图论算法——图的遍历_洛谷 图的深度优先算法-程序员宅基地
图论算法也是非常基础且重要的算法(ps:好像没有不重要的......)
图的基本应用——图的遍历,从具体的题目着手,学习图的遍历方式及代码形式。
我们先来看一下题目,然后再具体分析图的遍历方式。
题目选自洛谷P5318
题目描述
小K 喜欢翻看洛谷博客获取知识。每篇文章可能会有若干个(也有可能没有)参考文献的链接指向别的博客文章。小K 求知欲旺盛,如果他看了某篇文章,那么他一定会去看这篇文章的参考文献(如果他之前已经看过这篇参考文献的话就不用再看它了)。
假设洛谷博客里面一共有 n(n≤105) 篇文章(编号为 1 到 n)以及 m(m≤10^6) 条参考文献引用关系。目前小 K 已经打开了编号为 1 的一篇文章,请帮助小 K 设计一种方法,使小 K 可以不重复、不遗漏的看完所有他能看到的文章。
这边是已经整理好的参考文献关系图,其中,文献 X → Y 表示文章 X 有参考文献 Y。不保证编号为 1 的文章没有被其他文章引用。
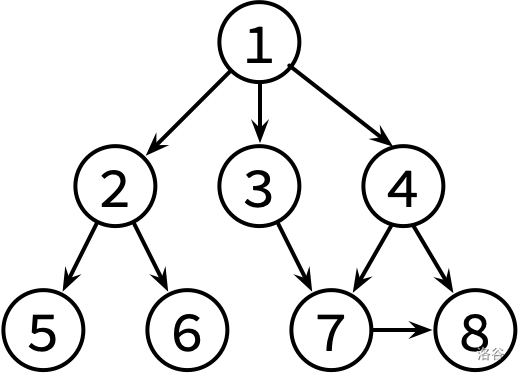
请对这个图分别进行 DFS 和 BFS,并输出遍历结果。如果有很多篇文章可以参阅,请先看编号较小的那篇(因此你可能需要先排序)。
输入格式
无
输出格式
无
输入输出样例
输入 1
8 9 1 2 1 3 1 4 2 5 2 6 3 7 4 7 4 8 7 8
输出 1
1 2 5 6 3 7 8 4 1 2 3 4 5 6 7 8
在之前的学习中已经接触到深度优先搜索DFS和广度优先搜索BFS。
深度优先遍历可以被看作在图中的深度优先搜索
广度优先遍历可以被看作在图中的广度优先搜索
可以比较一下,有助于更好理解和更快解题。
相信在座的各位应该知道图是个啥玩意,应该也知道“遍历”是啥:所谓“遍历”,就是把图上的每个顶点都找一遍呗!但是要找可不能瞎找,要不会把自己找晕,咱这里就有两种“防晕”的好方法!正所谓“举例是理解的试金石”,咱就拿样例来说!
首先看方式一
深度优先遍历
咱们可以一步一步向前去走:
从1出发,先去最小的2
然后从2出发,沿路到5
再从5出发......咦?没路了?好吧那就回去到2吧
出发点又到了2,这时候5已经到过啦,那就去6
6又没路了,好办!回到2,由于2通往的5和6都来过了,所以再回去到1,这时候1的路中2已经走过了,没走过的最前一个是3,那就在走到3
........
就这样一步一步走过去,可以得到顺序:
1 2 5 6 3 7 8 4这种方法就是一步一步去尝试,先从一条路走到黑,走完了就回去找另一条,总结成7个字就是“不撞南墙不回头”,有没有发现跟我们的“深度优先搜索”迷之相似???所以,我们叫它“图的深度优先遍历”
下面给出实例代码:(DFS版)
int n,m; vector<int> p[100005]; //使用邻接表来存储图 bool book[100005]; //记录某个点是否被访问过 void solve(int x){ cout<<x<<" "; for(int i=0,sz=p[x].size();i<sz;i++){ //邻接表的dfs方式 if(!book[p[x][i]]){ book[p[x][i]] = true; solve(p[x][i]); } } } int main(){ cin>>n>>m; for(int i=1;i<=m;i++){ //邻接表的存储方式 int x,y; cin>>x>>y; p[x].push_back(y); } book[1] = true; solve(1); return 0; }
然后看方式二
广度优先遍历
想用这种方法,你需要掌握一项技能——分身术还是从1出发,咱先把能走的都走一遍,依次到达2,3.4
1的走完了,咱就从下一个没往下走的地点开始,也就是从2出发,到达5,6
2的也走完了,目前最靠前的还没往下走过的点是3,好的,从3到达7,8
然后下一个没往下“扩展”的地点是4,哇,这时候7,8都已经走过了呢,那就走完啦
所以我们可以得到顺序:
1 2 3 4 5 6 7 8总之就是把每个没有向下走过的地方都走一遍,如果你看懂了,你可以发现这个方法和“广度优先搜索”算法很像,我们就叫它“图的广度优先遍历”
下面给出实例代码:(BFS版)
int n,m; vector<int> p[100005]; //使用邻接表来存储图 queue<int> q; //使用BFS当然得要队列了 bool book[100005]; //记录某个点是否被访问过 void bfs(){ //邻接表的bfs方式 book[1]=true; q.push(1); while(!q.empty()){ int x = q.front(); cout<<x<<" "; for(int i=0,sz=p[x].size();i<sz;i++){ if(!book[p[x][i]]){ book[p[x][i]] = true; q.push(p[x][i]); } } q.pop(); } } int main(){ cin>>n>>m; for(int i=1;i<=m;i++){ int x,y; cin>>x>>y; p[x].push_back(y); //将图保存到邻接表中 } bfs(); return 0; }
两种遍历方法都讲完了,接下来咱们考虑的就只有细节问题了,首先,这个题数据范围那么大,用邻接矩阵存肯定是会爆的,那咱们就用一种新的方法。
首先,我们用一个结构体vector(为了节省空间,咱用vector来存)存储每个边的起点和终点,然后用一个二维vector(也就是一个vector数组)存储边的信息。
这个存储方法可能有点难理解,不过其实也没那么难:我们用e[a][b]=c,来表示顶点a的第b条边是c号边。咱举个栗子,还是拿样例说吧:
8 9 1 2 //0号边(由于vector的下标是从0开始的,咱就“入乡随俗”,从0开始) 1 3 //1号边 1 4 //2号边 2 5 //3号边 2 6 //4号边 3 7 //5号边 4 7 //6号边 4 8 //7号边 7 8 //8号边最后二维vector中的存储会如下所示:
0 1 2 //1号顶点连着0、1、2号边 3 4 //2号顶点连着3、4号边 5 //3号顶点连着5号边 6 7 //4号顶点连着6、7号边 //5号顶点没有边 //6号顶点没有边 8 //7号顶点连着8号边 //8号顶点没有边看是不是对上号了?这个方法比较好懂,又节省空间,是个好方法。
别着急,我们题目还没解决呢。
回归到题目
别忘了题目要求:“如果有很多篇文章可以参阅,请先看编号较小的那篇”
那就排序呗!咱们按照题目要求,按照终点从小到大排列,如果终点相同按起点从小到大排列 注意我们说的第几号边是指排序后的序号
解题代码:
#include<stdio.h>
#include<iostream>
#include<algorithm>
#include<queue>
#include<vector>
using namespace std;
const int MAXN = 100010;
vector<int> G[MAXN];
int n, m;
bool visited[MAXN];
queue<int> q;
void dfs(int x, int cur) {
visited[x] = true;
cout << x << " ";
if (cur == n) return ;
for (int i=0; i<(int)G[x].size(); i++)
if (!visited[G[x][i]]) dfs(G[x][i], cur+1);
}
void bfs(int x) {
memset(visited, false, sizeof(visited));//记得一定要清空
visited[x] = true;
q.push(x);
while (!q.empty()) {
int v = q.front();
cout << v << " ";//输出
for (int i=0; i<(int)G[v].size(); i++)
if (!visited[G[v][i]]) {
visited[G[v][i]] = true;
q.push(G[v][i]);
}
q.pop();
}
}
int main() {
cin >> n >> m;
for (int i=1; i<=m; i++) {
int u, v;
cin >> u >> v;
G[u].push_back(v);//邻接表保存图
}
for (int i=1; i<=n; i++) sort(G[i].begin(), G[i].end());//标准vector排序
dfs(1, 0);
cout << endl;
bfs(1);
cout << endl;
return 0;
}智能推荐
2023.8DataWhale_cv夏令营第三期笔记_逻辑回归需要训练很多轮么-程序员宅基地
文章浏览阅读257次。使用官方提供的脑PET数据集,构建逻辑回归模型来进行脑PET图像的疾病预测,数据集被分为两类,分别为轻度认知障碍(MCI)患者的脑部影像数据和健康人(NC)的脑部影像数据,图像数据格式为nii,因此本赛题可抽象为一个二分类问题。nii是一种常用的医学图像数据格式,主要用于存储和交换神经影像数据。以下是一些主要特点:1.主要用于存储3D(三维)医学图像数据,如MRI(磁共振成像)和CT(计算机断层扫描)图像。2.支持多种数据类型,使得其可以支持不同类型的数据处理和分析。_逻辑回归需要训练很多轮么
通用指南-营销和设计中的增强现实(AR)-程序员宅基地
文章浏览阅读1.2k次,点赞31次,收藏26次。增强现实通常被视为一个利基领域。然而,在过去的两年里,它已经到了一个成熟的阶段,应该在一般的营销堆栈中进行考虑。正如我们所看到的,这个市场是巨大的,而且随着主要参与者向这项技术投入大量投资,它只会继续增长。从苹果到Meta,大公司都相信身临其境的未来,而想要获得成功的营销人员和创意人员也加入了进来。本文第三章,最佳设计实践除了深入讨论AR设计的原则外,还全面推荐了AI设计工具。旨在帮助读者的AI作品脱颖而出。
linux c 网络编程_usage: ./tcp_client hostname-程序员宅基地
文章浏览阅读473次。OSI七层网络模型由下至上为1至7层,分别为:物理层(Physical layer),数据链路层(Data link layer),网络层(Network layer),传输层(Transport layer),会话层(Session layer),表示层(Presentation layer),应用层(Application layer)。1.1 应用层,很简单,就是应用程序。这一层负责_usage: ./tcp_client hostname
Nexus3配置yum代理 pypi代理和npm代理(三合一)_maximum component age-程序员宅基地
文章浏览阅读2.8k次。环境准备安装 maven 安装 java 环境[root@cicd-nexus ~]# wget http://mirrors.tuna.tsinghua.edu.cn/apache/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz[root@cicd-nexus ~]# tar xf apache-maven-3.6.3-bin.tar.gz -C /usr/local/[root@cicd-nexus ~]# tar xf _maximum component age
使用js-xlsx handsontable 分批次导入Excel数据(兼容ie9)_js 导excel 分批写入-程序员宅基地
文章浏览阅读1.6k次。使用js-xlsx handsontable 可以把本地excel 解析到网页上,然后分批次传入后台。在chrome 下 可以参考 https://github.com/SheetJS/js-xlsx 【Browser file upload form element】但需要使用FileReader api 这个只有ie10 才开始支持。兼容ie9 ,ie9需要通过flash 来支持..._js 导excel 分批写入
wxWidgets 自绘按钮(图片+文字)_wxwidgets 中文按钮-程序员宅基地
文章浏览阅读2.5k次。在wxWidgets中,想要通过其本身的控件来实现图片+文件的按钮,貌似不太容易做到。但是可以通过重载wxControl来自绘图片+文件按钮。下面给出的是已经封装好的按钮类:wxBitmapButtonEx.h#ifndef _BITMAP_BUTTON_EX_H#define _BITMAP_BUTTON_EX_H#include "wx/wx.h"enum eBitm_wxwidgets 中文按钮
随便推点
invalidate()和postInvalidate()的区别_postinvalidate和invalidate的区别-程序员宅基地
文章浏览阅读847次。invalidate()与postInvalidate()都用于刷新View,主要区别是invalidate()在主线程中调用,若在子线程中使用需要配合handler;而postInvalidate()可在子线程中直接调用。postInvalidate它是向主线程发送个Message,然后handleMessage时,调用了invalidate()函数。(系统帮我们 写好了 Handle..._postinvalidate和invalidate的区别
计算机表格 求差,Excel表格中求差函数公式怎么用-程序员宅基地
文章浏览阅读9.1k次。excel数据进行分类汇总的步骤在做分类汇总前,我们需要对数据先进行排序,否则分类汇总无法进行。得到排序后的表格。点击上方工具栏中的“数据”→“分类汇总”。在弹出的对话框中选择“分类字段”→“汇总方式”→“决定汇总项”。点击确定出现数据汇总结果。Excel表格中求差函数公式使用的方法第一步:打开Excel表格,单击第一排,第三个“单元格”,也就是C1,在C1中输入“=A1-B1”;第二步:这个公式..._表格求差公式
Linux下OpenCV的安装与测试成功教程(解决E: 无法定位软件包 libjasper-dev、无法找到directory `opencv.pc‘、fatal error:“highgui.h“)_无法定位软件包 libgazebo-dev-程序员宅基地
文章浏览阅读1.5w次,点赞49次,收藏169次。前言好激动,断断续续装了两三天才装上,踩了好多坑。这里把成功安装的步骤详细写下来,如果有小伙伴需要,可以尝试一下,但我不能保证你也可以装好。首先说一下我的各个版本(不谈版本的安装教程都是耍流氓!)是用虚拟机软件:VirtualBOX6.1.30系统版本:ubuntu-20.04.3-desktop-amd64(最小安装模式,中文)OpenCV版本:4.5.5安装时间:2022.2.11下面是步骤1、进入OpenCV的官方下载地址Releases - OpenCV,下载So_无法定位软件包 libgazebo-dev
红帽子粉帽子绿帽子II(递归,递推)-程序员宅基地
文章浏览阅读320次,点赞6次,收藏10次。/是上一个的进化版,相邻的可以一样但是不能都是绿色,注意条件;~~~//仅当笔者个人备忘录使用。
解决Install Intel x86 Emulator Accelerator (HAXM installer) (revision: 7.6.5)“ failed问题-程序员宅基地
文章浏览阅读6.7k次。由于Install Intel x86 Emulator Accelerator (HAXM installer) (revision: 7.6.5)安装失败,导致我的安卓虚拟机无法启动。解决办法有一下几种:1.开机进入BIOS打开Virtual虚拟化功能,然后进入Androidstudio 的SDK manager里面安装HAXM2.关闭系统中的Hyper-v,进入控制面板的程序和功能,将Hyper-v去选即可。3.如果前面的方法都不行,那么建议你重新下载AndroidStudio最新版进行安装_intel x86 emulator
PowerBuilder的语言基础-程序员宅基地
文章浏览阅读1.1w次,点赞2次,收藏15次。 每一种语言都有一组基本的语法约定,POWERBUILDER也不例外。 (1)断行、续行与多条语句 通常情况下,powerbuilder的一条语句是写到一行上的,该条语句在书写完毕之后,按键转到下一行,开始写下一句的内容。也就是说,在PowerBuilder中,使用键作为一行的结束。在PowerBuilder语句比较长的情况下,为了方便阅读,可以使用续行符号把一条语句写到几_powerbuilder