使用python3爬取网页,利用aria2下载电影,Jellyfin自动更新最新电影_jellyfin自动播放下一集-程序员宅基地
前言:在我搭建好Jellyfin软件后,因为只能播放本地视频,就想能不能播放网络上的电影,可以每天自动下载并更新,这样就不用我手工下载好,再上传到NAS中播放。或许有更好的方法,那就是直接用电影播放源,那就有个问题了,没有那个视频网愿意给播放源,所以还是自己慢慢下载后再播放吧。个人对于python语言也是小白,在网络上寻找大神的脚本稍加修改得到的。
如果需要搭建jellyfin,请看我之前的博客-家庭影院Jellyfin搭建,linux网页视频播放器。
环境:centos7
工具:python3、jellyfin、shell脚本、aria2
1、安装python3
默认安装好centos7系统后,自带有python2.7.5的版本,所以需要安装python3的版本。2.7.5的版本不能删除,否则centos系统会崩溃。请从官网下载python3.8版本。
关于python2升级至python3,会有一些问题,但都能解决,请参考以下资料:
2)pbzip2: error while loading shared libraries: libbz2.so.1.0: cannot open shared object file
3)centos7安装python3及其配置pip(建立软连接)
2、编辑python脚本
命名脚本为movie.py,将以下复制到py脚本保存,执行python3 movie.py。查看爬取结果,是否生成文件。
脚本不是我编写的,是借鉴大神,然后根据电影天堂现在的地址和信息,做了一些改动,获取下载电影地址
# encoding: gbk
# 我们用到的库
import requests
import bs4
import re
import pandas as pd
def get_data(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = 'gbk'
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取电影列表
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
# 对电影列表中的每一部电影单独处理
for item in tbList:
movie = []
link = item.b.find_all('a')[0]
# 获取电影的名称
name = link.string
# 获取详情页面的 url
url = 'https://www.dytt8.net' + link["href"]
# 将数据存放到电影信息列表里
movie.append(name)
movie.append(url)
try:
# 访问电影的详情页面,查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('a')
print(tbody)
#^magnet.*?fannouce
# 下载链接有多个(也可能没有),这里将所有链接都放进来
for i in tbody:
lines = i.get("href")
if "magnet" in lines:
#download = lines.a.text
#print(lines)
movie.append(lines)
print(movie)
# 将此电影的信息加入到电影列表中
info.append(movie)
except Exception as e:
print(e)
return info
def save_data(data):
'''
功能:将 data 中的信息输出到文件中/或数据库中。
参数:data 将要保存的数据
'''
filename = 'C:/Users/Administrator/Desktop/movie.txt'
dataframe = pd.DataFrame(data)
dataframe.to_csv(filename, mode='a', index=False, sep=';', header=False)
def main():
# 循环爬取多页数据
#for page in range(1, 114):
# print('正在爬取:第' + str(page) + '页......')
# 根据之前分析的 URL 的组成结构,构造新的 url
#if page == 1:
# index = 'index'
#else:
# index = 'index_' + str(page)
# url = 'https://www.dy2018.com/2/'+ index +'.html'
#url='https://www.dy2018.com/2/index.html'
url='https://www.dytt8.net/html/gndy/dyzz/index.html'
# 依次调用网络请求函数,网页解析函数,数据存储函数,爬取并保存该页数据
html = get_data(url)
movies = parse_data(html)
save_data(movies)
#print('第' + str(page) + '页完成!')
if __name__ == '__main__':
print('爬虫启动成功!')
main()
print('爬虫执行完毕!')
3、安装aria2
安装教程,请访问我的博客第一条,安装nextcloud里面有详细的安装aria2教程
4、编写aria2下载的shell脚本
#!/bin/bash
cd /downloads
count=0
#/root/shell/movie.txt,这个地址是movie.py执行后生成的下载地址,请根据你实际的地址填写
route=/root/shell/movie.txt
name=(`awk -F ";" '{print $1}' $route | cut -d '《' -f2|cut -d '》' -f1 | cut -d '/' -f1`)
addr=(`awk -F ";" '{print $3}' $route`)
nr=`awk '{print NR}' $route | tail -n1`
prop=`awk -F ";" '{print $3}' $route | cut -d '&' -f2 | awk -F "." '{print $8}'`
for ((i=0; i<=nr; i++))
do
let count++
echo "正在下载第$count个电影,《${name[$i]}》"
sudo -u www nohup aria2c -o "${name[$i]}.${prop[$i]}" "${addr[$i]}" &
echo "第$count个电影完成创建,转后台下载中"
sleep 2
done
rm -rf /root/shell/movie.txt5、测试
执行脚本,请注意先后顺序,先执行python3 movie.py。等待爬取下载电影地址完成后,执行sh movie.sh。
6、增加自动任务,添加到crontab
crontab -e中增加以下信息,获取这个方法不完善,但仍在改进
#每2天运行python脚本,获取电影天堂下载地址
20 1 */2 * * python3 /root/shell/movie.py
#每2天运行一次aria2下载电影
30 1 */2 * * sh /root/shell/movie.sh
7、使用jellyfin添加媒体库
在这里,把媒体库的自动扫描调整为每个小时都扫描一次,这样可以很快的增加到媒体库。
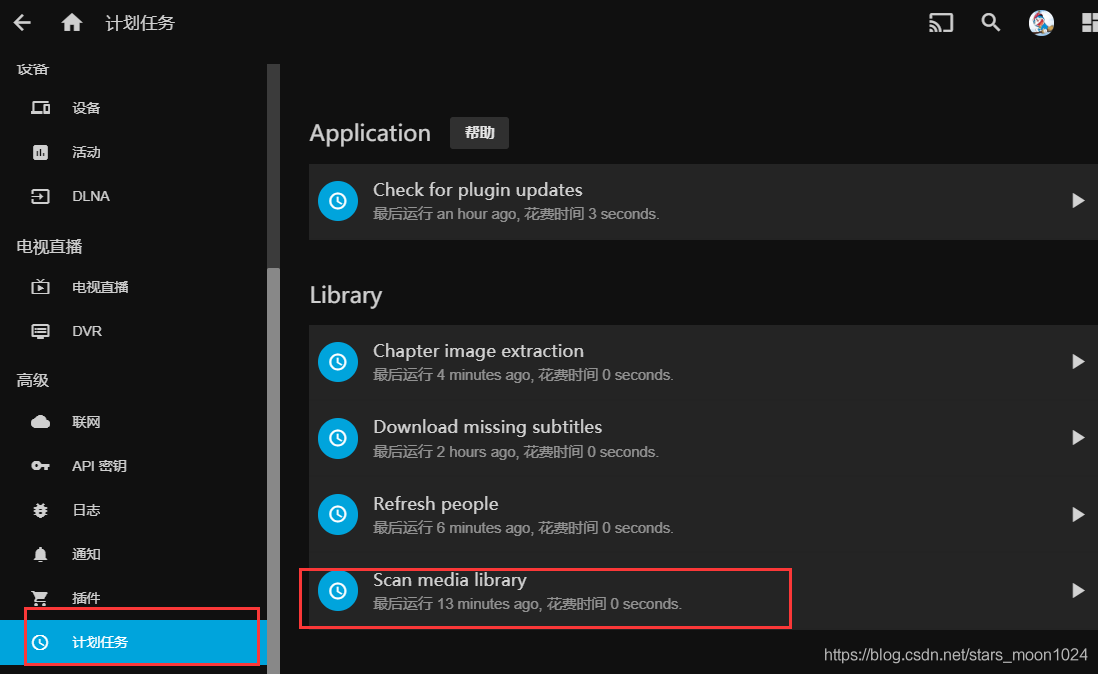
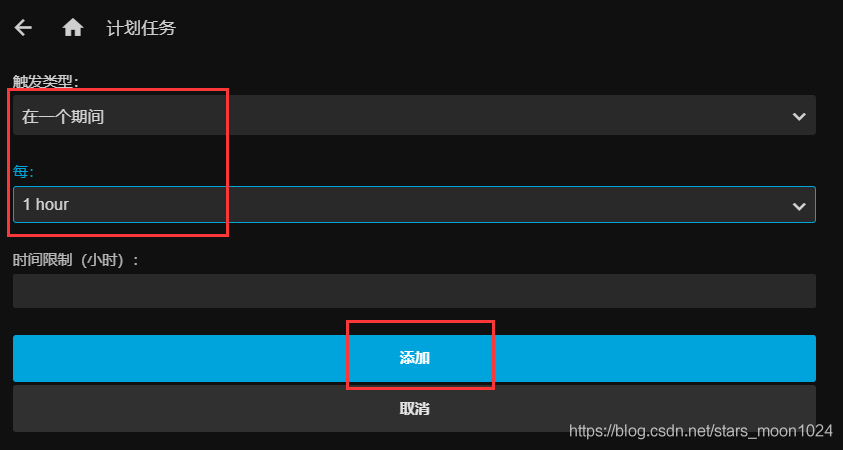
至此,已经完成了自动从电影网下载电影,并自动扫描到媒体库,就可以不用管了,每2天自动更新。写的脚本只下载了详情页的第一页,如果想下载很多页,请把主方法中的循环打开调整数字就可以了
智能推荐
AVFrame&AVPacket_天天av-程序员宅基地
文章浏览阅读1.5w次。AVFrame:( This structure describes decoded (raw) audio or video data. AVFrame must be allocated using av_frame_alloc(). Note that this only allocates the AVFrame itself, the buffers for the data mus_天天av
Java经典例题07:用100元人民币兑换10元、5元、1元的纸币_编程把100元换成1元5元10元-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏12次。解题思路分析:1.100元兑换10元纸币,可以兑换10张,但每种纸币都要有,所以最多只能兑换9张,最少兑换1张。则初始值为1;循环条件小于10或者小于等于9。2.100元兑换5元纸币,可以兑换20,但每种纸币都要有,所以最多只能兑换19张,最少兑换1张。初始值为1;循环条件小于20或者小于等于19。3.100元兑换1元纸币,可以兑换100张,但每种纸币都要有,所以最多只能兑换99张,最少兑换1张。则初始值为1;循环条件小于100或者小于等于99。_编程把100元换成1元5元10元
猜三次年龄_找人猜三次年龄-程序员宅基地
文章浏览阅读450次。1、允许用户最多尝试三次2、每尝试三次后,如果还没猜对,就问用户是否继续玩,如果回答Y,y,就继续猜三次,以此往复,如果回答N,n,就直接退出times=0count=3while times<=3:age=int(input(‘请输入年龄:’))if age == 18:print(‘猜对了’)breakelif age > 18:print(‘猜大了’)else:print(‘猜小了’)times+=1if times3:choose = input(‘继续猜Y_找人猜三次年龄
SDOI2017 Round2 详细题解-程序员宅基地
文章浏览阅读152次。这套题实在是太神仙了。。做了我好久。。。好多题都是去搜题解才会的 TAT。剩的那道题先咕着,如果省选没有退役就来填吧。「SDOI2017」龙与地下城题意丢 \(Y\) 次骰子,骰子有 \(X\) 面,每一面的概率均等,取值为 \([0, X)\) ,问最后取值在 \([a, b]\) 之间的概率。一个浮点数,绝对误差不超过 \(0.013579\) 为正确。数据范围每组数据有 \...
嵌入式数据库-Sqlite3-程序员宅基地
文章浏览阅读1.1k次,点赞36次,收藏25次。阅读引言: 本文将会从环境sqlite3的安装、数据库的基础知识、sqlite3命令、以及sqlite的sql语句最后还有一个完整的代码实例, 相信仔细学习完这篇内容之后大家一定能有所收获。
C++ Builder编写WinForm从Web服务器下载文件-程序员宅基地
文章浏览阅读51次。UnicodeString templateSavePath = ChangeFileExt(ExtractFilePath(Application->ExeName),"tmp.doc");IdAntiFreeze1->OnlyWhenIdle = false;//设置使程序有反应.TMemoryStream *templateStream ;templateStre..._c++webserver下载文件
随便推点
JAVA小项目潜艇大战_java潜艇大战-程序员宅基地
文章浏览阅读8.3k次,点赞10次,收藏41次。一、第一天1、创建战舰、侦察潜艇、鱼雷潜艇、水雷潜艇、水雷、深水炸弹类完整代码:package day01;//战舰public class Battleship { int width; int height; int x; int y; int speed; int life; void move(){ System.out.println("战舰移动"); }}package day01;//侦察潜艇_java潜艇大战
02表单校验的基本步骤-程序员宅基地
文章浏览阅读940次。表单校验的基本步骤_表单校验
libOpenBlas.dll缺失依赖解决办法-程序员宅基地
文章浏览阅读4.5k次。libOpenBlas.dll缺失依赖解决办法 intellij idea 1.dll文件缺失依赖,报错:“找不到指定模块”2.下载depends查看dll缺失文件3.下载缺失依赖libopenblas.dll出错起因由于java web项目需要调用openBlas库来进行运算,就下载了预编译的libopenblas文件进行调用,首先遇到路径出错问题、之后又是dll文件缺失依赖问题,以下是解决..._libopenblas.dll
Swoole 实践篇之结合 WebSocket 实现心跳检测机制-程序员宅基地
文章浏览阅读251次,点赞3次,收藏10次。这里实现的心跳检测机制是一个基础版的,心跳包的主要作用是用于检测用户端是否存活,有助于我们及时判断用户端是否存在断线的问题。在我之前开发过的项目中,有一个基于物联网在线直播抓娃娃的项目,其中就有需要实时监控设备在线状态的需求,该需求就是使用心跳包来实现的。实际上心跳检测技术,应用更广泛的是实时通信、或设备管理的场景偏多。
Maven dependency scope_maven dependent scope-程序员宅基地
文章浏览阅读714次。Dependency scope is used to limit the transitivity of a dependency, and also to affect the classpath used for various build tasks.There are 6 scopes available:compileThis is the default scop_maven dependent scope
TCP头部结构信息_tcp头部包含哪些信息-程序员宅基地
文章浏览阅读3.6k次。TCP 头部结构信息_tcp头部包含哪些信息