【论文阅读】Speech Driven Video Editing via an Audio-Conditioned Diffusion Model_diffused-heads public-程序员宅基地
技术标签: 论文阅读
DiffusionVideoEditing:基于音频条件扩散模型的语音驱动视频编辑
paper:[2301.04474] Speech Driven Video Editing via an Audio-Conditioned Diffusion Model (arxiv.org)
目录
1 介绍
本文提出一种使用去噪扩散模型进行端到端语音驱动视频编辑的方法。给定一个说话人视频和一个语音,嘴唇和下巴运动被重新同步,而不依赖于中间结构表示,如面部特征点或3D人脸模型。
在CREMA-D视听数据集上提供了基线模型。这是第一项 将端到端去噪扩散模型应用于音频驱动视频编辑任务 的工作。
贡献:
-
一种新颖的非结构化端到端方法,用去噪扩散模型进行音频驱动视频编辑。网络中以语音为条件,并训练它逐帧修改面部,使唇部和下颌运动与条件音频信号同步。
-
分别使用GRID [14]和CREMA-D [6]数据集训练了单个说话人和多个说话人的概念验证模型,在未见过的说话人上进行测试时取得了强有力的验证结果。
• 展示了我们方法在视频编辑任务上的适用性,并通过条件修复策略实现了竞争性的结果,该策略从先前的帧和音频谱嵌入中收集信息,生成当前帧。
2 背景
2.1. 音频驱动的视频生成
音频驱动的视频生成方法,根据是否使用基于音频驱动的面部结构表示来进行分类。
与前者相关的方法,共同之处在于:将中间的结构表示作为输入,传递给单独的神经渲染模型,通常将其作为图像到图像转换任务进行训练,生成逼真图像帧。
另一方面,非结构化/端到端方法利用潜在特征学习和图像重建技术以端到端的方式从输入的语音信号和参考图像/视频生成逼真的视频序列。尽管当前的端到端方法在输出分辨率质量上不及结构化方法,但有很大的改进空间。
2.2 扩散模型
扩散模型也被应用于相关的说话人生成任务,其中[Diffused heads: Diffusion models beat gans on talking-face generation.]是与我们工作同时进行的一种方法。
扩散模型是一类生成概率模型,包括两个步骤:1)前向扩散过程,在一系列时间步中稳定添加随机高斯噪声,直到数据成为标准高斯分布样本。2)反向扩散过程,训练一个去噪模型,在一系列时间步中逐渐去除噪声,来恢复数据的结构。经过训练的模型可以从随机高斯噪声中采样信息,并在一系列时间步骤中逐渐去噪以获得所需的输出。
由于扩散模型是在单一损失下进行训练,且不依赖于鉴别器,它们在训练过程中更加稳定,不会遭受GAN训练中常见的模式崩溃和梯度消失等问题。与GAN相比,扩散模型产生高质量的输出样本并展现了更好的模式覆盖。但是,由于需要在相同样本上多次运行反向扩散过程以完全去噪,扩散模型的采样速度较慢。
3 方法
3.1 扩散过程
扩散模型有两个步骤,一个是数据逐渐被破坏的正向扩散过程,另一个是学习到的重建数据的逆扩散过程,用于训练和推理。对图像和语音特征进行降噪U-Net,将目标帧的被屏蔽部分降噪到所需的输出中。
![]()
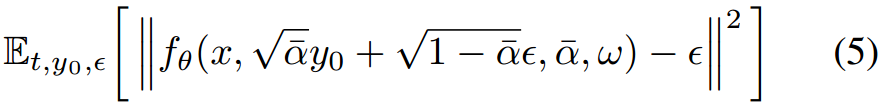

3.2 模型架构
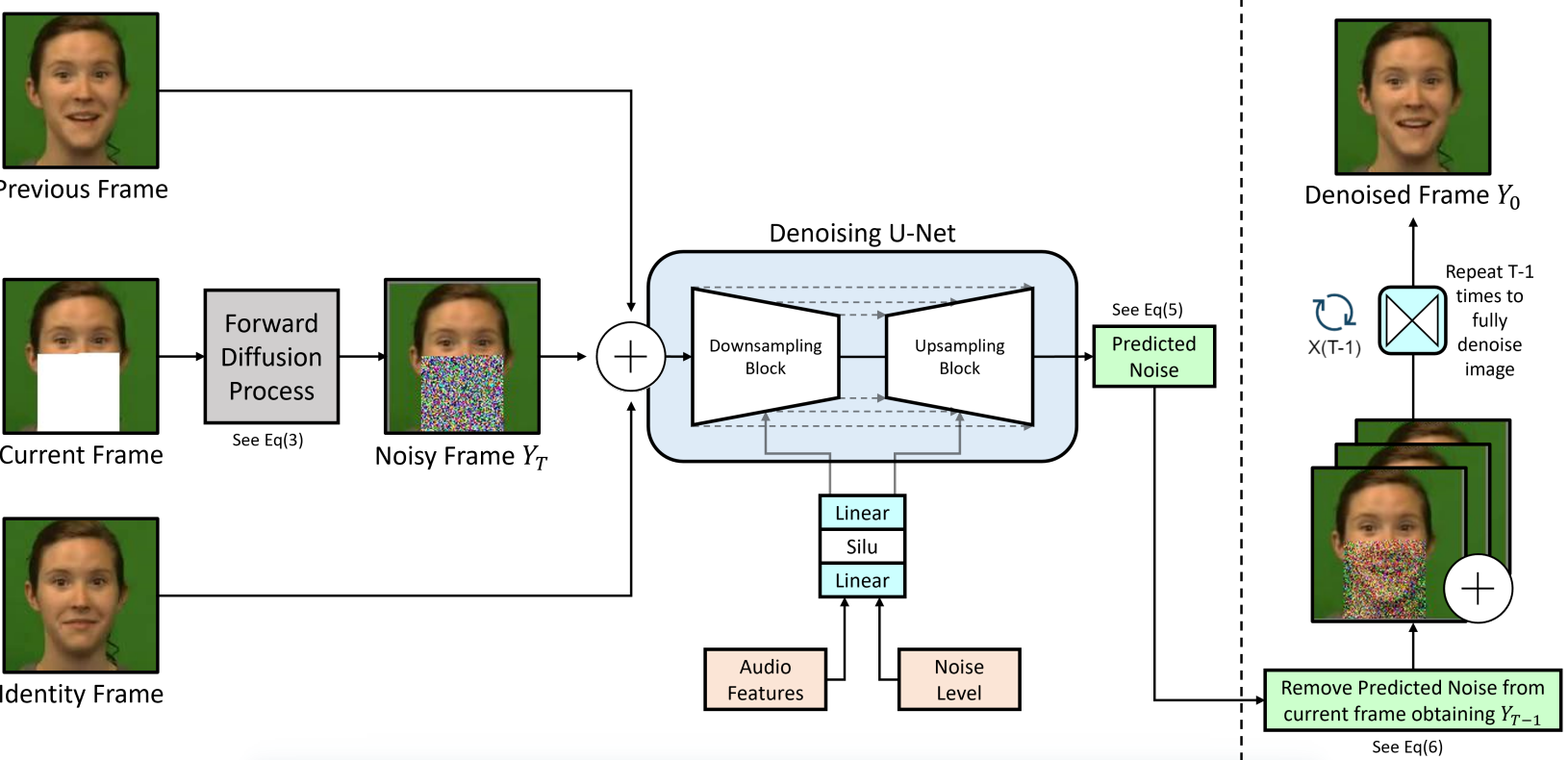
图1. pipeline。虚线左侧表示训练过程,右侧表示推理过程。![]() 表示连接运算符。
表示连接运算符。
训练:当前帧通过前向扩散过程,计算噪声并添加到面部的遮挡区域,得到噪声帧Yt(方程3)。然后,将前一帧和身份帧按通道连接,形成一个大小为128x128x9的特征,传递给U-Net。音频特征和噪声水平信息通过条件残差块输入到U-Net中,如方程7所述。

推理:从噪声图像Yt中移除预测的噪声,得到去噪图像Yt−1。然后,将前一帧和身份帧连接到Yt−1上,重复此过程,直到图像完全去噪(方程6)。

将音频驱动的视频编辑问题构建为有几个关键变化的条件修复任务。视频编辑必须为网络提供上下文信息来指导生成过程。为此,我们将条件步骤分为两个类别:基于帧和基于音频的条件。
基于帧的条件:对于给定帧yi,我们的模型输入三个图像:
- 要修复的当前遮挡噪声帧
 ,
, - 视频序列中的前一帧y(i−1),
- 一个恒定的身份帧y0。
方法是自回归的,逐帧操作。前一帧的作用是确保连续帧之间时间稳定。身份帧的作用是在生成过程中不偏离目标身份,这在自回归模型中经常发生。在训练多个身份的情况下,它对于模型泛化性至关重要。这三个帧按通道连接起来,以[128x128x9]的形式传入U-Net中,如图1左侧所示。
基于音频的条件:对于视频序列(y0,...,yn),存在一个对应的、从原始语音信号提取出的音频频谱特征序列(spec0,...,spec2n)。为了将音频信息提供给网络,从(spec2i−2到spec2i+2)中提取一个音频窗口,跨越120毫秒,表示为zi,并围绕当前视频帧yi居中。这样做是为了在窗口内捕获前后帧的音频信息,以确保对爆炸音("p、t、k、b、d、g")的唇部运动的准确生成,考虑到这些唇部运动在声音产生之前发生。我们使用条件残差块将这些信息引入U-Net,该块根据音频和噪声水平嵌入,调整U-Net的隐藏状态,遵循[Diffused heads: Diffusion models beat gans on talking-face generation]的方法进行缩放和偏移:
![]()
其中hs和hs+1表示U-Net的连续隐藏状态,
![]() ,MLP表示具有一些线性层,由SiLu()激活函数分隔的浅层神经网络,GN是组归一化层。如图1所示。
,MLP表示具有一些线性层,由SiLu()激活函数分隔的浅层神经网络,GN是组归一化层。如图1所示。
U-Net的设置:本文使用[Diffusion models beat gans on image synthesis.]描述的256x256 U-Net架构的轻量级128x128版本,省略了类别条件机制。
与[Palette: Image-to-image diffusion models.]类似,通过将前一帧和身份帧连接到遮挡帧上,来训练模型生成所需的帧。通过在U-Net内的条件残差块中发送音频特征,来驱动面部动画,详细描述见[Diffused heads: Diffusion models beat gans on talking-face generation. ]。表1中列出了与U-Net配置相关的所有细节。
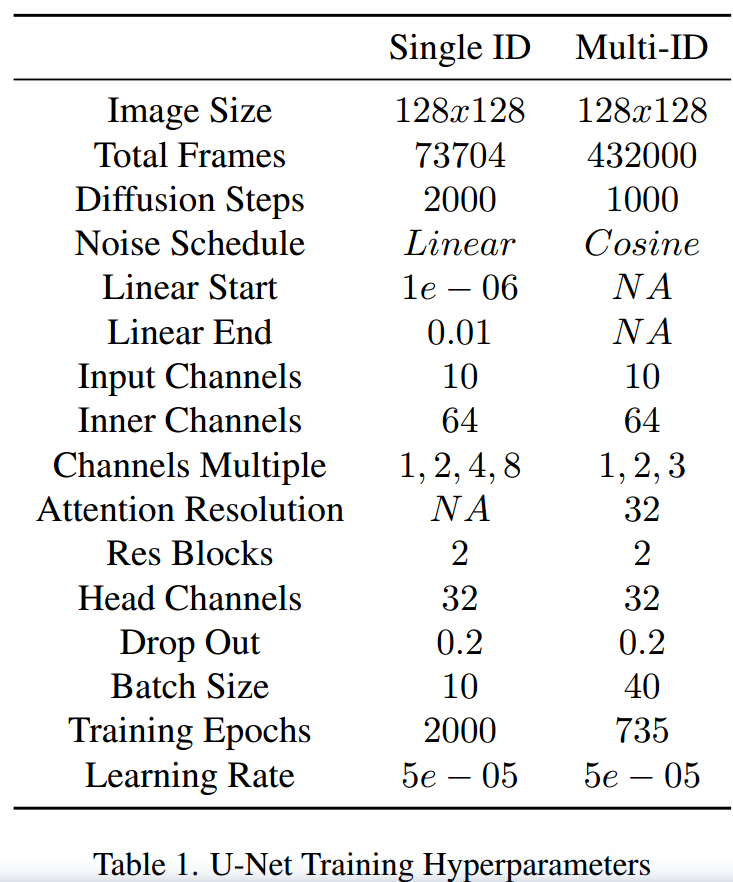
我们训练了两个模型,一个是在GRID数据集的身份S1上训练的单说话人模型,另一个是在CREMA-D数据集的训练集上训练的多说话人模型。区别是是否使用注意力机制。
在实验过程中发现在多说话人模型中使用注意力机制,对其泛化性至关重要。训练使用了4个32GB V100 GPU,每个GPU的批处理大小为40。
3.3 数据处理
3.3.1 数据集
使用了GRID [14]和CREMA-D [6]音频-视觉语音数据集。
3.3.2 音频预处理
从GRID和CREMA-D数据集中的每个视频中提取音频文件,并将其重采样为16KHz。从音频中计算重叠的梅尔频谱特征,使用n-fft 2048、窗长640、跳长320和256个梅尔频带。根据这些值,1秒钟的音频特征具有[50,256]的形状,与视频帧序列对齐。
3.3.3 视频预处理
首先,对每个视频帧进行以面部为中心的128x128像素裁剪。将视频中的面部与规范化的面部对准,并使用7帧的平滑窗口来完成,根据[End-to-end speech-driven facial animation with temporal gans]的方法。原因:去除任何无关的背景,减小图像大小以便于更快的训练和收敛速度。
最初的实验使用了256x256的图像尺寸,但是模型的训练成本太高。可以在我们的解决方案之上应用诸如[Learning trajectory-aware transformer for video superresolution]的视频超分辨率技术,以获得高分辨率的样本。
接下来,对面部的矩形区域遮罩。使用现成的面部特征点提取器[Mediapipe: A framework for building perception pipelines.]提取面部特征点坐标,以确定下颌的位置。根据这些信息,遮罩了面部的矩形区域,覆盖了鼻子下方的区域,如图1所示。这个面部遮罩在训练时,用到数据加载器中的帧上计算。
训练过程中,使用矩形面部遮罩来隐藏说话人的下颌线是至关重要的。这是因为网络很容易捕捉到唇部和下颌运动之间的强相关性,从而完全忽略语音输入。通过隐藏下颌线,迫使模型仅基于伴随的语音学习生成唇部运动。由于扩散过程依赖于单一损失函数,应用矩形面部遮罩是防止 基于帧的输入 主导 语音输入 的最简单方法。
3.3.4 音频-视频对齐
如前文第3.2节所述,给定一个帧序列(y0,...,yn),存在一个对应的从原始语音信号提取出的音频频谱特征序列(spec0,...,spec2n)。每个音频特征跨越40毫秒窗口,每20毫秒重叠。对于任何给定的帧Yi,它与(spec2i−2到spec2i+2)所覆盖的音频特征对齐。为了对齐第一个和最后一个视频帧,只需在它们各自的音频特征的开头和结尾附加静音。
选择音频窗口时,太大会导致网络无法使用最有意义的信息,太小可能无法为网络生成由爆炸音引起的更复杂的唇部运动提供足够的上下文。
4 实验
4.1 评估指标
计算SSIM(结构相似性指数)[74]、PSNR(峰值信噪比)和FID(Frechet Inception Distance)[23]分数,以衡量生成帧的整体质量。还计算CPBD(累积概率模糊检测)[46]分数以及SyncNet [13, 50]的置信度(LSE-C)和距离(LSE-D)分数。在计算图像质量指标时,为了保持公平性,尽可能只计算生成图像的部分。
4.2 单说话人模型
使用GRID音频-视觉语料库的身份S1上的数据来训练单说话人模型。总共有1000个视频,每个视频大约3秒钟,总共约50分钟的音频-视觉内容用于训练。我们使用950个视频对模型进行训练,并保留了其中的50个用于测试。训练895个Epochs。
在该模型的上/下采样块中没有使用注意力层,只在U-Net的中间块中使用了注意力层。节省训练时间。但是为了获得更好的结果,建议在多说话人模型中使用注意力层。
4.3 多说话人模型
在CREMA-D数据集的所有身份上训练了多说话人模型。训练735个Epochs。我们对训练多说话人模型进行了一些关键变化。首先,在32x32分辨率以及中间块中使用了自注意力层。其次,切换到余弦噪声,并减少了模型在训练过程中采用的扩散步骤数目至1000。最后,将通道倍增数减少为[1,2,3]。
还尝试了在上/下采样块中没有注意力的模型训练。该模型甚至无法收敛到训练集身份。推测将U-Net中使用的内部通道数量从64增加到128或256将显著改善结果,并且可以通过更长时间的训练来提高性能。
4.4 结果讨论
表2显示了我们的模型在未见测试集上与文献中其他方法进行比较时的得分结果。
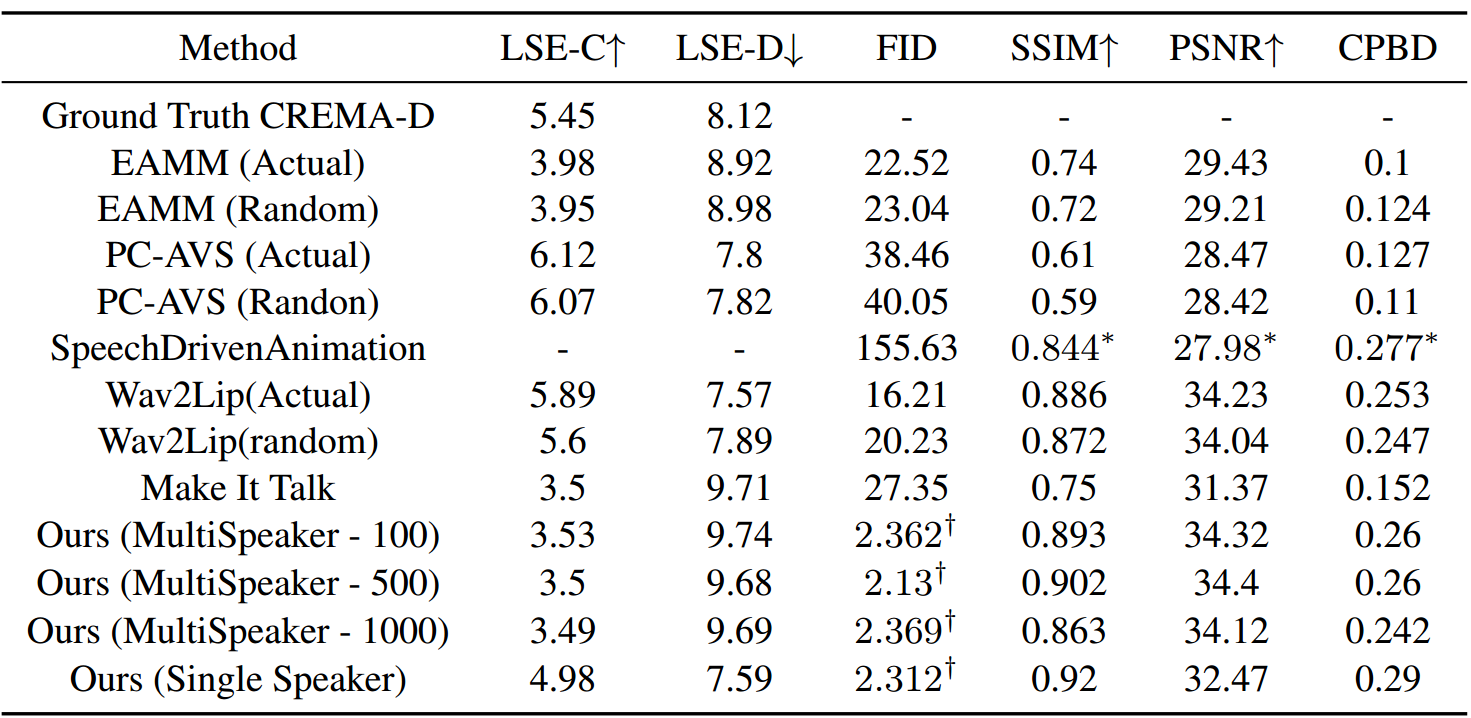
多说话人模型对未见说话人的泛化效果很好,在图像质量指标上得分很高,在SSIM和CPBD方面除Wav2Lip外,超过了所有其他方法。我们认为这是因为扩散模型具有对复杂、高维数据分布建模的能力,使其能够学习数据集的统计特性,并生成与训练集中相似的图像。此外,由于扩散模型在训练过程中逐渐去除目标图像中的噪声,有助于它生成更平滑的结果,而不像基于GAN的模型一样一次性生成帧。
在SyncNet [13]置信度(LSE-C)和距离(LSE-D)得分方面的评估中,我们的多说话人结果与文献中的其他流行方法相媲美,略优于MakeItTalk,但低于EAMM。 PC-AVS和Wav2Lip得分最高。值得注意的是,它们的方法明显优于真实数据。我们认为这是因为所有其他方法都经过特别训练,以优化惩罚模型对不良唇部同步情况的损失函数。在PC-AVS和Wav2Lip的情况下,它们都依赖于强大的唇部同步判别器,鼓励模型根据语音生成清晰、明确的唇部运动。
我们的方法没有使用这样的损失函数或判别器,在训练过程中固有地学习了语音与唇部运动之间的关系。因此,虽然我们在未见说话人上的唇部同步得分较低,但我们提供了一种新颖的方法来完成任务,因为我们并没有明确训练模型改善唇部同步。
值得注意的是,我们的单说话人模型在上述同步指标上表现非常好,这使我们推测,通过花更多的时间学习数据分布,多说话人模型在理论上也可以达到类似的结果。
在推断过程中,多说话人模型有时难以在整个生成过程中保持一致的身份,尤其是如果原始视频中存在头部姿势的极端变化。这是由于小错误的累积,因为我们的方法在推断时完全是自回归的,完全依赖于先前生成的帧和身份帧来修改当前帧。图2,失败的实例。

推测可以通过以下三种方式缓解这个问题:1)在训练期间,在前一帧上引入小量的面部扭曲,以模拟在生成过程中自然发生的扭曲。这将促使模型查看身份帧以进行修正。2)简单地延长模型的训练时间。3)在像VoxCeleb或LRS这样的具有不受限制条件的训练集中,训练更多样化的说话人数据。
多说话人模型对说话者音量和语调非常敏感,特别是当面对来自未见说话者的语音时。当说话者大声喊叫或清晰地对着麦克风说话时,唇部运动非常准确,看起来同步良好。当音量较低时,说话者似乎在咕哝,完整的唇部运动范围没有正确生成。怀疑这是因为我们在条件网络中使用了谱特征嵌入,而使用预训练的语音识别音频编码器可以降低这种影响。这是因为这些模型通常经过训练,从语音中提取内容,忽略被认为是无关的音调和语气等信息。
5 结论
未来工作
模型速度和野外训练:扩散模型的训练和采样速度都很慢。单说话人模型每个Epoch的训练时间约为6分钟,而多说话人模型为40分钟。曾尝试在潜空间中进行训练以加快训练速度,但是样本质量下降,因此在像素空间中操作。改进模型的训练速度对我们来说是首要任务,这将使我们能够在更大、更多样化的“野外”数据集上进行训练,如VoxCeleb [45]或LRS [12]。
外观一致性:正如之前讨论的,我们的多说话人模型在未见身份上生成的外观有时会与原始外观有所偏差。我们将探索这种效果是由于训练不充分还是训练数据集的多样性不足。
语音条件:计划探索使用更广泛的语音特征作为模型条件的潜力,例如尝试不同大小的窗口在计算谱特征时,或者使用预训练的音频编码器,如Wav2Vec2 [3]、Whisper [52]或DeepSpeech2 [1]。相信结合这些特征可能会提高我们模型的唇部同步性能,并生成更逼真、表现力更强的唇部运动。
结论
结果展示了去噪扩散模型在捕捉音频和视频信号之间复杂关系、以及为语音驱动的视频编辑任务,生成具有准确唇部运动的连贯视频序列方面的多功能性。
限制:CREMA-D数据集相对较小,这限制了我们方法在其他领域的推广能力。此外,需要大量的计算资源和时间来进行训练。这对于实时应用程序或大规模数据集的训练是一个挑战。
智能推荐
linux - 自启动脚本_linux自启动脚本-程序员宅基地
文章浏览阅读3.2k次。自启动脚本**注:软件安装的路径和版本以及端口都是要根据服务器做相应的调整1.linux添加开机自启动单个服务程序脚本编写脚本autostart.sh(这里以开机启动redis服务为例),脚本内容如下:#!/bin/sh#chkconfig: 2345 80 90#description:开机自动启动的脚本程序开启redis服务 端口为6379/usr/local/service/redis-2.8.3/src/redis-server --port 6379 &脚本第一行 “#!/b_linux自启动脚本
Springboot2.X集成redis集群(Lettuce)连接的方法_springboot 2 redis 集群链接-程序员宅基地
文章浏览阅读4.4k次。前提:搭建好redis集群环境1.新建工程,pom.xml文件中添加redis支持<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId></depen..._springboot 2 redis 集群链接
uboot和系统移植----------12、uboot 杂记 — logo 显示和 fastboot 原理_logo与fastbootlogo有什么差别-程序员宅基地
文章浏览阅读464次。一、x210 uboot 当中的LCD操作分析1、新旧版本开发板的LCD模组差异(1)2015.11月初之前购买的X210开发板都属于老版本,型号是 X210V3 ;之后购买的开发板都是新版本的,型号是X210V3S。(2)两个开发板主要电路是完全一样的,不同主要有3点:1、是把拨码开关换成了短路帽;2、另一个是LCD分辨率从800480升级成1024600;3、第三个是触摸屏芯片型号换了。2、背光电路分析(1)LCD的背光源有2种设计。一种是简单设计,背光只能点亮和熄灭两种状态,不能_logo与fastbootlogo有什么差别
Dubbo源码解析之服务调用过程-程序员宅基地
文章浏览阅读153次。简介在前面的文章中,我们分析了 Dubbo SPI、服务导出与引入、以及集群容错方面的代码。经过前文的铺垫,本篇文章我们终于可以分析服务调用过程了。Dubbo 服务调用过程比较复杂,包含众多步骤,比如发送请求、编解码、服务降级、过滤器链处理、序列化、线程派发以及响应请求等步骤。限于篇幅原因,本篇文章无法对所有的步骤一一进行分析。本篇文章将会重点分析请求的发送与接收、编解码、线程派发以及响应的发..._dubbo 服务调用过程源码解析
MATLAB/Simulink生成DSP代码——环境搭建(前期准备)_matlab转dsp-程序员宅基地
文章浏览阅读1.9k次。MATLAB/Simulink生成DSP代码——环境搭建(前期准备)_matlab转dsp
Linux内核(一) [ IMX RK ] TTY-UART驱动框架解析_内核tty框架-程序员宅基地
文章浏览阅读1.4k次。平台:NXP imx6ull 内核版本:4.1.15文章目录一、Linux TTY驱动框架二、Linux Uart驱动框架三、UART相关结构体uart_driver(UART驱动结构体) 、uart_port(UART端口) 、uart_ops(UART操作函数集)四、设备树配置五、串口驱动分析一、Linux TTY驱动框架Linux TTY驱动程序代码位于/drivers/tty下面。TTY整体框架大致分为TTY应用层、TTY文件层、TTY线路规程层、TTY驱动层、TTY设备驱动层。TTY应_内核tty框架
随便推点
QQ邮箱SMTP发送邮件时要注意哪些安全设置?-程序员宅基地
文章浏览阅读327次,点赞7次,收藏5次。只有做好这些安全设置,才能确保你的邮件发送过程既顺畅又安全。AokSend,利用API/SMTP接口,轻松对接QQ邮箱SMTP,一键发送邮件,高效便捷,助力企业沟通无障碍,营销宣传更给力!
100000569 - 《算法笔记》2.5小节——C/C++快速入门->数组-程序员宅基地
文章浏览阅读135次。《算法笔记》2.5小节——C/C++快速入门->数组26039 Problem A 习题6-4 有序插入#include <stdio.h>int main() { int a[10]; for (int i = 0; i < 10; i++) { scanf("%d", &a[i]); } int temp = a[9]; int j; f...
ICP算法详解——我见过最清晰的解释-程序员宅基地
文章浏览阅读4.2w次,点赞52次,收藏481次。问题引入 迭代最近点(Iterative Closest Point, 下简称ICP)算法是一种点云匹配算法。 假设我们通过RGB-D相机得到了第一组点云,相机经过位姿变换(旋转加平移)后又拍摄了第二组点云,注意这里的 和 的坐标分别对应移动前和移动后的坐标系(即坐标原点始终为相机光心,这里我们有移动前、移动后两个坐标系),并且我们通过相关算法筛选和调整了点云存储的顺序,使得和中的点一一对应,如在三维空间中对应同一个点。 现在我们要解决的问题..._icp算法
计算机绘图形考检测1-6,江苏开放大学计算机绘图形考1-程序员宅基地
文章浏览阅读343次。《江苏开放大学计算机绘图形考1》由会员分享,可在线阅读,更多相关《江苏开放大学计算机绘图形考1(15页珍藏版)》请在人人文库网上搜索。1、江 苏 开 放 大 学形成性考核作业学 号 姓 名 课程代码 110037课程名称 计算机绘图评阅教师 第 1 次任务共 4 次任务任务内容:一:根据已知条件利用直线命令绘制五角星。(不标注尺寸)结果作答:绘图步骤:步骤一:绘制直线命令: _line 指定第一点..._二:绘制含圆的平面图形(分层设置线型和线宽),不标注尺寸。(其中:左上角和右下角的
物联网pyqt5应用管理系统(Python、华为云)_python 基于pyqt的管理系统-程序员宅基地
文章浏览阅读427次。物联网应用管理系统是基于Python和PyQt5技术栈实现的应用端,旨在提供对烟感设备、水质设备和井盖设备等物联网设备的综合管理功能。该系统实现了设备管理、数据监控和远程控制等功能,并通过华为云平台实现了数据存储和云服务支持。_python 基于pyqt的管理系统
Rabbitmq 安装与配置-程序员宅基地
文章浏览阅读68次。RabbitMQ支持各种操作系统,包括Unix\Linux及其各种发行和变种版本、Windows、MAC等。 首先需要下载安装包,可以是二进制,也可以是源码安装,各种包集合下载地址在这里。 由于支持的操作系统众多,那么版本也就众多,本文以Centos为例:一、Erlang安装 RabbitMQ基于Erlang,所以必须先安装Erlang,具体如何安装参考这..._rabbitmq 版本与erlang 版本