NNLM Word2Vec FastText LSA Glove 总结_word2vec 和 nnlm 对比有什么区别?-程序员宅基地
NNLM(Neural Network Language Model)
顾名思义,就是神经网络语言模型,本质就是语言模型。word2vec也可以看成一种语言模型,但是为了计算的效率,把神经softmax给拿掉了,下面稍详细写写word2vec
Word2Vec
Word2Vec的结构如下图,假设输入词库的大小是V,每个词都用one-hot来表示,那么每个词的维度就是V。Input layer到Hidden layer之间用一个全连接网络相连,如果Hidden layer有N层,那么参数就是VN。而Output layer最终也是V维,因此从Hidden layer到Output layer之间的参数是VN。
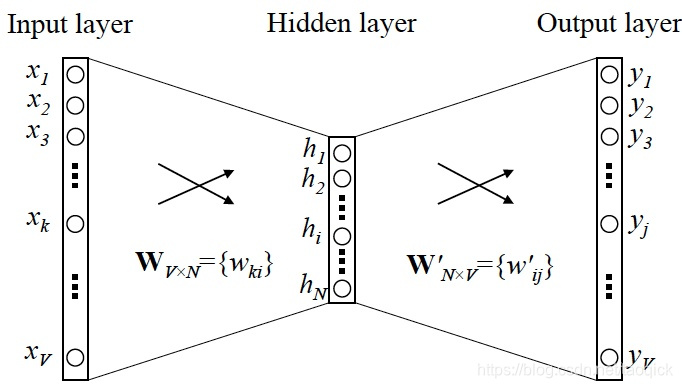
有了这个结构,Word2Vec有两个目标: ∑ w ∈ C l o g ( w ∣ c o n t e x t ) \sum_{w\in C}log(w|context) ∑w∈Clog(w∣context) (Continous bag-of-word)和 ∑ w ∈ C l o g ( c o n t e x t ∣ w ) \sum_{w\in C}log(context|w) ∑w∈Clog(context∣w) (Skip-gram)。当然输出层是一个向量,想把这个向量映射到某个词的概率得用softmax函数 P ( y = x n ∣ x ) = e x n ∑ i = 1 V e x i P(y=x_n|x)=\frac{e^{x_n}}{\sum_{i=1}^Ve^{x_i}} P(y=xn∣x)=∑i=1Vexiexn,其中x为最终输出层输出的向量, x n x_n xn表示x中和单词 w n w_n wn对应的维度的值。
有了这个结构以后,开始用back propagation来求解,但是由于Softmax激活函数中存在归一化项的缘故,推导出来的迭代公式需要对词汇表中的所有单词进行遍历,使得每次迭代过程非常缓慢。这部分推导可以参考word2vec Parameter Learning Explained by Xin Rong,里面非常详细。
为了优化back propagation,word2vec里用了hierarchy softmax,本质是把 N 分类问题变成 log(N)次二分类,但是这种方法还是训练慢。干脆更直接一点用了Negative Sample,实质上对每一个样本中每一个词都进行负例采样。
训练好以后,我们实际上是把隐藏层(Hidden layer也叫projection layer)里的权重拿出来,这样原始的V维one-hot就可以映射成一个N维的向量(N一般在50-300之间)。这个N维的向量有些很好的性质,例如叠加,再比如巴黎-法国=柏林-德国等等。我们在应用中直接load这个word2vec的词表就可以。
FastText
fastText简而言之,就是把文档中所有词通过lookup table变成向量,取平均后直接用线性分类器得到分类结果。
但是比如对下面的三个例子来说:The movie is not very good , but i still like it . [2]The movie is very good , but i still do not like it .I do not like it , but the movie is still very good .其中第1、3句整体极性是positive,但第2句整体极性就是negative。如果只是通过简单的取平均来作为sentence representation进行分类的话,可能就会很难学出词序对句子语义的影响。
这部分转自知乎
作者:董力
链接:https://www.zhihu.com/question/48345431/answer/111513229
LSA
潜在语义分析(Latent Semantic Analysis)可以基于co-occurance matrix构建词向量,实质上是基于全局语料采用SVD进行矩阵分解,然而SVD计算复杂度高,所以潜在语义分析是基于频率的
Glove
GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,说白了就是给共现矩阵降维,但是又不像LSA那么heavy,而是利用目标函数上的技巧来优化计算。
Glove的目标函数是
J = ∑ i , j N f ( X i , j ) ( v i T v j + b i + b j − l o g ( X i , j ) ) 2 J=\sum_{i,j}^Nf(X_{i,j})(v_i^Tv_j+b_i+b_j-log(X_{i,j}))^2 J=i,j∑Nf(Xi,j)(viTvj+bi+bj−log(Xi,j))2
其中f(x)是权重
f ( x ) = ( x / x m a x ) 0.75 , 当 x < x m a x f ( x ) = 1 , 当 x > = x m a x f(x)=(x/xmax)^{0.75}, 当x<xmax\\ f(x)=1, 当x>=xmax f(x)=(x/xmax)0.75,当x<xmaxf(x)=1,当x>=xmax
训练采用了AdaGrad的梯度下降算法,对矩阵X中的所有非零元素进行随机采样,学习曲率(learning rate)设为0.05,在vector size小于300的情况下迭代了50次,其他大小的vectors上迭代了100次,直至收敛。
这个目标函数的脑洞是这样的,两个词向量的乘积 v i T v j v_i^Tv_j viTvj是和 P i , j P_{i,j} Pi,j正相关的,其中 P i , j P_{i,j} Pi,j表示两个词共现的概率。那么
P i , j = X i , j X i = X i , j X i P_{i,j} = \frac{X_{i,j}}{X_i}=\frac{X_{i,j}}{X_i} Pi,j=XiXi,j=XiXi,j
同时希望满足以下除法的关系,因此需要加一下Log: P i , j = X i , k X j , k P_{i,j} = \frac{X_{i,k}}{X_{j,k}} Pi,j=Xj,kXi,k
那么的可以得到
l o g ( P i , j ) = v i T v j l o g ( X i , j ) − l o g ( X i ) = v i T v j l o g ( X i , j ) = v i T v j + b i + b j J = ∑ i , j N f ( X i , j ) ( v i T v j + b i + b j − l o g ( X i , j ) ) 2 log(P_{i,j})=v_i^Tv_j \\ log(X_{i,j})-log(X_{i})=v_i^Tv_j \\ log(X_{i,j}) =v_i^Tv_j+b_i+b_j \\ J=\sum_{i,j}^Nf(X_{i,j})(v_i^Tv_j+b_i+b_j-log(X_{i,j}))^2 log(Pi,j)=viTvjlog(Xi,j)−log(Xi)=viTvjlog(Xi,j)=viTvj+bi+bjJ=i,j∑Nf(Xi,j)(viTvj+bi+bj−log(Xi,j))2
详细目标函数的脑洞和推导可以参考:https://blog.csdn.net/coderTC/article/details/73864097和http://www.fanyeong.com/2018/02/19/glove-in-detail/
各种比较
以下转自知乎:https://zhuanlan.zhihu.com/p/57153934
1、word2vec和tf-idf 相似度计算时的区别?
word2vec 1、稠密的 低维度的 2、表达出相似度; 3、表达能力强;4、泛化能力强;
2、word2vec和NNLM对比有什么区别?(word2vec vs NNLM)
1)其本质都可以看作是语言模型;
2)词向量只不过NNLM一个产物,word2vec虽然其本质也是语言模型,但是其专注于词向量本身,因此做了许多优化来提高计算效率:
与NNLM相比,词向量直接sum,不再拼接,并舍弃隐层;
考虑到sofmax归一化需要遍历整个词汇表,采用hierarchical softmax 和negative sampling进行优化,hierarchical softmax 实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路劲变小;negative sampling更为直接,实质上对每一个样本中每一个词都进行负例采样;
3、 word2vec负采样有什么作用?
负采样这个点引入word2vec非常巧妙,两个作用,1.加速了模型计算,2.保证了模型训练的效果,一个是模型每次只需要更新采样的词的权重,不用更新所有的权重,那样会很慢,第二,中心词其实只跟它周围的词有关系,位置离着很远的词没有关系,也没必要同时训练更新,作者这点非常聪明。
4、word2vec和fastText对比有什么区别?(word2vec vs fastText)
1)都可以无监督学习词向量, fastText训练词向量时会考虑subword;
2)fastText还可以进行有监督学习进行文本分类,其主要特点:
结构与CBOW类似,但学习目标是人工标注的分类结果;
采用hierarchical softmax对输出的分类标签建立哈夫曼树,样本中标签多的类别被分配短的搜寻路径;
引入N-gram,考虑词序特征;
引入subword来处理长词,处理未登陆词问题;
5、glove和word2vec、 LSA对比有什么区别?(word2vec vs glove vs LSA)
1)glove vs LSA
LSA(Latent Semantic Analysis)可以基于co-occurance matrix构建词向量,实质上是基于全局语料采用SVD进行矩阵分解,然而SVD计算复杂度高;
glove可看作是对LSA一种优化的高效矩阵分解算法,采用Adagrad对最小平方损失进行优化;
2)word2vec vs LSA
主题模型和词嵌入两类方法最大的不同在于模型本身。
主题模型是一种基于概率图模型的生成式模型。其似然函数可以写为若干条件概率连乘的形式,其中包含需要推测的隐含变量(即主题)
词嵌入模型一般表示为神经网络的形式,似然函数定义在网络的输出之上。需要学习网络的权重来得到单词的稠密向量表示。
3)word2vec vs glove
word2vec是局部语料库训练的,其特征提取是基于滑窗的;而glove的滑窗是为了构建co-occurance matrix,是基于全局语料的,可见glove需要事先统计共现概率;因此,word2vec可以进行在线学习,glove则需要统计固定语料信息。
word2vec是无监督学习,同样由于不需要人工标注;glove通常被认为是无监督学习,但实际上glove还是有label的,即共现次数[公式]。
word2vec损失函数实质上是带权重的交叉熵,权重固定;glove的损失函数是最小平方损失函数,权重可以做映射变换。
总体来看,glove可以被看作是更换了目标函数和权重函数的全局word2vec。
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法