Python获取所有股票代码以及股票历史成交数据分析(二)_stock.csv-程序员宅基地
技术标签: python anaconda json 大数据 数据挖掘
接上一篇获取完股票代码信息后,我们打开东方财富网,一通瞎点,进到某股票的K线板块
打开调试界面,XHR中并没有我们想要的数据,从网页数据加载来看应该不是实时资源的肯定有个传输的地方,我们先清空完所有Network的资源
然后把鼠标放到K线上可以从后台再次获取传输数据,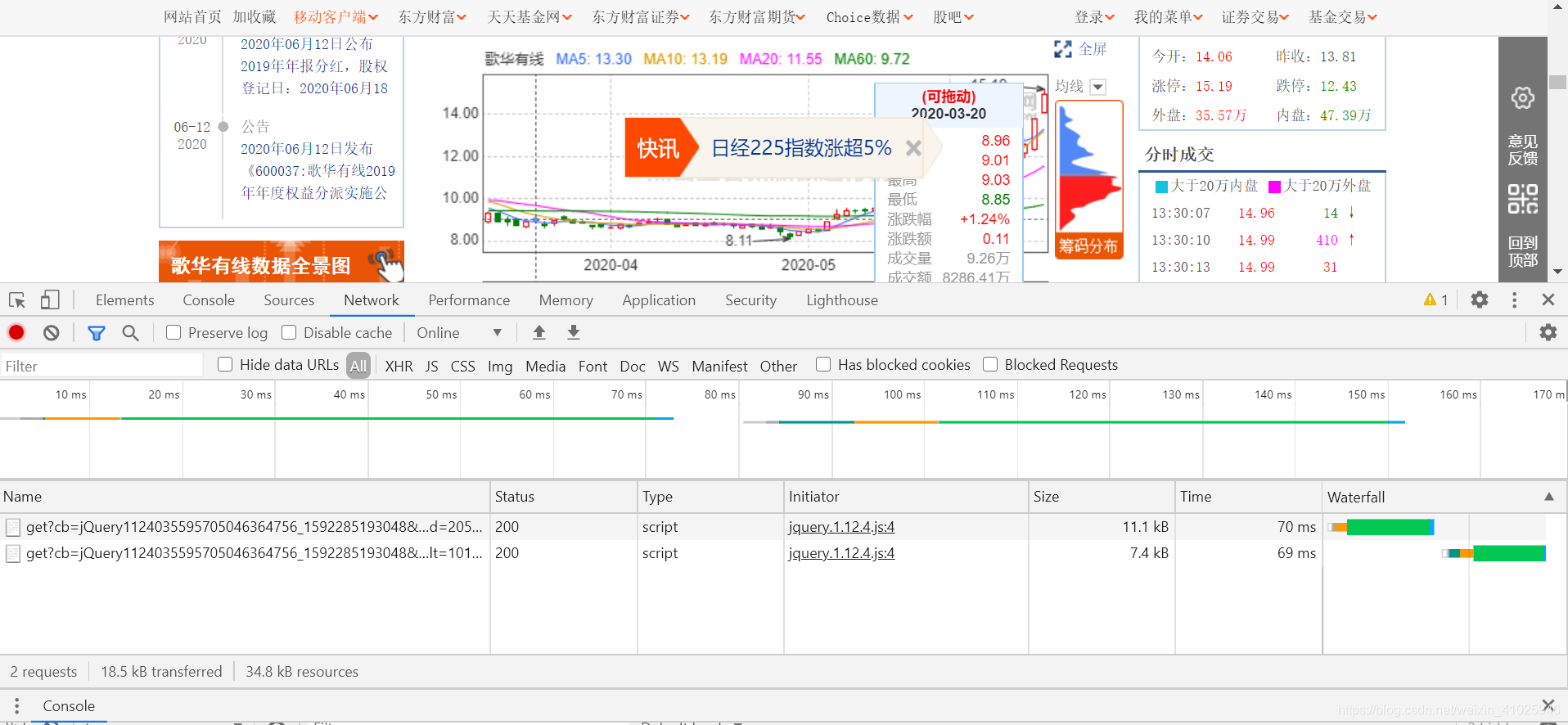
获取到数据立刻按按钮暂停获取,不然数据增多影响我们排查数据获取的Url,很快我们就可以查到JSON数据的url

该JSON数据获取地址的url为:http://56.push2his.eastmoney.com/api/qt/stock/kline/get?cb=jQuery1124035595705046364756_1592285193048&secid=1.600037&ut=fa5fd1943c7b386f172d6893dbfba10b&fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58&klt=101&fqt=0&end=20500101&lmt=120&_=1592285193152
首先我们能确认是个get请求方式,我们可以采用python代码进行提交参数的拆解,也可以肉眼拆解,
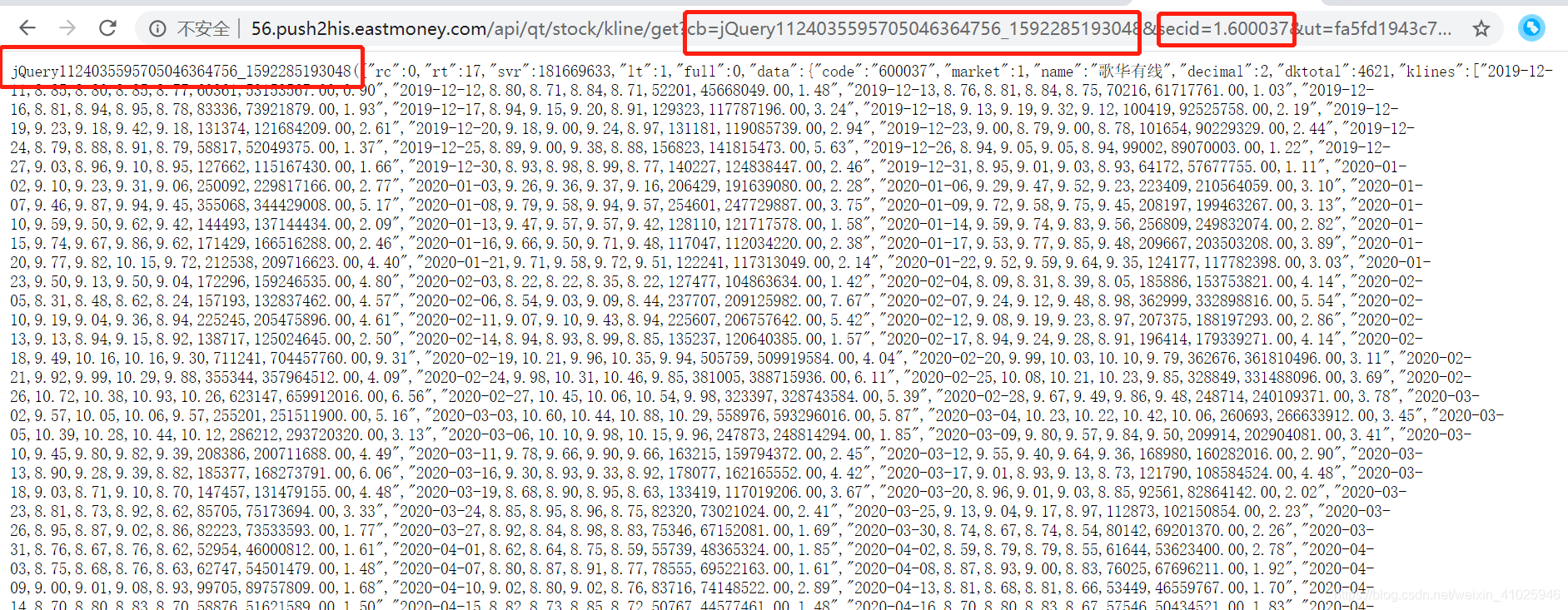
可以发现地址栏的jQuery与网页输出的部分数据相对应,股票代码为secid,但secid多了1. (此部分我们拿不同证券试验可以知道 深股为0. 上证为1. 开头 )。
我们去掉jQuery看能否获取数据,

可以看到可以获取到相关的数据,而且变得干净了不少,后续我们一个个拆解看有哪些没用的提交参数。
观察完页面和数据,我们来着手代码部分,首先从上一篇获取股票代码的文章我们已经拿到所有股票代码,需要进行股票代码输出
def get_stock_code():
#stock=['0.002415','0.000063']#深的股票为0. 上证为1.开头 加上对应股票代码
stock=[]
with open (file_stock,'r') as f:
for i in f.readlines():
if i !=None:
stock.append(i.strip("\n"))
#print(stock)
if stock:
return stock #返回股票代码
else:
return stock
接着进行网页数据获取
def get_json(url): # 获取JSON
try:
r=requests.get(url) # 抓取网页返回json信息
r.raise_for_status()
r.encoding = 'utf-8'
#print(r.json())
#with open(r"C:\Users\xxp\.spyder-py3\testcode\tmp.txt", "w") as fp:
#fp.write(json.dumps(r.json(),indent=4,ensure_ascii=False)) # txt测试是否成功获取网页
return r.json()
except:
return 'false'
进而可以写出获取股票代码对应的JSON数据文件的代码:
def main():
stock=get_stock_code()
start= time.time()
#print(num)
for code in stock: # 获取每个股票的数据
url = 'http://push2his.eastmoney.com/api/qt/stock/kline/get?fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf61&klt=101&fqt=1&secid='+str(code)+'&beg=0&end=20500000&_=1591683995756'# 1591683995 为时间戳
#此部分url删减了部分不需要的内容
stock_info=get_json(url)#获取json数据
get_stock_info(stock_info)#对数据进行处理
time.sleep(3)# 暂停3秒,防止被服务器拉黑
print('总耗时:' ,time.time()-start)
最后进行获取数据的整合,填充股票名称和股票代码,放入一个EXCEL中方便分析,总体代码如下:
import requests
import pandas as pd
import time
import json
import os
import csv
import numpy as np
file_stock=r'C:\Users\xxp\.spyder-py3\testcode\test\stock.txt' #股票代码txt
filename=r'C:\Users\xxp\.spyder-py3\testcode\test'#生成文件夹路径
file=r'C:\Users\xxp\.spyder-py3\testcode\test\stock.csv'#生成文件路径
class ClassName: # 构建类似static函数 python没有静态 只能自己构建
COUNT=0
def __init__(self, static):
self.static = static
ClassName.COUNT+=1
def get_json(url): # 获取JSON
try:
r=requests.get(url) # 抓取网页返回json信息
r.raise_for_status()
r.encoding = 'utf-8'
#print(r.json())
#with open(r"C:\Users\xxp\.spyder-py3\testcode\tmp.txt", "w") as fp:
#fp.write(json.dumps(r.json(),indent=4,ensure_ascii=False)) # txt测试是否成功获取网页
return r.json()
except:
return 'false'
def get_stock_code():
#stock=['0.002415','0.000063']#深的股票为0. 上证为1.开头 加上对应股票代码
stock=[]
with open (file_stock,'r') as f:
for i in f.readlines():
if i !=None:
stock.append(i.strip("\n"))
#print(stock)
if stock:
return stock #返回股票代码
else:
return stock
def data_write_csv(file, datas):#file为写入CSV文件的路径,datas为要写入数据列表
with open(file,'a+',encoding='utf-8-sig',newline='') as f:
writer = csv.writer(f)
for data in datas:
#print(data)#
#data_str=','.join(data) #列表拆分成str
#data_str=data_str.strip()
#print(data_str)
writer.writerow(data)
print("保存文件成功,处理结束")
def get_stock_info(result): # 获取某个股票的信息
try:
a_str = result.get("data").get("klines")# json数据对应值获取 报错时候跳过空值
s_name= result.get("data").get("name")
s_code= result.get("data").get("code")
array_str = np.array(a_str) #数组存储
#csv_str ="code,name,time,开盘,收盘,最高,最低,成交量,成交额,振幅,换手\n"
items_all=[]
for i in range(len(array_str)-31,len(array_str)-1): #数组长度限定30交易日内数据
item = array_str[i] #获取数据
items = item.split(",")#拆分后变成List函数
items.insert(0,s_name)
items.insert(0,'#'+s_code)#拼接数据
items_all.extend([items]) #数组整合
#print(items_all)
if os.path.exists(filename):#文件路径检测
#print("path exists")
if os.path.exists(file): #文件检测
data_write_csv(file,items_all)# 进行excel多个股票写入
ClassName(1)#调用自己构建的静态函数
print('股票数',ClassName.COUNT) #输出调用次数
else: #文件不存在就创建
df=pd.DataFrame(data=items_all,columns=['code','name','time','开盘','收盘','最高','最低',
'成交量','成交额','振幅','换手'])
df.to_csv(file,index=False,encoding='utf_8_sig')
print ('文件创建成功')
ClassName(1)#调用自己构建的静态函数
print('股票数',ClassName.COUNT) #输出调用次数
else:
os.makedirs(filename)
print('create path success')
return ''
except Exception as e :
return e
def main():
stock=get_stock_code()
start= time.time()
#print(num)
for code in stock: # 获取每个股票的数据
url = 'http://push2his.eastmoney.com/api/qt/stock/kline/get?fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf61&klt=101&fqt=1&secid='+str(code)+'&beg=0&end=20500000&_=1591683995756'# 1591683995 为时间戳
#此部分url删减了部分不需要的内容
stock_info=get_json(url)#获取json数据
get_stock_info(stock_info)#对数据进行处理
time.sleep(3)# 暂停3秒,防止被服务器拉黑
print('总耗时:' ,time.time()-start)
if __name__=='__main__': #在其他文件import这个py文件时,不会自动运行主函数
main()
关于股票代码的获取可以参考我上一篇文章:Python获取所有股票代码以及股票历史成交数据分析
有什么不懂的或者代码可以优化的可以留言沟通,这个代码可以再加入一个获取状态判断400系列,从而进行400相关数据重新获取,以及多线程+多进程方式加快数据的获取。
智能推荐
一文详解从拉格朗日乘子法、KKT条件、对偶上升法到罚函数与增广Lagrangian乘子法再到ADMM算法(交替方向乘子法)_拉格朗日乘子 二次惩罚系数-程序员宅基地
文章浏览阅读4.7k次,点赞19次,收藏129次。最近看了ADMM算法,发现这个算法需要用到许多不少前备知识,在搜索补齐这些知识的过程中感觉网上的资料与总结在零散的同时又不够清晰,在此本文对这一块的内容进行汇总,同时表达自己的一些理解。拉格朗日乘子法本段内容参考了拉格朗日(Lagrange)乘子法超简说明。先从物理意义上介绍拉格朗日乘子法。原问题我们要解决带有等式约束的最优化问题。为方便书写,以二维函数为例:maxf(x,y),s.t.g(x,y)=0用下图表示这个问题。 f(x,y)参数x,y在二维平面内,存..._拉格朗日乘子 二次惩罚系数
Python设计双序列全局比对的程序——生物信息_编写代码找出blosum62矩阵中得分最高的氨基酸配对-程序员宅基地
文章浏览阅读1w次,点赞20次,收藏100次。基本概念“**双序列比对**”一般来说,是对两个DNA或蛋白质序列进行比较,从而找出两者之间最大的相似性匹配。主要是为了确定两个序列之间的相似性源自于同源性,按照一定的规律进行排序。比对过程中,错配与突变相对应,而空位对应于插入或删除。该研究还可以拓展到现在热门的语言文本的研究中。在生物信息处理中,我们希望找出两条序列S和T之间具有的某种相似性关系,这种寻找生物序列相似性关系的算法就是**双..._编写代码找出blosum62矩阵中得分最高的氨基酸配对
traefik-ingress 实现http自动跳转https_ingress httponly-程序员宅基地
文章浏览阅读3.1k次。简介Kubernetes目前ingress主流的就是nginx-ingress和traefik-ingress.nginx-ingress中实现http转https加一个注解就可以了,很简单。但是traefik-ingress好像稍微要复杂一点。现就将整个过程整理成文。条件1. Kubernetes集群2.集群已经安装traefik-ingress插件步骤1.部署nginx应用和服务#kubectl apply -f nginx.yamlapiVersion: apps.._ingress httponly
电脑防泄密系统如何构建企业数据防泄密架构-程序员宅基地
文章浏览阅读223次。这些加密技术,不仅可以支持图纸文档类型的文件加密如:cad,sloidworks,ug等二维三维图纸,还支持源代码的加密,如c、c++、c#、java等开发语言的支持。安秉电脑防泄密系统,还可以保护企业当数据发生泄漏时,可以进行日志查询,找到泄漏根源,从根本上解决数据泄密的事情发生。2,审批授权,对于涉密的数据,需要外发时,可以设置在线审批管理员授权,经过管理员审批后同意外发的数据方可带离公司电脑正常使用。4,报警,对于员电脑特殊的泄密行业,可以设置管理端报警,发现可疑情况立即报警,及时发现问题并且整改。
MATLAB时域分析(附完整代码)_matlab进行时域性能分析-程序员宅基地
文章浏览阅读845次,点赞10次,收藏10次。MATLAB时域分析(附完整代码)_matlab进行时域性能分析
git取消【删除】已经提交的文件(夹)跟踪_git rm --cached <file/folder>-程序员宅基地
文章浏览阅读754次。git取消【删除】已经提交的文件(夹)跟踪git rm -r --cached <fold> 不删除本地文件git rm -r --f <fold> 删除本地文件git rm --cached <file> 不删除本地文件,仅仅不再跟踪文件git rm --f <file> 删除本地文件,并且不再跟踪文件..._git rm --cached
随便推点
【Linux】Linux cgroup(Control Groups)常见用法_cgroup监控资源状态-程序员宅基地
文章浏览阅读250次,点赞3次,收藏5次。Linux cgroup(Control Groups)是一种强大的资源管理工具,它允许系统管理员对系统资源进行细粒度的控制。cgroup通过将进程分组并对这些组施加限制,从而实现资源的隔离和优先级控制。_cgroup监控资源状态
php dynamic library,PHP Startup: Unable to load dynamic library 问题。-程序员宅基地
文章浏览阅读845次。PHP Startup: Unable to load dynamic library … (tried:… 这种算是比较常见的问题,当然这里只讨论在保证 php.ini 中启用了相关扩展,并且相应的.dll文件确实存在于加载目录中的情况。我个人遇到的是’pdo_firebird’和 ‘pdo_oci’.D:\Tool\php\php-7.2.7-Win32-VC15-x64>phpWarn..._unable to load dynamic library 'pdo_firebird
web3之以太坊链二层(layer2):StarkNet_ethereum layer 2 network starknet-程序员宅基地
文章浏览阅读1.3k次,点赞27次,收藏22次。StarkWare公司一直致力于通过零知识证明(ZK)来解决区块链扩容问题,先后研发了2个L2方案——StarkEx和StarkNet。_ethereum layer 2 network starknet
网页方向培训—JavaScript第二讲_当修改文本框内容后,触发onchange事件,调用check函数-程序员宅基地
文章浏览阅读340次。JavaScript第二讲一、事件响应1.1 什么是事件 JavaScript 创建动态页面。事件是可以被 JavaScript 侦测到的行为。 网页中的每个元素都可以产生某些可以触发 JavaScript 函数或程序的事件。比如说,当用户单击按钮或者提交表单数据时,就发生一个鼠标单击(onclick)事件,需要浏览器做出处理,返回给用户一个结果。..._当修改文本框内容后,触发onchange事件,调用check函数
java语言的命题原则_《 Java 语言程序设计(一) 》 课程全国统一命题考试说明 _ 重庆自考网...-程序员宅基地
文章浏览阅读68次。《 Java 语言程序设计(一) 》 课程全国统一命题考试说明为组织好高等教育自学考试 《 Java 语言程序设计(一) ) )课程的全国统一考试命题工作,根据全国统一命题课程的有关规定,特制定本说明。一、考试原则1 .考试标准本课程考试参照全日制普通高校同专业、同层次、同课程的 Java 语言程序设计(一)本科结业水平,并体现自学考试以培养应用型人才为主要目标的特点。在题量匕能够使中等水平的考生...
微信二维码转换成链接_微信二维码链接-程序员宅基地
文章浏览阅读6w次,点赞9次,收藏35次。微信二维码转换成链接我们很多人都在想,怎样才能把二维码转换成网址链接,然后点击网址链接就直接进入二维码呢?下面就是转换成链接的方法之一:微信转链接步骤一:打开https://cli.im/deqr然后上传你的二维码图片,然后得到解码网址(如下图);步骤二:http://qr.topscan.com/api.php?text= 然后加上你的解码后的网址;步骤三:http://h5..._微信二维码链接