深度学习--- GAN网络原理解析-程序员宅基地
技术标签: 生成对抗网络 GAN 深度学习 Machine Learning & Algorithm
Generative Adversarial Network对抗生成网络,这是当下机器视觉比较热门的一个技术,由两部分组成生成器( G n e t G_{net} Gnet)和判别器( D n e t D_{net} Dnet)组成
GAN区别与传统的生成网络,生成的图片还原度高,主要缘于D网络基于数据相对位置和数据本身对 r e a l real real数据奖励,对 f a k e fake fake数据惩罚的缘故
1.GAN思想 & 与单个传统生成器和判别器的对比
1.1GAN的思想类似于"零和博弈",百度百科这样介绍:
零和游戏的原理如下:两人对弈,总会有一个赢,一个输,如果我们把获胜计算为得1分,而输棋为-1分。则若A获胜次数为N,B的失败次数必然也为N。若A失败的次数为M,则B获胜的次数必然为M。这样,A的总分为(N-M),B的总分为(M-N),显然(N-M)+(M-N)=0,这就是零和游戏的数学表达式。
也就是奖励获胜者,惩罚失败者,在GAN中就是奖励真实图片,且惩罚伪造图片,且奖励和惩罚同时发生,当然现在说这个有点早,往后看你会慢慢的发现这就是D网络的一个反馈机制
1.2单个生成器和判别器与GAN的对比
1.2.1 生成器(Generation)
就是利用模型对图片的学习,最终达到可以自己生成图片的目的
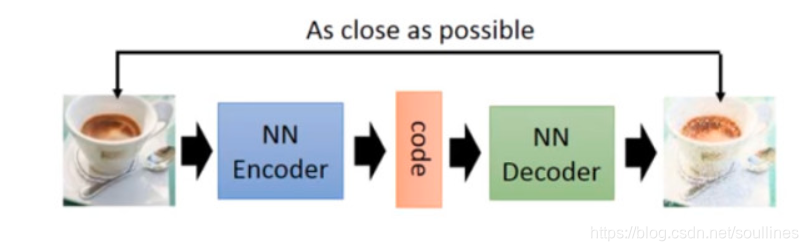
就像上图表示的就是生成器的一种(还有一种变分自编码器这里不做过多的赘述)
s t e p 1 : step1: step1:将图片传入解码器 NN-Encoder 转化为机器可以识别的array形式,然后通过 NN-Decoder生成图片 P i c f a k e Pic_{fake} Picfake
s t e p 2 : step2: step2:已知真实图片 P i c r e a l Pic_{real} Picreal,通过 l o s s loss loss函数 M S E MSE MSE,计算真实图片和生成图片的 l o s s loss loss,进而反馈网络
这样看起来好像是没有什么问题,但是需要注意一个问题,这里的 l o s s loss loss仅仅计算数据之间的差异,图片的像素 v a l val val不仅仅是数据的堆叠那么简单,同样相对位置(数据之间的相关性)也是很重要的一个部分,由于G网络没有办法学习到位置的相关性
所以 G e n e r a t i o n Generation Generation不能生成高还原度的图片
1.2.2 判别器(Discriminator)
简单来说就是一个判断 r e a l real real图片和 f a k e fake fake图片的二分类模型
i n p u t : x o u t p u t : y y ∈ [ 0 , 1 ] input:x output:y \;\;\;\;\; y\in[0,1] input:xoutput:yy∈[0,1]
Discriminator是一个卷积的神经网络,所以可以有效的区分图片的相对位置(即注重数据的相关性),但是由于Discriminator只对真实数据奖励(此时的 o u t p u t output output大),对伪造的数据惩罚(此时的 o u t p u t output output小)
所以随机数据的选取比较困难
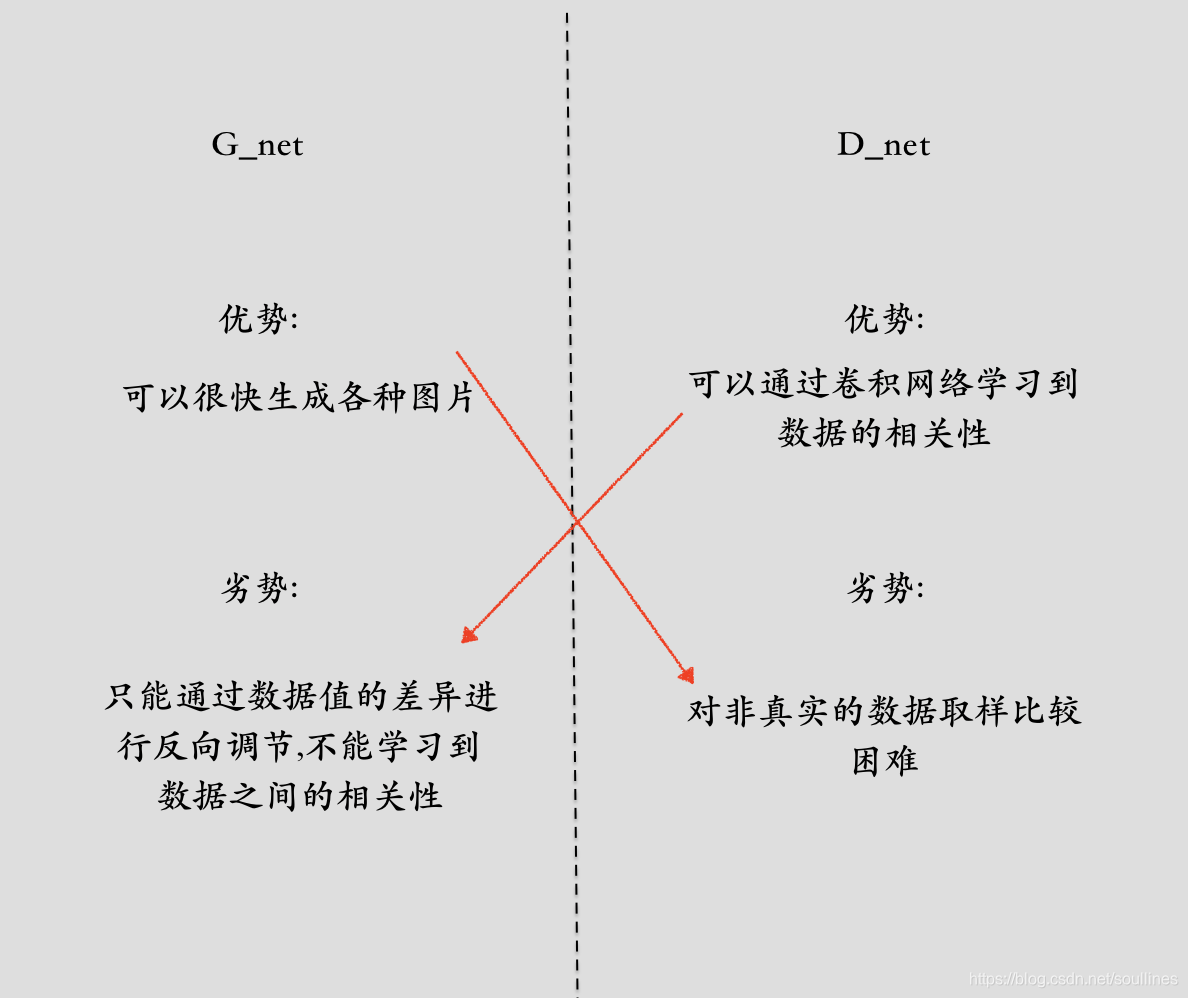
这样对比下 G 和 D的优劣:
这样来看 G网络和 D网络各有优缺点,但是刚刚好可以互补,所以GAN网络顺势而生
2.GAN原理
2.1 Generation
由于单一G网络不能学习到数据之间的相关性,所以G网络的反向传播依赖于D网络
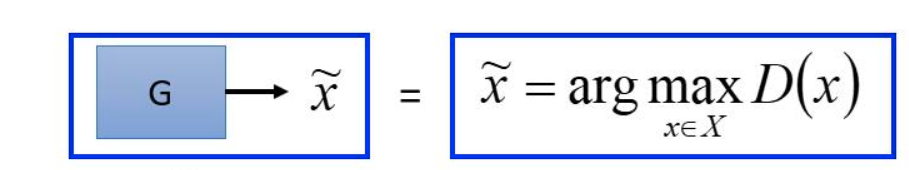
对于生成器而言,它的目的是Generation的 o u t p u t output output要无限接近于真实的数据分布:
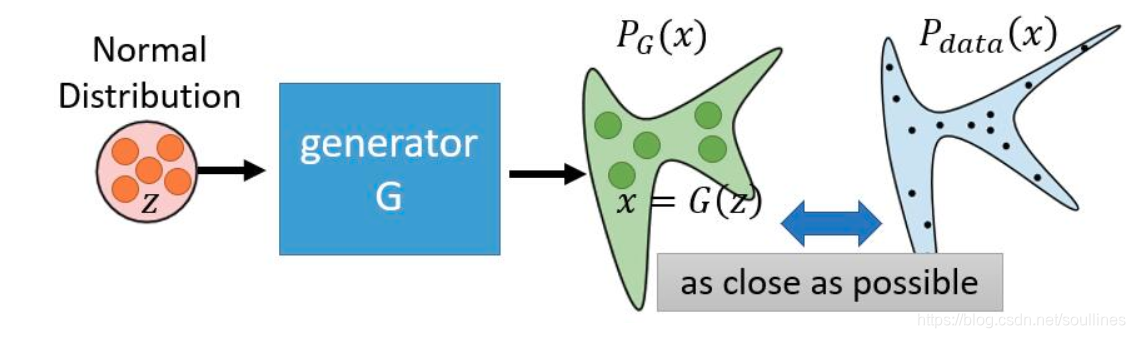
这里会用到极大似然估计:
s t e p 1 : step1: step1:给定真实的数据分布: P d a t a P_{data} Pdata,G网络 o u t p u t : x = G ( z ) output:x = G(z) output:x=G(z) ,这里的 z z z是G网络的 i n t p u t intput intput
s t e p 2 : step2: step2: 那么这个问题就变成一个求使G网络 o u t p u t output output无限接近于 P d a t a P_{data} Pdata这个真实分布的 θ \theta θ的极大似然估计求解过程
这里我们用 P ( x ; θ ) P(x;\theta) P(x;θ)表示G网络 o u t p u t output output与 P d a t a P_{data} Pdata相似的概率,所以G网络就是求
∀ θ ; P ( x ; θ ) \forall \theta;\;\;\;\;\ P(x;\theta) ∀θ; P(x;θ)最大 的过程;
下面是求解的过程:
θ ∗ = a r g m a x ∏ i = 1 m P G ( x i ; θ ) = a r g m a x ∑ i = 1 m l o g ( P G ( x i ; θ ) ) \theta^* = argmax\prod_{i=1}^m P_G(x^i;\theta)=argmax\sum_{i=1}^mlog(P_G(x^i;\theta)) θ∗=argmax∏i=1mPG(xi;θ)=argmax∑i=1mlog(PG(xi;θ))
≈ a r g m a x E x ∼ p d a t a [ l o g ( P G ( x i ; θ ) ) ] \approx argmaxE_{x \sim p_{data}}[log(P_G(x^i;\theta))] ≈argmaxEx∼pdata[log(PG(xi;θ))]
在这里我们要构建一个 K L − d i v e r g e n c e KL-divergence KL−divergence的形式,我们都知道个 K L − d i v e r g e n c e KL-divergence KL−divergence是描述两个概率之间差异的形式,上式后面加一个 ∫ x P d a t a ( x ) l o g ( P d a t a ( x ) d x \int_xP_{data}(x)log(P_{data}(x)dx ∫xPdata(x)log(Pdata(x)dx ,这是一个与 θ \theta θ无关的项所以不会影响后序结果,却可以辅助构建 K L − d i v e r g e n c e KL-divergence KL−divergence形式,所以上式可以这样变形
上式 = a r g m a x [ ∫ x P d a t a ( x ) l o g ( P G ( x i ; θ ) ) − ∫ x P d a t a ( x ) l o g ( P d a t a ( x ) d x ] = argmax[\int_xP_{data}(x)log(P_G(x^i;\theta)) -\int_xP_{data}(x)log(P_{data}(x)dx ] =argmax[∫xPdata(x)log(PG(xi;θ))−∫xPdata(x)log(Pdata(x)dx]
= a r g m a x K L ( P G ∣ ∣ P d a t a ) = argmaxKL(P_G||P_{data}) =argmaxKL(PG∣∣Pdata)
= a r g m n i K L ( P d a t a ∣ ∣ P G ) = argmniKL(P_{data}||P_G) =argmniKL(Pdata∣∣PG)
这样看来G网络的计算就是求解 a r g m n i G K L ( P d a t a ∣ ∣ P G ) argmni_GKL(P_{data}||P_G) argmniGKL(Pdata∣∣PG);但是 P G P_G PG的分布和 P d a t a P_{data} Pdata的差异(也就是 P d a t a 和 P G P_{data}和P_G Pdata和PG的 K L − d i v e r g e n c e KL-divergence KL−divergence),G网络是没有完全办法计算的(G网络不具备数据相关性的学习能力),需要用到D网络的卷积来进行有效计算 l o s s loss loss,所以接下来我们要引入D网络进行鉴别;
2.2 Discriminator
Discriminator鉴别器的机制是奖励真实样本,惩罚伪造样本,鉴别器需要获取G网络数据分布 P G P_G PG和真实数据分布 P d a t a P_{data} Pdata
- s t e p 1 : s a m p l e f r o m P d a t a s a m p l e f r o m P G step1: sample from P_{data} \;\;\; sample from P_G step1:samplefromPdatasamplefromPG
- s t e p 2 : step2: step2:这样我们就获取到了 r e a l real real和 f a k e fake fake的数据分布,用于D网络的 l o s s loss loss计算
下面给出D网络的 l o s s loss loss函数:
V ( G , D ) = E x ∼ p d a t a [ l o g ( D ( x ) ) ] + E x ∼ p G [ l o g ( 1 − D ( x ) ) ] V(G,D)=E_{x\sim p_{data}}[log(D(x))] + E_{x\sim p_{G}}[log(1- D(x))] V(G,D)=Ex∼pdata[log(D(x))]+Ex∼pG[log(1−D(x))]
这里简单赘述下,上面成本函数的计算过程,后面会详细提到:
V(G,D)可以看做是一个组合的 l o s s loss loss函数
-
若 x x x是生成的数据 x ∼ x^{\sim} x∼, P d a t a ( x ∼ ) = 0 P G ( x ∼ ) = 1 P_{data}(x^\sim) = 0 \;\; P_{G}(x^\sim) = 1 Pdata(x∼)=0PG(x∼)=1,那么:
V ( G , D ) = E x ∼ p G [ l o g ( 1 − D ( x ∼ ) ) ] V(G,D)=E_{x\sim p_{G}}[log(1- D(x^\sim))] V(G,D)=Ex∼pG[log(1−D(x∼))]
-
若 x x x是真实的数据 x x x, P d a t a ( x ) = 1 P G ( x ) = 0 P_{data}(x) = 1 \;\; P_{G}(x) = 0 Pdata(x)=1PG(x)=0,那么:
V ( G , D ) = E x ∼ p d a t a [ l o g ( D ( x ) ) ] V(G,D)=E_{x\sim p_{data}}[log(D(x ))] V(G,D)=Ex∼pdata[log(D(x))]
所以实际用到的:
V ( G , D ) = E x ∼ p d a t a [ l o g ( D ( x ) ) ] + E x ∼ ∼ p G [ l o g ( 1 − D ( x ∼ ) ) ] V(G,D)=E_{x\sim p_{data}}[log(D(x))] + E_{x^\sim\sim p_{G}}[log(1- D(x^\sim))] V(G,D)=Ex∼pdata[log(D(x))]+Ex∼∼pG[log(1−D(x∼))]
下面是求解的过程:
正如上面所说Discriminator鉴别器的机制是奖励真实样本,惩罚伪造样本;所以D网络的训练过程就是迭代计算使得其 l o s s loss loss函数 V ( G , D ) V(G,D) V(G,D)最大化的过程;也就是 a r g m a x V ( D , G ) argmaxV(D,G) argmaxV(D,G)的过程;
为了方便计算出 V ( G , D ) V(G,D) V(G,D)的最大值,我们求解最优的 D ∗ D^* D∗(也就是 D ( x ) D(x) D(x)),D网络运行阶段G网络可以看做是固定不变的;
V ( G , D ) = E x ∼ p d a t a [ l o g ( D ( x ) ) ] + E x ∼ p G [ l o g ( 1 − D ( x ) ) ] V(G,D)=E_{x\sim p_{data}}[log(D(x))] + E_{x\sim p_{G}}[log(1- D(x))] V(G,D)=Ex∼pdata[log(D(x))]+Ex∼pG[log(1−D(x))]
= ∫ x P d a t a ( x ) l o g D ( x ) d x + ∫ x P G ( x ) l o g ( 1 − D ( x ) ) d x = \int_xP_{data}(x)logD(x)dx + \int_xP_G(x)log(1-D(x))dx =∫xPdata(x)logD(x)dx+∫xPG(x)log(1−D(x))dx
= ∫ x [ P d a t a ( x ) l o g D ( x ) + ∫ x P G ( x ) l o g ( 1 − D ( x ) ) ] d x =\int_x[P_{data}(x)logD(x) + \int_xP_G(x)log(1-D(x))]dx =∫x[Pdata(x)logD(x)+∫xPG(x)log(1−D(x))]dx
令 a = P d a t a ( x ) D = D ( x ) b = P G ( x ) a=P_{data}(x) \;\;\; D = D(x) \;\;\; b = P_G(x) a=Pdata(x)D=D(x)b=PG(x)
则 V ( G , D ) = a l o g D + b l o g ( 1 − D ) V(G,D) = alogD + blog(1-D) V(G,D)=alogD+blog(1−D)
通过偏导来求上述公式的最大值:
∂ V ( G , D ) ∂ D = a D + b 1 − D = 0 \frac{\partial V(G,D)}{\partial D} = \frac{a}{D} + \frac{b}{1-D} = 0 ∂D∂V(G,D)=Da+1−Db=0
则: D = a / a + b D = a/a+b D=a/a+b
所以 D ∗ = P d a t a ( x ) / ( P d a t a ( x ) + P G ( x ) ) D^* = P_{data}(x) / (P_{data}(x) + P_G(x)) D∗=Pdata(x)/(Pdata(x)+PG(x)) 此为使 V ( D , G ) V(D,G) V(D,G)最大化的最优解
代入 V ( G , D ) V(G,D) V(G,D)
上式 = V ( G , D ∗ ) = V(G,D^*) =V(G,D∗)
= E x ∼ p d a t a [ l o g P d a t a ( x ) P d a t a ( x ) + P G ( x ) ] + E x ∼ p G [ l o g P G ( x ) P d a t a ( x ) + P G ( x ) ] = Ex\sim p_{data}[log\frac{P_{data}(x)}{P_{data}(x) + P_G(x)}] + Ex\sim p_{G}[log\frac{P_{G}(x)}{P_{data}(x) + P_G(x)}] =Ex∼pdata[logPdata(x)+PG(x)Pdata(x)]+Ex∼pG[logPdata(x)+PG(x)PG(x)]
= ∫ x P d a t a ( x ) l o g P d a t a ( x ) P d a t a ( x ) + P G ( x ) d x + ∫ x P G ( x ) l o g P G ( x ) P d a t a ( x ) + P G ( x ) d x = \int_xP_{data}(x)log\frac{P_{data}(x)}{P_{data}(x) + P_G(x)}dx + \int_xP_{G}(x)log\frac{P_{G}(x)}{P_{data}(x) + P_G(x)}dx =∫xPdata(x)logPdata(x)+PG(x)Pdata(x)dx+∫xPG(x)logPdata(x)+PG(x)PG(x)dx
= ∫ x P d a t a ( x ) l o g P d a t a ( x ) P d a t a ( x ) + P G ( x ) 2 ∗ 1 2 d x + ∫ x P G ( x ) l o g P G ( x ) P d a t a ( x ) + P G ( x ) 2 ∗ 1 2 d x = \int_xP_{data}(x)log\frac{P_{data}(x)}{\frac{P_{data}(x) + P_G(x)}{2}} * \frac{1}{2}dx + \int_xP_{G}(x)log\frac{P_{G}(x)}{\frac{P_{data}(x) + P_G(x)}{2}}* \frac{1}{2}dx =∫xPdata(x)log2Pdata(x)+PG(x)Pdata(x)∗21dx+∫xPG(x)log2Pdata(x)+PG(x)PG(x)∗21dx
= − 2 l o g 2 + ∫ x P d a t a ( x ) l o g P d a t a ( x ) P d a t a ( x ) + P G ( x ) 2 d x + ∫ x P G ( x ) l o g P G ( x ) P d a t a ( x ) + P G ( x ) 2 d x = -2log2 + \int_xP_{data}(x)log\frac{P_{data}(x)}{\frac{P_{data}(x) + P_G(x)}{2}}dx + \int_xP_{G}(x)log\frac{P_{G}(x)}{\frac{P_{data}(x) + P_G(x)}{2}}dx =−2log2+∫xPdata(x)log2Pdata(x)+PG(x)Pdata(x)dx+∫xPG(x)log2Pdata(x)+PG(x)PG(x)dx
这里需要提到J一个知识点:
-
J S D d i v e r g e n c e JSD divergence JSDdivergence 是 K L d i v e r g e n c e KL divergence KLdivergence 的对称平滑版本,表示了两个分布之间的差异,上式没有办法转化为 K L − d i v e r g e n c e KL-divergence KL−divergence.所以这里我们使用 J S D JSD JSD
-
J S D JSD JSD公式: J S D ( P ∣ ∣ Q ) = 1 2 D ( P ∣ ∣ M ) + 1 2 D ( Q ∣ ∣ M ) JSD(P||Q) = \frac{1}{2}D(P||M) + \frac{1}{2}D(Q||M) JSD(P∣∣Q)=21D(P∣∣M)+21D(Q∣∣M) M = 1 2 ( P + Q ) M = \frac{1}{2}(P+Q) M=21(P+Q)
上式 = − 2 l o g 2 + K L ( P d a t a ( x ) ∣ ∣ P d a t a ( x ) + P G ( x ) 2 ) + K L ( P G ( x ) ∣ ∣ P d a t a ( x ) + P G ( x ) 2 ) = -2log2 + KL(P_{data}(x)||\frac{P_{data}(x) + P_G(x)}{2}) + KL(P_{G}(x)||\frac{P_{data}(x) + P_G(x)}{2}) =−2log2+KL(Pdata(x)∣∣2Pdata(x)+PG(x))+KL(PG(x)∣∣2Pdata(x)+PG(x))
= − 2 l o g 2 + 2 J S D ( P ∣ ∣ Q ) = -2log2 + 2JSD(P||Q) =−2log2+2JSD(P∣∣Q)
在数学中可以证明(这里不详细赘述), J S D m a x = l o g 2 JSD_{max} = log2 JSDmax=log2
所以 V ( G , D ) V(G,D) V(G,D)最大值是0,最小值是 − 2 l o g 2 -2log2 −2log2;也就是说 J S D JSD JSD越大P和Q的差异越大, J S D JSD JSD越小P和Q的差异就越小
所以D网络最优的场景应当是:
m a x D ( G , D ) max_D(G,D) maxD(G,D)最小的情况,此时 P G = P d a t a P_G = P_{data} PG=Pdata也就是生成数据完全与真实数据相等
综上来看,GAN就是 θ G , θ D = a r g m i n G m a x D V ( G , D ) \theta_G,\;\theta_D = argmin_Gmax_DV(G,D) θG,θD=argminGmaxDV(G,D)的过程
3.GAN训练过程

这就是 GAN的整个训练过程,蓝色框是D网络的训练过程,红色框是G网络的训练过程
这里我们会注意到:
- D的 l o s s loss loss迭代过程中要趋向于最大,所以 θ d = θ d + η ∇ l o s s \theta_d = \theta_d + \eta \nabla loss θd=θd+η∇loss;
- G的 l o s s loss loss迭代过程中要趋向于最小,所以 θ d = θ d − η ∇ l o s s \theta_d = \theta_d - \eta \nabla loss θd=θd−η∇loss;
- 可以看出来一般情况下D网络每迭代多次,G网络仅迭代一次;主要原因G,D的反馈传播均依赖于D网络,G网络迭代一次,会让D网络的 l o s s loss loss较之前下降,所以D网络要调节多次使得D网络的 l o s s loss loss尽可能的大;
- D的 l o s s loss loss可以看做对D网络而言分辨 r e a l real real数据和 f a k e fake fake数据的损失,所以要最大化真实数据的期望 l o g D ( x ) logD(x) logD(x),同时最小化生成数据期望 l o g D ( x ∼ ) logD(x^\sim) logD(x∼),也就是最大化 l o g ( 1 − D ( x ∼ ) ) log(1-D(x^\sim)) log(1−D(x∼)),而 l o s s D = E x ∼ p d a t a [ l o g ( D ( x ) ) ] + E x ∼ ∼ p G [ l o g ( 1 − D ( x ∼ ) ) ] loss_D = E_{x\sim p_{data}}[log(D(x))] + E_{x^\sim\sim p_{G}}[log(1- D(x^\sim))] lossD=Ex∼pdata[log(D(x))]+Ex∼∼pG[log(1−D(x∼))],所以D的期望是最大化 l o s s loss loss
- 而G网络的 l o s s G = E x ∼ ∼ p G [ l o g ( 1 − D ( x ∼ ) ) ] loss_G = E_{x^\sim\sim p_{G}}[log(1- D(x^\sim))] lossG=Ex∼∼pG[log(1−D(x∼))],G网络的输入是没有 P d a t a P_{data} Pdata作为 i n p u t input input,所以G网络仅保留V的后半部分,也可以看做一个类别的二分类器.是计算生成图片与目标图片的距离;所以越小越好
4.GAN的优化
我们先来看下G网络loss的图像:
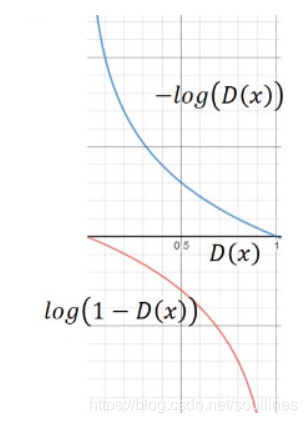
可以看到 原始的G网络的 l o s s = l o g ( 1 − D ( x ) ) loss = log(1-D(x)) loss=log(1−D(x)),首先我们知道我们初始化一般从0开始,而这个 l o s s loss loss在0附近梯度较小,从0->1,梯度越来越大;这显然不符合我们的习惯,我们期望的模型迭代应当是初期梯度较大,随着 e p o c h epoch epoch的增加梯度越来越小,这样有利于函数的收敛
所以我们可以把G网络的 l o s s loss loss函数转化为 − l o g ( D ( x ) ) -log(D(x)) −log(D(x))
以上是GAN基础学习中的一些感悟和整理,感谢阅读
智能推荐
第二十章 多线程-程序员宅基地
文章浏览阅读792次,点赞22次,收藏19次。Windows操作系统是多任务操作系统,它以进程为单位。一个进程是一个包含有自身地址的程序,每个独立执行的程序都称为进程。也就是说每个正在执行的程序都是一个进程。系统可以分配给每一个进程有一段有限的使用CPU的时间(也可以称为CPU时间片),CPU在这段时间中执行某个进程,然后下一个时间片又跳至另一个进程中去执行。由于CPU转换比较快,所以使得每个进程好像是同时执行一样。下图表明了Windows操作系统的执行模式创建线程继承Thread类。
【全局敏感性分析】【基于方差的灵敏度指数】【基于密度的灵敏度指数】【不确定性分析】基于累积分布函数的全局敏感性分析的简单高效方法(Matlab代码实现)-程序员宅基地
文章浏览阅读813次,点赞22次,收藏22次。基于方差的灵敏度指数在不同环境建模领域的GSA应用中越来越受欢迎(例如,参见Pastres等人,1999年;Nossent等人,2011年;然而,在输出分布高度倾斜或具有多峰性的情况下,考虑模型输出的整个概率密度函数(PDF),而不仅是其方差的方法,更为合适,因为方差可能无法充分代表不确定性。我们期望PAWN能够促进基于密度的方法的应用,并作为基于方差的GSA的补充方法。全局敏感性分析(GSA)是一组数学技术,旨在评估不确定性通过数值模型的传播,特别是理解不同不确定性来源对模型输出变异性的相对贡献。
c#表达式树实现浅拷贝对象_c# copy objects 表达式树-程序员宅基地
文章浏览阅读657次。浅拷贝对象对比手写的Copy方法100万次耗时对比(CPU是 i7 - 4710MQ)static void Main(string[] args){ var value = new TestClass { Age = 18, Name = "张三", Sex = Gender.Man }; Console.Wri..._c# copy objects 表达式树
keras提取模型中的某一层_Tensorflow笔记:高级封装——Keras-程序员宅基地
文章浏览阅读1.9k次,点赞4次,收藏8次。前言之前在《Tensorflow笔记:高级封装——tf.Estimator》中介绍了Tensorflow的一种高级封装,本文介绍另一种高级封装Keras。Keras的特点就是两个字——简单,不用花时间和脑子去研究各种细节问题。1. 贯序结构最简单的情况就是贯序模型,就是将网络层一层一层堆叠起来,比如DNN、LeNet等,与之相对的非贯序模型的层和层之间可能存在分叉、合并等复杂结构。下面通过一个Le..._tf2 model提取某层
FCN全卷积网络理解及代码实现(来自pytorch官方实现)_fcn代码-程序员宅基地
文章浏览阅读1w次,点赞12次,收藏113次。FCN是首个端对端的针对像素级预测的全卷积网络而换为卷积层之后,最后得到的是1000通道的2D图像,可以可视化为heat map图。一般说的vgg16是D:全连接操作前后:77512(通道)【假设忽略偏置】\color{red}{【假设忽略偏置】}【假设忽略偏置】全连接FC1计算:计算对应某一个结点的输出,将该节点与上一层某一个结点的权重与输入对应节点数值相乘,再求和下层使用7*7的卷积核、stride=1,4096个卷积核的一个卷积层一个卷积核和FC1一个节点参数量一样\color{red}{一_fcn代码
Nextcloud自动清理回收站_nextcloud回收站自动清理-程序员宅基地
文章浏览阅读2.3k次。Nextcloud自动清理回收站注意,本文Nextcloud为snap安装的,如果是手动安装也不会麻烦那么多了。然后也没有添加www-data这样的用户对应该Nextcloud的权限,全是管理员权限,如和您安装的方式与设置不一样导致其它bug也是没办法的事。本文仅作自留档,毕竟已经折腾Nextcloud两次了。首先是如果想手动清空的话,比如以下命令清空所有用户的回收站sudo nextcloud.occ trashbin:cleanup -all-users但如果要自动清除呢?以下参考https:_nextcloud回收站自动清理
随便推点
医院网络建设和综合布线设计_医院网络规划设计-程序员宅基地
文章浏览阅读1k次,点赞3次,收藏14次。通常情况下,可以根据用户需求以及建设资金的不同,把其中的几层进行合并后再进行处理。接入层作用:方便用户接入使用,与此同时,接入层还为用户提供了丰富的接入控制以及大量的接口。核心层作用:高速的数据通信交换,提供稳定可靠的冗余性,并且可以不用配置很复杂的策略。现代医院网络的组网一般情况下可以分为三层,依次可以称为:核心层、汇聚层和接入层。汇聚层作用:汇聚层进行流量控制和进行复杂的控制策略,以及要求必要的冗余设计等等。5.2.2测试医院门诊楼访问急诊楼 29。5.2.4测试医院行政楼访问医技楼 30。_医院网络规划设计
【基础知识】~ FIFO-程序员宅基地
文章浏览阅读6.8k次,点赞12次,收藏101次。了解FIFO定义FIFO(First In First Out),即先进先出队列。FIFO存储器是一个先入先出的双口缓冲器,即第一个进入其内的数据第一个被移出,其中一个是存储器的输入口,另一个口是存储器的输出口。对于单片FIFO来说,主要有两种结构:触发导向结构和零导向传输结构。触发导向传输结构的FIFO是由寄存器阵列构成的,零导向传输结构的FIFO是由具有读和写地址指针的双口RAM构成。FPGA 使用的 FIFO 一般指的是对数据的存储具有先进先出特性的一个缓存器,常被用于数据的缓存,或者高速异步数_fifo
QTableView/QTableWeight表头设置自适应列宽_tableweight怎么用-程序员宅基地
文章浏览阅读598次。qt4: tableview->horizontalHeader()->setStretchLastSection(true); tableview->horizontalHeader()->setResizeMode(QHeaderView::Stretch); qt5: /*设置tableview等宽*/ QHeaderView* headerView = ui_tableweight怎么用
WEBRTC之测试STUN/TURN服务器是否可用_turn/stun测试地址、-程序员宅基地
文章浏览阅读7.6k次,点赞2次,收藏6次。可以通过这个地址进行测试:https://webrtc.github.io/samples/src/content/peerconnection/trickle-ice/如果测试的是一个STUN服务器,在连接有效时应该可以收集一个类型为“srflx”的候选者。类似地,对于有效的TURN服务器,可以收集一个类型为“relay”的候选者。..._turn/stun测试地址、
ssm633高校智能培训管理系统分析与设计+vue-程序员宅基地
文章浏览阅读755次,点赞16次,收藏15次。本科毕业设计论文题目:高校智能培训管理系统设计与实现系 别:专 业:班 级:学生姓名:学生学号:指导教师:如今的年代,已经是步入信息社会了,不仅信息更新速度频繁,信息量也大,在信息时代必须有相应的处理信息的方法,如果还采用以前的结绳记事或者笔写纸记,不仅是信息录入效率上赶不上节奏,在信息检索的速度上更是让人无法承受。幸而当今社会上计算机技术发展的相当不错,可以通过计算机在信息处理上面实现自动化或者半自动化的作业,采用计算机技术,能有效的提高信息录入以及信息检索的效率,社会上相同行业之间本身
使用Chrome插件搭建本地的临时服务器,快速上手!_chrome plugin 开启server-程序员宅基地
文章浏览阅读1.6k次。一秒变http服务器,轻松传资源,解决以下三个问题:静态网站文件列表下载其他设备可以拖动上传文件临时服务器用处很大呀,比如临时上传下载个文件、看一张照片、播放一段视频等等。Web Server for Chrome 就能实现,只需要运行以后,打开 Web Server:第一步:打开Chrome网上应用商店地址:https://chrome.google.com/webstore/detail/web-server-for-chrome/ofhbbkphhbklhfoeikjpcbhemlo_chrome plugin 开启server