Python网络爬虫与信息提取——网络爬虫Scrapy框架_网络爬虫与信息提取 目录-程序员宅基地
技术标签: 爬虫 MOOC python 笔记 Scrapy框架
第五章 网络爬虫之Scrapy框架
● Scrapy爬虫框架
- Scrapy爬虫框架介绍
1、Scrapy安装:cmd-> pip install scrapy
2、Scrapy不是一个函数功能库而是一个爬虫框架。
爬虫框架:
1)爬虫框架是实现爬虫功能的一个软件结构和功能组件集合。
2)爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
3、Scrapy爬虫框架结构(5主要模块+2中间键)
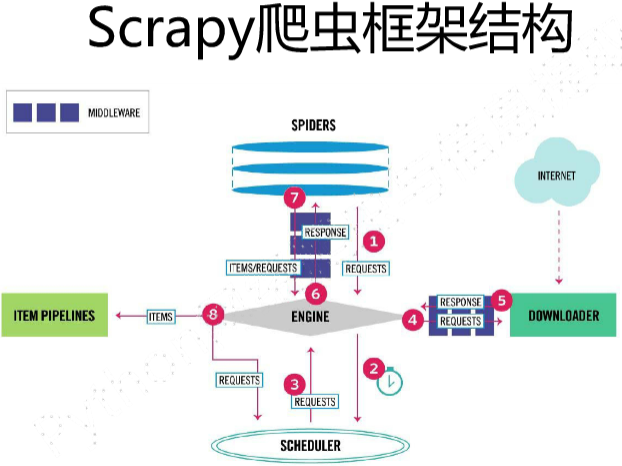
数据流的三个路径
路径1:
1)Engine从 Spider处获得爬取请求( Request);
2)Engine将爬取请求转发给 Scheduler,用于调度;
路径2:
3)Engine从 Scheduler处获得下一个要爬取的请求;
4)Engine将爬取请求通过中间件发送给 Downloader;
5)爬取网页后, Downloader形成响应( Response),通过中间件发给 Engine;
6)Engine将收到的响应通过中间件发送给 Spider处理;
路径3:
7)Spider处理响应后产生爬取项(scraped Item)和新的爬取请求( Requests)给Engine;
8)Engine将爬取项发送给Item Pipeline(框架出口);
9)Engine将爬取请求发送给Scheduler。
数据流的出入口
Engine控制各模块数据流,不间断从 Scheduler处获得爬取请求,直至请求为空。
框架入口: Spider的初始爬取请求
框架出口: Item Pipeline
ENGINE、SCHEDULER、DOWNLOAD模块功能已有实现,SPIDERS、ITEM PIPELINES模块有用户编写(配置)。 - Scrapy爬虫框架解析
1、Engine模块(不需要用户修改)—核心
1)控制所有模块之间的数据流;
2)根据条件触发事件;
2、Downloader模块(不需要用户修改:根据请求下载网页;
3、Scheduler模块(不需要用户修改:对所有爬取请求进行调度管理;
4、Spider模块(需用户编写配置代码)
1)解析Downloader返回的响应(Response);
2)产生爬取项(scraped item);
3)产生额外的爬取请求(Request);
5、Item Pipelines模块(需用户编写配置代码)
1)以流水线方式处理 Spider产生的抓取项;
2)由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型;
3)可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库;
6、Downloader Middleware中间键(用户可编写配置代码)
目的:实施 Engine、Scheduler和Downloader间进用户可配置的控制;
功能:修改、丟弃、新增请求或响应;
7)Spider middleware中间键(用户可编写配置代码)
目的:对请求和爬取项的再处理;
功能:修改、丢弃、新增请求或爬取项。 - requests库和Scrapy爬虫比较
1、相同点
1)两者都可以进行页面请求和爬取, Python爬虫的两个重要技术路线;
2)两者可用性都好,文档丰富,入门简单;
3)两者都没有处理js、提交表单、应对验证码等功能(可扩展)。
2、不同点
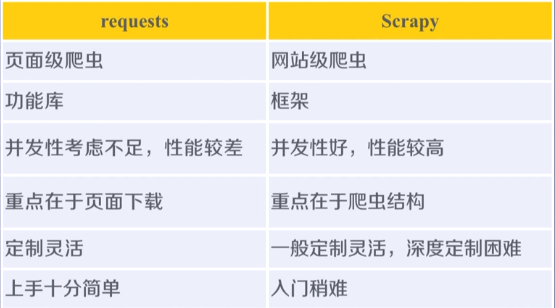
3、开发爬虫技术路线选择
1)非常小的需求, requests库。
2)不太小的需求, Scrapy框架。
3)定制程度很高的需求(不考虑规模),自搭框架,requests>Scrapy。 - Scrapy爬虫常用命令
1、Scrapy命令行:Scrapy是为持续运行设计的专业爬虫框架,提供操作的Scrap命令行,打开命令行操作:CMD窗口->scrapy -h。
2、Scrapy命令行格式

3、Scrapy常用命令
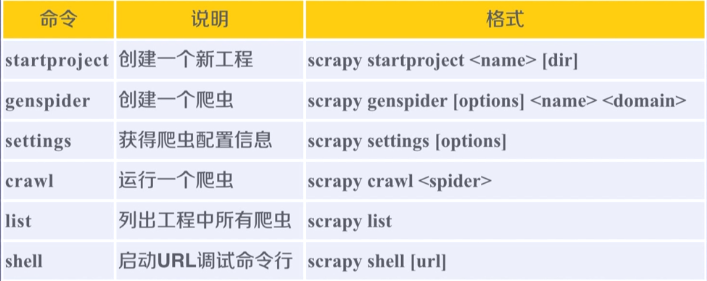
最常用:startproject、genspider、crawl
4、为什么 Scrapy采用命令行创建和运行爬虫?
1)命令行(不是图形界面)更容易自动化,适合脚本控制;
2)本质上,Scrapy是给程序员用的,功能(而不是界面)更重要。
● Scrapy爬虫基本使用
- Scrapy爬虫案列讲解
应用Scrapy爬虫框架主要是编写配置型代码
1、产生步骤
步骤1:建立一个Scrapy爬虫工程
选取一个目录(F:\pycodes\),然后执行如下命令:
F:\pycodes>scrapy startprojrct python123demo
Scrapy 1.6.0 - no active project
Unknown command: startprojrct
Use "scrapy" to see available commands
F:\pycodes>scrapy startproject python123demo
New Scrapy project 'python123demo', using template directory 'c:\users\hp\appdata\local\programs\python\python37-32\lib\site-packages\scrapy\templates\project', created in:
F:\pycodes\python123demo
You can start your first spider with:
cd python123demo
scrapy genspider example example.com
步骤2:在工程中产生一个Scrapy爬虫
进入工程目录(F:\pycodes\python123demo),然后执行如下命令:
F:\pycodes\python123demo>scrapy genspider demo python123.io
Spider 'demo' already exists in module:
python123demo.spiders.demo
该命令作用:
1)生成一个名称为demo的spider;
2)在spiders目录下增加代码文件 demo.py;
该命令仅用于生成 demo.py,该文件也可以手工生成。
步骤3:配置产生的spider爬虫
配置:1)初始URL地址;2)获取页面后的解析方式
import scrapy
class DemoSpider(scrapy.Spider):
name = "demo"
#allowed_domains = ["python123.io"]
start_urls = ['https://python123.io/ws/demo.html']
def parse(self, response):
fname = response.url.split('/')[-1]
with open(fname, 'wb') as f:
f.write(response.body)
self.log('Saved file %s.' % name)
步骤4:运行爬虫,获取网页
在命令行下,执行如下命令:demo爬虫被执行,捕获页面存储在demo.html
F:\pycodes\python123demo>scrapy crawl demo
2、生成的工程目录结构
python123demo/ --------------→外层目录
scrap.cfg --------→部署 Scrapy爬虫的配置文件(将爬虫放在特定的服务器,并在服务器配置相关的操作接口)
python 123demo/--------→Scrapy框架的用户自定义 Python代码
_init_.py -------→初始化脚本
items.py -------→Items代码模板(继承类)(一般不需要编写)
middlewares.py----→Middlewares代码模板(继承类)(扩展middlewares功能时编写)
pipelines.py -----→pipelines代码模板(继承类)
settings.py ------→scrap爬虫的配置文件(优化爬虫功能,需修改对应的配置项)
spiders/ -------→Spiders代码模板目录(继承类)(存放工程爬虫,要求其中爬虫符合爬虫模板的约束)
_init_.py —→初始文件,无需修改
_pycache_.py →缓存目录,无需修改
(内层目录结构 用户自定义的spider代码增加在此处)
3、工程爬虫模板

1)类必须继承于scrapy.Spider子类;
2)name为当前爬虫名;
3)allowed_domains为提交给命令行的域名,爬虫在爬取网站只能爬取这个域名以下的相关链接;
4) start_urls以列表形式包含的一个或多个url,为scrapy框架最初爬取网址;
5)parse()用于处理响应,解析内容形成字典,发现新的URL爬取请求。
- yield关键字的使用
1、yield←→ 生成器
1)生成器是一个不断产生值的函数;
2)包含yield语句的函数是一个生成器;
3)生成器每次产生一个值(yield语句),函数被冻结,被唤醒后再产生一个值。
2、生成器相比一次列出所有内容的优势:
1)更节省存储空间;
2)响应更迅速;
3)使用更灵活。 - Scrapy爬虫基本使用
1、Scrapy爬虫的使用步骤
步骤1:创建一个工程和Spider模板;
步骤2:编写Spider;
步骤3:编写Item Pipeline;
步骤4:优化配置策略。
2、Scrapy爬虫的数据类型
Request类:class scrapy.http.Request()
Request类介绍:
1)Request对象表示一个HTTP请求;
2)由Spider生成,由Downloader执行。
Request类方法 Response类:class scrapy.http.Response()
Response类:class scrapy.http.Response()
Response类介绍:
1)Response对象表示一个HTTP响应;
2)由Downloader生成,由Spider处理。
Response类方法
 Item类:class scrapy.item.Item()
Item类:class scrapy.item.Item()
Item类介绍:
1)Item对象表示一个从HTML页面中提取的信息内容;
2)由Spider生成,由Item Pipeline处理;
3)Item类似字典类型,可以按照字典类型操作。
3、Scrapy爬虫支持多种HTML信息提取方法:
• Beautiful Soup
• lxml
• re
• XPath Selector
• CSS Selector
CSS Selector的基本使用
1)格式:
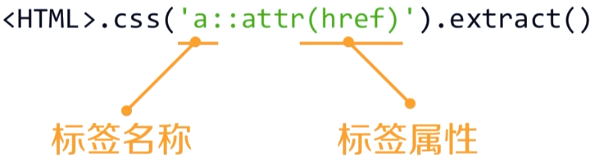
2)CSS Selector由W3C组织维护并规范
● Scrapy爬虫实例
- 股票数据 Scrape爬中实例介绍
1、功能描述
目标:获取上交所和深交所所有股票的名称和交易信息
输出:保存到文件中
技术路线:scrapy
2、数据网站的确定
获取股票列表:
东方财富网:http://quote.eastmoney.com/stocklist.html
获取个股信息:
百度股票:https://gupiao.baidu.com/stock/
单个股票:https://gupiao.baidu.com/stock/sz002439.html
3、程序框架:编写spider处理链接爬取和页面解析,编写pipelines处理信息存储。 - “股票数据 Scrap爬虫实例编写(仅供参考)
步骤
步骤1:建立工程和Spider模板
1)>scrapy startproject BaiduStocks
2)>cd BaiduStocks
3)>scrapy genspider stocks baidu.com
4)进一步修改spiders/stocks.py文件
步骤2:编写Spider
1)配置stocks.py文件
2)对返回页面的处理
3)修改对新增URL爬取请求的处理
stocks.py文件源代码
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = "stocks"
start_urls = ['https://quote.eastmoney.com/stocklist.html']
def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"[s][hz]\d{6}", href)[0]
url = 'https://gupiao.baidu.com/stock/' + stock + '.html'
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
def parse_stock(self, response):
infoDict = {
}
stockInfo = response.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dt').extract()
valueList = stockInfo.css('dd').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*</dt>', keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*</dd>', valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key]=val
infoDict.update(
{
'股票名称': re.findall('\s.*\(',name)[0].split()[0] + \
re.findall('\>.*\<', name)[0][1:-1]})
yield infoDict
步骤3:编写ITEM Pipelines
1)配置pipelines.py文件
pipelines.py文件源代码
class BaidustocksPipeline(object):
def process_item(self, item, spider):
return item
class BaidustocksInfoPipeline(object):
def open_spider(self, spider):
self.f = open('BaiduStockInfo.txt', 'w')
def close_spider(self, spider):
self.f.close()
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
2)定义对爬取项(Scraped Item)的处理类
3)配置ITEM_PIPELINES选项
settings.py文件中被修改的区域
ITEM_PIPELINES = {
'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300,
}
步骤4:程序的执行:>scrapy crawl stocks
- “股票数据 Scrap爬虫实例优化
配置并发连接选项——settings.py文件

智能推荐
2022黑龙江最新建筑八大员(材料员)模拟考试试题及答案_料账的试题-程序员宅基地
文章浏览阅读529次。百分百题库提供建筑八大员(材料员)考试试题、建筑八大员(材料员)考试预测题、建筑八大员(材料员)考试真题、建筑八大员(材料员)证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。310项目经理部应编制机械设备使用计划并报()审批。A监理单位B企业C建设单位D租赁单位答案:B311对技术开发、新技术和新工艺应用等情况进行的分析和评价属于()。A人力资源管理考核B材料管理考核C机械设备管理考核D技术管理考核答案:D312建筑垃圾和渣土._料账的试题
chatgpt赋能python:Python自动打开浏览器的技巧-程序员宅基地
文章浏览阅读614次。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。AI职场汇报智能办公文案写作效率提升教程 专注于AI+职场+办公方向。下图是课程的整体大纲下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具。_python自动打开浏览器
Linux中安装JDK-RPM_linux 安装jdk rpm-程序员宅基地
文章浏览阅读545次。Linux中安装JDK-RPM方式_linux 安装jdk rpm
net高校志愿者管理系统-73371,计算机毕业设计(上万套实战教程,赠送源码)-程序员宅基地
文章浏览阅读25次。免费领取项目源码,请关注赞收藏并私信博主,谢谢-高校志愿者管理系统主要功能模块包括页、个人资料(个人信息。修改密码)、公共管理(轮播图、系统公告)、用户管理(管理员、志愿用户)、信息管理(志愿资讯、资讯分类)、活动分类、志愿活动、报名信息、活动心得、留言反馈,采取面对对象的开发模式进行软件的开发和硬体的架设,能很好的满足实际使用的需求,完善了对应的软体架设以及程序编码的工作,采取SQL Server 作为后台数据的主要存储单元,采用Asp.Net技术进行业务系统的编码及其开发,实现了本系统的全部功能。
小米宣布用鸿蒙了吗,小米OV对于是否采用鸿蒙保持沉默,原因是中国制造需要它们...-程序员宅基地
文章浏览阅读122次。原标题:小米OV对于是否采用鸿蒙保持沉默,原因是中国制造需要它们目前华为已开始对鸿蒙系统大规模宣传,不过中国手机四强中的另外三家小米、OPPO、vivo对于是否采用鸿蒙系统保持沉默,甚至OPPO还因此而闹出了一些风波,对此柏铭科技认为这是因为中国制造当下需要小米OV几家继续将手机出口至海外市场。 2020年中国制造支持中国经济渡过了艰难的一年,这一年中国进出口贸易额保持稳步增长的势头,成为全球唯一..._小米宣布用鸿蒙系统
Kafka Eagle_kafka eagle git-程序员宅基地
文章浏览阅读1.3k次。1.Kafka Eagle实现kafka消息监控的代码细节是什么?2.Kafka owner的组成规则是什么?3.怎样使用SQL进行kafka数据预览?4.Kafka Eagle是否支持多集群监控?1.概述在《Kafka 消息监控 - Kafka Eagle》一文中,简单的介绍了 Kafka Eagle这款监控工具的作用,截图预览,以及使用详情。今天_kafka eagle git
随便推点
Eva.js是什么(互动小游戏开发)-程序员宅基地
文章浏览阅读1.1k次,点赞29次,收藏19次。Eva.js 是一个专注于开发互动游戏项目的前端游戏引擎。:Eva.js 提供开箱即用的游戏组件供开发人员立即使用。是的,它简单而优雅!:Eva.js 由高效的运行时和渲染管道 (Pixi.JS) 提供支持,这使得释放设备的全部潜力成为可能。:得益于 ECS(实体-组件-系统)架构,你可以通过高度可定制的 API 扩展您的需求。唯一的限制是你的想象力!_eva.js
OC学习笔记-Objective-C概述和特点_objective-c特点及应用领域-程序员宅基地
文章浏览阅读1k次。Objective-C概述Objective-C是一种面向对象的计算机语言,1980年代初布莱德.考斯特在其公司Stepstone发明Objective-C,该语言是基于SmallTalk-80。1988年NeXT公司发布了OC,他的开发环境和类库叫NEXTSTEP, 1994年NExt与Sun公司发布了标准的NEXTSTEP系统,取名openStep。1996_objective-c特点及应用领域
STM32学习笔记6:TIM基本介绍_stm32 tim寄存器详解-程序员宅基地
文章浏览阅读955次,点赞20次,收藏16次。TIM(Timer)定时器定时器可以对输入的时钟进行计数,并在计数值达到设定值时触发中断16位计数器、预分频器、自动重装寄存器的时基单元,在 72MHz 计数时钟下可以实现最大 59.65s 的定时,59.65s65536×65536×172MHz59.65s65536×65536×721MHz不仅具备基本的定时中断功能,而且还包含内外时钟源选择、输入捕获、输出比较、编码器接口、主从触发模式等多种功能。_stm32 tim寄存器详解
前端基础语言HTML、CSS 和 JavaScript 学习指南_艾编程学习资料-程序员宅基地
文章浏览阅读1.5k次。对于任何有兴趣学习前端 Web 开发的人来说,了解 HTML、CSS 和JavaScript 之间的区别至关重要。这三种前端语言都是您访问过的每个网站的用户界面构建块。而且,虽然每种语言都有不同的功能重点,但它们都可以共同创建令人兴奋的交互式网站,让用户保持参与。因此,您会发现学习所有三种语言都很重要。如果您有兴趣从事前端开发工作,可以通过多种方式学习这些语言——在艾编程就可以参与到学习当中来。在本文中,我们将回顾每种语言的特征、它们如何协同工作以及您可以在哪里学习它们。HTML vs C._艾编程学习资料
三维重构(10):PCL点云配准_局部点云与全局点云配准-程序员宅基地
文章浏览阅读2.8k次。点云配准主要针对点云的:不完整、旋转错位、平移错位。因此要得到完整点云就需要对局部点云进行配准。为了得到被测物体的完整数据模型,需要确定一个合适的坐标系变换,将从各个视角得到的点集合并到一个统一的坐标系下形成一个完整的数据点云,然后就可以方便地进行可视化,这就是点云数据的配准。点云配准技术通过计算机技术和统计学规律,通过计算机计算两个点云之间的错位,也就是把在不同的坐标系下的得到的点云进行坐标变..._局部点云与全局点云配准
python零基础学习书-Python零基础到进阶必读的书藉:Python学习手册pdf免费下载-程序员宅基地
文章浏览阅读273次。提取码:0oorGoogle和YouTube由于Python的高可适应性、易于维护以及适合于快速开发而采用它。如果你想要编写高质量、高效的并且易于与其他语言和工具集成的代码,《Python学习手册:第4 版》将帮助你使用Python快速实现这一点,不管你是编程新手还是Python初学者。本书是易于掌握和自学的教程,根据作者Python专家Mark Lutz的著名培训课程编写而成。《Python学习..._零基础学pythonpdf电子书