链表基础知识详解(非常详细简单易懂)-程序员宅基地
技术标签: c++ 笔记 STM32 FreeRTOS 数据结构
概述:
链表作为 C 语言中一种基础的数据结构,在平时写程序的时候用的并不多,但在操作系统里面使用的非常多。不管是RTOS还是Linux等使用非常广泛,所以必须要搞懂链表,链表分为单向链表和双向链表,单向链表很少用,使用最多的还是双向链表。单向链表懂了双向链表自然就会了。
文章目录
一、链表的概念
定义:
链表是一种物理存储上非连续,数据元素的逻辑顺序通过链表中的指针链接次序,实现的一种线性存储结构。
特点:
链表由一系列节点(链表中每一个元素称为节点)组成,节点在运行时动态生成 (malloc),每个节点包括两个部分:
一个是存储数据元素的数据域
另一个是存储下一个节点地址的指针域

图1 单向链表
链表的构成:
链表由一个个节点构成,每个节点一般采用结构体的形式组织,例如:
typedef struct student{
int num;
char name[20];
struct student *next;
}STU;链表节点分为两个域
数据域:存放各种实际的数据,如:num、score等
指针域:存放下一节点的首地址,如:next等.

图2 节点内嵌在一个数据结构中
链表的操作:
链表最大的作用是通过节点把离散的数据链接在一起,组成一个表,这大概就是链表 的字面解释了吧。 链表常规的操作就是节点的插入和删除,为了顺利的插入,通常一条链 表我们会人为地规定一个根节点,这个根节点称为生产者。通常根节点还会有一个节点计 数器,用于统计整条链表的节点个数,具体见图3中的 root_node。

图3带根节点的链表
双向链表
双向链表与单向链表的区别就是节点中有两个节点指针,分别指向前后两个节点,其 它完全一样。有关双向链表的文字描述参考单向链表小节即可,有关双向链表的示意图具体见图4

图4双向链表
链表与数组的对比
在很多公司的嵌入式面试中,通常会问到链表和数组的区别。在 C 语言中,链表与数 组确实很像,两者的示意图具体见图5,这里以双向链表为例。
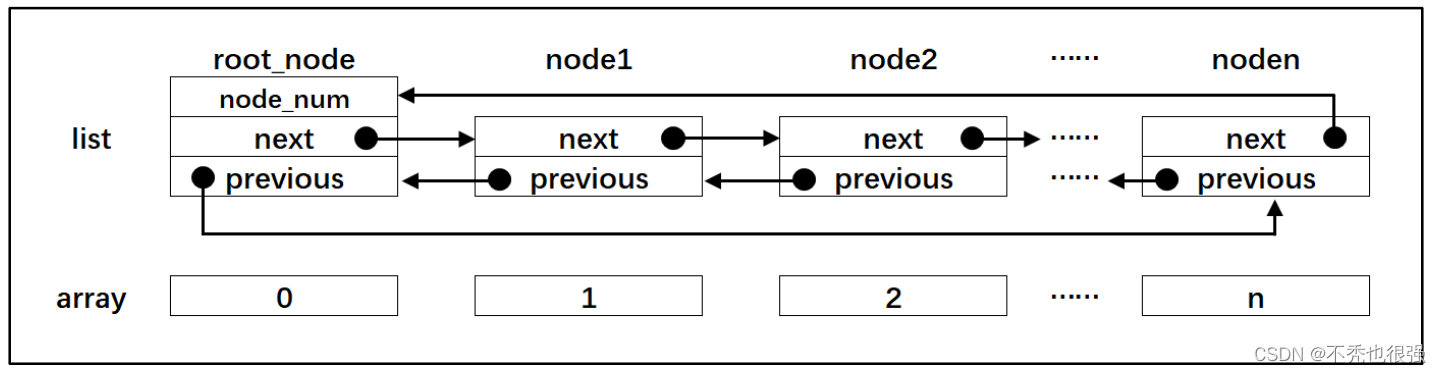 图5 链表与数组的对比
图5 链表与数组的对比
链表是通过节点把离散的数据链接成一个表,通过对节点的插入和删除操作从而实现 对数据的存取。而数组是通过开辟一段连续的内存来存储数据,这是数组和链表最大的区 别。数组的每个成员对应链表的节点,成员和节点的数据类型可以是标准的 C 类型或者是 用户自定义的结构体。数组有起始地址和结束地址,而链表是一个圈,没有头和尾之分, 但是为了方便节点的插入和删除操作会人为的规定一个根节点。
二、链表的创建
第一步:创建一个节点
![]()
第二步:创建第二个节点,将其放在第一个节点的后面(第一的节点的指针域保存第二个节点的地址)
![]()
第三步:再次创建节点,找到原本链表中的最后一个节点,接着讲最后一个节点的指针域保存新节点的地址,以此内推。
![]()
#include <stdio.h>
#include <stdlib.h>
//定义结点结构体
typedef struct student
{
//数据域
int num; //学号
int score; //分数
char name[20]; //姓名
//指针域
struct student *next;
}STU;
void link_creat_head(STU **p_head,STU *p_new)
{
STU *p_mov = *p_head;
if(*p_head == NULL) //当第一次加入链表为空时,head执行p_new
{
*p_head = p_new;
p_new->next=NULL;
}
else //第二次及以后加入链表
{
while(p_mov->next!=NULL)
{
p_mov=p_mov->next; //找到原有链表的最后一个节点
}
p_mov->next = p_new; //将新申请的节点加入链表
p_new->next = NULL;
}
}
int main()
{
STU *head = NULL,*p_new = NULL;
int num,i;
printf("请输入链表初始个数:\n");
scanf("%d",&num);
for(i = 0; i < num;i++)
{
p_new = (STU*)malloc(sizeof(STU));//申请一个新节点
printf("请输入学号、分数、名字:\n"); //给新节点赋值
scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);
link_creat_head(&head,p_new); //将新节点加入链表
}
}
三、链表的遍历
第一步:输出第一个节点的数据域,输出完毕后,让指针保存后一个节点的地址
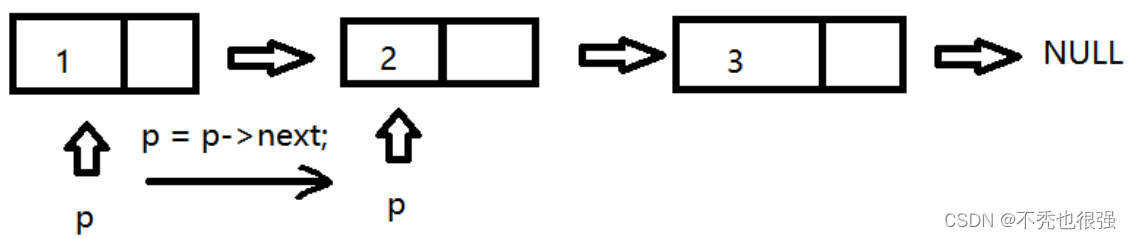
第二步:输出移动地址对应的节点的数据域,输出完毕后,指针继续后移
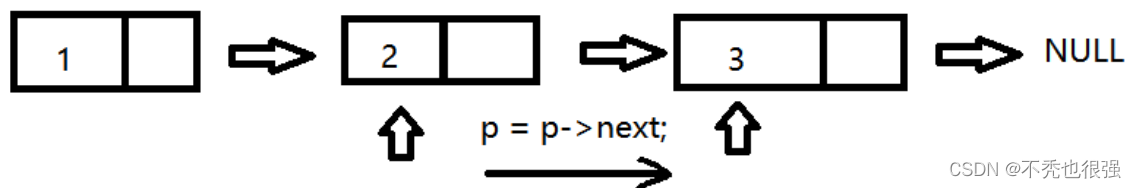
第三步:以此类推,直到节点的指针域为NULL
//链表的遍历
void link_print(STU *head)
{
STU *p_mov;
//定义新的指针保存链表的首地址,防止使用head改变原本链表
p_mov = head;
//当指针保存最后一个结点的指针域为NULL时,循环结束
while(p_mov!=NULL)
{
//先打印当前指针保存结点的指针域
printf("num=%d score=%d name:%s\n",p_mov->num,\
p_mov->score,p_mov->name);
//指针后移,保存下一个结点的地址
p_mov = p_mov->next;
}
}四、链表的释放
重新定义一个指针q,保存p指向节点的地址,然后p后移保存下一个节点的地址,然后释放q对应的节点,以此类推,直到p为NULL为止

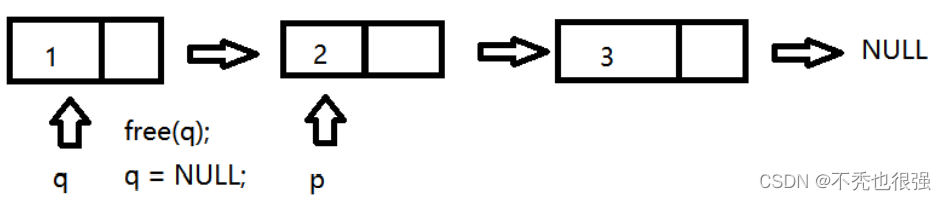
//链表的释放
void link_free(STU **p_head)
{
//定义一个指针变量保存头结点的地址
STU *pb=*p_head;
while(*p_head!=NULL)
{
//先保存p_head指向的结点的地址
pb=*p_head;
//p_head保存下一个结点地址
*p_head=(*p_head)‐>next;
//释放结点并防止野指针
free(pb);
pb = NULL;
}
}五、链表节点的查找
先对比第一个结点的数据域是否是想要的数据,如果是就直接返回,如果不是则继续查找下 一个结点,如果到达最后一个结点的时候都没有匹配的数据,说明要查找数据不存在
//链表的查找
//按照学号查找
STU * link_search_num(STU *head,int num)
{
STU *p_mov;
//定义的指针变量保存第一个结点的地址
p_mov=head;
//当没有到达最后一个结点的指针域时循环继续
while(p_mov!=NULL)
{
//如果找到是当前结点的数据,则返回当前结点的地址
if(p_mov->num == num)//找到了
{
return p_mov;
}
//如果没有找到,则继续对比下一个结点的指针域
p_mov=p_mov->next;
}
//当循环结束的时候还没有找到,说明要查找的数据不存在,返回NULL进行标识
return NULL;//没有找到
}
//按照姓名查找
STU * link_search_name(STU *head,char *name)
{
STU *p_mov;
p_mov=head;
while(p_mov!=NULL)
{
if(strcmp(p_mov->name,name)==0)//找到了
{
return p_mov;
}
p_mov=p_mov->next;
}
return NULL;//没有找到
}六、链表节点的删除
如果链表为空,不需要删除 如果删除的是第一个结点,则需要将保存链表首地址的指针保存第一个结点的下一个结点的 地址 如果删除的是中间结点,则找到中间结点的前一个结点,让前一个结点的指针域保存这个结 点的后一个结点的地址即可
//链表结点的删除
void link_delete_num(STU **p_head,int num)
{
STU *pb,*pf;
pb=pf=*p_head;
if(*p_head == NULL)//链表为空,不用删
{
printf("链表为空,没有您要删的节点");\
return ;
}
while(pb->num != num && pb->next !=NULL)//循环找,要删除的节点
{
pf=pb;
pb=pb->next;
}
if(pb->num == num)//找到了一个节点的num和num相同
{
if(pb == *p_head)//要删除的节点是头节点
{
//让保存头结点的指针保存后一个结点的地址
*p_head = pb->next;
}
else
{
//前一个结点的指针域保存要删除的后一个结点的地址
pf->next = pb->next;
}
//释放空间
free(pb);
pb = NULL;
}
else//没有找到
{
printf("没有您要删除的节点\n");
}
}七、链表中插入一个节点
链表中插入一个结点,按照原本链表的顺序插入,找到合适的位置
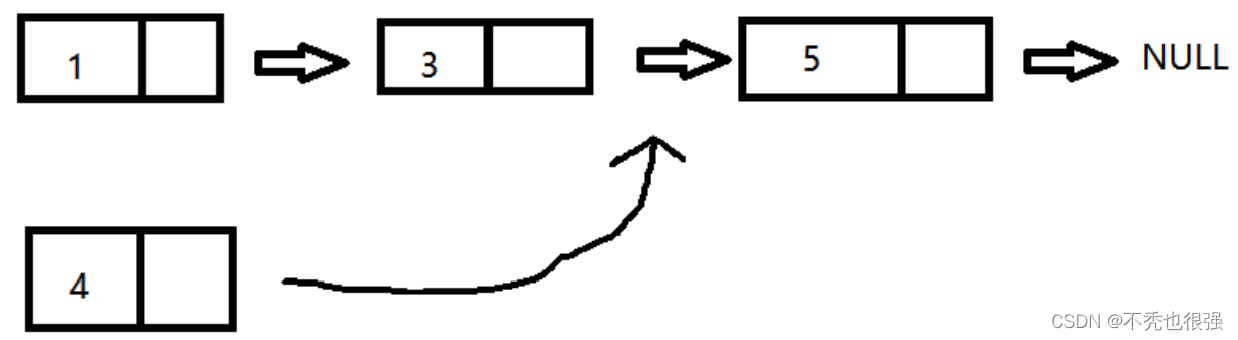
情况(按照从小到大):
如果链表没有结点,则新插入的就是第一个结点。
如果新插入的结点的数值最小,则作为头结点。
如果新插入的结点的数值在中间位置,则找到前一个,然后插入到他们中间。
如果新插入的结点的数值最大,则插入到最后。
//链表的插入:按照学号的顺序插入
void link_insert_num(STU **p_head,STU *p_new)
{
STU *pb,*pf;
pb=pf=*p_head;
if(*p_head ==NULL)// 链表为空链表
{
*p_head = p_new;
p_new->next=NULL;
return ;
}
while((p_new->num >= pb->num) && (pb->next !=NULL) )
{
pf=pb;
pb=pb->next;
}
if(p_new->num < pb->num)//找到一个节点的num比新来的节点num大,插在pb的前面
{
if(pb== *p_head)//找到的节点是头节点,插在最前面
{
p_new->next= *p_head;
*p_head =p_new;
}
else
{
pf->next=p_new;
p_new->next = pb;
}
}
else//没有找到pb的num比p_new->num大的节点,插在最后
{
pb->next =p_new;
p_new->next =NULL;
}
}八、链表排序
如果链表为空,不需要排序。
如果链表只有一个结点,不需要排序。
先将第一个结点与后面所有的结点依次对比数据域,只要有比第一个结点数据域小的,则交 换位置。
交换之后,拿新的第一个结点的数据域与下一个结点再次对比,如果比他小,再次交换,依 次类推。
第一个结点确定完毕之后,接下来再将第二个结点与后面所有的结点对比,直到最后一个结 点也对比完毕为止。
//链表的排序
void link_order(STU *head)
{
STU *pb,*pf,temp;
pf=head;
if(head==NULL)
{
printf("链表为空,不用排序\n");
return ;
}
if(head->next ==NULL)
{
printf("只有一个节点,不用排序\n");
return ;
}
while(pf->next !=NULL)//以pf指向的节点为基准节点,
{
pb=pf->next;//pb从基准元素的下个元素开始
while(pb!=NULL)
{
if(pf->num > pb->num)
{
temp=*pb;
*pb=*pf;
*pf=temp;
temp.next=pb->next;
pb->next=pf->next;
pf->next=temp.next;
}
pb=pb->next;
}
pf=pf->next;
}
}九、双向链表的创建和遍历
第一步:创建一个节点作为头节点,将两个指针域都保存NULL
第二步:先找到链表中的最后一个节点,然后让最后一个节点的指针域保存新插入节点的地址,新插入节点的两个指针域,一个保存上一个节点的地址,一个保存NULL
#include <stdio.h>
#include <stdlib.h>
//定义结点结构体
typedef struct student
{
//数据域
int num; //学号
int score; //分数
char name[20]; //姓名
//指针域
struct student *front; //保存上一个结点的地址
struct student *next; //保存下一个结点的地址
}STU;
void double_link_creat_head(STU **p_head,STU *p_new)
{
STU *p_mov=*p_head;
if(*p_head==NULL) //当第一次加入链表为空时,head执行p_new
{
*p_head = p_new;
p_new->front = NULL;
p_new->next = NULL;
}
else //第二次及以后加入链表
{
while(p_mov->next!=NULL)
{
p_mov=p_mov->next; //找到原有链表的最后一个节点
}
p_mov->next = p_new; //将新申请的节点加入链表
p_new->front = p_mov;
p_new->next = NULL;
}
}
void double_link_print(STU *head)
{
STU *pb;
pb=head;
while(pb->next!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->next;
}
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
printf("***********************\n");
while(pb!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->front;
}
}
int main()
{
STU *head=NULL,*p_new=NULL;
int num,i;
printf("请输入链表初始个数:\n");
scanf("%d",&num);
for(i=0;i<num;i++)
{
p_new=(STU*)malloc(sizeof(STU));//申请一个新节点
printf("请输入学号、分数、名字:\n"); //给新节点赋值
scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);
double_link_creat_head(&head,p_new); //将新节点加入链表
}
double_link_print(head);
}
十、双向链表插入节点
按照顺序插入结点
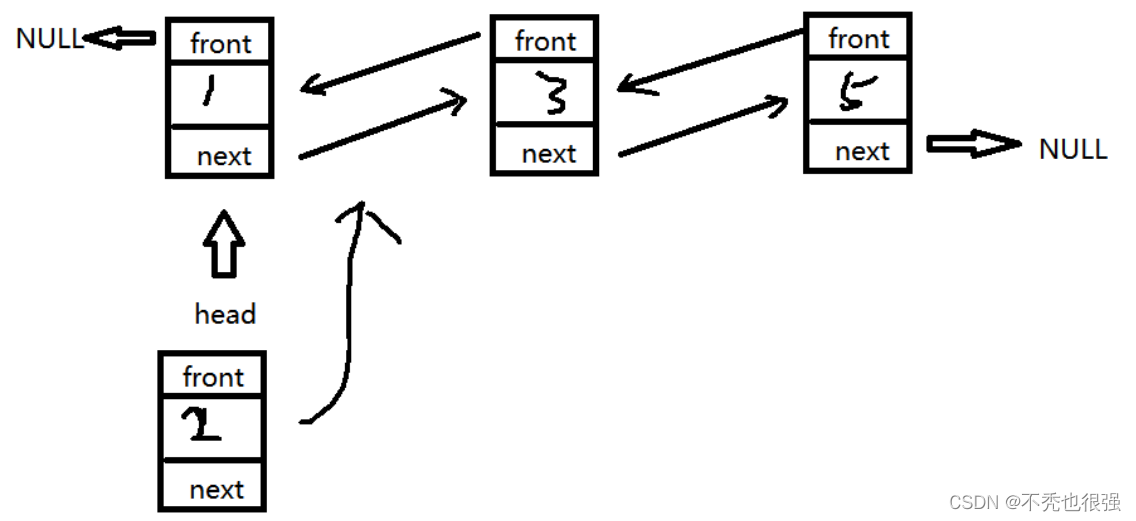
#include <stdio.h>
#include <stdlib.h>
//定义结点结构体
typedef struct student
{
//数据域
int num; //学号
int score; //分数
char name[20]; //姓名
//指针域
struct student *front; //保存上一个结点的地址
struct student *next; //保存下一个结点的地址
}STU;
void double_link_creat_head(STU **p_head,STU *p_new)
{
STU *p_mov=*p_head;
if(*p_head==NULL) //当第一次加入链表为空时,head执行p_new
{
*p_head = p_new;
p_new->front = NULL;
p_new->next = NULL;
}
else //第二次及以后加入链表
{
while(p_mov->next!=NULL)
{
p_mov=p_mov->next; //找到原有链表的最后一个节点
}
p_mov->next = p_new; //将新申请的节点加入链表
p_new->front = p_mov;
p_new->next = NULL;
}
}
void double_link_print(STU *head)
{
STU *pb;
pb=head;
while(pb->next!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->next;
}
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
printf("***********************\n");
while(pb!=NULL)
{
printf("num=%d score=%d name:%s\n",pb->num,pb->score,pb->name);
pb=pb->front;
}
}
//双向链表的删除
void double_link_delete_num(STU **p_head,int num)
{
STU *pb,*pf;
pb=*p_head;
if(*p_head==NULL)//链表为空,不需要删除
{
printf("链表为空,没有您要删除的节点\n");
return ;
}
while((pb->num != num) && (pb->next != NULL) )
{
pb=pb->next;
}
if(pb->num == num)//找到了一个节点的num和num相同,删除pb指向的节点
{
if(pb == *p_head)//找到的节点是头节点
{
if((*p_head)->next==NULL)//只有一个节点的情况
{
*p_head=pb->next;
}
else//有多个节点的情况
{
*p_head = pb->next;//main函数中的head指向下个节点
(*p_head)->front=NULL;
}
}
else//要删的节点是其他节点
{
if(pb->next!=NULL)//删除中间节点
{
pf=pb->front;//让pf指向找到的节点的前一个节点
pf->next=pb->next; //前一个结点的next保存后一个结点的地址
(pb->next)->front=pf; //后一个结点的front保存前一个结点的地址
}
else//删除尾节点
{
pf=pb->front;
pf->next=NULL;
}
}
free(pb);//释放找到的节点
}
else//没找到
{
printf("没有您要删除的节点\n");
}
}
int main()
{
STU *head=NULL,*p_new=NULL;
int num,i;
printf("请输入链表初始个数:\n");
scanf("%d",&num);
for(i=0;i<num;i++)
{
p_new=(STU*)malloc(sizeof(STU));//申请一个新节点
printf("请输入学号、分数、名字:\n"); //给新节点赋值
scanf("%d %d %s",&p_new->num,&p_new->score,p_new->name);
double_link_creat_head(&head,p_new); //将新节点加入链表
}
double_link_print(head);
printf("请输入您要删除的节点的num\n");
scanf("%d",&num);
double_link_delete_num(&head,num);
double_link_print(head);
}
智能推荐
EBS R12基本概念与应用基础-程序员宅基地
文章浏览阅读1.8k次。摘自: [ORACLE EBS 入门及供应链核心系统详解教程] (书籍)EBS基础功能架构(13个核心模块,业财一体化)业务运营管理,价值增值财务会计管理,价值实现应用架构Finance财务,资金流Accounting财务管理Bisuness业务,实物流核心业务,与财务高度集成;PUR、INV、制造、订单履行等间接业务,or专业业务,为核心业务提供支持;HR..._ebs r12
Java中Date和Timestamp的区别_java date timestamp区别-程序员宅基地
文章浏览阅读838次。转载:https://blog.csdn.net/ccecwg/article/details/39546307_java date timestamp区别
如何用原生js封装一个类似jq的选择器_原声js实现jq元素选择器-程序员宅基地
文章浏览阅读1.4k次。1、我们先了解一下原生js中的选择器ID选择器(在整个文档中获取id为xxx的元素)document.getElementId([ID]);类名选择器(在整个文档中或者在指定上下文中获取类名为xxx的元素)document.getElementsByClassName(' ');[context].getElementsByClassName(' ');标签名选择器(在整个文档中或者..._原声js实现jq元素选择器
Hive中partition by和distribute by区别_partition by distribute by-程序员宅基地
文章浏览阅读1.2k次,点赞3次,收藏4次。通常查询时会对整个数据库查询,而这带来了大量的开销,因此引入了partition的概念,在建表的时候通过设置partition的字段, 会根据该字段对数据分区存放,更具体的说是存放在不同的文件夹,这样通过指定设置Partition的字段条件查询时可以减少大量的开销。1)partition by [key..] order by [key..]只能在窗口函数中使用,而distribute by [key...] sort by [key...]在窗口函数和select中都可以使用。_partition by distribute by
游标(cursor )是什么?_c# cursor-程序员宅基地
文章浏览阅读7.3k次。Private SQL Area A private SQL area holds information about a parsed SQLstatement and other session-specific information for processing. When a serverprocess executes SQL or PL/SQL code, the process_c# cursor
listview使用的一些心得_listview的使用——购物商城实验心得-程序员宅基地
文章浏览阅读616次。近日在用ListView中的一些注意点,和公用代码,整理如下1.ListView.Items.Clear而不是ListView.Clear一般如果ListView是动态填充的,我们在填充之前都会先进行清理。但需要注意一下,我们是清理Items,如果去直接Clear整个ListView,就连原先定义好的列都没有了2.给ListView绑定数据ListView并不能直接_listview的使用——购物商城实验心得
随便推点
java 注解处理器的作用_深入理解Java:注解(Annotation)--注解处理器-程序员宅基地
文章浏览阅读110次。如果没有用来读取注解的方法和工作,那么注解也就不会比注释更有用处了。使用注解的过程中,很重要的一部分就是创建于使用注解处理器。Java SE5扩展了反射机制的API,以帮助程序员快速的构造自定义注解处理器。注解处理器类库(java.lang.reflect.AnnotatedElement):Java使用Annotation接口来代表程序元素前面的注解,该接口是所有Annotation类型的父接口..._java注解处理器作用
全国职业技能大赛高职组(最新职业院校技能大赛_大数据应用开发2023国赛样题解析-模块C:实时数据处理-任务二:实时指标计算)_大数据 国赛 样题-程序员宅基地
文章浏览阅读1.8k次,点赞27次,收藏28次。全国职业技能大赛高职组(最新职业院校技能大赛_大数据应用开发样题解析-模块B:数据采集-任务一:离线数据采集-程序员宅基地。_大数据 国赛 样题
ssm+mysql+微信小程序疫情防控小程序-计算机毕业设计源码73691_ssm+微信小程序-程序员宅基地
文章浏览阅读926次。本系统分为管理员和注册用户两个角色,主要有疫情新闻、疫情案例介绍、健康信息申报、行程信息申报、就医流程介绍、举报、在线留言、用户管理、信息统计等模块。用户需要先注册成为会员,成功登录后,可以查看网站发布的疫情新闻,可以查看疫情相关病例介绍,有助于疫情防范,还可以查看网站发布的重大疫情案例,了解疫情的发展状况,出行时候好做好防护,同时通过网站可以上报健康信息,以及上报行程信息,方便社区了解自己的出行情况;网站还发布了疫情状态下的就医流程,方便大家就医时候做好准备;同时网站还提供了举报功能,如果发现外来人员或_ssm+微信小程序
Linux 操作系统 022-串口/U盘/共享文件夹-程序员宅基地
文章浏览阅读296次,点赞3次,收藏9次。本节关键字:Linux、centos、串口、U盘、共享文件夹本节相关指令:echo、cat、mkdir、mount
解密C++新特性:内联函数、auto和基于范围的for循环-程序员宅基地
文章浏览阅读1.3k次,点赞45次,收藏29次。本篇主题为: 解密C++新特性:内联函数、auto关键字和基于范围的for循环。
上岸整理:2023前端面试题-vue,小程序,js,css_今年的前端面试难不难-程序员宅基地
文章浏览阅读774次,点赞4次,收藏11次。1、浏览器常见的报错信息与含义2、304与204的区别,http缓存,强缓存,协商缓存3、浏览器从输入地址到渲染,经历了什么状态?4、vue的界面渲染,经过哪些过程(生命周期)5、三次握手,四次挥手6、重排与重绘7、用css实现一个三角形8、常见的flex布局,有哪些功能9、用css实现一个水平垂直居中10、null与undefined的区别11、虚拟dom12、深拷贝与浅拷贝13、es6新增的功能15、async await 与promise。_今年的前端面试难不难