数仓日记 - 数据采集平台_jdbc2console.sh-程序员宅基地
技术标签: flume项目经验 各集群shell脚本启动 Kafka项目经验 大数据 Sqoop项目经验
世间万事,风云变幻,苍黄翻覆。纵使波谲云诡,但制心一处,便无事不办
目录
一、埋点数据生成模块
1. 事件日志格式及字段含义
2. 启动日志格式及字段含义
3. 说明
二、采集平台准备
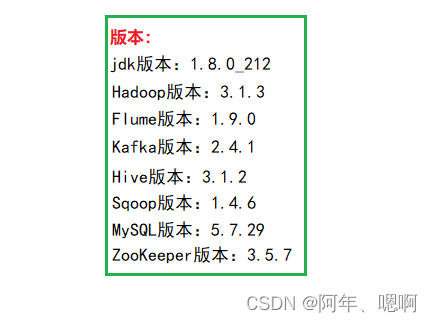
1. 框架版本选型
2. 集群部署规划
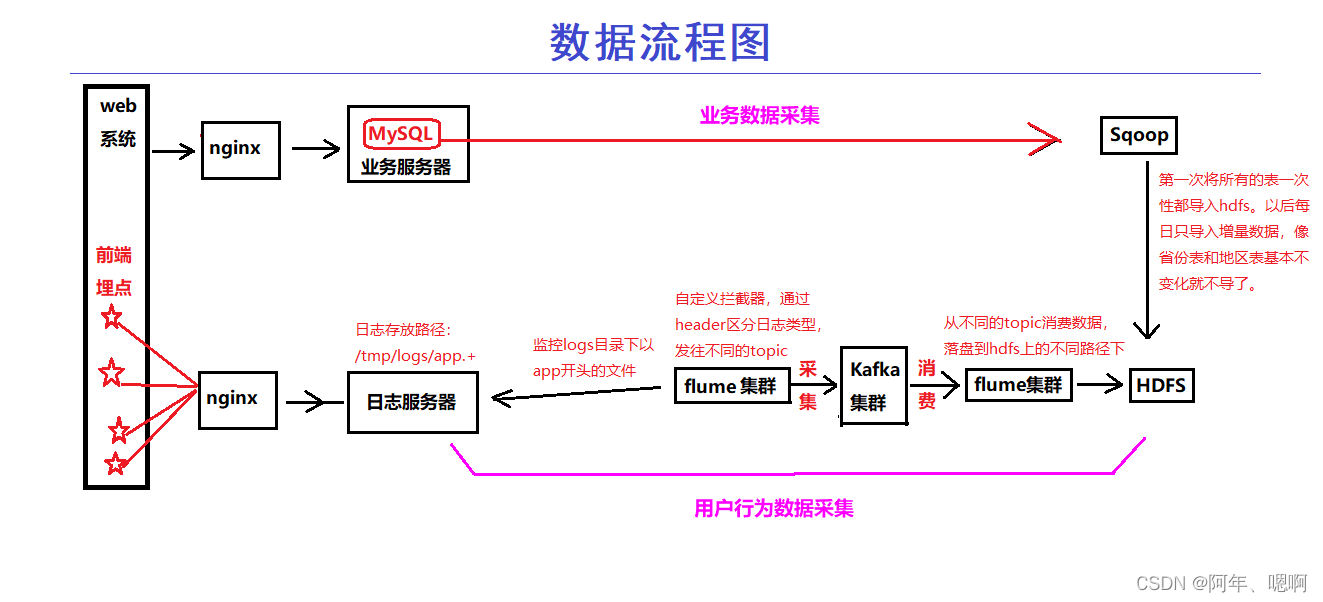
3. 数据流程图
三、用户行为数据采集模块
1. 环境准备
2. JDK安装
3. Hadoop安装
• 项目经验之HDFS存储多目录
• 项目经验之支持LZO压缩配置
• 项目经验之LZO创建索引
• 项目经验之Hadoop基准测试
• 项目经验之Hadoop参数调优
4. Zookeeper安装
5. 日志生成
6. 采集日志Flume
7. kafka安装
• 项目经验之Kafka压力测试
• 项目经验之Kafka机器数量计算
8. Flume消费Kafka数据到HDFS
• 项目经验之Flume组件详解
• 项目经验之Flume内存优化
四、业务数据采集模块
1. MySQL安装
2. Sqoop安装
3. 业务数据生成
4. 业务数据导入HDFS
• 项目经验
5. Hive安装部署
一、埋点数据生成模块
1.事件日志格式:
1667544719686 | {
"cm": {
//公共字段
"ln": "-35.5", // (double) lng经度
"sv": "V2.3.0", // (String) sdkVersion sdk版本
"os": "8.2.6", // (String) Android系统版本
"g": "[email protected]", // (String) gmail
"mid": "994", // (String) 设备唯一标识
"nw": "3G", // (String) 网络模式
"l": "pt", // (String) language系统语言
"vc": "13", // (String) versionCode,程序版本号
"hw": "640*1136", // (String) heightXwidth,屏幕宽高
"ar": "MX", // (String) area区域
"uid": "994", // (String) 用户标识
"t": "1667508769684", // (String) 客户端日志产生时的时间
"la": "-34.3", // (double) lat 纬度
"md": "sumsung-15", // (String) model手机型号
"vn": "1.0.1", // (String) versionName,程序版本名
"ba": "Sumsung", // (String) brand手机品牌
"sr": "G" // (String) 渠道号,应用从哪个渠道来的。
},
"ap": "app", //项目数据来源 app pc
"et": [{
//事件
"ett": "1667527012297", //客户端事件产生时间
"en": "ad", //事件名称
"kv": {
//事件结果,以key-value形式自行定义
"activityId": "1",
"displayMills": "96469",
"entry": "2",
"action": "1",
"contentType": "0"
}
}, {
"ett": "1667504023634",
"en": "notification",
"kv": {
"ap_time": "1667542746000",
"action": "2",
"type": "3",
"content": ""
}
}, {
"ett": "1667514981776",
"en": "active_background",
"kv": {
"active_source": "3"
}
}, {
"ett": "1667500071675",
"en": "error",
"kv": {
//errorDetail 错误详情
"errorDetail": "java.lang.NullPointerException\\n at cn.lift.appIn.web.AbstractBaseController.validInbound(AbstractBaseController.java:72)\\n at cn.lift.dfdf.web.AbstractBaseController.validInbound",
//errorBrief 错误摘要
"errorBrief": "at cn.lift.dfdf.web.AbstractBaseController.validInbound(AbstractBaseController.java:72)"
}
}, {
"ett": "1667515331033",
"en": "favorites",
"kv": {
"course_id": 2,
"id": 0,
"add_time": "1667486897821",
"userid": 4
}
}]
}
事件类型:商品列表页(loading)、商品点击(display)、商品详情页(newsdetail)、广告(ad)、消息通知(notification)、用户后台活跃(active_background)、评论(comment)、收藏(favorites)、点赞(praise)、错误(error)
2.启动日志格式:
{
"action": "1", //状态:成功=1 失败=2
"ar": "MX",
"ba": "Sumsung",
"detail": "", //失败码(没有则上报空)
"en": "start", //日志类型start
"entry": "3", //入口: push=1,widget=2,icon=3,notification=4, lockscreen_widget =5
"extend1": "", //失败的message(没有则上报空)
"g": "[email protected]",
"hw": "640*960",
"l": "es",
"la": "-4.7",
"ln": "-45.0",
"loading_time": "16", //加载时长:计算下拉开始到接口返回数据的时间,(开始加载报0,加载成功或加载失败才上报时间)
"md": "sumsung-13",
"mid": "995",
"nw": "3G",
"open_ad_type": "2", //开屏广告类型: 开屏原生广告=1, 开屏插屏广告=2
"os": "8.1.7",
"sr": "M",
"sv": "V2.6.4",
"t": "1667455282969",
"uid": "995",
"vc": "18",
"vn": "1.0.2"
}
3.说明:
用Java生成上述格式的日志,并存储在
/tmp/logs/目录下,日志文件名为:
app-年-月-日.log,单个日志文件最大大小为10MB,日志默认保留30天,30天后自动删除。
程序已打包,上传到资源。
logcollector-1.0-SNAPSHOT.jar
logcollector-1.0-SNAPSHOT-jar-with-dependencies.jar
二、采集平台准备
1. 框架版本选型
2. 集群部署规划

3. 数据流程图
三、用户行为数据采集模块
1. 环境准备
-
安装必要环境
sudo yum install -y epel-release sudo yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git -
修改静态IP
sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33 将BOOTPROTO修改为static BOOTPROTO=static 最后一行ONBOOT改为yes ONBOOT=yes 添加如下内容: IPADDR=填IP地址 NETMASK=子网掩码 GATEWAY=网关IP DNS1=8.8.8.8 DNS2=8.8.4.4 -
修改主机名及映射
修改主机名:将文件内容修改为主机名 sudo vim /etc/hostname 添加映射: sudo vim /etc/hosts 添加如下内容: 192.168.176.101 hadoop101 192.168.176.102 hadoop102 192.168.176.103 hadoop103 -
关闭防火墙
关闭防火墙: sudo systemctl stop firewalld 永久关闭防火墙: sudo systemctl disable firewalld 查看防火墙状态: systemctl status firewalld -
创建普通用户
sudo useradd atguigu sudo passwd atguigu -
重启虚拟机后,配置普通用户具有root权限。sudo vim /etc/sudoers 在root所在的行(100行)后,添加一行 ## Allow root to run any commands anywhere root ALL=(ALL) ALL atguigu ALL=(ALL) NOPASSWD:ALL -
在
/opt目录下创建软件安装文件夹和存放安装包的文件夹并修改所有者。sudo mkdir module sudo mkdir software sudo mkdir /opt/module /opt/software sudo chown atguigu:atguigu /opt/module /opt/software
2. JDK安装
-
解压JDK并配置环境变量
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/ sudo vim /etc/profile.d/my_env.sh 添加如下内容: #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin -
测试JDK是否安装成功
java -version看到如下结果就证明安装成功:
java version "1.8.0_212" Java(TM) SE Runtime Environment (build 1.8.0_212-b10) Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
3. Hadoop安装
-
解压
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ -
添加环境变量
sudo vim /etc/profile.d/my_env.sh 添加如下内容: ##HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin -
让修改后的文件生效
source /etc/profile.d/my_env.sh -
测试是否安装成功
hadoop version出现如下结果证明安装成功:
Hadoop 3.1.3 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579 Compiled by ztang on 2019-09-12T02:47Z Compiled with protoc 2.5.0 From source with checksum ec785077c385118ac91aadde5ec9799 This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar -
集群配置
core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <property> <name>hadoop.proxyuser.atguigu.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.atguigu.groups</name> <value>*</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>atguigu</value> </property> <property> <name>io.compression.codecs</name> <value> org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.SnappyCodec, com.hadoop.compression.lzo.LzoCodec, com.hadoop.compression.lzo.LzopCodec </value> </property> <property> <name>io.compression.codec.lzo.class</name> <value>com.hadoop.compression.lzo.LzoCodec</value> </property> </configuration>hdfs-site.xml<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop103:9868</value> </property> <!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>yarn-site.xml<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop102</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>workershadoop101 hadoop102 hadoop103
项目经验之HDFS存储多目录
当HDFS存储空间紧张的时候,需要对DataNode进行磁盘扩展
1)在DataNode节点增加磁盘并进行挂载
挂载:fdisk -l | grep FAT32
在mnt目录下建立挂载目录:mkdir /mnt/usb
挂载:mount -t vfat /dev/sdb1 /mnt/usb/
卸载:umount /mnt/usb/
2)在hdfs-site.xml文件中配置多目录,注意新挂载磁盘的访问权限问题
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///hd2/dfs/data2,file:///hd3/dfs/data3,file:///hd4/dfs/data4</value>
</property>
3)增加磁盘后,保证每个目录数据均衡
开启数据均衡命令:
bin/start-balancer.sh -threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
停止数据均衡:
bin/stop-balancer.sh
项目经验之支持LZO压缩配置
1)hadoop本身并不支持lzo压缩,故需要使用twitter提供的hadoop-lzo开源组件。hadoop-lzo需依赖hadoop和lzo进行编译。
2)将编译好后的hadoop-lzo-0.4.20.jar 放入hadoop-3.1.3/share/hadoop/common/
3)同步hadoop-lzo-0.4.20.jar到hadoop102、hadoop103
4)core-site.xml增加配置支持LZO压缩
<configuration>
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
</configuration>
5)同步core-site.xml到hadoop102、hadoop103
6)启动及查看集群
项目经验之LZO创建索引
1)创建LZO文件的索引,LZO压缩文件的可切片特性依赖于其索引,故我们需要手动为LZO压缩文件创建索引。若无索引,则LZO文件的切片只有一个。
hadoop jar /path/to/your/hadoop-lzo.jar com.hadoop.compression.lzo.DistributedLzoIndexer big_file.lzo
2)测试
(1)将bigtable.lzo(150M)上传到集群的根目录
(2)执行wordcount程序
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output1
(3)对上传的LZO文件建索引
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /input/bigtable.lzo
(4)再次执行WordCount程序
项目经验之Hadoop基准测试
1) 测试HDFS写性能
测试内容:向HDFS集群写10个128M的文件
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
2)测试HDFS读性能
测试内容:读取HDFS集群10个128M的文件
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
测试生成的数据在HDFS中存在,要记得删除,不然占地方。
3)使用Sort程序评测MapReduce
(1)使用RandomWriter来产生随机数,每个节点运行10个Map任务,每个Map产生大约1G大小的二进制随机数
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar randomwriter random-data
(2)执行Sort程序
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar sort random-data sorted-data
(3)验证数据是否真正排好序了
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-data
项目经验之Hadoop参数调优
1)HDFS参数调优hdfs-site.xml
dfs.namenode.handler.count=20 * log2(Cluster Size),比如集群规模为8台时,此参数设置为60
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。对于大集群或者有大量客户端的集群来说,通常需要增大参数dfs.namenode.handler.count的默认值10。设置该值的一般原则是将其设置为集群大小的自然对数乘以20,即20logN,N为集群大小。
2)YARN参数调优yarn-site.xml
(1)情景描述:总共7台机器,每天几亿条数据,数据源->Flume->Kafka->HDFS->Hive
面临问题:数据统计主要用HiveSQL,没有数据倾斜,小文件已经做了合并处理,开启的JVM重用,而且IO没有阻塞,内存用了不到50%。但是还是跑的非常慢,而且数据量洪峰过来时,整个集群都会宕掉。基于这种情况有没有优化方案。
(2)解决办法:
内存利用率不够。这个一般是Yarn的2个配置造成的,单个任务可以申请的最大内存大小,和Hadoop单个节点可用内存大小。调节这两个参数能提高系统内存的利用率。
(a)yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。
(b)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
备注:mapreduce.map.memory.mb一个MapTask可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。
mapreduce.reduce.memory.mb一个ReduceTask可使用的资源上限(单位:MB),默认为1024。如果ReduceTask实际使用的资源量超过该值,则会被强制杀死。
单任务内存怎么调:根据输入端数据的大小
128m数据对应 1g内存(maptask)
比如,有1G数据,那么1G/128m=8 ,也就是需要8个maptask = 8g,就将yarn.scheduler.maximum-allocation-mb设置为8;如果2G数据那就是单任务需要16G
3)Hadoop宕机
(1)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)
(2)如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。或者修改flume的bathsize大小,默认一次拉取100个/s,快的话就减小,控制写入过快,导致的宕机。再不行,就加机器。
4. Zookeeper安装
-
zookeeper群起脚本
zk.sh
#!/bin/bash case $1 in "start"){ for i in hadoop101 hadoop102 hadoop103 do echo "--------------- $i zookeeper启动---------------" ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start" done };; "stop"){ for i in hadoop101 hadoop102 hadoop103 do echo "--------------- $i zookeeper停止---------------" ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop" done };; "status"){ for i in hadoop101 hadoop102 hadoop103 do echo "--------------- $i zookeeper状态---------------" ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status" done };; esac -
增加执行权限
chmod 777 zk.sh -
Zookeeper集群启动、停止
集群启动: zk.sh start 集群停止: zk.sh stop
5. 日志生成
说明:如果jar包用到的环境在集群上有,那就选不带环境的,如果没有,那就选带环境的将jar包上传到集群
-
第一种执行方式:
这种执行方式会把运行日志打印到控制台 java -classpath logcollector-1.0-SNAPSHOT-jar-with-dependencies.jar com.qcln.appclient.AppMain 这种执行方式会把运行日志收集起来,存到当前目录的test.log文件中 java -classpath logcollector-1.0-SNAPSHOT-jar-with-dependencies.jar com.qcln.appclient.AppMain > /opt/module/test.log运行后生成的日志文件在
/tmp/logs目录下,文件名字为app-2022-10-02.log,这个都在代码的logback.xml中配置的 -
第二种执行方式:
java -jar log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar >/opt/module/test.log这种执行方式的前提是,你解压后看你的jar包META-INF/MANIFEST.MF文件中Main-Class是否有全类名,如果有那就可以,否则只能用第一种方式指定主类名
-
企业中一般用这种写法:java -jar log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar >/dev/null 2>&1标准输入0:从键盘获得输入 /proc/self/fd/0
标准输出1:输出到屏幕(即控制台) /proc/self/fd/1
错误输出2:输出到屏幕(即控制台) /proc/self/fd/2
这种写法的含义是:往黑洞里面扔,把错误输出2扔到标准输出1里面,再把1扔到黑洞里面,他是下面这种的简写:
java -jar log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar 2>/dev/null 1>/dev/null集群日志生成启动脚本#!/bin/bash for i in hadoop101 hadoop102 do echo "---------- $i 生成日志 ----------" ssh $i "java -jar /opt/module/logcollector-1.0-SNAPSHOT-jar-with-dependencies.jar >/dev/null 2>&1" done集群时间同步修改脚本(仅作测试用)注意:该脚本仅仅是测试使用,生产环境勿用!!!
#!/bin/bash for i in hadoop101 hadoop102 hadoop103 do echo "---------- $i ----------" ssh -t $i "sudo date -s $1" done说明 -t参数是解决sudo报错:没有终端存在,且未指定askpass程序。用的,含义是创建一个终端
集群同步执行命令脚本#!/bin/bash for i in hadoop101 hadoop102 hadoop103 do echo "---------- $i ----------" ssh $i "$*" done
先用时间同步修改脚本统一把集群时间修改为2020-xx-xx,然后运行日志生成脚本生成当天的用户行为数据
6. 采集日志Flume
Flume安装
-
解压、重命名
tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/ mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume -
将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
rm /opt/module/flume/lib/guava-11.0.2.jar -
将flume/conf下的flume-env.sh.template文件修改为flume-env.sh,并配置flume-env.sh文件
mv flume-env.sh.template flume-env.sh vim flume-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_212
类型选择
1)Source
(1)source选择 TailDir Source,他的优点是:支持断点续传、多目录。flume1.6后支持
(2)batchSize大小如何设置?这个就是Kafka读取数据的数据,当Event1k左右的时候,500-1000合适(默认为100)
2)Channel
采用Kafka Channel,省去了Sink,提高了效率。KafkaChannel数据存储在Kafka里面,所以数据是存储在磁盘中
Flume1.7以前Kafka Channel很少有人使用,因为 每一行数据都有个前缀(topic+数据内容),而parseAsFlumeEvent 设置为false去不掉这个前缀,但是1.7之后就修改好了
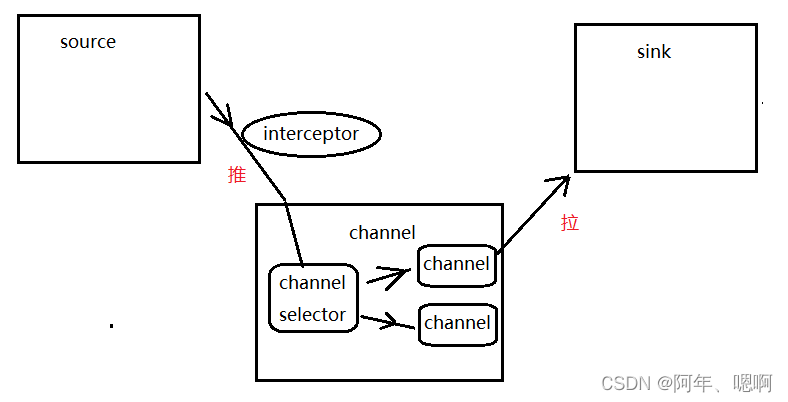
复习回忆:Channel Selectors,可以让不同的项目日志通过不同的Channel到不同的Sink中去。官方文档上Channel Selectors有两种类型:Replicating Channel Selector (default)和Multiplexing Channel selector
这两种selector的区别是:Replicating 会将source过来的events发往所有channel,而Multiplexing可以选择该发往哪些channel 。
flume配置文件file-flume-kafka.conf
a1.sources=r1
a1.channels=c1 c2
# configure source
a1.sources.r1.type = TAILDIR
# 断点续传的时候持久化到磁盘的时候的索引位置
a1.sources.r1.positionFile = /opt/module/flume/test/log_position.json
# 支持多文件目录的读取,定义第一个目录f1
a1.sources.r1.filegroups = f1
# .+是正则表达式,.是任意单个字符,+是前面的子表达式出现一次或多次
a1.sources.r1.filegroups.f1 = /tmp/logs/app.+
# 添加一个头部,为文件的绝对路径
a1.sources.r1.fileHeader = true
# 这个source发往c1和c2
a1.sources.r1.channels = c1 c2
#interceptor
# 定义两个拦截器,需要根据用户的逻辑自己定义
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.LogETLInterceptor$Builder
a1.sources.r1.interceptors.i2.type = com.atguigu.flume.interceptor.LogTypeInterceptor$Builder
a1.sources.r1.selector.type = multiplexing
# 一个Event是有header和body,就是靠头区分数据发往那个channel
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
# configure channel
# channel c1的配置,topic类型是start
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_start
a1.channels.c1.parseAsFlumeEvent = false
# 定义一个消费者组
a1.channels.c1.kafka.consumer.group.id = flume-consumer
# channel c2的配置,topic类型是event
a1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c2.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092
a1.channels.c2.kafka.topic = topic_event
a1.channels.c2.parseAsFlumeEvent = false
# 定义一个消费者组
a1.channels.c2.kafka.consumer.group.id = flume-consumer
flume自定义拦截器步骤:定义类、实现interceptor接口、重写四个方法(初始化、单Event、多Event、关闭)
Java知识:将字节数组转换成字符串:
String s = new String(byte[],Charset.forName("UTF-8"));
ETL拦截器
LogETLInterceptor类
package com.qcln.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
public class LogETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 将event 转换为string 方便处理
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
if(log.contains("start")){
// 清洗启动日志
if(LogUtils.vaildateStart(log)){
return event;
}
}else{
// 清洗事件日志
if(LogUtils.vaildateEvent(log)){
return event;
}
}
return null;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> interceptors = new ArrayList<>();
// 遍历event
for (Event event : events) {
// 调用上面的单event方法进行清洗
Event intercept1 = intercept(event);
if(intercept1 != null){
interceptors.add(intercept1);
}
}
return interceptors;
}
@Override
public void close() {
}
// 静态内部类
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
// new 一个自己
return new LogETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
LogUtils类
package com.qcln.flume.interceptor;
import org.apache.commons.lang.math.NumberUtils;
public class LogUtils {
public static boolean vaildateStart(String log) {
if(log == null){
return false;
}
// 是否是大括号开头和结尾,不是的话就干掉
if(!log.trim().startsWith("{") || !log.trim().endsWith("}")){
return false;
}
return true;
}
public static boolean vaildateEvent(String log) {
if(log == null){
return false;
}
// 时间 | json
// 切割
String[] logConents = log.split("\\|"); //正则表达式中 \| 表示 | ,所以要以|分隔的话就转义一下 \\|
// 判断长度
if(logConents.length != 2){
return false;
}
// 判断服务器时间 长度和都是数字,工具类,不等于13位和不全是数字就干掉
if(logConents[0].length() != 13 || !NumberUtils.isDigits(logConents[0])){
return false;
}
// 判断json完整性
if(!logConents[1].trim().startsWith("{") || !logConents[1].trim().endsWith("}")){
return false;
}
return true;
}
}
日志类型拦截器
LogTypeInterceptor类
package com.qcln.flume.interceptor;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class LogTypeInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 去除body数据
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
// 取出header
Map<String, String> headers = event.getHeaders();
if(log.contains("start")){
headers.put("topic","topic_start");
}else{
headers.put("topic","topic_event");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> resultEvents = new ArrayList<>();
for (Event event : events) {
// 不用判断因为只是添加了一个标记
resultEvents.add(event);
}
return resultEvents;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new LogTypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
完成后打包上传到服务器,flume目录下的lib包下。
注意配置文件中拦截器的定义和选择器的定义,一定要和代码中的相对应
7. kafka安装
kafka安装
- 解压、重命名
tar -zxvf kafka_2.11-2.4.1.tgz -C /opt/module/ mv kafka_2.11-2.4.1/ kafka - 在/opt/module/kafka目录下创建logs文件夹
mkdir logs - 修改配置文件
cd config/ vim server.properties 修改以下内容: #broker的全局唯一编号,不能重复 broker.id=0 #增加删除topic功能 delete.topic.enable=true #kafka运行日志存放的路径 log.dirs=/opt/module/kafka/logs #配置连接Zookeeper集群地址 zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181/kafka - 配置环境变量
sudo vim /etc/profile.d/my_env.sh 添加如下内容: #KAFKA_HOME export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/bin 刷新使环境变量生效: source /etc/profile.d/my_env.sh
kafka群起脚本
kf.sh
-
#!/bin/bash case $1 in "start"){ for i in hadoop101 hadoop102 hadoop103 do echo "---------- $i Kafka启动----------" ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties" done };; "stop"){ for i in hadoop101 hadoop102 hadoop103 do echo "---------- $i Kafka停止----------" ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh" done };; esac
先启动zookeeper,然后启动Kafka。然后在Hadoop101上执行命令bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf启动flume,然后执行命令bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --from-beginning --topic topic_start启动一个Kafka消费者,消费topic_start中的数据。最后执行日志生成启动脚本生成日志,可以看到Kafka消费到了topic_start中的数据。
zk.sh
bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf
bin/kafka-console-consumer.sh --bootstrap-server hadoop101:9092 --from-beginning --topic topic_start
flume群起脚本
f1.sh
-
#!/bin/bash case $1 in "start"){ for i in hadoop101 hadoop102 do echo "---------- 启动 $i 采集flume" ssh $i "nohup /opt/module/flume-1.9.0/bin/flume-ng agent --conf-file /opt/module/flume-1.9.0/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume-1.9.0/test1 2>&1 &" done };; "stop"){ for i in hadoop101 hadoop102 do echo "---------- 停止 $i 采集flume" ssh $i "ps -ef | grep flume | grep -v grep | awk '{print \$2}' | xargs -n1 kill -9" done };; esac备注:
grep -v grep:意思是去掉grep那个进程awk ‘{print $2}’:取出第二列,awk的默认分割符就是空格,也可以修改,反斜线的含义是转义,因为在shell中$2含义是第二个参数,而这里的含义是前面输出结果的第二列,所以需要转义xargs -n1 kill -9:xargs将前面的运行结果作为下一个命令的参数传递过去,-n1是因为有时候前面截取到的那一列有空行,而我们只想要第一行,所以加个-n1
项目经验之Kafka压力测试
使用官方自带的脚本(kafka-consumer-perf-test.sh、kafka-producer-perf-test.sh)
-
测试命令(往Kafka写):
kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop101:9092,hadoop102:9092,hadoop103:9092说明:
record-size是一条信息有多大,单位是字节。num-records是总共发送多少条信息。
throughput 是每秒多少条信息,设成-1,表示不限流,可测出生产者最大吞吐量。

-
测试命令(从Kafka读):
bin/kafka-consumer-perf-test.sh --broker-list hadoop101:9092,hadoop102:9092,hadoop103:9092 --topic test --fetch-size 10000 --messages 10000000 --threads 1参数说明:
–zookeeper 指定zookeeper的链接信息–topic 指定topic的名称
–fetch-size 指定每次fetch的数据的大小
–messages 总共要消费的消息个数

项目经验之Kafka机器数量计算
Kafka机器数量(经验公式)=2*(峰值生产速度副本数/100)+1
先拿到峰值生产速度,再根据设定的副本数,就能预估出需要部署Kafka的数量。
比如我们的峰值生产速度是50M/s。副本数为2。
Kafka机器数量=2(50*2/100)+ 1=3台
8. Flume消费Kafka数据到HDFS
flume配置-channel技术选型
(1)file Channel基于磁盘速度慢可靠性高100万event
(2)memory channel基于内存速度快可靠性差100个event
生产环境怎么选择?
如果是普通的日志﹐追求效率,丢一点数据不影响大局,选memory channel
如果是金融的数据或者和钱有关系的数据,数据比较重要不允许丢,只能牺牲速度换取安全性,选file Channel
kafka-flume-hdfs.conf配置文件
因为用户行为日志分为两类,一类启动日志,一类事件日志,要分别存到HDFS上的不同路径下,所以要两个source、channel、sinks,分别采集启动日志和事件日志。在这个项目中我们选用KafkaSource、file channel、hdfs sink。
## 组件
a1.sources=r1 r2
a1.channels=c1 c2
a1.sinks=k1 k2
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
# sources每次拉取多少个event
a1.sources.r1.batchSize = 5000
# 延迟时间,条数没够,时间够了也会拉取
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics=topic_start
## source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092
a1.sources.r2.kafka.topics=topic_event
## channel1
a1.channels.c1.type = file
# 检查点
a1.channels.c1.checkpointDir = /opt/module/flume-1.9.0/checkpoint/behavior1
# 数据存储目录
a1.channels.c1.dataDirs = /opt/module/flume-1.9.0/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## channel2
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /opt/module/flume-1.9.0/checkpoint/behavior2
a1.channels.c2.dataDirs = /opt/module/flume-1.9.0/data/behavior2/
a1.channels.c2.maxFileSize = 2146435071
a1.channels.c2.capacity = 1000000
a1.channels.c2.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d
# 存储文件的前缀
a1.sinks.k1.hdfs.filePrefix = logstart-
##sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
## 不要产生大量小文件
# 10秒滚动下一个文件,企业中常用3600,一个小时
a1.sinks.k1.hdfs.rollInterval = 10
# 当文件的大小到达128m的时候滚动
a1.sinks.k1.hdfs.rollSize = 134217728
# 不按照event的个数滚动
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
## 控制输出文件是原生文件。
# 是否启用压缩流
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
# 压缩的方式 lzo plus
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2
启动消费flume命令:
bin/flume-ng agent --conf-file /opt/module/flume-1.9.0/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE
消费flume启动脚本
f2.sh
后续启动消费flume总不能每次都敲那么长一个命令吧,直接搞个脚本一键启动停止,一劳永逸。
#! /bin/bash
case $1 in
"start"){
for i in hadoop103
do
echo " --------启动 $i 消费flume-------"
ssh $i "nohup /opt/module/flume-1.9.0/bin/flume-ng agent --conf-file /opt/module/flume-1.9.0/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume-1.9.0/log.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop103
do
echo " --------停止 $i 消费flume-------"
ssh $i "ps -ef | grep kafka-flume-hdfs | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
done
};;
esac
项目经验之Flume组件详解
1)FileChannel和MemoryChannel区别
Memory Channel传输数据速度更快,但因为数据保存在JVM的堆内存中,Agent进程挂掉会导致数据丢失,适用于对数据质量要求不高的需求。
File Channel传输速度相对于Memory慢,但数据安全保障高,Agent进程挂掉也可以从失败中恢复数据。
2)File Channel优化
通过配置dataDirs指向多个路径,每个路径对应不同的硬盘,增大Flume吞吐量。
官方说明如下:
Comma separated list of directories for storing log files. Using multiple directories on separate disks can improve file channel peformance
checkpointDir和backupCheckpointDir也尽量配置在不同硬盘对应的目录中,保证checkpoint坏掉后,可以快速使用backupCheckpointDir恢复数据
3)Sink:HDFS Sink
(1)HDFS存入大量小文件,有什么影响?
元数据层面:每个小文件都有一份元数据,其中包括文件路径,文件名,所有者,所属组,权限,创建时间等,这些信息都保存在Namenode内存中。所以小文件过多,会占用Namenode服务器大量内存,影响Namenode性能和使用寿命
计算层面:默认情况下MR会对每个小文件启用一个Map任务计算,非常影响计算性能。同时也影响磁盘寻址时间。
(2)HDFS小文件处理
官方默认的这三个参数配置写入HDFS后会产生小文件,hdfs.rollInterval、hdfs.rollSize、hdfs.rollCount
基于以上hdfs.rollInterval=3600,hdfs.rollSize=134217728,hdfs.rollCount =0几个参数综合作用,效果如下:
(1)文件在达到128M时会滚动生成新文件
(2)文件创建超3600秒时会滚动生成新文件
(3)hdfs.rollCount=0是不启用的意思,因为每个event的大小不一样,不好控制。
项目经验之Flume内存优化
1)问题描述:如果启动消费Flume抛出如下异常
ERROR hdfs.HDFSEventSink: process failed
java.lang.OutOfMemoryError: GC overhead limit exceeded
2)解决方案步骤:
-
在hadoop101服务器的/opt/module/flume/conf/flume-env.sh文件中增加如下配置
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"-Xms:启动flume所需要的内存,内存上限是100m
-Xmx:flume正常运行后,能使用的内存上限是2000m -
同步配置到hadoop102、hadoop103服务器
[atguigu@hadoop102 conf]$ xsync flume-env.sh -
Flume内存参数设置及优化
JVM heap一般设置为4G或更高,部署在单独的服务器上(4核8线程16G内存)
-Xmx与-Xms最好设置一致,减少内存抖动带来的性能影响,如果设置不一致容易导致频繁fullgc。
-Xms表示JVM Heap(堆内存)最小尺寸,初始分配。
-Xmx 表示JVM Heap(堆内存)最大允许的尺寸,按需分配。
如果设置不一致,容易在初始化时,由于内存不够,频繁触发fullgc。
9. 采集通道启动/停止脚本
zookeeper集群启动脚本:zk.sh
flume采集集群启动脚本:f1.sh
Kafka集群启动脚本:kf.sh
flume消费集群启动脚本:f2.sh
#!/bin/bash
case $1 in
"start"){
echo " -------- 启动 集群 -------"
echo " -------- 启动 hadoop集群 -------"
/opt/module/hadoop-3.1.3/sbin/start-dfs.sh
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
#启动 Zookeeper集群
zk.sh start
sleep 6s;
#启动 Flume采集集群
f1.sh start
#启动 Kafka采集集群
kf.sh start
sleep 8s;
#启动 Flume消费集群
f2.sh start
};;
"stop"){
echo " -------- 停止 集群 -------"
#停止 Flume消费集群
f2.sh stop
#停止 Kafka采集集群
kf.sh stop
sleep 8s;
#停止 Flume采集集群
f1.sh stop
#停止 Zookeeper集群
zk.sh stop
echo " -------- 停止 hadoop集群 -------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
};;
esac
四、业务数据采集模块
1. MySQL安装
1)卸载自带的MySQL-libs
rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e --nodeps
grep -i 不区分大小写 -E 给grep增加and语义,a或b
2)将安装包和JDBC驱动上传到服务器,一共6个
01_mysql-community-common-5.7.29-1.el7.x86_64.rpm
02_mysql-community-libs-5.7.29-1.el7.x86_64.rpm
03_mysql-community-libs-compat-5.7.29-1.el7.x86_64.rpm
04_mysql-community-client-5.7.29-1.el7.x86_64.rpm
05_mysql-community-server-5.7.29-1.el7.x86_64.rpm
mysql-connector-java-5.1.48.jar
3)安装mysql依赖
sudo rpm -ivh 01_mysql-community-common-5.7.29-1.el7.x86_64.rpm
sudo rpm -ivh 02_mysql-community-libs-5.7.29-1.el7.x86_64.rpm
sudo rpm -ivh 03_mysql-community-libs-compat-5.7.29-1.el7.x86_64.rpm
4)安装mysql-client
sudo rpm -ivh 04_mysql-community-client-5.7.29-1.el7.x86_64.rpm
5)安装mysql-server
sudo rpm -ivh 05_mysql-community-server-5.7.29-1.el7.x86_64.rpm
6)启动mysql
sudo systemctl start mysqld
7)查看mysql密码
sudo cat /var/log/mysqld.log | grep password
配置MySQL
配置只要是root用户+密码,在任何主机上都能登录MySQL数据库。
1)用刚刚查到的密码进入mysql
mysql -uroot -p’password’
3)更改mysql密码策略
set global validate_password_length=4;
set global validate_password_policy=0;
4)设置简单好记的密码
set password=password("000000");
5)进入msyql库
use mysql
6)查询user表
select user, host from user;
7)修改user表,把Host表内容修改为%
update user set host="%" where user="root";
8)刷新
flush privileges;
9)退出
quit;
2. Sqoop安装
- 进入到/opt/module/sqoop/conf目录,重命名配置文件
mv sqoop-env-template.sh sqoop-env.sh
- 修改配置文件
vim sqoop-env.sh
增加如下内容
export HADOOP_COMMON_HOME=/opt/module/hadoop-3.1.3
export HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3
export HIVE_HOME=/opt/module/hive
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7
export ZOOCFGDIR=/opt/module/zookeeper-3.5.7/conf
3)拷贝JDBC驱动
因为sqoop要将MySQL中的数据导入到hdfs,所以要将MySQL驱动jar包拷贝到sqoop的lib目录下
cp mysql-connector-java-5.1.48.jar /opt/module/sqoop/lib/
4)验证Sqoop
sqoop help
出现一些Warning警告,并伴随有帮助命令的输出。
5)测试Sqoop是否能够成功连接数据库
sqoop list-databases --connect jdbc:mysql://hadoop101:3306/ --username root --password 000000
3. 业务数据生成
1)通过MySQL可视化工具连接MySQL
2)创建gmall数据库
3)运行数据库结构脚本(gmall2020-03-16.sql)
这个脚本会生成数据库的结构和一点数据
4)把gmall-mock-db-2020-03-16-SNAPSHOT.jar和 application.properties上传到服务器的/opt/module/db_log路径上
5)修改application.properties相关配置
主要是检查下jdbc链接、用户名、密码、业务数据的时间、是否重置,其他参数都已经差不多调到最优了。
logging.level.root=info
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://hadoop102:3306/gmall?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8
spring.datasource.username=root
spring.datasource.password=000000
logging.pattern.console=%m%n
mybatis-plus.global-config.db-config.field-strategy=not_null
#业务日期
mock.date=2020-03-10
#是否重置,1是重置的意思
mock.clear=1
#是否生成新用户
mock.user.count=50
#男性比例
mock.user.male-rate=20
#收藏取消比例
mock.favor.cancel-rate=10
#收藏数量
mock.favor.count=100
#购物车数量
mock.cart.count=10
#每个商品最多购物个数
mock.cart.sku-maxcount-per-cart=3
#用户下单比例
mock.order.user-rate=80
#用户从购物中购买商品比例
mock.order.sku-rate=70
#是否参加活动
mock.order.join-activity=1
#是否使用购物券
mock.order.use-coupon=1
#购物券领取人数
mock.coupon.user-count=10
#支付比例
mock.payment.rate=70
#支付方式 支付宝:微信 :银联
mock.payment.payment-type=30:60:10
#评价比例 好:中:差:自动
mock.comment.appraise-rate=30:10:10:50
#退款原因比例:质量问题 商品描述与实际描述不一致 缺货 号码不合适 拍错 不想买了 其他
mock.refund.reason-rate=30:10:20:5:15:5:5
6)生成2020-03-10日期数据
java -jar gmall-mock-db-2020-03-16-SNAPSHOT.jar
7)在配置文件application.properties中修改
mock.date=2020-03-11
mock.clear=0
8)再次执行命令,生成2020-03-11日期数据:
java -jar gmall-mock-db-2020-03-16-SNAPSHOT.jar
4. 业务数据导入HDFS
1)脚本编写
#! /bin/bash
sqoop=/opt/module/sqoop/bin/sqoop
do_date=`date -d '-1 day' +%F`
if [[ -n "$2" ]]; then
do_date=$2
fi
import_data(){
$sqoop import \
--connect jdbc:mysql://hadoop101:3306/gmall \
--username root \
--password 000000 \
--target-dir /origin_data/gmall/db/$1/$do_date \
--delete-target-dir \
--query "$2 and \$CONDITIONS" \
--num-mappers 1 \
--fields-terminated-by '\t' \
--compress \
--compression-codec lzop \
--null-string '\\N' \
--null-non-string '\\N'
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /origin_data/gmall/db/$1/$do_date
}
import_order_info(){
import_data order_info "select
id,
final_total_amount,
order_status,
user_id,
out_trade_no,
create_time,
operate_time,
province_id,
benefit_reduce_amount,
original_total_amount,
feight_fee
from order_info
where (date_format(create_time,'%Y-%m-%d')='$do_date'
or date_format(operate_time,'%Y-%m-%d')='$do_date')"
}
import_coupon_use(){
import_data coupon_use "select
id,
coupon_id,
user_id,
order_id,
coupon_status,
get_time,
using_time,
used_time
from coupon_use
where (date_format(get_time,'%Y-%m-%d')='$do_date'
or date_format(using_time,'%Y-%m-%d')='$do_date'
or date_format(used_time,'%Y-%m-%d')='$do_date')"
}
import_order_status_log(){
import_data order_status_log "select
id,
order_id,
order_status,
operate_time
from order_status_log
where date_format(operate_time,'%Y-%m-%d')='$do_date'"
}
import_activity_order(){
import_data activity_order "select
id,
activity_id,
order_id,
create_time
from activity_order
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_user_info(){
import_data "user_info" "select
id,
name,
birthday,
gender,
email,
user_level,
create_time,
operate_time
from user_info
where (DATE_FORMAT(create_time,'%Y-%m-%d')='$do_date'
or DATE_FORMAT(operate_time,'%Y-%m-%d')='$do_date')"
}
import_order_detail(){
import_data order_detail "select
od.id,
order_id,
user_id,
sku_id,
sku_name,
order_price,
sku_num,
od.create_time
from order_detail od
join order_info oi
on od.order_id=oi.id
where DATE_FORMAT(od.create_time,'%Y-%m-%d')='$do_date'"
}
import_payment_info(){
import_data "payment_info" "select
id,
out_trade_no,
order_id,
user_id,
alipay_trade_no,
total_amount,
subject,
payment_type,
payment_time
from payment_info
where DATE_FORMAT(payment_time,'%Y-%m-%d')='$do_date'"
}
import_comment_info(){
import_data comment_info "select
id,
user_id,
sku_id,
spu_id,
order_id,
appraise,
comment_txt,
create_time
from comment_info
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_order_refund_info(){
import_data order_refund_info "select
id,
user_id,
order_id,
sku_id,
refund_type,
refund_num,
refund_amount,
refund_reason_type,
create_time
from order_refund_info
where date_format(create_time,'%Y-%m-%d')='$do_date'"
}
import_sku_info(){
import_data sku_info "select
id,
spu_id,
price,
sku_name,
sku_desc,
weight,
tm_id,
category3_id,
create_time
from sku_info where 1=1"
}
import_base_category1(){
import_data "base_category1" "select
id,
name
from base_category1 where 1=1"
}
import_base_category2(){
import_data "base_category2" "select
id,
name,
category1_id
from base_category2 where 1=1"
}
import_base_category3(){
import_data "base_category3" "select
id,
name,
category2_id
from base_category3 where 1=1"
}
import_base_province(){
import_data base_province "select
id,
name,
region_id,
area_code,
iso_code
from base_province
where 1=1"
}
import_base_region(){
import_data base_region "select
id,
region_name
from base_region
where 1=1"
}
import_base_trademark(){
import_data base_trademark "select
tm_id,
tm_name
from base_trademark
where 1=1"
}
import_spu_info(){
import_data spu_info "select
id,
spu_name,
category3_id,
tm_id
from spu_info
where 1=1"
}
import_favor_info(){
import_data favor_info "select
id,
user_id,
sku_id,
spu_id,
is_cancel,
create_time,
cancel_time
from favor_info
where 1=1"
}
import_cart_info(){
import_data cart_info "select
id,
user_id,
sku_id,
cart_price,
sku_num,
sku_name,
create_time,
operate_time,
is_ordered,
order_time
from cart_info
where 1=1"
}
import_coupon_info(){
import_data coupon_info "select
id,
coupon_name,
coupon_type,
condition_amount,
condition_num,
activity_id,
benefit_amount,
benefit_discount,
create_time,
range_type,
spu_id,
tm_id,
category3_id,
limit_num,
operate_time,
expire_time
from coupon_info
where 1=1"
}
import_activity_info(){
import_data activity_info "select
id,
activity_name,
activity_type,
start_time,
end_time,
create_time
from activity_info
where 1=1"
}
import_activity_rule(){
import_data activity_rule "select
id,
activity_id,
condition_amount,
condition_num,
benefit_amount,
benefit_discount,
benefit_level
from activity_rule
where 1=1"
}
import_base_dic(){
import_data base_dic "select
dic_code,
dic_name,
parent_code,
create_time,
operate_time
from base_dic
where 1=1"
}
case $1 in
"order_info")
import_order_info
;;
"base_category1")
import_base_category1
;;
"base_category2")
import_base_category2
;;
"base_category3")
import_base_category3
;;
"order_detail")
import_order_detail
;;
"sku_info")
import_sku_info
;;
"user_info")
import_user_info
;;
"payment_info")
import_payment_info
;;
"base_province")
import_base_province
;;
"base_region")
import_base_region
;;
"base_trademark")
import_base_trademark
;;
"activity_info")
import_activity_info
;;
"activity_order")
import_activity_order
;;
"cart_info")
import_cart_info
;;
"comment_info")
import_comment_info
;;
"coupon_info")
import_coupon_info
;;
"coupon_use")
import_coupon_use
;;
"favor_info")
import_favor_info
;;
"order_refund_info")
import_order_refund_info
;;
"order_status_log")
import_order_status_log
;;
"spu_info")
import_spu_info
;;
"activity_rule")
import_activity_rule
;;
"base_dic")
import_base_dic
;;
"first")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_province
import_base_region
import_base_trademark
import_activity_info
import_activity_order
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
;;
"all")
import_base_category1
import_base_category2
import_base_category3
import_order_info
import_order_detail
import_sku_info
import_user_info
import_payment_info
import_base_trademark
import_activity_info
import_activity_order
import_cart_info
import_comment_info
import_coupon_use
import_coupon_info
import_favor_info
import_order_refund_info
import_order_status_log
import_spu_info
import_activity_rule
import_base_dic
;;
esac
脚本说明:
1. [ -n 变量值 ] 变量值不为空返回true,否则返回false
2. [ -z 变量值 ] 变量值长度为0返回true,否则返回false
3. 如果日期是传进来的就直接赋值给他,如果没有传进来那就用当前日期减一
4. (` )反引号(esc键下方的那个键),当在脚本中需要执行一些指令并且将执行的结果赋给变量的时候需要使用“反引号”。
5. date +%F 提取时间,提取出来的格式为 年-月-日 date -d '-1 day' 系统当前时间减1
6. mr的输出目录必须不存在
--delete-target-dir \
7. 为啥全表导有where 1=1 ,因为参数2是SQL 为了语法正确 select * from 表名 where 1=1 and $CONDITIONS
--query "$2 and \$CONDITIONS" \
8. 底层是mr,map的数量1,默认四个
--num-mappers 1 \
9. 列分割符号
--fields-terminated-by '\t' \
10. 压缩流
--compress \
11. 编码方式loz压缩
--compression-codec lzop \
12. MySQL中空是null,而hive中空是\n,为了解决歧义
--null-string '\\N' \
--null-non-string '\\N'
13. 落盘到hdfs后立马生成loz索引文件
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /origin_data/gmall/db/$1/$do_date
2)修改脚本权限
chmod 777 gmall_mysql_to_hdfs.sh
3)初次导入
gmall_mysql_to_hdfs.sh first 2020-03-10
将所有的表一次性都导入HDFS
4)每日导入
gmall_mysql_to_hdfs.sh all 2020-03-11
地区表和省份表没必要每次都导入HDFS,所以第一个参数为all的时间除了地区表和省份表,将其他的表都导入HDFS
项目经验
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。
在导出数据时增加如下配置:
--input-null-string '\\N' \
--input-null-non-string '\\N'
导入数据时增加如下配置:
--null-string
--null-non-string
5. Hive安装部署
1)修改/etc/profile.d/my_env.sh,添加环境变量
sudo vim /etc/profile.d/my_env.sh
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
2)解决日志Jar包冲突,进入/opt/module/hive/lib目录
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
Hive元数据配置到MySql
1)将MySQL的JDBC驱动拷贝到Hive的lib目录下
cp /opt/software/mysql-connector-java-5.1.48.jar /opt/module/hive/lib/
2)在$HIVE_HOME/conf目录下新建hive-site.xml文件
内容如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop101:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop101:9083</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop101</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
启动Hive
1)初始化元数据库
1. 登陆MySQL
mysql -uroot -p000000
2. 新建Hive元数据库
create database metastore;
quit;
3. 初始化Hive元数据库
schematool -initSchema -dbType mysql -verbose
2)启动metastore和hiveserver2
Hive 2.x以上版本,要先启动这两个服务,否则会报错
在/opt/module/hive/bin目录编写hive服务启动脚本
hiveservices.sh内容如下:
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
mkdir -p $HIVE_LOG_DIR
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
3)添加执行权限
chmod +x hiveservices.sh
4)启动Hive后台服务
hiveservices.sh start
5)查看Hive后台服务运行情况
hiveservices.sh status
6)启动Hive客户端
bin/hive
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象