Flask-SQLAlchemy_flask_sqlalchemy-程序员宅基地
认识Flask-SQLAlchemy
- Flask-SQLAlchemy 是一个为 Flask 应用增加 SQLAlchemy 支持的扩展。它致力于简化在 Flask 中 SQLAlchemy 的使用。
- SQLAlchemy 是目前python中最强大的 ORM框架, 功能全面, 使用简单。
ORM优缺点
优点
- 有语法提示, 省去自己拼写SQL,保证SQL语法的正确性
- orm提供方言功能(dialect, 可以转换为多种数据库的语法), 减少学习成本
- 防止sql注入攻击
- 搭配数据迁移, 更新数据库方便
- 面向对象, 可读性强, 开发效率高
缺点
- 需要语法转换, 效率比原生sql低
- 复杂的查询往往语法比较复杂 (可以使用原生sql替换)
环境安装
pip install flask-sqlalchemy
- flask-sqlalchemy 在安装/使用过程中, 如果出现 ModuleNotFoundError: No module named 'MySQLdb’错误, 则表示缺少mysql依赖包, 可依次尝试下列两个方案后重试:
方案1: 安装 mysqlclient依赖包 (如果失败再尝试方案2)
pip install mysqlclient
方案2: 安装pymysql依赖包
pip install pymysql
mysqlclient 和 pymysql 都是用于mysql访问的依赖包, 前者由C语言实现的, 而后者由python实现, 前者的执行效率比后者更高, 但前者在windows系统中兼容性较差, 工作中建议优先前者。
组件初始化
基本配置
flask-sqlalchemy 的相关配置也封装到了 flask 的配置项中, 可以通过app.config属性 或 配置加载方案 (如config.from_object) 进行设置
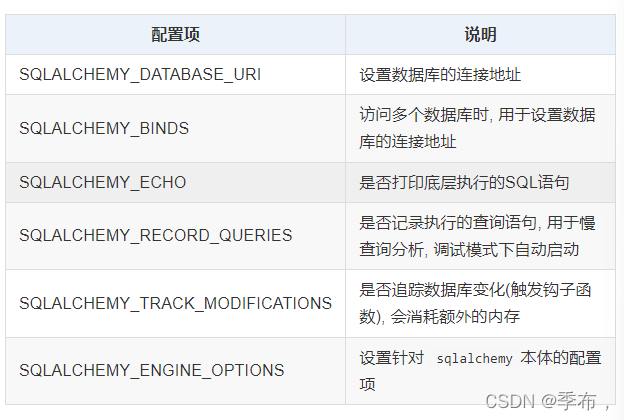
- 数据库URI(连接地址)格式: 协议名://用户名:密码@数据库IP:端口号/数据库名, 如:
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
注意点
- 如果数据库驱动使用的是 pymysql, 则协议名需要修改为
mysql+pymysql://xxxxxxx
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 设置数据库连接地址
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
# 是否追踪数据库修改(开启后会触发一些钩子函数) 一般不开启, 会影响性能
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
# 是否显示底层执行的SQL语句
app.config['SQLALCHEMY_ECHO'] = True
两种初始化方式
.方式1
flask-sqlalchemy 支持两种组件初始化方式:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 应用配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 方式1: 初始化组件对象, 直接关联Flask应用
db = SQLAlchemy(app)
方式2: 先创建组件, 延后关联Flass应用
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 方式2: 初始化组件对象, 延后关联Flask应用
db = SQLAlchemy()
def create_app(config_type):
"""工厂函数"""
# 创建应用
flask_app = Flask(__name__)
# 加载配置
config_class = config_dict[config_type]
flask_app.config.from_object(config_class)
# 关联flask应用
db.init_app(app)
return flask_app
构建模型类
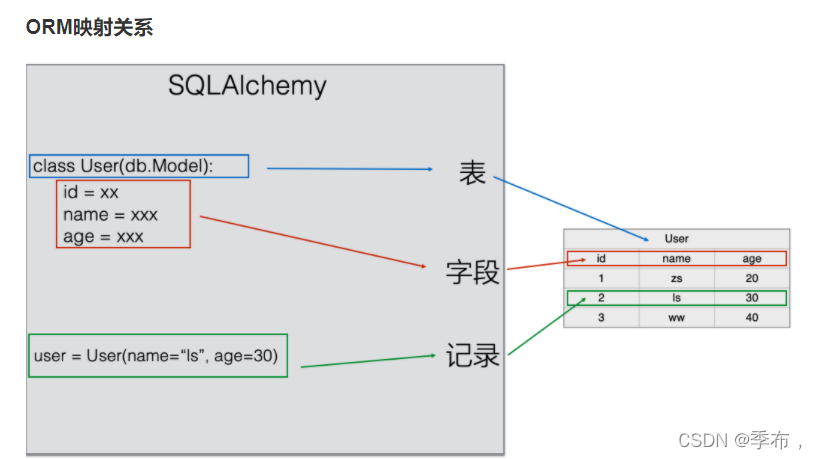
flask-sqlalchemy 的关系映射和 Django-orm 类似
- 类 对应 表
- 类属性 对应 字段
- 实例对象 对应 记录
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类 类->表 类属性->字段 实例对象->记录
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
if __name__ == '__main__':
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
app.run(debug=True)
注意点
- 模型类必须继承 db.Model, 其中 db 指对应的组件对象
- 表名默认为类名小写, 可以通过 __tablename__类属性 进行修改
- 类属性对应字段, 必须是通过 db.Column() 创建的对象
- 可以通过 create_all() 和 drop_all()方法 来创建和删除所有模型类对应的表
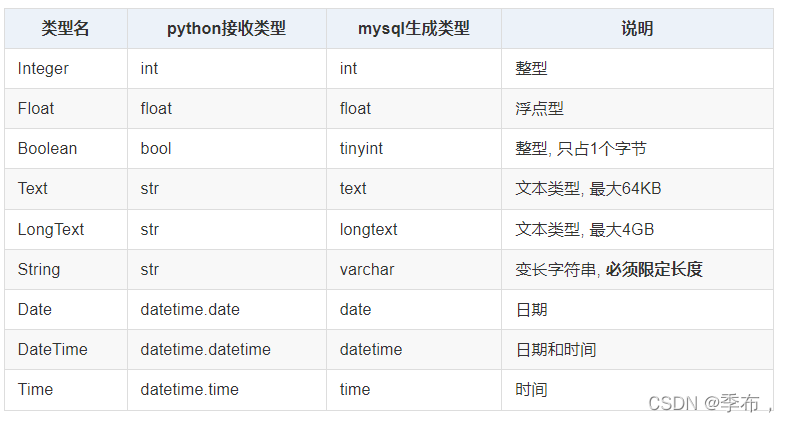
常用的字段类型
常用的字段选项
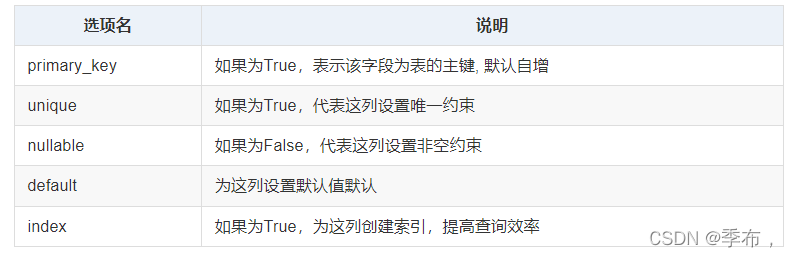
注意点: 如果没有给对应字段的类属性设置default参数, 且添加数据时也没有给该字段赋值, 则sqlalchemy会给该字段设置默认值 None
数据操作
增加数据
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column('username', db.String(20), unique=True)
age = db.Column(db.Integer, index=True)
@app.route('/')
def index():
"""增加数据"""
# 1.创建模型对象
user1 = User(name='zs', age=20)
# user1.name = 'zs'
# user1.age = 20
# 2.将模型对象添加到会话中
db.session.add(user1)
# 添加多条记录
# db.session.add_all([user1, user2, user3])
# 3.提交会话 (会提交事务)
# sqlalchemy会自动创建隐式事务
# 事务失败会自动回滚
db.session.commit()
return "index"
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
注意点:
- 这里的 会话 并不是 状态保持机制中的 session,而是 sqlalchemy 的会话。它被设计为 数据操作的执行者, 从SQL角度则可以理解为是一个 加强版的数据库事务
- sqlalchemy 会 自动创建事务, 并将数据操作包含在事务中, 提交会话时就会提交事务
- 事务提交失败会自动回滚
查询数据
# hm_03_数据查询.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:[email protected]:3306/test31"
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
app.config["SQLALCHEMY_ECHO"] = False
db = SQLAlchemy(app)
# 自定义类 继承db.Model 对应 表
class User(db.Model):
__tablename__ = "users" # 表名 默认使用类名的小写
# 定义类属性 记录字段
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64))
email = db.Column(db.String(64))
age = db.Column(db.Integer)
def __repr__(self): # 自定义 交互模式 & print() 的对象打印
return "(%s, %s, %s, %s)" % (self.id, self.name, self.email, self.age)
@app.route('/')
def index():
"""
查询所有用户数据
查询有多少个用户
查询第1个用户
查询id为4的用户[3种方式]
查询名字结尾字符为g的所有用户[开始 / 包含]
查询名字和邮箱都以li开头的所有用户[2种方式]
查询age是25 或者 `email`以`itheima.com`结尾的所有用户
查询名字不等于wang的所有用户[2种方式]
查询id为[1, 3, 5, 7, 9]的用户
所有用户先按年龄从小到大, 再按id从大到小排序, 取前5个
查询年龄从小到大第2-5位的数据
分页查询, 每页3个, 查询第2页的数据
查询每个年龄的人数 select age, count(name) from t_user group by age 分组聚合
只查询所有人的姓名和邮箱 优化查询 默认使用select *
"""
return 'index'
if __name__ == '__main__':
# 删除所有表
db.drop_all()
# 创建所有表
db.create_all()
# 添加测试数据
user1 = User(name='wang', email='[email protected]', age=20)
user2 = User(name='zhang', email='[email protected]', age=33)
user3 = User(name='chen', email='[email protected]', age=23)
user4 = User(name='zhou', email='[email protected]', age=29)
user5 = User(name='tang', email='[email protected]', age=25)
user6 = User(name='wu', email='[email protected]', age=25)
user7 = User(name='qian', email='[email protected]', age=23)
user8 = User(name='liu', email='[email protected]', age=30)
user9 = User(name='li', email='[email protected]', age=28)
user10 = User(name='sun', email='[email protected]', age=26)
# 一次添加多条数据
db.session.add_all([user1, user2, user3, user4, user5, user6, user7, user8, user9, user10])
db.session.commit()
app.run(debug=True)
# 查询所有用户数据
User.query.all() 返回列表, 元素为模型对象
# 查询有多少个用户
User.query.count()
# 查询第1个用户
User.query.first() 返回模型对象/None
# 查询id为4的用户[3种方式]
# 方式1: 根据id查询 返回模型对象/None
User.query.get(4)
# 方式2: 等值过滤器 关键字实参设置字段值 返回BaseQuery对象
# BaseQuery对象可以续接其他过滤器/执行器 如 all/count/first等
User.query.filter_by(id=4).all()
# 方式3: 复杂过滤器 参数为比较运算/函数引用等 返回BaseQuery对象
User.query.filter(User.id == 4).first()
# 查询名字结尾字符为g的所有用户[开始 / 包含]
User.query.filter(User.name.endswith("g")).all()
User.query.filter(User.name.startswith("w")).all()
User.query.filter(User.name.contains("n")).all()
User.query.filter(User.name.like("w%n%g")).all() # 模糊查询
# 查询名字和邮箱都以li开头的所有用户[2种方式]
User.query.filter(User.name.startswith('li'), User.email.startswith('li')).all()
from sqlalchemy import and_
User.query.filter(and_(User.name.startswith('li'), User.email.startswith('li'))).all()
# 查询age是25 或者 `email`以`itheima.com`结尾的所有用户
from sqlalchemy import or_
User.query.filter(or_(User.age==25, User.email.endswith("itheima.com"))).all()
# 查询名字不等于wang的所有用户[2种方式]
from sqlalchemy import not_
User.query.filter(not_(User.name == 'wang')).all()
User.query.filter(User.name != 'wang').all()
# 查询id为[1, 3, 5, 7, 9]的用户
User.query.filter(User.id.in_([1, 3, 5, 7, 9])).all()
# 所有用户先按年龄从小到大, 再按id从大到小排序, 取前5个
User.query.order_by(User.age, User.id.desc()).limit(5).all()
# 查询年龄从小到大第2-5位的数据 2 3 4 5
User.query.order_by(User.age).offset(1).limit(4).all()
# 分页查询, 每页3个, 查询第2页的数据 paginate(页码, 每页条数)
pn = User.query.paginate(2, 3)
pn.pages 总页数 pn.page 当前页码 pn.items 当前页的数据 pn.total 总条数
# 查询每个年龄的人数 select age, count(name) from t_user group by age 分组聚合
from sqlalchemy import func
data = db.session.query(User.age, func.count(User.id).label("count")).group_by(User.age).all()
for item in data:
# print(item[0], item[1])
print(item.age, item.count) # 建议通过label()方法给字段起别名, 以属性方式获取数据
# 只查询所有人的姓名和邮箱 优化查询 User.query.all() # 相当于select *
from sqlalchemy.orm import load_only
data = User.query.options(load_only(User.name, User.email)).all() # flask-sqlalchem的语法
for item in data:
print(item.name, item.email)
data = db.session.query(User.name, User.email).all() # sqlalchemy本体的语法
for item in data:
print(item.name, item.email)
更新数据
flask-sqlalchemy 提供了两种更新数据的方案
- 先查询, 再更新
对应SQL中的 先select, 再update - 基于过滤条件的更新 (推荐方案)
对应SQL中的 update xx where xx = xx (也称为 update子查询 )
先查询, 再更新
这种方式的缺点
- 查询和更新分两条语句, 效率低
- 如果并发更新, 可能出现更新丢失问题(Lost Update)
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类 商品表
class Goods(db.Model):
__tablename__ = 't_good' # 设置表名
id = db.Column(db.Integer, primary_key=True) # 设置主键
name = db.Column(db.String(20), unique=True) # 商品名称
count = db.Column(db.Integer) # 剩余数量
@app.route('/')
def purchase():
"""购买商品"""
# 更新方式1: 先查询后更新
# 缺点: 并发情况下, 容易出现更新丢失问题 (Lost Update)
# 1.执行查询语句, 获取目标模型对象
goods = Goods.query.filter(Goods.name == '方便面').first()
# 2.对模型对象的属性进行赋值 (更新数据)
goods.count = goods.count - 1
# 3.提交会话
db.session.commit()
return "index"
if __name__ == '__main__':
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
# 添加一条测试数据
goods = Goods(name='方便面', count=1)
db.session.add(goods)
db.session.commit()
app.run(debug=True)
基于过滤条件的更新
这种方式的优点:
- 一条语句, 被网络IO影响程度低, 执行效率更高
- 查询和更新在一条语句中完成, 单条SQL具有原子性, 不会出现更新丢失问题
- 会对满足过滤条件的所有记录进行更新, 可以实现批量更新处理
操作步骤如下:
- 配合 查询过滤器filter() 和 更新执行器update() 进行数据更新
- 提交会话
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类 商品表
class Goods(db.Model):
__tablename__ = 't_good'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
count = db.Column(db.Integer)
@app.route('/')
def purchase():
"""购买商品"""
# 更新方式2: update子查询 可以避免更新丢失问题
# update t_good set count = count - 1 where name = '方便面';
Goods.query.filter(Goods.name == '方便面').update({
'count': Goods.count - 1})
# 提交会话
db.session.commit()
return "index"
if __name__ == '__main__':
# 重置数据库数据
db.drop_all()
db.create_all()
# 添加一条测试数据
goods = Goods(name='方便面', count=1)
db.session.add(goods)
db.session.commit()
app.run(debug=True)
删除数据
类似更新数据, 也存在两种删除数据的方案
先查询, 再删除
- 对应SQL中的 先select, 再delete
基于过滤条件的删除 (推荐方案)
- 对应SQL中的 delete xx where xx = xx (也称为 delete子查询 )
这种方式的缺点:
- 查询和删除分两条语句, 效率低
@app.route('/del')
def delete():
"""删除数据"""
# 方式1: 先查后删除
goods = Goods.query.filter(Goods.name == '方便面').first()
# 删除数据
db.session.delete(goods)
# 提交会话 增删改都要提交会话
db.session.commit()
return "index"
基于过滤条件的删除
这种方式的优点:
- 一条语句, 被网络IO影响程度低, 执行效率更高
- 会对满足过滤条件的所有记录进行删除, 可以实现批量删除处理
操作步骤如下:
- 配合 查询过滤器filter() 和 删除执行器delete() 进行数据删除
- 提交会话
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类 商品表
class Goods(db.Model):
__tablename__ = 't_good'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
count = db.Column(db.Integer)
@app.route('/del')
def delete():
"""删除数据"""
# 方式2: delete子查询
Goods.query.filter(Goods.name == '方便面').delete()
# 提交会话
db.session.commit()
return "index"
if __name__ == '__main__':
# 重置数据库数据
db.drop_all()
db.create_all()
# 添加一条测试数据
goods = Goods(name='方便面', count=1)
db.session.add(goods)
db.session.commit()
app.run(debug=True)
- 增删改操作都需要提交会话, 对应事务中进行数据库变化后提交事务
刷新数据
- Session 被设计为数据操作的执行者, 会先将操作产生的数据保存到内存中
- 在执行 flush刷新操作 后, 数据操作才会同步到数据库中
- 有两种情况下会 隐式执行刷新操作
提交会话
执行查询操作 (包括 update 和 delete 子查询)
开发者也可以 手动执行刷新操作 session.flush()
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
# 构建模型类
class Goods(db.Model):
__tablename__ = 't_good'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
count = db.Column(db.Integer)
@app.route('/')
def purchase():
goods = Goods(name='方便面', count=20)
db.session.add(goods)
# 主动执行flush操作, 立即执行SQL操作(数据库同步)
db.session.flush()
# Goods.query.count() # 查询操作会自动执行flush操作
db.session.commit() # 提交会话会自动执行flush操作
return "index"
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
多表查询

案例中包含两个模型类: User用户模型 和 Address地址模型, 并且一个用户可以有多个地址, 两张表之间存在一对多关系
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = False
# 创建组件对象
db = SQLAlchemy(app)
# 用户表 主表(一) 一个用户可以有多个地址
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20))
# 地址表 从表(多)
class Address(db.Model):
__tablename__ = 't_adr'
id = db.Column(db.Integer, primary_key=True)
detail = db.Column(db.String(20))
user_id = db.Column(db.Integer) # 定义外键
@app.route('/')
def index():
"""添加并关联数据"""
user1 = User(name='张三')
db.session.add(user1)
db.session.flush() # 需要手动执行flush操作, 让主表生成主键, 否则外键关联失败
# db.session.commit() # 有些场景下, 为了保证数据操作的原子性不能分成多个事务进行操作
adr1 = Address(detail='中关村3号', user_id=user1.id)
adr2 = Address(detail='华强北5号', user_id=user1.id)
db.session.add_all([adr1, adr2])
db.session.commit()
return "index"
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
关联查询
关联查询步骤: (以主查从为例)
- 先查询主表数据
- 再通过外键字段查询 关联的从表数据
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = False
# 创建组件对象
db = SQLAlchemy(app)
# 用户表 一 一个用户可以有多个地址
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20))
# 地址表 多
class Address(db.Model):
__tablename__ = 't_adr'
id = db.Column(db.Integer, primary_key=True)
detail = db.Column(db.String(20))
user_id = db.Column(db.Integer) # 定义外键
@app.route('/demo')
def demo():
"""查询多表数据 需求: 查询姓名为"张三"的所有地址信息"""
# 1.先根据姓名查找到主表主键
user1 = User.query.filter_by(name='张三').first()
# 2.再根据主键到从表查询关联地址
adrs = Address.query.filter_by(user_id=user1.id).all()
for adr in adrs:
print(adr.detail)
return "demo"
@app.route('/')
def index():
"""添加并关联数据"""
user1 = User(name='张三')
db.session.add(user1)
db.session.flush()
adr1 = Address(detail='中关村3号', user_id=user1.id)
adr2 = Address(detail='华强北5号', user_id=user1.id)
db.session.add_all([adr1, adr2])
db.session.commit()
return "index"
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
关系属性
关系属性是 sqlalchemy 封装的一套查询关联数据的语法, 其目的为 让开发者使用 面向对象的形式 方便快捷的获取关联数据
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = False
# 创建组件对象
db = SQLAlchemy(app)
# 用户表 一 一个用户可以有多个地址
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20))
addresses = db.relationship('Address') # 1.定义关系属性 relationship("关联数据所在的模型类")
# 地址表 多
class Address(db.Model):
__tablename__ = 't_adr'
id = db.Column(db.Integer, primary_key=True)
detail = db.Column(db.String(20))
# 2. 外键字段设置外键参数 db.ForeignKey('主表名.主键')
user_id = db.Column(db.Integer, db.ForeignKey('t_user.id'))
@app.route('/')
def index():
"""添加数据"""
user1 = User(name='张三')
db.session.add(user1)
db.session.flush()
adr1 = Address(detail='中关村3号', user_id=user1.id)
adr2 = Address(detail='华强北5号', user_id=user1.id)
db.session.add_all([adr1, adr2])
db.session.commit()
"""查询多表数据 需求: 查询姓名为"张三"的所有地址信息"""
# 先根据姓名查找用户主键
user1 = User.query.filter_by(name='张三').first()
# 3.使用关系属性获取关系数据
for address in user1.addresses:
print(address.detail)
return "index"
if __name__ == '__main__':
# 重置所有继承自db.Model的表
db.drop_all()
db.create_all()
app.run(debug=True)
连接查询
- 开发中有 联表查询需求 时, 一般会使用 join连接查询
- sqlalchemy 也提供了对应的查询语法
db.session.query(主表模型字段1, 主表模型字段2, 从表模型字段1, xx.. ).join(从表模型类, 主表模型类.主键 == 从表模型类.外键)
- join语句 属于查询过滤器, 返回值也是 BaseQuery 类型对象
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = False
# 创建组件对象
db = SQLAlchemy(app)
# 用户表 一
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20))
# 地址表 多
class Address(db.Model):
__tablename__ = 't_adr'
id = db.Column(db.Integer, primary_key=True)
detail = db.Column(db.String(20))
user_id = db.Column(db.Integer) # 定义外键
@app.route('/demo')
def demo():
"""查询多表数据 需求: 查询姓名为"张三"的用户id和地址信息"""
# sqlalchemy的join查询
data = db.session.query(User.id, Address.detail).join(Address, User.id == Address.user_id).filter(User.name == '张三').all()
for item in data:
print(item.detail, item.id)
return "demo"
@app.route('/')
def index():
"""添加数据"""
user1 = User(name='张三')
db.session.add(user1)
db.session.flush()
adr1 = Address(detail='中关村3号', user_id=user1.id)
adr2 = Address(detail='华强北5号', user_id=user1.id)
db.session.add_all([adr1, adr2, user1])
db.session.commit()
return 'index'
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
关联查询的性能优化
- 通过前边的学习, 可以发现 无论使用 外键 还是 关系属性 查询关联数据, 都需要查询两次, 一次查询用户数据, 一次查询地址数据
- 两次查询就需要发送两次请求给数据库服务器, 如果数据库和web应用不在一台服务器中, 则 网络IO会对查询效率产生一定影响
- 可以考虑使用 连接查询 join 使用一条语句就完成关联数据的查询
# 使用join语句优化关联查询
adrs = Address.query.join(User, Address.user_id == User.id).filter(User.name == '张三').all() # 列表中包含地址模型对象
Session机制
生命周期
flask-sqlalchemy 对于 sqlalchemy本体 的 Session 进行了一定的封装:
Session的生命周期和请求相近
- 请求中的首次数据操作会创建Session
- 整个请求过程中使用的Session为同一个, 并且线程隔离
- 请求结束时会自动销毁Session(释放内存)
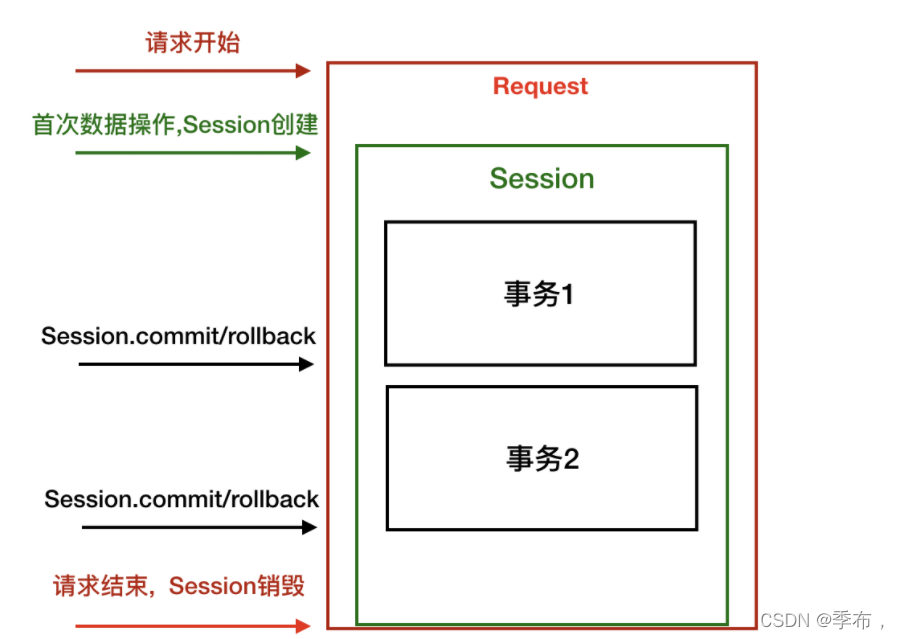
Session和事务
- Session中可以包含多个事务, 提交事务失败后, 会自动执行SQL的回滚操作
- 同一个请求中, 想要在前一个事务失败的情况下创建新的事务, 必须先手动回滚事务 Session.rollback
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/toutiao'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column('username', db.String(20), unique=True)
age = db.Column(db.Integer, default=0, index=True)
@app.route('/')
def index():
"""事务1"""
try:
user1 = User(name='zs', age=20)
db.session.add(user1)
db.session.commit()
except BaseException:
# 手动回滚 同一个session中, 前一个事务如果失败, 必须手动回滚, 否则无法创建新的事务
db.session.rollback()
"""事务2"""
user1 = User(name='lisi', age=30)
db.session.add(user1)
db.session.commit()
return "index"
if __name__ == '__main__':
"""为了进行测试, 首次运行 建表并添加一条测试数据后, 注释下方代码, 并重新运行测试"""
# 重置所有继承自db.Model的表
# db.drop_all()
# db.create_all()
# 添加一条测试数据
# user1 = User(name='zs', age=20)
# db.session.add(user1)
# db.session.commit()
app.run(debug=True)
数据迁移
- flask-migrate组件 为flask-sqlalchemy提供了数据迁移功能, 以便进行数据库升级, 如增加字段、修改字段类型等
- 安装组件 pip install flask-migrate
# hm_数据迁移.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test32'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
# SQlalchemy组件初始化
db = SQLAlchemy(app)
# 迁移组件初始化
Migrate(app, db)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column('username', db.String(20), unique=True)
# age= db.Column(db.Integer, default=10, index=True)
@app.route('/')
def index():
return "index"
if __name__ == '__main__':
app.run(debug=True)
执行迁移命令
export FLASK_APP=hm_数据迁移.py # 设置环境变量指定启动文件
flask db init # 生成迁移文件夹 只执行一次
flask db migrate # ⽣成迁移版本, 保存到迁移文件夹中
flask db upgrade # 执行迁移
执行迁移命令前需要先设置环境变量指定启动文件
添加age字段
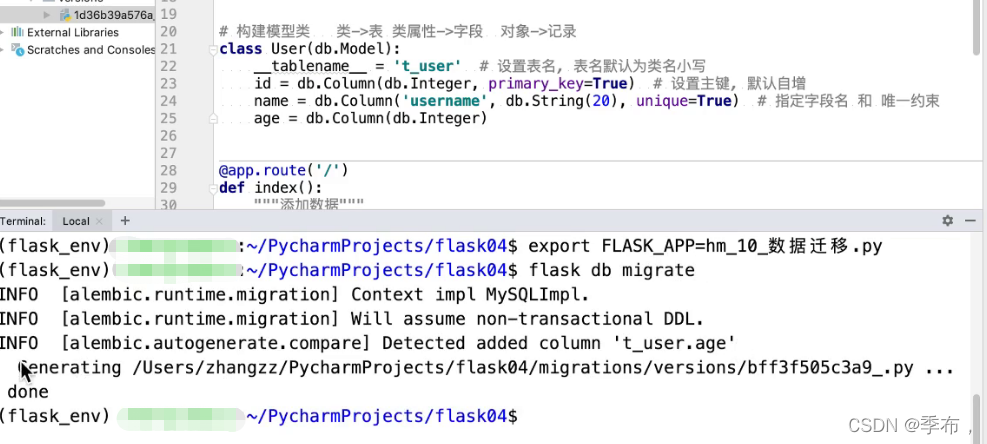
这里连接查询,比如User表连接address表,join后面的条件正常可以写Address,但是也可以写User,需要注意的是如果写User,那么User.id这个条件需要放在等号后面

智能推荐
2022黑龙江最新建筑八大员(材料员)模拟考试试题及答案_料账的试题-程序员宅基地
文章浏览阅读529次。百分百题库提供建筑八大员(材料员)考试试题、建筑八大员(材料员)考试预测题、建筑八大员(材料员)考试真题、建筑八大员(材料员)证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。310项目经理部应编制机械设备使用计划并报()审批。A监理单位B企业C建设单位D租赁单位答案:B311对技术开发、新技术和新工艺应用等情况进行的分析和评价属于()。A人力资源管理考核B材料管理考核C机械设备管理考核D技术管理考核答案:D312建筑垃圾和渣土._料账的试题
chatgpt赋能python:Python自动打开浏览器的技巧-程序员宅基地
文章浏览阅读614次。本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。AI职场汇报智能办公文案写作效率提升教程 专注于AI+职场+办公方向。下图是课程的整体大纲下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具。_python自动打开浏览器
Linux中安装JDK-RPM_linux 安装jdk rpm-程序员宅基地
文章浏览阅读545次。Linux中安装JDK-RPM方式_linux 安装jdk rpm
net高校志愿者管理系统-73371,计算机毕业设计(上万套实战教程,赠送源码)-程序员宅基地
文章浏览阅读25次。免费领取项目源码,请关注赞收藏并私信博主,谢谢-高校志愿者管理系统主要功能模块包括页、个人资料(个人信息。修改密码)、公共管理(轮播图、系统公告)、用户管理(管理员、志愿用户)、信息管理(志愿资讯、资讯分类)、活动分类、志愿活动、报名信息、活动心得、留言反馈,采取面对对象的开发模式进行软件的开发和硬体的架设,能很好的满足实际使用的需求,完善了对应的软体架设以及程序编码的工作,采取SQL Server 作为后台数据的主要存储单元,采用Asp.Net技术进行业务系统的编码及其开发,实现了本系统的全部功能。
小米宣布用鸿蒙了吗,小米OV对于是否采用鸿蒙保持沉默,原因是中国制造需要它们...-程序员宅基地
文章浏览阅读122次。原标题:小米OV对于是否采用鸿蒙保持沉默,原因是中国制造需要它们目前华为已开始对鸿蒙系统大规模宣传,不过中国手机四强中的另外三家小米、OPPO、vivo对于是否采用鸿蒙系统保持沉默,甚至OPPO还因此而闹出了一些风波,对此柏铭科技认为这是因为中国制造当下需要小米OV几家继续将手机出口至海外市场。 2020年中国制造支持中国经济渡过了艰难的一年,这一年中国进出口贸易额保持稳步增长的势头,成为全球唯一..._小米宣布用鸿蒙系统
Kafka Eagle_kafka eagle git-程序员宅基地
文章浏览阅读1.3k次。1.Kafka Eagle实现kafka消息监控的代码细节是什么?2.Kafka owner的组成规则是什么?3.怎样使用SQL进行kafka数据预览?4.Kafka Eagle是否支持多集群监控?1.概述在《Kafka 消息监控 - Kafka Eagle》一文中,简单的介绍了 Kafka Eagle这款监控工具的作用,截图预览,以及使用详情。今天_kafka eagle git
随便推点
Eva.js是什么(互动小游戏开发)-程序员宅基地
文章浏览阅读1.1k次,点赞29次,收藏19次。Eva.js 是一个专注于开发互动游戏项目的前端游戏引擎。:Eva.js 提供开箱即用的游戏组件供开发人员立即使用。是的,它简单而优雅!:Eva.js 由高效的运行时和渲染管道 (Pixi.JS) 提供支持,这使得释放设备的全部潜力成为可能。:得益于 ECS(实体-组件-系统)架构,你可以通过高度可定制的 API 扩展您的需求。唯一的限制是你的想象力!_eva.js
OC学习笔记-Objective-C概述和特点_objective-c特点及应用领域-程序员宅基地
文章浏览阅读1k次。Objective-C概述Objective-C是一种面向对象的计算机语言,1980年代初布莱德.考斯特在其公司Stepstone发明Objective-C,该语言是基于SmallTalk-80。1988年NeXT公司发布了OC,他的开发环境和类库叫NEXTSTEP, 1994年NExt与Sun公司发布了标准的NEXTSTEP系统,取名openStep。1996_objective-c特点及应用领域
STM32学习笔记6:TIM基本介绍_stm32 tim寄存器详解-程序员宅基地
文章浏览阅读955次,点赞20次,收藏16次。TIM(Timer)定时器定时器可以对输入的时钟进行计数,并在计数值达到设定值时触发中断16位计数器、预分频器、自动重装寄存器的时基单元,在 72MHz 计数时钟下可以实现最大 59.65s 的定时,59.65s65536×65536×172MHz59.65s65536×65536×721MHz不仅具备基本的定时中断功能,而且还包含内外时钟源选择、输入捕获、输出比较、编码器接口、主从触发模式等多种功能。_stm32 tim寄存器详解
前端基础语言HTML、CSS 和 JavaScript 学习指南_艾编程学习资料-程序员宅基地
文章浏览阅读1.5k次。对于任何有兴趣学习前端 Web 开发的人来说,了解 HTML、CSS 和JavaScript 之间的区别至关重要。这三种前端语言都是您访问过的每个网站的用户界面构建块。而且,虽然每种语言都有不同的功能重点,但它们都可以共同创建令人兴奋的交互式网站,让用户保持参与。因此,您会发现学习所有三种语言都很重要。如果您有兴趣从事前端开发工作,可以通过多种方式学习这些语言——在艾编程就可以参与到学习当中来。在本文中,我们将回顾每种语言的特征、它们如何协同工作以及您可以在哪里学习它们。HTML vs C._艾编程学习资料
三维重构(10):PCL点云配准_局部点云与全局点云配准-程序员宅基地
文章浏览阅读2.8k次。点云配准主要针对点云的:不完整、旋转错位、平移错位。因此要得到完整点云就需要对局部点云进行配准。为了得到被测物体的完整数据模型,需要确定一个合适的坐标系变换,将从各个视角得到的点集合并到一个统一的坐标系下形成一个完整的数据点云,然后就可以方便地进行可视化,这就是点云数据的配准。点云配准技术通过计算机技术和统计学规律,通过计算机计算两个点云之间的错位,也就是把在不同的坐标系下的得到的点云进行坐标变..._局部点云与全局点云配准
python零基础学习书-Python零基础到进阶必读的书藉:Python学习手册pdf免费下载-程序员宅基地
文章浏览阅读273次。提取码:0oorGoogle和YouTube由于Python的高可适应性、易于维护以及适合于快速开发而采用它。如果你想要编写高质量、高效的并且易于与其他语言和工具集成的代码,《Python学习手册:第4 版》将帮助你使用Python快速实现这一点,不管你是编程新手还是Python初学者。本书是易于掌握和自学的教程,根据作者Python专家Mark Lutz的著名培训课程编写而成。《Python学习..._零基础学pythonpdf电子书