Python学习笔记-程序员宅基地
文章目录

一、数据类型和变量
# 1.十六进制表示
if 0x10 == 16:
print("0x10 == 16") #
else:
print("0x10 != 16")
# 2.下划线数据表示
if 100_000_000.5 == 100000000.5:
print("100_000_000.5 == 100000000.5") #
else:
print("100_000_000.5 != 100000000.5")
# 3.科学计数法
if 1e8 == 100000000:
print("1e8 == 100000000") #
else:
print("1e8 != 100000000")
# 4.取消字符串转义
print(r"\n \t \0") # \n \t \0
# 5.布尔值与逻辑运算
print(True and False) # False
print(True or False) # True
print(not False) # True
# 6.空值
if (None == 0):
print("None == 0")
else:
print("None != 0") # C中NULL等于0 C++中nullptr也等于0
# 7.Python中的所有变量本质上都是指针
a = ["a"]
b = a # 令b指向a指向的变量
a[0] = "b"
print(b) # ['b']
a = "a"
b = a
a = "b" # a会指向一个新的变量
print(b) # a
# 8.地板除
print(10 // 3) # 3
# 9.Python中的整型可以按照长度动态分配内存 因此理论上没有大小限制
print(10**10000 + 1) # 100···001
二、字符串和编码
1.编码
Python3中字符串默认以Unicode编码,可以通过encode()函数和decode()函数对字符串进行编码和解码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
print("北京市".encode("utf-8")) # b'\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82' 以字节为单位的bytes对象
print(b"\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82".decode("utf-8")) # 北京市 字符串对象
print(len("北京市")) # 3 统计字符数
print(len("北京市".encode("utf-8"))) # 9 统计字节数
ord()函数用于获取指定字符的ASCII码或者Unicode数值:
print(ord("\n")) # 10
print(ord("风")) # 39118
print("\u98ce") # 风 39118D与98ceH相等 \u表示采用Unicode编码
2.字符串操作
strip()方法用于移除字符串头尾指定的字符(默认为空格)或字符序列,但该方法只能删除开头或是结尾的字符,不能删除中间部分的字符,该方法常与切片函数split()一起使用:
s = " Miss Fortune, Ezreal "
print(s.strip()) # Miss Fortune, Ezreal
print(s.split(",")) # [' Miss Fortune', ' Ezreal ']
print([i.strip() for i in s.split(",")]) # ['Miss Fortune', 'Ezreal']
字符串的连接可以借助于加号+或者join()函数:
s = ["The quick brown fox", "jumps over", "the lazy dog."]
print(s[0] + " " + s[1] + " " + s[2]) # The quick brown fox jumps over the lazy dog.
print(" ".join(s)) # The quick brown fox jumps over the lazy dog.
子串的判断借助于关键字in,定位借助于方法index()或find(),find和index的区别是在找不到指定字符串时index产生异常,而find会返回-1:
s = "The quick brown fox jumps over the lazy dog."
print(s.find(" ")) # 3
print(s.index(" ")) # 3
print(s.find("0")) # -1
print(s.index("0"))
# Traceback (most recent call last):
# File "/Users/Atreus/PycharmProjects/pythonProject/main.py", line 7, in <module>
# print(s.index("0"))
# ValueError: substring not found
此外,还可以通过count()函数统计字符出现的次数,通过replace()函数进行替换,通过lower()函数和upper()函数进行大小写转换,通过endswith()和startwith()判断字符串的前缀与后缀:
s = "AD"
print(s.count("D")) # 1
print(s.replace("D", "P")) # AP
s = s.lower()
print(s) # ad
s = s.upper()
print(s) # AD
print(s.startswith("A")) # True
print(s.endswith("P")) # False
Python也支持对字符串的格式化输出:
print("%dD %f %s %xH" % (17, 1.1, "A", 0x11)) # 17D 1.100000 A 11H
print("|%-7.3f|" % 12.34) # |12.340 | 总共7位 小数点后3位 左对齐
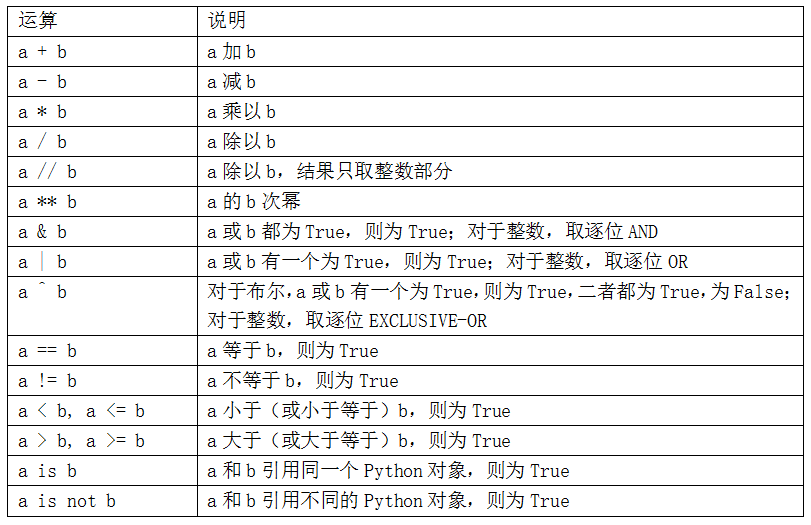
三、常用运算符
四、数据结构
1.list
list可以由方括号或者list()函数初始化:
legends = ["Qiyana", "Vi", "Thresh", "Jinx", "Zed"]
print(legends) # ['Qiyana', 'Vi', 'Thresh', 'Jinx', 'Zed']
li = list(range(3))
print(li) # [0, 1, 2]
list的正向索引和反向索引:
print(legends[0]) # Qiyana
print(legends[1]) # Vi
print(legends[-1]) # Zed
print(legends[-2]) # Jinx
对list中的数据进行增删改查:
legends.append("Viktor")
print(legends) # ['Qiyana', 'Vi', 'Thresh', 'Jinx', 'Zed', 'Viktor']
legends.insert(1, "Ezreal")
print(legends) # ['Qiyana', 'Ezreal', 'Vi', 'Thresh', 'Jinx', 'Zed', 'Viktor']
legends.pop()
print(legends) # ['Qiyana', 'Ezreal', 'Vi', 'Thresh', 'Jinx', 'Zed']
legends.pop(1)
print(legends) # ['Qiyana', 'Vi', 'Thresh', 'Jinx', 'Zed']
legends.remove("Qiyana")
print(legends) # ['Vi', 'Thresh', 'Jinx', 'Zed']
legends[-2] = "Pyke"
print(legends) # ['Vi', 'Thresh', 'Pyke', 'Zed']
print("Thresh" in legends) # True
print("Ezreal" not in legends) # True
list中的数据类型也可以不同:
li = ["A", 1, True, legends]
print(li) # ['A', 1, True, ['Qiyana', 'Vi', 'Thresh', 'Pyke', 'Zed']]
print(li[-1][-1]) # Zed
print(len(li)) # 4
sort()方法可以实现对list的原地排序:
li = [2, 4, 6, 5, 3, 1]
li.sort()
print(li) # [1, 2, 3, 4, 5, 6]
li.sort(reverse=True) # 逆序排序
print(li) # [6, 5, 4, 3, 2, 1]
li = ["C", "C++", "Python"]
li.sort(key=len) # 按长排序
print(li) # ['C', 'C++', 'Python']
通过enumerate()函数可以在遍历时跟踪当前序号:
li = ["C", "C++", "Python"]
for key, value in enumerate(li):
print(key, value)
# 0 C
# 1 C++
# 2 Python
2.tuple
tuple本身是一个长度固定、元素不可变的list:
tup = ("Jinx", "Vi", "Shen") # 括号也可省略
print(tup) # ('Jinx', 'Vi', 'Shen')
print(tup[0]) # Jinx
tup = tuple([1, 2, 3])
print(tup) # (1, 2, 3)
tup = tuple("string")
print(tup) # ('s', 't', 'r', 'i', 'n', 'g')
对于含有单个元素的tuple要通过逗号来消除歧义:
tup = (1)
print(type(tup)) # <class 'int'>
tup = (1,)
print(type(tup)) # <class 'tuple'>
元素不变指的是元素的指向不变而不是指向的内容不变:
tup = ("Jinx", ["Vi", "Shen"])
tup[-1][-1] = "Miss Fortune"
print(tup) # 'Jinx', ['Vi', 'Miss Fortune'])
对元组进行运算:
tup = (1, True, "str") + (False, "Jinx")
print(tup) # (1, True, 'str', False, 'Jinx')
tup = (1, True, "str") * 3
print(tup) # (1, True, 'str', 1, True, 'str', 1, True, 'str')
如果你想将元组赋值给类似元组的变量,Python会将元组进行拆分:
a, b, (c, d) = (1, 2, (3, 4))
print(a, b, c, d) # 1 2 3 4
利用这个特性可以方便地实现两个变量的交换:
a, b = b, a
print(a, b) # 2 1
变量拆分也可以用来迭代元组或列表序列:
for i, j, k in ((1, 2, 3), (4, 5, 6), (7, 8, 9)):
print(i, j, k)
# 1 2 3
# 4 5 6
# 7 8 9
count()方法可以用来统计元组中某个值的出现频率:
tup = (1, 0, 0, 8, 6)
print(tup.count(0)) # 2
enumerate()函数可以用于在迭代时追踪元素下标:
li = ["Ezreal", "Neeko", "Thresh"]
for key, value in enumerate(li):
print(key, value)
# 0 Ezreal
# 1 Neeko
# 2 Thresh
3.dict
dict的初始化:
dic = {
"C": 1, "C++": 3, "Python": 6}
print(dic) # {'C': 1, 'C++': 3, 'Python': 6}
对dict中的数据进行增删改查
dic["C#"] = 2
print(dic) # {'C': 1, 'C++': 3, 'Python': 6, 'C#': 2}
dic.pop("C++") # dict的pop方法必须传入参数
print(dic) # {'C': 1, 'Python': 6, 'C#': 2}
del dic["Python"]
print(dic) # {'C': 1, 'C#': 2}
dic["C"] = -1
print(dic) # {'C': -1, 'C#': 2}
print(dic["C#"]) # 2
print(dic.get("C")) # -1
print(dic.get("Java")) # None
print("C" in dic) # True
print("Java" in dic) # False
获取字典全部的键和值:
print(dic.keys()) # dict_keys(['C', 'C#'])
print(dic.values()) # dict_values([-1, 2])
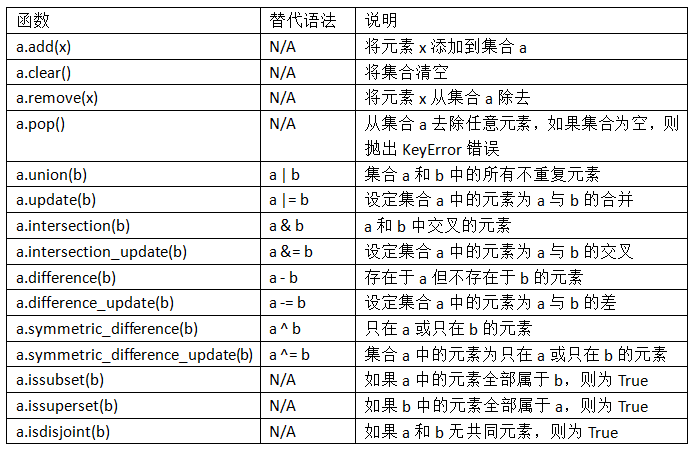
4.set
set的初始化:
s = set([1, 2, 3, 2, 3]) # 重复元素在set中会被自动过滤
print(s) # {1, 2, 3}
set的添加和删除:
s.add(4)
print(s) # {1, 2, 3, 4}
s.remove(4)
print(s) # {1, 2, 3}
对set进行集合操作:
s1 = set([1, 2, 3])
s2 = set([2, 3, 4])
print(s1 & s2) # {2, 3}
print(s1.intersection(s2)) # {2, 3}
print(s1 | s2) # {1, 2, 3, 4}
print(s1.union(s2)) # {1, 2, 3, 4}
五、切片
对list使用切片操作符:
names = ["Sona", "Ezreal", "Vi", "Irelia", "Akali"]
print(names[1:3]) # ['Ezreal', 'Vi'] 左闭右开区间
print(names[:3]) # ['Sona', 'Ezreal', 'Vi'] 从0开始时0可以省略
print(names[1:]) # ['Ezreal', 'Vi', 'Irelia', 'Akali'] 到最后一个截止最后一个也可省略
print(names[-3:-1]) # ['Vi', 'Irelia'] 反向切片
print(names[0:5:2]) # ['Sona', 'Vi', 'Akali'] 改变切片步长
对tuple和字符串使用切片操作符:
print((0, 1, 2, 3, 4)[1:4]) # (1, 2, 3)
print("01234"[1:4]) # 123
六、循环分支
1.循环结构
Python简单循环分支:
for i in range(5): # <<=>>
if i < 2:
print("<", end="")
elif i == 2:
print("=", end="")
else:
print(">", end="")
print()
Python中的for-else结构:
for i in range(5):
pass # 空语句
# break
else:
print("The break statement has been executed.") # 当for循环正常执行完毕时else中的语句就会被执行
2.迭代
对dict进行迭代:
dict = {
"C": 1, "C++": 3, "Python": 6}
for i in dict:
print(i) # C C++ Python
for i in dict.values():
print(i) # 1 3 6
for i in dict.items():
print(i) # ('C', 1) ('C++', 3) ('Python', 6)
for i, j in dict.items():
print(i, j) # C 1 C++ 3 Python 6
可以通过isinstance()方法判断一个类型是否可迭代:
from collections.abc import Iterable
print(isinstance("string", Iterable)) # True
print(isinstance([(1, 2), (3, 4), (5, 6)], Iterable)) # True
print(isinstance(2022, Iterable)) # False
七、函数
1.普通函数
类型转换函数:
print(int("5")) # 5
print(int(5.5)) # 5
print(float("5.5")) # 5.5
print(float(5)) # 5.0
print(str(5)) # 5
print(str(5.5)) # 5.5
print(bool("")) # False
print(bool(1)) # True
Python可以以tuple的形式令一个函数返回多值:
def calculate(a, b):
return a + b, a - b
addition, subtraction = calculate(1, 2)
print(addition, subtraction) # 3 -1
print(calculate(1, 2)) # (3, -1)
函数可以有一些位置参数(positional)和一些关键字参数(keyword)。关键字参数通常用于指定默认值或可选参数而且关键字参数必须位于位置参数(如果有的话)之后:
def sum_(a, b = 1): # 位置参数在前 关键字参数在后
return a + b
print(sum_(1)) # 2
print(sum_(1, 2)) # 3
默认参数必须指向不可变对象:
def add_end(l=[]):
l.append("END")
return l
print(add_end()) # ['END']
print(add_end()) # ['END', 'END']
def add_end(l=None):
if l is None:
l = []
l.append("END")
return l
print(add_end()) # ['END']
print(add_end()) # ['END']
可变参数:
def get_sum(*nums):
total = 0
for i in nums:
total += i
return total
print(get_sum(1, 2, 3)) # 6
print(get_sum(*[1, 2, 3])) # 6 通过*可以将list或者tuple中的元素作为可变参数传入
关键字参数:
def person(name, age, **kw):
print(name, age, kw)
person("Ezreal", 20) # Ezreal 20 {}
person("Ezreal", 20, job="ADC", city="Piltover") # Ezreal 20 {'job': 'ADC', 'city': 'Piltover'}
def person_(name, age, *, job, city): # 命名关键字参数
print(name, age, job, city)
person_("Ezreal", 20, job="ADC", city="Piltover") # Ezreal 20 ADC Piltover
利用递归函数解决汉诺塔问题:
def hanoi(n, a, b, c):
if n == 1:
print(a, "->", c, sep="")
else:
hanoi(n - 1, a, c, b)
print(a, "->", c, sep="")
hanoi(n - 1, b, a, c)
hanoi(3, "a", "b", "c") # a->c a->b c->b a->c b->a b->c a->c
2.匿名函数
过匿名函数筛选奇数
print(list(filter(lambda n: n % 2 == 1, range(1, 10))))
3.函数式编程
普通高阶函数:
def abs_sum(x, y, fun): # 类似于函数指针
return fun(x) + fun(y)
print(abs_sum(-1, 1, abs)) # 2
通过map()函数求列表中所有元素的平方:
def square(x):
return x * x
print(list(map(square, [0, 1, 2]))) # [0, 1, 4] map将传入的函数依次作用到序列的每个元素
通过reduce()函数将列表转化为整数:
from functools import reduce
def add(x, y):
return x * 10 + y
print(reduce(add, [1, 2, 3])) # 123 reduce把结果继续和序列的下一个元素做累积计算
通过filter()函数过滤出列表中的所有奇数:
def is_odd(x):
return x % 2 == 1
print(list(filter(is_odd, [1, 2, 3, 4, 5])))
# [1, 3, 5] filter把传入的函数依次作用于每个元素后根据返回值是True还是False决定保留还是丢弃该元素
通过sorted()函数对列表按绝对值进行逆向排序:
print(sorted([1, -2, 3, -4, 5], key=abs, reverse=True)) # [5, -4, 3, -2, 1]
八、列表生成式
# 1.使用列表生成式创建列表
L = list(x * x for x in range(5))
print(L) # [0, 1, 4, 9, 16]
L = list(x for x in range(1, 6) if x % 2 == 0)
print(L) # [2, 4]
L = list(x if x % 2 == 0 else 0 for x in range(1, 6))
print(L) # [0, 2, 0, 4, 0]
# 2.使用列表生成式获取当前目录下的文件和目录名
import os
L = list(i for i in os.listdir("."))
print(L) # ['.DS_Store', 'venv', 'demo.html', 'main.py', '.idea']
九、生成器
一个带有yield的函数就是一个generator,它和普通函数不同,生成一个generator的过程看起来像是函数调用,但不会执行任何函数代码,直到对其调用next()才开始执行(在 for 循环中会自动调用)。虽然执行流程仍按函数的流程执行,但每执行到一个yield语句就会中断并返回一个迭代值,下次执行时从yield的下一个语句继续执行。
这看起来就好像一个函数在正常执行的过程中被yield中断了数次,每次中断都会通过yield返回当前的迭代值。
# 1.使用generator生成斐波那契数列
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
for i in fib(5):
print(i) # 1 1 2 3 5
# 2.使用generator生成杨辉三角
def triangles():
ans = []
n = 0
while True:
line = []
for i in range(n + 1):
if i == 0 or i == n:
line.append(1)
else:
line.append(ans[n - 1][i - 1] + ans[n - 1][i])
yield line
n = n + 1
ans.append(line)
n = 0
for i in triangles():
print(i)
n = n + 1
if n == 10:
break
# [1]
# [1, 1]
# [1, 2, 1]
# [1, 3, 3, 1]
# [1, 4, 6, 4, 1]
# [1, 5, 10, 10, 5, 1]
# [1, 6, 15, 20, 15, 6, 1]
# [1, 7, 21, 35, 35, 21, 7, 1]
# [1, 8, 28, 56, 70, 56, 28, 8, 1]
# [1, 9, 36, 84, 126, 126, 84, 36, 9, 1]
十、面向对象编程
1.Python简单面向对象
class Legend(object):
def __init__(self, name, camp):
self.__name = name # 通过两个下划线将变量变为私有变量
self.__camp = camp
def __str__(self):
return "%s: %s" % (self.__name, self.__camp)
Ezreal = Legend("Ezreal", "Piltover")
print(Ezreal) # Ezreal: Piltover
class MID(Legend): # MID继承自Legend
pass
Zoe = MID("Zoe", "MountTargon")
print(Zoe) # Zoe: MountTargon
print(type(Ezreal)) # <class '__main__.Legend'>
print(type(Zoe)) # <class '__main__.MID'>
print(isinstance(Zoe, Legend)) # True
print(isinstance(Zoe, MID)) # True
2.通过类属性和实例属性统计实例数
class Brand(object):
count = 0
def __init__(self, name):
self.__name = name
Brand.count = Brand.count + 1
Uni = Brand("Uni")
Sakura = Brand("Sakura")
Pilot = Brand("Pilot")
print(Brand.count) # 3
3.通过类实现斐波那契数列
class Fib(object):
def __init__(self, n):
self.__a, self.__b = 0, 1
self.__n = n
def __iter__(self):
return self
def __next__(self):
self.__a, self.__b = self.__b, self.__a + self.__b
if self.__a > self.__n:
raise StopIteration
return self.__a
for i in Fib(10):
print(i) # 1 1 2 3 5 8
4.枚举类
from enum import Enum
Month = Enum('Month', ('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
print(Month.Jan.value) # 1
print(Month.Nov.value) # 11
5.with-as用法
class demo:
def __enter__(self):
print("enter")
return "print"
def __exit__(self, type, value, traceback):
print("exit")
with demo() as thing:
print(thing)
# enter
# print
# exit
十一、文件操作
# 文件打开
try:
my_file = open("./main.py", "r")
except FileNotFoundError as e:
print("FileNotFoundError:", e)
finally:
pass
# 文件读写
try:
print(my_file.read())
my_file.write("#")
except IOError as e:
print("IOError:", e)
finally:
pass
# 文件关闭
my_file.close()

十二、正则表达式
import re
# 1.match
print(re.match(r"^\d{3}\-\d{3,8}$", "010-10010")) # <re.Match object; span=(0, 9), match='010-10010'>
print(re.match(r"^\d{3}\-\d{3,8}$", "010 10010")) # None
ans = re.match(r"^(\d{3})\-(\d{3,8})$", "010-10010")
print(ans.group(0)) # 010-10010
print(ans.group(1)) # 010
print(ans.group(2)) # 10010
print(re.match(r"^(\d+)(0*)$", "12300").groups()) # ('12300', '') 贪婪匹配
print(re.match(r"^(\d+?)(0*)$", "12300").groups()) # ('123', '00') 非贪婪匹配
# 2.split
print(re.split(r"\s+", "a b c d e")) # ['a', 'b', 'c', 'd', 'e']
十三、常用内建模块
1.os
import os
# 1.获取操作系统信息
print(os.name) # posix
print(os.uname()) # posix.uname_result(sysname='Darwin', nodename='AtreusdeMBP', release='21.4.0', version='Darwin Kernel Version 21.4.0: Fri Mar 18 00:46:32 PDT 2022; root:xnu-8020.101.4~15/RELEASE_ARM64_T6000', machine='arm64')
# 2.操作文件和目录
print(os.path.abspath(".")) # /Users/atreus/PycharmProjects/pythonProject
print(os.path.join("./", "test_dir")) # ./test_dir
os.mkdir("./test_dir") # 创建目录
os.rmdir("./test_dir") # 删除目录
2.json
import json
# 1.使用json对dict进行序列化
languages = {
"C": 1, "C++": 3, "Python": 6}
print(json.dumps(languages)) # {"C": 1, "C++": 3, "Python": 6}
# 2.使用json对list进行序列化
legends = ["Ezreal", "Vi", "Jinx"]
print(json.dumps(legends)) # ["Ezreal", "Vi", "Jinx"]
# 3.使用json进行反序列化
json_str = '{"C": 1, "C++": 3, "Python": 6}'
languages_dict = json.loads(json_str)
print(languages_dict["C++"]) # 3
# 4.使用json对对象进行序列化和反序列化
class Legend(object):
def __init__(self, name, camp):
self.name = name
self.camp = camp
def to_dict(legend):
return {
"name": legend.name,
"camp": legend.camp
}
Ezreal = Legend("Ezreal", "Piltover")
print(json.dumps(Ezreal, default=to_dict)) # {"name": "Ezreal", "camp": "Piltover"}
def to_legend(json_dict):
return Legend(json_dict["name"], json_dict["camp"])
print(json.loads('{"name": "Jinx", "camp": "Zaun"}', object_hook=to_legend)) # <__main__.Legend object at 0x104def100>
3.datetime
from datetime import datetime
print(datetime.now()) # 2022-05-10 10:16:41.384150
print(datetime(2021, 12, 25, 8, 0)) # 2021-12-25 08:00:00
print(datetime(1970, 1, 1, 8, 0).timestamp()) # 0.0
print(datetime.fromtimestamp(0.0)) # 1970-01-01 08:00:00
print(datetime.now().strftime("%a, %b %d, %H:%M")) # Tue, May 10, 10:24
4.collections
# 1.namedtuple
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"]) # 将元组定义为一个坐标
point = Point(1, 0)
print(point.x, point.y) # 1 0
Circle = namedtuple("Circle", ["x", "y", "r"]) # 将元组定义为一个圆
circle = Circle(0, 0, 1)
print(circle) # Circle(x=0, y=0, r=1)
# 2.deque
from collections import deque
L = deque([1, 2, 3, 4, 5]) # 双向链表
print(L) # deque([1, 2, 3, 4, 5])
L.append(6)
print(L) # deque([1, 2, 3, 4, 5, 6])
L.appendleft(0)
print(L) # deque([0, 1, 2, 3, 4, 5, 6])
L.pop()
print(L) # deque([0, 1, 2, 3, 4, 5])
L.popleft()
print(L) # deque([1, 2, 3, 4, 5])
# 3.OrderedDict
from collections import OrderedDict
order_dict = OrderedDict([("C", 1), ("C++", 3), ("Python", 6)]) # OrderedDict的Key会按照插入的顺序而不是Key本身排序
print(order_dict) # OrderedDict([('C', 1), ('C++', 3), ('Python', 6)])
print(list(order_dict.keys())) # ['C', 'C++', 'Python']
# 4.Counter
from collections import Counter
counter = Counter()
for i in "Ezreal": # 通过循环更新计数器
counter[i] += 1
print(counter) # Counter({'E': 1, 'z': 1, 'r': 1, 'e': 1, 'a': 1, 'l': 1})
counter.update("EZ") # 一次性更新计数器
print(counter) # Counter({'E': 2, 'z': 1, 'r': 1, 'e': 1, 'a': 1, 'l': 1, 'Z': 1})
5.argparse
import argparse
# The accumulate attribute will be either the sum() function, if '--sum' was specified at the command line, or the max() function if it was not.
parser = argparse.ArgumentParser(description='Process some integers.') # 创建一个ArgumentParser对象
parser.add_argument('integers', metavar='N', type=int,
nargs='+', help='an integer for the accumulator') # 添加参数'integers'
parser.add_argument('--sum', dest='accumulate', action='store_const',
const=sum, default=max, help='sum the integers (default: find the max)') # 添加参数'--sum'
# args = parser.parse_args(['--sum', '1', '2', '3']) # 6
# args = parser.parse_args(['1', '2', '3']) # 3
args = parser.parse_args() # 对参数进行语法分析
print(args.accumulate(args.integers))
(venv) (base) atreus@bogon pythonProject % python main.py --help
usage: main.py [-h] [--sum] N [N ...]
Process some integers.
positional arguments:
N an integer for the accumulator
optional arguments:
-h, --help show this help message and exit
--sum sum the integers (default: find the max)
(venv) (base) atreus@bogon pythonProject % python main.py --sum 1 2 3
6
(venv) (base) atreus@bogon pythonProject % python main.py 1 2 3
3
(venv) (base) atreus@bogon pythonProject %
十四、常用第三方模块
1.pillow
利用pillow生成验证码
from PIL import Image, ImageDraw, ImageFont, ImageFilter
import random
# 随机字母
def rand_char():
return chr(random.randint(65, 90))
# 随机颜色
def rand_color():
return random.randint(64, 255), random.randint(64, 255), random.randint(64, 255)
def back_rand_color():
return random.randint(32, 127), random.randint(32, 127), random.randint(32, 127)
# 创建Image对象
width = 60 * 4
height = 60
image = Image.new("RGB", (width, height), (255, 255, 255))
# 创建Font对象
font = ImageFont.truetype("Arial.ttf", 36)
# 创建Draw对象
draw = ImageDraw.Draw(image)
# 填充每个像素
for x in range(width):
for y in range(height):
draw.point((x, y), fill=rand_color())
# 输出文字
for t in range(4):
draw.text((60 * t + 10, 10), rand_char(), font=font, fill=back_rand_color())
# 保存图片
image.save("./code.jpg", "jpeg")

2.requests
通过requests访问网页
import requests
r = requests.get("https://www.liaoxuefeng.com/")
print(r.status_code) # 200
print(r.text[0: 15]) # <!DOCTYPE html>
智能推荐
MyBatis-Plus使用queryWrapper解决字符串中含数字的排序问题_mybatis字符串数字排序-程序员宅基地
文章浏览阅读7.4k次,点赞6次,收藏9次。今天遇到了Oracle数据库字符串(含数字)排序问题,这里记录的是如何用MyBatis-Plus的queryWrapper条件构造器来解决的方法。造成的原因:数据库字段为varchar类型(若为Number类型则无此问题)数据库字符串排序是按照顺序一位一位比较的,按照ascII码值比较。如:2比1大,所以12会排在2前面解决办法:先按字符串长度排序,再按字段排序关键代码(queryWrapper条件构造器实现形式)//利用数据库length函数获取字符串长度(这里的code是我数据库中的_mybatis字符串数字排序
kube operator部署kubernetes集群_kubeop-程序员宅基地
文章浏览阅读1.3k次。kube operator简介kube operator是一个kubernetes集群部署及多集群管理工具,提供web ui支持在离线环境部署多个kubernetes集群。KubeOperator 是一个开源项目,通过 Web UI 在 VMware、OpenStack 和物理机上规划、部署和运营生产级别的 Kubernetes 集群。支持内网离线环境、支持 GPU、内置应用商店,已通过 CNCF 的 Kubernetes 软件一致性认证。官网:https://kubeoperator.io/离线包_kubeop
openmv学习日记(二)openmv4 H7_openmv4 h7 cam-程序员宅基地
文章浏览阅读1.1w次,点赞10次,收藏81次。今天先介绍一下openmv4 H7的相关资料文章目录简介引脚电路图板子信息尺寸规格功耗温度范围简介openmv4 H7具有:STM32H743VI ARM Cortex M7 处理器,480 MHz ,1MB RAM,2 MB flash. 所有的 I/O 引脚输出 3.3V 并且 5V 耐受。并且还有以下的IO接口:1.全速 USB (12Mbs) 接口,连接到电脑。当插入Open..._openmv4 h7 cam
机器学习与数据挖掘网上资源搜罗——良心推荐-程序员宅基地
文章浏览阅读509次。前面我曾经发帖推荐过网上的一些做“图像处理和计算机视觉的”有料博客资源,原帖地址图像处理与机器视觉网络资源收罗——倾心大放送http://blog.csdn.net/baimafujinji/article/details/32332079做机器学习和数据挖掘方面的研究和开发,常会在线搜索一些资源,日积月累便挖出了一堆比较牛的博主,特别说明:做这个方向的
windows10和kali linux双系统的安装_kali系统和win可以共同吗-程序员宅基地
文章浏览阅读1.5w次,点赞14次,收藏92次。0x00 准备工具1、容量8G及以上的U盘2、kali linux镜像下载 - 下载地址:https://www.kali.org/downloads/3、镜像刻录软件Win32 Disk Imager - 下载地址:https://win32-disk-imager.en.lo4d.com/4、硬盘分区助手 - 下载地址:https://www.disktool.cn/5、制作引导工具..._kali系统和win可以共同吗
毕业设计django新闻发布和评论管理系统-程序员宅基地
文章浏览阅读587次,点赞6次,收藏14次。因为媒体的宣传能够带给我们重要的信息资源,新闻发布和评论管理是国家管理机制重要的一环,,面对这一世界性的新动向和新问题,新闻发布如何适应新的时代和新的潮流,开展有效的信息服务工作,完成时代赋予的新使命?在新闻发布和评论管理系统开发之前所做的市场调研及其他的相关的管理系统,都是没有任何费用的,都是通过开发者自己的努力,所有的工作的都是自己亲力亲为,在碰到自己比较难以解决的问题,大多是通过同学和指导老师的帮助进行相关信息的解决,所以对于新闻发布和评论管理系统的开发在经济上是完全可行的,没有任何费用支出的。
随便推点
HTTP方式在线访问Hadoop HDFS上的文件解决方案
为了通过HTTP方式在线访问HDFS上的文件,您可以利用WebHDFS REST API或者HttpFS Gateway这两种机制实现。1:httpfs是cloudera公司提供的一个hadoop hdfs的一个http接口,通过WebHDFS REST API 可以对hdfs进行读写等访问2:与WebHDFS的区别是不需要客户端可以访问hadoop集群的每一个节点,通过httpfs可以访问放置在防火墙后面的hadoop集群3:httpfs是一个Web应用,部署在内嵌的tomcat中。
WordPress优化Google广告加载速度_wordpress 怎么做谷歌优化-程序员宅基地
文章浏览阅读236次。网站的快速加载是良好用户体验和搜索引擎优化的要素之一,但每当谷歌AdSense的广告代码部署到网站上时,速度都会显着下降,这是因为要下载大量文件才能显示广告,并且其中包含大量无用、被墙的请求及代码。_wordpress 怎么做谷歌优化
c# controls.add 控件的使用 ,间接引用还是值引用_this.controls.add-程序员宅基地
文章浏览阅读8.6k次。c# controls.add 控件的使用 10函数内部用下面代码增加控件:Button btn = new Button();btn.Location = new Point( 20, 20);btn.Size = new Size( 60,40);btn.Text = "btn'sText";this.Controls.Add( btn );问题:函数执行完后,bt_this.controls.add
占位式插件化一Activity的跳转_activity跳转 插件-程序员宅基地
文章浏览阅读329次。原理宿主APP安装在手机中的APP,并且通过该APP加载插件中的Activity插件APP没有安装的apk,通过宿主直接打开其内部Activity标准(协议)宿主APP和插件APP通信的桥梁。宿主APP通过一个空壳Activity(代理Activity)加载插件app中的Activity,实际上插件app中的Activity并没有入栈,也没法入栈,因为插件app没有安装,没有上下文和..._activity跳转 插件
PTA 剥洋葱(C语言 + 详细注释 + 代码超简单)_c语言pta怎么使用-程序员宅基地
文章浏览阅读1.0k次,点赞9次,收藏13次。输入格式:一行,一个整数,即图形的层数输出格式:如上述图形输入样例:3输出样例:AAAAAABBBAABCBAABBBAAAAAA//打印图形题关键是找规律,一般只需两重循环(行循环、列循环)#include<stdio.h>#include<string.h>int main() { int i, n; char ..._c语言pta怎么使用
docker配置国内镜像源_docker国内镜像源-程序员宅基地
文章浏览阅读3.3w次,点赞9次,收藏25次。刚开始学习docker,发现下载镜像非常的慢。如果不经过,docker的镜像下载都来源于国外,因此需要配置国内的镜像源。Docker中国区官方镜像。_docker国内镜像源