00_Ubuntu系统入门_ubuntu入门-程序员宅基地
技术标签: 学习 嵌入式Linux驱动开发 ubuntu linux
目录
前言
前一段时间学习Linux驱动,实在是迷糊了。
决定利用闲余时间,整理笔记,争取消除困惑。
打算从基础(Ubuntu入门)开始,把笔记整理一番。
这篇主要是为了驱动学习做的前期工作。
全文大量参考正点原子的教程,在此对正点原子团队表示感谢。
一、Ubuntu系统安装
简单来说,分两步:1.安装VMware。2.安装Ubuntu。
过程很简单,我是参考正点原子教程安装的,当然也遇到了一些问题,总结如下:
1.1 VMware15安装虚拟机不兼容,无法打开
先把VMware15卸载,然后安装VMware16。
VMware15卸载参考:https://blog.csdn.net/qq_45011675/article/details/105476677
VMware16安装教程:https://blog.csdn.net/m0_50519965/article/details/116175873
1.2 Ubuntu联网问题
安装好的Ubuntu无法联网,下面是找的一种联网方式,可参考。
链接:让Ubuntu联网
二、Ubuntu系统入门
2.1 Ubuntu系统初体验
熟悉一下这个系统的图形界面,直接上图。
2.2 Ubuntu终端操作
鼠标右击,选择打开终端。
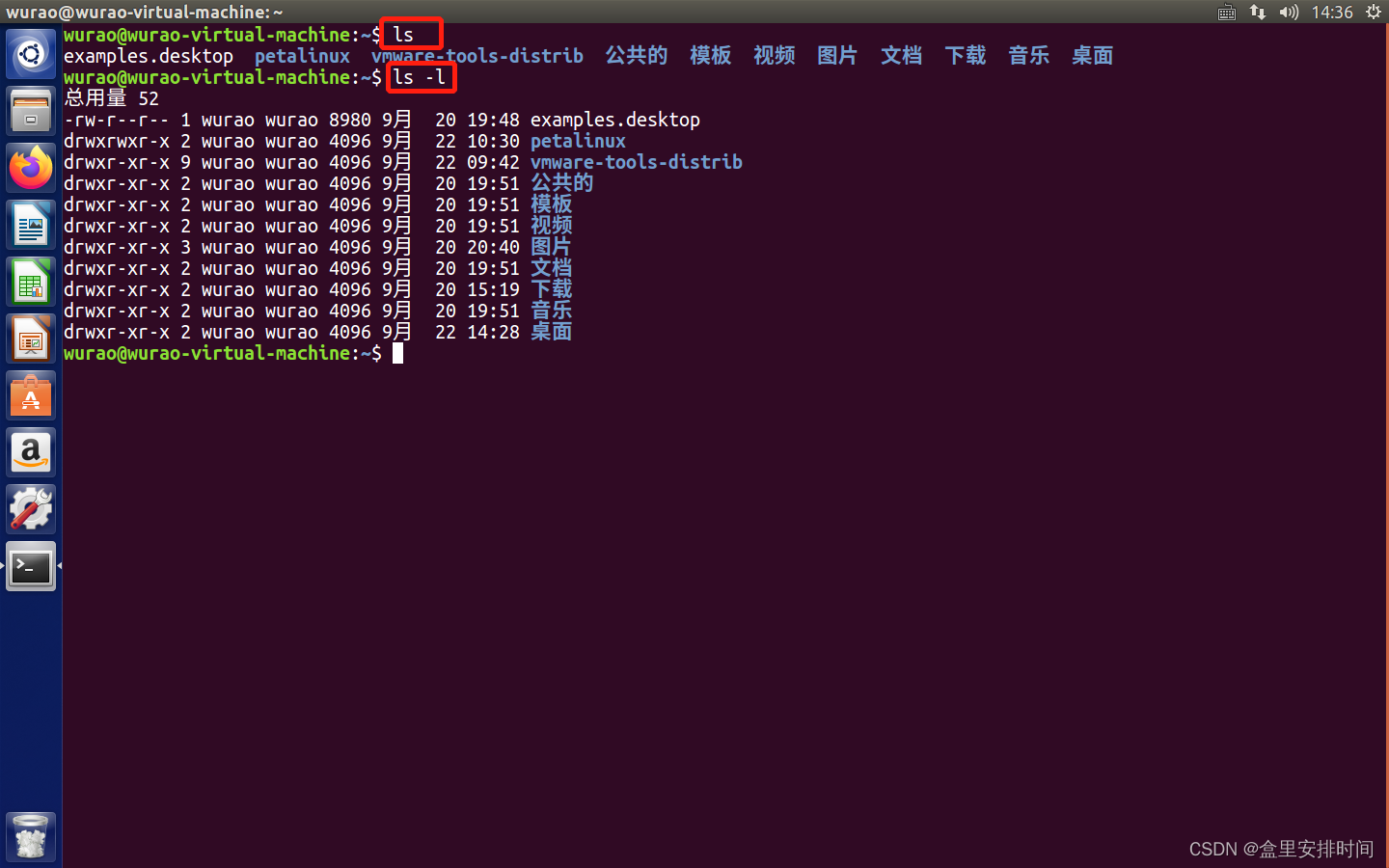
命令“ls”是打印出当前所在目录中所有文件和文件夹。
2.3 shell操作
2.3.1 shell简介
严格意义上来讲,Shell 是一个应用程序,它负责接收用户输入的命令,然后根据命令做出相应的动作,Shell 负责将应用层或者用户输入的命令传递给系统内核,由操作系统内核来完成相应的工作,然后将结果反馈给应用层或者用户。
2.3.2 Shell 基本操作
command -options [argument]
lsls -lls /usr
运行结果如下:
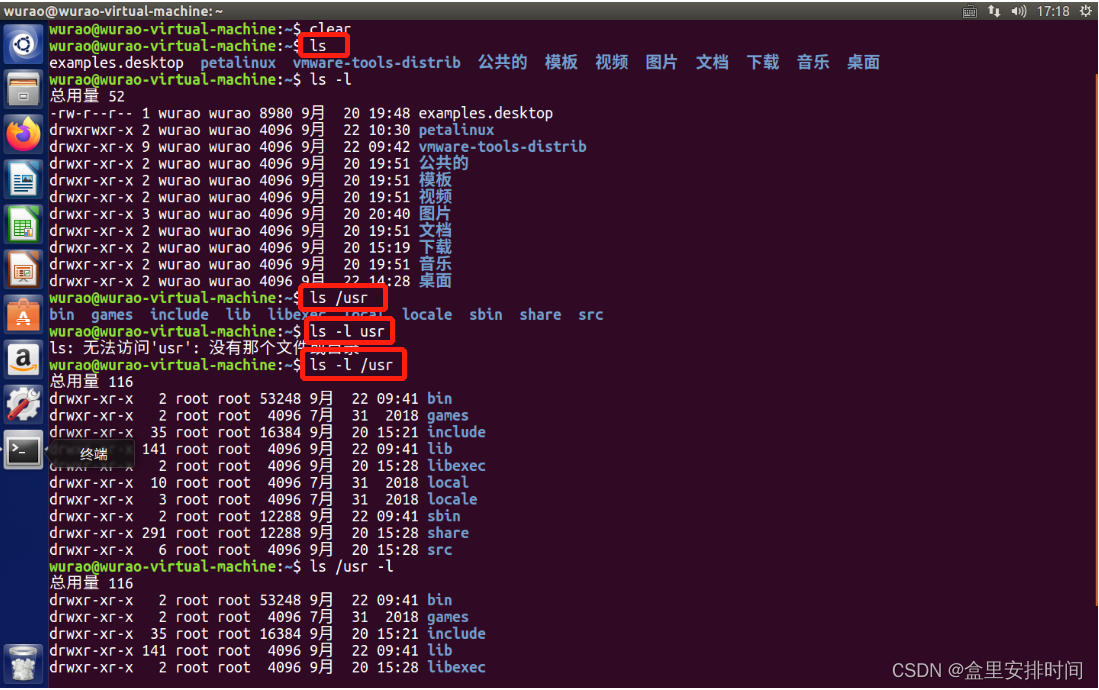
注:Shell 命令支持自动补全功能,使用自动补全功能以后我们只需要输入命令的前面一部分字母,然后按下 TAB 键,如果只有一个命令匹配的话就会自动补全这个命令剩下的字母。如果有多个命令匹配的话系统就会发出报警声音,此时在按下一次 TAB 键就会列出所有匹配的命令。
2.3.3 常用shell命令
ls [选项] [路径]
2.4 APT下载工具
APT 工具常用的命令如下:
1、更新本地数据库
sudo apt-get update
这个命令会访问源地址,并且获取软件列表并保存在本电脑上。
2、检查依赖关系
sudo apt-get check
3、软件安装
sudo apt-get install package-name
sudo apt-get install minicom
您希望继续执行吗?[Y/n]
sudo apt-get upgrade package-name
sudo apt-get remove package-name
2.5Ubuntu 下文本编辑
我个人比较喜欢的文本编辑方式是:
在Windows上编辑后,拷贝到Ubuntu。
Windows:notepad++ Ubuntu:vim
2.5.1 安装 VIM 编辑器:
sudo apt-get install vim
2.5.2 vim编辑器的使用
指令式的编辑器,不需要鼠标,也没有菜单,仅仅使用键盘来完成所有的编辑工作。
三种工作模式:输入模式、指令模式和底行模式,通过切换不同的模式可以完成不同的功能。
VIM 默认是以只读模式打开的文档,因此我们要切换到输入模式,切换到输入模式的命令如下:
按下键盘上的“a”键,这时候终端左下角会提 示“插入”字样,表示我们进入到了输入模式。
从 输入模式切换到指令模式:按下键盘的 ESC 键。
指令模式顾名思义就是输入指令的模式,这些指令是控制文本的指令:
1、移动光标指令:
2.6 Linux 文件系统
操作系统的基本功能之一就是文件管理,而文件的管理是由文件系统来完成的。Linux 支持多种文件系统,本节我们就来讲解 Linux 下的文件系统、文件系统类型、文件系统结构和文件系统相关 Shell 命令。
2.6.1 Linux 文件系统简介以及类型
Linux 下常用的磁盘分割工具为: fdisk 工具。
后面会用到:移植 Linux 的时候需要将 SD 卡分为两个分区来存储不同的东西。
格式化:使用 fdisk 创建好分区以后也是要先在创建好的分区上面创建文件系统。
在 Linux 下创建一个分区并且格式化好以后我们要将其 “挂载”到一个目录下才能访问这个分区。Linux 下我们使用 mount 命令来挂载磁盘。挂载磁盘的时候是需要确定挂载点 的,也就是你的这个磁盘要挂载到哪个目录下。
ext4 文件系统
在终端中输入如下命令来查询当前磁盘挂 载的是啥文件系统:
df -T -h
2.6.2 Linux 文件系统结构
根目录“/”
创建一个用户,系统会在/home 这个目录下创建一个以这个用户名命名的文件 夹,这个文件夹就是这个用户的根目录(“~”)。
cd / //进入到根目录“ / ”ls //查看根目录“ / ”下的文件以及文件夹
2.6.3 文件操作命令
1、创建新文件命令—touch
touch [参数] [文件名]
2、文件夹创建命令—mkdir
mkdir [参数] [文件夹名目录名]
rm [参数] [目的文件或文件夹目录名]
rmdir [参数] [文件夹(目录)]
cp [参数] [源地址] [目的地址]
mv [参数] [源地址] [目的地址]
2.6.4 命令行进行文件的压缩和解压缩
命令行下进行压缩和解压缩常用的命令有三个:zip、unzip 和 tar。
zip [参数] [压缩文件名.zip] [被压缩的文件]
unzip [参数] [压缩文件名.zip]
tar [参数] [压缩文件名] [被压缩文件名]
tar -vcjf test1.tar.bz2 test1tar -vczf test1.tar.gz test1
tar -vxjf test1.tar.bz2tar -vxzf test2.tar.gz
2.6.5 文件查询和搜索(没怎么用过)
1、命令 find
find [路径] [参数] [关键字]
2、命令 grep
grep [参数] 关键字 文件列表
2.6.6文件类型
2.7 Linux 用户权限管理
2.7.1Ubuntu 用户系统
cat /etc/passwd
2.7.2权限管理
-rw-rw-r-- 1 wurao wurao 0 10 月 12 21:14 test.c
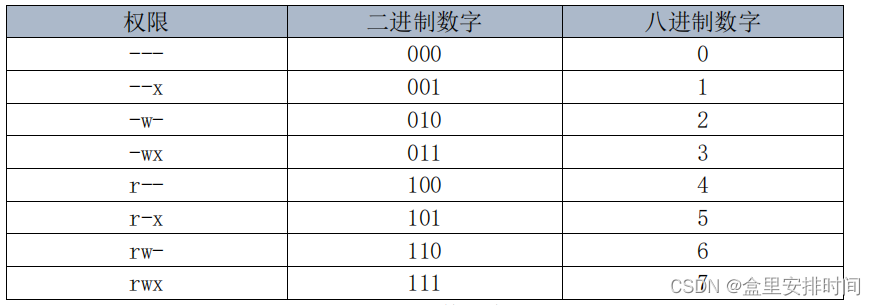
权限所对应的八进制数字就是每个权限对应的位相加,比如权限 rwx 就是 4+2+1=7。前面的文件 test.c 其权限为“rw-rw-r--”,因此其十进制表示就是:664。
另外我们也开始使用 a、u、g 和 o 表示文件的归属关系,用=、+和-表示文件权限的变化。
2.7.3 权限管理命令
1、权限修改命令 chmod
chmod [参数] [文件名/目录名]
chomd 766 test
chown [参数] [用户名.<组名>] [文件名/目录]
2.8 Linux磁盘管理
2.8.1 Linux磁盘管理基本概念
cat /etc/fstab
ls /dev/sd*
2.8.2 磁盘管理命令
1、磁盘分区命令 fdisk(放在后面详细操作)
fdisk [参数]
sudo fdisk /dev/sdb
三、Linux C 编程入门
Ubuntu 下也有一些可以进行编程的工具,但是大多都只是编辑器,也就是只能进行代码编辑。
Ubuntu 下要编译的话就需要用到 GCC 编译器,使用 GCC 编译器肯定就要接触到Makefile。
3.1 Hello World!
编写代码包括两部分:代码编写和编译。
代码编写用 notepad++ (Windows)和 VIM(Ubuntu)。
编译:GCC 编译器。
3.1.1编写代码
cd ~
mkdir C_Program
cd C_Program
mkdir 3.1
set ts=4
set nu
cd 3.1vi main.c
#include <stdio.h>
int main(int argc, char *argv[])
{
printf("Hello World!\n");
}cat main.c
3.1.2 编译代码
Ubuntu 下的 C 语言编译器是 GCC,GCC 编译器在我们安装 Ubuntu 的时候就已经默认安装好了,可以通过如下命令查看 GCC 编译器的版本号:
gcc -v
gcc main.c
gcc main.c –o main
3.2 GCC编译器
3.2.1 gcc 命令
gcc [选项] [文件名字]
3.2.2 编译错误警告
GCC 编译器和其它编译器一样,不仅能够检测出错误类型,而且标记除了错误发生在哪个文件、哪一行,方便我们去修改代码。
3.2.3 编译流程
GCC 编译器的编译流程是:预处理、汇编、编译和链接。预处理就是对程序中的宏定义等相关的内容先进行前期的处理。汇编是先将 C 文件转换为汇编文件。当 C 文件转换为汇编文件以后就是文件编译了,编译过程就是将 C 源文件编译成.o 结尾的目标文件。编译生成的.o 文 件不能直接执行,而是需要最后的链接,如果你的工程有很多个 c 源文件的话最终就会有很 多.o 文件,将这些.o 文件链接在一起形成完整的一个可执行文件。
上一小节演示的例程都只有一个文件,而且文件非常简单,因此可以直接使用 gcc 命令生成可执行文件,并没有先将 c 文件编译成.o 文件,然后在链接在一起。
3.3 Makefile 基础
3.3.1 何为Makefile
通过在终端执行 gcc 命令来完成 C 文件的编译,如果我们的工程只有一两个 C 文件还好,需要输入的命令不多,当文件有几十、上百甚至上万个的时候用终端输入 GCC 命令的方法显然是不现实的。
如果我们能够 编写一个文件,这个文件描述了编译哪些源码文件、如何编译那就好了,每次需要编译工程的时侯只需要使用这个文件就行了。
为此提出了一个解决大 工程编译的工具:Make,描述哪些文件需要编译、哪些需要重新编译的文件就叫做 Makefile。
Makefile 就跟脚本文件一样,Makefile 里面还可以执行系统命令。使用的时候只需要一 个 make 命令即可完成整个工程的自动编译,极大的提高了软件开发的效率。
如果大家以前一 直使用 IDE 来编写 C 语言的话肯定没有听说过 Makefile 这个东西,其实这些 IDE 是有的,只 不过这些 IDE 对其进行了封装,提供给大家的是已经经过封装后的图形界面了,我们在 IDE 中添加要编译的 C 文件,然后点击按钮就完成了编译。
作为一个专业的程序员,是 一定要懂得 Makefile 的,一是因为在 Linux 下你不得不懂 Makefile,再就是通过 Makefile 你就能了解整个工程的处理过程。
由于 Makefile 的知识比较多,完全可以单独写本书,因此本章我们只讲解 Makefile 基础 入门,如果想详细的研究 Makefile,推荐大家阅读《跟我一起写 Makefile》这份文档。
3.3.2 Makefile 的引入
完成一个小工程:通过键盘输入两个整形数字,然后计算他们的和并将结果显示在屏幕上。
包括以下文件:main.c,input.c , calcu.c,input.h,calcu.h
main.c 是主体
input.c 负责接收从键盘输入的数值
calcu.h 进行任意两个数相加
main.c :
#include <stdio.h>
#include "input.h"
#include "calcu.h"
int main(int argc, char *argv[])
{
int a, b, num;
input_int(&a, &b);
num = calcu(a, b);
printf("%d + %d = %d\r\n", a, b, num);
} #include <stdio.h>
#include "input.h"
void input_int(int *a, int *b)
{
printf("input two num:");
scanf("%d %d", a, b);
printf("\r\n");
} #include "calcu.h"
int calcu(int a, int b)
{
return (a + b);
}input.h :
#ifndef _INPUT_H
#define _INPUT_H
void input_int(int *a, int *b);
#endifcalcu.h :
#ifndef _CALCU_H
#define _CALCU_H
int calcu(int a, int b);
#endif接下来使用 3.1 节讲的方法来对其进行编 译,在终端输入如下命令:
gcc main.c calcu.c input.c -o main
使用命令“gcc main.c calcu.c input.c -o main”看起来很简单,只需要一行就可以完成编译,但是我们这个工程只有三个文件!如果几千个文件呢?再就是如果有一个文件被修改了呢,使用上面的命令编译的时候所有的文件都会重新编译,如果工程有几万个文件(Linux 源码就有这么多文件),想想这几万个文件编译一次所需要的时间就可怕。最好的办法肯定是哪个文件被修改了,只编译这个修改的文件即可,其它没有修改的文件就不需要再次重新编译了,为此我们改变我们的编译方法,如果第一次编译工程,我们先将工程中的文件都编译一遍,然后后面修改了哪个文件就编译哪个文件,命令如下:
gcc -c main.cgcc -c input.cgcc -c calcu.cgcc main.o input.o calcu.o -o main
gcc -c calcu.cgcc main.o input.o calcu.o -o main
但是这样就又有一个问题,如果修改的文件一多,我自己可能都不记得哪个文件修改过了, 然后忘记编译,然后……,为此我们需要这样一个工具:
很明显,能够完成这个功能的就是 Makefile 了,在工程目录下创建名为“Makefile”的文件,文件名一定要叫做“Makefile”!区分大小写!
在 Makefile 文件中输入如下代码:
main: main.o input.o calcu.o
gcc -o main main.o input.o calcu.o
main.o: main.c
gcc -c main.c
input.o: input.c
gcc -c input.c
calcu.o: calcu.c
gcc -c calcu.c
clean:
rm *.o
rm main上述代码中所有行首需要空出来的地方一定要使用“TAB”键!不要使用空格键!这是 Makefile 的语法要求。
Makefile 编写好以后我们就可以使用 Make 命令来编译我们的工程了,直接在命令行中输入“make”即可,Make 命令会在当前目录下查找是否存在“Makefile”这个文件,如果存在的话就会按照 Makefile 里面定义的编译方式进行编译。
3.4 Makefile 语法
3.4.1 Makefile 规则格式
目标… … : 依赖文件集合… …
命令 1
命令 2
… …比如下面这条规则:
main : main.o input.o calcu.o
gcc -o main main.o input.o calcu.o命令列表中的每条命令必须以 TAB 键开始,不能使用空格!
make 命令会为 Makefile 中的每个以 TAB 开始的命令创建一个 Shell 进程去执行。
了解了 Makefile 的基本运行规则以后我们再来分析一下 3.3 中的 Makefile,代码如下:
main: main.o input.o calcu.o
gcc -o main main.o input.o calcu.o
main.o: main.c
gcc -c main.c
input.o: input.c
gcc -c input.c
calcu.o: calcu.c
gcc -c calcu.c
clean:
rm *.o
rm main上述代码中一共有 5 条规则,1~2 行为第一条规则,3~4 行为第二条规则,5~6 行为第三条规则,7~8 行为第四条规则,10~12 为第五条规则,make 命令在执行这个 Makefile 的时候其执行步骤如下:
首先更新第一条规则中的 main,第一条规则的目标成为默认目标,只要默认目标更新了那么就完成了 Makefile 的工作,完成了整个 Makefile 就是为了完成这个工作。在第一次编译的时候由于 main 还不存在,因此第一条规则会执行,第一条规则依赖于文件 main.o、input.o和 calcu.o 这个三个.o 文件,这三个.o 文件目前还都没有,因此必须先更新这三个文件。make会查找以这三个.o 文件为目标的规则并执行。以 main.o 为例,发现更新 main.o 的是第二条规则,因此会执行第二条规则,第二条规则里面的命令为“gcc –c main.c”,这行命令很熟悉了吧,就是不链接编译 main.c,生成 main.o,其它两个.o 文件同理。最后一个规则目标是clean,它没有依赖文件,因此会默认为依赖文件都是最新的,所以其对应的命令不会执行,当我们想要执行 clean 的话可以直接使用命令“make clean”,执行以后就会删除当前目录下所有的.o 文件以及 main,因此 clean 的功能就是完成工程的清理。
总结一下 Make 的执行过程:
1) make 命令会在 当前目录下 查找以 Makefile(makefile 其实也可以)命名的文件。2) 当找到 Makefile 文件以后就会 按照 Makefile 中定义的规则去 编译生成最终的目标文件。3) 当发现目标文件 不存在,或者目标所依赖的文件比目标文件 新(也就是最后修改时间比目标文件晚) 的话就会执行后面的命令来 更新目标。
3.4.2 Makefile 变量
跟 C 语言一样 Makefile 也支持变量的,先看一下前面的例子:
main: main.o input.o calcu.o
gcc -o main main.o input.o calcu.o#Makefile 变量的使用
objects = main.o input.o calcu.o
main: $(objects)
gcc -o main $(objects)分析一下,第 1 行是注释,Makefile 中可以写注释,注释开头要用符号“#”。第 2 行我们定义了一个变量 objects,并且给这个变量进行了赋值,其值为字符串“main.o input.o calcu.o”,第 3 和 4 行使用到了变量 objects,Makefile 中变量的引用方法是“$(变量名)”,比如本例中的“$(objects)” 就是使用变量 objects。
Makefile 变量的赋值符有“=”,“:=”和“?=”,三种赋值符的区别:
1、赋值符“=”
使用“=”在给变量的赋值的时候,不一定要用已经定义好的值,也可以使用后面定义的值,比如如下代码:
name = zzk
curname = $(name)
name = wurao
print:
@echo curname: $(curname)我们来分析一下上述代码,第 1 行定义了一个变量 name,变量值为“zzk”,第 2 行也定义了一个变量 curname,curname 的变量值引用了变量 name,按照我们写 C 语言的经验此curname 的值就是“zzk”。第 3 行将变量 name 的值改为了“wurao”,第 5、6 行是输出变量 curname 的值。在 Makefile 要输出一串字符的话使用“echo”,就和 C 语言中的“printf”一样,第 6 行中的“echo”前面加了个“@”符号,因为 Make 在执行的过程中会自动输出命令执行过程,在命令前面加上“@”的话就不会输出命令执行过程,也可以测试一下不加“@” 的效果。
使用“make”执行上述代码:

2、赋值符“:=”
修改代码如下:
name = zzk
curname := $(name)
name = zuozhongkai
print:
@echo curname: $(curname)
“?=”是一个很有用的赋值符,比如下面这行代码:
curname ?= wuraoobjects = main.o inpiut.o
objects += calcu.o一开始变量 objects 的值为“main.o input.o”,后面我们给他追加了一个“calcu.o”,因此变量 objects 变成了“main.o input.o calcu.o”,这个就是变量的追加。
3.4.3 Makefile 模式规则
在 3.3.2 小节中我们编写了一个 Makefile 文件用来编译工程,这个 Makefile 的内容如下:
main: main.o input.o calcu.o
gcc -o main main.o input.o calcu.o
main.o: main.c
gcc -c main.c
input.o: input.c
gcc -c input.c
calcu.o: calcu.c
gcc -c calcu.c
clean:
rm *.o
rm main当“%”出现在目标中的时候,目标中“%”所代表的值决定了依赖中的“%”值,使用方法如下:
%.o : %.c
命令
因此上面的 Makefile 可以改为如下形式:
objects = main.o input.o calcu.o
main: $(objects)
gcc -o main $(objects)
%.o : %.c
#命令
clean:
rm *.o
rm main修改以后的 Makefile 还不能运行,因为第 6 行的命令我们还没写呢,第 6 行的命令我们需要借助另外一种强大的变量—自动化变量。
3.4.4 Makefile 自动化变量
上面讲的模式规则中,目标和依赖都是一系列的文件,每一次对模式规则进行解析的时候都会是不同的目标和依赖文件,而命令只有一行,如何通过一行命令来从不同的依赖文件中生成对应的目标呢?自动化变量就是完成这个功能的。所谓自动化变量就是这种变量会把模式中所定义的一系列的文件自动的挨个取出,直至所有的符合模式的文件都取完,自动化变量只应该出现在规则的命令中,常用的自动化变量如下表:

7 个自动化变量中,常用的三种:$@、$< 和 $^ ,我们使用自动化变量来完成上面的 Makefile,最终的完整代码如下所示:
objects = main.o input.o calcu.o
main: $(objects)
gcc -o main $(objects)
%.o : %.c
gcc -c $<
clean:
rm *.o
rm main3.4.5 Makefile 伪目标
clean:
rm *.o
rm main.PHONY : cleanobjects = main.o input.o calcu.o
main: $(objects)
gcc -o main $(objects)
.PHONY : clean
%.o : %.c
gcc -c $<
clean:
rm *.o
rm main上述代码第 5 行声明 clean 为伪目标,声明 clean 为伪目标以后不管当前目录下是否存在名为“clean”的文件,输入“make clean”的话规则后面的 rm 命令都会执行。
3.4.6 Makefile 条件判断
在 C 语言中我们通过条件判断语句来根据不同的情况来执行不同的分支,Makefile 也支持条件判断,语法有两种如下:
<条件关键字><条件为真时执行的语句>endif
<条件关键字><条件为真时执行的语句>else<条件为假时执行的语句>endif
其中条件关键字有 4 个:ifeq、ifneq、ifdef 和 ifndef,这四个关键字其实分为两对、 ifeq 与 ifneq、ifdef 与 ifndef,先来看一下 ifeq 和 ifneq,ifeq 用来判断是否相等,ifneq 就是判断是否不相等,ifeq 用法如下:
ifeq (<参数 1>, <参数 2>)ifeq ‘<参数 1 >’,‘ <参数 2>’ifeq “<参数 1>”, “<参数 2>”ifeq “<参数 1>”, ‘<参数 2>’ifeq ‘<参数 1>’, “<参数 2>”
ifndef <变量名>
3.4.7 Makefile 函数使用
$(函数名 参数集合)
或者
${函数名 参数集合}
$(subst <from>,<to>,<text>)
$(subst wurao,man,my name is wurao)
$(patsubst <pattern>,<replacement>,<text>)
$(patsubst %.c,%.o,a.c b.c c.c)
$(dir <names…>)
$(dir </src/a.c>)
$(notdir <names…>)
$(notdir </src/a.c>)
$(foreach <var>, <list>,<text>)
$(wildcard PATTERN…)
$(wildcard *.c)
本篇总结
重点是各种shell命令的使用和Makefile。
shell多敲就会了,Makefile多学习几个例子便熟悉了。
智能推荐
蓝鲸智云实现虚拟机交付(三)-跳板机管理(JUMP)_jumpserver vsphere-程序员宅基地
文章浏览阅读1.3k次。简介蓝鲸智云实现虚拟机交付(二)-虚拟机管理(VSPHERE)原子实现的是从模板克隆新的虚拟机,下面我们需要将其添加到jumpserver中。在此我们要借助于jumpserver的API,我们可以直接查看jumpserver swagger来查看相关API。可参见官网说明:jumpserver开发文档思路jumpserver添加主机的流程:1.创建资产,需要主机的基本信息、管理用户、..._jumpserver vsphere
SpringMVC@NotEmpty等注解不生效_notempty注解不生效-程序员宅基地
文章浏览阅读2w次,点赞5次,收藏6次。现象 表单数据对应的Java Bean属性上添加的诸多校验注解不生效,如下示例:@NotEmpty(message = "规则不能为空", groups = {AppConfigGroup.Add.class,AppConfigGroup.Update.class})@Size(max = 200,groups= {AppConfigGroup.Add.class,AppConfigGro..._notempty注解不生效
LocalDate时间换算常用方法_localdateutil 日期转换-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏2次。LocalDate时间换算常用方法/** * jdk1.8 localDate工具类 */public class LocalDateUtil { /** * yyyy-MM-dd */ public static final String DAY_FORMAT = "yyyy-MM-dd"; /** * yyyy-MM-dd HH:mm:ss */ public static final String FULL_FORMAT = "yyyy-MM-dd HH:mm:ss";_localdateutil 日期转换
字体样式_文字字体风格normal-程序员宅基地
文章浏览阅读1k次。1.字体样式设置字体样式大致有如下几种特征:字体类型(风格)、字体粗细、字体大小、字体系列(1)字体类型(风格) font-style用于设置字体风格,可设置以下值:① normal:普通字体② italic:斜体③ oblique:倾斜字体HTML代码如下:对应的CSS代码如下:运行效果:(2)字体粗细 font-weight用于设置字体粗细,可设置以下值:① norm..._文字字体风格normal
centos7离线安装mysql_centos7 离线安装mysql-程序员宅基地
文章浏览阅读3.8k次,点赞5次,收藏26次。1.下载mysql安装包:地址:https://dev.mysql.com/downloads/mysql/点击archives,查看历史版本选择版本和OS,然后点击download2.解压刚刚下载的tar包到 /home/mysql/下,得到rpm包:[root@localhost ~]# tar -xf mysql-5.7.19-1.el7.x86_64.rpm-bundle.tar -C /home/mysql/3.查询并卸载系统自带的Mariadb:rpm -.._centos7 离线安装mysql
对口升学计算机网络网络试题,中职对口升学计算机网络检测试题一-程序员宅基地
文章浏览阅读631次。习题1. 填空题1)计算机网络主要有2)TCP的汉语意思是IP的汉语意思是。3)计算机网络中的共享资源指的是硬件、软件和4)计算机通信采用的交换技术主要有交换和电路交换两种,前者比后者实时性差,线路的利用率高。5)在计算机网络中,通信双方必须共同遵守的规则或约定称为6)在计算机网络中,人们通常用来描述数据传输速率的符号是7)在信号的接受与发送两站点进行之间进行的数据传输只建立一条通信线路,每次只传..._中职对口高考计算机试题真题
随便推点
零碎知识点整理-程序员宅基地
文章浏览阅读389次,点赞9次,收藏11次。
超微主板升级bios_超微主板bios升级大盘点-程序员宅基地
文章浏览阅读3.9k次。如今,电子设备已越来越普及,开始走进千家万户,空调、冰箱、微波炉、电视、音箱、数码相机、随身听几乎家家都有,汽车上装有无线导航,电话、手机等通讯产品必不可少,各种数控设备、仪器、仪表、电线电缆更是在工业中屡见不鲜。而作为先进的电子设备——电脑由于它高端的工作能力和娱乐方式也越来越受欢迎。用电脑的人越来越多,懂电脑的人越来越多,电脑也随着人们的开发不断更新,超微主板BIOS大家应该都听说过吧!它是..._超微的bios主板都差不多嘛
时间序列_python自相关系数(ACF)绘图_acf_corr 的算法流程图-程序员宅基地
文章浏览阅读1w次,点赞10次,收藏56次。一、概述自相关函数,用来度量同一事件在不同时期之间的相关程度,或者说是一个信号经过类似于反射、折射等其它情况的延时后的副本信号与原信号的相似程度。R(τ)=E[(Xt−μ)(Xt−τ−μ)]σ2R(\tau) = \frac{E[(X_t - \mu)(X_{t-\tau} - \mu)]}{\sigma ^ 2}R(τ)=σ2E[(Xt−μ)(Xt−τ−μ)]简单讲就是比较不同时间延迟两个序列的相似程度,就好比下图蓝色框内序列和红色框内序列之间的相关性。二、python实现&s_acf_corr 的算法流程图
【语言处理与Python】6.4决策树/6.5朴素贝叶斯分类器/6.6最大熵分类器-程序员宅基地
文章浏览阅读85次。6.4决策树 决策树是一个简单的为输入值选择标签的流程图。这个流程图由检查特征值的决策节点 和分配标签的叶节点组成。为输入值选择标签,我们以流程图的初始决策节点(称为其根节点)开始。 熵和信息增益在决策树桩确定上的应用(可以自行查找相关资料阅读) 可以参考:http://blog.csdn.net/athenaer/article/details/8425479 决策树的一些..._朴素贝叶斯与最大熵方法
王下邀月熊_Chevalier的前端每周清单系列文章索引-程序员宅基地
文章浏览阅读173次。感谢 王下邀月熊_Chevalier 分享的前端每周清单,为方便大家阅读,特整理一份索引。王下邀月熊大大也于 2018 年 3 月 31 日整理了自己的前端每周清单系列,并以年/月为单位进行分类,具体内容看这里:前端每周清单年度总结与盘点。前端每周清单第 56 期:D3 5.0,深入 React 事件系统,SketchCode 界面..._王下邀月
《软件登记测试报告》可以作为软件第三方检测报告使用吗_软件登记测评报告是否可用于投标产品功能鉴定评测?-程序员宅基地
文章浏览阅读802次。《软件登记测试报告》本身属于第三方软件检测报告,但是从软件登记测试与其他软件检测类型来看,测试内容和测试强度是不同的,并且测试报告使用目的还是有所不同的。软件登记测试内容1、功能性:系统安装卸载、功能模块挂接、功能模块实现2、安全可靠性:软件容错性、安全保密性、稳定性3、用户界面:界面输入、界面显示、界面文字4、中文特性:界面中文符合性、软件提示中文符合性、字库中文符合性、产品包装盒说明本地化5、用户文档:完备性、正确性、一致性主要是检测软件是否达到了需求要求的“基本”实现,_软件登记测评报告是否可用于投标产品功能鉴定评测?