【文献阅读】A2-Nets: Double Attention Networks-程序员宅基地
技术标签: 算法 卷积 文献阅读 机器学习 计算机视觉 深度学习
原文链接:https://arxiv.org/abs/1810.11579
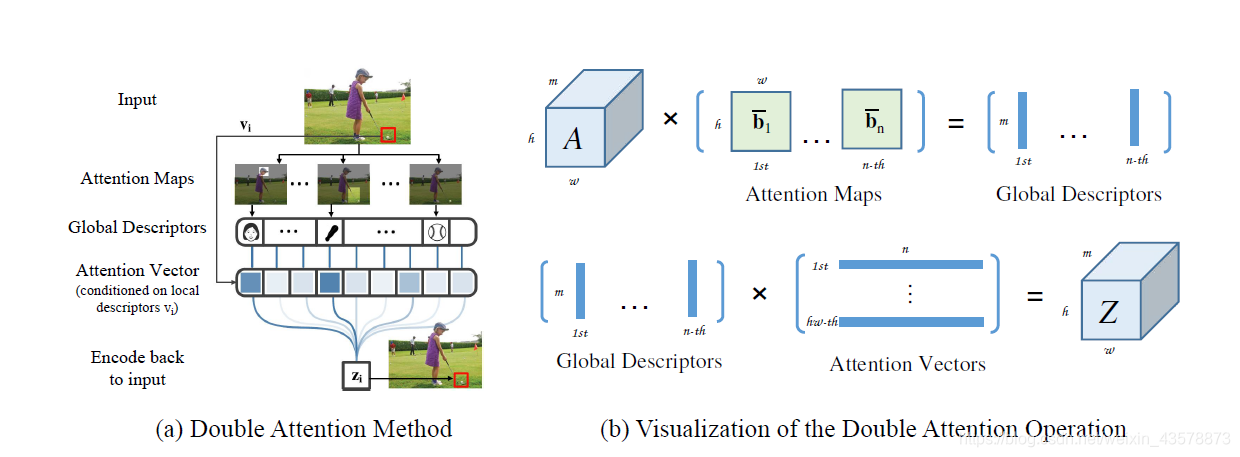
学习捕获长距离关系是图像/视频识别的基础。现有的CNN模型一般依赖于增加深度来对这种关系进行建模,效率非常低。作者提出了“双注意力块”,这是一种新的组件,它从输入图像/视频的整个时空空间中聚集和传播信息的全局特征,使后续的卷积层能够有效地从整个空间访问特征。该组件设计为两步双注意机制,第一步通过二级注意池将整个空间的特征集合成一个紧凑的集合,第二步通过另一个注意力自适应地选择和分配特征到每个位置。
CNN天生就受到卷积运算的限制,卷积运算致力于捕获局部特征和关系,并且在建模长距离相互依赖关系方面效率低下。虽然叠加多个卷积算子可以扩大接受域,但在实践中也存在一些不利的问题。
- 将多个操作符叠加在一起,使得模型变得不必要的深和大,导致更高的计算和内存成本,增加了过度拟合的风险;
- 远离特定位置的特征在影响正向传播和反向传播的位置之前,都要经过一层堆栈,增加了训练过程中的优化难度;
- 远处可见的特征实际上是后面几层的“延迟”的,导致了低效的推理。
作者提出的A2-Net的核心思想是首先将整个空间的关键特征收集到一个紧凑的集合中,然后自适应地将其分布到每个位置,这样后续的卷积层即使没有很大的接收域也可以感知整个空间的特征。
第一级的注意力集中操作有选择地从整个空间中收集关键特征,而第二级的注意力集中操作采用另一种注意力机制,自适应地分配关键特征的子集,这些特征有助于补充高级任务的每个时空位置。
A2-Net与SENet、协方差池化、Non-local、Transformer有点类似,但是不同点在于它的第一个注意力操作隐式地计算池化特征的二阶统计,并能捕获SENet中使用的全局平均池化无法捕获的复杂外观和运动相关性;它的第二注意力操作从一个紧凑的袋子中自适应地分配特征,这比 Non-local、Transformer中将所有位置的特征与每个特定位置进行穷举关联更有效。
主要贡献如下:
- 提出了一个通用的公式,通过通用的收集和分布函数来捕获长期的特征相关性
- 提出了一种用于收集和分布长距离特征的双注意块,它是一种有效的二次特征统计和自适应特征分配的体系结构。该块可以用较低的计算和内存占用来建模长期的相互依赖关系,同时显著提高图像/视频识别性能
- 通过广泛的消融研究来调查提出的A2-Net的影响,并通过与当前技术水平的比较来证明它在图像识别和视频动作识别任务的一些公共基准上的优越性能
方法
设 X ∈ R c × h × w X\in \mathbb{R}^{c \times h \times w} X∈Rc×h×w为输入,每个位置 i = 1 , ⋯ , h w i=1, \cdots,hw i=1,⋯,hw的特征为 v i v_i vi,定义
z i = F d i s t r ( G g a t h e r ( X ) , v i ) z_i=F_{distr}(G_{gather}(X),v_i) zi=Fdistr(Ggather(X),vi)
为输出:首先收集整个空间的特征,然后将其分配回每个输入位置 i i i,同时考虑该位置的局部特征 v i v_i vi。
这种先 g a t h e r i n g gathering gathering再 d i s t r i b u t i n g distributing distributing的想法源于SENet,而SENet在收集过程中使用 g l o b a l a v e r a g e p o o l i n g global \space average \space pooling global average pooling而产生的单个全局特性被分发到所有位置,忽略了位置之间的不同需求。
而A2-Net中,更复杂的全局关系可以被一组紧凑的特征所捕获,每个位置可以接收其自定义的全局信息,这些信息与现有的局部特征相辅相成,有助于学习更复杂的关系。
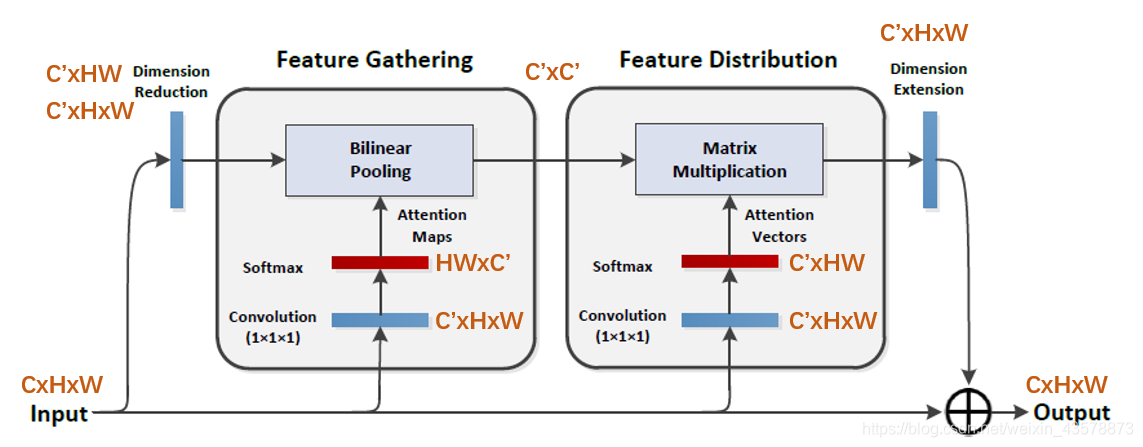
Feature Gathering
与只计算一阶统计量的传统平均池化和最大池化相比,双线性池化能更好地捕捉和保持复杂关系。
双线性池化就是将两张输入特征图 A A A和 B B B里的特征向量对 ( a i , b i ) (a_i,b_i) (ai,bi)做外积并相加:
G b i l i n e a r ( A , B ) = A B T = ∑ ∀ i a i b i T G_{bilinear}(A,B)=AB^T=\sum_{\forall i}a_i b_i^T Gbilinear(A,B)=ABT=∀i∑aibiT
其中, A = [ a 1 , ⋯ , a h w ] ∈ R m × h w A=[a_1,\cdots,a_{hw}] \in \mathbb{R}^{m \times hw} A=[a1,⋯,ahw]∈Rm×hw; B = [ b 1 , ⋯ , b h w ] ∈ R n × h w B=[b_1,\cdots,b_{hw}] \in \mathbb{R}^{n \times hw} B=[b1,⋯,bhw]∈Rn×hw。在CNNs中, A A A和 B B B可以是同层出来的特征图 A = B A=B A=B;也可以是两个不同层出来的特征图 A = ϕ ( X ; W ϕ ) A=\phi(X;W_{\phi}) A=ϕ(X;Wϕ), B = θ ( X ; W θ ) B=\theta(X;W_{\theta}) B=θ(X;Wθ), W ϕ W_{\phi} Wϕ和 W θ W_{\theta} Wθ是参数。
通过引入输出变量 G = [ g 1 , ⋯ , g n ] ∈ R m × n G=[g_1,\cdots,g_n]\in \mathbb{R}^{m \times n} G=[g1,⋯,gn]∈Rm×n并且重写第二个特征 B = [ b ˉ 1 , ⋯ , b ˉ n ] B=[\bar{b}_1,\cdots,\bar{b}_n] B=[bˉ1,⋯,bˉn], b ˉ i \bar{b}_i bˉi是一个 h w hw hw维的行向量,输出为
g i = A b ˉ i T = ∑ ∀ j b ˉ i j a j g_i=A \bar{b}_i^T=\sum_{\forall j}\bar{b}_{ij}a_j gi=AbˉiT=∀j∑bˉijaj
上述公式不仅是计算二阶统计量,输出 G G G实际上是一个视觉基元包,每个基元 g i g_i gi是通过收集局部特征用 b ˉ i \bar{b}_i bˉi加权得到的; j j j为特征图上的位置; i i i为不同的 A t t e n t i o n M a p s Attention \space Maps Attention Maps。
进一步将 s o f t m a x softmax softmax应用于 B B B, ∑ j b ˉ i j = 1 \sum_j \bar{b}_{ij}=1 ∑jbˉij=1,可得到二阶注意力池化过程为
g i = A s o f t m a x ( b ˉ i ) T g_i=A \space softmax(\bar{b}_i)^T gi=A softmax(bˉi)T
令 A = ϕ ( X ; W ϕ ) A=\phi(X;W_{\phi}) A=ϕ(X;Wϕ), B = s o f t m a x ( θ ( X ; W θ ) ) B=softmax(\theta(X;W_{\theta})) B=softmax(θ(X;Wθ)), X X X为输入的特征图。
Feature Distribution
从整个空间中收集特征后的下一步是将它们分布到输入的每个位置,这样即使使用很小的卷积核,后续的卷积层也可以感知全局信息。
不像SENet那样将相同的全局特性分布到所有的位置,而是在每个位置上根据特征 v i v_i vi的需要分布一个自适应的视觉基元包来获得更大的灵活性。
这是通过 s o f t a t t e n t i o n soft \space attention soft attention从 G g a t h e r ( X ) G_{gather}(X) Ggather(X)中选择一个特征向量子集来实现的:
z i = ∑ ∀ j v i j g j = G g a t h e r ( X ) v i , w h e r e ∑ ∀ j v i j = 1 z_i=\sum_{\forall j}v_{ij}g_j=G_{gather}(X)v_i,\space where \space \sum_{\forall j}v_{ij}=1 zi=∀j∑vijgj=Ggather(X)vi, where ∀j∑vij=1
V = s o f t m a x ( ρ ( X ; W ρ ) ) V=softmax(\rho(X;W_{\rho})) V=softmax(ρ(X;Wρ)),其中 W ρ W_{\rho} Wρ为参数。
The Double Attention Block
将上面两个注意步骤结合起来,形成双注意块里模块:
Z = F d i s t r ( G g a t h e r ( X ) , V ) = G g a t h e r ( X ) s o f t m a x ( ρ ( X ; W ρ ) ) = [ ϕ ( X ; W ϕ ) s o f t m a x ( θ ( X ; W θ ) ) T ] s o f t m a x ( ρ ( X ; W ρ ) ) \begin{aligned} Z & =F_{distr}(G_{gather}(X), V) \\ & = G_{gather}(X)softmax(\rho(X;W_{\rho})) \\ & = [\phi(X;W_{\phi})softmax(\theta(X;W_{\theta}))^T]softmax(\rho(X;W_{\rho})) \end{aligned} Z=Fdistr(Ggather(X),V)=Ggather(X)softmax(ρ(X;Wρ))=[ϕ(X;Wϕ)softmax(θ(X;Wθ))T]softmax(ρ(X;Wρ))
智能推荐
王斌老师的博客_王斌 github-程序员宅基地
文章浏览阅读480次。http://blog.sina.com.cn/s/blog_736d0b9101018cgc.html_王斌 github
ACM OJ Collection_htt//acm.wydtang.top/-程序员宅基地
文章浏览阅读737次。原文来自:http://blog.csdn.net/hncqp/article/details/4455263 ACM OJ Collection(排名不分先后):中国:浙江大学(ZJU):http://acm.zju.edu.cn/北京大学(PKU):htt_htt//acm.wydtang.top/
ios 自己服务器 苹果支付_修复苹果IOS支付-程序员宅基地
文章浏览阅读467次。更新记录1.0.0(2019-07-01)插件简介专门用来修复苹果IOS支付时出现"您已购买此App内购买项目。此项目将免费恢复"。问题描述首先在IOS平台里面创建“APP内购买项目”,选择的是“消耗型项目”,然后用uni-app官方的支付api进行支付,多支付几次,有时候就会出现提示“您已购买此App内购买项目。此项目将免费恢复”,特别是在沙盒测试里面支付很大几率出现,我明明选的是消耗型项目,应..._ios开发苹果支付恢复权益
spring MVC mock类单元测试(controller)_mvcmock-程序员宅基地
文章浏览阅读5.6k次。Spring从J2EE的Web端为每个关键接口提供了一个mock实现:MockHttpServletRequest几乎每个单元测试中都要使用这个类,它是J2EE Web应用程序最常用的接口HttpServletRequest的mock实现。MockHttpServletResponse此对象用于HttpServletRespons_mvcmock
【我的世界Minecraft-MC】常见及各种指令大杂烩【2022.8版】_summon生成掉落物-程序员宅基地
文章浏览阅读8.5k次,点赞7次,收藏22次。execute as @a at @s run clear @s minecraft:dark_oak_planks{display:{Name:“{“text”:“第三关[阴森古堡]”,“color”:“red”,“italic”:false}”,color:“16711680”},Enchantments:[{id:“protection”,lvl:1}],Unbreakable:1b} 1。Lore:[“{“text”:“免费”,“color”:“blue”,“italic”:false}”]..._summon生成掉落物
CentOS 7安装教程(图文详解)_centos 安装-程序员宅基地
文章浏览阅读10w+次,点赞487次,收藏2.1k次。CentOS 7安装教程: 准备: 软件:VMware Workstation 镜像文件:CentOS-7-x86_64-bin-DVD1.iso (附:教程较为详细,注释较多,故将操作的选项进行了加粗字体显示。) 1、文件--新建虚拟机--自定义 2、..._centos 安装
随便推点
Github项目分享——免费的画图工具drow,前端插件化面试_draw github画图-程序员宅基地
文章浏览阅读333次,点赞3次,收藏3次。项目介绍一款很好用的免费画图软件,支持ER图、时序图、流程图等等在项目的releases就可以下载最新版本同时支持在线编辑。_draw github画图
如何开始学习人工智能?入门的学习路径和资源是什么?_人工智能学习路径-程序员宅基地
文章浏览阅读930次。嗨,大家好!如果你对人工智能充满了好奇,并且想要入门这个领域,那么你来对地方了。本文将向你介绍如何从零基础开始学习人工智能,并逐步掌握核心概念和技能。无论你是大学生、职场新人还是对人工智能感兴趣的任何人,都可以按照以下学习路径逐步提升自己。_人工智能学习路径
Unity3D 导入资源_unity怎么导入压缩包-程序员宅基地
文章浏览阅读4.3k次,点赞2次,收藏8次。打开Unity3D的:window-asset store就会出来这样的界面:我们选择一个天空纹理,注意这里的标签只有一个,如果有多个就会显示所有标签的内容:找个比较小的免费的下载一下试试,比如这个:下载以后:点击import就会出现该窗口:然后再点击最底下的import:就导入到我们这里来了。从上面可以切换场景:..._unity怎么导入压缩包
jqgrid 服务器端验证,javascript – jqgrid服务器端错误消息/验证处理-程序员宅基地
文章浏览阅读254次。在你以前的问题的the answer的最后一部分,我试着给出你当前的问题的答案.也许我表示不够清楚.您不应该将错误信息放在标准成功响应中.您应该遵循用于服务器和客户端之间通信的HTTP协议的主要规则.根据HTTP协议实现网格中的加载数据,编辑行和与服务器的所有Ajax通信.每个HTTP响应都有响应第一行的状态代码.了解这个意义非常重要.典型的JSON数据成功请求如下HTTP/1.1 200 OK...._decode message error
白山头讲PV: 用calibre进行layout之间的比对-程序员宅基地
文章浏览阅读4k次,点赞8次,收藏29次。我们在流片之后,通常还是有机会对layout进行局部小的修改。例如metal change eco或者一些层次的局部修改。当我们修改之后,需要进行与之前gds的对比,以便确认没有因为某些..._calibre dbdiff
java exit方法_Java:如何测试调用System.exit()的方法?-程序员宅基地
文章浏览阅读694次。问题我有一些方法应该在某些输入上调用567779278。不幸的是,测试这些情况会导致JUnit终止!将方法调用放在新线程中似乎没有帮助,因为System.exit()终止了JVM,而不仅仅是当前线程。是否有任何常见的处理方式?例如,我可以将存根替换为System.exit()吗?[编辑]有问题的类实际上是一个命令行工具,我试图在JUnit中测试。也许JUnit根本不适合这份工作?建议使用互补回归测..._检查system.exit