公司的CDH早就装好了,一直想自己装一个玩玩,最近组了台电脑,笔记本就淘汰下来了,加上之前的,一共3台,就在X宝上买了CPU和内存升级了下笔记本,就自己组了个集群。
话说,好想去捡垃圾,捡台8核16线程64G内存的回来,手动滑稽。
3台笔记本的配置和角色分配:
宿主CPU 宿主内存 虚拟机 虚拟机CPU/台 角色及内存
双核双线程 4G 1台 双核双线程 nexus、yum、ntp、svn
双核四线程 8G 2台 双核四线程 master(4G)、node01(2G)
双核四线程 8G 3台 双核四线程 node02、node03、node04(各2G)
双核四线程 8G 1台 双核四线程 master(6G)
双核四线程 8G 2台 双核四线程 node01、node02(各3G)
虚拟机的网卡都使用桥接模式,保证在同一网段下。
双核双线程那台本想也虚拟出2台来,但实在太老了,就给集群当个通用服务器吧。
试安装的时候,原本想整个7个节点,每个给2G,但master给2G,根本不够用,卡得要死,空余内存就20多M,所以建议master给4G以上,我也就只能整5台了。
master给4G,选择安装所有服务也是不够的,最后的时候一共10步骤,执行到第八步会报错,网上老司机对这个错误解释是内存不足,所以只给4G的话就少装点服务吧,给了6G可以装所有服务。
另据 hyj 所述,master上要装mysql,小于4G可能会出现未知错误。
感觉CDH比Apache原生的Hadoop多吃好多内存,毕竟要起服务管理和监控。
我安装过程中参考了很多教程,主要参考了 hyj 写的:http://www.aboutyun.com/thread-9086-1-1.html,感谢 hyj 和其它小伙伴的教程。
因为我装的是5.9版,与 hyj 装的5.0稍有出入,本篇算是对 hyj 教程的补充和更新,并加入了个人的心得总结(采坑填坑)。
PS:善用虚拟机的快照功能。
本文命令一律使用root用户,非root用户,请设置sudo。
〇、安装文件准备
Cloudera Manager 5.9:http://archive-primary.cloudera.com/cm5/cm/5/cloudera-manager-el6-cm5.9.0_x86_64.tar.gz
CDH5.9 主文件:http://archive-primary.cloudera.com/cdh5/parcels/5.9.0.23/CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel
CDH5.9 sha文件:http://archive-primary.cloudera.com/cdh5/parcels/5.9.0.23/CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel.sha1
manifest 文件:http://archive-primary.cloudera.com/cdh5/parcels/5.9.0.23/manifest.json
一、虚拟机准备
系统用的是Centos6.8的Minimal安装(事实证明,最小安装也是个坑啊~),常规的设置或最小安装不带的软件,诸如:设置ip地址,hosts,ssh免密登录,scp,sudo,关闭防火墙,yum,ntp时间同步,我这不再叙述(可参考hyj的文章),这些是安装CDH的基础,请务必设置好。
虚拟机我用的完整克隆,这样网络会不可用,解决方案如下:
1、修改hostname
vi /etc/sysconfig/network
NETWORKING=yes HOSTNAME=node02
2、修改ip
vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0 TYPE=Ethernet ONBOOT=yes NM_CONTROLLED=yes BOOTPROTO=static IPADDR=192.168.2.102 PREFIX=24 GATEWAY=192.168.2.99
3、删除旧网卡
vi /etc/udev/rules.d/70-persistent-net.rules
可以看到会有2张PCI device网卡,删除eth0那行,再把eth1的那行里的"eth1"改成"eth0"。
4、重启
reboot
二、实用shell脚本
本文除特别说明,都是在master机上操作
0、节点List文件(文件名nodes,不将master列在其中,不然下面的scp脚本会出问题的,详见二-2)
vi nodes node01 node02 node03 node04
1、ssh免密登录批处理(需要同级目录下的nodes文件)
#!/bin/bash PASSWORD=hadoop auto_ssh_copy_id() { expect -c "set timeout -1; spawn ssh-copy-id $1; expect { *(yes/no)* {send -- yes\r;exp_continue;} *assword:* {send -- $2\r;exp_continue;} eof {exit 0;} }"; } cat nodes | while read host do { auto_ssh_copy_id $host $PASSWORD }&wait done
2、scp批处理(需要同级目录下的nodes文件),即下文命令中的scp.sh
nodes文件中不能包含master,不然就是master scp到master,scp目录的时候会反复在目录下创建目录再拷贝,直至路径太长而创建失败,然后才scp到node01等
#!/bin/bash cat nodes | while read host do { scp -r $1 $host:$2 }&wait done
3、ssh批处理(需要同级目录下的nodes文件),即下文命令中的ssh.sh
#!/bin/bash cat nodes | while read host do { ssh $host $1 }&wait done
三、Cloudera推荐设置
在试安装的过程,发现Cloudera给出了一些警告,如下图:

身为一个有洁癖的码农,自然是连黄色的感叹号都要消灭的。因此在安装CM/CDH之前就先全部设置好。
1、设置swap空间
vi /etc/sysctl.conf 末尾加上 vm.swappiness=10
使用scp批处理拷贝/etc/sysctl.conf到各节点
./scp.sh /etc/sysctl.conf /etc/
使用ssh批处理生效
./ssh.sh "sysctl -p"
2、关闭大页面压缩
试过只设置defrag,但貌似个别节点还是会有警告,干脆全部设置
vi /etc/rc.local 末尾加上(永久生效) echo never > /sys/kernel/mm/transparent_hugepage/enabled echo never > /sys/kernel/mm/transparent_hugepage/defrag
批处理拷贝
./scp.sh /etc/rc.local /etc/
生效
reboot 或 ./ssh.sh "echo never > /sys/kernel/mm/transparent_hugepage/enabled" ./ssh.sh "echo never > /sys/kernel/mm/transparent_hugepage/defrag"
3、关闭SELinux
Cloudera企业版本支持在SELinux平台上部署,咱们不花钱的还是关掉吧。
文档地址:http://www.cloudera.com/documentation/enterprise/release-notes/topics/rn_consolidated_pcm.html#xd_583c10bfdbd326ba--5a52cca-1476e7473cd--7f8d
说明原文:Cloudera Enterprise is supported on platforms with Security-Enhanced Linux (SELinux) enabled. However, Cloudera does not support use of SELinux with Cloudera Navigator. Cloudera is not responsible for policy support nor policy enforcement. If you experience issues with SELinux, contact your OS provider.
vi /etc/selinux/config
SELINUX=disabled
批处理拷贝
./scp.sh /etc/selinux/config /etc/selinux/
重启
reboot
四、Java安装(安装按照个人习惯)
1、解压并创建软连接
tar -zxvf jdk-8u112-linux-x64.tar.gz -C /opt/program/ ln -s /opt/program/jdk1.8.0_112/ /opt/java
2、设置环境变量
vi /etc/profile 末尾添加 export JAVA_HOME=/opt/java export PATH=$JAVA_HOME/bin:$PATH
3、批处理拷贝
./scp.sh /opt/program/jdk1.8.0_112/ /opt/program/jdk1.8.0_112/ ./scp.sh /etc/profile /etc/
4、生效
./ssh.sh "ln -s /opt/program/jdk1.8.0_112/ /opt/java" ./ssh.sh "source /etc/profile"(此条无效,请在各节点手动执行)
5、设置全局变量(重要,我试安装的时候没加导致CM找不到JAVA_HOME而安装失败)
echo "JAVA_HOME=/opt/java" >> /etc/environment
五、安装Mysql(供CM使用)
1、yum安装Mysql
yum install -y mysql mysql-server mysql-devel
2、设置随系统启动
chkconfig mysqld on
3、启动mysql
service mysqld start
4、设置root用户密码
mysql USE mysql; UPDATE user SET Password=PASSWORD('hdp') WHERE user='root'; FLUSH PRIVILEGES;
exit;
5、设置允许远程登录
mysql -u root -p
hdp
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'hdp' WITH GRANT OPTION;
6、创建CM用的数据库
安装集群时按需创建,详见第七章第13步
--hive数据库 create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci; --oozie数据库 create database oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci; --hue数据库 create database hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
六、安装CM
1、解压到/opt目录下,不能解压到其他地方,因为cdh5的源会默认在/opt/cloudera/parcel-repo寻找,而CM可以按照个人喜好安装
tar -zxvf cloudera-manager-el6-cm5.9.0_x86_64.tar.gz -C /opt/ mv /opt/cm-5.9.0/ /opt/program/ ln -s /opt/program/cm-5.9.0/ /opt/cm
2、将CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel 和 CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel.sha1移动到/opt/cloudera/parcel-repo
这样安装时CM就能直接找到了。
mv CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel.sha1 /opt/cloudera/parcel-repo/
3、将CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel.sha1重命名为CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel.sha(去掉结尾的1)
非常重要。我试安装时,这点遗漏了,导致安装CDH的时候一直刷不出5.9版本。
旧版本好像还需要manifest.json,用manifest.json里的信息来生成*.sha,新版本直接可以下载,也就不用manifest.json了,严谨一点的话可以比对一下。
通过日志发现,没有manifest.json就会去下载,不能访问外网就报错了,但不影响安装CDH,还是mv一下吧
mv manifest.json /opt/cloudera/parcel-repo/
cd /opt/cloudera/parcel-repo/ mv CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel.sha1 CDH-5.9.0-1.cdh5.9.0.p0.23-el6.parcel.sha
4、修改配置文件中的server_host
vi /opt/cm/etc/cloudera-scm-agent/config.ini server_host=master
5、将mysql的JDBC驱动放入CM的lib目录下
JDBC驱动下载:http://dev.mysql.com/downloads/connector/j/
gz和zip都无所谓,最终要的是里面的jar包。
解压获得mysql-connector-java-5.1.40-bin.jar上传到集群。
mv mysql-connector-java-5.1.40-bin.jar /opt/cm/share/cmf/lib/
6、为CM创建数据库
/opt/cm/share/cmf/schema/scm_prepare_database.sh mysql cm -hlocalhost -uroot -phdp --scm-host localhost scm scm scm
7、为每个节点创建cloudera-scm用户
useradd --system --home=/opt/cm/run/cloudera-scm-server --no-create-home --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm
接下来其实可以直接在master上启动服务安装了,但因为其它节点没有CM,最后还是通过远程的yum在线下载再安装,我这设置了内部网络,其它节点是访问不了外网的,所以拷贝CM到其它节点进行完全离线安装。
8、拷贝CM到每个节点
./scp.sh /opt/program/cm-5.9.0/ /opt/program/cm-5.9.0/ ./ssh.sh "ln -s /opt/program/cm-5.9.0/ /opt/cm"
看着滚动着的屏幕,等吧~
PS:我单独搞了个二级路由器给集群当交换机,但用的是无线,这路由器也是个便宜货,scp的时候看了下,速度峰值只有2Mb/s左右,普遍在1.2Mb/s,所以scp的时候特别慢,应该和路由器及笔记本的无线网卡有关(笔记本比较老,无线网卡型号也挺旧)。有线没试,估计会好很多,毕竟100M的有线网卡很早就普及了。所以大的数据量,无线是搞不起来的。大数据搞不了,小数据还是可以搞搞的嘛~小数据要什么分布式集群啊?
所以,大数据处理速度想要快,CPU、内存、网速和IO速度,这几项硬件还是大头啊。大头既然搞不了(关键是没钱),小头还是可以搞搞的嘛~比如:重构啊,序列化啊什么的,下次在这上面试试效果。
拷贝了快1个小时,完了赶紧虚拟机快照一下。
9、在master上启动CM的service服务
/opt/cm/etc/init.d/cloudera-scm-server start
10、在所有你想作为worker的节点上启动CM的agent服务
/opt/cm/etc/init.d/cloudera-scm-agent start
然后就能在http://master:7180/上开始安装CDH了。但因为是刚启动,需要等上个几分钟,才能看到web页面。当然,你电脑快,当我没说0.0
等页面能访问了,看了下master上剩余内存只有300M了。
七、安装CDH(图大部分是以5台节点的时候截的,最后几张是3台节点。图要是看不清楚,可以右击选择"在新标签中查看")
1、使用admin(密码admin)登录

2、勾选然后“继续”
3、按需选择,我选择免费
4、继续

5、因为我们在节点上启动了agent,所以直接点“当前管理的主机”。如果节点上没有CM,只有master上有,这边可以在新主机下去搜索,例如192.168.2.[100-104],但这样最后从节点会去yum在线安装。

6、全部勾上,然后继续

7、选择版本,然后继续
8、开始安装了,等着吧
9、好了之后继续

10、 全部是勾,完美!
这里可能会有各种各样的问题,但每个问题,cloudera都会给出相应的建议,当然也有一些很恶心的黄色感叹号。比如:
我明明JDK都是一个tar.gz解压出来的,它硬说我版本不一致,查看提示发现一个JAVA_HOME是/opt/java,一个是/opt/java/,多了个斜杠他就认为不一致了,我回档快照然后再整就没问题了,这种其实可以直接忽略掉。
所以这边有问题,请仔细看提示,看看是不是哪个漏了或搞错了。
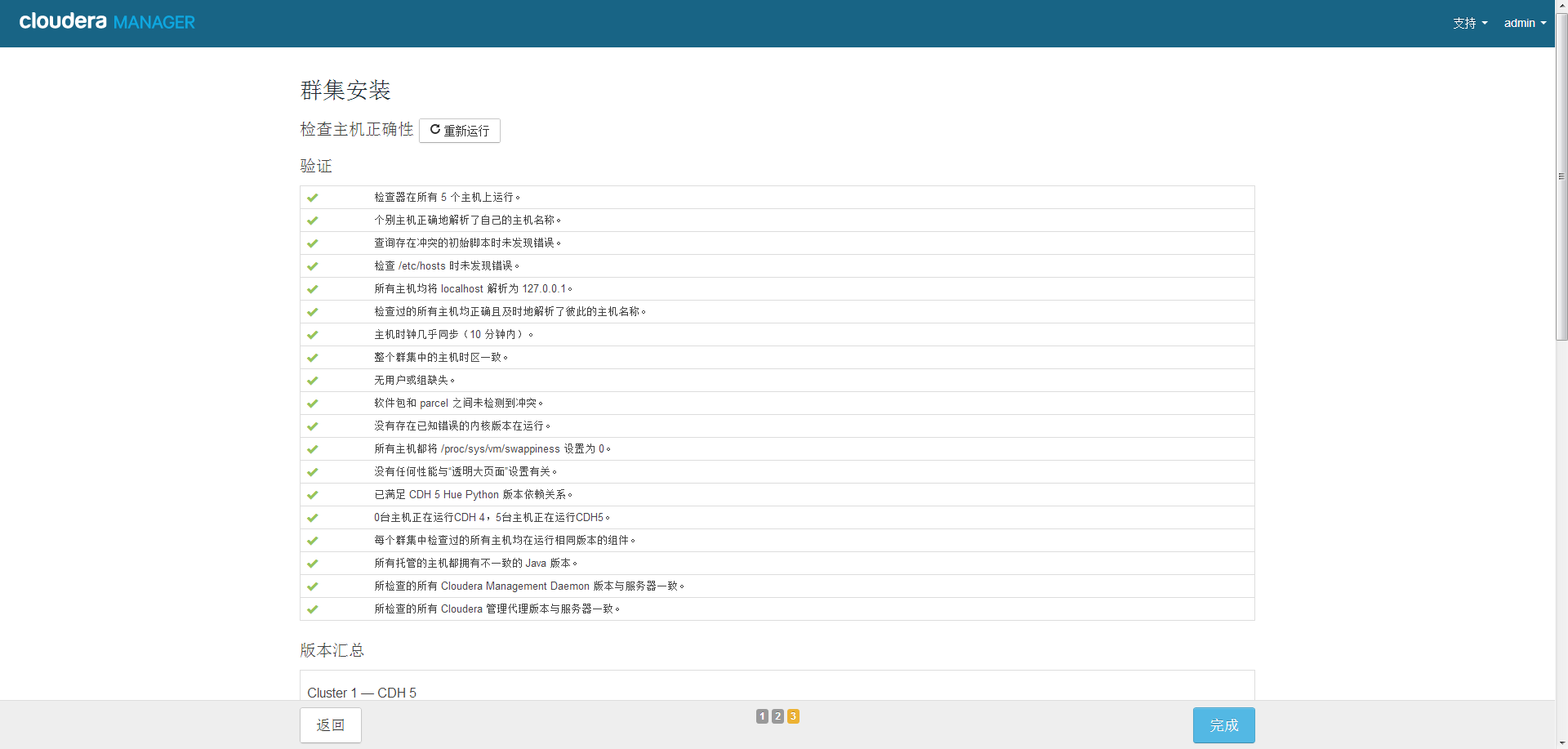
11、集群设置,按需选择
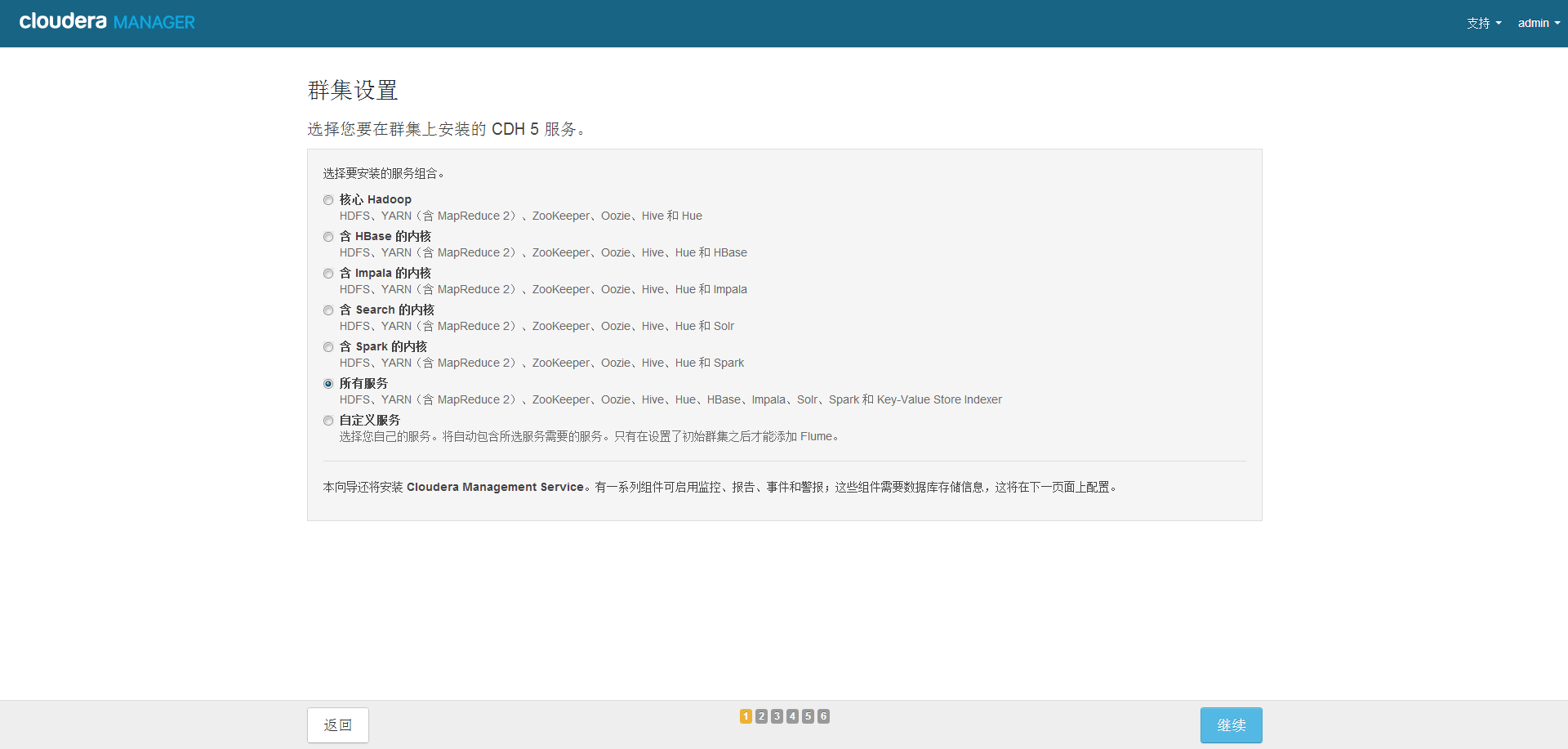
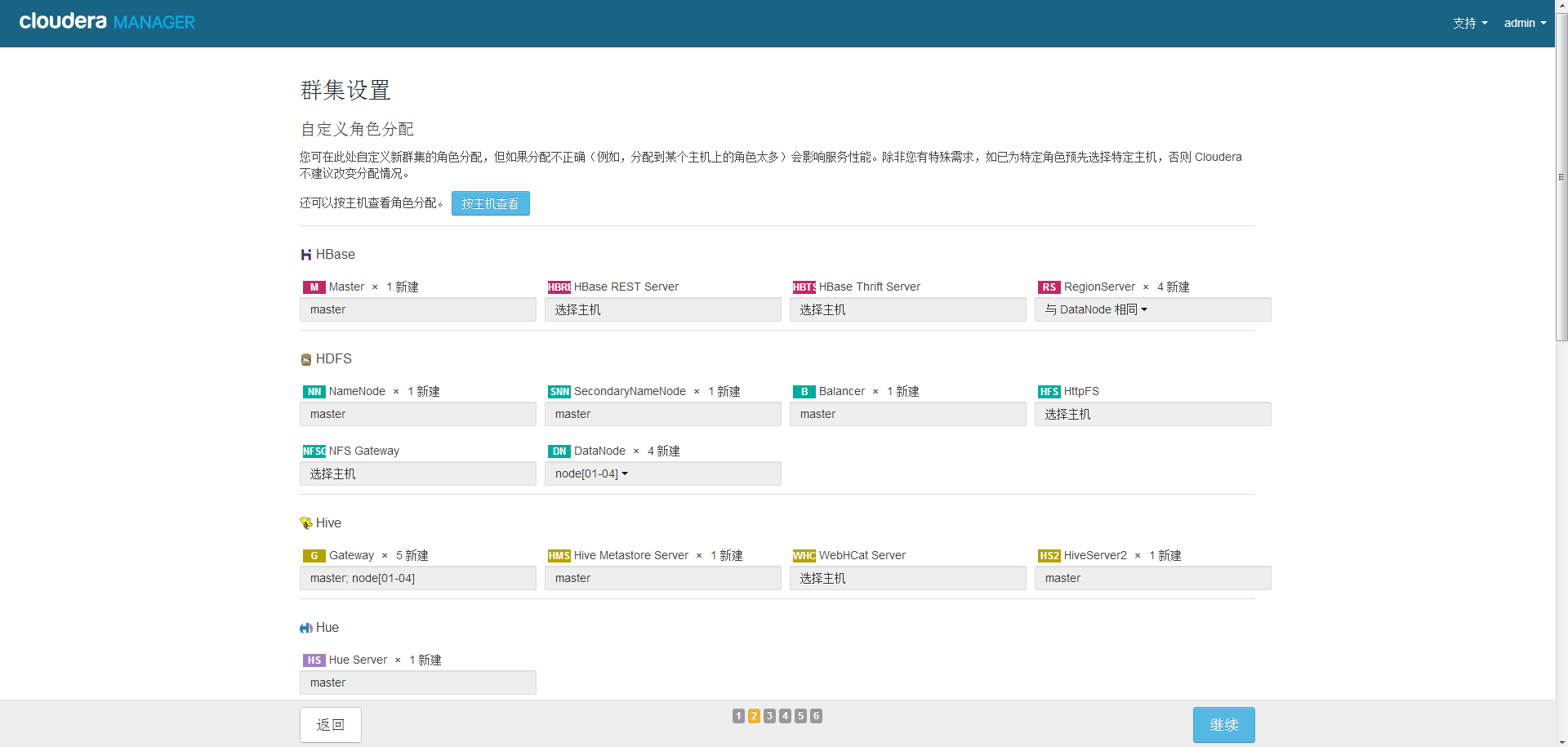
12、角色分配,按需分配
13、创建Mysql数据库并测试(按需创建,比如你没选oozie,就不用创建oozie的数据库)
--hive数据库 create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci; --oozie数据库 create database oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci; --hue数据库 create database hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
这时hue是连不上的,会报错:Unexpected error. Unable to verify database connection.
这是因为我是Centos最小安装,缺了个东西:yum install -y python-lxml
这个坑了我很久,还是在http://www.cnblogs.com/jasondan/p/4011153.html下面的回复里找到的解决方案。感谢那位小伙伴。

14、集群设置
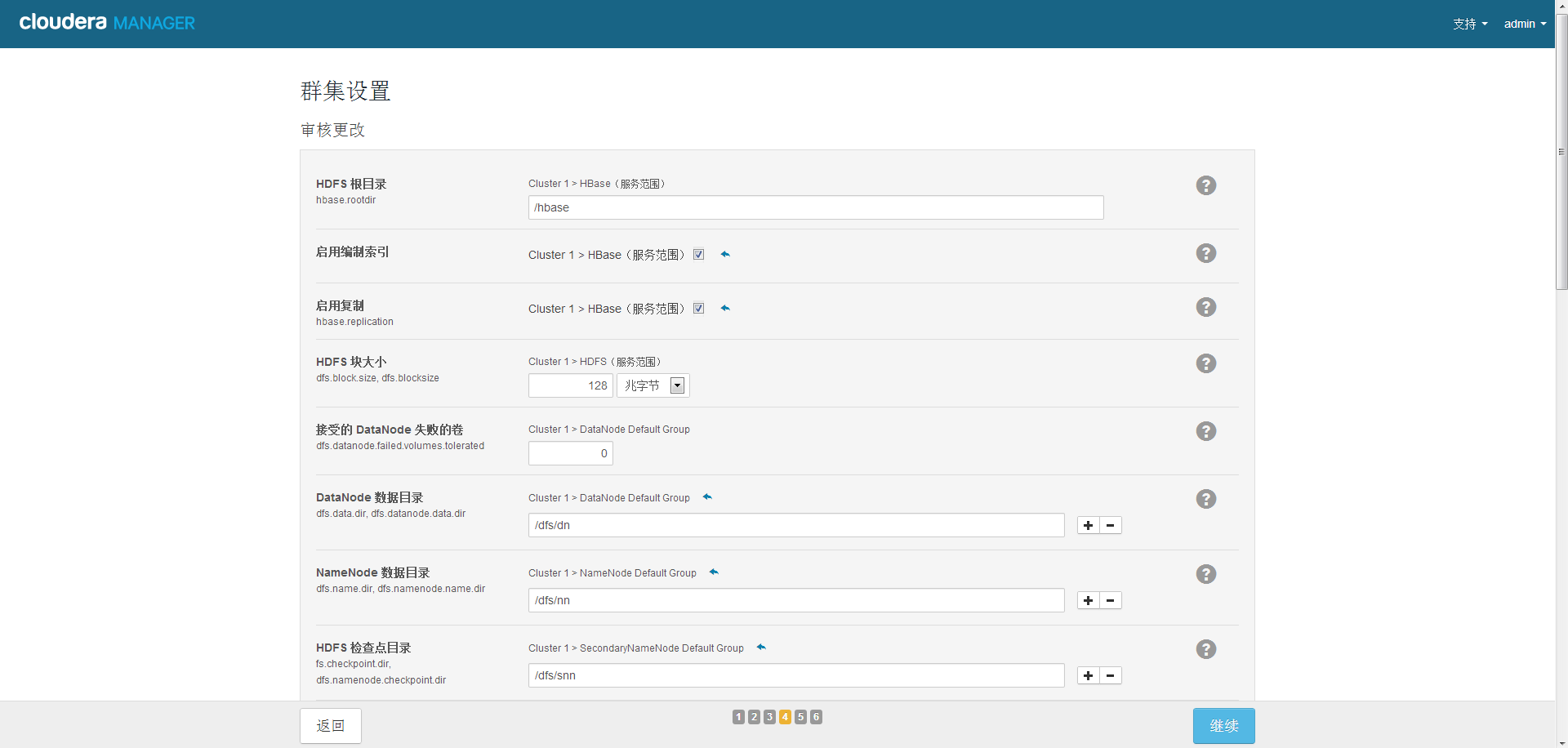
15、报错了,看日志显示没装perl,每个节点都装一下
yum install -y perl
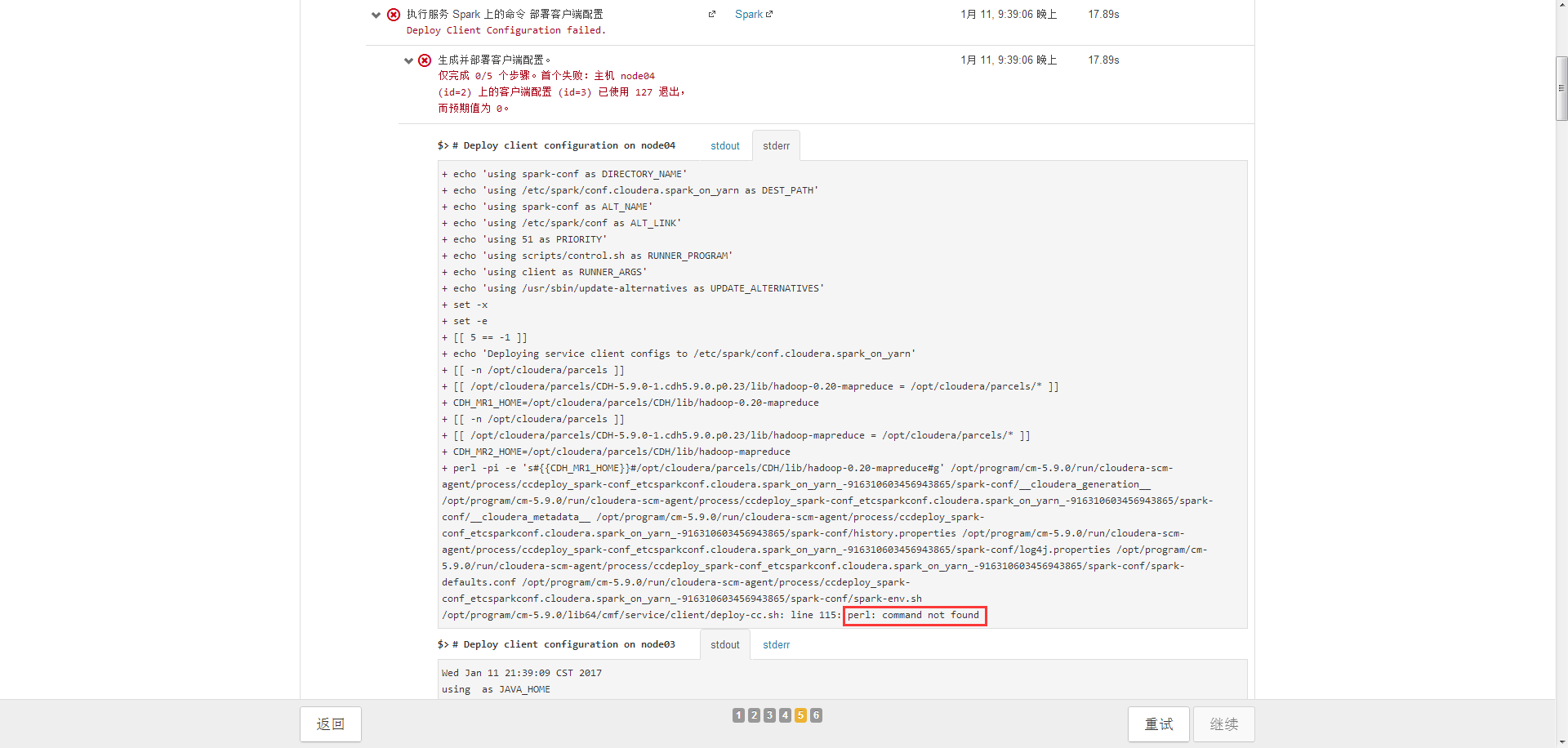
16、然后就让我蛋疼了很久,如下图,JAVA_HOME竟然找不到了,但只是spark找不到,其它hdfs、yarn等都好的,说明我肯定都设置好了啊。
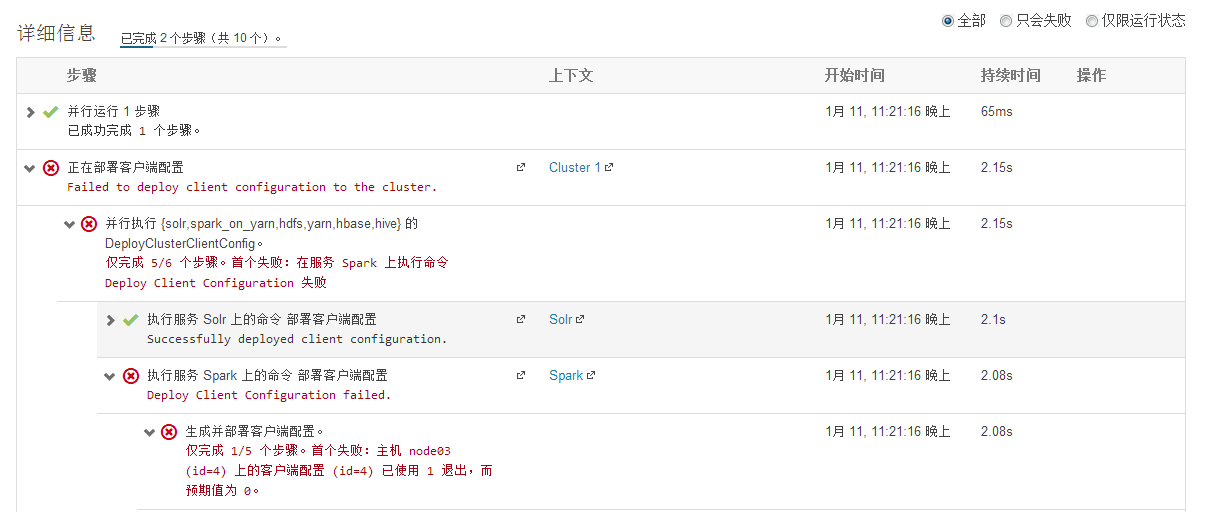
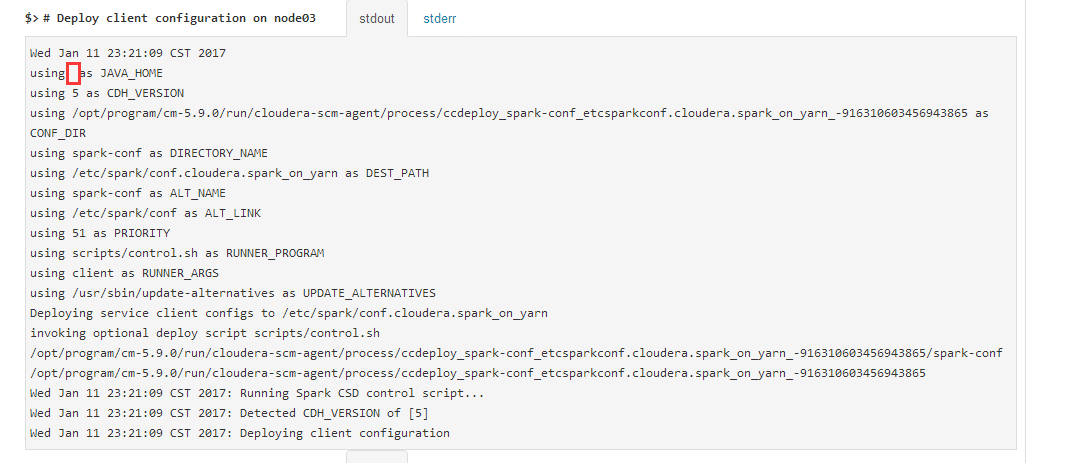

我做了2个尝试,就好了,也不知道到底是哪个是有效操作,还是2个操作是有依赖的。
尝试一:
cat /etc/environment
然后在web上点“重试”试试看。不行的话:
尝试二:
find / -type f -name "*.sh" | xargs grep "as ALT_NAME"
定位到/opt/cm/lib64/cmf/service/client/deploy-cc.sh
直接在上面加上
JAVA_HOME=/opt/java
export JAVA_HOME=/opt/java

scp到每个节点
./scp.sh /opt/cm/lib64/cmf/service/client/deploy-cc.sh /opt/cm/lib64/cmf/service/client/
再搞一遍这个
cat /etc/environment
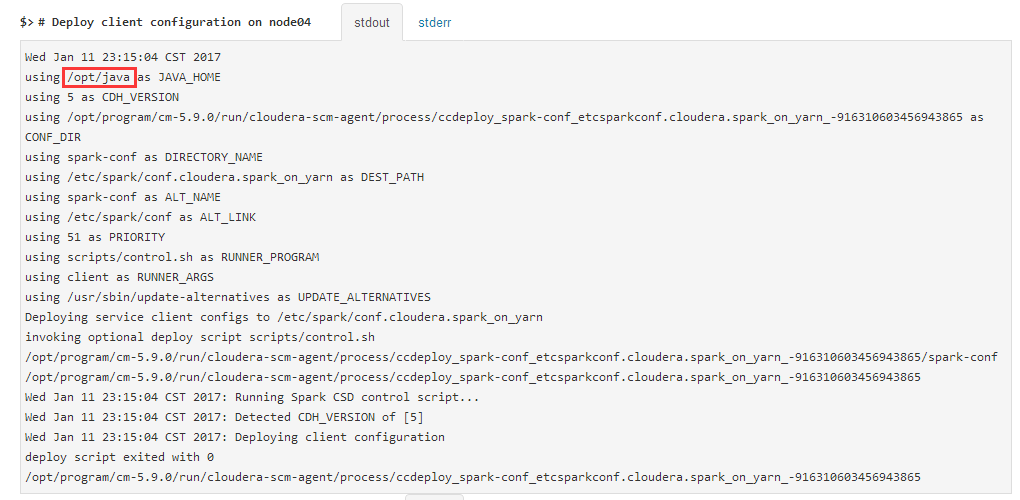
然后再点“重试”就好了
17、继续安装,启动hive的时候失败,看日志是没有Mysql的JDBC,cp一个过去再继续
cp mysql-connector-java-5.1.40-bin.jar /opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/hive/lib/
18、安装oozie的时候失败,还是JDBC,再cp一个
cp mysql-connector-java-5.1.40-bin.jar /var/lib/oozie/
19、mater给4G的时候,执行到oozie我就报错了,图忘记截了,网上说是内存不足。下图是master给了6G。

20、终于装好了0.0
八、测试,使用spark计算PI
因为权限问题,先切换到hdfs用户,之前安装过程中CDH已经创建好hdfs用户了。
su hdfs spark-submit \ --master yarn-client \ --class org.apache.spark.examples.SparkPi \ --driver-memory 512m \ --executor-memory 512m \ --executor-cores 2 \ /opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/spark/examples/lib/spark-examples-1.6.0-cdh5.9.0-hadoop2.6.0-cdh5.9.0.jar \ 10
17/01/12 23:28:30 INFO spark.SparkContext: Running Spark version 1.6.0 17/01/12 23:28:33 INFO spark.SecurityManager: Changing view acls to: hdfs 17/01/12 23:28:33 INFO spark.SecurityManager: Changing modify acls to: hdfs 17/01/12 23:28:33 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hdfs); users with modify permissions: Set(hdfs) 17/01/12 23:28:34 INFO util.Utils: Successfully started service 'sparkDriver' on port 38078. 17/01/12 23:28:36 INFO slf4j.Slf4jLogger: Slf4jLogger started 17/01/12 23:28:37 INFO Remoting: Starting remoting 17/01/12 23:28:37 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:34306] 17/01/12 23:28:37 INFO Remoting: Remoting now listens on addresses: [akka.tcp://[email protected]:34306] 17/01/12 23:28:37 INFO util.Utils: Successfully started service 'sparkDriverActorSystem' on port 34306. 17/01/12 23:28:37 INFO spark.SparkEnv: Registering MapOutputTracker 17/01/12 23:28:37 INFO spark.SparkEnv: Registering BlockManagerMaster 17/01/12 23:28:37 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-d9897e9d-bdd0-424a-acdb-b636ba57cd04 17/01/12 23:28:37 INFO storage.MemoryStore: MemoryStore started with capacity 265.1 MB 17/01/12 23:28:38 INFO spark.SparkEnv: Registering OutputCommitCoordinator 17/01/12 23:28:39 INFO util.Utils: Successfully started service 'SparkUI' on port 4040. 17/01/12 23:28:39 INFO ui.SparkUI: Started SparkUI at http://192.168.2.100:4040 17/01/12 23:28:39 INFO spark.SparkContext: Added JAR file:/opt/cloudera/parcels/CDH-5.9.0-1.cdh5.9.0.p0.23/lib/spark/examples/lib/spark-examples-1.6.0-cdh5.9.0-hadoop2.6.0-cdh5.9.0.jar at spark://192.168.2.100:38078/jars/spark-examples-1.6.0-cdh5.9.0-hadoop2.6.0-cdh5.9.0.jar with timestamp 1484234919364 17/01/12 23:28:40 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.2.100:8032 17/01/12 23:28:41 INFO yarn.Client: Requesting a new application from cluster with 2 NodeManagers 17/01/12 23:28:42 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (1024 MB per container) 17/01/12 23:28:42 INFO yarn.Client: Will allocate AM container, with 896 MB memory including 384 MB overhead 17/01/12 23:28:42 INFO yarn.Client: Setting up container launch context for our AM 17/01/12 23:28:42 INFO yarn.Client: Setting up the launch environment for our AM container 17/01/12 23:28:42 INFO yarn.Client: Preparing resources for our AM container 17/01/12 23:28:44 INFO yarn.Client: Uploading resource file:/tmp/spark-40750070-91a7-4a5b-ae27-1cfd733d0be8/__spark_conf__3134783970337565626.zip -> hdfs://master:8020/user/hdfs/.sparkStaging/application_1484232210824_0004/__spark_conf__3134783970337565626.zip 17/01/12 23:28:45 INFO spark.SecurityManager: Changing view acls to: hdfs 17/01/12 23:28:45 INFO spark.SecurityManager: Changing modify acls to: hdfs 17/01/12 23:28:45 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hdfs); users with modify permissions: Set(hdfs) 17/01/12 23:28:45 INFO yarn.Client: Submitting application 4 to ResourceManager 17/01/12 23:28:46 INFO impl.YarnClientImpl: Submitted application application_1484232210824_0004 17/01/12 23:28:47 INFO yarn.Client: Application report for application_1484232210824_0004 (state: ACCEPTED) 17/01/12 23:28:47 INFO yarn.Client: client token: N/A diagnostics: N/A ApplicationMaster host: N/A ApplicationMaster RPC port: -1 queue: root.users.hdfs start time: 1484234925930 final status: UNDEFINED tracking URL: http://master:8088/proxy/application_1484232210824_0004/ user: hdfs 17/01/12 23:28:48 INFO yarn.Client: Application report for application_1484232210824_0004 (state: ACCEPTED) 17/01/12 23:28:49 INFO yarn.Client: Application report for application_1484232210824_0004 (state: ACCEPTED) 17/01/12 23:28:50 INFO yarn.Client: Application report for application_1484232210824_0004 (state: ACCEPTED) 17/01/12 23:28:51 INFO cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(null) 17/01/12 23:28:51 INFO yarn.Client: Application report for application_1484232210824_0004 (state: ACCEPTED) 17/01/12 23:28:51 INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> master, PROXY_URI_BASES -> http://master:8088/proxy/application_1484232210824_0004), /proxy/application_1484232210824_0004 17/01/12 23:28:51 INFO ui.JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter 17/01/12 23:28:52 INFO yarn.Client: Application report for application_1484232210824_0004 (state: RUNNING) 17/01/12 23:28:52 INFO yarn.Client: client token: N/A diagnostics: N/A ApplicationMaster host: 192.168.2.101 ApplicationMaster RPC port: 0 queue: root.users.hdfs start time: 1484234925930 final status: UNDEFINED tracking URL: http://master:8088/proxy/application_1484232210824_0004/ user: hdfs 17/01/12 23:28:52 INFO cluster.YarnClientSchedulerBackend: Application application_1484232210824_0004 has started running. 17/01/12 23:28:52 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 42832. 17/01/12 23:28:52 INFO netty.NettyBlockTransferService: Server created on 42832 17/01/12 23:28:52 INFO storage.BlockManager: external shuffle service port = 7337 17/01/12 23:28:52 INFO storage.BlockManagerMaster: Trying to register BlockManager 17/01/12 23:28:52 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.2.100:42832 with 265.1 MB RAM, BlockManagerId(driver, 192.168.2.100, 42832) 17/01/12 23:28:52 INFO storage.BlockManagerMaster: Registered BlockManager 17/01/12 23:28:53 INFO scheduler.EventLoggingListener: Logging events to hdfs://master:8020/user/spark/applicationHistory/application_1484232210824_0004 17/01/12 23:28:53 INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8 17/01/12 23:28:55 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:36 17/01/12 23:28:55 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:36) with 10 output partitions 17/01/12 23:28:55 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:36) 17/01/12 23:28:55 INFO scheduler.DAGScheduler: Parents of final stage: List() 17/01/12 23:28:55 INFO scheduler.DAGScheduler: Missing parents: List() 17/01/12 23:28:55 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32), which has no missing parents 17/01/12 23:28:57 INFO spark.ExecutorAllocationManager: Requesting 1 new executor because tasks are backlogged (new desired total will be 1) 17/01/12 23:28:57 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1904.0 B, free 1904.0 B) 17/01/12 23:28:58 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1202.0 B, free 3.0 KB) 17/01/12 23:28:58 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.2.100:42832 (size: 1202.0 B, free: 265.1 MB) 17/01/12 23:28:58 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006 17/01/12 23:28:58 INFO spark.ExecutorAllocationManager: Requesting 2 new executors because tasks are backlogged (new desired total will be 3) 17/01/12 23:28:58 INFO scheduler.DAGScheduler: Submitting 10 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:32) 17/01/12 23:28:58 INFO cluster.YarnScheduler: Adding task set 0.0 with 10 tasks 17/01/12 23:28:59 INFO spark.ExecutorAllocationManager: Requesting 2 new executors because tasks are backlogged (new desired total will be 5) 17/01/12 23:29:09 INFO cluster.YarnClientSchedulerBackend: Registered executor NettyRpcEndpointRef(null) (node02:49339) with ID 1 17/01/12 23:29:09 INFO storage.BlockManagerMasterEndpoint: Registering block manager node02:37527 with 265.1 MB RAM, BlockManagerId(1, node02, 37527) 17/01/12 23:29:10 INFO spark.ExecutorAllocationManager: New executor 1 has registered (new total is 1) 17/01/12 23:29:11 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, node02, executor 1, partition 0,PROCESS_LOCAL, 2071 bytes) 17/01/12 23:29:11 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, node02, executor 1, partition 1,PROCESS_LOCAL, 2073 bytes) 17/01/12 23:29:16 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on node02:37527 (size: 1202.0 B, free: 265.1 MB) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, node02, executor 1, partition 2,PROCESS_LOCAL, 2073 bytes) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, node02, executor 1, partition 3,PROCESS_LOCAL, 2073 bytes) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, node02, executor 1, partition 4,PROCESS_LOCAL, 2073 bytes) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5, node02, executor 1, partition 5,PROCESS_LOCAL, 2073 bytes) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6, node02, executor 1, partition 6,PROCESS_LOCAL, 2073 bytes) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 6402 ms on node02 (executor 1) (1/10) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 250 ms on node02 (executor 1) (2/10) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 308 ms on node02 (executor 1) (3/10) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 6855 ms on node02 (executor 1) (4/10) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Starting task 7.0 in stage 0.0 (TID 7, node02, executor 1, partition 7,PROCESS_LOCAL, 2073 bytes) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 266 ms on node02 (executor 1) (5/10) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 190 ms on node02 (executor 1) (6/10) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Starting task 8.0 in stage 0.0 (TID 8, node02, executor 1, partition 8,PROCESS_LOCAL, 2073 bytes) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 156 ms on node02 (executor 1) (7/10) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Starting task 9.0 in stage 0.0 (TID 9, node02, executor 1, partition 9,PROCESS_LOCAL, 2073 bytes) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Finished task 7.0 in stage 0.0 (TID 7) in 149 ms on node02 (executor 1) (8/10) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Finished task 8.0 in stage 0.0 (TID 8) in 131 ms on node02 (executor 1) (9/10) 17/01/12 23:29:17 INFO scheduler.TaskSetManager: Finished task 9.0 in stage 0.0 (TID 9) in 128 ms on node02 (executor 1) (10/10) 17/01/12 23:29:17 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:36) finished in 19.406 s 17/01/12 23:29:17 INFO cluster.YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool 17/01/12 23:29:17 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:36, took 22.241001 s Pi is roughly 3.142676 17/01/12 23:29:18 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.2.100:4040 17/01/12 23:29:18 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread 17/01/12 23:29:18 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors 17/01/12 23:29:18 INFO cluster.YarnClientSchedulerBackend: Asking each executor to shut down 17/01/12 23:29:19 INFO cluster.YarnClientSchedulerBackend: Stopped 17/01/12 23:29:19 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 17/01/12 23:29:19 INFO storage.MemoryStore: MemoryStore cleared 17/01/12 23:29:19 INFO storage.BlockManager: BlockManager stopped 17/01/12 23:29:19 INFO storage.BlockManagerMaster: BlockManagerMaster stopped 17/01/12 23:29:19 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 17/01/12 23:29:19 INFO spark.SparkContext: Successfully stopped SparkContext 17/01/12 23:29:20 INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon. 17/01/12 23:29:20 INFO util.ShutdownHookManager: Shutdown hook called 17/01/12 23:29:20 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports. 17/01/12 23:29:20 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-40750070-91a7-4a5b-ae27-1cfd733d0be8
上面已经计算出来了:Pi is roughly 3.142676
收工收工。