四.HIVE及其相关大数据组件_hive组件-程序员宅基地
技术标签: hive hadoop # HIVE性能调优实战 大数据
HIVE及其相关大数据组件
Hive是构建在Hadoop大数据平台之上,Hive数据存储依赖于HDFS,HiveSQL的执行引擎依赖于MapReduce、Spark、Tez等分布式计算引擎,Hive作业的资源调度依赖于YARN、Mesos等大数据资源调度管理组件。如果脱离Hadoop生态单聊Hive优化,那无异于隔靴搔痒,解决不了根本的性能问题。
与Hive相关的组件有4个部分:Hive元数据、资源管理和调度、分布式文件系统和计算引擎。
1.HIVE架构
Hive依托于Hadoop大数据平台,其架构随着Hadoop版本的迭代和自身的发展也在不断地演变,但在Hadoop步入2.x版本、Hive步入1.x版本后,整体架构稳定,后续的迭代版本就没有太多重大的调整,更多的只是功能增强了。例如,Hive 2.x引入的LLAP,Hive 3.x在2.x的基础上加大了对LLAP和Tez的支持。
1.1 Hive 1.x版本基本结构
在Hadoop 2.x版本以后,Hive所有运行的任务都是交由YARN来统一管理。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U11FKUTM-1673883081022)(img_6.png)]](https://img-blog.csdnimg.cn/bd202bf5e3914b8398dfdadf278502b1.png)
客户端提交SQL作业到HiveServer2,HiveServer2会根据用户提交的SQL作业及数据库中现有的元数据信息生成一份可供计算引擎执行的计划。每个执行计划对应若干MapReduce作业,Hive会将所有的MapReduce作业都一一提交到YARN中,由YARN去负责创建MapReduce作业对应的子任务任务,并协调它们的运行。YARN创建的子任务会与HDFS进行交互,获取计算所需的数据,计算完成后将最终的结果写入HDFS或者本地。
整个Hive运行作业的过程,我们可以知道Hive自身主要包含如下3个部分:
第一部分是客户端(client)。Hive支持多种客户端的连接,包括beeline、jdbc、thrift和HCatalog。早期的Hive Command Line(CLI)由于可以直接操作HDFS存储的数据,权限控制较为困难,支持的用户数有限,已经被废弃。
第二部分是HiveServer2。替代早期的HiveServer,提供了HTTP协议的Web服务接口和RPC协议的thrift服务接口,使得Hive能够接收多种类型客户端的并发访问,并将客户端提交的SQL进行编译转化可供计算引擎执行的作业。借助于HiveServer2,Hive可以做到更为严格的权限验证。在实际使用中需要注意HiveServre2服务Java堆大小的设置,默认情况下是50MB,在查询任务增多的情况下,容器发生内存溢出,导致服务崩溃,用户访问不了Hive。
第三部分是元数据及元数据服务。Hive的元数据记录了Hive库内对象的信息,包括表的结构信息、分区结构信息、字段信息及相关的统计信息等。
1.2 Hive元数据
Hive的元数据保存在Hive的metastore数据中,里面记录着Hive数据库、表、分区和列的一些当前状态信息,通过收集这些状态信息,可以帮助我们更好地监控Hive数据库当前的状态,提前感知可能存在的问题;可以帮助基于成本代价的SQL查询优化,做更为正确的自动优化操作。
Hive的元数据主要分为5个大部分:数据库相关的元数据、表相关的元数据、分区相关的元数据、文件存储相关的元数据及其他。
1.2.1数据库的元数据

DBS:描述Hive中所有的数据库库名、存储地址(用字段DB_LOCATION_URI表示)、拥有者和拥有者类型。DBS表的内容:

Hive可以通过命令“desc database库名”来查询DBS的信息
DATABASE_PARAMS:描述数据库的属性信息(DBPROPERTIES)。查询MySQL中的DATABASE_PARAMS表

DB_PRIVS:描述数据库的权限信息。
FUNCS:记录用户自己编写的函数信息(UDF),包括该函数的函数名、对应的类名和创建者等信息。用户可以通过命令“create function函数名…”来创建自定义函数。
FUNCS_RU:记录自定义函数所在文件的路径,例如使用Java编写Hive的自定义函数,FUNCS_RU表会记录该函数所在JAR包的HDFS存储位置,以及该JAR包引用的其他JAR包信息。
1.2.2 表的元数据
表的元数据及这些元数据之间的关系
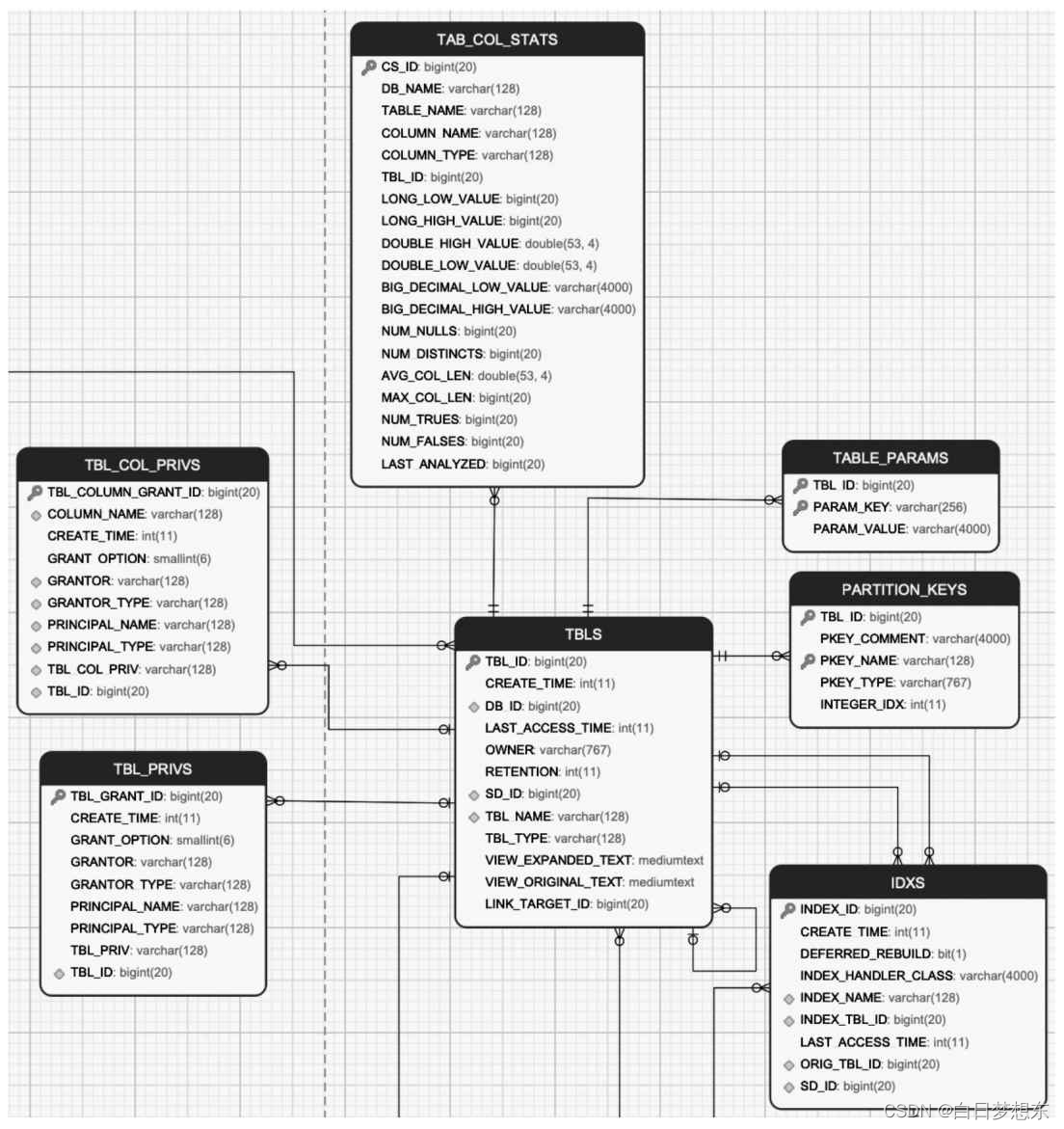
TBLS:记录Hive数据库创建的所有表,包含表所属的数据库、创建时间、创建者和表的类型(包括内部表、外部表、虚拟视图等)。在Hive中使用命令“desc formatted表名”,查看Detailed Table Information一节的信息

TABLE_PARAMS:表的属性信息,对应的是创建表所指定的TBLPROPERTIES内容或者通过收集表的统计信息。收集表的统计信息可以使用如下的命令:Analyze table表名compute statistics表的统计信息一般包含表存储的文件个数(numFiles)、总文件大小(totalSize)、表的总行数(numRows)、分区数(numPartitions)和未压缩的每行的数据量(rawDataSize)等。
TAB_COL_STATS:表中列的统计信息,包括数值类型的最大和最小值,如LONG_LOW_VALUE、LONG_HIGH_VALUE、 DOUBLE_HIGH_VALUE、DOUBLE_LOW_VALUE、BIG_DECIMAL_LOW_VALUE、BIG_DECIMAL_HIGHT_VALUE、空值的个数、列去重的数值、列的平均长度、最大长度,以及值为TRUE/FALSE的个数等。
TBL_PRIVS:表或者视图的授权信息,包括授权用户、被授权用户和授权的权限等。
TBL_COL_PRIVS:表或者视图中列的授权信息,包括授权用户、被授权的用户和授权的权限等。
PARTITION_KEYS:表的分区列。
IDXS:Hive中索引的信息,Hive 3.0已经废弃。
1.2.3 分区的元数据
分区的元数据及这些元数据之间的关系

·PARTITIONS:存储分区信息,包括分区列,分区创建的时间。
·PARTITION_PARAMS:存储分区的统计信息,类似于表的统计信息一样。
·PART_COL_STATS:分区中列的统计信息,类似于表的列统计信息一致。
·PART_PRIVS:分区的授权信息,类似于表的授权信息。
·PART_COL_PRIVS:分区列的授权信息,类似于表的字段授权信息。
·PARTITION_KEY_VALS:分区列对应的值。
1.2.4 数据存储的元数据
数据存储的元数据及这些元数据之间的关系
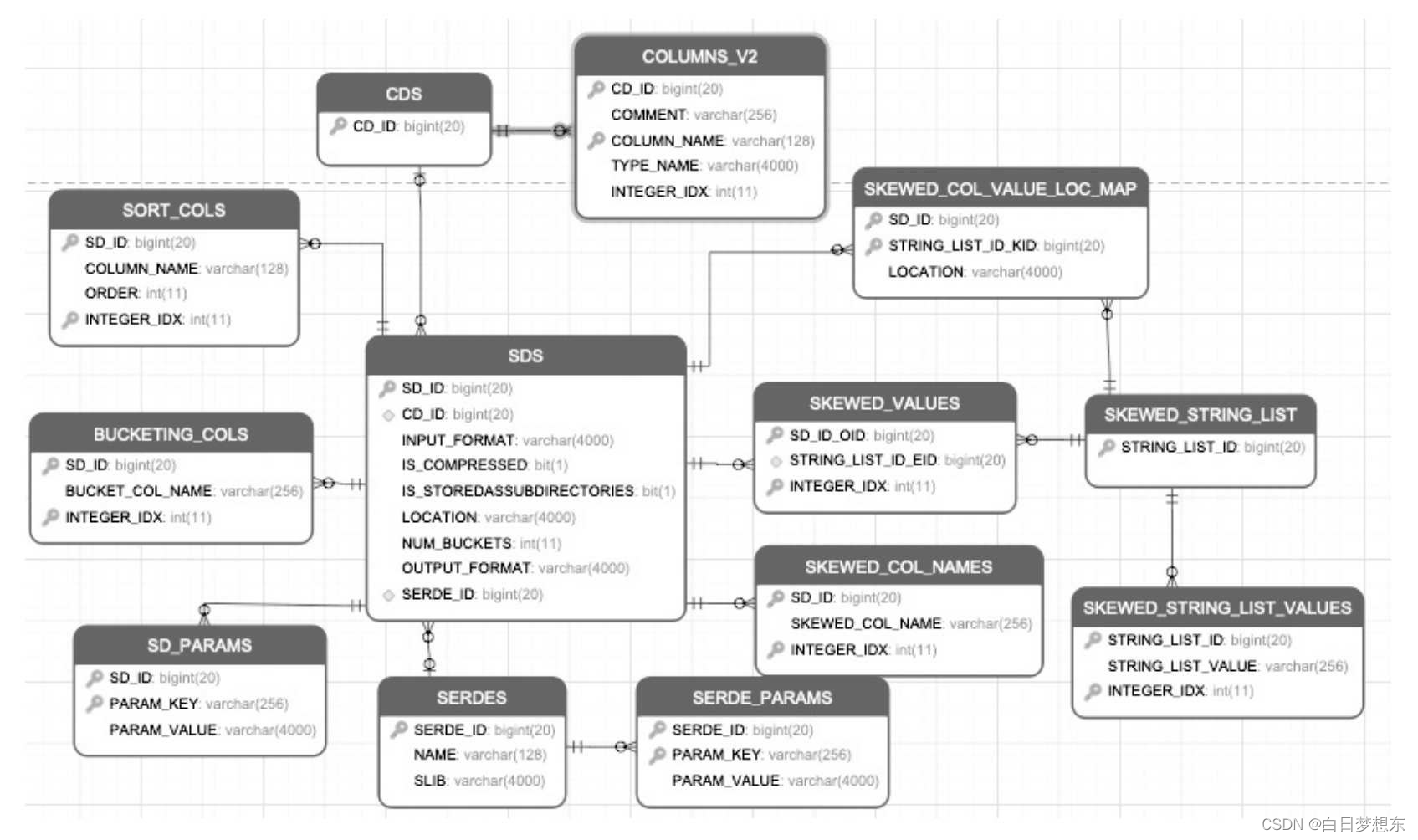
·SDS:保存数据存储的信息,包含分区、表存储的HDFS路径地址、输入格式(INPUTFORMAT)、输出格式(OUTPUTFORMAT)、分桶的数量、是否有压缩、是否包含二级子目录。
·CDS、COLUMN_V2:表示该分区、表存储的字段信息,包含字段名称和类型等。
·SORT_COLS:保存Hive表、分区有排序的列信息,包括列名和排序方式等。
·BUCKETING_COLS:保存Hive表,分区分桶列的信息、列名等。
·SERDES:保存Hive表、分区序列化和反序列化的方式。
·SERDES_PARAMS:保存Hive,分区序列化和反序列化的配置属性,例如行的间隔符(line.delim)、字段的间隔符(filed.delim)。
·SKEWED_COL_NAMES:保存表、分区有数据倾斜的列信息,包括列名。
·SKEWED_VALUES:保存表、分区有数据倾斜的列值信息。
·SKEWED_COL_VALUE_LOC_MAP:保存表、分区倾斜列对应的本地文件路径。
·SKEWED_STRING_LIST、SKEWED_STRING_LIST_VALUES:保存表,分区有数据倾斜的字符串列表和值信息。
2.YARN组件
在生产环境中的大数据集群,所有作业或系统运行所需的资源,都不是
直接向操作系统申请,而是交由资源管理器和调度框架代为申请。每个作业
或系统所需的资源都是由资源管理和调度框架统一分配、协调。在业界中扮
演这一角色的组件有YARN、Mesos等。
- 待详细写
3.HDFS组件
- 待详细记录
4.计算引擎
HiveSQL最后都会转化成各个计算引擎所能执行的任务,目前Hive支持MapReduce、Tez和Spark 3种计算引擎。
- 待详细记录
智能推荐
JAVA中一些术语的中英文对照_java中declare是什么意思-程序员宅基地
文章浏览阅读1.3w次,点赞11次,收藏58次。前几天借了一本JAVA完全参考手册,想从头好好学一下,正好里面很多术语都有英文注释,于是想总结出来万一以后看英文文档用的上呢!每天积累一点点!OOP(Object-Oriented Programming):面向对象编程process-oriented model:面向过程模型structed programming:结构化编程bytecode:字节码interpret_java中declare是什么意思
院内导航移动导诊服务体系,院内导航怎么实现?-程序员宅基地
文章浏览阅读361次。● 基于地标物导航(专利技术产品,零成本实现室内实时导航):室内无GPS、北斗信号,实现导航需进行室内5G、蓝牙、WiFi、UWB等定位系统覆盖进行支撑,投资大、实施复杂,懒图采用地标物导航模式,在地图完成后自动提取生成地标参照物,根据人们在生活中的寻人问路习惯,地图导航结合用户身处场景,明确告知客户朝能看到的地标物方向行进或转弯,如同专人引导;● 集成停车服务,实现医院停车场的一体化服务,为开车的人提供服务,实现停车位去医院各科室的路径指引,同时在就医结束后帮助用户实现反向寻车;
使用nodejs对Marketing Cloud的contact主数据进行修改操作-程序员宅基地
文章浏览阅读145次。假设在Marketing Cloud有这样一个contact主数据:现在需求是使用编程语言比如nodejs修改这个contact实例的高亮属性。代码如下:..._nodejs 对返回的数据进行修改
Android:LayoutInflater 如何使用_怎么layoutinflater-程序员宅基地
文章浏览阅读1.1k次。今天在写Fragment加载布局文件时,用到了LayoutInflater 的 inflate方法。当时用的是 inflate(resource, root)。但是当运行程序时,报了个异常:java.lang.IllegalStateException: The specified child already has a parent. You must call removeView()_怎么layoutinflater
手把手带你玩转Spark机器学习-Spark的安装及使用_spark 安装使用-程序员宅基地
文章浏览阅读7.1k次,点赞13次,收藏56次。本文首先介绍了Spark的基础知识以及RDD和DataFrame这些核心概念,然后演示了如何下载Spark二进制版本并搭建一个本地单机模式下的开发环境,最后通过Python语言来编写第一个Spark程序。_spark 安装使用
美国退伍军人事务部应对大数据挑战的七种方式-程序员宅基地
文章浏览阅读103次。大数据一定要让人大伤脑筋? 美国退伍军人事务部(简称VA)在大数据方面遇上了大难题。 作为弗吉尼亚州数据管理与分析事务助理部长兼分析师,Dat Tran在本周于美国马萨诸塞州坎布里奇市的麻省理工学院第七届年度信息质量研讨会上担任主讲嘉宾。VA是美国国内第二大...
随便推点
JavaScript操作SVG画图库:基于jquery的插件jquery.svgmagic.js_jquery 引用 svg.js-程序员宅基地
文章浏览阅读2.6k次。1.svgmagic.js插件操作SVG方法: 示例:http://blog.csdn.net/linshutao/article/details/30053233 jquery.svgmagic.js地址:https://github.com/dirkgroenen/SVGMagic http://www.jqcool.net/jquery-svgmagic.html http://www_jquery 引用 svg.js
WiFi信息_dwresult = wlangetavailablenetworklist(hclient, &p-程序员宅基地
文章浏览阅读274次。官网范例:https://docs.microsoft.com/en-us/windows/win32/api/wlanapi/nf-wlanapi-wlangetavailablenetworklist简单范例:#ifndef UNICODE#define UNICODE#endif#include <windows.h>#include <iostream>#include <wlanapi.h>#include <objbase.h>_dwresult = wlangetavailablenetworklist(hclient, πfinfo->interfaceguid, 0,
BS模式与CS模式的区别_简述bs模式和cs模式-程序员宅基地
文章浏览阅读2.5k次。BS模式(Browser Server)简称:浏览器服务器意思就是客户端可以通过浏览器就可以访问服务端只要你的电脑上装有浏览器就可以访问不过在美工方面BS不如CS,速度也不如CS快。如京东,百度网页版本的,只要有浏览器就可以访问只有当服务器升级你才需要升级。CS模式(Client Server)简称:客户端服务器客户端想要访问服务器时,必须在本机上安装客户端软件。如果软件升级那么,都需要升级。比如QQ10.0版本,服务器升级了11.0,那么全世界每一个使用QQ的客户端都要升级..._简述bs模式和cs模式
armlink - Scatter file文件格式 _veneer$$code-程序员宅基地
文章浏览阅读5.8k次。Scatter file (分散加载描述文件)用于armlink的输入参数,他指定映像文件内部各区域的download与运行时位置。Armlink将会根据scatter file生成一些区域相关的符号,他们是全局的供用户建立运行时环境时使用。 (注意:当使用了scatter file 时将不会生成以下符号:Image$$RW$$Base,Image$$RW$$Limit,Ima_veneer$$code
每天一道C语言编程:合格密码的判定_c语言验证密码是否安全-程序员宅基地
合格密码的判定,通过统计密码中每个字母的个数,判断是否满足长度要求和字母个数要求。
【云服务器部署】---Linux下安装MySQL-程序员宅基地
文章浏览阅读365次。【云服务器部署】---Linux下安装MySQL 有关如何阿里云ECS建网站,推荐一片文章,我是是通过这篇文章安装tomcat和jdk的 网址:阿里云ECS建网站(建站)超详细全套完整图文教程! 注意:阿里云服务器默认是没有开8080端口的,所以你要先去开启控制台开启8080端口,才能访问tomcat ..._移动云服务器上装 linux 为什么mysql 没办法安装上去