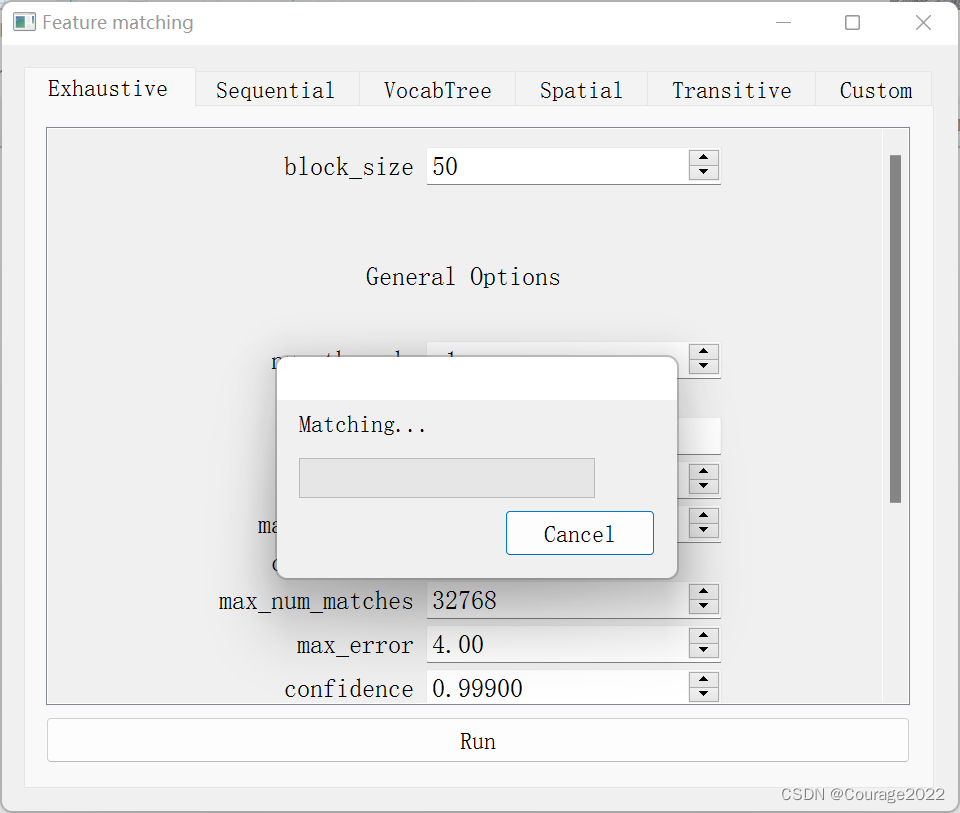
下一步就是特征提取,
点击提取
特征匹配完成!
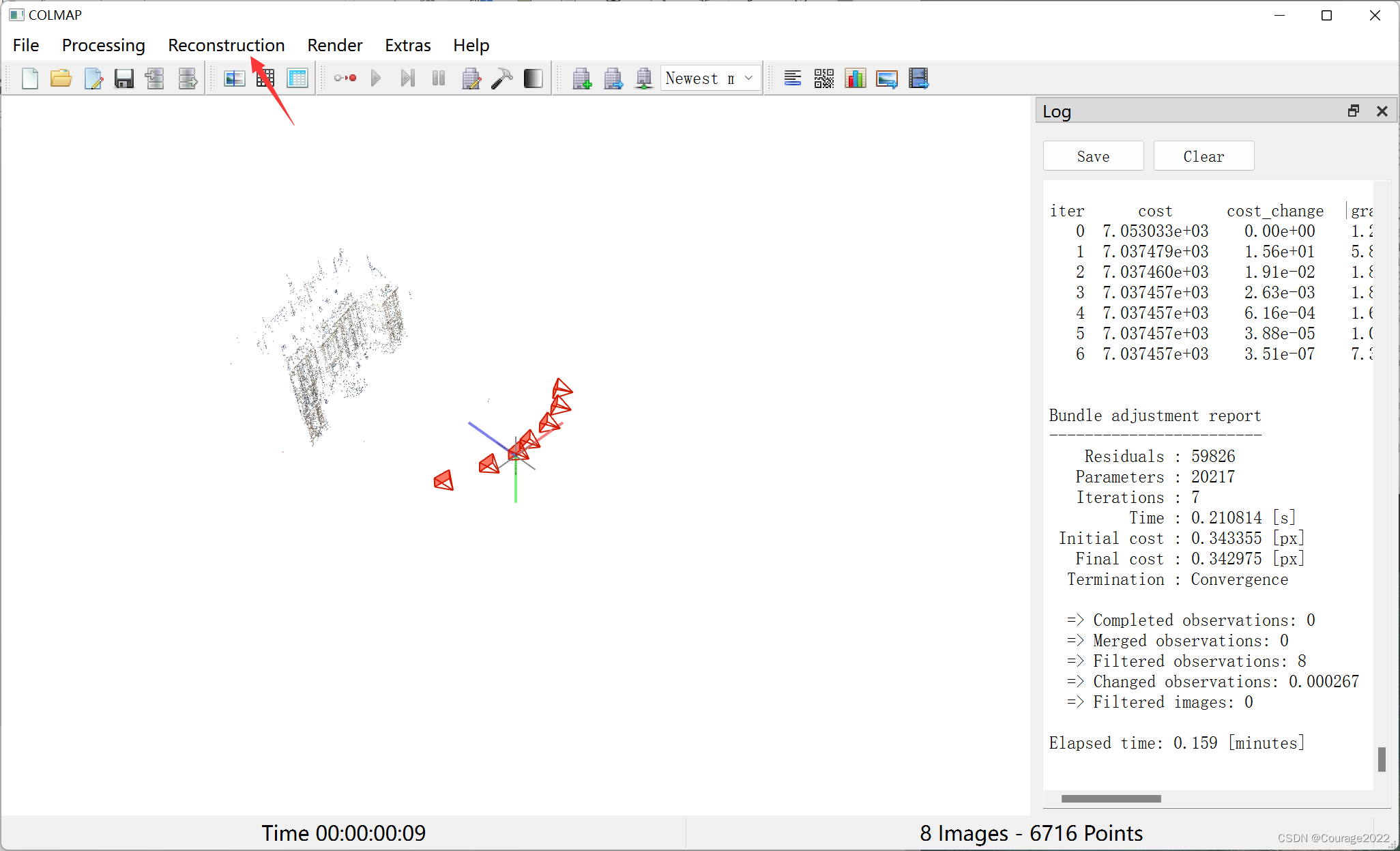
重建,点击开始重建。
红色的就是每帧相机的位置,黑色的就是稀疏的地图点。
现在我们就得到了哪些相机可以观测到哪些点、相机的位姿信息、相机的内参等。
我们就可以用地图点计算深度范围计算初始的深度图都是可以的,接下来我们导出信息。FIle/Import model as text:
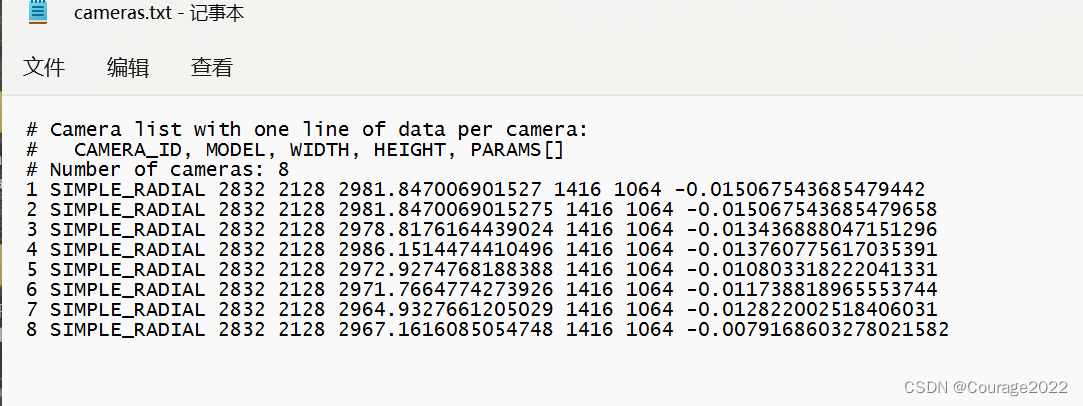
camera.txt里面是相机的参数:对应相机ID、相机属性、图像大小、相机内参
images.txt:图像ID、平移四元数、旋转信息、哪个相机照的这个图像、图像的名称
POINTS2D[] as (X, Y, POINT3D_ID):投影坐标
points3D.txt:3D点的ID、3D点坐标、3D点的RGB信息、错误信息、可以被哪张图片看到,该点在该张图片的索引是多少。





6.2 将colmap位姿转换成MVS读取的数据格式
转换成MVS格式直接由DataLoader调用即可:
我们看怎么实现:colmap_input.py 我在源码中进行了标注
#!/usr/bin/env python from __future__ import print_function import collections import struct import numpy as np import multiprocessing as mp import os import argparse import shutil import cv2 #============================ read_model.py ============================# CameraModel = collections.namedtuple( "CameraModel", ["model_id", "model_name", "num_params"]) Camera = collections.namedtuple( "Camera", ["id", "model", "width", "height", "params"]) BaseImage = collections.namedtuple( "Image", ["id", "qvec", "tvec", "camera_id", "name", "xys", "point3D_ids"]) Point3D = collections.namedtuple( "Point3D", ["id", "xyz", "rgb", "error", "image_ids", "point2D_idxs"]) class Image(BaseImage): def qvec2rotmat(self): return qvec2rotmat(self.qvec) CAMERA_MODELS = { CameraModel(model_id=0, model_name="SIMPLE_PINHOLE", num_params=3), CameraModel(model_id=1, model_name="PINHOLE", num_params=4), CameraModel(model_id=2, model_name="SIMPLE_RADIAL", num_params=4), CameraModel(model_id=3, model_name="RADIAL", num_params=5), CameraModel(model_id=4, model_name="OPENCV", num_params=8), CameraModel(model_id=5, model_name="OPENCV_FISHEYE", num_params=8), CameraModel(model_id=6, model_name="FULL_OPENCV", num_params=12), CameraModel(model_id=7, model_name="FOV", num_params=5), CameraModel(model_id=8, model_name="SIMPLE_RADIAL_FISHEYE", num_params=4), CameraModel(model_id=9, model_name="RADIAL_FISHEYE", num_params=5), CameraModel(model_id=10, model_name="THIN_PRISM_FISHEYE", num_params=12) } CAMERA_MODEL_IDS = dict([(camera_model.model_id, camera_model) \ for camera_model in CAMERA_MODELS]) def read_next_bytes(fid, num_bytes, format_char_sequence, endian_character="<"): """Read and unpack the next bytes from a binary file. :param fid: :param num_bytes: Sum of combination of {2, 4, 8}, e.g. 2, 6, 16, 30, etc. :param format_char_sequence: List of {c, e, f, d, h, H, i, I, l, L, q, Q}. :param endian_character: Any of {@, =, <, >, !} :return: Tuple of read and unpacked values. """ data = fid.read(num_bytes) return struct.unpack(endian_character + format_char_sequence, data) def read_cameras_text(path): """ see: src/base/reconstruction.cc void Reconstruction::WriteCamerasText(const std::string& path) void Reconstruction::ReadCamerasText(const std::string& path) """ cameras = {} with open(path, "r") as fid: while True: line = fid.readline() if not line: break line = line.strip() if len(line) > 0 and line[0] != "#": elems = line.split() camera_id = int(elems[0]) # camera 类型 model = elems[1] width = int(elems[2]) height = int(elems[3]) # 相机的参数 params = np.array(tuple(map(float, elems[4:]))) cameras[camera_id] = Camera(id=camera_id, model=model, width=width, height=height, params=params) return cameras def read_cameras_binary(path_to_model_file): """ see: src/base/reconstruction.cc void Reconstruction::WriteCamerasBinary(const std::string& path) void Reconstruction::ReadCamerasBinary(const std::string& path) """ cameras = {} with open(path_to_model_file, "rb") as fid: num_cameras = read_next_bytes(fid, 8, "Q")[0] print("num of cameras") print(num_cameras) for camera_line_index in range(num_cameras): camera_properties = read_next_bytes( fid, num_bytes=24, format_char_sequence="iiQQ") camera_id = camera_properties[0] print("camera id") print(camera_id) model_id = camera_properties[1] # print("model id") # print(model_id) model_name = CAMERA_MODEL_IDS[camera_properties[1]].model_name width = camera_properties[2] height = camera_properties[3] num_params = CAMERA_MODEL_IDS[model_id].num_params params = read_next_bytes(fid, num_bytes=8*num_params, format_char_sequence="d"*num_params) cameras[camera_id] = Camera(id=camera_id, model=model_name, width=width, height=height, params=np.array(params)) assert len(cameras) == num_cameras return cameras def read_images_text(path): """ see: src/base/reconstruction.cc void Reconstruction::ReadImagesText(const std::string& path) void Reconstruction::WriteImagesText(const std::string& path) """ images = {} with open(path, "r") as fid: while True: # 一行一行读 line = fid.readline() if not line: break line = line.strip() # 前面几行有带#的注释 if len(line) > 0 and line[0] != "#": elems = line.split() image_id = int(elems[0]) # 四元数(旋转矩阵转换的四元数) qvec = np.array(tuple(map(float, elems[1:5]))) # 内参t tvec = np.array(tuple(map(float, elems[5:8]))) # camera ID camera_id = int(elems[8]) # 图片名称 image_name = elems[9] elems = fid.readline().split() # 特征点在图像中的2D坐标 xys = np.column_stack([tuple(map(float, elems[0::3])), tuple(map(float, elems[1::3]))]) point3D_ids = np.array(tuple(map(int, elems[2::3]))) images[image_id] = Image( id=image_id, qvec=qvec, tvec=tvec, camera_id=camera_id, name=image_name, xys=xys, point3D_ids=point3D_ids) return images def read_images_binary(path_to_model_file): """ see: src/base/reconstruction.cc void Reconstruction::ReadImagesBinary(const std::string& path) void Reconstruction::WriteImagesBinary(const std::string& path) """ images = {} with open(path_to_model_file, "rb") as fid: num_reg_images = read_next_bytes(fid, 8, "Q")[0] # print("img num") # print(num_reg_images) for image_index in range(num_reg_images): binary_image_properties = read_next_bytes( fid, num_bytes=64, format_char_sequence="idddddddi") image_id = binary_image_properties[0] # print("image_id") # print(image_id) qvec = np.array(binary_image_properties[1:5]) tvec = np.array(binary_image_properties[5:8]) camera_id = binary_image_properties[8] # print("image_id_camera") # print(camera_id) image_name = "" current_char = read_next_bytes(fid, 1, "c")[0] while current_char != b"\x00": # look for the ASCII 0 entry image_name += current_char.decode("utf-8") current_char = read_next_bytes(fid, 1, "c")[0] num_points2D = read_next_bytes(fid, num_bytes=8, format_char_sequence="Q")[0] x_y_id_s = read_next_bytes(fid, num_bytes=24*num_points2D, format_char_sequence="ddq"*num_points2D) xys = np.column_stack([tuple(map(float, x_y_id_s[0::3])), tuple(map(float, x_y_id_s[1::3]))]) point3D_ids = np.array(tuple(map(int, x_y_id_s[2::3]))) # print("point_3d") # print(point3D_ids) images[image_id] = Image( id=image_id, qvec=qvec, tvec=tvec, camera_id=camera_id, name=image_name, xys=xys, point3D_ids=point3D_ids) return images def read_points3D_text(path): """ see: src/base/reconstruction.cc void Reconstruction::ReadPoints3DText(const std::string& path) void Reconstruction::WritePoints3DText(const std::string& path) """ points3D = {} with open(path, "r") as fid: while True: line = fid.readline() if not line: break line = line.strip() if len(line) > 0 and line[0] != "#": elems = line.split() point3D_id = int(elems[0]) xyz = np.array(tuple(map(float, elems[1:4]))) rgb = np.array(tuple(map(int, elems[4:7]))) error = float(elems[7]) image_ids = np.array(tuple(map(int, elems[8::2]))) point2D_idxs = np.array(tuple(map(int, elems[9::2]))) points3D[point3D_id] = Point3D(id=point3D_id, xyz=xyz, rgb=rgb, error=error, image_ids=image_ids, point2D_idxs=point2D_idxs) return points3D def read_points3d_binary(path_to_model_file): """ see: src/base/reconstruction.cc void Reconstruction::ReadPoints3DBinary(const std::string& path) void Reconstruction::WritePoints3DBinary(const std::string& path) """ points3D = {} with open(path_to_model_file, "rb") as fid: num_points = read_next_bytes(fid, 8, "Q")[0] # print("num points") # print(num_points) for point_line_index in range(num_points): binary_point_line_properties = read_next_bytes( fid, num_bytes=43, format_char_sequence="QdddBBBd") point3D_id = binary_point_line_properties[0] xyz = np.array(binary_point_line_properties[1:4]) rgb = np.array(binary_point_line_properties[4:7]) error = np.array(binary_point_line_properties[7]) track_length = read_next_bytes( fid, num_bytes=8, format_char_sequence="Q")[0] track_elems = read_next_bytes( fid, num_bytes=8*track_length, format_char_sequence="ii"*track_length) image_ids = np.array(tuple(map(int, track_elems[0::2]))) point2D_idxs = np.array(tuple(map(int, track_elems[1::2]))) points3D[point3D_id] = Point3D( id=point3D_id, xyz=xyz, rgb=rgb, error=error, image_ids=image_ids, point2D_idxs=point2D_idxs) return points3D def read_model(path, ext): if ext == ".txt": # 读取相机参数、图像、3D点 cameras = read_cameras_text(os.path.join(path, "cameras" + ext)) images = read_images_text(os.path.join(path, "images" + ext)) points3D = read_points3D_text(os.path.join(path, "points3D") + ext) else: cameras = read_cameras_binary(os.path.join(path, "cameras" + ext)) images = read_images_binary(os.path.join(path, "images" + ext)) points3D = read_points3d_binary(os.path.join(path, "points3D") + ext) return cameras, images, points3D def qvec2rotmat(qvec): return np.array([ [1 - 2 * qvec[2]**2 - 2 * qvec[3]**2, 2 * qvec[1] * qvec[2] - 2 * qvec[0] * qvec[3], 2 * qvec[3] * qvec[1] + 2 * qvec[0] * qvec[2]], [2 * qvec[1] * qvec[2] + 2 * qvec[0] * qvec[3], 1 - 2 * qvec[1]**2 - 2 * qvec[3]**2, 2 * qvec[2] * qvec[3] - 2 * qvec[0] * qvec[1]], [2 * qvec[3] * qvec[1] - 2 * qvec[0] * qvec[2], 2 * qvec[2] * qvec[3] + 2 * qvec[0] * qvec[1], 1 - 2 * qvec[1]**2 - 2 * qvec[2]**2]]) def rotmat2qvec(R): Rxx, Ryx, Rzx, Rxy, Ryy, Rzy, Rxz, Ryz, Rzz = R.flat K = np.array([ [Rxx - Ryy - Rzz, 0, 0, 0], [Ryx + Rxy, Ryy - Rxx - Rzz, 0, 0], [Rzx + Rxz, Rzy + Ryz, Rzz - Rxx - Ryy, 0], [Ryz - Rzy, Rzx - Rxz, Rxy - Ryx, Rxx + Ryy + Rzz]]) / 3.0 eigvals, eigvecs = np.linalg.eigh(K) qvec = eigvecs[[3, 0, 1, 2], np.argmax(eigvals)] if qvec[0] < 0: qvec *= -1 return qvec if __name__ == '__main__': parser = argparse.ArgumentParser(description='Convert colmap results into input for PatchmatchNet') parser.add_argument('--folder', default='./data',type=str, help='Project dir.') parser.add_argument('--theta0', type=float, default=5) parser.add_argument('--sigma1', type=float, default=1) parser.add_argument('--sigma2', type=float, default=10) # 测试程序是否可用,如果置此位为true则不保存结果 parser.add_argument('--test', action='store_true', default=False, help='If set, do not write to file.') # 转换格式,将图片转换成jpg格式 parser.add_argument('--convert_format', action='store_true', default=False, help='If set, convert image to jpg format.') args = parser.parse_args() # 图片路径,即这个路径下要有图像 image_dir = os.path.join(args.folder, 'images') # 位姿路径 model_dir = os.path.join(args.folder, 'sparse') # 这两个文件夹是我们要保存的结果 cam_dir = os.path.join(args.folder, 'cams') renamed_dir = os.path.join(args.folder, 'images') # 相机参数、图像、3D点读入到变量中 cameras, images, points3d = read_model(model_dir, '.txt') #cameras, images, points3d = read_model(model_dir, '.bin') num_images = len(list(images.items())) param_type = { 'SIMPLE_PINHOLE': ['f', 'cx', 'cy'], 'PINHOLE': ['fx', 'fy', 'cx', 'cy'], 'SIMPLE_RADIAL': ['f', 'cx', 'cy', 'k'], 'SIMPLE_RADIAL_FISHEYE': ['f', 'cx', 'cy', 'k'], 'RADIAL': ['f', 'cx', 'cy', 'k1', 'k2'], 'RADIAL_FISHEYE': ['f', 'cx', 'cy', 'k1', 'k2'], 'OPENCV': ['fx', 'fy', 'cx', 'cy', 'k1', 'k2', 'p1', 'p2'], 'OPENCV_FISHEYE': ['fx', 'fy', 'cx', 'cy', 'k1', 'k2', 'k3', 'k4'], 'FULL_OPENCV': ['fx', 'fy', 'cx', 'cy', 'k1', 'k2', 'p1', 'p2', 'k3', 'k4', 'k5', 'k6'], 'FOV': ['fx', 'fy', 'cx', 'cy', 'omega'], 'THIN_PRISM_FISHEYE': ['fx', 'fy', 'cx', 'cy', 'k1', 'k2', 'p1', 'p2', 'k3', 'k4', 'sx1', 'sy1'] } # intrinsic intrinsic = {} for camera_id, cam in cameras.items(): params_dict = {key: value for key, value in zip(param_type[cam.model], cam.params)} print(cam.model) if 'f' in param_type[cam.model]: params_dict['fx'] = params_dict['f'] params_dict['fy'] = params_dict['f'] i = np.array([ [params_dict['fx'], 0, params_dict['cx']], [0, params_dict['fy'], params_dict['cy']], [0, 0, 1] ]) intrinsic[camera_id] = i print('intrinsic[0]\n', intrinsic, end='\n\n') # extrinsic extrinsic = {} for image_id, image in images.items(): e = np.zeros((4, 4)) e[:3, :3] = qvec2rotmat(image.qvec) e[:3, 3] = image.tvec e[3, 3] = 1 extrinsic[image_id] = e print('extrinsic[1]\n', extrinsic[1], end='\n\n') # depth range and interval depth_ranges = {} for i in range(num_images): zs = [] for p3d_id in images[i+1].point3D_ids: if p3d_id == -1: continue transformed = np.matmul(extrinsic[i+1], [points3d[p3d_id].xyz[0], points3d[p3d_id].xyz[1], points3d[p3d_id].xyz[2], 1]) zs.append(np.asscalar(transformed[2])) zs_sorted = sorted(zs) # relaxed depth range depth_min = zs_sorted[int(len(zs) * .01)] depth_max = zs_sorted[int(len(zs) * .99)] depth_ranges[i+1] = (depth_min, depth_max) print('depth_ranges[1]\n', depth_ranges[1], end='\n\n') # view selection score = np.zeros((len(images), len(images))) queue = [] for i in range(len(images)): for j in range(i + 1, len(images)): queue.append((i, j)) # def calc_score(inputs): # i, j = inputs # id_i = images[i+1].point3D_ids # id_j = images[j+1].point3D_ids # id_intersect = [it for it in id_i if it in id_j] # cam_center_i = -np.matmul(extrinsic[i+1][:3, :3].transpose(), extrinsic[i+1][:3, 3:4])[:, 0] # cam_center_j = -np.matmul(extrinsic[j+1][:3, :3].transpose(), extrinsic[j+1][:3, 3:4])[:, 0] # score = 0 # for pid in id_intersect: # if pid == -1: # continue # p = points3d[pid].xyz # theta = (180 / np.pi) * np.arccos(np.dot(cam_center_i - p, cam_center_j - p) / np.linalg.norm(cam_center_i - p) / np.linalg.norm(cam_center_j - p)) # score += np.exp(-(theta - args.theta0) * (theta - args.theta0) / (2 * (args.sigma1 if theta <= args.theta0 else args.sigma2) ** 2)) # return i, j, score # p = mp.Pool(processes=mp.cpu_count()) # result = p.map(calc_score, queue) for i, j in queue: id_i = images[i+1].point3D_ids id_j = images[j+1].point3D_ids id_intersect = [it for it in id_i if it in id_j] cam_center_i = -np.matmul(extrinsic[i+1][:3, :3].transpose(), extrinsic[i+1][:3, 3:4])[:, 0] cam_center_j = -np.matmul(extrinsic[j+1][:3, :3].transpose(), extrinsic[j+1][:3, 3:4])[:, 0] s = 0 for pid in id_intersect: if pid == -1: continue p = points3d[pid].xyz theta = (180 / np.pi) * np.arccos(np.dot(cam_center_i - p, cam_center_j - p) / np.linalg.norm(cam_center_i - p) / np.linalg.norm(cam_center_j - p)) s += np.exp(-(theta - args.theta0) * (theta - args.theta0) / (2 * (args.sigma1 if theta <= args.theta0 else args.sigma2) ** 2)) score[i, j] = s score[j, i] = s view_sel = [] for i in range(len(images)): sorted_score = np.argsort(score[i])[::-1] view_sel.append([(k, score[i, k]) for k in sorted_score[:10]]) print('view_sel[0]\n', view_sel[0], end='\n\n') # write try: os.makedirs(cam_dir) except os.error: print(cam_dir + ' already exist.') for i in range(num_images): with open(os.path.join(cam_dir, '%08d_cam.txt' % i), 'w') as f: f.write('extrinsic\n') for j in range(4): for k in range(4): f.write(str(extrinsic[i+1][j, k]) + ' ') f.write('\n') f.write('\nintrinsic\n') for j in range(3): for k in range(3): f.write(str(intrinsic[images[i+1].camera_id][j, k]) + ' ') f.write('\n') f.write('\n%f %f \n' % (depth_ranges[i+1][0], depth_ranges[i+1][1])) with open(os.path.join(args.folder, 'pair.txt'), 'w') as f: f.write('%d\n' % len(images)) for i, sorted_score in enumerate(view_sel): f.write('%d\n%d ' % (i, len(sorted_score))) for image_id, s in sorted_score: f.write('%d %f ' % (image_id, s)) f.write('\n') for i in range(num_images): if args.convert_format: img = cv2.imread(os.path.join(image_dir, images[i+1].name)) cv2.imwrite(os.path.join(renamed_dir, '%08d.jpg' % i), img) else: shutil.copyfile(os.path.join(image_dir, images[i+1].name), os.path.join(renamed_dir, '%08d.jpg' % i))
智能推荐
C语言杂记3_movc字节数-程序员宅基地
文章浏览阅读381次。四、数据类型标识符 区分大小写,首字母为字母或下划线关键字 具有固定名称和含义char 通常用于定义处理字符数据的变量或常量,默认值为signed char 类型。signed char 类型用字节中最高位字节表示数据的符号,“0”表示正数,“1”表示负数,负数用补码表示。*正数的补码与原码相同,负二进制数的补码等于它的绝对值按位取反后加 1。int 默认值为signed int 类型,..._movc字节数
SEO内链优化的8个终极策略-程序员宅基地
文章浏览阅读285次。网站SEO优化主要分为两个大类,一类是站外优化,另一类是站内优化。站内优化的内链建设优化是SEO优化工作的重中之重,可以视为网站内部的内功修炼之一。本文将介绍什么是内链,网站页面设置内链的方法,以及详细阐述了SEO内链优化的8个终极策略。内链应该是有意义和有目的的,而不是随机添加的链接。内链应该有助于用户和搜索引擎理解网站的内容,提高相关性和可访问性。过度使用内链或不相关的内链可能会降低用户体验,因此应该谨慎使用。
asp.net控件开发基础(20)-程序员宅基地
文章浏览阅读34次。示例代码 上面我们讨论了数据绑定控件的做法,但都未涉及到asp.net2.0中数据源控件的用法,让用惯了数据源控件的人可能感觉不适应。这次我们就开始讨论在asp.net2.0中,我们该如何重新定义数据绑定控件。我一直在想,是先讨论数据源控件呢,还是先讨论数据绑定控件,两者是密不可分的。在看下文之前,我想大家应该对asp.net2.0中的数据源控件使用的简易性非常...
【多径衰落仿真】小尺度多径衰落仿真(Jakes模型)【含Matlab源码 3405期】_matlab wsn多径衰落信道建模-程序员宅基地
文章浏览阅读486次,点赞14次,收藏10次。小尺度多径衰落仿真(Jakes模型)完整的代码,方可运行;可提供运行操作视频!适合小白!_matlab wsn多径衰落信道建模
【C++】STL 容器 - string 字符串操作 ⑧ ( string 字符串相关算法 | 字符串转换 - std::transform 函数 | 字符串翻转- std::reverse 函数 )_c++ string反转函数-程序员宅基地
文章浏览阅读480次。一、string 字符串转换 - std::transform 函数1、std::transform 函数原型说明2、代码示例 - string 类 transform 函数转换二、string 字符串翻转 - std::reverse 函数1、std::reverse 函数原型说明2、代码示例 - std::reverse 函数_c++ string反转函数
基于灰狼优化算法优化XGBOOST实现故障数据分类附matlab代码GWO-XGBOOST-程序员宅基地
文章浏览阅读35次。故障数据分类一直是工程领域中一个重要的课题,尤其是在大型设备和系统中。通过对故障数据进行分类,我们可以更好地理解设备的运行状况,及时发现问题,并采取相应的措施进行维修和保养。在过去的研究中,XGBOOST算法在故障数据分类中取得了一定的成果,但是在实际应用中仍然存在一些问题,比如算法的收敛速度和分类准确度等方面还有待提高。近年来,灰狼优化算法作为一种新兴的优化算法,受到了越来越多研究者的关注。该算法模拟了灰狼群体的社会行为,具有较强的全局寻优能力和快速收敛速度,逐渐被应用到了各个领域。
随便推点
arcgis10.2发布要素服务(feature service)_gis10.2可以发要素服务吗-程序员宅基地
文章浏览阅读2.8k次。一、创建地理数据库1.需要安装ArcSDE2.在arcCatalog里创建地理数据库 二、ArcGIS Server 注册托管数据库1.添加一个数据库连接 2.在server里注册托管数据库 在arcCatalog里右键选server properties_gis10.2可以发要素服务吗
ubuntu下conda如何设置镜像源(清华镜像源)_ubuntu conda 设置镜像-程序员宅基地
文章浏览阅读2.4k次,点赞10次,收藏19次。首先贴出.condarc,直接给出清华的镜像源,需要的小伙伴直接使用,别看内容了添加conda镜像源命令(直接使用)接下来开始慢慢介绍了。_ubuntu conda 设置镜像
LSB隐写的信息导出_png图片lsb-程序员宅基地
文章浏览阅读363次。如果图像是 jpg 图片的话,就没法使用lsb隐写了,原因是 jpg 图片对像数进行了有损压缩,我们修改的信息就可能会在压缩的过程中被破坏。png 图片中的图像像数一般是由 RGB 三原色(红绿蓝)组成,每一种颜色占用8位,取值范围为 0x00~0xFF,即有 256 种颜色,一共包含了 256 的3次方的颜色,即 16777216 种颜色。LSB 隐写就是修改 RGB 颜色分量的最低二进制位也就是最低有效位(LSB),而人类的眼睛不会注意到这前后的变化,每个像数可以携带3比特的信息。_png图片lsb
宠物领养系统(源码+开题)-程序员宅基地
文章浏览阅读813次,点赞17次,收藏22次。本系统(程序源码)带文档lw万字以上文末可获取一份本项目的java源码和数据库参考。系统程序文件列表开题报告内容研究背景: 随着人们生活水平的提高,越来越多的人选择养宠物来陪伴自己。然而,由于一些不负责任的宠物主人或者无法承担养宠物的责任,导致大量的流浪动物出现。为了解决这一问题,许多组织和机构开始提供宠物领养服务。然而,传统的宠物领养管理方式存在着诸多问题,如信息不透明、效率低下等,无法满足现代宠物领养服务的需求。因此,建立一个高效、智能的宠物领养管理系统势在必行。
snmp服务配置功能_snmputil get 192.168.0.3 public .1.3.6.1.2.1.1.3.0-程序员宅基地
文章浏览阅读1.6k次。本来是默认配置就可以的 但是有时候会出现这个错误 error on SnmpMgrRequest 40解决方法:1,进入本机的服务,然后找到snmp双击进行配置2,陷阱里添加团体名称public 添加到列表 。下面添加陷阱目标:127.0.0.13,安全里添加 团体名称:public 勾上“发送身份验证陷阱”。4,最后点确定 。重新输入命令:snmputil get 1_snmputil get 192.168.0.3 public .1.3.6.1.2.1.1.3.0什么意思
XP SN-程序员宅基地
文章浏览阅读1.1k次。CYKG6-VVD9B-9TQ8Q-68JXJ-4VMQ8TBR2X-BPTYD-FGXHR-7G8T4-7PKVMDJGDQ-3MGQF-6QMBC-FCBFD-V967BM8WQD-DFWVD-WHTFD-PXY7B-M27V8MT8KK-JRRP9-P2J28-3KPDG-T6HRWJBQKD-FYJFQ-3VGKW-VYR2K-RYBGBR9BHR-6BWTM-W7..._sn.xpxx