Flink双流JOIN-程序员宅基地
1、引子
1.1 数据库SQL中的JOIN
我们先来看看数据库SQL中的JOIN操作。如下所示的订单查询SQL,通过将订单表的id和订单详情表order_id关联,获取所有订单下的商品信息。
select
a.id as '订单id',
a.order_date as '下单时间',
a.order_amount as '订单金额',
b.order_detail_id as '订单详情id',
b.goods_name as '商品名称',
b.goods_price as '商品价格',
b.order_id as '订单id'
from
dwd_order_info_pfd a
right join
dwd_order_detail_pfd b
on a.id = b.order_id
这是一段很简单的SQL代码,就不详细展开叙述了。此处主要引出SQL中的JOIN类型,这里用到的是 right join , 即右连接。
left join: 保留左表全部数据和右表关联数据,右表非关联数据置NULL
right join: 保留右表全部数据和左表关联数据,左表非关联数据置NULL
inner join: 保留左表关联数据和右边关联数据
cross join: 保留左表和右表数据笛卡尔积
基于关联键值逐行关联匹配,过滤表数据并生成最终结果,提供给下游数据分析使用。
就此打住,关于数据库SQL中的JOIN原理不再多赘述,感兴趣的话大家可自行研究,下面我们将目光转移到大数据领域看看吧。
1.2 离线场景下的JOIN
假设存在这样一个场景:
已知Mysql数据库中订单表和订单明细表,且满足一对多的关系,统计T-1天所有订单的商品分布详情。
聪明的大家肯定已经给出了答案,没错~就是上面的SQL:
select a.*, b.*
from
dwd_order_info_pfd a
right join
dwd_order_detail_pfd b
on a.id = b.order_id
现在修改下条件:已知订单表和订单明细表均为亿级别数据,求相同场景下的分析结果。
咋办?此时关系型数据库貌似不大合适了~开始放大招:使用大数据计算引擎来解决。
考虑到T-1统计场景对时效性要求很低,可以使用Hive SQL来处理,底层跑Mapreduce任务。如果想提高运行速度,换成Flink或Spark计算引擎,使用内存计算。
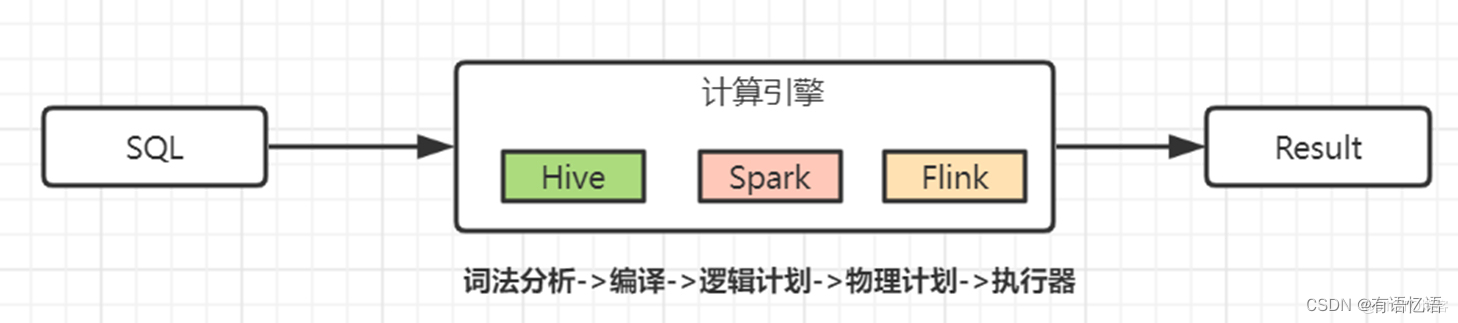
至于查询SQL和上面一样,并将其封装成一个定时调度任务, 等系统调度运行。如果结果不正确的话,由于数据源和数据静态不变,大不了重跑,看起来感觉皆大欢喜~
可是好景不长,产品冤家此时又给了你一个无法拒绝的需求:我要实时统计!!
2、实时场景下的JOIN
还是上面的场景,此时数据源换成了实时订单流和实时订单明细流,比如Kafka的两个topic,要求实时统计每分钟内所有订单下的商品分布详情。
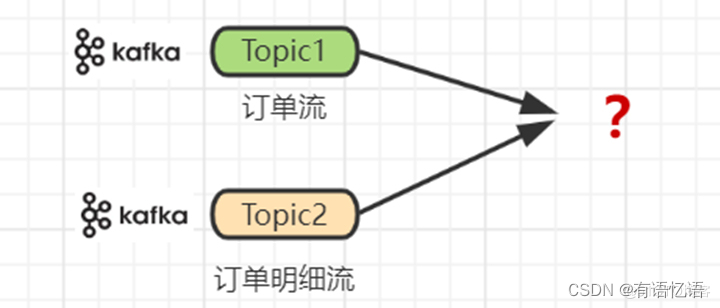
现在情况貌似变得复杂了起来,简单分析下:
-
数据源。实时数据流,和静态流不同,数据是实时流入的且动态变化,需要计算程序支持实时处理机制。
-
关联性。前面提到静态数据执行多次join操作,左表和右表能关联的数据是很恒定的;而实时数据流(左右表)如果进入时机不一致,原本可以关联的数据会关联不上或者发生错误。
-
延迟性。实时统计,提供分钟甚至秒级别响应结果。
由于流数据join的特殊性,在满足实时处理机制、低延迟、强关联性的前提下,看来需要制定完善的数据方案,才能实现真正的流数据JOIN。
2.1 方案思路
我们知道订单数据和订单明细数据是一对多的关系,即一条订单数据对应着多条商品明细数据,毕竟买一件商品也是那么多邮费,不如打包团购。。而一条明细数据仅对应一条订单数据。
这样,双流join策略可以考虑如下思路:
当数据流为订单数据时。无条件保留,无论当前是否关联到明细数据,均留作后续join使用。
当数据流为明细数据时。在关联到其订单数据后,就可以say goodbye了,否则暂时保留等待下一次与订单数据的邂逅。
完成所有处于同一时段内的订单数据和订单明细数据join, 清空存储状态
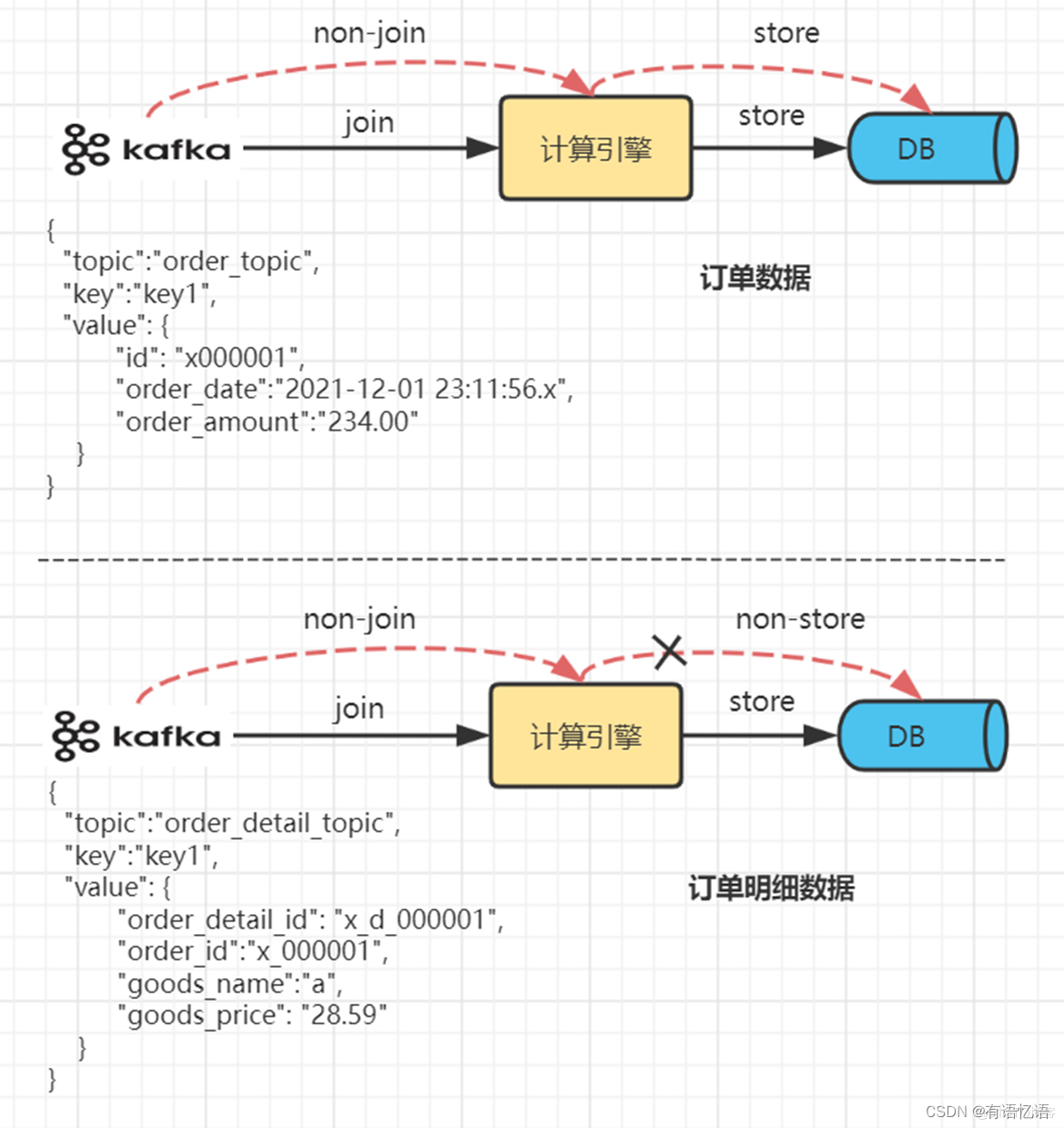
实际生产场景中,需要考虑更多的复杂情况,包括JOIN过程的数据丢失等异常情况的处理,此处仅示意。
好了,看起来我们已经有了一个马马虎虎的实时流JOIN方案雏形。
貌似可以准备动手大干一场了~ 别着急,有人已经帮我们偷偷的实现了:Apache Flink
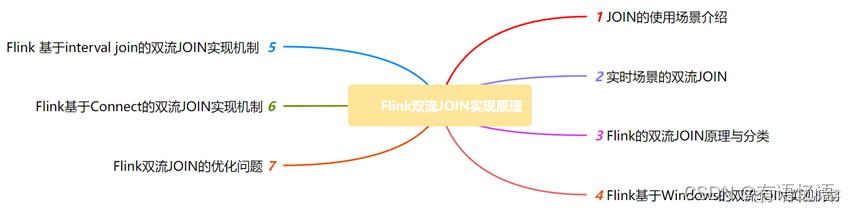
3、Flink的双流JOIN
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。——来自Flink官网定义
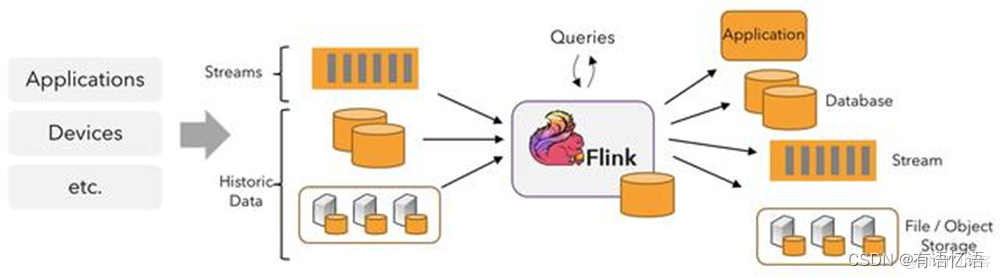
这里我们只需要知道Flink是一个实时计算引擎就行了,主要关注其如何实现双流JOIN。
3.1 内部运行机制
内存计算:Flink任务优先在内存中计算,内存不够时保存到访问高效的磁盘,提供秒级延迟响应。
状态强一致性:Flink使用一致性快照保存状态,并定期检查本地状态、持久存储来保证状态一致性。
分布式执行: Flink应用程序可以划分为无数个并行任务在集群中执行,几乎无限量使用CPU、主内存、磁盘和网络IO。
内置高级编程模型:Flink编程模型抽象为SQL、Table、DataStream|DataSet API、Process四层,并封装成丰富功能的算子,其中就包含JOIN类型的算子。
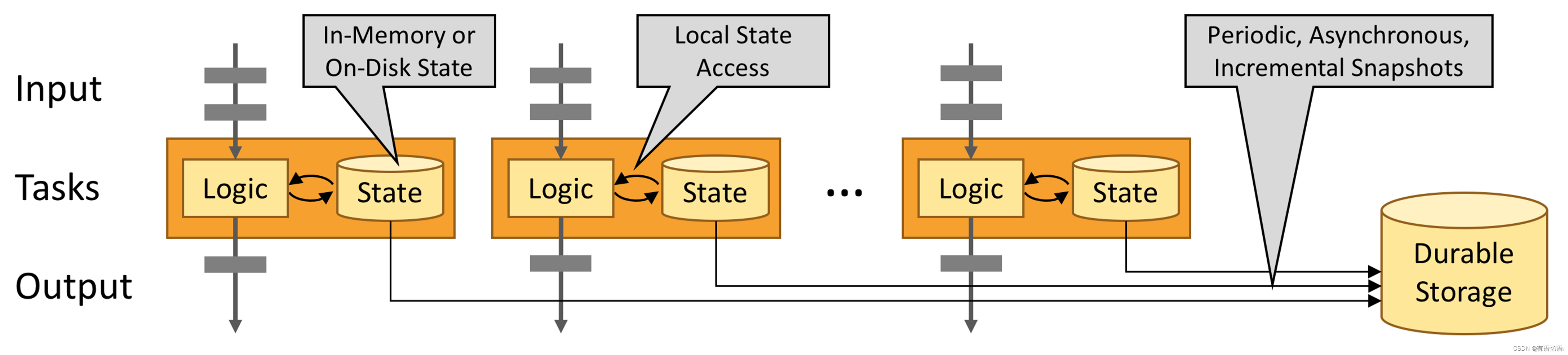
仔细看看,我们前面章节讨论的实时流JOIN方案的前提是否都满足了呢?
-
实时处理机制: Flink天生即实时计算引擎
-
低延迟: Flink内存计算秒级延迟
-
强关联性: Flink状态一致性和join类算子
不由感叹, 这个Flink果然强啊~
保持好奇心,我们去瞅瞅Flink双流join的真正奥义!!
3.2 JOIN实现机制
Flink双流JOIN主要分为两大类。一类是基于原生State的Connect算子操作,另一类是基于窗口的JOIN操作。其中基于窗口的JOIN可细分为window join和interval join两种。
实现原理:底层原理依赖Flink的State状态存储,通过将数据存储到State中进行关联join, 最终输出结果。
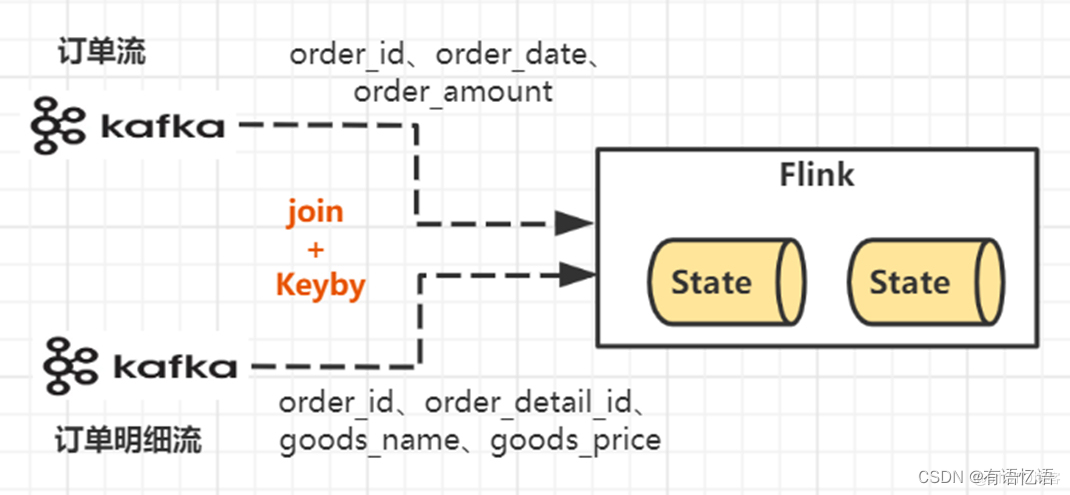
恍然大悟, Flink原来是通过State状态来缓存等待join的实时流。
这里给大家抛出一个问题:
用redis存储可不可以,state存储相比redis存储的区别?
回到正题,这几种方式到底是如何实现双流JOIN的?我们接着往下看。
注意: 后面内容将多以文字 + 代码的形式呈现,避免枯燥,我放了一堆原创示意图~
4、基于Window Join的双流JOIN实现机制
顾名思义,此类方式利用Flink的窗口机制实现双流join。通俗理解,将两条实时流中元素分配到同一个时间窗口中完成Join。
底层原理: 两条实时流数据缓存在Window State中,当窗口触发计算时,执行join操作。
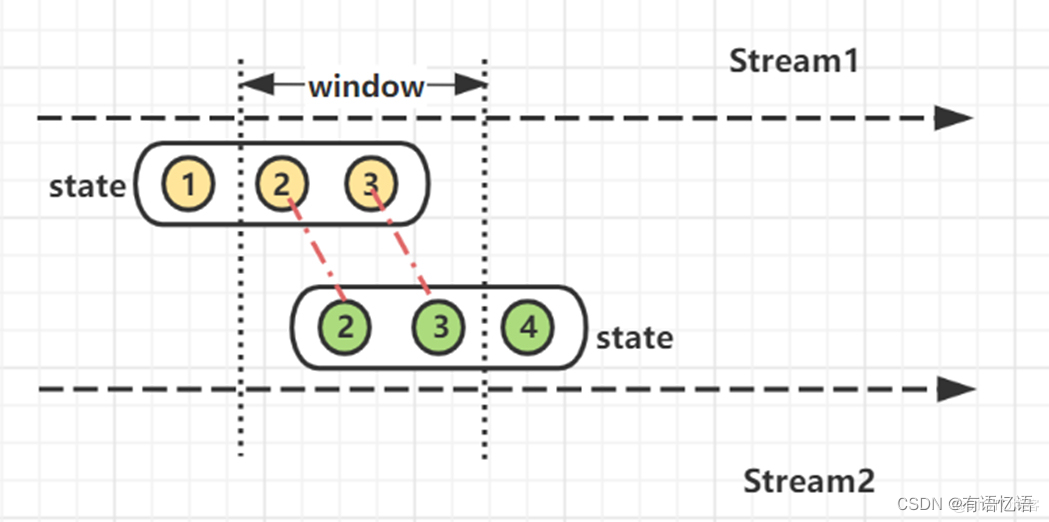
4.1 join算子
先看看Window join实现方式之一的join算子。这里涉及到Flink中的窗口(window)概念,因此Window Joinan按照窗口类型区分的话某种程度来说可以细分出3种:
Tumbling Window Join (滚动窗口)

Sliding Window Join (滑动窗口)
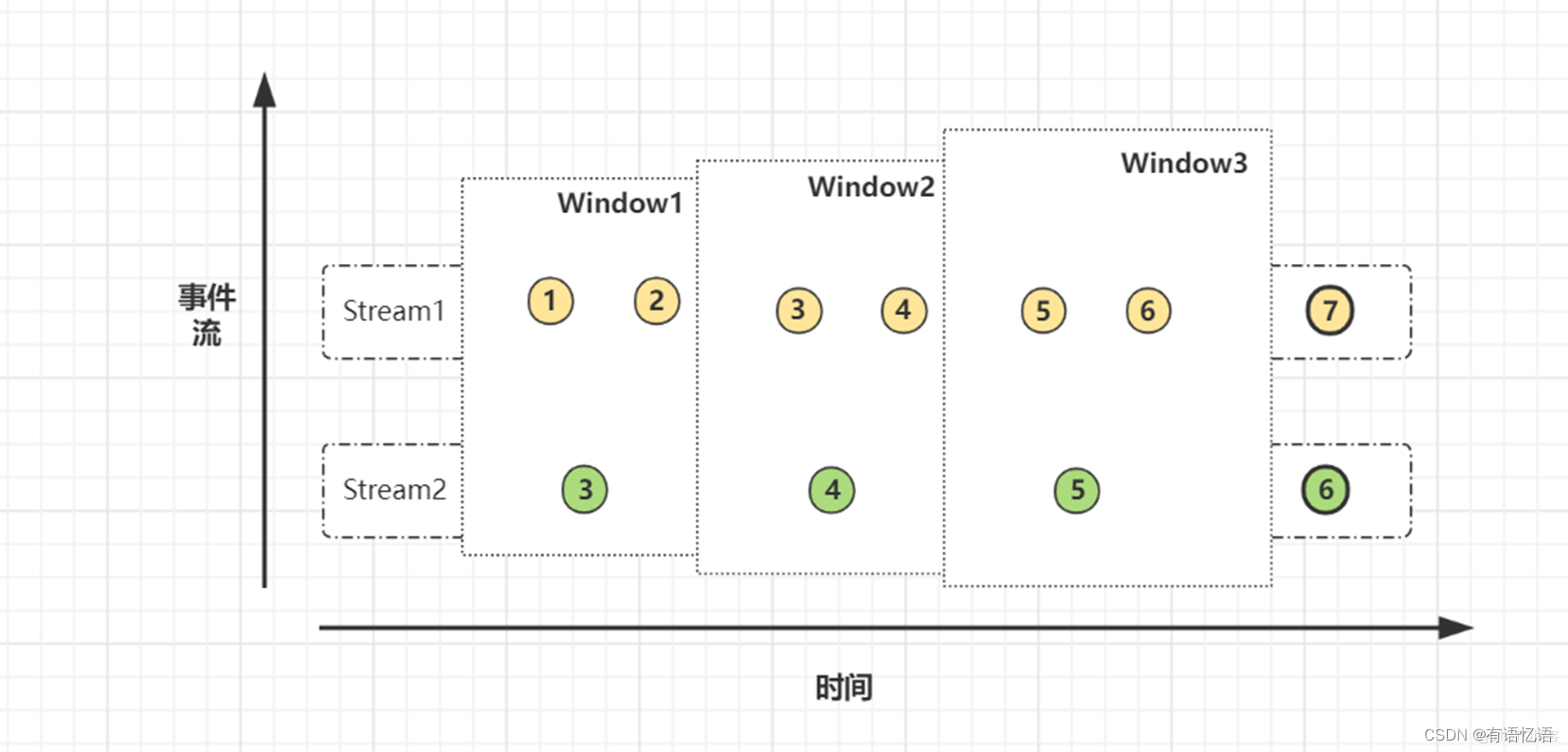
Session Widnow Join(会话窗口)
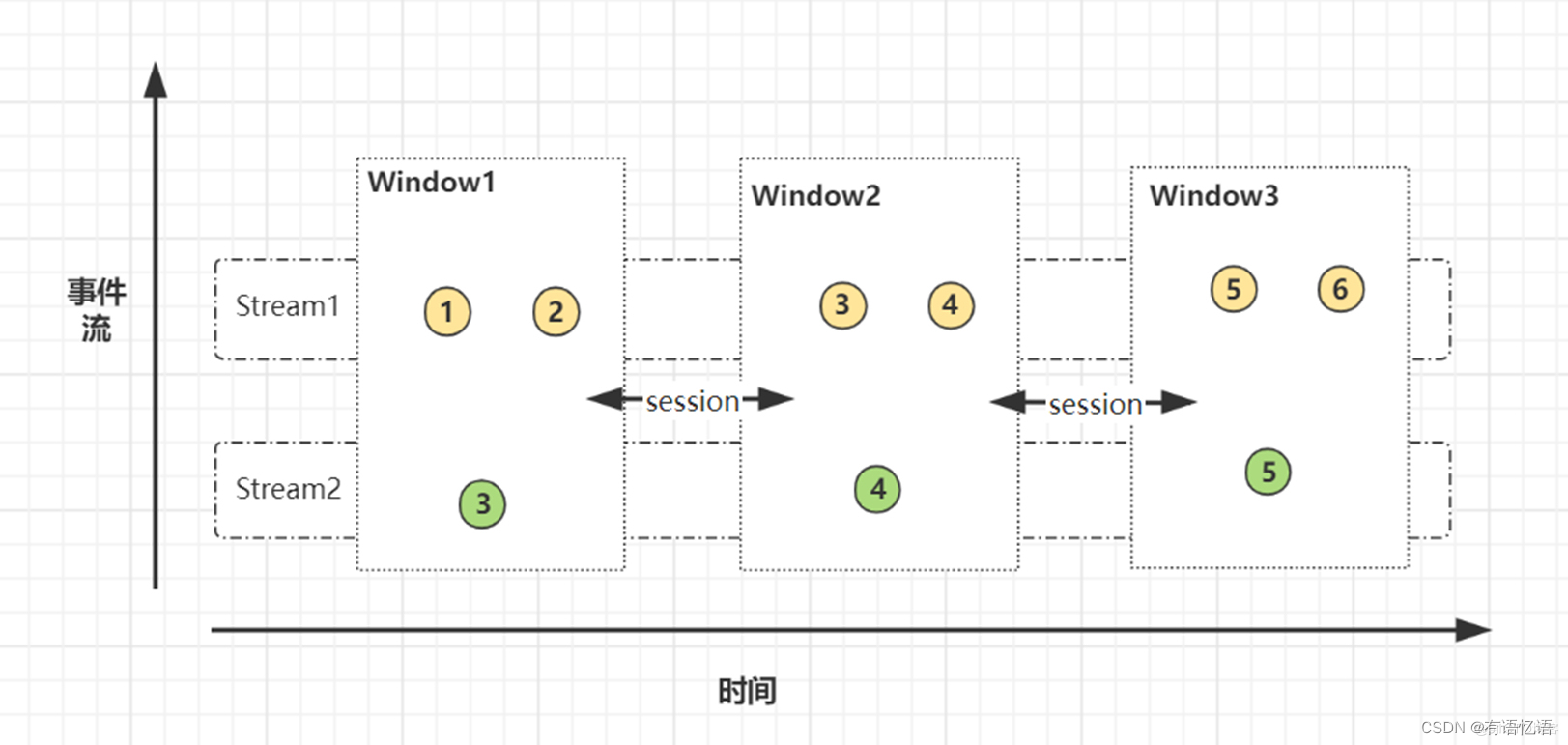
两条流数据按照关联主键在(滚动、滑动、会话)窗口内进行inner join, 底层基于State存储,并支持处理时间和事件时间两种时间特征,看下源码:
源码核心总结:windows窗口 + state存储 + 双层for循环执行join()
现在让我们把时间轴往回拉一点点,在实时场景JOIN那里我们收到了这样的需求:统计每分钟内所有订单下的商品明细分布。
OK, 使用join算子小试牛刀一下。我们定义60秒的滚动窗口,将订单流和订单明细流通过order_id关联,得到如下的程序:
val env = ...
// kafka 订单流
val orderStream = ...
// kafka 订单明细流
val orderDetailStream = ...
orderStream.join(orderDetailStream)
.where(r => r._1) //订单id
.equalTo(r => r._2) //订单id
.window(TumblingProcessTimeWindows.of(
Time.seconds(60)))
.apply {
(r1, r2) => r1 + " : " + r2}
.print()
整个代码其实很简单,概要总结下:
定义两条输入实时流A、B
A流调用join(b流)算子
关联关系定义: where为A流关联键,equalTo为B流关联键,都是订单id
定义window窗口(60s间隔)
apply方法定义逻辑输出
这样只要程序稳定运行,就能够持续不断的计算每分钟内订单分布详情,貌似解决问题了奥~
还是别高兴太早,别忘了此时的join类型是inner join。复习一下知识: inner join指的是仅保留两条流关联上的数据。
这样双流中没关联上的数据岂不是都丢掉了?别担心,Flink还提供了另一个window join操作: coGroup算子。
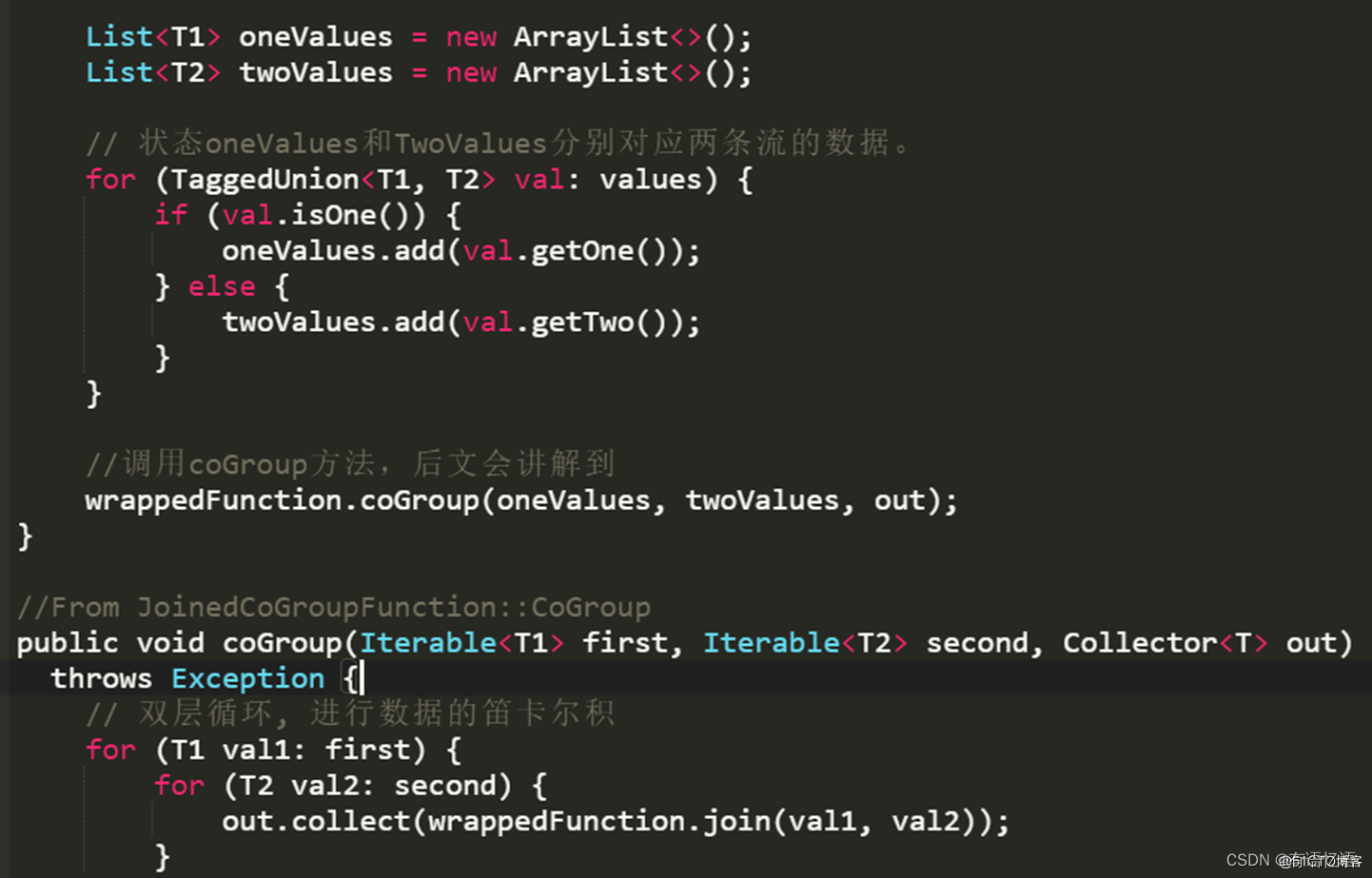
4.2 coGroup算子
coGroup算子也是基于window窗口机制,不过coGroup算子比Join算子更加灵活,可以按照用户指定的逻辑匹配左流或右流数据并输出。
换句话说,我们通过自己指定双流的输出来达到left join和right join的目的。
现在来看看在相同场景下coGroup算子是如何实现left join:
#这里看看java算子的写法
orderDetailStream
.coGroup(orderStream)
.where(r -> r.getOrderId())
.equalTo(r -> r.getOrderId())
.window(TumblingProcessingTimeWindows.of(Time.seconds(60)))
.apply(new CoGroupFunction<OrderDetail, Order, Tuple2<String, Long>>() {
@Override
public void coGroup(Iterable<OrderDetail> orderDetailRecords, Iterable<Order> orderRecords, Collector<Tuple2<String, Long>> collector) {
for (OrderDetail orderDetaill : orderDetailRecords) {
boolean flag = false;
for (Order orderRecord : orderRecords) {
// 右流中有对应的记录
collector.collect(new Tuple2<>(orderDetailRecords.getGoods_name(), orderDetailRecords.getGoods_price()));
flag = true;
}
if (!flag) {
// 右流中没有对应的记录
collector.collect(new Tuple2<>(orderDetailRecords.getGoods_name(), null));
}
}
}
})
.print();
这里需要说明几点:
join算子替换为coGroup算子
两条流依然需要在一个window中且定义好关联条件
apply方法中自定义判断,此处对右值进行判断:如果有值则进行连接输出,否则右边置为NULL。
可以这么说,现在我们已经彻底搞定了窗口双流JOIN。
只要你给我提供具体的窗口大小,我就能通过join或coGroup算子鼓捣出各种花样join,而且使用起来特别简单。
但是假如此时我们亲爱的产品又提出了一个小小问题:
大促高峰期,商品数据某时段会写入不及时,时间可能比订单早也可能比订单晚,还是要计算每分钟内的订单商品分布详情,没问题吧~
当然有问题:两条流如果步调不一致,还用窗口来控制能join的上才怪了~ 很容易等不到join流窗口就自动关闭了。
还好,我知道Flink提供了Interval join机制。
5、基于Interval Join的双流JOIN实现机制
Interval Join根据右流相对左流偏移的时间区间(interval)作为关联窗口,在偏移区间窗口中完成join操作。
有点不好理解,我画个图看下:

stream2.time ∈ (stream1.time +low, stream1.time +high)
满足数据流stream2在数据流stream1的 interval(low, high)偏移区间内关联join。interval越大,关联上的数据就越多,超出interval的数据不再关联。
实现原理:interval join也是利用Flink的state存储数据,不过此时存在state失效机制ttl,触发数据清理操作。
这里再引出一个问题:
state的ttl机制需要怎么设置?不合理的ttl设置会不会撑爆内存?
我会在后面的文章中深入讲解下State的ttl机制,欢迎大家一起探讨~
下面简单看下interval join的代码实现过程:
val env = ...
// kafka 订单流
val orderStream = ...
// kafka 订单明细流
val orderDetailStream = ...
orderStream.keyBy(_.1)
// 调用intervalJoin关联
.intervalJoin(orderDetailStream._2)
// 设定时间上限和下限
.between(Time.milliseconds(-30), Time.milliseconds(30))
.process(new ProcessWindowFunction())
class ProcessWindowFunction extends ProcessJoinFunction...{
override def processElement(...) {
collector.collect((r1, r2) => r1 + " : " + r2)
}
}
订单流在流入程序后,等候(low,high)时间间隔内的订单明细流数据进行join, 否则继续处理下一个流。
从代码中我们发现,interval join需要在两个KeyedStream之上操作,即keyBy(),并在between()方法中指定偏移区间的上下界。
需要注意的是interval join实现的也是inner join,且目前只支持事件时间。
6、基于Connect的双流JOIN实现机制
前面在使用Window join或者Interval Join来实现双流join的时候,我发现了其中的共性:
无论哪种实现方式,Flink内部都将join过程透明化,在算子中封装了所有的实现细节。
这是什么?是编程语言中的抽象概念~ 隐藏底层细节,对外暴露统一API, 大幅简化程序编码。
可是这样会引来一个问题:如果程序报错或者数据异常,如何快速进行调优排查,直接看源码吗?不大现实。。
这里介绍基于Connect算子实现的双流JOIN方法,我们可自己控制双流JOIN处理逻辑,同时保持过程时效性和准确性。
6.1 Connect算子原理
对两个DataStream执行connect操作,将其转化为ConnectedStreams, 生成的Streams可以调用不同方法在两个实时流上执行,且双流之间可以共享状态。
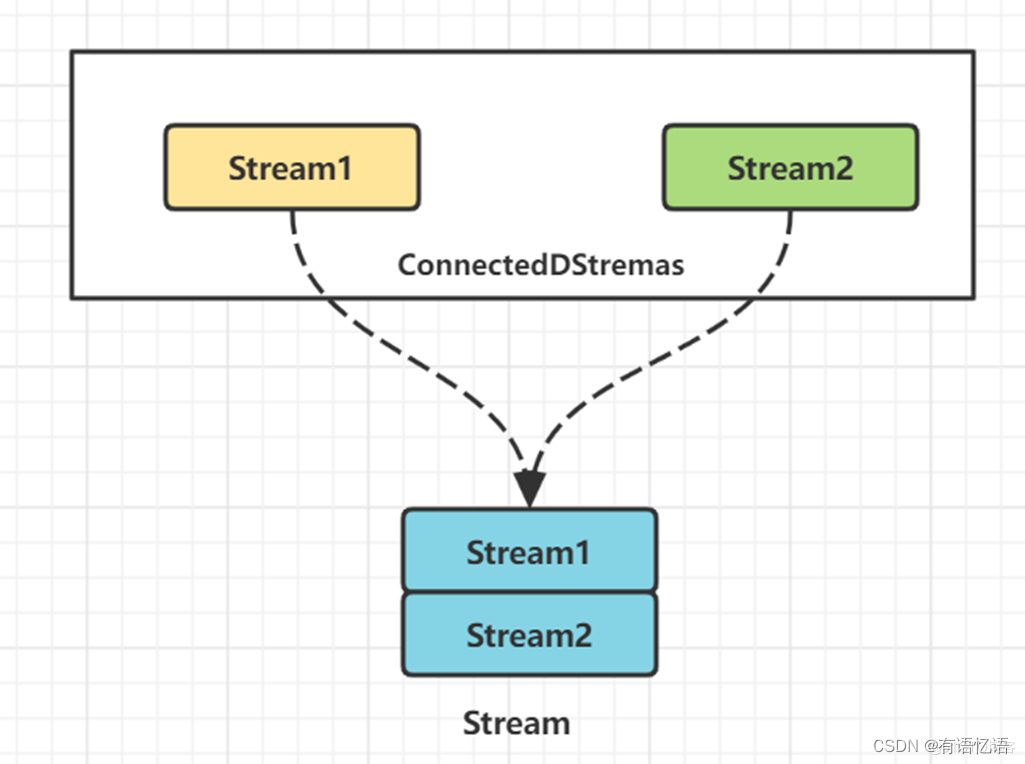
图上我们可以看到,两个数据流被connect之后,只是被放在了同一个流中,内部依然保持各自的数据和形式,两个流相互独立。
[DataStream1, DataStream2] -> ConnectedStreams[1,2]
这样,我们可以在Connect算子底层的ConnectedStreams中编写代码,自行实现双流JOIN的逻辑处理。
6.2 技术实现
1.调用connect算子,根据orderid进行分组,并使用process算子分别对两条流进行处理。
orderStream.connect(orderDetailStream)
.keyBy("orderId", "orderId")
.process(new orderProcessFunc());
2.process方法内部进行状态编程, 初始化订单、订单明细和定时器的ValueState状态。
private ValueState<OrderEvent> orderState;
private ValueState<TxEvent> orderDetailState;
private ValueState<Long> timeState;
// 初始化状态Value
orderState = getRuntimeContext().getState(
new ValueStateDescriptor<Order>
("order-state",Order.class));
····
3.为每个进入的数据流保存state状态并创建定时器。在时间窗口内另一个流达到时进行join并输出,完成后删除定时器。
@Override
public void processElement1(Order value, Context ctx, Collector<Tuple2<Order, OrderDetail>> out){
if (orderDetailState.value() == null){
//明细数据未到,先把订单数据放入状态
orderState.update(value);
//建立定时器,60秒后触发
Long ts = (value.getEventTime()+10)*1000L;
ctx.timerService().registerEventTimeTimer(
ts);
timeState.update(ts);
}else{
//明细数据已到,直接输出到主流
out.collect(new Tuple2<>(value,orderDetailS
tate.value()));
//删除定时器
ctx.timerService().deleteEventTimeTimer
(timeState.value());
//清空状态,注意清空的是支付状态
orderDetailState.clear();
timeState.clear();
}
}
...
@Override
public void processElement2(){
...
}
4.未及时达到的数据流触发定时器输出到侧输出流,左流先到而右流未到,则输出左流,反之输出右连流。
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Tuple2<Order, OrderDetail>> out) {
// 实现左连接
if (orderState.value() != null){
ctx.output(new OutputTag<String>("left-jo
in") {},
orderState.value().getTxId());
// 实现右连接
}else{
ctx.output(new OutputTag<String>("left-jo
in") {},
orderDetailState.value().getTxId());
}
orderState.clear();
orderDetailState.clear();
timeState.clear();
}
总体思想:基于数据时间实现订单数据及订单明细数据的关联,超时或者缺失则由侧输出流输出。
在connect中针对订单流和订单明细流,先创建定时器并保存state状态,处于窗口内就进行join, 否则进入侧输出流。
7、双流JOIN的优化与总结
- 为什么我的双流join时间到了却不触发,一直没有输出
检查一下watermark的设置是否合理,数据时间是否远远大于watermark和窗口时间,导致窗口数据经常为空
- state数据保存多久,会内存爆炸吗
state自带有ttl机制,可以设置ttl过期策略,触发Flink清理过期state数据。建议程序中的state数据结构用完后手动clear掉。
- 我的双流join倾斜怎么办
join倾斜三板斧: 过滤异常key、拆分表减少数据、打散key分布。当然可以的话我建议加内存!加内存!加内存!!
- 想实现多流join怎么办
目前无法一次实现,可以考虑先union然后再二次处理;或者先进行connnect操作再进行join操作,仅建议~
- join过程延迟、没关联上的数据会丢失吗
这个一般来说不会,join过程可以使用侧输出流存储延迟流;如果出现节点网络等异常,Flink checkpoint也可以保证数据不丢失。
智能推荐
解决Rstudio打开空白_rstudio打开后一片空白-程序员宅基地
文章浏览阅读1.9w次,点赞13次,收藏31次。近期更新了下Rstudio,突然出现打不开的情况,看了两天,终于让我解决了,解决方法如下:首先检查:1、R语言安装指定为64位(其实安装时按默认方式就行,现在电脑大多数都是64的);2、R语言和Rstudio的安装父目录要为同一个,你可以选择一个盘直接在里面创建一个R文件夹,把R语言和Rstudio两个安装路径选择我们创建的R文件夹就可以了;3、R语言和Rstudio的安装路径不要有汉字,这个是必须知道的。4、有些人还是会显示空白,就可以选择右键选择以管理员身份运行,如果可以进了,可以用以下方式_rstudio打开后一片空白
理解 Ruby Symbol (Ruby中的冒号)_ruby 冒号-程序员宅基地
文章浏览阅读3w次,点赞5次,收藏16次。Symbol 是什么Ruby 是一个强大的面向对象脚本语言(本文所用 Ruby 版本为1.8.6),在 Ruby 中 Symbol 表示“名字”,比如字符串的名字,标识符的名字。创建一个 Symbol 对象的方法是在名字或者字符串前面加上冒号:创建 symbol 对象 :foo:test_ruby 冒号
2018.12.04 verification models and identification models_learning deep features from body and parts for per-程序员宅基地
文章浏览阅读200次。参考文章内容:Learning deep features from body and parts for person re-identification in camera networksverification models and identification models:The verification models [10–12] takepairs of images a..._learning deep features from body and parts for person re-identification in c
Android i2cdetect i2cdump i2cget i2cset调试工具使用_i2cget命令详解-程序员宅基地
文章浏览阅读5.5k次,点赞6次,收藏36次。本文介绍Android/Linux (反正是ARM) 的I2C调试工具用法 , 包括i2cdetect、i2cdump、i2cget和i2cset,可实现I2C设备的识别、监控和配置。i2cdetect用于扫描所有设备地址,i2cdump读取寄存器的值,而i2cget和i2cset分别实现读取和写入寄存器的功能。这些工具提供了便捷的方式与I2C设备进行交互,深入了解设备状态与配置。_i2cget命令详解
你以为的计算机网络技术,tgwgua计算机网络技术对人类社会发展的影响-程序员宅基地
文章浏览阅读89次。tgwgua计算机网络技术对人类社会发展的影响-+懒惰是很奇怪的东西,它使你以为那是安逸,是休息,是福气;但实际上它所给你的是无聊,是倦怠,是消沉;它剥夺你对前途的希望,割断你和别人之间的友情,使你心胸日渐狭窄,对人生也越来越怀疑。—罗兰计算机网络技术对人类社会发展的影响摘要:20世纪大众媒体在世界范围内经历了网络化的历程,信息化,数字化和网络化的高度一体化的信息交流方式使人们明显感觉到这种新的方..._计算机说tgw
火出圈的ChatGPT,在地学、地球科学领域的强大应用_chatgpt在地学-程序员宅基地
文章浏览阅读1.1k次,点赞37次,收藏23次。以ChatGPT、LLaMA、Gemini、DALL·E、Midjourney、Stable Diffusion、星火大模型、文心一言、千问为代表AI大语言模型带来了新一波人工智能浪潮,可以。4) 国内外经典大模型(ChatGPT、LLaMA、Gemini、DALL·E、Midjourney、Stable Diffusion、星火大模型、文心一言、千问等)2) 数据清洗方法(重复值、缺失值处理、异常值检验、标准化、归一化、数据长宽转换,数据分组聚合)4) 深度学习算法(神经网络、激活函数、交叉熵、优化器)_chatgpt在地学
随便推点
jquery——移动端滚动条插件iScroll.js-程序员宅基地
文章浏览阅读286次。官网:http://cubiq.org/iscroll-5demo:滚动刷新:http://cubiq.org/dropbox/iscroll4/examples/pull-to-refresh/ 'Carousel' demoiScroll功能很强大,目前我只用来自定义滚动条以下简单介绍一下iscrol在移动端自定义滚动条时的使用和...
海康威视iVMS系统在野 0day漏洞复现_/eps/api/resourceoperations/upload-程序员宅基地
文章浏览阅读1.9k次,点赞5次,收藏2次。简介:海康威视iVMS系统存在在野 0day 漏洞,攻击者通过获取密钥任意构造token,请求/resourceOperations/upload接口任意上传文件,导致获取服务器webshell权限,同时可远程进行恶意代码执行。_/eps/api/resourceoperations/upload
Beam Search 及5种优化方法-程序员宅基地
文章浏览阅读4.7k次,点赞7次,收藏28次。文章目录Beam Search 及优化1. Review Beam Search2. Beam Search Refinement2.1 Hypothesis filtering2.2 Normalization2.2.1 Length Normalization2.2.2 Coverage Normalization2.2.3 End of sentence Normalization2.3 Decoding with auxiliary language model2.4 Decoding with _beam search
Windows11 解除TPM限制破解安装方法汇总_win11 解除tpm-程序员宅基地
文章浏览阅读1w次。从应用的维度,来学习一下蓝牙_win11 解除tpm
新建groovy-maven工程(一)_new groovy project-程序员宅基地
文章浏览阅读1k次。@新建groovy-maven工程(一)#一、写在前面ngrinder脚本页面,可以支持简单的post或get请求,填入url、参数等信息即可完成脚本创建,但是后续脚本的增强(如参数化等)需要自己手写代码完成,其他请求脚本(如java请求)也需要自己手写代码,由于在ngrinder脚本页面,没有语法校验,也无法自动下载依赖jar包,十分不方便。幸好ngrinder在脚本页面,提供了可新建gro..._new groovy project
戴尔服务器修改分辨率,dell显示器怎么设置分辨率-程序员宅基地
文章浏览阅读4.2k次。显示器的概念还没有统一的说法,但对其认识却大都相同,顾名思义它应该是将一定的电子文件通过特定的传输设备显示到屏幕上再反射到人眼的一种显示工具。下面是学习啦小编带来的关于dell显示器怎么设置分辨率的内容,欢迎阅读!dell显示器怎么设置分辨率?CRT显示器最佳分辨率的设置方法:针对CRT显示器,通过将其设置为最高分辨率将是最明智的选择。同时当发现屏幕出现晃动的现象时,通过可以将“刷新率”设置高一些..._服务器分辨率怎么提高