卡尔曼滤波器详解-程序员宅基地
技术标签: 算法
目录
一阶卡尔曼(无详细推导,初步认识原理)
字符定义
X ^ k \hat{X}_k X^k表示第k次估计值(上面的 ^ \hat{} ^ 号表示估计)
Z k Z_k Zk表示第k次测量值
K k K_k Kk表示第k次得到的卡尔曼系数
e E S T k e_{EST_k} eESTk表示第k次估计误差
e M E A k e_{MEA_k} eMEAk表示第k次测量误差
递归算法
如果我们想要得到某个数据时,可以通过测量获得。但测量总是存在误差的。比如我们想要知道一本书的厚度,可以用尺子进行测量,而尺子上的量程是毫米,所以我们最多只能得到精确到毫米的厚度。如果书厚度的真实值是10.49mm,那么我们的测量值大概就是10mm或者11mm,这时候测量值与书厚度的真实值就存在误差了。
这时我们可以通过多次测量求平均来得到一个相对准确的估计值,用式子表示就是:
X ^ k = Z 1 + Z 2 + . . . + Z k k \hat{X}_k=\frac {Z_1+Z_2+...+Z_k}k X^k=kZ1+Z2+...+Zk
当我们测量的次数一多时,需要记录的测量值也变多,有什么方法可以减少需要记录下的测量值吗?这时我们可以继续简单推导就可得:
X ^ k = 1 k × ( Z 1 + Z 2 + . . . + Z k ) = 1 k × ( Z 1 + Z 2 + . . . + Z k − 1 ) + 1 k × Z k = k − 1 k × [ 1 k − 1 × ( Z 1 + Z 2 + . . . + Z k − 1 ) ] + 1 k × Z k = k − 1 k × X ^ k − 1 + 1 k × Z k = X ^ k − 1 + 1 k × ( Z k − X ^ k − 1 ) \begin{aligned} \hat{X}_k&=\frac {1}k \times (Z_1+Z_2+...+Z_k) \\&=\frac {1}k \times (Z_1+Z_2+...+Z_{k-1})+\frac {1}k \times Z_{k} \\&=\frac {k-1}k \times \big[ \frac 1{k-1} \times (Z_1+Z_2+...+Z_{k-1}) \big]+\frac {1}k \times Z_{k} \\&=\frac {k-1}k \times \hat{X}_{k-1}+\frac {1}k \times Z_{k} \\&=\hat{X}_{k-1}+\frac {1}k \times (Z_{k}-\hat{X}_{k-1}) \end{aligned} X^k=k1×(Z1+Z2+...+Zk)=k1×(Z1+Z2+...+Zk−1)+k1×Zk=kk−1×[k−11×(Z1+Z2+...+Zk−1)]+k1×Zk=kk−1×X^k−1+k1×Zk=X^k−1+k1×(Zk−X^k−1)
这时我们每次计算当前估计值 X ^ k \hat{X}_k X^k就只需要上一次估计值 X k − 1 ^ \hat{X_{k-1}} Xk−1^、当前测量值 Z k Z_{k} Zk,而不是所有的测量值。
令卡尔曼系数 K k = 1 k K_k=\frac 1k Kk=k1,我们就得到了一阶卡尔曼滤波的第一条基本公式
X ^ k = X ^ k − 1 + K k × ( Z k − X ^ k − 1 ) (1-1) \hat{X}_k=\hat{X}_{k-1}+K_k \times (Z_{k}-\hat{X}_{k-1})\tag{1-1} X^k=X^k−1+Kk×(Zk−X^k−1)(1-1)
一阶卡尔曼系数
对于式1-1,我们清楚地知道 X ^ k \hat{X}_k X^k是估计值, Z k Z_k Zk是测量值,那么 K k K_k Kk表示什么呢?
我们先不进行推导直接给出两条式子(推导会在卡尔曼增益详细推导中给出)。
K k = e E S T k − 1 e E S T k − 1 + e M E A k (1-2) K_k=\frac{e_{EST_{k-1}}}{e_{EST_{k-1}}+e_{MEA_{k}}} \tag{1-2} Kk=eESTk−1+eMEAkeESTk−1(1-2)
e E S T k = ( 1 − K k ) × e E S T k − 1 (1-3) e_{EST_k}=(1-K_k)\times e_{EST_{k-1}}\tag{1-3} eESTk=(1−Kk)×eESTk−1(1-3)
由式1-2可知:
当估计误差远远大于计算误差,即 e E S T k > > e M E A k e_{EST_k}\gt\gt e_{MEA_{k}} eESTk>>eMEAk时, K k = 1 K_k=1 Kk=1, X ^ k = Z k \hat{X}_k=Z_k X^k=Zk;
当估计误差远远小于计算误差,即 e E S T k < < e M E A k e_{EST_k}\lt\lt e_{MEA_{k}} eESTk<<eMEAk时, K k = 0 K_k=0 Kk=0, X ^ k = X ^ k − 1 \hat{X}_k=\hat{X}_{k-1} X^k=X^k−1。
这时我们就可以大概看出卡尔曼系数 K k K_k Kk的意义,
当估计误差大,测量误差小时,卡尔曼系数就越接近1,我们的计算结果就接近测量值;
当估计误差小,测量误差大时,卡尔曼系数就越接近0,我们的计算结果就接近估计值。
所以卡尔曼系数表示的是对测量值的信任程度。
从实际来说也是特别好理解的,
当我们测量的值越准时,卡尔曼系数就越接近1,我们就越相信测量值;
当我们估计的值越准时,卡尔曼系数就越接近0,我们就越不相信测量值。
一阶卡尔曼滤波器的简单使用
使用一阶卡尔曼滤波器需要进行三个步骤,然后不断重复这三个步骤即可。
s t e p 1 计 算 卡 尔 曼 系 数 K k = e E S T k − 1 e E S T k − 1 + e M E A k s t e p 2 计 算 估 计 值 X ^ k = X ^ k − 1 + K k × ( Z k − X ^ k − 1 ) s t e p 3 更 新 估 计 误 差 e E S T k = ( 1 − K k ) × e E S T k − 1 \begin{aligned} step1&\quad计算卡尔曼系数K_k=\frac{e_{EST_{k-1}}}{e_{EST_{k-1}}+e_{MEA_{k}}} \\step2&\quad计算估计值\hat{X}_k=\hat{X}_{k-1}+K_k \times (Z_{k}-\hat{X}_{k-1}) \\step3&\quad更新估计误差e_{EST_k}=(1-K_k)\times e_{EST_{k-1}} \end{aligned} step1step2step3计算卡尔曼系数Kk=eESTk−1+eMEAkeESTk−1计算估计值X^k=X^k−1+Kk×(Zk−X^k−1)更新估计误差eESTk=(1−Kk)×eESTk−1
我们知道用同一测量工具测量时,测量误差是不用变的。而当我们的估计模型改变时,估计误差也改变了。一阶卡尔曼滤波器的估计模型就是step2的公式。
第一步,我们根据测量误差与估计误差确定卡尔曼系数,从而确定一个一阶卡尔曼滤波器的模型。
第二步,我们利用新模型和新的测量值计算出新的估计值。
第三步,我们用新的卡尔曼系数来更新新模型的估计误差。
然后不断循环,使用模型越来越合适。
例子:假设我们测量一个桌子的高度,真实值是500cm,测量误差是10cm(也就是说测量值在490cm到510cm之间任意取值),我们假设最开始的估计值为400cm,估计误差为120cm(估计值和估计误差可以任意取值,因为从上面那三个步骤我们可以知道估计值和估计误差会随着计算而自动改变)。
我用excel得:

其中可以调整的数据为测量误差,首个估计误差,首个估计值。虽然测量值是随机的,可以改变,但并不算我们研究的范围。
接下来给出不同初始值,相同测量值的图,然后大家自己分析不同的原因。
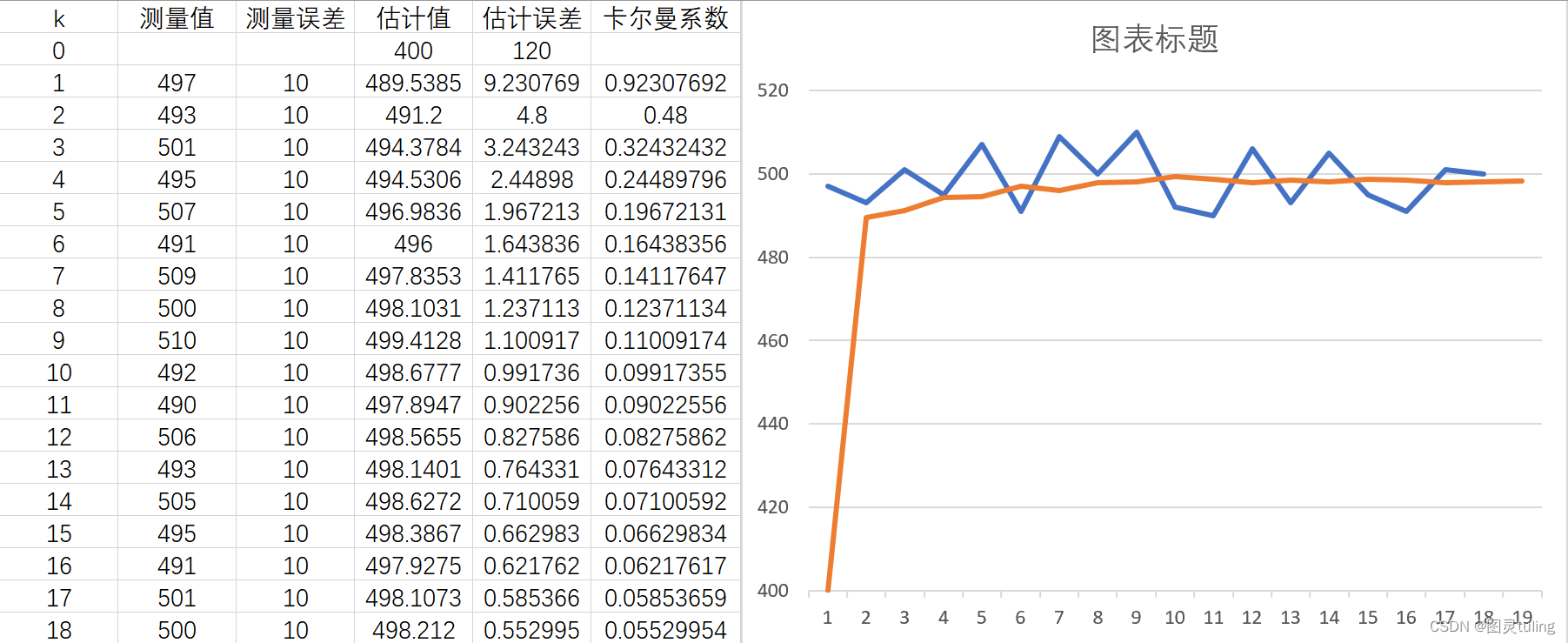
测量误差:10,首个估计误差:120,首个估计值:400。
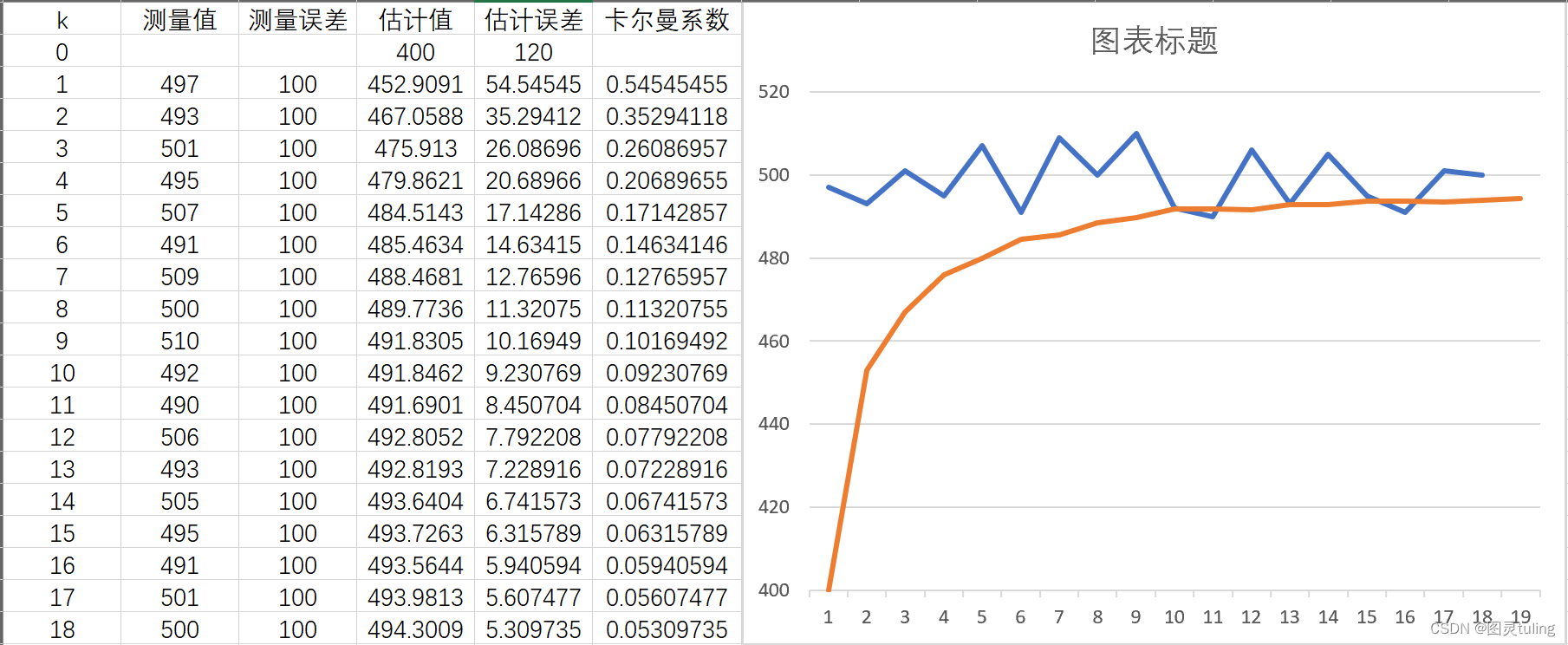
测量误差:100,首个估计误差:120,首个估计值:400。
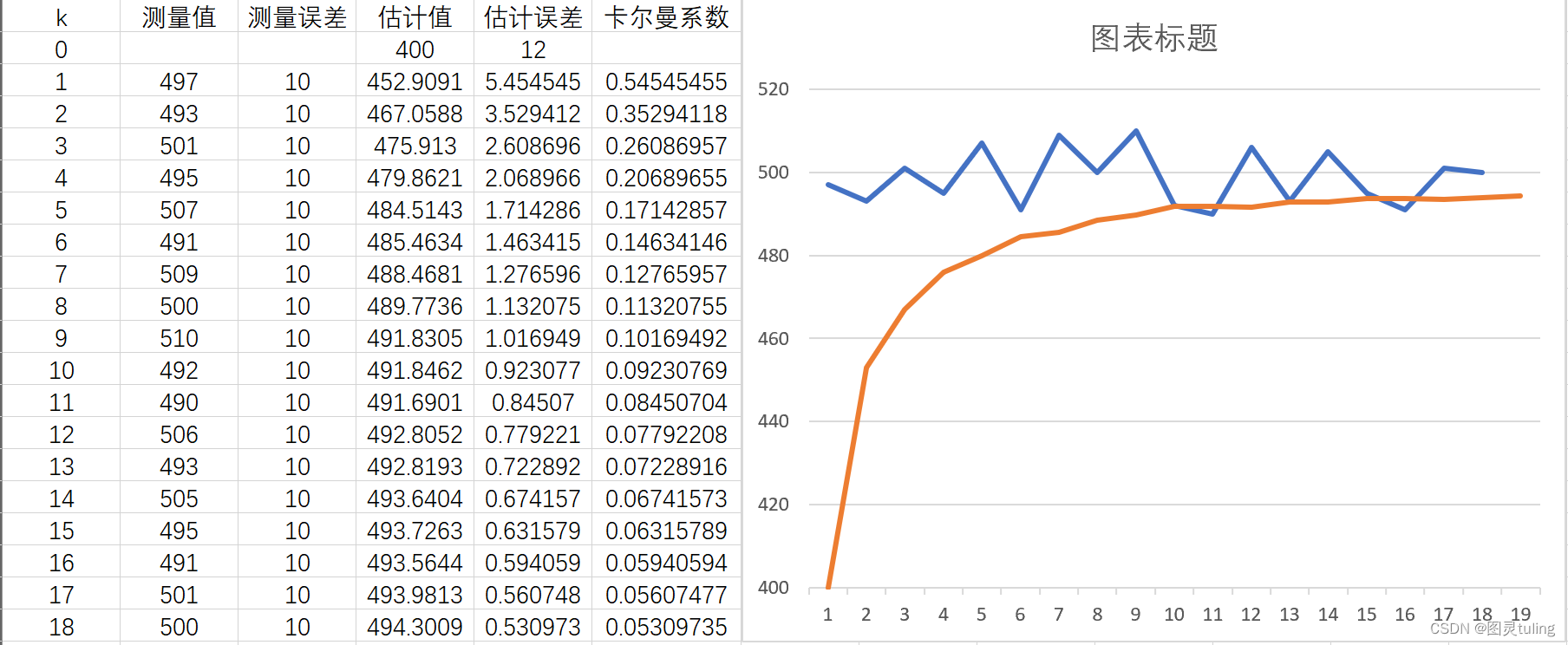
测量误差:10,首个估计误差:12,首个估计值:400。
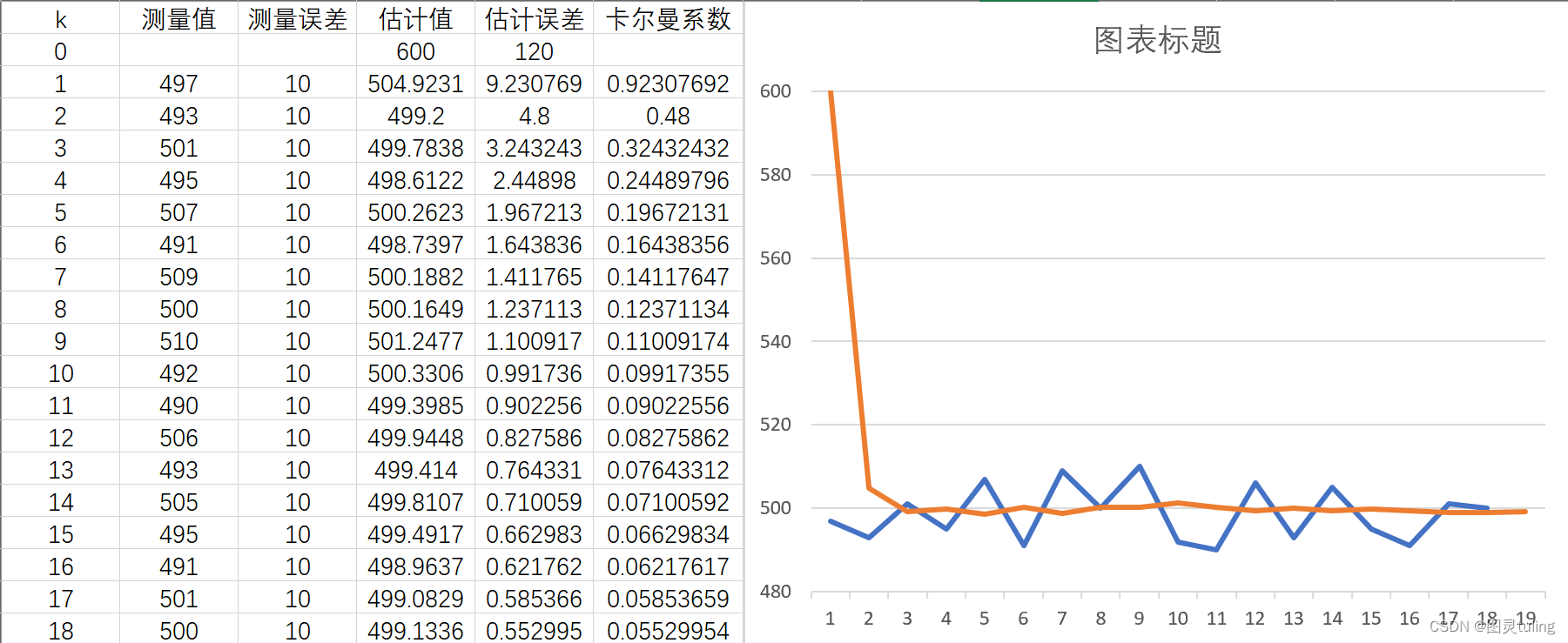
测量误差:10,首个估计误差:120,首个估计值:600。
测量误差:10,首个估计误差:120,首个估计值:500。
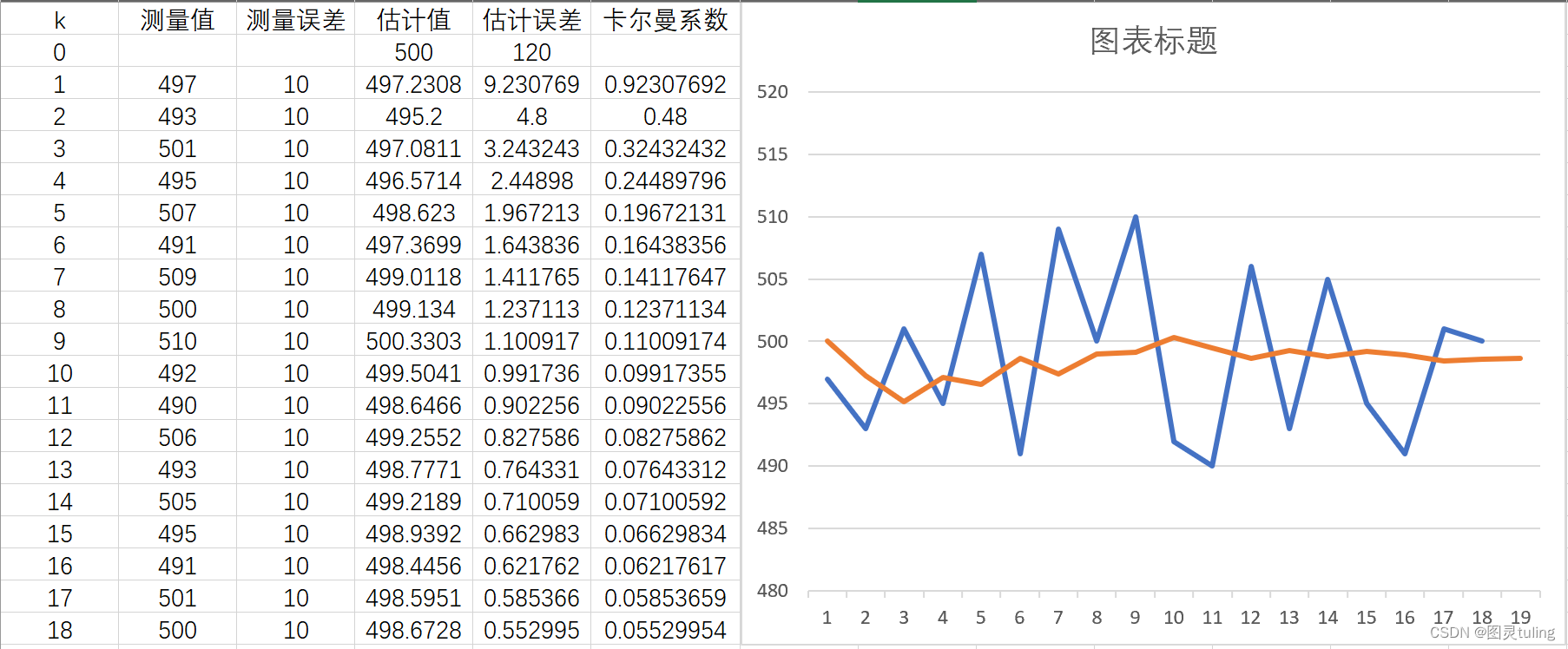
可以看出,不管如何,估计值最终都会逼近真实值,只是响应不同的区别而已。
卡尔曼滤波(矩阵运算,详细推导)
前置知识
这里简单介绍给出概念,想要真正学会这些前置知识需要查找其它资料深入学习。
且后继的所有变量几乎都是矩阵,还需要进行概率运算,所以需要拥有一定的概率论和线性代数基础。
数据融合
数据融合,大概就是把一系列原始数据进行处理,最后得到一个更加优化的数据。一阶卡尔曼的第一条基本公式 X ^ k = X ^ k − 1 + K k × ( Z k − X ^ k − 1 ) \hat{X}_k=\hat{X}_{k-1}+K_k \times (Z_{k}-\hat{X}_{k-1}) X^k=X^k−1+Kk×(Zk−X^k−1)就可以对两个数据进行融合,不过它需要变化一下,变为:
X ^ = Z 1 + K k × ( Z 2 − Z 1 ) \hat{X}={Z}_{1}+K_k \times (Z_{2}-{Z}_{1}) X^=Z1+Kk×(Z2−Z1)
其中 X ^ \hat{X} X^为融合后的数据(估计值), Z 1 Z_1 Z1, Z 2 Z_2 Z2为融合前的原始数据, K k K_k Kk来控制如何融合(由融合目标推出)。
比如:我们用两个测试工具来测试一个鸡蛋的重量,其中一个测得45g,它的测量误差服从正态分布,方差 σ 1 \sigma_1 σ1为3g,另一个测得47g,它的测量误差也服从正态分布,方差 σ 2 \sigma_2 σ2为2g。
现在就是已知 Z 1 = 45 Z_1=45 Z1=45, Z 2 = 47 Z_2=47 Z2=47, σ 1 = 3 \sigma_1=3 σ1=3, σ 2 = 2 \sigma_2=2 σ2=2,要求一个更为准确的重量 X ^ \hat{X} X^,目标为更加准确(即方差最小)。
所以得 D ( X ^ ) = D ( Z 1 + K k × ( Z 2 − Z 1 ) ) D(\hat X)=D\big(Z_1+K_k \times (Z_2-Z_1)\big) D(X^)=D(Z1+Kk×(Z2−Z1))
Z 1 Z_1 Z1与 Z 2 Z_2 Z2相互独立,所以 D ( X ^ ) = D ( Z 1 + K k × ( Z 2 − Z 1 ) ) D(\hat X)=D\big(Z_1+K_k \times (Z_2-Z_1)\big) D(X^)=D(Z1+Kk×(Z2−Z1))
D ( X ^ ) = D ( Z 1 × ( 1 − K k ) + Z 2 × K k ) = D ( Z 1 × ( 1 − K k ) ) + D ( Z 2 × K k ) = ( 1 − K k ) 2 D ( Z 1 ) + K k 2 D ( Z 2 ) = ( 1 − K k ) 2 σ 1 2 + K k 2 σ 2 2 \begin{aligned} D(\hat X)&=D\big(Z_1 \times (1-K_k)+Z_2 \times K_k\big) \\&=D\big(Z_1 \times (1-K_k)\big)+D\big(Z_2 \times K_k\big) \\&=(1-K_k)^2D(Z_1)+K_k^2D(Z_2) \\&=(1-K_k)^2\sigma_1^2+K_k^2\sigma_2^2 \end{aligned} D(X^)=D(Z1×(1−Kk)+Z2×Kk)=D(Z1×(1−Kk))+D(Z2×Kk)=(1−Kk)2D(Z1)+Kk2D(Z2)=(1−Kk)2σ12+Kk2σ22
我们要通过改变 K k K_k Kk使得 D ( X ^ ) D(\hat X) D(X^)最小,所以 D ( X ^ ) D(\hat X) D(X^)对 K k K_k Kk求导,算出极值点。
d D ( X ^ ) d K k = − 2 ( 1 − K k ) σ 1 2 + 2 σ 2 2 K k = 0 \frac {dD(\hat X)}{dK_k}=-2(1-K_k)\sigma_1^2+2\sigma_2^2K_k=0 dKkdD(X^)=−2(1−Kk)σ12+2σ22Kk=0
解得 K k = σ 1 2 σ 1 2 + σ 2 2 ≈ 0.69 K_k=\frac {\sigma_1^2}{\sigma_1^2+\sigma_2^2}\approx0.69 Kk=σ12+σ22σ12≈0.69
故 X ^ = Z 1 + K k × ( Z 2 − Z 1 ) ≈ 46.385 g σ x = D ( X ^ ) = ( 1 − K k ) 2 σ 1 2 + K k 2 σ 2 2 ≈ 1.67 g \hat{X}={Z}_{1}+K_k \times (Z_{2}-{Z}_{1})\approx46.385g \\\sigma_x=\sqrt{D(\hat X)}=\sqrt{(1-K_k)^2\sigma_1^2+K_k^2\sigma_2^2}\approx1.67g X^=Z1+Kk×(Z2−Z1)≈46.385gσx=D(X^)=(1−Kk)2σ12+Kk2σ22≈1.67g
求解完成,我们用两个有误差的数据进行数据融合,获得了一个误差更小的数据。
协方差矩阵
协方差矩阵就是把方差和协方差在一个矩阵中表示出来,体现变量之间的关系。
比如我们有三组变量 x i , y i , z i x_i,y_i,z_i xi,yi,zi,具体如下:
| i | x | y | z |
|---|---|---|---|
| 1 | 179 | 74 | 33 |
| 2 | 187 | 80 | 31 |
| 3 | 175 | 71 | 28 |
可得 x ˉ = 180.3 , y ˉ = 75 , z ˉ = 30.7 σ x 2 = 1 3 ( ( x 1 − x ˉ ) 2 + ( x 2 − x ˉ ) 2 + ( x 3 − x ˉ ) 2 ) = 24.89 σ y 2 = 1 3 ( ( y 1 − y ˉ ) 2 + ( y 2 − y ˉ ) 2 + ( y 3 − y ˉ ) 2 ) = 14 σ z 2 = 1 3 ( ( z 1 − z ˉ ) 2 + ( z 2 − z ˉ ) 2 + ( z 3 − z ˉ ) 2 ) = 4.22 σ x σ y = σ y σ x = 1 3 ( ( x 1 − x ˉ ) ( y 1 − y ˉ ) + ( x 2 − x ˉ ) ( y 2 − y ˉ ) + ( x 3 − x ˉ ) ( y 3 − y ˉ ) = 18.7 σ x σ z = σ z σ x = 1 3 ( ( x 1 − x ˉ ) ( z 1 − z ˉ ) + ( x 2 − x ˉ ) ( z 2 − z ˉ ) + ( x 3 − x ˉ ) ( z 3 − z ˉ ) = 4.4 σ y σ z = σ z σ y = 1 3 ( ( y 1 − y ˉ ) ( z 1 − z ˉ ) + ( y 2 − y ˉ ) ( z 2 − z ˉ ) + ( y 3 − y ˉ ) ( z 3 − z ˉ ) = 3.3 \bar x=180.3,\bar y=75,\bar z=30.7 \\\sigma^2_x=\frac 13\big((x_1-\bar x)^2+(x_2-\bar x)^2+(x_3-\bar x)^2\big)=24.89 \\\sigma^2_y=\frac 13\big((y_1-\bar y)^2+(y_2-\bar y)^2+(y_3-\bar y)^2\big)=14 \\\sigma^2_z=\frac 13\big((z_1-\bar z)^2+(z_2-\bar z)^2+(z_3-\bar z)^2\big)=4.22 \\\sigma_x\sigma_y=\sigma_y\sigma_x=\frac 13\big((x_1-\bar x)(y_1-\bar y)+(x_2-\bar x)(y_2-\bar y)+(x_3-\bar x)(y_3-\bar y)=18.7 \\\sigma_x\sigma_z=\sigma_z\sigma_x=\frac 13\big((x_1-\bar x)(z_1-\bar z)+(x_2-\bar x)(z_2-\bar z)+(x_3-\bar x)(z_3-\bar z)=4.4 \\\sigma_y\sigma_z=\sigma_z\sigma_y=\frac 13\big((y_1-\bar y)(z_1-\bar z)+(y_2-\bar y)(z_2-\bar z)+(y_3-\bar y)(z_3-\bar z)=3.3 xˉ=180.3,yˉ=75,zˉ=30.7σx2=31((x1−xˉ)2+(x2−xˉ)2+(x3−xˉ)2)=24.89σy2=31((y1−yˉ)2+(y2−yˉ)2+(y3−yˉ)2)=14σz2=31((z1−zˉ)2+(z2−zˉ)2+(z3−zˉ)2)=4.22σxσy=σyσx=31((x1−xˉ)(y1−yˉ)+(x2−xˉ)(y2−yˉ)+(x3−xˉ)(y3−yˉ)=18.7σxσz=σzσx=31((x1−xˉ)(z1−zˉ)+(x2−xˉ)(z2−zˉ)+(x3−xˉ)(z3−zˉ)=4.4σyσz=σzσy=31((y1−yˉ)(z1−zˉ)+(y2−yˉ)(z2−zˉ)+(y3−yˉ)(z3−zˉ)=3.3
所以这三组数据的协方差矩阵为
P = [ σ x 2 σ y σ x σ z σ x σ x σ y σ y 2 σ z σ y σ x σ z σ y σ z σ z 2 ] = [ 24.89 18.7 4.4 18.7 14 3.3 4.4 3.3 4.22 ] P=\begin{bmatrix} \sigma^2_x & \sigma_y\sigma_x & \sigma_z\sigma_x\\ \sigma_x\sigma_y & \sigma^2_y & \sigma_z\sigma_y\\ \sigma_x\sigma_z& \sigma_y\sigma_z & \sigma^2_z \end{bmatrix}=\begin{bmatrix} 24.89 & 18.7 & 4.4\\ 18.7 & 14 & 3.3\\ 4.4 & 3.3 & 4.22 \end{bmatrix} P=⎣⎡σx2σxσyσxσzσyσxσy2σyσzσzσxσzσyσz2⎦⎤=⎣⎡24.8918.74.418.7143.34.43.34.22⎦⎤
其中,以 σ x σ y \sigma_x\sigma_y σxσy就表示变量x与变量y的线性关系程度,越趋近 + ∞ +\infty +∞就越正相关,越趋近 − ∞ -\infty −∞就越负相关,越趋近0就越无线性关系。但不同协方差之间不能比较,比如不能因为 σ x σ y > σ x σ z \sigma_x\sigma_y>\sigma_x\sigma_z σxσy>σxσz就说变量x与y的线性关系比x与z的线性关系强,因为这与变量值的大小有关,可以用计算式子看出来。
最终我们可以求协方差矩阵的通用式子:
如果存在一个数据矩阵 [ x 1 y 1 z 1 . . . x 2 y 2 z 2 . . . . . . . . . . . . . . . x n y n z n . . . ] \begin{bmatrix} x_1 & y_1 & z_1 & ...\\ x_2 & y_2 & z_2 & ...\\ ... & ... & ... & ... \\ x_n & y_n & z_n & ... \end{bmatrix} ⎣⎢⎢⎡x1x2...xny1y2...ynz1z2...zn............⎦⎥⎥⎤
则有过渡矩阵 a = [ x 1 y 1 z 1 . . . x 2 y 2 z 2 . . . . . . . . . . . . . . . x n y n z n . . . ] − 1 3 [ 1 1 1 . . . 1 1 1 . . . . . . . . . . . . . . . 1 1 1 . . . ] [ x 1 y 1 z 1 . . . x 2 y 2 z 2 . . . . . . . . . . . . . . . x n y n z n . . . ] a=\begin{bmatrix} x_1 & y_1 & z_1 & ...\\ x_2 & y_2 & z_2 & ...\\ ... & ... & ... & ... \\ x_n & y_n & z_n & ... \end{bmatrix}-\frac 13\begin{bmatrix} 1 & 1 & 1 & ...\\ 1 & 1 & 1 & ...\\ ... & ... & ... & ... \\ 1 & 1 & 1 & ... \end{bmatrix}\begin{bmatrix} x_1 & y_1 & z_1 & ...\\ x_2 & y_2 & z_2 & ...\\ ... & ... & ... & ... \\ x_n & y_n & z_n & ... \end{bmatrix} a=⎣⎢⎢⎡x1x2...xny1y2...ynz1z2...zn............⎦⎥⎥⎤−31⎣⎢⎢⎡11...111...111...1............⎦⎥⎥⎤⎣⎢⎢⎡x1x2...xny1y2...ynz1z2...zn............⎦⎥⎥⎤
(所有元素全为1的矩阵与数据矩阵大小相同,过渡矩阵就是数据矩阵减去它的平均值,相当于 x i − x ˉ x_i-\bar x xi−xˉ)
则这个数据矩阵的协方差矩阵为
P = 1 3 a T a ( a T 为 a 的 转 置 ) P=\frac 13a^Ta(a^T为a的转置) P=31aTa(aT为a的转置)
可以用上面的例子自己一步一步计算体验一下,最终得到的协方差矩阵是一样的。
状态空间方程
我们以一个简单的弹簧振动阻尼系统为例:
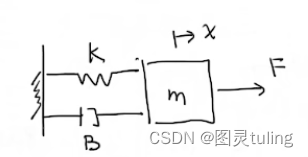
向右为x轴正方向,弹簧胡克系数为k,阻尼系数为B(可理解为与空气阻力有关的系数),物体质量为m,对物体施加的力为F。
我们可以得到 m x ¨ + B x ˙ + k x = F = u m\ddot{x}+B\dot{x}+kx=F=u mx¨+Bx˙+kx=F=u,其中 x ˙ \dot{x} x˙为 x x x的一阶导, F F F可以理解为对这个系统的输入(input),即 u u u
我们可以设两个状态变量 x 1 , x 2 x_1,x_2 x1,x2分别位置,速度,得:
x 1 = x x 2 = x ˙ x ˙ 1 = x 2 x ˙ 2 = x ¨ = 1 m u − B m x 2 − k m x 1 x_1=x \\ x_2=\dot{x}\\\dot{x}_1=x_2\\\dot{x}_2=\ddot{x}=\frac 1mu-\frac Bmx_2-\frac kmx_1 x1=xx2=x˙x˙1=x2x˙2=x¨=m1u−mBx2−mkx1
这时我们可以列出它们前后的状态矩阵的关系:
[ x ˙ 1 x ˙ 2 ] = [ 0 1 − k m − B m ] [ x 1 x 2 ] + [ 0 1 m ] u \begin{bmatrix} \dot{x}_1 \\ \dot{x}_2 \end{bmatrix}=\begin{bmatrix} 0 & 1 \\ -\frac km & -\frac Bm \end{bmatrix}\begin{bmatrix} {x}_1 \\ {x}_2 \end{bmatrix}+\begin{bmatrix} 0 \\ \frac 1m \end{bmatrix}u [x˙1x˙2]=[0−mk1−mB][x1x2]+[0m1]u
而在一个系统中通常不单单只有状态量,还有观测量。这时假设我们观测得到的值没有误差,即 Z 1 = x = x 1 ( 位 置 ) Z 2 = x ˙ = x 2 ( 速 度 ) Z_1=x=x_1 (位置)\\Z_2=\dot{x}=x_2(速度) Z1=x=x1(位置)Z2=x˙=x2(速度)
可以得测量矩阵方程:
[ Z 1 Z 2 ] = [ 1 0 0 1 ] [ x 1 x 2 ] \begin{bmatrix} Z_1 \\ Z_2 \end{bmatrix}=\begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}\begin{bmatrix} {x}_1 \\ {x}_2 \end{bmatrix} [Z1Z2]=[1001][x1x2]
通过提炼上面的状态矩阵方程和测量矩阵方程我们可以得到:
X ˙ ( t ) = A X ( t ) + B u ( t ) Z ( t ) = H X ( t ) \begin{aligned}\dot X_{(t)}&=AX_{(t)}+Bu_{(t)}\\Z_{(t)}&=HX_{(t)}\end{aligned} X˙(t)Z(t)=AX(t)+Bu(t)=HX(t)
离散化可得:
X k = A X k − 1 + B u k − 1 Z k = H X k \begin{aligned}X_{k}&=AX_{k-1}+Bu_{k-1}\\Z_{k}&=HX_{k}\end{aligned} XkZk=AXk−1+Buk−1=HXk
同时一个系统在变化时会有过程噪声 ω k \omega_k ωk,测量时会有测量噪声 ν k \nu_k νk(噪声可理解为误差)
最终我们可以得到一个较通用的离散化状态空间方程:
X k = A X k − 1 + B u k − 1 + ω k Z k = H X k + ν k \begin{aligned}X_{k}&=AX_{k-1}+Bu_{k-1}+\omega_k\\Z_{k}&=HX_{k}+\nu_k\end{aligned} XkZk=AXk−1+Buk−1+ωk=HXk+νk
噪声的协方差矩阵
对于不确定的噪声,我们一般视它服从期望为0的正态分布。
那么这个噪声的协方差矩阵是多少呢。
假设现在一个噪声 ω \omega ω且 P ( ω ) ∼ ( 0 , Q ) P(\omega)\sim(0,Q) P(ω)∼(0,Q),其中 Q Q Q就是这个噪声的协方差矩阵。
可知 D ( ω ) = E ( ω 2 ) − E ( ω ) 2 = E ( ω 2 ) D(\omega)=E(\omega^2)-E(\omega)^2=E(\omega^2) D(ω)=E(ω2)−E(ω)2=E(ω2)
即 Q = E [ ω ω T ] Q=E[\omega \omega^T] Q=E[ωωT]
字符定义
X k X_k Xk为系统第k次所得状态真实值
X ^ k − \hat X^-_k X^k−为系统第k次所得状态先验估计值(即模型计算出来的,未进行数据融合的值)
X ^ k \hat X_k X^k为系统第k次所得状态后验估计值(即进行数据融合优化过的值)
u k u_{k} uk为对系统输入的控制量
Z k Z_k Zk为系统第k次测量值
A A A为状态矩阵, B B B为控制矩阵, H H H为测量矩阵
ω k \omega_k ωk为过程噪声且 P ( ω ) ∼ ( 0 , Q ) P(\omega)\sim(0,Q) P(ω)∼(0,Q), Q Q Q为过程噪声协方差矩阵
ν k \nu_k νk为测量噪声 P ( ν ) ∼ ( 0 , R ) P(\nu)\sim(0,R) P(ν)∼(0,R), R R R为测量噪声协方差矩阵
e k e_k ek为测量噪声 P ( e ) ∼ ( 0 , P ) P(e)\sim(0,P) P(e)∼(0,P), P P P为误差协方差矩阵
推导目标
由前置知识我们知道要描述一个系统可以用状态空间方程
X k = A X k − 1 + B u k − 1 + ω k − 1 Z k = H X k + ν k \begin{aligned}X_{k}&=AX_{k-1}+Bu_{k-1}+\omega_{k-1}\\Z_{k}&=HX_{k}+\nu_k\end{aligned} XkZk=AXk−1+Buk−1+ωk−1=HXk+νk
因为噪声是不测的,所以我们可以掌握的是
X ^ k − = A X ^ k − 1 + B u k − 1 X ^ k − = H − 1 Z k ( 即 Z k = H X ^ k − ) \begin{aligned}\hat X^-_{k}&=A\hat X_{k-1}+Bu_{k-1}\\\hat X^-_{k}&=H^{-1}Z_k(即Z_{k}=H\hat X^-_{k})\end{aligned} X^k−X^k−=AX^k−1+Buk−1=H−1Zk(即Zk=HX^k−)
其中第一条为我们的建立的模型所预测的(未优化),第二条为测量所得,两个数据都存在误差(即噪声),我们可以前置知识中的数据融合,来将这两个数据融合成一个误差更小的数据,即:
X ^ k = X ^ k − + G ( H − 1 Z k − X ^ k − ) \hat X_k=\hat X^-_k+G(H^{-1}Z_k-\hat X^-_k) X^k=X^k−+G(H−1Zk−X^k−)
令 G = K k H G=K_kH G=KkH得: X ^ k = X ^ k − + K k ( Z k − H X ^ k − ) \hat X_k=\hat X^-_k+K_k(Z_k-H\hat X^-_k) X^k=X^k−+Kk(Zk−HX^k−)
可知:
K k ∈ [ 0 , H − 1 ] 当 K k = 0 时 , X ^ k = X ^ k − 当 K k = H − 1 时 , X ^ k = H − 1 Z k K_k\in[0,H^{-1}]\\当K_k=0时,\hat X_k=\hat X^-_k\\当K_k=H^{-1}时,\hat X_k=H^{-1}Z_k Kk∈[0,H−1]当Kk=0时,X^k=X^k−当Kk=H−1时,X^k=H−1Zk
我们的目标就是选择合适的 K k K_k Kk让我们优化后的数据 X ^ k \hat X_k X^k接近真实值 X k X_k Xk,使误差协方差矩阵的迹最小。
卡尔曼增益 K k K_k Kk
设误差 e k = X k − X ^ k e_k=X_k-\hat X_k ek=Xk−X^k,且误差服从正态分布 P ( e k ) ∼ ( 0 , P ) P(e_k)\sim (0,P) P(ek)∼(0,P)
先推导 e k e_k ek
e k = X k − X ^ k = X k − ( X ^ k − + K k ( Z k − H X ^ k − ) ) = X k − X ^ k − − K k Z k + H X ^ k − = X k − X ^ k − − K k H X k − K k ν k + H X ^ k − = ( I − K k H ) ( X k − X ^ k − ) − K k ν k \begin{aligned} e_k&=X_k-\hat X_k \\ &= X_k-\big(\hat X^-_k+K_k(Z_k-H\hat X^-_k)\big) \\ &= X_k-\hat X^-_k-K_kZ_k+H\hat X^-_k \\ &= X_k-\hat X^-_k-K_kHX_k-K_k\nu_k+H\hat X^-_k \\ &= (I-K_kH)(X_k-\hat X^-_k)-K_k\nu_k \end{aligned} ek=Xk−X^k=Xk−(X^k−+Kk(Zk−HX^k−))=Xk−X^k−−KkZk+HX^k−=Xk−X^k−−KkHXk−Kkνk+HX^k−=(I−KkH)(Xk−X^k−)−Kkνk
所以误差协方差矩阵为:
P k = E [ e k e k T ] = E [ ( X k − X ^ k ) ( X k − X ^ k ) T ] = E [ ( ( I − K k H ) ( X k − X ^ k − ) − K k ν k ) ( ( I − K k H ) ( X k − X ^ k − ) − K k ν k ) T ] \begin{aligned} P_k&=E[e_ke^T_k] \\&=E[(X_k-\hat X_k )(X_k-\hat X_k )^T] \\&=E[\big((I-K_kH)(X_k-\hat X^-_k)-K_k\nu_k\big)\big((I-K_kH)(X_k-\hat X^-_k)-K_k\nu_k\big)^T] \end{aligned} Pk=E[ekekT]=E[(Xk−X^k)(Xk−X^k)T]=E[((I−KkH)(Xk−X^k−)−Kkνk)((I−KkH)(Xk−X^k−)−Kkνk)T]
结合线代和概率论知识:
( A B ) T = B T A T ( A + B ) T = A T + B T E ( e k − ν k T ) = 0 (AB)^T=B^TA^T\\(A+B)^T=A^T+B^T\\E(e_k^-\nu_k^T)=0 (AB)T=BTAT(A+B)T=AT+BTE(ek−νkT)=0
最终可得:
P k = E [ ( ( I − K k H ) ( X k − X ^ k − ) − K k ν k ) ( ( I − K k H ) ( X k − X ^ k − ) − K k ν k ) T ] = ( I − K k H ) E ( e k − e k − T ) ( I − K k H ) T + K k E ( ν k ν k T ) K k T = ( P k − − K k H P k − ) ( I T − H T K k T ) + K k = P k − − K k H P k − − P k − H T K k T + K k H P k − H T K k T + K k R K k T \begin{aligned} P_k &=E[\big((I-K_kH)(X_k-\hat X^-_k)-K_k\nu_k\big)\big((I-K_kH)(X_k-\hat X^-_k)-K_k\nu_k\big)^T] \\&=(I-K_kH)E(e_k^-e_k^{-T})(I-K_kH)^T+K_kE(\nu_k\nu_k^T)K_k^T \\&=(P_k^--K_kHP_k^-)(I^T-H^TK_k^T)+K_k \\&=P^-_k-K_kHP^-_k-P^-_kH^TK_k^T+K_kHP_k^-H^TK_k^T+K_kRK_k^T \end{aligned} Pk=E[((I−KkH)(Xk−X^k−)−Kkνk)((I−KkH)(Xk−X^k−)−Kkνk)T]=(I−KkH)E(ek−ek−T)(I−KkH)T+KkE(νkνkT)KkT=(Pk−−KkHPk−)(IT−HTKkT)+Kk=Pk−−KkHPk−−Pk−HTKkT+KkHPk−HTKkT+KkRKkT
可由 d t r ( A B ) d A = B T \frac {dtr(AB)}{dA}=B^T dAdtr(AB)=BT得:
d t r ( P k ) d K k = 0 − 2 ( H P k − ) T + 2 K k P k − H T + 2 K k R = 0 \frac {dtr(P_k)}{dK_k}=0-2(HP^-_k)^T+2K_kP^-_kH^T+2K_kR=0 dKkdtr(Pk)=0−2(HPk−)T+2KkPk−HT+2KkR=0
解得 K k = P k − H T H P k − H T + R K_k=\frac {P^-_kH^T}{HP^-_kH^T+R} Kk=HPk−HT+RPk−HT
K k ∈ [ 0 , H − 1 ] 我 们 可 以 知 道 , 当 R → ∞ 时 , K k = 0 , X ^ k = X ^ k − 当 R → 0 时 , K k = H − 1 , X ^ k = H − 1 Z k K_k\in[0,H^{-1}]\\我们可以知道,当R\to\infty时,K_k=0,\hat X_k=\hat X^-_k\\当R\to 0时,K_k=H^{-1},\hat X_k=H^{-1}Z_k Kk∈[0,H−1]我们可以知道,当R→∞时,Kk=0,X^k=X^k−当R→0时,Kk=H−1,X^k=H−1Zk
误差协方差矩阵 P k P_k Pk
我们现在已经得到卡尔曼滤波的三条公式,分别为:
先 验 估 计 值 X ^ k − = A X ^ k − 1 + B u k − 1 后 验 估 计 值 X ^ k = X ^ k − + K k ( Z k − H X ^ k − ) 卡 尔 曼 增 益 K k = P k − H T H P k − H T + R \begin{aligned} 先验估计值\hat X^-_{k}&=A\hat X_{k-1}+Bu_{k-1}\\ 后验估计值\hat X_k&=\hat X^-_k+K_k(Z_k-H\hat X^-_k)\\ 卡尔曼增益K_k&=\frac {P^-_kH^T}{HP^-_kH^T+R} \end{aligned} 先验估计值X^k−后验估计值X^k卡尔曼增益Kk=AX^k−1+Buk−1=X^k−+Kk(Zk−HX^k−)=HPk−HT+RPk−HT
可以发现其中还差一个 P k − P^-_k Pk−,这节我们就是来求这个。
先简化一下 e k − e^-_k ek−:
e k − = X k − X ^ k − = ( A X k − 1 + B u k − 1 + ω k − 1 ) − ( A X ^ k − 1 + B u k − 1 ) = A e k − 1 + ω k − 1 \begin{aligned} e^-_k&=X_k-\hat X^-_k\\ &=(AX_{k-1}+Bu_{k-1}+\omega_{k-1})-(A\hat X_{k-1}+Bu_{k-1})\\ &=Ae_{k-1}+\omega_{k-1} \end{aligned} ek−=Xk−X^k−=(AXk−1+Buk−1+ωk−1)−(AX^k−1+Buk−1)=Aek−1+ωk−1
所以:
P k − = E [ e k − e k − T ] = E [ ( A e k − 1 + ω k − 1 ) ( A e k − 1 + ω k − 1 ) T ] = E [ ( A e k − 1 + ω k − 1 ) ( e k − 1 T A T + ω k − 1 T ) ] = A E [ e k − 1 e k − 1 T ] A T + E [ ω k − 1 ω k − 1 T ] = A P k − 1 A T + Q \begin{aligned} P^-_k&=E[e^-_ke_k^{-T}]\\ &=E[(Ae_{k-1}+\omega_{k-1})(Ae_{k-1}+\omega_{k-1})^T]\\ &=E[(Ae_{k-1}+\omega_{k-1})(e^T_{k-1}A^T+\omega^T_{k-1})]\\ &=AE[e_{k-1}e_{k-1}^T]A^T+E[\omega_{k-1}\omega^T_{k-1}]\\ &=AP_{k-1}A^T+Q \end{aligned} Pk−=E[ek−ek−T]=E[(Aek−1+ωk−1)(Aek−1+ωk−1)T]=E[(Aek−1+ωk−1)(ek−1TAT+ωk−1T)]=AE[ek−1ek−1T]AT+E[ωk−1ωk−1T]=APk−1AT+Q
其中 P k − 1 P_{k-1} Pk−1可由之前的公式继续推得:
P k = P k − − K k H P k − − P k − H T K k T + K k H P k − H T K k T + K k R K k T = P k − − K k H P k − − P k − H T K k T + K k ( H P k − H T + R ) K k T = P k − − K k H P k − − P k − H T K k T + P k − H T H P k − H T + R ( H P k − H T + R ) K k T = P k − − K k H P k − = ( I − K k H ) P k − \begin{aligned} P_k&=P^-_k-K_kHP^-_k-P^-_kH^TK_k^T+K_kHP_k^-H^TK_k^T+K_kRK_k^T\\ &=P^-_k-K_kHP^-_k-P^-_kH^TK_k^T+K_k(HP_k^-H^T+R)K_k^T\\ &=P^-_k-K_kHP^-_k-P^-_kH^TK_k^T+\frac {P_k^-H^T}{HP_k^-H^T+R}(HP_k^-H^T+R)K_k^T\\ &=P^-_k-K_kHP^-_k\\ &=(I-K_kH)P^-_k \end{aligned} Pk=Pk−−KkHPk−−Pk−HTKkT+KkHPk−HTKkT+KkRKkT=Pk−−KkHPk−−Pk−HTKkT+Kk(HPk−HT+R)KkT=Pk−−KkHPk−−Pk−HTKkT+HPk−HT+RPk−HT(HPk−HT+R)KkT=Pk−−KkHPk−=(I−KkH)Pk−
到此所有的公式就都推导出来了。
卡尔曼滤波器使用说明
| 预测 | 校正 |
|---|---|
| 先验估计 X ^ k − = A X ^ k − 1 + B u k − 1 \hat X^-_{k}=A\hat X_{k-1}+Bu_{k-1} X^k−=AX^k−1+Buk−1 | 卡尔曼增益 K k = P k − H T H P k − H T + R K_k=\frac {P^-_kH^T}{HP^-_kH^T+R} Kk=HPk−HT+RPk−HT |
| 先验误差协方差 P k − = A P k − 1 A T + Q P^-_k=AP_{k-1}A^T+Q Pk−=APk−1AT+Q | 后验估计 X ^ k = X ^ k − + K k ( Z k − H X ^ k − ) \hat X_k=\hat X^-_k+K_k(Z_k-H\hat X^-_k) X^k=X^k−+Kk(Zk−HX^k−) |
| 更新误差协方差 P k = ( I − K k H ) P k − P_k=(I-K_kH)P^-_k Pk=(I−KkH)Pk− |
X ^ k − \hat X^-_k X^k−为状态先验估计值(即模型计算出来的,未进行数据融合的值)
X ^ k \hat X_k X^k为状态后验估计值(即进行数据融合优化过的值)
u k u_{k} uk为对系统输入的控制量
Z k Z_k Zk为测量值
A A A为状态矩阵, B B B为控制矩阵, H H H为测量矩阵
Q Q Q为过程噪声协方差矩阵
R R R为测量噪声协方差矩阵
P P P为误差协方差矩阵
其中, A , B , H A,B,H A,B,H与估计模型和测量方式有关,是不可变的,但可以确定。而 Q , R Q,R Q,R是噪声,不可确定,也不可变,只能大概判断给出。而剩下的都是可变的。
在卡尔曼滤波器的使用过程中,我们只需要确定的是后验估计 X ^ 1 \hat X_1 X^1和后验误差协方差 P 1 P_1 P1,然后整个模型会随着测量值 Z k Z_k Zk和控制量 u k u_{k} uk的输入来调整自身使其最佳。
s t e p 1 计 算 卡 尔 曼 系 数 K k = e E S T k − 1 e E S T k − 1 + e M E A k s t e p 2 计 算 估 计 值 X ^ k = X ^ k − 1 + K k × ( Z k − X ^ k − 1 ) s t e p 3 更 新 估 计 误 差 e E S T k = ( 1 − K k ) × e E S T k − 1 \begin{aligned} step1&\quad计算卡尔曼系数K_k=\frac{e_{EST_{k-1}}}{e_{EST_{k-1}}+e_{MEA_{k}}} \\step2&\quad计算估计值\hat{X}_k=\hat{X}_{k-1}+K_k \times (Z_{k}-\hat{X}_{k-1}) \\step3&\quad更新估计误差e_{EST_k}=(1-K_k)\times e_{EST_{k-1}} \end{aligned} step1step2step3计算卡尔曼系数Kk=eESTk−1+eMEAkeESTk−1计算估计值X^k=X^k−1+Kk×(Zk−X^k−1)更新估计误差eESTk=(1−Kk)×eESTk−1
大家也看出一阶卡尔曼就是它的简化,只有校正部分,但在调整参数上两者出现的反应差不多,大家可以自行调整测试看看。
扩展卡尔曼
我还不会,等我学会了有空就继续写。
智能推荐
LightOJ - 1067 Combinations(快速幂+逆元)_快速幂求逆元 在线oj-程序员宅基地
文章浏览阅读484次。DescriptionGiven n differentobjects, you want to take k of them. How many ways to can do it? For example, saythere are 4 items; you want to take 2 of them. So, you can do it 6 ways. Take 1, _快速幂求逆元 在线oj
Fairseq学习日记:注定麻烦的旅程_final_lr_scale-程序员宅基地
文章浏览阅读6.6k次,点赞10次,收藏23次。现在开头:Fairseq是一个正在快速迭代的产品,而且是开源的!这不是表扬,这意味着三件事情:1.他没有文档!所有框架代码都没有任何注释,包括函数docstring都没有2.他没有经过有效测试,估计是抢时间吧!即使是官网Readme里的例子也是无法跑起来的!3.他是一个框架,而且是一个非常不Pythonic的框架,充斥着inline/包装器/莫名其妙的语法。虽然这三点决定他真的对不住Facebook的金字招牌,但是作为一个学习者,总要把他运行起来,那么开始这场针对 FaceBOOK派“全_final_lr_scale
[Linux][Busybox]分享你不知道Top 命令参数_busybox top-程序员宅基地
文章浏览阅读5.1k次。目录摘要:基本操作与命令介绍:进入top后交互一点点新的操作Author: Keivn.Xu [email protected]摘要: 玩过Linux一定使用过busybox top命令,但下面的操作方法,你不一定有见过。基本操作与命令介绍:console:/ $ busybox top -help top: invalid optio..._busybox top
rssi参数获取_信号强度(RSSI)知识整理-程序员宅基地
文章浏览阅读1.6k次。为什么无线信号(RSSI)是负值答:其实归根到底为什么接收的无线信号是负值,这样子是不是容易理解多了。因为无线信号多为mW级别,所以对它进行了极化,转化为dBm而已,不表示信号是负的。1mW就是0dBm,小于1mW就是负数的dBm数。弄清信号强度的定义就行了:RSSI(接收信号强度)Received Signal Strength IndicatorRss=10logP,只需将接受到的信号功率P代..._c#获取低功耗设备的rssi信号强度
后端服务的雪崩效应及解决思路_接口超时时间过长导致雪崩效应-程序员宅基地
文章浏览阅读204次。1.RPC与本地调用的区别RPC远程调用,一般是跨平台、采用http协议,因为http协议底层使用socket技术,只要你的语言支持socket技术,就可以相互进行通讯。比如:java语言开发的接口,使用http协议,如此以来C#语言可以调用。本地调用:只支持java语言与java语言开发,使用虚拟机和虚拟机之间的通讯,RMI。2.雪崩效应产生的原因默认情况下只有一个线程池维护所有的服务接口,如果大量的请求访问同一个接口,达到tomcat线程池默认极限,可能会导致其他服务无法访问。3.雪_接口超时时间过长导致雪崩效应
linux操作redis_linux 连接redis-程序员宅基地
文章浏览阅读2.7w次,点赞4次,收藏35次。redis常用命令_linux 连接redis
随便推点
[BAT]Win7下可用于bat文件中的call调用-程序员宅基地
文章浏览阅读982次。全部已在本机验证,可能根据用户安装的系统功能不同而有些命令无效。设备管理器 hdwwiz.cpl 或devmgmt.msc添加或删除程序 appwiz.cpl管理工具 control admintoolsBluetooth文件传送向导 fsquirt计算器 calc证书管理控制台 certmgr.msc字符映..._window bat call 环境
计算机视觉——相机标定-程序员宅基地
文章浏览阅读1.1w次,点赞8次,收藏82次。相机标定_相机标定
js获取年月日 时分秒的日期格式_js 时分秒 时间格式-程序员宅基地
文章浏览阅读1.1k次。const date = new Date()const year = date.getFullYear()const month = date.getMonth() + 1 >= 10 ? date.getMonth() + 1 : `0${date.getMonth() + 1}`const day = date.getDate() >= 10 ? date.getDate() : `0${date.getDate()}`const hours = date.getHours() ._js 时分秒 时间格式
【模拟】Oracle重建索引_oracle 重建索引-程序员宅基地
文章浏览阅读2.2k次。摘要:简述重建索引的情况及重建索引_oracle 重建索引
keil迁移到cubeIDE_cubeide生成代码 keil打开-程序员宅基地
文章浏览阅读2.7k次。以stm32f105rct6为例子,keil迁移到cubeIDE_cubeide生成代码 keil打开
语音处理:Python实现dBFS刻度和采样值相互转换_dbfs 频域-程序员宅基地
文章浏览阅读781次。以对数域常用的dBFS刻度为例,支持主流音频信号位深:整型16/24/32位和浮点32位,编写Python实现对数域和采样值单位互换功能_dbfs 频域