【uCore实验Lab1】清华大学操作系统实验_操作系统实验lab1-程序员宅基地
技术标签: ubuntu
系列文章目录
文章目录
一、关于内联汇编
在c语言程序中加入汇编代码,包括基本内联汇编和拓展内联汇编。
- 基本内联汇编
例:
static incline void
sti(void)
{
asm volatile("sti");
}
static incline void
cli(void)
{
asm volatile("cli");
}
sti函数:打开终端,使CPU能响应外来终端;
cli函数:关闭终端。
- 扩展内联汇编
基本功能:把寄存器和变量做绑定(可进可出)
例1:
static inline void
outb(unit16_t port,unit8_t data)
{
asm volatile("outb %0,%1" :: "a"(data),"d"(port));
}
static inline void
outw(unit16_t port,unit16_t data)
{
asm volatile("outw %0,%1" :: "a"(data),"d"(port));
}
outb:输出一个字节的数据
把数据data传到端口port上,16、8分别表示16个字节和8个字节。
什么是端口?主机和IO设备的接口,对应设备上的寄存器(包括数据寄存器和状态寄存器),有对应端口号。
第一个冒号后:输出操作数(此处无,但该冒号不可省略);
第二个冒号后:输入操作数,“a”表示eax寄存器(指令中对应%0),括号中对应数据data,从而将data里的变量传到eax寄存器上;“d”表示edx寄存器(指令中对应%1),端口号为(port),指令outb将数据输出到对应的端口上。
第三个冒号后:乱码表
outw:输出两个字节(一个word)
例2
static inline unit8_t
inb(unit16_t port)
{
unit8_t data;
asm volatile ("inb %1, %0 : "=a"(data) : "d"(port));
return data;
}
inb:在某个IO设备端口上输入一个字节的数据
port为端口号,输入的数据放在data中
第一个冒号后:输出操作数"=a"(对应%0),表示eax寄存器,上面的数据放到data中被传出(注意前面要加等号)
第二个冒号后:输入操作数”d"(对应%1),表示edx寄存器,其中存放了端口号port
例3
asm("movl%0,%%eax;movl%1,%%ecx;call_foo" ::"r"(from),"r"(to):"eax""ecx");
第一个指令movl:把%0中的内容传到eax寄存器中去(从左传到右),从而eax被改变
第二个指令movl:把%1中的内容传到ecx寄存器中去,从而ecx被改变
第三个冒号乱码表的意义:告诉计算机eax、ecx这两个寄存器的内容被修改了
例4:
static inline void
insl(unit32_t port,void *addr,int cnt)
{
asm volatile ("cld;""repne;insl;"
:"=D"(addr),"=c"(cnt)
:"d"(port),"0"(addr),"1"(cnt)
:"memory","cc");
}
三个形式参数分别对应:port端口号、*addr数组名(存放读入的数据)、cnt指令重复次数
第一条指令"cld;“:把DF位设置为0,使每次操作后指针增加(正向传输)
第二条指令"repne;insl;”:repne表示循环读入数据,insl:从某个IO设备的端口上读一个long型(l)数据进来;
第一个冒号后:输出操作数:“=D”表示edi寄存器(大写,如果小写d对应的是edx),对应%0,结果输出到addr变量上;“=c”表示ecx,对应%1,结果输出到cnt变量上;
第二个冒号后:输入操作数:“d”表示edx,变量port端口号;“0”表示前面的%0,即"=D"edi寄存器,把数组首地址addr赋给它;“1”表示前面的%1,即"=c"ecx寄存器,把循环次数cnt放到上面;
第三个冒号后:乱码表:“memory”(内存)和“cc”(标志寄存器)可能有变化。
补充:什么是DF位和ZF位?
DF 位和 ZF 位通常是指 x86 架构中的标志寄存器(FLAGS Register)中的两个特定位。
DF 位:DF 是 Direction Flag 的缩写,它是标志寄存器中的一个标志位。当 DF 位为 0 时,串操作(比如字符串复制、移动等)默认向前增加地址;当 DF 位为 1 时,串操作则向后减小地址。程序员可以通过控制 DF 位来指定串操作的方向。
ZF 位:ZF 是 Zero Flag 的缩写,也是标志寄存器中的一个标志位。ZF 位用于指示最近的算术或逻辑运算结果是否为零。当运算结果为零时,ZF 位被置为 1;否则,ZF 位被清零。程序员经常通过检查 ZF 位来进行条件判断,比如判断两个数是否相等。
二、uCore结构布局以及启动过程
1.uCore结构布局
分为两块:bootloader(系统引导程序)和kernel(内核),放在硬盘镜像文件ucore.img下

2.启动过程
- 启动系统,BIOS调用bootloader进入内存;
- bootloader程序加载到TEXT段和DATA段;
- 把kernel程序ELF(可执行文件)的文件头header调入对应内存位置(10000-11000),从而找到可执行文件ELF的代码段和数据段;
- kernel程序加载到内存中的TEXT段、DATA段和BSS段中去(100000即1MB开始)
操作系统启动的过程可以分为以下几个简单易懂的步骤:
- 开机启动:当你按下计算机的电源按钮时,计算机开始启动。电源会向计算机的各个组件提供电能,使得计算机的硬件开始工作。
- BIOS自检:计算机的**基本输入/输出系统(BIOS)**会首先运行,进行自检(POST,Power-On Self-Test)。在自检过程中,BIOS会检查计算机的硬件设备是否正常,如内存、硬盘、键盘等。
- 引导加载程序:自检完成后,BIOS会尝试从硬盘或其他存储介质中**加载引导加载程序(Bootloader)**到内存中。引导加载程序是一个小型的程序,负责加载操作系统内核到内存中并启动执行。
- 加载内核:引导加载程序会读取存储介质上的操作系统内核文件(Kernel),将内核加载到内存中的适当位置。通常,内核文件位于硬盘的引导扇区或特定的分区中。
- 启动内核:一旦内核加载到内存中,引导加载程序会将控制权转交给内核,使得内核开始执行。内核初始化各种系统资源,如内存管理、中断控制、设备驱动等,并最终启动用户空间程序。
- 用户空间初始化:内核初始化完成后,它会启动用户空间程序,如系统服务、用户登录界面等。这标志着操作系统已经完全启动,可以开始响应用户的操作和请求。
总的来说,操作系统启动的过程就是从计算机的电源启动开始,经过自检、加载引导加载程序、加载内核、启动内核等步骤,最终完成操作系统的初始化并进入用户空间。
三、开启A20、进入保护模式
1.开启A20
- 什么是A20
A20 是一个内存地址线,可以用来寻址 1MB 以上的内存。在早期的 8086 和 80286 处理器中,由于历史原因,只有 20 根地址线被用来寻址内存,限制了系统只能寻址 1MB 的内存空间。为了解决这个问题,Intel 设计了一个地址线 A20,它允许处理器访问超过 1MB 的内存地址空间。通过控制 A20 地址线的状态,可以实现对额外的内存地址空间的访问。 - 如何开启A20
利用8042键盘控制器来开启
8042的2个端口:
0x64:命令、状态端口
0x60:数据端口
# Enable A20:
# For backwards compatibility with the earliest PCs, physical
# address line 20 is tied low, so that addresses higher than
# 1MB wrap around to zero by default. This code undoes this.
seta20.1:
inb $0x64, %al #从0x64端口读一个字节到al寄存器
testb $0x2, %al #testb指令:把两个操作按位与,从而al寄存器中的值只有1位保持不变,对应了键盘是否有空,如果1位是1表示键盘没空
jnz seta20.1 #如果不等于0就jump(jump no zero),即继续循环,直到键盘有空为止
movb $0xd1, %al # 0xd1是一个命令码,表示要把数据写到P2命令寄存器(0x64)上,把它放到al寄存器上
out %al,$0x64 # 通过out指令把al寄存器上的命令输出到0x64端口上
seta20.2:
inb $0x64, %al # Wait for not busy(8042 input buffer empty).
testb $0x2, %al
jnz seta20.2
movb $0xdf, %al # 0xdf -> port 0x60
outb %al, $0x60 # 0xdf = 11011111, means set P2's A20 bit(the 1 bit) to 1
为什么上面的movb和outb不能合成一条?
汇编语言中规定,指令中一个操作数必须是寄存器,从而保证每条指令足够快
这段代码的作用是通过8042键盘控制器来开启A20地址线。让我们逐行解释这段代码:
- seta20.1::
这是一个标签,用于指示程序执行到这里时的位置。 - inb $0x64, %al:
这条指令从0x64端口读取一个字节的数据到AL寄存器中。在x86架构中,0x64端口是用于与8042键盘控制器通信的端口。 - testb $0x2, %al:
这条指令执行一个按位与操作,将AL寄存器中的值与0x2进行按位与操作。这个操作的目的是检查AL寄存器中的第2位是否为1,即检查键盘控制器是否忙碌。如果键盘控制器忙碌,第2位会被设置为1。 - jnz seta20.1:
如果上述按位与操作的结果不为零(即键盘控制器忙碌),则跳转到标签seta20.1处,继续循环等待键盘控制器空闲。 - movb $0xd1, %al:
这条指令将0xd1值加载到AL寄存器中,0xd1是一个命令码,表示接下来要向8042键盘控制器发送一个数据。 - out %al,$0x64:
这条指令将AL寄存器中的数据发送到0x64端口,将命令码0xd1发送给8042键盘控制器,告诉它接下来要发送的数据是要写入P2命令寄存器的。 - seta20.2::
这是另一个标签,用于指示程序执行到这里时的位置。 - inb $0x64, %al:
这条指令从0x64端口读取一个字节的数据到AL寄存器中,用于等待8042键盘控制器的输入缓冲区变为空。 - testb $0x2, %al:
这条指令再次执行按位与操作,检查AL寄存器中的第2位是否为1,即检查键盘控制器是否忙碌。 - jnz seta20.2:
如果键盘控制器忙碌,则跳转到标签seta20.2处,继续等待键盘控制器空闲。 - movb $0xdf, %al:
这条指令将0xdf值加载到AL寄存器中,0xdf是用来设置P2端口的A20位(第20位)为1的数据。 - outb %al, $0x60:
这条指令将AL寄存器中的数据发送到0x60端口,向8042键盘控制器发送数据0xdf,表示设置P2端口的A20位为1,以启用A20地址线。
注:"$"表示立即数,否则表示地址
2.进入保护模式
从实模式进入保护模式:把控制寄存器CR0的0位设置成1
# Switch from real to protected mode, using a bootstrap GDT
# and segment translation that makes virtual addresses
# identical to physical addresses, so that the
# effective memory map does not change during the switch.
lgdt gdtdesc
movl %cr0, %eax
orl $CR0_PE_ON, %eax
movl %eax, %cr0
第一条movl指令:把cr0寄存器的值读到eax寄存器中
第二条orl指令:或运算,l表示都是32位的,把或的结果放在eax寄存器中,前面的$CR0_PE_ON表示立即数000……001,相当于把eax中的数(cr0)的0位 置为1
第三条movl指令:把0位已经被置为1的数据传回cr0控制寄存器中
最上面的lgdt gdtdesc指令:特权指令,在用户态无法执行,这条指令表示将当前正在运行的程序的段表的信息(起始地址和长度)放到专门的段表寄存器中。gdt:段表,用于将逻辑地址转换为物理地址。在使用分段式内存管理的系统中,内存被划分为若干个段(Segment),每个段用来存储不同类型的程序或数据。
这段代码用于在x86处理器上从实模式切换到保护模式。下面是代码的逐行解释:
- lgdt gdtdesc:
lgdt 是 Load Global Descriptor Table 的缩写,用于加载全局描述符表(GDT)。
gdtdesc 是一个包含 GDT 描述符的数据结构的地址。这里使用 lgdt 指令将 GDT 描述符加载到处理器的 GDTR(全局描述符表寄存器)中。 - movl %cr0, %eax:
这条指令将 CR0 寄存器的内容加载到 EAX 寄存器中。CR0 寄存器是 x86 处理器中的控制寄存器,用于控制处理器的运行模式和各种特性。 - orl $CR0_PE_ON, %eax:
这里使用逻辑或操作,将 CR0_PE_ON 常量与 EAX 寄存器中的值进行或操作。CR0_PE_ON 是一个掩码,用于将 CR0 寄存器的保护模式位(PE)设置为 1,表示启用保护模式。 - movl %eax, %cr0:
最后一条指令将修改后的值写回 CR0 寄存器,从而启用了保护模式。
四、实现分段机制
1.段选择子结构
段选择子是一个数字,共有16位,高的13位对应INDEX(要访问的段的段号),低的2位为RPL(Request Privilege Level请求特权级),第3位为TI
INDEX是在GDT数组或LDT数组的索引号,TI是Table Indicator,值为0表示查找GDT,值为1表示查找LDT,RPL表示请求特权级。
把段选择子设置在三个段寄存器上:DS(数据段寄存器),ES(附加数据段寄存器,低两位为RPL)、SS(堆栈段寄存器,放堆栈段的段号),CPL(当前特权级)存放在CS(代码段寄存器,低两位为CPL)上。
什么是特权级?
段的特权级(Privilege Level)是指操作系统在分段内存管理中用于控制对内存段访问权限的级别。它决定了进程或程序在访问某个段时所需的特权级别。在一些计算机体系结构中,特权级别通常被划分为不同的级别,最常见的是使用数字表示,如0、1、2、3等级。这些级别通常称为"特权级"或"权限环"。
一般来说,较低的特权级别拥有更高的权限,可以执行更多的操作,而较高的特权级别则受到更多的限制。特权级别通常涉及对内存、设备和指令的访问权限限制。
举个例子,在x86架构中,存在四个特权级别(也称为"保护环"),分别是Ring 0、Ring 1、Ring 2和Ring 3。Ring 0是最高特权级别,也称为内核模式,操作系统内核运行在该特权级别下,可以执行任何指令并具有对系统资源的完全访问权限。Ring 3是最低特权级别,也称为用户模式,应用程序通常在该特权级别下运行,受到操作系统的保护和限制。
什么是CPL、RPL、DPL?
CPL(Current Privilege Level):CPL表示当前正在执行的代码的特权级别。它由当前执行的代码段的选择子的特权级别字段指定。CPL用来限制代码的访问权限,操作系统会检查代码的CPL与要访问的段的DPL(Descriptor Privilege Level)进行比较,以确定是否允许访问该段。
RPL(Requested Privilege Level):RPL表示请求访问某个段时所需的特权级别。RPL由段选择子中的请求特权级别字段指定。当程序请求访问一个段时,通过设置RPL,可以降低或提高访问该段所需的特权级别。操作系统会检查RPL与段的DPL进行比较,以确定访问权限。
DPL(Descriptor Privilege Level):DPL是描述符(段描述符)中的特权级别字段。每个段描述符都包含一个DPL字段,用于指定该段的特权级别。DPL规定了对该段的访问权限,只有当前特权级别(CPL)小于等于段的DPL时,才允许访问该段。
进程访问一个段时,特权级应满足:EPL(有效特权级,取当前和请求中特权级低的那个)=max{CPL,RPL}<=DPL
CPL可以比RPL特权级高(数字小),也就是申请特权级可以比当前特权级低(安全考虑)
例1:
.set PROT_MODE_CSEG, 0x8 # kernel code segment selector
.code32 # Assemble for 32-bit mode
protcseg:
# 设置数据段寄存器和堆栈段寄存器的段选择子 Set up the protected-mode data segment registers
movw $PROT_MODE_DSEG, %ax # Our data segment selector
movw %ax, %ds # -> DS: Data Segment基础数据段
movw %ax, %es # -> ES: Extra Segment附加数据段
movw %ax, %fs # -> FS附加数据段
movw %ax, %gs # -> GS附加数据段
movw %ax, %ss # -> SS: Stack Segment堆栈段
PROT_MODE_CSEG是0x8,即0000000000001000,最低的两位是00,代表RPL,即希望以特权级0访问;前十三位是0……001,代表段号INDEX为1,低三位为0是GDT
# Set up the stack pointer and call into C. The stack region is from 0--start(0x7c00)
movl $0x0, %ebp
movl $start, %esp. #设置栈顶,指针esp指向栈顶
call bootmain
# If bootmain returns (it shouldn't), loop.
spin:
jmp spin
例2:
.set PROT_MODE_DSEG, 0x10 # kernel data segment selector
# Jump to next instruction, but in 32-bit code segment.
# Switches processor into 32-bit mode.
ljmp $PROT_MODE_CSEG, $protcseg #前一个参数PROT_MODE_CSEG是段选择子,protcseg是段内偏移
.code32 # Assemble for 32-bit mode
protcseg:
# Set up the protected-mode data segment registers
movw $PROT_MODE_DSEG, %ax # Our data segment selector
movw %ax, %ds # -> DS: Data Segment
movw %ax, %es # -> ES: Extra Segment
movw %ax, %fs # -> FS
movw %ax, %gs # -> GS
movw %ax, %ss # -> SS: Stack Segment
# Set up the stack pointer and call into C. The stack region is from 0--start(0x7c00)
movl $0x0, %ebp
movl $start, %esp
call bootmain
# If bootmain returns (it shouldn't), loop.
spin:
jmp spin
ljmp(long jump)从一个段跳到另一个段,为什么要跳转?前面是16位的代码,后面是32位的代码,无法顺序执行,需要长跳转指令
PROT_MODE_DSEG是段选择子,值为0x10,即0000000000010000,高的十三位为0……010即2号段,希望访问权限CPL是00
2.段描述符结构
段表:GDT全局描述符表(Global Descriptor Table)
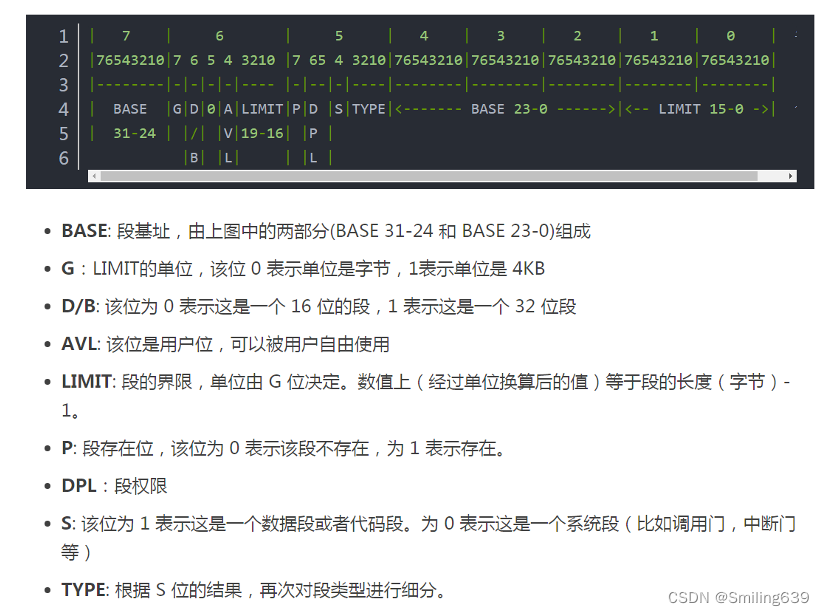
共8个字节(64位)
G为1时表示单位是页(大小是4KB),从而段长最长可达到2的32次方(4GB)
3.进程的内存布局
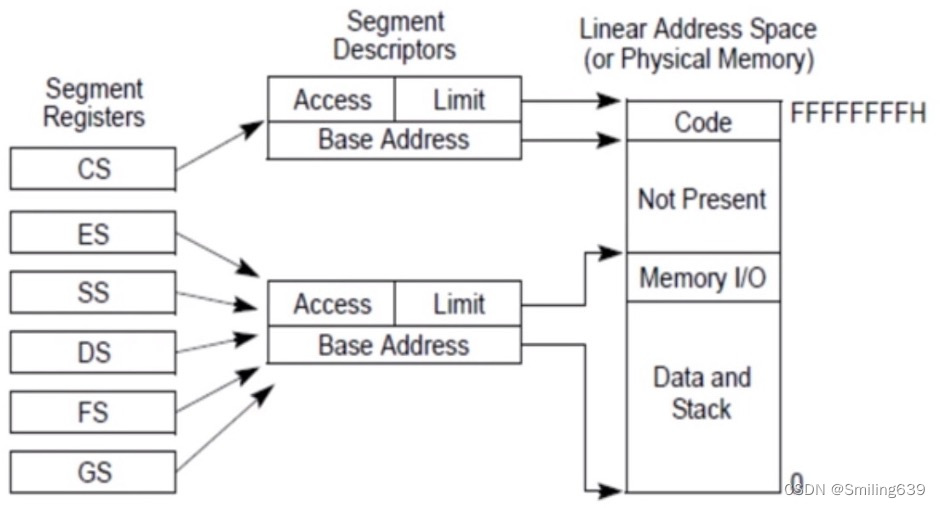
有若干数据段寄存器(上图最左一列中的ES、DS、FS、GS),可以分别指向不同的分段,根据这些数据段的高的13位(INDEX)可以找到段表的表象(即上面的段描述符结构),从而找到Base Address基址,段长Limit。
CS是代码段段寄存器,低两位对应程序当前特权级(CPL),高的十三位对应当前程序代码段的段号INDEX,同理也可以知道代码段的地址、长度等信息。
4.GDT的初始化
例:
# Bootstrap GDT
.p2align 2 # force 4 byte alignment
gdt:
SEG_NULLASM # null seg
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) # code seg for bootloader and kernel调用宏设置段表表象,STA_X|STA_R表示type,可写可读;0x0是起始地址base;0xffffffff是段长
SEG_ASM(STA_W, 0x0, 0xffffffff) # data seg for bootloader and kernel
gdtdesc:
.word 0x17 # sizeof(gdt) - 1
.long gdt # address gdt
此处SEG_ASM这个宏的定义如下:
#define SEG_ASM(type,base,lim)
.word(((lim) >> 12) & 0xffff),((base) & 0xffff);
.byte(((base) >> 16) & 0xff),(0x90|(type)),
lim右移12位,即除以2的12次方(单位是页面大小4KB),和0xffff(16个1)做与运算
让我们逐行解释这段代码的作用:
- .p2align 2:这个指令是为了将后面的内容按照4字节对齐。
- gdt::这是一个标签,用于指示GDT表的起始位置。
- SEG_NULLASM:这是一个宏,用于生成一个空的段描述符。在x86的GDT中,第一个段描述符通常被设置为一个空描述符,即不起作用的描述符。
- SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff):这是一个宏,用于生成一个代码段描述符。STA_X表示可执行(executable),STA_R表示可读(readable)。这个段描述符将整个32位地址空间的代码区域映射为可执行和可读。
- SEG_ASM(STA_W, 0x0, 0xffffffff):这是另一个宏,用于生成一个数据段描述符。STA_W表示可写(writable)。这个段描述符将整个32位地址空间的数据区域映射为可写。
- gdtdesc::这是一个标签,用于指示GDT描述符的起始位置。
- .word 0x17:这里指定了GDT的大小减1,0x17是GDT的大小(以字节为单位),即17个字节。因为在x86中,GDT的大小必须是16字节的倍数减1,所以这里是17。
- .long gdt:这里指定了GDT表的起始地址,gdt是之前定义的GDT的标签,这样CPU就能够找到GDT的位置。
五、加载uCore Kernel
此时文件系统还不存在,直接去读扇区,第一个扇区放bootloader,第二个扇区放uCore的操作系统(kernel的eif可执行文件),如何把kernel读到内存中,从而执行操作系统代码?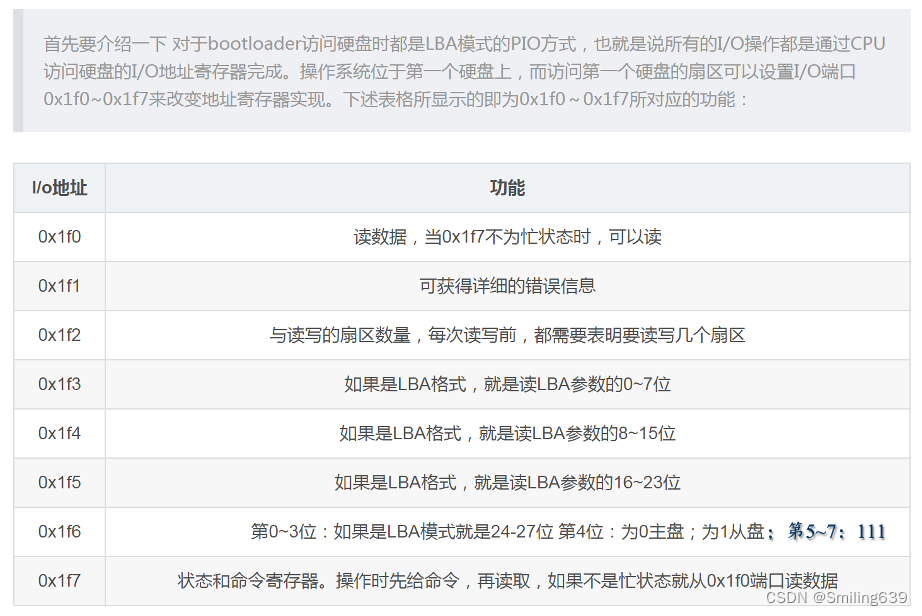
例:
/* waitdisk - wait for disk ready */
static void
waitdisk(void) {
while ((inb(0x1F7) & 0xC0) != 0x40)
/* do nothing */;
}
这段代码是一个等待磁盘准备就绪的函数。解释其功能和作用:
while ((inb(0x1F7) & 0xC0) != 0x40):这是一个while循环,其条件是检查端口0x1F7中的状态。inb()函数用于从指定端口读取一个字节的数据。0x1F7是一个I/O端口,用于与硬盘控制器进行通信。通过读取这个端口的值,我们可以了解磁盘的状态。
在这个表达式中,(inb(0x1F7) & 0xC0)会获取端口0x1F7的值,并与0xC0进行位与运算。这个运算的目的是提取出状态寄存器中的高两位,这两位包含了磁盘的状态信息。然后,这个结果与0x40进行比较,0x40表示磁盘准备就绪(最高的两位是01)的状态。
/* readsect - read a single sector at @secno into @dst */
static void
readsect(void *dst, uint32_t secno) {
// wait for disk to be ready
waitdisk();
outb(0x1F2, 1); // count = 1
outb(0x1F3, secno & 0xFF);
outb(0x1F4, (secno >> 8) & 0xFF);
outb(0x1F5, (secno >> 16) & 0xFF);
outb(0x1F6, ((secno >> 24) & 0xF) | 0xE0);
outb(0x1F7, 0x20); // cmd 0x20 - read sectors
// wait for disk to be ready
waitdisk();
// read a sector
insl(0x1F0, dst, SECTSIZE / 4);
}
这段代码是用于从磁盘读取一个扇区的函数。逐行解释其功能和作用:
- 两个参数分别是void *dst和uint32_t secno。
void *dst:这是一个指向内存地址的指针,用于存储从磁盘读取的数据。void *表示这是一个通用指针,可以指向任何类型的数据。在函数内部,这个指针会被用来接收从磁盘读取的数据。
uint32_t secno:这是一个uint32_t类型的整数,表示要读取的扇区号。磁盘上的数据被分割成扇区,每个扇区通常是512字节。secno用来指定要读取的扇区在磁盘上的位置。 - waitdisk():这是一个函数调用,用于等待磁盘准备好。在读取或写入磁盘之前,通常需要等待磁盘准备好。
- outb(port, value):这是一个输出一个字节到指定端口的函数。在这段代码中,使用了多次outb()函数来向磁盘控制器发送命令和参数。
0x1F2:向端口0x1F2写入值1,指定要读取的扇区数目,这里是1个扇区。
0x1F3、0x1F4、0x1F5:向这三个端口分别写入扇区号,使用了位掩码来提取32位扇区号的各个字节。
0x1F6:这里设置磁盘头寻址(head addressing),secno的高4位与0xE0进行或运算,表示磁盘号和头号,并设置最高位为1,表明要从硬盘读取数据。
0x1F7:向端口0x1F7写入0x20,这是读取扇区的命令。 - waitdisk():再次调用这个函数等待磁盘准备好。
- insl(port, dst, cnt):这是一个从端口读取多个字节到内存的函数。在这里,它从端口0x1F0开始读取数据,并将其存储到dst指向的内存地址中。参数cnt表示要读取的字节数,这里是SECTSIZE / 4,即一个扇区的大小除以4,因为insl()函数每次读取4字节。
接下来从操作系统中读kernel程序:
/* *
* readseg - read @count bytes at @offset from kernel into virtual address @va,
* might copy more than asked.
* */
static void
readseg(uintptr_t va, uint32_t count, uint32_t offset) {
uintptr_t end_va = va + count;
// round down to sector boundary
va -= offset % SECTSIZE;
// translate from bytes to sectors; kernel starts at sector 1
uint32_t secno = (offset / SECTSIZE) + 1;
// If this is too slow, we could read lots of sectors at a time.
// We'd write more to memory than asked, but it doesn't matter --
// we load in increasing order.
for (; va < end_va; va += SECTSIZE, secno ++) {
readsect((void *)va, secno);
}
}
这段代码中的函数readseg()有三个参数,分别是:
- uintptr_t va:这是一个无符号整数类型的指针,表示要将数据读取到的目标虚拟地址。在函数内部,数据将从内核中读取并复制到这个地址指向的内存位置。
- uint32_t count:这是一个无符号整数类型,表示要读取的字节数。函数将会尝试从内核中读取这么多字节的数据。
- uint32_t offset:这是一个无符号整数类型,表示从内核的哪个偏移量开始读取数据。偏移量指的是数据在内核文件中的位置,以字节为单位。这个偏移量通常是相对于整个内核文件的起始位置的,而不是指向具体的某个数据结构或函数。
这段代码的作用是从内核中读取指定数量的字节到虚拟地址空间中的指定位置。逐行解释其功能和作用:
- uintptr_t end_va = va + count;:计算读取数据的结束地址,即目标地址va加上要读取的字节数count。
- va -= offset % SECTSIZE;:将目标地址va向下舍入到扇区边界。这是因为磁盘操作必须以扇区为单位,所以需要确保读取的起始地址是扇区的起始位置。
- uint32_t secno = (offset / SECTSIZE) + 1;:计算要读取的起始扇区号。偏移量offset除以扇区大小SECTSIZE得到的结果再加1,是因为内核的起始扇区通常是1,而不是0。
- for (; va < end_va; va += SECTSIZE, secno ++) { readsect((void *)va, secno); }:循环读取数据。从起始地址va开始,每次增加一个扇区的大小SECTSIZE,直到达到读取的结束地址end_va为止。在每次循环中,调用readsect()函数来读取一个扇区的数据,并将其存储到虚拟地址空间中的指定位置。
注意:虽然循环可能会读取比请求的更多数据(因为是以扇区为单位读取的),但是因为数据是按顺序加载的,所以多读取的部分不会影响程序的执行。
ELF(Executable and Linkable Format)是一种常见的可执行文件格式,用于存储可执行程序、共享库和核心转储文件。elfhdr是一个可能在操作系统内核中出现的数据结构,用于表示ELF文件头部(ELF Header)的内容。
ELF文件头部是一个重要的数据结构,它位于ELF文件的开头,并包含了关于文件本身的重要信息,例如文件类型、目标体系结构、入口点地址等等。在加载和执行程序时,操作系统需要解析ELF文件头部,以了解如何正确地加载和执行该程序。
在典型的操作系统内核中,elfhdr通常用于表示ELF文件头部(ELF Header),其中包含了关于ELF文件的重要信息。以下是elfhdr结构中可能包括的一些参数信息:
- ELF文件标识(ELF Identification):包括ELF魔数和文件类别等信息,用于识别文件是否为有效的ELF文件。
- ELF文件类型(ELF Type):描述文件的类型,如可执行文件、共享对象、目标文件等。
- 目标体系结构(Target Architecture):描述编译目标的体系结构,如x86、ARM等。
- 入口点地址(Entry Point Address):指示程序的入口点,即程序开始执行的地址。
- 程序头表的偏移和数量(Program Header Table Offset and Entry Count):指示程序头表在文件中的偏移量和包含的条目数量。
- 节头表的偏移和数量(Section Header Table Offset and Entry Count):指示节头表在文件中的偏移量和包含的条目数量。
- 文件版本号(File Version):描述ELF文件格式的版本号。
- 程序头表条目大小(Program Header Table Entry Size):每个程序头表条目的大小。
- 节头表条目大小(Section Header Table Entry Size):每个节头表条目的大小。
- ELF标志(ELF Flags):描述ELF文件的一些特性或属性。
- ELF头部大小(ELF Header Size):ELF头部的大小,以字节为单位。
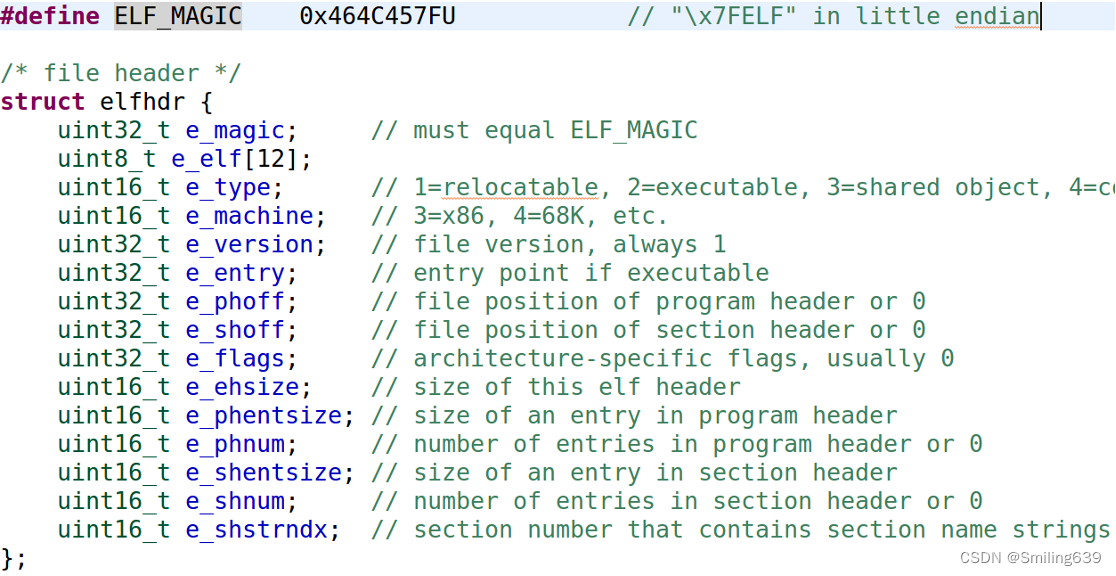
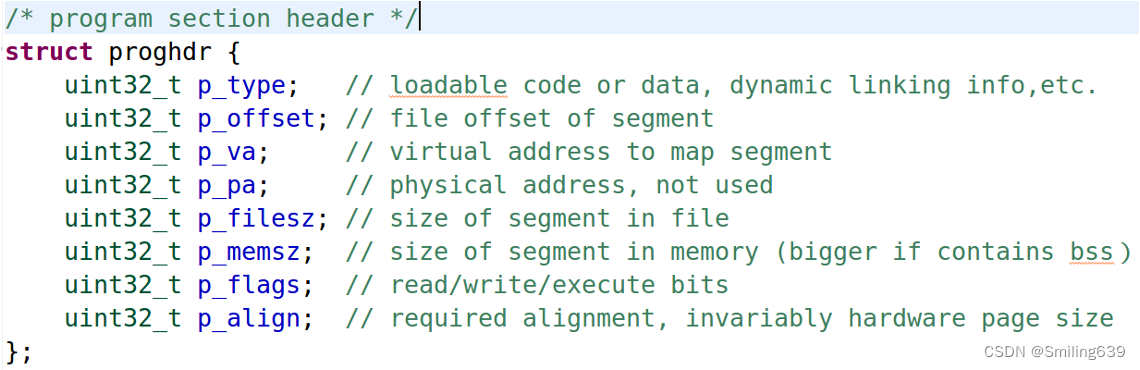
proghdr通常指的是ELF文件中的程序头表(Program Header Table),它是ELF格式的一部分,用于描述可执行文件或共享库中的各个段(segment)。段是内存映像中的连续区域,包含可执行代码、数据、只读数据、动态链接信息等。
在典型的操作系统内核中,proghdr这个数据结构通常包括描述程序头表中每个条目的参数信息。这些信息可能包括但不限于:
- 段类型(Segment Type):描述段的类型,如可加载段、动态链接信息段、Note段等。
- 段在文件中的偏移(File Offset):指示段在可执行文件中的偏移量。
- 段在内存中的虚拟地址(Virtual Address):指示段在内存中的虚拟地址,即加载到内存时的起始地址。
- 段在文件中的大小(File Size):指示段在可执行文件中的大小,以字节为单位。
- 段在内存中的大小(Memory Size):指示段在内存中的大小,以字节为单位。这可能会与文件大小不同,因为在加载时可能需要对段进行对齐或填充。
- 段的标志(Flags):描述段的属性,如读、写、执行等。
- 段在文件中的对齐(File Alignment):指示段在文件中的对齐方式。
- 段在内存中的对齐(Memory Alignment):指示段在内存中的对齐方式。
unsigned int SECTSIZE = 512 ;
struct elfhdr * ELFHDR = ((struct elfhdr *)0x10000) ; // scratch space
/* bootmain - the entry of bootloader */
void
bootmain(void) {
// read the 1st page off disk
readseg((uintptr_t)ELFHDR, SECTSIZE * 8, 0);
// is this a valid ELF?
if (ELFHDR->e_magic != ELF_MAGIC) {
goto bad;
}
struct proghdr *ph, *eph;
// load each program segment (ignores ph flags)
ph = (struct proghdr *)((uintptr_t)ELFHDR + ELFHDR->e_phoff);
eph = ph + ELFHDR->e_phnum;
for (; ph < eph; ph ++) {
readseg(ph->p_va & 0xFFFFFF, ph->p_memsz, ph->p_offset);
}
// call the entry point from the ELF header
// note: does not return
((void (*)(void))(ELFHDR->e_entry & 0xFFFFFF))();
bad:
outw(0x8A00, 0x8A00);
outw(0x8A00, 0x8E00);
/* do nothing */
while (1);
}
这段代码是一个引导加载程序(bootloader)的入口函数bootmain(),它负责从磁盘读取操作系统内核并将其加载到内存中运行。逐行解释其功能和作用:
readseg((uintptr_t)ELFHDR, SECTSIZE * 8, 0);:调用readseg()函数,从磁盘读取前8个扇区的内容到内存中,起始地址为ELFHDR指向的位置。这个位置通常用于存储操作系统内核的ELF头部(ELF Header)信息。if (ELFHDR->e_magic != ELF_MAGIC) { goto bad; }:检查读取的ELF头部是否合法。e_magic是ELF头部中的一个字段,用于标识ELF文件的魔数,ELF_MAGIC是一个预定义的常量,用于表示合法的ELF文件。如果读取的ELF头部中的魔数与ELF_MAGIC不匹配,就跳转到标签bad处。struct proghdr *ph, *eph;:定义指向程序头表条目的指针ph和eph。ph = (struct proghdr *)((uintptr_t)ELFHDR + ELFHDR->e_phoff);:计算程序头表的起始地址,根据ELF头部中的偏移量e_phoff,将其指向ELF头部后的位置。eph = ph + ELFHDR->e_phnum;:计算程序头表的结束地址,根据ELF头部中的程序头表条目数量e_phnum,将其指向程序头表的末尾。for (; ph < eph; ph ++) { readseg(ph->p_va & 0xFFFFFF, ph->p_memsz, ph->p_offset); }:循环遍历每个程序头表条目,调用readseg()函数加载每个段到内存中。p_va是段在内存中的虚拟地址,p_memsz是段在内存中的大小,p_offset是段在文件中的偏移量。((void (*)(void))(ELFHDR->e_entry & 0xFFFFFF))();:调用操作系统内核的入口点函数,这个函数指针保存在ELF头部的字段e_entry中。通过位掩码& 0xFFFFFF提取函数地址,并将其转换为函数指针类型后执行。bad::跳转到的标签,如果ELF文件不合法,则执行相应的错误处理操作。outw(0x8A00, 0x8A00); outw(0x8A00, 0x8E00);:执行一些简单的I/O操作,可能是用于指示加载错误或其他状态。while (1);:无限循环,程序在此处停止执行。
综上所述,这段代码的主要功能是加载ELF格式的操作系统内核并将其运行,同时进行了一些错误处理和状态指示操作。
六、实现中断机制
中断机制包括外中断和内中断。
外中断:外部设备向CPU发出中断请求(比如计时器倒计时结束、敲击一下键盘暂停等
每个中断都对应一个中断号,对于外中断,是从32开始的,时钟中断32+0,键盘中断32+1,CPU根据中断号来调用对应的中断服务程序。
如何根据中断号找到对应的中断服务程序?
通过中断描述符表IDT(一个数组)。
中断描述符表(Interrupt Descriptor Table,IDT)是在x86体系结构中用于处理中断和异常的重要数据结构之一。它是操作系统内核中的一部分,用于将不同类型的中断或异常映射到相应的处理程序。每个中断或异常都由一个唯一的编号(称为中断向量或异常向量)来表示,在IDT中,每个向量都有一个对应的条目。这些条目包含了指向处理程序的地址,以及处理程序的特权级别和一些其他的标志位。
以中断号作为INDEX,找到中断描述符表中对应的中断描述符,知道中断服务程序对应的段选择子。
内中断:系统功能调用(比如int 0x80,可以产生0x80这个中断),同样去找中断描述符表。
异常:比如除以0,对应的中断号就是0,也要去查相应的中断描述符表。
IDTR指的是中断描述符表寄存器(Interrupt Descriptor Table Register)。在x86架构中,IDTR是一个专门的CPU寄存器,用于存储中断描述符表(IDT)的基地址和界限。
IDTR是一个48位的寄存器,它包含了一个64位的基地址和一个16位的界限。基地址指向IDT的起始位置,而界限指定了IDT的大小。当发生中断或异常时,CPU会根据IDTR中存储的信息来访问IDT,并从中获取相应的中断处理程序的地址。
操作系统在初始化时会配置IDTR,将IDT的基地址和界限加载到IDTR中,以便CPU能够正确地响应和处理中断或异常。
1. 中断描述符表的结构
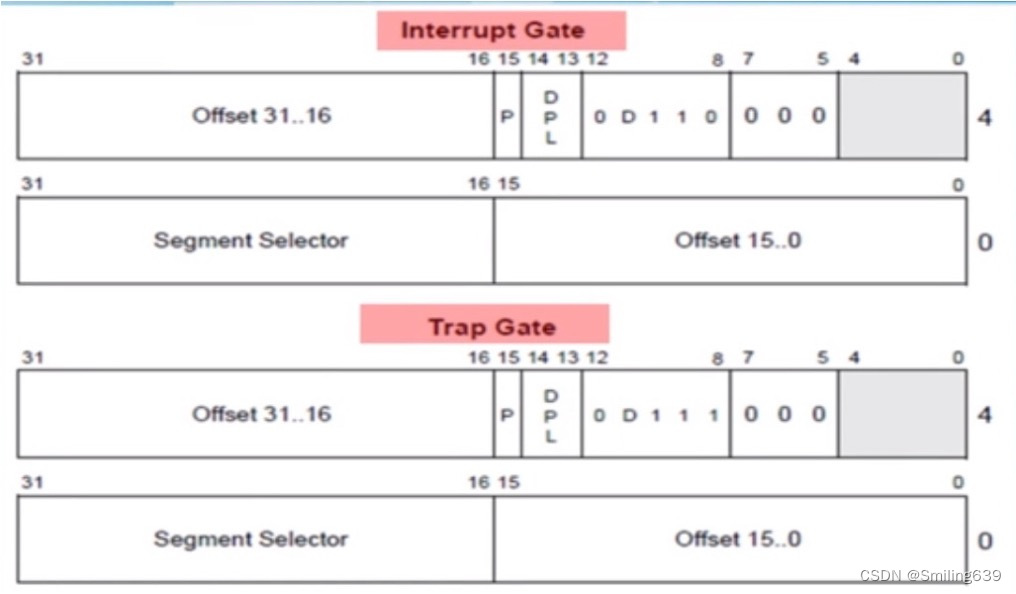
中断描述符表(Interrupt Descriptor Table,IDT)是x86架构中用于处理中断和异常的重要数据结构之一。IDT的结构如下:
(1)IDT条目(中断门Interrupt Gate或异常门Exception Gate或陷阱门Trap Gate):
每个IDT条目对应一个中断向量或异常向量,用于存储与该向量相关联的处理程序的信息。每个IDT条目包含以下字段:
·偏移地址(Offset):指向中断处理程序的地址,总共32位:0~15,16~31。
·段选择子(Segment Selector):指定中断处理程序所在的段。
·类型和属性(Type and Attributes):包括门类型、特权级别和其他控制标志。其中,P表示中断服务程序对应分段是(1)否(0)已经载入内存;DPL表示访问中断服务程序要求的特权级(一般情况下是3,这样用户程序也能调用中断服务程序)
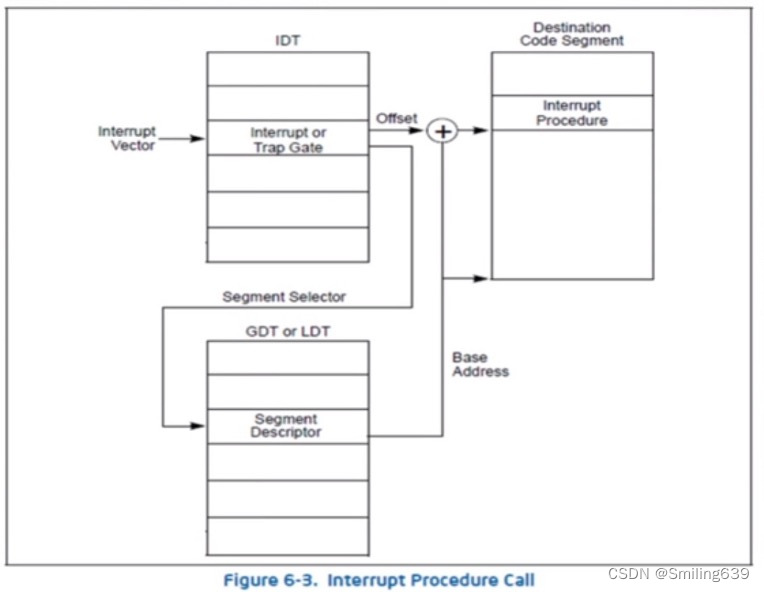
如果有一个时钟,定时时间到了,会产生一个时钟中断,对应的中断号是32,如何找到它对应的中断服务程序?
(1)查IDT,以32作为INDEX找到对应的中断描述符(即中断门);
(2)中断门里有一个段选择子(Segment Selector),根据这个段选择子的高13位index,就可以知道段号(中断服务程序在哪个段中);
(3)根据段号查GDT(段表),就可以找到分段相关信息,其中包括分段起始地址(Base Address),和中断门里的段内偏移(Offset)加在一起就可以知道对应的中断服务程序。
中断处理有两种情况:没有发生特权级变化和发生特权级变化。
中断服务程序一定是特权级0,如果程序本身就是特权级0,那么它调用中断服务程序时特权级没有变化。
没有发生特权级变化的情况下,进入中断时,硬件会自动保存:
(1)EFLAGS:标志寄存器,有很多位,包括ZF位(前面计算结果是不是0)、CF位(前面计算有没有进位)
(2)CS和EIP:当前程序的指针,CS寄存器存储了当前正在执行的代码所在的段的段选择子,段选择子包含了代码段的基地址和权限信息。EIP寄存器存储了CPU正在执行的指令的线性地址的偏移量。通过结合CS和EIP,CPU可以确定下一条要执行的指令在内存中的准确位置。在执行完一条指令后,EIP会自动递增,以指向下一条要执行的指令的地址。
程序会自动保存:
(3)Error Code:当发生某些中断或异常时,CPU会将错误码存储在相应的寄存器中,以提供有关事件更多的上下文信息,帮助操作系统或软件进行更精细的错误处理。
发生了特权级变化的情况下:
用户态堆栈和内核态堆栈不在一起,进入内核态后会进入内核态堆栈,这其中比上述情况多了:
(1)SS:SS寄存器(Stack Segment Register)是x86架构中的一个特殊寄存器,用于存储当前堆栈段的段选择子。在实模式下,SS寄存器存储的是堆栈段的段地址,而在保护模式下,SS寄存器存储的是堆栈段在GDT(Global Descriptor Table)或LDT(Local Descriptor Table)中的段选择子。
(2)ESP:ESP(Extended Stack Pointer)是x86架构中的一个特殊寄存器,用于存储当前堆栈的栈顶指针。栈顶指针指示了堆栈中下一个要被使用的位置,即最近压入堆栈的数据所在的位置。
由于不是同一个堆栈,所以中断服务程序会首先把当前程序(用户态)的堆栈段起始地址(SS)和偏移(ESP)保存在内核态堆栈中。
2.代码实现中断机制
- 建立中断向量表
(1)代码段
# handler
.text #代码段
.globl __alltraps
.globl vector0
vector0: #中断0的offset地址
pushl $0 #把errorcode(0表示没有错误)放入堆栈
pushl $0 #把中断号放入堆栈
jmp __alltraps #跳转到中断服务程序(入口地址)
.globl vector1
vector1:
pushl $0
pushl $1
jmp __alltraps
.globl vector2
vector2:
pushl $0
pushl $2
jmp __alltraps
(2)数据段
# vector table
.data #数据段
.globl __vectors
__vectors: #中断向量表
.long vector0 #中断0的起始地址
.long vector1 #中断1的起始地址
.long vector2
.long vector3
.long vector4
.long vector5
.long vector6
(3)定义中断描述符
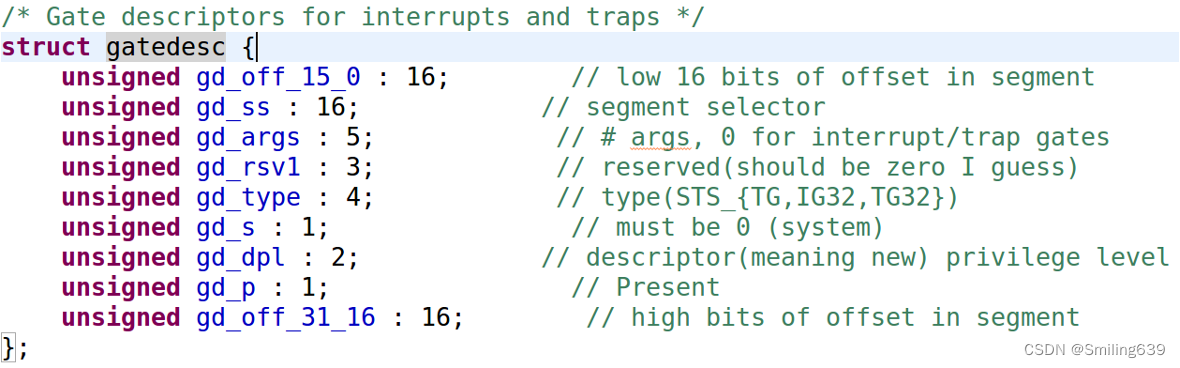
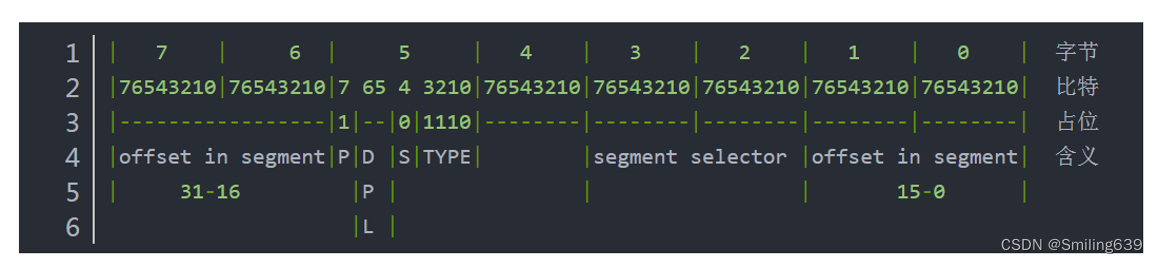
(4)定义kernel的段
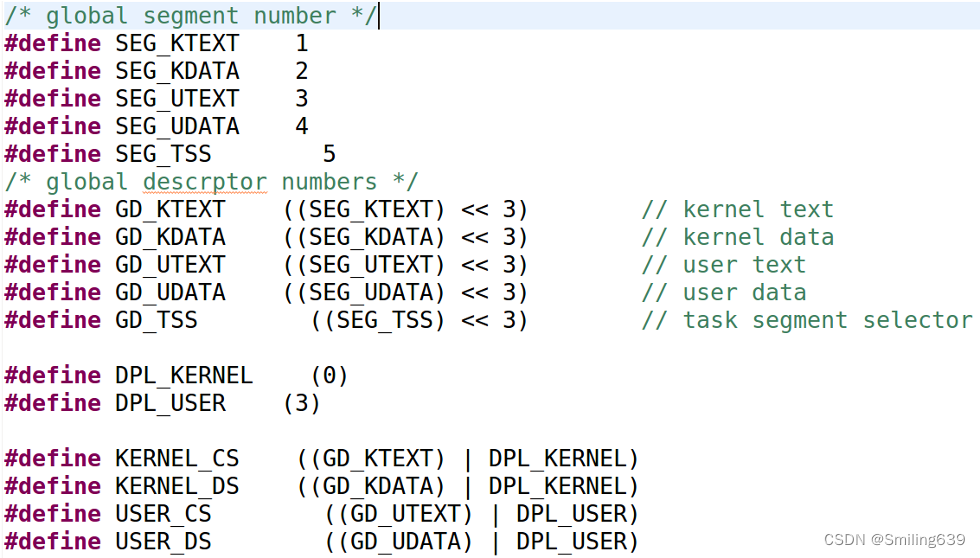
段SEG_xxx:一共5个段,1号段:内核态程序段;2号段:内核态数据段;3号段:用户态程序段;4号段:用户态数据段
最后一部分内容表示段选择子:段左移3位后加上DPL(特权级)。
(5)定义宏(用来设置段描述符)

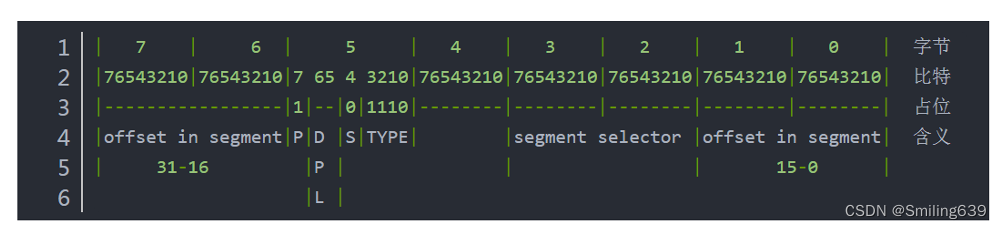
(6)设置中断向量表
static struct gatedesc idt[256] = {
{
0}};
static struct pseudodesc idt_pd = {
sizeof(idt) - 1, (uintptr_t)idt
};
/* idt_init - initialize IDT to each of the entry points in kern/trap/vectors.S */
void
idt_init(void) {
extern uintptr_t __vectors[];
int i;
for (i = 0; i < sizeof(idt) / sizeof(struct gatedesc); i ++) {
SETGATE(idt[i], 0, GD_KTEXT, __vectors[i], DPL_KERNEL);
}
// set for switch from user to kernel
SETGATE(idt[T_SWITCH_TOK], 0, GD_KTEXT, __vectors[T_SWITCH_TOK], DPL_USER);
// load the IDT
lidt(&idt_pd);
}
这段代码是用于初始化中断描述符表(Interrupt Descriptor Table, IDT)的。一步步分析:
- static struct gatedesc idt[256] = {
{0}};:
这行代码定义了一个包含256个gatedesc结构体的数组idt,并将所有元素初始化为0。在C语言中,这种初始化方法会将数组中的所有元素都初始化为0。gatedesc结构体用于描述中断门或陷阱门的信息。 - static struct pseudodesc idt_pd = { sizeof(idt) - 1, (uintptr_t)idt };:
这行代码定义了一个伪描述符(pseudodesc)idt_pd,用于加载IDT。idt_pd结构体中包含了IDT的大小(减去1,因为索引从0开始)和IDT的起始地址。uintptr_t是一个无符号整数类型,用于保存指针的地址。 - void idt_init(void) {:
这是一个函数idt_init的定义,用于初始化IDT。 - extern uintptr_t __vectors[];:
这行代码声明了一个外部变量__vectors[],该变量在其他地方定义。这个变量应该是一个指向中断处理函数的数组。 - int i; for (i = 0; i < sizeof(idt) / sizeof(struct gatedesc); i ++) {:
这是一个循环,用于遍历IDT数组。循环从0开始,直到IDT的大小除以struct gatedesc结构体的大小为止(有多少个表目),即遍历整个IDT。 - SETGATE(idt[i], 0, GD_KTEXT, __vectors[i], DPL_KERNEL);:
这行代码使用宏SETGATE来设置IDT的条目。这个宏应该会填充idt[i]这个中断门描述符。GD_KTEXT表示这是内核代码段的中断门,__vectors[i]是对应的中断处理函数的地址,DPL_KERNEL表示特权级为内核级别。 - SETGATE(idt[T_SWITCH_TOK], 0, GD_KTEXT, __vectors[T_SWITCH_TOK], DPL_USER);:
这行代码设置了一个特殊的中断门,用于从用户态切换到内核态。T_SWITCH_TOK应该是一个常量,表示切换到内核态的中断向量的索引。它也被设置为内核代码段的中断门,但是特权级被设置为用户级别(DPL_USER),这样用户程序就可以通过这个中断门切换到内核态。 - lidt(&idt_pd);:
最后一行代码调用了lidt函数,将IDT加载到处理器中。idt_pd结构体作为参数传递给了lidt函数,告诉处理器IDT的位置和大小。
总的来说,这段代码初始化了一个包含256个中断门描述符的IDT,然后为每个中断门设置了相应的中断处理函数的地址。最后,它还设置了一个特殊的中断门,用于在用户态和内核态之间切换。
(7)中断处理程序入口
# vectors.S sends all traps here.
.text
.globl __alltraps
__alltraps:
# push registers to build a trap frame
# therefore make the stack look like a struct trapframe
pushl %ds
pushl %es
pushl %fs
pushl %gs
pushal
# load GD_KDATA into %ds and %es to set up data segments for kernel
movl $GD_KDATA, %eax
movw %ax, %ds
movw %ax, %es
# push %esp to pass a pointer to the trapframe as an argument to trap()
pushl %esp
# call trap(tf), where tf=%esp
call trap
这段代码是一个中断处理程序,用于处理发生的所有异常和中断。下面是代码的逐行分析:
- .text:
这是一个汇编语言的指令,指定接下来的指令要放在代码段中。 - .globl __alltraps:
这行代码声明了__alltraps为一个全局标签,使得它可以在其他文件中使用。 - __alltraps::
这是一个标签,标记了一个代码段的起始位置。 - pushl %ds、pushl %es、pushl %fs、pushl %gs、pushal:
这些指令将各个段寄存器的值以及所有通用寄存器的值保存到堆栈中。这是为了建立一个“中断帧”(interrupt frame),用于保存中断发生时的处理器状态。 - movl $GD_KDATA, %eax:
这行代码将内核数据段描述符的地址加载到%eax寄存器中。 - movw %ax, %ds、movw %ax, %es:
这两行代码将%eax寄存器中的值(内核数据段描述符地址)写入%ds和%es段寄存器,用于设置内核数据段。 - pushl %esp:
这行代码将当前栈指针的值(即指向中断帧的指针)压入堆栈。这将作为参数传递给trap()函数,以便在处理中断时可以访问中断帧的内容。 - call trap:
这行代码调用了一个C语言函数trap(),并传递了指向中断帧的指针作为参数。trap()函数的作用是处理中断。由于这是汇编代码,trap()函数的实现应该在其他地方定义。
总的来说,这段汇编代码的作用是建立一个中断帧,设置内核数据段,并调用一个C语言函数trap()来处理中断。
void
trap(struct trapframe *tf) {
// dispatch based on what type of trap occurred
trap_dispatch(tf);
}
trap函数里的形式参数就是指向堆栈栈顶的指针,根据指针就可以找到堆栈。
七、uCore Kernel总体程序分析
void
kern_init(void){
extern char edata[], end[];
memset(edata, 0, end - edata);
cons_init(); // init the console
const char *message = "(THU.CST) os is loading ...";
cprintf("%s\n\n", message);
print_kerninfo();
grade_backtrace();
pmm_init(); // init physical memory management
pic_init(); // init interrupt controller
idt_init(); // init interrupt descriptor table
clock_init(); // init clock interrupt
intr_enable(); // enable irq interrupt
//LAB1: CAHLLENGE 1 If you try to do it, uncomment lab1_switch_test()
// user/kernel mode switch test
lab1_switch_test();
/* do nothing */
while (1);
}
这段代码是操作系统内核的初始化函数kern_init()。让我们逐行分析:
- extern char edata[], end[];:
这行代码声明了两个外部变量edata和end,它们应该是链接器在编译时定义的符号,用于表示内核代码段的结束位置和数据段的起始位置。 - memset(edata, 0, end - edata);:
这行代码使用memset函数将内核数据段中的内容清零,确保所有数据的初始状态为0。这是因为edata到end之间的内存是内核的数据段。 - cons_init();:
这行代码调用了一个函数cons_init(),用于初始化控制台。这个函数可能会设置控制台所需的硬件设备以及初始化相关的数据结构。 - const char *message = “(THU.CST) os is loading …”;:
这行代码定义了一个常量字符串message,用于存储加载操作系统时显示的消息。 - cprintf(“%s\n\n”, message);:
这行代码使用cprintf函数在控制台上输出message中的内容,显示加载操作系统的消息。 - print_kerninfo();:
这行代码调用了一个函数print_kerninfo(),用于打印内核信息。这个函数可能会打印内核版本、编译时间等信息。 - grade_backtrace();:
这行代码调用了一个函数grade_backtrace(),可能用于打印函数调用栈的信息。这在调试时可能会很有用。 - pmm_init();:
这行代码调用了一个函数pmm_init(),用于初始化物理内存管理。这个函数可能会初始化页表、空闲物理页面管理等。 - pic_init();:
这行代码调用了一个函数pic_init(),用于初始化中断控制器。这个函数可能会设置中断相关的硬件设备以及初始化中断处理相关的数据结构。 - idt_init();:
这行代码调用了一个函数idt_init(),用于初始化中断描述符表(IDT)。这个函数可能会为处理器设置中断处理函数和中断向量等。 - clock_init();:
这行代码调用了一个函数clock_init(),用于初始化时钟中断。这个函数可能会设置时钟中断的相关硬件设备,并初始化时钟中断处理相关的数据结构。 - intr_enable();:
这行代码调用了一个函数intr_enable(),用于使能中断。这个函数可能会设置处理器使能中断的寄存器位。 - lab1_switch_test();:
这行代码调用了一个函数lab1_switch_test(),它可能是一个实验性质的函数,用于测试用户态和内核态之间的切换功能。 - while (1);:
这是一个无限循环,意味着一旦初始化完成,系统将会停留在这里,等待进一步的操作。
总的来说,这段代码完成了一系列操作系统内核的初始化工作,包括控制台初始化、打印系统信息、物理内存管理初始化、中断初始化等。最后,它通过一个无限循环来保持系统处于运行状态。
智能推荐
PCL_Tutorial2-1.7-点云保存PNG_pcl::io:savepng-程序员宅基地
文章浏览阅读4.4k次。1.7-savingPNG介绍代码详情函数详解savePNGFile()源码savePNGFile()源码提示savePNGFile()推荐用法处理结果代码链接介绍PCL提供了将点云的值保存到PNG图像文件的可能性。这只能用有有序的云来完成,因为结果图像的行和列将与云中的行和列完全对应。例如,如果您从类似Kinect或Xtion的传感器中获取了点云,则可以使用它来检索与该云匹配的640x480 RGB图像。代码详情#include <pcl / io / pcd_io.h>#incl_pcl::io:savepng
知乎问答:程序员在咖啡店编程,喝什么咖啡容易吸引妹纸?-程序员宅基地
文章浏览阅读936次。吸引妹子的关键点不在于喝什么咖啡,主要在于竖立哪种男性人设。能把人设在几分钟内快速固定下来,也就不愁吸引对口的妹子了。我有几个备选方案,仅供参考。1. 运动型男生左手单手俯卧撑,右手在键盘上敲代码。你雄壮的腰腹肌肉群活灵活现,简直就是移动的春药。2.幽默男生花 20 块找一个托(最好是老同学 or 同事)坐你对面。每当你侃侃而谈,他便满面涨红、放声大笑、不能自已。他笑的越弱_咖啡厅写代码
【笔试面试】腾讯WXG 面委会面复盘总结 --一次深刻的教训_腾讯面委会面试是什么-程序员宅基地
文章浏览阅读1.2w次,点赞5次,收藏5次。今天 (应该是昨天了,昨晚太晚了没发出去)下午参加了腾讯WXG的面委会面试。前面在牛客上搜索了面委会相关的面经普遍反映面委会较难,因为都是微信的核心大佬,问的问题也会比较深。昨晚还蛮紧张的,晚上都没睡好。面试使用的是腾讯会议,时间到了面试官准时进入会议。照例是简单的自我介绍,然后是几个常见的基础问题:例如数据库索引,什么时候索引会失效、设计模式等。这部分比较普通,问的也不是很多,不再赘述。现在回想下,大部分还是简历上写的技能点。接下来面试官让打开项目的代码,对着代码讲解思路。我笔记本上没有这部分代码,所_腾讯面委会面试是什么
AI绘画自动生成器:艺术创作的新浪潮-程序员宅基地
文章浏览阅读382次,点赞3次,收藏4次。AI绘画自动生成器是一种利用人工智能技术,特别是深度学习算法,来自动创建视觉艺术作品的软件工具。这些工具通常基于神经网络模型,如生成对抗网络(GANs),通过学习大量的图像数据来生成新的图像。AI绘画自动生成器作为艺术与科技结合的产物,正在开启艺术创作的新篇章。它们不仅为艺术家和设计师提供了新的工具,也为普通用户提供了探索艺术的机会。随着技术的不断进步,我们可以预见,AI绘画自动生成器将在未来的创意产业中发挥越来越重要的作用。
获取list集合中重复的元素_list找到重复的元素-程序员宅基地
文章浏览阅读1.6w次,点赞3次,收藏13次。老规矩,二话不说直接上代码:package com.poinne17.test;import org.apache.commons.collections.CollectionUtils;import org.junit.Test;import java.util.*;/** * @author:Pionner17 * @date: 2017/9/3 22:41 * @em_list找到重复的元素
系统运维—1.0 解压缩_winzip收费-程序员宅基地
文章浏览阅读1k次。一、zip和unzip 一般情况下,windows中的压缩包都是rar或者zip格式,对应的压缩软件为winzip和winrar。winzip是免费的,winrar是收费的。rar比zip压缩率更高,即同样的文件压缩完后体积更小,同时因为国内盗版,以及winrar安装后,右击默认压缩为rar的原因,导致国内的rar的使用率远超zip。 放眼全世界,zip的使用率反而远超rar,在ubuntu中,zip是默认安装的,免费使用,而rar需要额外安装,并且收费。故在linux中一般情况下,我们使用zip格_winzip收费
随便推点
Flutter ListView ListView.build ListView.separated_flutter listview.separated和listview.builder-程序员宅基地
文章浏览阅读1.7k次。理解为ListView 的三种形式吧ListView 默认构造但是这种方式创建的列表存在一个问题:对于那些长列表或者需要较昂贵渲染开销的子组件,即使还没有出现在屏幕中但仍然会被ListView所创建,这将是一项较大的开销,使用不当可能引起性能问题甚至卡顿直接返回的是每一行的Widget,相当于ios的row。行高按Widget(cell)高设置ListView.build 就和io..._flutter listview.separated和listview.builder
2021 最新前端面试题及答案-程序员宅基地
文章浏览阅读1.4k次,点赞4次,收藏14次。废话不多说直接上干货1.js运行机制JavaScript单线程,任务需要排队执行同步任务进入主线程排队,异步任务进入事件队列排队等待被推入主线程执行定时器的延迟时间为0并不是立刻执行,只是代表相比于其他定时器更早的被执行以宏任务和微任务进一步理解js执行机制整段代码作为宏任务开始执行,执行过程中宏任务和微任务进入相应的队列中整段代码执行结束,看微任务队列中是否有任务等待执行,如果有则执行所有的微任务,直到微任务队列中的任务执行完毕,如果没有则继续执行新的宏任务执行新的宏任务,凡是在..._前端面试
linux基本概述-程序员宅基地
文章浏览阅读1k次。(3)若没有查到,则将请求发给根域DNS服务器,并依序从根域查找顶级域,由顶级查找二级域,二级域查找三级,直至找到要解析的地址或名字,即向客户机所在网络的DNS服务器发出应答信息,DNS服务器收到应答后现在缓存中存储,然后,将解析结果发给客户机。(3)若没有查到,则将请求发给根域DNS服务器,并依序从根域查找顶级域,由顶级查找二级域,二级域查找三级,直至找到要解析的地址或名字,即向客户机所在网络的DNS服务器发出应答信息,DNS服务器收到应答后现在缓存中存储,然后,将解析结果发给客户机。_linux
JavaScript学习手册十三:HTML DOM——文档元素的操作(一)_javascript学习手册十三:html dom——文档元素的操作(一)-程序员宅基地
文章浏览阅读7.9k次,点赞26次,收藏66次。HTML DOM——文档元素的操作1、通过id获取文档元素任务描述相关知识什么是DOM文档元素节点树通过id获取文档元素代码文件2、通过类名获取文档元素任务描述相关知识通过类名获取文档元素代码文件3、通过标签名获取文档元素任务描述相关知识通过标签名获取文档元素获取标签内部的子元素代码文件4、html5中获取元素的方法一任务描述相关知识css选择器querySelector的用法代码文件5、html5中获取元素的方法二任务描述相关知识querySelectorAll的用法代码文件6、节点树上的操作任务描述相关_javascript学习手册十三:html dom——文档元素的操作(一)
《LeetCode刷题》172. 阶乘后的零(java篇)_java 给定一个整数n,返回n!结果尾数中零的数量-程序员宅基地
文章浏览阅读132次。《LeetCode学习》172. 阶乘后的零(java篇)_java 给定一个整数n,返回n!结果尾数中零的数量
php 公众号消息提醒,如何开启公众号消息提醒功能-程序员宅基地
文章浏览阅读426次。请注意,本文将要给大家分享的并不是开启公众号的安全操作风险提醒,而是当公众号粉丝给公众号发消息的时候,公众号的管理员和运营者如何能在手机上立即收到消息通知,以及在手机上回复粉丝消息。第一步:授权1、在微信中点击右上角+,然后选择“添加朋友”,然后选择“公众号”,然后输入“微小助”并关注该公众号。2、进入微小助公众号,然后点击底部菜单【新增授权】,如下图所示:3、然后会打开一个温馨提示页面。请一定要..._php微信公众号服务提示