【语义分割】深度学习中常见概念回顾(全大白话解释,一读就能懂!)_epoch/iter-程序员宅基地
技术标签: 深度学习
记录一下常见的术语!
一、epoch、batch size和iteration
1.1 Epoch
定义:一个epoch指代所有的数据送入网络中完成一次前向计算及反向传播的过程。简而言之:训练集中的全部样本/数据 “喂” 给网络一次,就叫做一个epoch
补充1:在训练时,将所有数据迭代训练一次是不够的,需要反复多次才能拟合收敛,即:需要把数据集多放入网络训练几次。简而言之:看书看一遍是不够的的,需要多看几遍,神经网络也是。
补充2: 由于一个epoch常常太大,一次全 “喂” 给网络,计算机无法负荷,我们会将它分成几个较小的batch,即引出了batch size这个概念
1.2 Batch Size
定义:所谓Batch就是每次送入网络中训练的一部分数据,而Batch Size就是每个batch中训练样本的数量。其取值通常为:2^N,如:32、64、128…
作用: Batch Size 如果过小,训练数据就收敛困难;如果过大,虽然相对处理速度加快,但所需内存容量增加。使用中需要根据计算机性能和训练次数之间平衡Batch Size,其中一个epoch中的训练次数又叫做:iteration,迭代
1.3 Iteration
定义: iterations就是完成一次epoch所需的batch个数。
举个例子:我们有2000个数据,分成4个batch,那么batch size就是500。运行所有的数据进行训练,完成1个epoch,需要进行4次iterations。
1.4 其他版本
定义:
(1)batchsize:批大小,即:每次训练在训练集中取batchsize个样本训练;
(2)iteration:1个iteration等于使用batchsize个样本训练一次;
(3)epoch:1个epoch等于使用训练集中的全部样本训练一次;
举个例子:训练集有1000个样本,batchsize=10,则训练完一次整个样本集需要:
iteration = 1000 / 10 = 100 次
epoch = 1 个
参考
- 深度学习中的Epoch,Batchsize,Iterations,都是什么鬼?
- 机器学习基本概念:batch_size、epoch、 iteration
- 神经网络中epoch、batch size和iteration的区别
- 神经网络中Epoch、Iteration、Batchsize相关理解和说明
- 【调参炼丹】 Batch_size和Epoch_size
二、Softmax
简而言之,一个主要用于多分类求概率的函数,常应用:
(1)用于神经网络输出层
(2)和argmax函数合作用
示意图如下: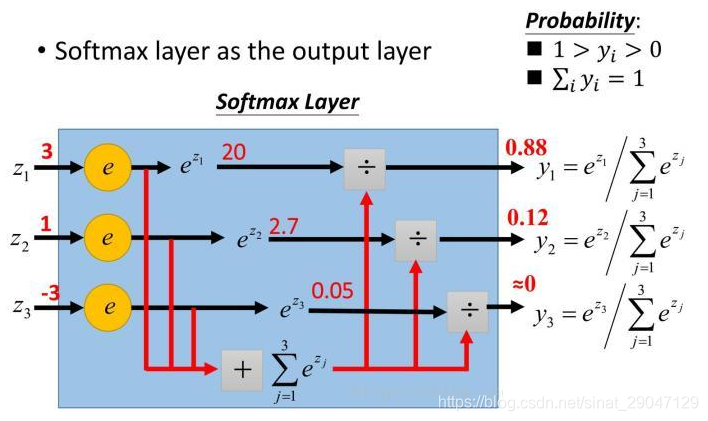
参考: 小白都能看懂的softmax详解
三、激活函数和卷积核
3.1 激活函数
概念:对数据进行映射。
(1)微观理解:若网络不使用激活函数,则只能处理线性数据;使用激活函数后,网络可处理非线性数据。如Relu函数,把直线(线性)“掰弯”(非线性):
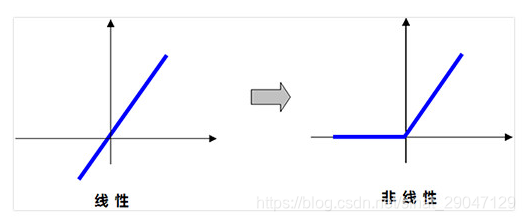
(2)宏观理解:使用激活函数,便于更好的提取图像特征
更多激活函数介绍详见:
3.2 卷积核
单一神经元模型如下图:
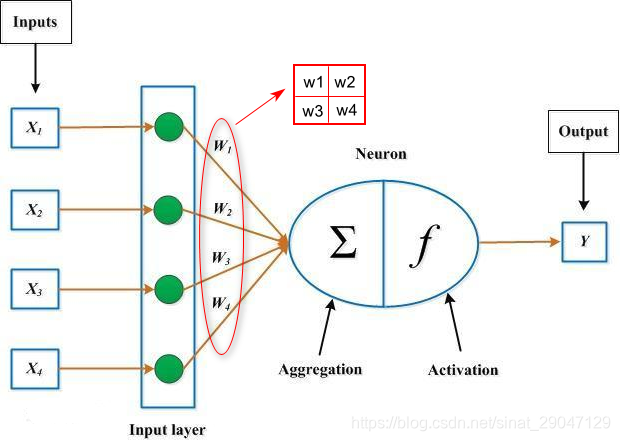
其中,
卷积核的大小:
(1)大小是提前预设的,常见的是3x3,但为什么是3x3,并没有理论依据,通过大量的实践测试得来的,这个大小最好用。
(2)还有一个特殊的是1x1的,一般做降维或者线性变换的时候用
卷积核内的每个参数值(权重):
(1)核中每个参数的值是通过训练得来的,训练网络的过程,也就是训练这些参数的过程
(2)核中的权重(参数:W和b),最初都被初始化为随机值,最终不断优化训练网络、不断调整权重。
(3)在使用训练数据对网络进行BP训练时,W和b的值都会往局部最优的方向更新,直至算法收敛。所以卷积神经网络中的卷积核是从训练数据中学习得来的。(详情参考请点击)
那么,卷积核中的权重值是怎样进行修正的呢?用到了什么技术呢?请参考下述的:损失函数和优化器。
四、损失函数和优化器
背景介绍:
深度神经网络中的的损失用来度量我们的模型得到的的预测值和数据真实值之间差距,也是一个用来衡量我们训练出来的模型泛化能力好坏的重要指标。(损失函数)
对模型进行优化的最终目的是尽可能地在不过拟合的情况下降低损失值。(优化器)
两者关系:
先用损失函数计算出损失值,再基于损失值优化模型参数(卷积核参数)
4.1 损失函数
常见的有:均方误差函数、均方根误差函数、平均绝对误差函数等等。
详细的损失函数介绍,请参考:
4.2 优化器
优化器的鼻祖是:梯度下降(Gradient Descent,GD),其涉及:梯度和学习率。
GD是参数优化的基础方法,虽然已广泛应用,但是其自身存在许多不足,所以在其基础上改进的优化函数也非常多,比如:梯度下降最常见的三种变形 BGD,SGD,MBGD。
详细的优化器介绍,请参考:
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
- 损失函数和优化函数
- 深度学习笔记(五)—损失函数与优化器
五、上采样
常见的上采样方法有:双线性插值、转置卷积、上采样(unsampling)和上池化(unpooling)。其中前两种方法较为常见,后两种用得较少。
详情参考:上采样方法原理简介
六、归一化
6.1 归一化
概念:
传统机器学习中归一化也叫做标准化,其一般是将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位。如:有的特征取值范围[10<sup>9</sup>,10<sup>99</sup>],另一些特征取值范围为[0,01, 0.1],通过归一化可将这些不同取值范围的特征值映射到相同的范围,如将上述两个范围映射到[-1, 1]之间。
作用:
数据标准化让机器学习模型看到的不同取值范围的样本彼此之间更加形似,有助于模型的学习与对新数据的泛化。
6.2 批归一化
概念:Batch Normalization,批归一化和普通的数据归一化类似,是将分散的数据统一到某一特定区间的一种方法,也是优化神经网络的一种方法。
应用:
(1)在数据预处理时进行批归一化,可以加速网络收敛;
(2)在神经网络中进行批归一化,即:在网络的每一次变换之后进行数据归一化,也可加速网路收敛。为什么要在训练过程中批归一化?答:训练过程中均值和方差随时间发生变化,需重新对数据进行批归一化,这样网络每一层看到的数据都属于同一分布。
(3)批标准化一般放在:卷积层后,即:先卷积,后批标准化,再卷积,再批标准化
作用:
(1)批标准化解决的问题是梯度消失和梯度爆炸
(2)批标准化是一种训练优化方法
(3)具有正则化效果,可抑制过拟合
(4)可提高模型的泛化能力。因为:它可使同一神经网络的每一层看到的数据都属于同一分布范围,无论什么范围的数据过来,都能很好的处理。
(5)允许更高的学习速率从而加速网络收敛
(6)批标准化有助于梯度传播,因此可基于批标准化创建更深的网络,如:ResNet50、Inception V3和Xception等。
其他:
(1)BatchNormalization层通常在卷积层或密集连接层后使用,tf 2.0中对应函数:Tf.keras.layers.Batchnormalization()
七、过拟合问题解决
当网络训练后出现过拟合,如:训练集上准确率上升,验证集上准确率恒定,可采用:
(1)dropout层
(2)l1、l2正则化
解决过拟合问题。
智能推荐
关于XML解析报错问题(LF、CRLF)-程序员宅基地
文章浏览阅读2.1k次。报错内容的主要部分:UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x80 in position123: illegal multibyte sequence问题产生在做目标检测时,使用的数据集来自网络,在将xml和图片转换到特定格式时,有些xml文件解析出现了问题。像这样:我发现,当我未使用labelImg工具,而直接通过记..._xml解析报错
C1083_qt 提升自定义控件 no such file or directory-程序员宅基地
文章浏览阅读145次。在使用QT过程中会自定义一些控件。比如:自定义了一个树形控件。使用的时候,在界面上拖动创建一个树形控件,然后使用“提升为”当前自定义的树形控件。提升之后的结果:但是编译的时候,出现了错误:\GeneratedFiles\ui_QtGuiUserDraw.h(23): fatal error C1083: 无法打开包括文件: “userdrawgeotree.h”: No such file or directory (编译源文件 QtGuiUserDraw.cpp)1。_qt 提升自定义控件 no such file or directory
java中所有的类都继承于_Java中所有的类都是通过直接或间接地继承( )类得到的...-程序员宅基地
文章浏览阅读4.2k次。Java中所有的类都是通过直接或间接地继承( )类得到的答:java.lang.Object关于主机地址 192.168.19.125 (子网掩码: 255.255.255.248 ),以下说法正确答:广播地址为:192.168.19.127 ; 网络地址为:192.168.19.120 ;在小儿基本手法中,逆运内八卦的功效是?(??)答:宽胸利膈,行滞消食对事物的知觉是答:人脑对直接作用感官的..._java中所有的类都是通过直接或间接地继承( )类得到的。 2分 a、java.lang.object
【幻化万千戏红尘】qianfengDay21-java基础学习:进程、线程、Timer-程序员宅基地
文章浏览阅读222次。课程回顾:面向对象数组异常常用类集合IO流今日内容:进程:应用程序运行时,产生的独立的应用程序,拥有独立的代码和存储空间多进程:操作系统可以并发的执行多个进程线程:进程内部的一条执行路径多线程:java语言支持程序内部进行多线程开发进程内部可以有多个线程线程的作用:可以分担压力,提高性能主要用来完成耗时
重生奇迹mu武器镶嵌顺序-程序员宅基地
文章浏览阅读71次。例如:雷1J10%冰技能+37火每等级,这样就可以30%出现属性,如果没有出,可以破坏某一个洞,继续镶嵌同属性的宝石,直到定现为止,由于1J雷和37技能冰的比较贵,所以可以破坏火荧石,不断镶嵌到出现属性为止。荧光宝石可从以前的物品中获得。从上到下的镶嵌顺寻按照雷、冰、火镶嵌,就有30%的概率出现技能攻击力加11的幸运荧光属性。从上到下的镶嵌顺寻按照土、风、水镶嵌,就有30%的概率出现最大生命值+29的幸运荧光属性。从上到下的镶嵌顺寻按照火、冰、雷镶嵌,就有30%的概率出现攻击力加11的幸运荧光属性。
人工智能第三章(1)——无信息搜索(盲目搜索) (附书本资料)_无信息搜索又称为-程序员宅基地
文章浏览阅读8.8k次,点赞21次,收藏51次。这篇文章的意义在于哪里呢?1)向大家展示如何形式化定义一个搜索问题,又如何去求解;2)通过讲述各种盲目搜索算法,帮大家梳理无信息搜索的脉络。_无信息搜索又称为
随便推点
OpenCV 2.4.8组件结构全解析_opencv2.4 build结构-程序员宅基地
文章浏览阅读501次。之前啃了不少OpenCV的官方文档,发现如果了解了一些OpenCV整体的模块架构后,再重点学习自己感兴趣的部分的话,就会有一览众山小的感觉,于是,就决定写出这篇文章,作为启程OpenCV系列博文的第二篇。 至于OpenCV组件结构的研究方法,我们不妨管中窥豹,通过opencv安装路径下include目录里面头文件的分类存放,来一窥OpenCV这些年迅猛发展起来的庞杂组件架构。_opencv2.4 build结构
source insight遇到__attribute__解析不到函数_sourceinsight识别不了特殊的函数类型-程序员宅基地
文章浏览阅读7.2k次,点赞10次,收藏8次。bestboyxie 励志做一名能帮助到他人的程序员,如果你觉得这篇文章对你有帮助,麻烦你点赞最近分析DPDK代码的时候遇到 __attribute__这种东西。就无法解析对应的函数,跳转苦不堪言:如果你遇到这个问题,然后有幸,看到了我的文章。告诉你有幸啦打开 source insight 安装目录C:\Program Files (x86)\Sou_sourceinsight识别不了特殊的函数类型
Android 单独抽取 WebRtc-VAD(语音端点检测) 模块_android webrtc vad-程序员宅基地
文章浏览阅读3.7k次,点赞3次,收藏10次。本文基于webrtc最新源码进行抽取编译做简单讲解。最终目的是Android 单独抽取 WebRtc-VAD 模块,封装好JNI层,并且ndk-build出so库。希望对大家有所帮助,有需要看JNI层实现和完整demo的,请加我V:15092216090先来看一下vad模块的头文件,webrtc_vad.h,该文件路径为common_audio\vad\include\webrtc_v..._android webrtc vad
夏天到,装饰器让Python秀出性感属性:Property+Decorators+-+Getters,+Setters,+and+Deleters_@property (decorators)-程序员宅基地
文章浏览阅读262次。John Smith曾经是我的好基友,没有之一,今天我们拿他做个试验:初始代码,我们做一个打印员工John Smith信息的类,实例emp_1会用类属性输出:class Employee: def __init__(self, first, last): self.first = first self.last = last self.email = first + "." + last + '@email.com' def fullnam_@property (decorators)
Oracle单个字段多记录拼接_oracle 一个字段多条记录的拼接-程序员宅基地
文章浏览阅读2.4k次。sql查询中,一个字段多个结果拼接的两种方式_oracle 一个字段多条记录的拼接
vue 项目中 html中出现clear错误_[vue/comment-directive] clear-程序员宅基地
文章浏览阅读934次。clear报错_[vue/comment-directive] clear