Impala安装部署_shell<!-- 打开dfsclient本地读取数据的控制--> <property> <name-程序员宅基地
技术标签: Apache Impala Impala安装部署
一、安装前提
集群提前安装好hadoop,hive。
hive安装包scp在所有需要安装impala的节点上,因为impala需要引用hive的依赖包。
hadoop框架需要支持C程序访问接口,查看下图,如果有该路径下有这么文件,就证明支持C接口。

二、下载安装包、依赖包
由于impala没有提供tar包进行安装,只提供了rpm包。因此在安装impala的时候,需要使用rpm包来进行安装。rpm包只有cloudera公司提供了,所以去cloudera公司网站进行下载rpm包即可。
但是另外一个问题,impala的rpm包依赖非常多的其他的rpm包,可以一个个的将依赖找出来,也可以将所有的rpm包下载下来,制作成我们本地yum源来进行安装。这里就选择制作本地的yum源来进行安装。
所以首先需要下载到所有的rpm包,下载地址如下
http://archive.cloudera.com/cdh5/repo-as-tarball/5.14.0/cdh5.14.0-centos6.tar.gz
##由于下载的cdh5.14.0-centos6.tar.gz包非常大,大概5个G,解压之后也最少需要5个G的空间。而我们的虚拟机磁盘有限,可能会不够用了,所以可以为虚拟机挂载一块新的磁盘,专门用于存储的cdh5.14.0-centos6.tar.gz包。
三、配置本地yum源
1、上传安装包解压
tar -zxvf cdh5.14.0-centos6.tar.gz
rz 最大只能上传4G以内的数据,所以需要换种方式上传例如使用sslclient.
2、配置本地yum源信息
安装Apache Server服务器
yum -y install httpd
service httpd start
chkconfig httpd on
3、配置本地yum源的文件
cd /etc/yum.repos.d
vim cdh.repo

创建apache httpd的读取链接
ln -s /export/servers/cdh/5.14.0 /var/www/html/CDH
确保linux的Selinux关闭
临时关闭:
[root@localhost ~]# getenforce
Enforcing
[root@localhost ~]# setenforce 0
[root@localhost ~]# getenforce
Permissive
永久关闭:
[root@localhost ~]# vim /etc/sysconfig/selinux
SELINUX=enforcing 改为 SELINUX=disabled
重启服务reboot通过浏览器访问本地yum源,如果出现下述页面则成功。
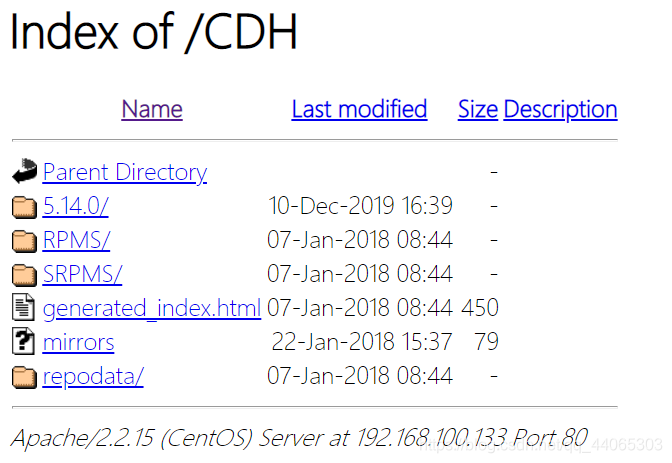
将本地yum源配置文件localimp.repo发放到所有需要安装impala的节点。
cd /etc/yum.repos.d/
scp cdh.repo node02:$PWD
scp cdh.repo node03:$PWD
四、安装Impala
1、集群规划
| 服务名称 |
从节点 |
从节点 |
主节点 |
| impala-catalog |
|
|
Node-3 |
| impala-state-store |
|
|
Node-3 |
| impala-server(impalad) |
Node-1 |
Node-2 |
Node-3 |
在规划的主节点node-3执行以下命令进行安装:
yum install -y impala impala-server impala-state-store impala-catalog impala-shell在规划的从节点node-1、node-2执行以下命令进行安装:
yum install -y impala-server五、修改Hadoop、Hive配置
需要在3台机器整个集群上进行操作,都需要修改。hadoop、hive是否正常服务并且配置好,是决定impala是否启动成功并使用的前提
1、修改hive配置
vim /export/servers/hive/conf/hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hadoop</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 绑定运行hiveServer2的主机host,默认localhost -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node01</value>
</property>
<!-- 指定hive metastore服务请求的uri地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://node01:9083</value>
<!-- 启动impala使用hive的时候要在这里指定的节点开启hive服务 -->
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>3600</value>
</property>
</configuration>将hive配置cp给其他两个机器。
cd $HIVE_HOME/conf
scp hive-site.xml node02:$PWD
scp hive-site.xml node03:$PWD
2、修改hadoop配置
所有节点创建下述文件夹
mkdir -p /var/run/hdfs-sockets
修改所有节点的hdfs-site.xml添加以下配置,修改完之后重启hdfs集群生效
vim etc/hadoop/hdfs-site.xml
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hdfs-sockets/dn</value>
</property>
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value>10000</value>
</property>
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>dfs.domain.socket.path是Datanode和DFSClient之间沟通的Socket的本地路径。dfs.client.read.shortcircuit 打开DFSClient本地读取数据的控制,
把更新hadoop的配置文件,scp给其他机器。
cd $HADOOP_HOME/etc/hadoop
scp -r hdfs-site.xml node02:$PWD
scp -r hdfs-site.xml node03:$PWD
注意:root用户不需要下面操作,普通用户需要这一步操作。
给这个文件夹赋予权限,如果用的是普通用户hadoop,那就直接赋予普通用户的权限,例如:
chown -R hadoop:hadoop /var/run/hdfs-sockets/
3、重启hadoop、hive
在node01上执行下述命令分别启动hive metastore服务和hadoop。
cd /$HIVE
nohup bin/hive --service metastore &
nohup bin/hive --service hiveserver2 &
cd /$HADOOP_HOME
sbin/stop-dfs.sh | sbin/start-dfs.sh
4、复制hadoop、hive配置文件
impala的配置目录为/etc/impala/conf,这个路径下面需要把core-site.xml,hdfs-site.xml以及hive-site.xml。
所有节点执行以下命令
cp -r /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml
cp -r /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml
cp -r /export/servers/hive-1.1.0-cdh5.14.0/conf/hive-site.xml /etc/impala/conf/hive-site.xml
六、修改impala配置
1、修改impala默认配置
所有节点更改impala默认配置文件
vim /etc/default/impala
IMPALA_CATALOG_SERVICE_HOST=node03
IMPALA_STATE_STORE_HOST=node03
scp /etc/default/impala node02:$PWD
scp /etc/default/impala node03:$PWD
2、添加mysql驱动
通过配置/etc/default/impala中可以发现已经指定了mysql驱动的位置名字。
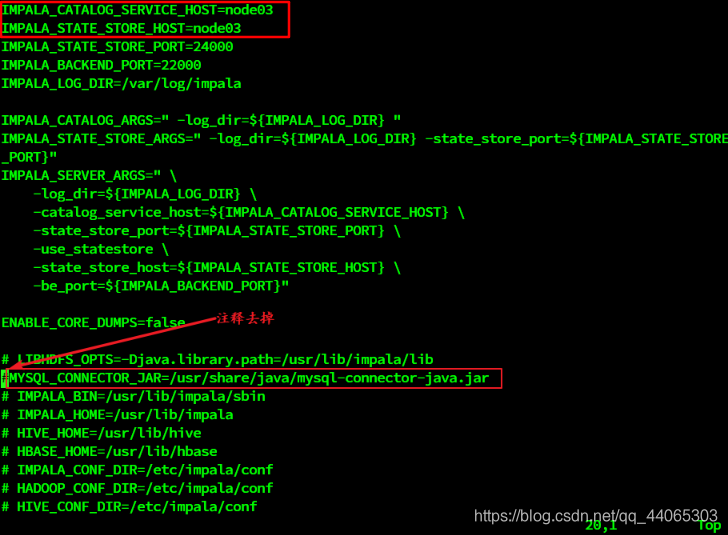
使用软链接指向该路径即可(3台机器都需要执行)
ln -s /export/servers/hive/lib/mysql-connector-java-5.1.32.jar /usr/share/java/mysql-connector-java.jar
3、修改bigtop配置
修改bigtop的java_home路径(3台机器)
vim /etc/default/bigtop-utils
export JAVA_HOME=/export/servers/jdk1.8.0_65
七、启动、关闭impala服务
主节点node-3启动以下三个服务进程
service impala-state-store start
service impala-catalog start
service impala-server start
从节点启动node-1与node-2启动impala-server
service impala-server start
查看impala进程是否存在
ps -ef | grep impala

启动之后所有关于impala的日志默认都在/var/log/impala
如果需要关闭impala服务 把命令中的start该成stop即可。注意如果关闭之后进程依然驻留,可以采取下述方式删除。正常情况下是随着关闭消失的。
解决方式:

impala web ui
访问impalad的管理界面http://node-3:25000/
访问statestored的管理界面http://node-3:25010/
智能推荐
UIAutomator2.0详解(UIDevice篇----Wait)_uidevice wait-程序员宅基地
文章浏览阅读9.7k次,点赞2次,收藏7次。感觉拖了好久,今天将Wait接口的总结补上,顺便把SearchCondition也捎带结了。 直接上图。Wait方法含义:查看查询条件是否符合,若符合,则返回结果。若不符合,则继续等待,直至超时。 返回结果可能为UIObject2对象或者UIObject2对象列表,或者布尔类型。其中,传参SearchCondition是一个抽象类,若想获取其实体对象,需要调用Until工具类。 该类提供了4个_uidevice wait
SpringBoot——入门案例之“Hello SpringBoot“-程序员宅基地
文章浏览阅读8.1k次,点赞2次,收藏4次。SpringBoot——入门案例之“Hello SpringBoot“_hello springboot
Docker精华 ,超全文档!-程序员宅基地
文章浏览阅读1.2k次。我们的口号是:人生不设限!! 学习规划:继续上篇 《Docker入门》https://www.cnblogs.com/dk1024/p/13121389.html 继续讲解:一、容器数据卷1、什么是容器数据卷:Docker是将应用和环境打包成一个镜像,发布到服务器,这个跑起来的容器如果不小心删除掉,呢么数据就会全部丢失,尤其是Mysql之类的容器,name现在就有一个需求,数..._avtxt
Java高级特性之XML_java xml示“收藏信息.xml”文件中收藏的手机品牌和型号-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏15次。XML 简介、编写规范、Java 解析 XML(DOM 解析 XML、DOM4J 解析 XML)……关于 Java 高级特性之 XML 比较详细、系统的整理。_java xml示“收藏信息.xml”文件中收藏的手机品牌和型号
笔记:《高效能人士的七个习惯》第九章 习惯六 统合综效——创造性合作的原则_高效能人士的七个习惯 第九章统合综效-程序员宅基地
文章浏览阅读6.4k次。1、统合综效的基本心态是:如果一位具有相当聪明才智的人跟我意见不同,那么对方的主张必定有我尚未体会的奥妙,值得加以了解。2、与人合作最重要的是,重视不同个体的不同心理、情绪与智能,以及个人眼中所见到的不同世界。与所见略同的人沟通,益处不大,要有分歧才有收获。3、我以圣者的期望自勉:对关键事务——团结,对重大事务——求变,对所有事务——宽大。——美国前总统乔治.布什(George Bush)_高效能人士的七个习惯 第九章统合综效
【实用工具】几款常用GIS/测绘工具分享_坐标转换工具-程序员宅基地
文章浏览阅读846次。笑脸工具,用于坐标转换。_坐标转换工具
随便推点
基于法向量的点云分割方法及Matlab实现-程序员宅基地
文章浏览阅读36次。在本文中,我们介绍了基于法向量的点云分割方法,并提供了Matlab实现代码。该方法通过分析点云中的法向量信息,可以有效地划分点云数据集,识别出不同的表面和物体。基于法向量的点云分割方法将点云中的每个点的法向量信息作为关键特征来进行分割。基于法向量的点云分割方法将点云中的每个点的法向量信息作为关键特征来进行分割。该方法通过分析点云中的法向量信息,可以有效地划分点云数据集,识别出不同的表面和物体。点云分割是计算机视觉和模式识别领域的重要任务之一,它的目标是将点云数据集划分为具有不同属性或语义的子集。
【OpenVINO】C#调用OpenVINO部署Al模型项目开发-2.软件安装_vs2022如何安装openvino c# api-程序员宅基地
文章浏览阅读630次。C#调用OpenVINOTM部署Al模型项目开发项目,简称OpenVinoSharp,这是一个示例项目,该项目实现在C#编程语言下调用Intel推出的 OpenVINO 工具套件,进行深度学习等Al项目在C#框架下的部署。该项目由C++语言编写OpenVINO API接口,并在C#语言下实现应用。..._vs2022如何安装openvino c# api
Flyway提供的六种命令_flyway命令-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏4次。Flyway对数据库进行版本管理主要由Metadata表(默认是flyway_schema_history)和6种命令完成,Metadata主要用于记录每次执行的脚本和version等信息,下面一一介绍。Metadata表(flyway_schema_history)Flyway中最核心的就是用于记录所有版本执行结果和状态的Metadata表,在Flyway首次启动时会创建默认名为flywa..._flyway命令
Android常见Crash介绍_android crash-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏7次。Crash问题分析定位:通过Log文件夹下全局搜am_crash,此时会把log文件下下所有的包含am_crash的行显示出来一.导致Android Crash 问题的主要类型4)Other由上图可见,在APP层面我们出现并能解决的BUG 集中在App Crash 和System crash 层;_android crash
curl 访问https接口_php使用curl获取https请求的方法-程序员宅基地
文章浏览阅读1.1k次。这篇文章主要介绍了php使用curl获取https请求的方法,涉及curl针对https请求的操作技巧,非常具有实用价值,需要的朋友可以参考下本文实例讲述了php使用curl获取https请求的方法。分享给大家供大家参考。具体分析如下:今日在做一个项目,需要curl获取第三方的API,对方的API是https方式的。之前使用curl能获取http请求,但今天获取https请求时,出现了以下的错误提..._curl 访问 api ssl
Redis cluster集群搭建_redis cluster 搭建-程序员宅基地
文章浏览阅读1.1k次,点赞23次,收藏21次。1.2数据存储采用分片存储方式,整个redis集群有16384个哈希槽,集群中的每个节点负责一部分哈希槽,现在集群中三个主节点,就会把这些哈希槽平均分配给三个主节点,即节点A存储的哈希槽范围是:0 – 5500,节点B存储的哈希槽范围是:5501 – 11000,节点C存储的哈希槽范围是:11001 – 16384,当需要扩容主节点时会将ABC的哈希槽数据提取一部分到新的主节点D上,若是删除主节点A,就需要先将A中的哈希槽数据转移到BC节点上再进行删除。因为redis是用c实现的,所有要进行编译操作;_redis cluster 搭建