大数据:聚类算法深度解析-程序员宅基地
文章目录
深度解析大数据聚类分析
大数据聚类分析是数据科学领域中的关键技术之一,它能够帮助我们从庞大而复杂的数据集中提取有意义的信息和模式。在这篇博文中,我们将深入探讨大数据聚类分析的概念、方法、应用和挑战。
1. 聚类分析的基本概念
1.1 什么是聚类分析?
聚类分析是一种将数据分成具有相似特征的组的技术。其目标是使组内的数据点相似度最大化,而组间的相似度最小化。这有助于发现数据中的隐藏结构和模式,为进一步的分析和决策提供基础。
在聚类分析中,我们将数据点划分为不同的簇,使得同一簇内的数据点相互之间更为相似。这种相似性是通过一定的距离度量来定义的,常见的包括欧氏距离、曼哈顿距离等。而组间的相似度最小化,则意味着不同簇之间的差异性较大。
聚类的过程类似于将一堆未标记的数据分成若干组,使得同一组内的数据点更加相似,例如下面分类结果。
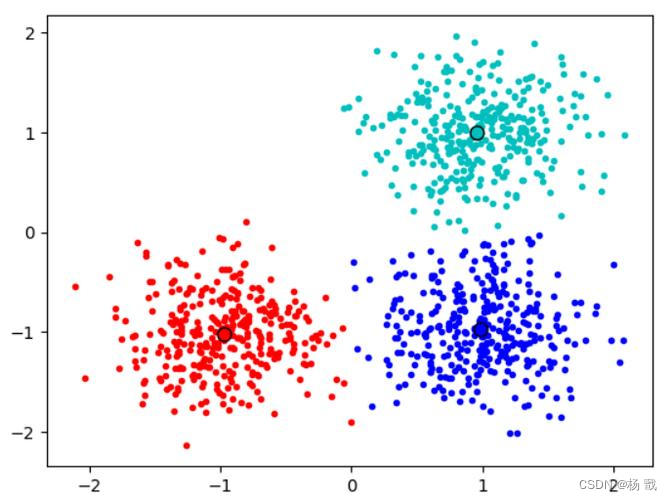
这有助于我们在没有先验标签的情况下发现数据中的潜在结构,为后续的分析和应用提供了基础。
# 伪代码:K均值算法实现聚类分析
from sklearn.cluster import KMeans
import numpy as np
# 假设有一组数据 points,其中每一行代表一个数据点的特征
points = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]])
# 假设我们要将数据分成两个簇
kmeans = KMeans(n_clusters=2)
kmeans.fit(points)
# 获取每个数据点所属的簇
labels = kmeans.labels_
# 输出结果
print("数据点所属簇:", labels)
在上述代码中,我们使用了K均值算法对一组数据进行聚类分析。该算法将数据点划分为两个簇,输出每个数据点所属的簇。这就是聚类分析的基本原理之一。
聚类分析的应用非常广泛,从市场细分到图像分割,都离不开聚类的帮助。通过深入理解聚类分析的概念和方法,我们能够更好地应用它来解决实际问题。
1.2 大数据背景下的挑战
在大数据背景下,数据量巨大、多样性高、实时性要求等因素给聚类分析带来了巨大的挑战。传统的聚类算法可能无法有效处理这些庞大的数据集,因此需要采用分布式计算和更高效的算法来应对这些挑战。
1.2.1 数据量巨大
大数据的特点之一是其庞大的数据量,传统的单机计算无法处理如此大规模的数据。对于聚类分析而言,这就要求我们使用分布式计算框架,如Apache Spark,以同时处理并行计算,提高处理效率。

1.2.2 多样性高
大数据往往涉及多种类型的数据,包括结构化数据、半结构化数据和非结构化数据。传统聚类算法可能只适用于特定类型的数据,因此需要采用更灵活的算法或者组合多种算法来处理这种多样性。
1.2.3 实时性要求
在大数据背景下,很多应用场景要求对数据进行实时的聚类分析。例如,在在线广告投放中,需要实时了解用户的兴趣以提供更精准的广告。因此,聚类算法不仅需要高效处理大规模数据,还需要具备实时性能。
为了解决这些挑战,大数据聚类分析引入了诸如流式计算、近似算法和增量式计算等技术。下面是一个简单的流式聚类的示例:
# 伪代码:流式聚类示例
from sklearn.cluster import MiniBatchKMeans
import numpy as np
# 初始化MiniBatchKMeans模型
mbk = MiniBatchKMeans(n_clusters=3, random_state=42)
# 模拟流式数据输入
streaming_data = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]])
# 逐步更新聚类模型
for i in range(len(streaming_data)):
mbk.partial_fit([streaming_data[i]])
# 获取聚类结果
labels = mbk.labels_
print("数据点所属簇:", labels)
在上述示例中,我们使用了MiniBatchKMeans模型来模拟流式数据输入,并逐步更新聚类模型。这种方式使得算法能够在数据流不断到来的情况下进行实时聚类。
通过克服大数据背景下的这些挑战,我们可以更好地应用聚类分析在复杂和庞大的数据集中发现有价值的模式和信息。
2. 大数据聚类算法
2.1 K均值算法
K均值是最常用的聚类算法之一,它通过将数据点分配到K个簇,使得簇内的数据点尽量相似。该算法迭代进行簇分配和簇中心更新,直至收敛。在大数据背景下,可以使用分布式计算框架如Apache Spark来加速计算过程。
K均值算法步骤:
- 初始化: 随机选择K个数据点作为初始簇中心。
- 分配: 将每个数据点分配到距离最近的簇中心。
- 更新: 重新计算每个簇的中心,即取簇中所有数据点的平均值。
- 重复: 重复步骤2和步骤3,直至簇中心不再发生明显变化或达到预定迭代次数。
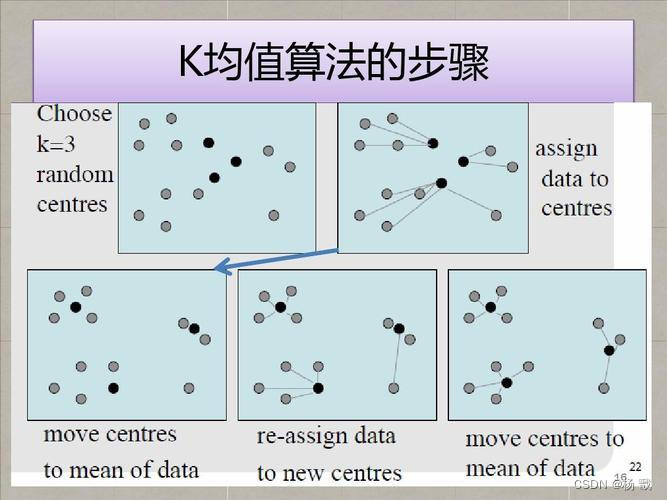
K均值算法的优点之一是其简单性和易于理解。然而,在大数据背景下,传统的K均值算法可能面临计算效率低下的问题。因此,我们可以借助分布式计算框架来提高其处理大规模数据的能力。
# 伪代码:K均值算法在Apache Spark中的实现
from pyspark.ml.clustering import KMeans
# 假设data是一个大数据集的DataFrame
kme智能推荐
874计算机科学基础综合,2018年四川大学874计算机科学专业基础综合之计算机操作系统考研仿真模拟五套题...-程序员宅基地
文章浏览阅读1.1k次。一、选择题1. 串行接口是指( )。A. 接口与系统总线之间串行传送,接口与I/0设备之间串行传送B. 接口与系统总线之间串行传送,接口与1/0设备之间并行传送C. 接口与系统总线之间并行传送,接口与I/0设备之间串行传送D. 接口与系统总线之间并行传送,接口与I/0设备之间并行传送【答案】C2. 最容易造成很多小碎片的可变分区分配算法是( )。A. 首次适应算法B. 最佳适应算法..._874 计算机科学专业基础综合题型
XShell连接失败:Could not connect to '192.168.191.128' (port 22): Connection failed._could not connect to '192.168.17.128' (port 22): c-程序员宅基地
文章浏览阅读9.7k次,点赞5次,收藏15次。连接xshell失败,报错如下图,怎么解决呢。1、通过ps -e|grep ssh命令判断是否安装ssh服务2、如果只有客户端安装了,服务器没有安装,则需要安装ssh服务器,命令:apt-get install openssh-server3、安装成功之后,启动ssh服务,命令:/etc/init.d/ssh start4、通过ps -e|grep ssh命令再次判断是否正确启动..._could not connect to '192.168.17.128' (port 22): connection failed.
杰理之KeyPage【篇】_杰理 空白芯片 烧入key文件-程序员宅基地
文章浏览阅读209次。00000000_杰理 空白芯片 烧入key文件
一文读懂ChatGPT,满足你对chatGPT的好奇心_引发对chatgpt兴趣的表述-程序员宅基地
文章浏览阅读475次。2023年初,“ChatGPT”一词在社交媒体上引起了热议,人们纷纷探讨它的本质和对社会的影响。就连央视新闻也对此进行了报道。作为新传专业的前沿人士,我们当然不能忽视这一热点。本文将全面解析ChatGPT,打开“技术黑箱”,探讨它对新闻与传播领域的影响。_引发对chatgpt兴趣的表述
中文字符频率统计python_用Python数据分析方法进行汉字声调频率统计分析-程序员宅基地
文章浏览阅读259次。用Python数据分析方法进行汉字声调频率统计分析木合塔尔·沙地克;布合力齐姑丽·瓦斯力【期刊名称】《电脑知识与技术》【年(卷),期】2017(013)035【摘要】该文首先用Python程序,自动获取基本汉字字符集中的所有汉字,然后用汉字拼音转换工具pypinyin把所有汉字转换成拼音,最后根据所有汉字的拼音声调,统计并可视化拼音声调的占比.【总页数】2页(13-14)【关键词】数据分析;数据可..._汉字声调频率统计
linux输出信息调试信息重定向-程序员宅基地
文章浏览阅读64次。最近在做一个android系统移植的项目,所使用的开发板com1是调试串口,就是说会有uboot和kernel的调试信息打印在com1上(ttySAC0)。因为后期要使用ttySAC0作为上层应用通信串口,所以要把所有的调试信息都给去掉。参考网上的几篇文章,自己做了如下修改,终于把调试信息重定向到ttySAC1上了,在这做下记录。参考文章有:http://blog.csdn.net/longt..._嵌入式rootfs 输出重定向到/dev/console
随便推点
uniapp 引入iconfont图标库彩色symbol教程_uniapp symbol图标-程序员宅基地
文章浏览阅读1.2k次,点赞4次,收藏12次。1,先去iconfont登录,然后选择图标加入购物车 2,点击又上角车车添加进入项目我的项目中就会出现选择的图标 3,点击下载至本地,然后解压文件夹,然后切换到uniapp打开终端运行注:要保证自己电脑有安装node(没有安装node可以去官网下载Node.js 中文网)npm i -g iconfont-tools(mac用户失败的话在前面加个sudo,password就是自己的开机密码吧)4,终端切换到上面解压的文件夹里面,运行iconfont-tools 这些可以默认也可以自己命名(我是自己命名的_uniapp symbol图标
C、C++ 对于char*和char[]的理解_c++ char*-程序员宅基地
文章浏览阅读1.2w次,点赞25次,收藏192次。char*和char[]都是指针,指向第一个字符所在的地址,但char*是常量的指针,char[]是指针的常量_c++ char*
Sublime Text2 使用教程-程序员宅基地
文章浏览阅读930次。代码编辑器或者文本编辑器,对于程序员来说,就像剑与战士一样,谁都想拥有一把可以随心驾驭且锋利无比的宝剑,而每一位程序员,同样会去追求最适合自己的强大、灵活的编辑器,相信你和我一样,都不会例外。我用过的编辑器不少,真不少~ 但却没有哪款让我特别心仪的,直到我遇到了 Sublime Text 2 !如果说“神器”是我能给予一款软件最高的评价,那么我很乐意为它封上这么一个称号。它小巧绿色且速度非
对10个整数进行按照从小到大的顺序排序用选择法和冒泡排序_对十个数进行大小排序java-程序员宅基地
文章浏览阅读4.1k次。一、选择法这是每一个数出来跟后面所有的进行比较。2.冒泡排序法,是两个相邻的进行对比。_对十个数进行大小排序java
物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)_网络调试助手连接阿里云连不上-程序员宅基地
文章浏览阅读2.9k次。物联网开发笔记——使用网络调试助手连接阿里云物联网平台(基于MQTT协议)其实作者本意是使用4G模块来实现与阿里云物联网平台的连接过程,但是由于自己用的4G模块自身的限制,使得阿里云连接总是无法建立,已经联系客服返厂检修了,于是我在此使用网络调试助手来演示如何与阿里云物联网平台建立连接。一.准备工作1.MQTT协议说明文档(3.1.1版本)2.网络调试助手(可使用域名与服务器建立连接)PS:与阿里云建立连解释,最好使用域名来完成连接过程,而不是使用IP号。这里我跟阿里云的售后工程师咨询过,表示对应_网络调试助手连接阿里云连不上
<<<零基础C++速成>>>_无c语言基础c++期末速成-程序员宅基地
文章浏览阅读544次,点赞5次,收藏6次。运算符与表达式任何高级程序设计语言中,表达式都是最基本的组成部分,可以说C++中的大部分语句都是由表达式构成的。_无c语言基础c++期末速成