storm消费kafka实现实时计算_storm+kafka实现实时-程序员宅基地
技术标签: storm offset kafka KafkaSpout 实时计算
大致架构
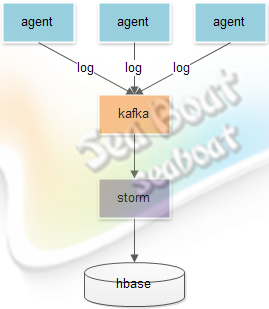
* 每个应用实例部署一个日志agent
* agent实时将日志发送到kafka
* storm实时计算日志
* storm计算结果保存到hbase
storm消费kafka
- 创建实时计算项目并引入storm和kafka相关的依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.0.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>1.0.2</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.2.0</version>
</dependency>- 创建消费kafka的spout,直接用storm提供的KafkaSpout即可。
- 创建处理从kafka读取数据的Bolt,JsonBolt负责解析kafka读取到的json并发送到下个Bolt进一步处理(下一步处理的Bolt不再写,只要继承BaseRichBolt就可以对tuple处理)。
public class JsonBolt extends BaseRichBolt {
private static final Logger LOG = LoggerFactory
.getLogger(JsonBolt.class);
private Fields fields;
private OutputCollector collector;
public JsonBolt() {
this.fields = new Fields("hostIp", "instanceName", "className",
"methodName", "createTime", "callTime", "errorCode");
}
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String spanDataJson = tuple.getString(0);
LOG.info("source data:{}", spanDataJson);
Map<String, Object> map = (Map<String, Object>) JSONValue
.parse(spanDataJson);
Values values = new Values();
for (int i = 0, size = this.fields.size(); i < size; i++) {
values.add(map.get(this.fields.get(i)));
}
this.collector.emit(tuple, values);
this.collector.ack(tuple);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(this.fields);
}
}- 创建拓扑MyTopology,先配置好KafkaSpout的配置SpoutConfig,其中zk的地址端口和根节点,将id为KAFKA_SPOUT_ID的spout通过shuffleGrouping关联到jsonBolt对象。
public class MyTopology {
private static final String TOPOLOGY_NAME = "SPAN-DATA-TOPOLOGY";
private static final String KAFKA_SPOUT_ID = "kafka-stream";
private static final String JsonProject_BOLT_ID = "jsonProject-bolt";
public static void main(String[] args) throws Exception {
String zks = "132.122.252.51:2181";
String topic = "span-data-topic";
String zkRoot = "/kafka-storm";
BrokerHosts brokerHosts = new ZkHosts(zks);
SpoutConfig spoutConf = new SpoutConfig(brokerHosts, topic, zkRoot,
KAFKA_SPOUT_ID);
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
spoutConf.zkServers = Arrays.asList(new String[] { "132.122.252.51" });
spoutConf.zkPort = 2181;
JsonBolt jsonBolt = new JsonBolt();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(KAFKA_SPOUT_ID, new KafkaSpout(spoutConf));
builder.setBolt(JsonProject_BOLT_ID, jsonBolt).shuffleGrouping(
KAFKA_SPOUT_ID);
Config config = new Config();
config.setNumWorkers(1);
if (args.length == 0) {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(TOPOLOGY_NAME, config,
builder.createTopology());
Utils.waitForSeconds(100);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
} else {
StormSubmitter.submitTopology(args[0], config,
builder.createTopology());
}
}
}- 本地测试时直接不带运行参数运行即可,放到集群是需带拓扑名称作为参数。
- 另外需要注意的是:KafkaSpout默认从上次运行停止时的位置开始继续消费,即不会从头开始消费一遍,因为KafkaSpout默认每2秒钟会提交一次kafka的offset位置到zk上,如果要每次运行都从头开始消费可以通过配置实现。
========广告时间========
公众号的菜单已分为“分布式”、“机器学习”、“深度学习”、“NLP”、“Java深度”、“Java并发核心”、“JDK源码”、“Tomcat内核”等,可能有一款适合你的胃口。
鄙人的新书《Tomcat内核设计剖析》已经在京东销售了,有需要的朋友可以购买。感谢各位朋友。
=========================
欢迎关注:

智能推荐
网络分流器|高速骨干网流量采集与分流实现-程序员宅基地
文章浏览阅读202次。网络分流器|高速骨干网流量采集与分流实现方案1 流量采集|网络分流器所谓流量采集,就是将网络流量通过物理层、数据链路层的信号解析和解帧,实现IP原始报文的获取。骨干网流量采集系统是一种对骨干网进行流量获取并分析的系统,主要应用于政府网络管理、运行商广告推送、运行商计费取证服务、运行商信令监控服务、园区网审计、公安网监、大数据分析等领域。2 高速网络流量采集系统|网络分..._流上报 分流器 doc
ESP32 (UART 接收发送)-串口之接收发送通讯(4)_esp32接收发送16进制指令-程序员宅基地
文章浏览阅读9.7k次,点赞8次,收藏54次。提示:本博客作为学习笔记,有错误的地方希望指正文章目录一、ESP32串口介绍二、硬件设计三、实现代码四、串口实验演示结果五、ESP32串口函数API5.1、uart_types.h文件中的内容的API5.2、在uart.h文件中的内容的API一、ESP32串口介绍 UART 是一种以字符为导向的通用数据链,可以实现设备间的通信。异步传输的意思是不需要在发送数据上添加时钟信息。这也要求发送端和接收端的速率、停止位、奇偶校验位等都要相同,通信才能成功。 一个典型的 UART 帧开始于一个起始位,紧接_esp32接收发送16进制指令
第4章 学习Shader所需的数学基础(下)(坐标空间及其变换)_扩展到齐次坐标空间-程序员宅基地
文章浏览阅读580次。版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 ..._扩展到齐次坐标空间
插入排序、冒泡排序、选择排序、快速排序、归并排序、堆排序-程序员宅基地
文章浏览阅读345次。插入排序、冒泡排序、选择排序、快速排序
【Linux】Bonding配置,管理-程序员宅基地
文章浏览阅读217次。1 通过Ifenslave手动配置Bonding该方法适用于某些发行包,它们的网络初始化脚本(sysconfig或initscripts包)没有bonding相关的知识。SuSE Linux Enterprise Server 版本8就是这样的一个发行包。对于这些系统一般的方法是,把bonding模块的参数放进/etc/modules.conf或..._echo "all" > /sys/class/net/bond0/bonding/arp_validate echo "100" > /sys
Tableau工作表的筛选器如何一键应用到该工作表所在的工作簿的所有表_tableau更换筛选器后怎么添加到汇总表里-程序员宅基地
文章浏览阅读2.3k次。很简单,看图:_tableau更换筛选器后怎么添加到汇总表里
随便推点
js-01-程序员宅基地
文章浏览阅读103次。<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8"> <title>Title</title> <script type="text/javascript"> /** * 局部变量,函数内生效;函数外失效!(非要实现,研究闭包!) */ function aa.
程序员面试被要求徒手写代码?你与顶级程序员差别就在这!_自从自己入职稳定以后,就一直在整理自己这一段时间自己的经历,想要写下来。今天是-程序员宅基地
文章浏览阅读346次。在面试中,你被要手写代码,原本自信心爆棚的你突然间提笔忘字。在一张纸上反复涂涂画画,最后勉强的写出了一个功能。结果却漏洞百出。面试过程相当不顺利,丢下笔,敷衍的结束了这场面试,回去对周围的朋友苦涩地说:这都什么时代了,还要求手写代码?这家公司落后了。然而,这就是你与顶级程序员最根本的差距。那么顶级程序员们手写代码都特别厉害吗?随便一动笔就是行云流水,一泻千里?不不不!也许,他们根本就没手写过代..._自从自己入职稳定以后,就一直在整理自己这一段时间自己的经历,想要写下来。今天是
【c++】rand()随机函数的应用(二)——舒尔特方格数字的生成_山东大学c++舒尔特方格代码-程序员宅基地
文章浏览阅读800次。本例提出了一种新的方法实现不同维数舒尔特方格的生成方法,需要用到rand()、srand()函数,在算法上采用动态取模方法。_山东大学c++舒尔特方格代码
android输入法好用,安卓手机输入法哪个最好用?-程序员宅基地
文章浏览阅读2.5k次。纵观目前的安卓手机输入法,已经获得大多数用户认可的有以下四种:搜狗输入法、百度输入法、QQ输入法,以及讯飞语音输入法。但是这四种安卓手机输入法哪个最好用?谁的联想最完美,稳定性和兼容性最强?今天,凌少就通过四种输入法的详细对比介绍,来告诉大家,到底安卓手机输入法哪个最好用。评测手机:HTC HD2手机系统:Andriod 2.2评测对象:搜狗输入法、百度输入法、QQ输入法,以及讯飞口讯语音输入法手..._安卓手机好用的输入法
Kibana:创建你的第一个仪表板_kinaba仪表盘-程序员宅基地
文章浏览阅读2.8k次,点赞4次,收藏4次。了解从你自己的数据创建仪表板的最常用方法。本教程将从分析师查看网站日志的角度使用示例数据,但这种类型的仪表板适用于任何类型的数据。完成后,你将全面了解示例 Web 日志数据。在本次的展示中,我将使用最新的 Elastic Stack 8.7.1 来进行展示。_kinaba仪表盘
layui table表格带图片,图片显示不全问题_layui表格图片显示不全-程序员宅基地
文章浏览阅读9.8k次,点赞10次,收藏30次。这个平时没有注意过,今天有人问到,就记录一下吧layui的表格使用非常简单,layui文档中已经非常详细,下面直接上代码了1.jsp代码 <div class="demoTable"> <button class="layui-btn" data-type="publish">发布Banner</button> </..._layui表格图片显示不全