【Python数据分析】数据挖掘建模——分类与预测——决策树_决策树分类python-程序员宅基地
决策树是一种树状结构,它的每一个叶节点对应着一个分类,非叶节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。构造决策树的核心问题是在每一步如何选择适当的属性对样本做拆分。
常见的决策树算法如下:
| 决策树算法 | 算法描述 |
| ID3算法 | 在决策树各级节点上,使用信息增益的方法作为属性的选择标准 |
| C4.5算法 | ID3的改进版,使用信息增益率来选择节点属性。ID3只适用于离散的描述属性,而C4.5算法既能够处理离散的描述属性,也可以处理连续的描述属性 |
| CART算法 | 通过构建树、修剪树、评估树来构建一个二叉树。当终节点为连续变量时,该树为回归树,当终节点是分类变量时,该树为分类树 |
一、信息熵与信息增益
 pi一般可以用某一类下面的样本数/总样本数来估计(si/s)
pi一般可以用某一类下面的样本数/总样本数来估计(si/s)


更具体的介绍可以参考:机器学习实战(三)——决策树_呆呆的猫的博客-程序员宅基地_决策树
二、ID3算法
ID3算法基于信息熵来选择最佳测试属性。它选择当前样本集中具有最大信息增益值的属性作为测试属性;样本集的划分则依据测试属性的取值进行,测试属性有多少不同取值就将样本集划分为多少子样本集,同时决策树上与该样本集相应的节点长出新的叶子节点。
1.ID3具体实现步骤:
(1)对当前样本集合,计算所有属性的信息增益;
(2)选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划分为同一子样本集;
(3)若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应符号,然后返回调用处;否则对子样本集递归调用本算法。
2.在Python中实现ID3决策树算法:
import pandas as pd
filename = './Python数据分析与挖掘实战(第2版)/chapter5/demo/data/sales_data.xls'
data = pd.read_excel(filename, index_col ="序号")
data.head(10)数据如下

#数据是类别标签,将它转换为数据
data[data == "好"] = 1
data[data == "是"] = 1
data[data == "高"] = 1
data[data != 1] = -1
x = data.iloc[:,:3].astype(int)
y = data.iloc[:,3].astype(int)astype的用法参考:Python Pandas DataFrame.astype()用法及代码示例 - 纯净天空
#构建基于信息熵的决策树
from sklearn.tree import DecisionTreeClassifier as DTC
dtc = DTC(criterion = "entropy")
dtc.fit(x,y)输出如下:

参数说明如下:
class_weight:类别权重,可选参数,默认是None,也可以字典、字典列表、balanced。指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多,导致训练的决策树过于偏向这些类别。类别的权重可以通过{class_label:weight}这样的格式给出,这里可以自己指定各个样本的权重,或者用balanced,如果使用balanced,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。当然,如果你的样本类别分布没有明显的偏倚,则可以不管这个参数,选择默认的None。
criterion:特征选择标准,可选参数,默认是gini,可以设置为entropy。gini是基尼不纯度,是将来自集合的某种结果随机应用于某一数据项的预期误差率,是一种基于统计的思想。entropy是香农熵,也就是上篇文章讲过的内容,是一种基于信息论的思想。Sklearn把gini设为默认参数,应该也是做了相应的斟酌的,精度也许更高些?ID3算法使用的是entropy,CART算法使用的则是gini。
splitter:特征划分点选择标准,可选参数,默认是best,可以设置为random。每个结点的选择策略。best参数是根据算法选择最佳的切分特征,例如gini、entropy。random随机的在部分划分点中找局部最优的划分点。默认的”best”适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐”random”。
min_impurity_split:节点划分最小不纯度,可选参数,默认是1e-7。这是个阈值,这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。
presort:数据是否预排序,可选参数,默认为False,这个值是布尔值,默认是False不排序。一般来说,如果样本量少或者限制了一个深度很小的决策树,设置为true可以让划分点选择更加快,决策树建立的更加快。如果样本量太大的话,反而没有什么好处。问题是样本量少的时候,我速度本来就不慢。所以这个值一般懒得理它就可以了。
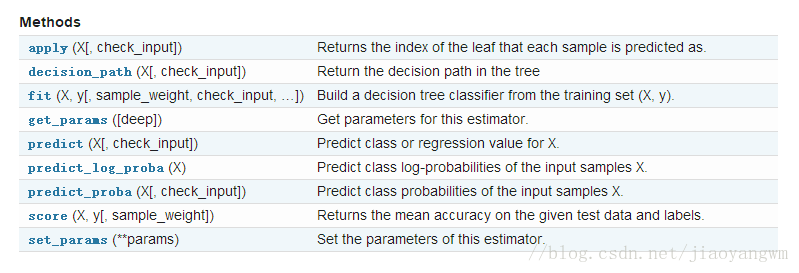
更多说明可见:机器学习实战(三)——决策树_呆呆的猫的博客-程序员宅基地_决策树sklearn.tree.DecisionTreeClassifier()提供了一些方法供我们使用,如下图所示:
#得到模型的平均准确度
dtc.score(x,y)#导入相关函数,可视化决策树
#导出的文件是一个dot文件,需要安装graphviz才能将它转换为pdf等格式
from sklearn.tree import export_graphviz
x = pd.DataFrame(x)
with open("./Python数据分析与挖掘实战(第2版)/chapter5/demo/data/tree.dot","w",encoding='utf-8') as f:
f = export_graphviz(dtc,feature_names = x.columns, out_file =f)安装好graphviz后,在dot所在目录下运行:
$ dot -Tpdf tree.dot -o tree.pdf
如果中文字没法正常显示,可以把原来的
node [shape=box] ;改为
node [shape=box, fontname="Microsoft YaHei"] ;
即可得到生成的结果图

三、C4.5算法与CART算法
C4.5算法与ID3算法相似,但是做了改进,将信息增益比作为选择特征的标准。
关于C4.5对ID3的改进可以看:决策树算法原理(ID3,C4.5) - 做梦当财神 - 博客园
这里主要介绍CART算法。

1.CART分类树
CART分类树预测分类离散型数据,采用基尼指数选择最优特征,同时决定该特征的最优二值切分点。分类过程中,假设有K个类,样本点属于第k个类的概率为Pk,则概率分布的基尼指数定义为

根据基尼指数定义,可以得到样本集合D的基尼指数,其中Ck表示数据集D中属于第k类的样本子集。

如果数据集D根据特征A在某一取值a上进行分割,得到D1,D2两部分后,那么在特征A下集合D的基尼系数如下所示。其中基尼系数Gini(D)表示集合D的不确定性,基尼系数Gini(D,A)表示A=a分割后集合D的不确定性。基尼指数越大,样本集合的不确定性越大。

对于属性A,分别计算任意属性值将数据集划分为两部分之后的Gain_Gini,选取其中的最小值,作为属性A得到的最优二分方案。然后对于训练集S,计算所有属性的最优二分方案,选取其中的最小值,作为样本及S的最优二分方案。

比如:


2.CART回归树

具体例子可以参考:决策树(ID3、C4.5、CART)的原理、Python实现、Sklearn可视化和应用 - 知乎
CART算法在Python中的实现跟前面ID3差不多,不同的是dtc = DTC(criterion = "entropy")中entropy改为gini
三者的区别:

参考:决策树算法原理(CART分类树) - 做梦当财神 - 博客园
四、决策树剪枝
决策树算法本身的执行过程决定了它对训练集的分类是十分精确的,由于考虑到了绝大部分属性,一般都能对训练集中的数据进行比较精确的判断。但是这样所生成的树一般非常复杂,层数较多,有可能将本身并不具显著意义的属性也加以考虑,导致面对未见的新样本时泛化能力较差,产生过拟合问题。因此,有必要在一定程度上降低决策树的复杂度,即消除一些代表性不强的决策路径。即便这样可能会导致模型对训练集的分类精度下降,但决策树的泛化性能会有效提高。
在进行剪枝时,主要有预剪枝和后剪枝两种思路。
预剪枝是指在决策树的生成过程中,对每个节点在划分前先进行评估,若当前的划分不能带来泛化性能的提升,则停止划分,并将当前节点标记为叶节点。
后剪枝是指先从训练集生成一颗完整的决策树,然后自底向上对非叶节点进行考察,若将该节点对应的子树替换为叶节点,能带来泛化性能的提升,则将该子树替换为叶节点。
关于剪枝介绍可以参考:CART决策树原理(分类树与回归树) - 云+社区 - 腾讯云
关于剪枝在Python中的实现可以参考:Python——决策树分类模型剪枝 - 知乎
目前,决策树已演化发展为GBDT、XGBoost等模型:
可以参考:
GBDT的原理、公式推导、Python实现、可视化和应用 - 知乎
XGBoost的原理、公式推导、Python实现和应用 - 知乎
智能推荐
tf实现Focal-Loss_focal loss tf-程序员宅基地
文章浏览阅读966次。tf实现Focal−Losstf实现Focal-Losstf实现Focal−Loss_focal loss tf
sql server 2000 示例数据库 Pubs 全库脚本 SQLServer2000 自带数据库-程序员宅基地
文章浏览阅读232次。/* *//* InstPubs.SQL - Creates the Pubs database */ /* *//*** Copyright Microsoft, Inc. 1994 - 2000** All Rights Reserved.*/SET NOCOUNT ONGOset nocount onset dateformat mdyUSE masterdeclare @d..._sql2000中自带的pubs数据库中的表
【无标题】App iOS端适配iOS 15系统_lsapplicationqueriesschemes 超过 50 怎么办-程序员宅基地
文章浏览阅读2.6k次。各位好:App iOS端适配iOS 15系统,适配后将使用新的xcode 13打包提交App Store。一、适配内容:1、新增了iPhone 13 mini机型(尺寸同iPhone12 mini),5.4 英寸 (对角线) OLED 全面屏,屏幕分辨率为2340 x 1080 像素。如果是通过分辨率来判断则需要增加一个模式。 #define iPhone13mini ([UIScreen instancesRespondToSelector:@selector(currentMo_lsapplicationqueriesschemes 超过 50 怎么办
抓包工具Fiddler的下载安装使用_fiddler抓包下载-程序员宅基地
文章浏览阅读497次。右侧显示就是我们主机发送http/https请求的记录。如果我们要查看某一次访问,可以双击该记录,在右侧就会显示这次http请求的内容以及返回的响应的内容。右键全选,点击remove,选择selected sessions,就能删除选择的sessions。安装过程只用一路next即可;_fiddler抓包下载
html语言ppt,htmlppt课件-程序员宅基地
文章浏览阅读642次。PPT内容这是htmlppt课件,关于第2章Web编程技术,包括了HTML的发展历史,HTML的基本框架,HTML的各种常用标记:文字标记、图片标记、超级链接标记,CSS的基本使用方法,如何让CSS与HTML协同工作,JavaScript中的变量、数组、表达式、运算符、流程控制语句,JavaScript的函数、内置对象、浏览器对象的层次和DOM模型的建立和使用等内容,欢迎点击下载。第2章 Web编..._html if elseppt课件
solr html显示,Solr查询界面-程序员宅基地
文章浏览阅读259次。您可以使用查询界面将搜索查询提交给 Solr 集合并分析结果。在下面截图中的例子中,查询已经被提交,并且界面显示了作为 JSON 形式发送到浏览器的查询结果。在这个例子中,genre:Fantasy 的查询被发送到 “films” 集合。表单中的所有其他选项都使用了默认值,下表中对此进行了简要介绍,本指南的后面部分将对此进行详细介绍。该响应显示在窗体的右侧。对 Solr 的请求只是简单的 HTTP..._solr查询界面
随便推点
RuntimeError: split_size can only be 0 if dimension size is 0, but got dimension size of 2-程序员宅基地
文章浏览阅读624次。使用pytorch时遇到下面的问题RuntimeError: split_size can only be 0 if dimension size is 0, but got dimension size of 2原因:训练的batch size 比使用的GPU数量少,导致上述问题。解决办法增加batch size数值,保证为GPU数量整数倍。参考:1.https://discuss.pytorch.org/t/concatenating-images/40961/10_split_size can only be 0 if dimension size is 0, but got dimension size of 1
RabbitMQ订阅发布的消息,通过WebSocket实现数据实时推送到前端_rabbitmq怎么返回给前端数据-程序员宅基地
文章浏览阅读7.3k次,点赞3次,收藏12次。一、架构简单概述 RabbitMQ消息队列服务善于解决多系统、异构系统间的数据交换(消息通知/通讯)问题,并且可以订阅和发布,而随着HTML5诞生的WebSocket协议实现了浏览器与服务器的全双工通信,扩展了浏览器与服务端的通信功能,使服务端也能主动向客户端发送数据。 因此,我们可以使用RabbitMQ的订阅发布技术,订阅后,当RabbitMQ端有新的数据就直接发布到指定的queue,订_rabbitmq怎么返回给前端数据
Mendix Excel导出介绍_mendix实现excel导出-程序员宅基地
文章浏览阅读320次。本文介绍了Excel导出的两种方式及成果展示_mendix实现excel导出
5 gtm 工作原理_基于GTM法的水泥稳定碎石力学性能研究-程序员宅基地
文章浏览阅读226次。文章来源:微信公众号”沥青路面“引 言众所周知,以水泥稳定碎石为代表的半刚性材料是中国目前使用最为广泛的基层材料,因为其力学性能优良、使用成本较低、原材料来源广泛和施工工艺简单等优点,水泥稳定碎石在未来十几年内仍将是中国使用最为广泛的基层材料。目前水泥稳定碎石在设计和施工方面存在一些问题,例如室内成型方式与实际道路受力状态存在一定差异;设计指标和施工检测指标相关性不足;对矿质石料级配的要求没有体现..._无侧限抗压强度与劈裂强度的的关系
黑科技,Python 脚本帮你找出微信上删除你好友的人_微信出现brandsessionholder-程序员宅基地
文章浏览阅读1.5k次。编者按:本文来自稀土掘金江昪编译自 Github:0x5e/wechat-deleted-friends “ 清理下[微笑],不用回。你的朋友圈没事也该清清了,打开设置,通用,功能,群助手,全选,把我的信息粘贴一下,就可以了,发送就知道谁把你删了,方便你清人,不清不知道 ,一清吓一跳。” 相信大家在微信上一定被上面的这段话刷过屏,群发消息应该算是微信上流传最广的找到删除好友的方法..._微信出现brandsessionholder
MySQL存储过程 游标循环的使用_存储过程 重复定义同名游标 会覆盖吗?-程序员宅基地
文章浏览阅读1.5k次。MySQL存储过程 游标循环的使用_存储过程 重复定义同名游标 会覆盖吗?