通过写代码学习AWS DynamoDB (2)_aws ddb-程序员宅基地
简介
在上一篇文章里,我们实现了DDB的基本API。上一篇文章请见《通过写代码学习AWS DynamoDB(1)》。在本文中,我们将进一步增强该DDB的模拟实现,给DDB加入Partition。
Partition是Shard的一种。关于Shard的介绍可以参看这篇文章。我们简单介绍一下Shard和Parition的概念。然后我们会在DDB的实现中加上一个简单的Parition的实现。
Shard介绍
区别于传统的基于集中式环境实现数据存储,分布式系统是将数据分散的存储在多个地方,可能是不同的host,或者是server,或者是cluster,等等。每一个这样的节点就是一个shard。使用shard带来的好处有以下几点:
- scale更加容易实现和管理:假如数据存储在一个集中的节点上,我们就要预先估计我们要使用的数据存储容量。过大会浪费很多存储,过小又会需要经常调整,非常麻烦。而且单一存储节点的容量调整本身也很麻烦,一般需要具有一定的专业知识,通过复杂的操作和指令来实现存储容量的扩容。但是有了shard这一切就变得简单和灵活很多。在需要调整数据存储容量时,我们仅仅需要增加和减少shard。
- 系统的robust会得到加强。传统的集中存储方式,一旦存储的服务器出现问题,整个系统就会瘫痪。但是基于shard的实现,如果一个shard出现问题,系统仅仅是部分数据无法访问,整体功能仍然可以部分得到保障。如果我们将shard和replica配合使用,则可以保障整体系统的robust会更好。
- 系统的响应时间会得到改善。不同于传统的集中式存储,数据可以根据需要存储在多个shard里。首先,多个存储本身就很有利于并行的处理数据操作,从而使得响应时间得到改善。其次,shard可以根据需要部署到和client更近的地方,从而改善响应时间。例如,如果数据是和城市有关的,那么我们可以将数据按照城市分别存到不同的shard里,并将每个城市的shard部署到该城市。
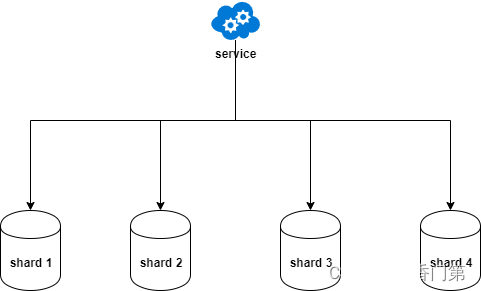
Shard的方法:
- Range-based sharding:通过对某一条或者几条attribute进行区间划分来决定shard。比如对于人口的数据按照年龄的分布,0到10岁存储到一个shard,10岁到20岁存储到一个shard,等。
- Hashed sharding:通过对key进行hash来决定该一条记录所对应的shard。
- Directory sharding:通过某种形式的对应来决定一条记录所对应的shard。比如存储文章,我们可以将历史类的存储在一个shard,文学类的存储在一个shard,等。
- Geo sharding:通过地理位置来决定shard。比如上面例子中通过城市来决定。
Partition介绍
数据库的Partition是将数据分成多个小组进行处理的一种技术。所以partition和shard基本一样的设计理念,但是不完全一样。Parition分为两种:
- 横向partition:将数据表的行进行分组。
- 纵向partition:将数据表的列进行分组。
事实上,两种partition都可以认为是shard在数据库中的具体实现。
在DynamoDB的模拟实现中加入Partition
首先我们先实现一个Parition类。这个Partition类可以实现CRUD的功能(也就是create,read,update,delete),同时它还提供了一个接口可以返回该partition的统计信息。具体代码如下:
class Partition:
def __init__(self):
self.storage = {}
def put_item(self, key, value):
self.storage.update({key: value})
def get_item(self, key):
return self.storage[key]
def delete_item(self, key):
self.storage.pop(key)
def get_item_count(self):
return len(self.storage.items())我们将给DDB的table添加Parition List。在这里我们使用Hash partition。针对每一个key,我们首先计算该key的hash value,然后对partition的个数取模来确定该key应该存在在哪个partition里。并且现在Table将不再保存数据的统计信息(例如有多少条数据),因为数据已经分布到多个partition里,所以Table将通过轮询Paritition的方式来汇总Table级别的统计信息(参见Table.describe()的实现)。代码的实现如下:
import functools
from partition import Partition
# class to provide DDB public APIs
# - support partitions based on hash value of key;
class DDB:
def __init__(self):
self.tables = {}
def create_table(self, table_name):
self.tables[table_name] = self.Table(table_name)
def list_table(self):
for table in self.tables.values():
table.describe()
def delete_table(self, table_name):
self.tables.pop(table_name)
def get_table(self, table_name):
return self.tables[table_name]
class Table:
def __init__(self, name, partition_count=3):
self.name = name
self.partitions = [Partition() for _ in range(partition_count)]
self.partition_count = partition_count
def put_item(self, key, value):
print("save {} to partition {}".format(key, self.get_partition_id(key)))
self.partitions[self.get_partition_id(key)].put_item(key, value)
def update_item(self, key, value):
self.partitions[self.get_partition_id(key)].put_item(key, value)
def get_item(self, key):
print("get {} from partition {}".format(key, self.get_partition_id(key)))
return self.partitions[self.get_partition_id(key)].get_item(key)
def delete_item(self, key):
print("delete {} from partition {}".format(key, self.get_partition_id(key)))
self.partitions[self.get_partition_id(key)].delete_item(key)
def describe(self):
item_count = functools.reduce(lambda x, y : x + y.get_item_count(), self.partitions, 0)
print("Table name: {}, item size: {}".format(self.name, item_count))
def get_partition_id(self, key):
return self.my_hash(key) % self.partition_count
def my_hash(self, text:str):
hash=0
for ch in text:
hash = ( hash*281 ^ ord(ch)*997) & 0xFFFFFFFF
return hash现在我们DDB的class diagram看起来是这个样子:

显示我们修改一下我们之前的测试代码,并且看一下partition是否工作正常:
from ddb import DDB
ddb = DDB()
table_name = "test_table"
key = "test_key"
value = "test_value"
ddb.create_table(table_name)
ddb.list_table()
ddb_table = ddb.get_table(table_name)
ddb_table.put_item("1", value)
ddb_table.put_item("2", value)
ddb_table.put_item("3", value)
print(ddb_table.get_item("1"))
print(ddb_table.get_item("2"))
print(ddb_table.get_item("3"))
ddb_table.delete_item("1")
ddb_table.describe()
代码的运行结果:
Table name: test_table, item size: 0
save 1 to partition 1
save 2 to partition 2
save 3 to partition 0
get 1 from partition 1
test_value
get 2 from partition 2
test_value
get 3 from partition 0
test_value
delete 1 from partition 1
Table name: test_table, item size: 2我们看到每条记录被正确的存储到各个partition里,并且可以正常的访问。关于整张表的统计信息,也就是表里有多少条记录也是正确的。
小结
我们的DDB已经可以将数据灵活的存储在多个partition里了。现在我们可以很容易scale out或者scale in我们的DDB。但是我们注意到如下问题:
- 如果partition增加,根据hash value模partition的数量来确定partition的方式就不正确了,因为一条数据对应的partition会发生改变。
- 我们仅仅是在存储上实现了partition,但是并没有真正实现并行的数据处理。
- 我们的数据库没有replica来保障数据和服务availability。
这些问题我们将在后面的文章中继续解决。
智能推荐
874计算机科学基础综合,2018年四川大学874计算机科学专业基础综合之计算机操作系统考研仿真模拟五套题...-程序员宅基地
文章浏览阅读1.1k次。一、选择题1. 串行接口是指( )。A. 接口与系统总线之间串行传送,接口与I/0设备之间串行传送B. 接口与系统总线之间串行传送,接口与1/0设备之间并行传送C. 接口与系统总线之间并行传送,接口与I/0设备之间串行传送D. 接口与系统总线之间并行传送,接口与I/0设备之间并行传送【答案】C2. 最容易造成很多小碎片的可变分区分配算法是( )。A. 首次适应算法B. 最佳适应算法..._874 计算机科学专业基础综合题型
XShell连接失败:Could not connect to '192.168.191.128' (port 22): Connection failed._could not connect to '192.168.17.128' (port 22): c-程序员宅基地
文章浏览阅读9.7k次,点赞5次,收藏15次。连接xshell失败,报错如下图,怎么解决呢。1、通过ps -e|grep ssh命令判断是否安装ssh服务2、如果只有客户端安装了,服务器没有安装,则需要安装ssh服务器,命令:apt-get install openssh-server3、安装成功之后,启动ssh服务,命令:/etc/init.d/ssh start4、通过ps -e|grep ssh命令再次判断是否正确启动..._could not connect to '192.168.17.128' (port 22): connection failed.
杰理之KeyPage【篇】_杰理 空白芯片 烧入key文件-程序员宅基地
文章浏览阅读209次。00000000_杰理 空白芯片 烧入key文件
一文读懂ChatGPT,满足你对chatGPT的好奇心_引发对chatgpt兴趣的表述-程序员宅基地
文章浏览阅读475次。2023年初,“ChatGPT”一词在社交媒体上引起了热议,人们纷纷探讨它的本质和对社会的影响。就连央视新闻也对此进行了报道。作为新传专业的前沿人士,我们当然不能忽视这一热点。本文将全面解析ChatGPT,打开“技术黑箱”,探讨它对新闻与传播领域的影响。_引发对chatgpt兴趣的表述
中文字符频率统计python_用Python数据分析方法进行汉字声调频率统计分析-程序员宅基地
文章浏览阅读259次。用Python数据分析方法进行汉字声调频率统计分析木合塔尔·沙地克;布合力齐姑丽·瓦斯力【期刊名称】《电脑知识与技术》【年(卷),期】2017(013)035【摘要】该文首先用Python程序,自动获取基本汉字字符集中的所有汉字,然后用汉字拼音转换工具pypinyin把所有汉字转换成拼音,最后根据所有汉字的拼音声调,统计并可视化拼音声调的占比.【总页数】2页(13-14)【关键词】数据分析;数据可..._汉字声调频率统计
linux输出信息调试信息重定向-程序员宅基地
文章浏览阅读64次。最近在做一个android系统移植的项目,所使用的开发板com1是调试串口,就是说会有uboot和kernel的调试信息打印在com1上(ttySAC0)。因为后期要使用ttySAC0作为上层应用通信串口,所以要把所有的调试信息都给去掉。参考网上的几篇文章,自己做了如下修改,终于把调试信息重定向到ttySAC1上了,在这做下记录。参考文章有:http://blog.csdn.net/longt..._嵌入式rootfs 输出重定向到/dev/console
随便推点
uniapp 引入iconfont图标库彩色symbol教程_uniapp symbol图标-程序员宅基地
文章浏览阅读1.2k次,点赞4次,收藏12次。1,先去iconfont登录,然后选择图标加入购物车 2,点击又上角车车添加进入项目我的项目中就会出现选择的图标 3,点击下载至本地,然后解压文件夹,然后切换到uniapp打开终端运行注:要保证自己电脑有安装node(没有安装node可以去官网下载Node.js 中文网)npm i -g iconfont-tools(mac用户失败的话在前面加个sudo,password就是自己的开机密码吧)4,终端切换到上面解压的文件夹里面,运行iconfont-tools 这些可以默认也可以自己命名(我是自己命名的_uniapp symbol图标
C、C++ 对于char*和char[]的理解_c++ char*-程序员宅基地
文章浏览阅读1.2w次,点赞25次,收藏192次。char*和char[]都是指针,指向第一个字符所在的地址,但char*是常量的指针,char[]是指针的常量_c++ char*
Sublime Text2 使用教程-程序员宅基地
文章浏览阅读930次。代码编辑器或者文本编辑器,对于程序员来说,就像剑与战士一样,谁都想拥有一把可以随心驾驭且锋利无比的宝剑,而每一位程序员,同样会去追求最适合自己的强大、灵活的编辑器,相信你和我一样,都不会例外。我用过的编辑器不少,真不少~ 但却没有哪款让我特别心仪的,直到我遇到了 Sublime Text 2 !如果说“神器”是我能给予一款软件最高的评价,那么我很乐意为它封上这么一个称号。它小巧绿色且速度非
对10个整数进行按照从小到大的顺序排序用选择法和冒泡排序_对十个数进行大小排序java-程序员宅基地
文章浏览阅读4.1k次。一、选择法这是每一个数出来跟后面所有的进行比较。2.冒泡排序法,是两个相邻的进行对比。_对十个数进行大小排序java
物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)_网络调试助手连接阿里云连不上-程序员宅基地
文章浏览阅读2.9k次。物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)其实作者本意是使用4G模块来实现与阿里云物联网平台的连接过程,但是由于自己用的4G模块自身的限制,使得阿里云连接总是无法建立,已经联系客服返厂检修了,于是我在此使用网络调试助手来演示如何与阿里云物联网平台建立连接。一.准备工作1.MQTT协议说明文档(3.1.1版本)2.网络调试助手(可使用域名与服务器建立连接)PS:与阿里云建立连解释,最好使用域名来完成连接过程,而不是使用IP号。这里我跟阿里云的售后工程师咨询过,表示对应_网络调试助手连接阿里云连不上
<<<零基础C++速成>>>_无c语言基础c++期末速成-程序员宅基地
文章浏览阅读544次,点赞5次,收藏6次。运算符与表达式任何高级程序设计语言中,表达式都是最基本的组成部分,可以说C++中的大部分语句都是由表达式构成的。_无c语言基础c++期末速成