大数据之Hadoop图解概述-程序员宅基地
文章目录
0 写在开头
开始更新
Hadoop系列教学文章了,从零带你入门大数据,期待的你的关注️️
1 Hadoop是什么
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
2 Hadoop 发展历史(了解)
1)Hadoop创始人Doug Cutting,为 了实 现与Google类似的全文搜索功能,他在Lucene框架基础上进行优
化升级,查询引擎和索引引擎。
2)2001年年底Lucene成为Apache基金会的一个子项目。
3)对于海量数据的场景,Lucene框 架面 对与Google同样的困难,存 储海量数据困难,检 索海 量速度慢。
4)学习和模仿Google解决这些问题的办法 :微型版Nutch。
5)可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
- GFS —>HDFS
- Map-Reduce —>MR
- BigTable —>HBas
6)2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用
了2年业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。
7)2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。
8)2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS)分别被纳入到 Hadoop 项目
中,Hadoop就此正式诞生,标志着大数据时代来临。
9)名字来源于Doug Cutting儿子的玩具大象
Hadoop的log

3 Hadoop 三大发行版本(了解)
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks。
Apache版本最原始(最基础)的版本,对于入门学习最好。2006- Cloudera 内部集成了很多大数据框架,对应产品 CDH。2008
- Hortonworks 文档较好,对应产品
HDP。2011 - Hortonworks 现在已经被 Cloudera 公司收购,推出新的品牌
CDP。
①Apache Hadoop(常用)
官网地址:http://hadoop.apache.org
下载地址:https://hadoop.apache.org/releases.html
②Cloudera Hadoop
官网地址:https://www.cloudera.com/downloads/cdh
下载地址:https://docs.cloudera.com/documentation/enterprise/6/releasenotes/topics/rg_cdh_6_download.html
1)2008 年成立的 Cloudera 是最早将 Hadoop 商用的公司,为合作伙伴提供 Hadoop 的
商用解决方案,主要是包括支持、咨询服务、培训。
2)2009 年 Hadoop 的创始人 Doug Cutting 也加盟 Cloudera 公司。Cloudera 产品主
要为 CDH,Cloudera Manager,Cloudera Support
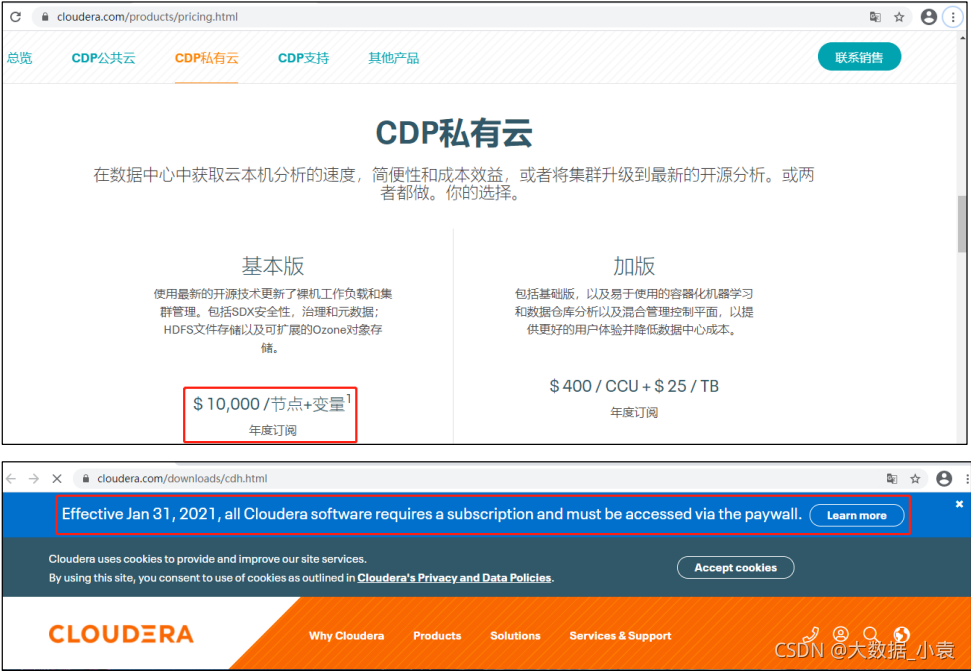
3)CDH 是 Cloudera 的 Hadoop 发行版,完全开源,比 Apache Hadoop 在兼容性,安
全性,稳定性上有所增强。Cloudera 的标价为每年每个节点 10000 美元。
4)Cloudera Manager 是集群的软件分发及管理监控平台,可以在几个小时内部署好一
个 Hadoop 集群,并对集群的节点及服务进行实时监控。
③Hortonworks Hadoop
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
1)2011 年成立的 Hortonworks 是雅虎与硅谷风投公司 Benchmark Capital 合资组建。
2)公司成立之初就吸纳了大约 25 名至 30 名专门研究 Hadoop 的雅虎工程师,上述
工程师均在 2005 年开始协助雅虎开发 Hadoop,贡献了 Hadoop80%的代码。
3)Hortonworks 的主打产品是 Hortonworks Data Platform(HDP),也同样是 100%开
源的产品,HDP 除常见的项目外还包括了 Ambari,一款开源的安装和管理系统。
4)2018 年 Hortonworks 目前已经被 Cloudera 公司收购
4 Hadoop 优势(4 高)
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。

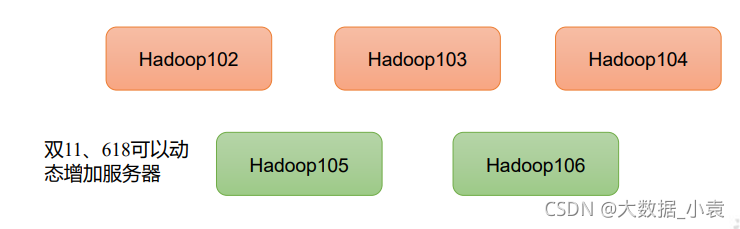
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
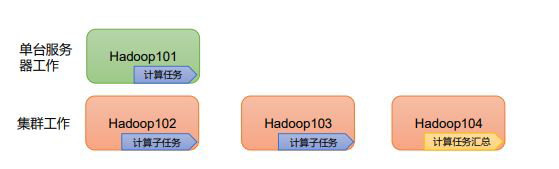
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
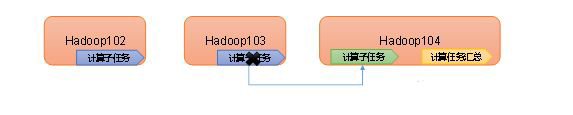
4)高容错性:能够自动将失败的任务重新分配。
5 Hadoop 组成(面试重点)
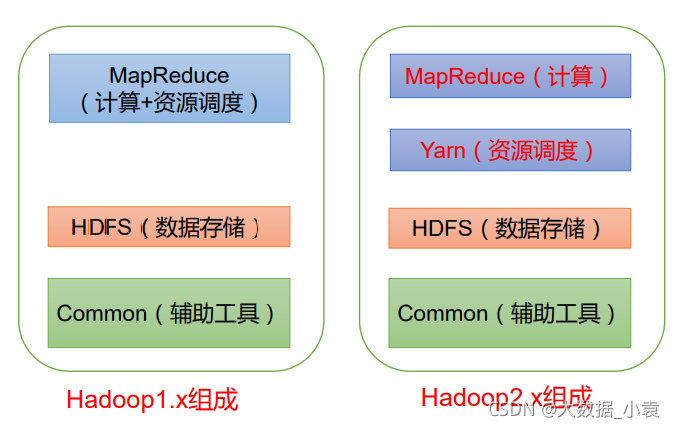
- 在 Hadoop1.x 时 代 ,Hadoop中 的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
- 在Hadoop2.x 时代,增加 了Yarn。Yarn只负责资源的调 度 ,MapReduce 只负责运算。
- 在Hadoop3.x 时代,在组成上没有变化。
5.1 HDFS 架构概述
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。
HDFS架构概述:
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。

2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。

3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
5.2 YARN 架构概述
Yet Another Resource Negotiator 简称 YARN ,另一种资源协调者,是 Hadoop 的资源管理器。
1)ResourceManager(RM):整个集群资源(内存、CPU等)的老大
3)ApplicationMaster(AM):单个任务运行的老大
2)NodeManager(N M):单个节点服务器资源老大
4)Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。

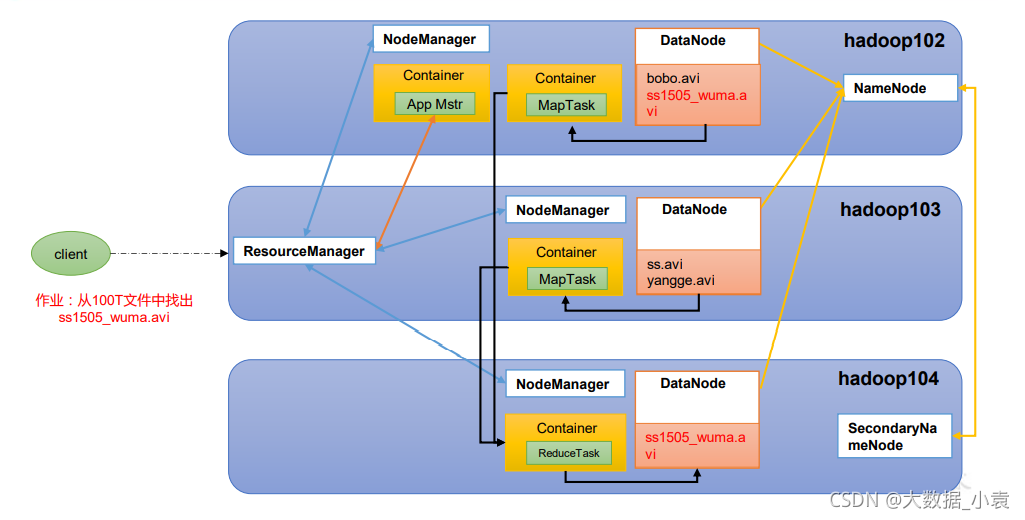
5.3 MapReduce 架构概述
MapReduce:分布式的离线并行计算框架,对海量数据的处理。将计算过程分为Map和Reduce两个阶段,Map阶段并行处理输入数据,Reduce阶段对Map结果进行汇总。
Mapper:
- 1.第一阶段是把输入文件进行分片(inputSplit)得到block。有多少个block就对应启动多少maptask
- 2.第二阶段是对输入片中的记录按照一定的规则解析成键值对。键(key)表示每行首字符偏移值,值(value)表示本行文本内容。
- 3.第三阶段是调用map方法。解析出来的每个键值对,调用一次map方法。
- 4.第四阶段是按照一定规则对第三阶段输出的键值对进行分区。
- 5.第五阶段是对每个分区中的键值对进行排序。首先按照键进行排序,然后按照值。完成后将数据写入内存中,内存中这片区域叫做环形缓冲区。
Reduce:
- 1.第一阶段(copy)reduce任务从Mapper任务复制输出的键值对。
- 2.第二阶段(sort)合并排序是把复制到Reduce本地数据,全部合并。再对合并后的数据排序
- 3.第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
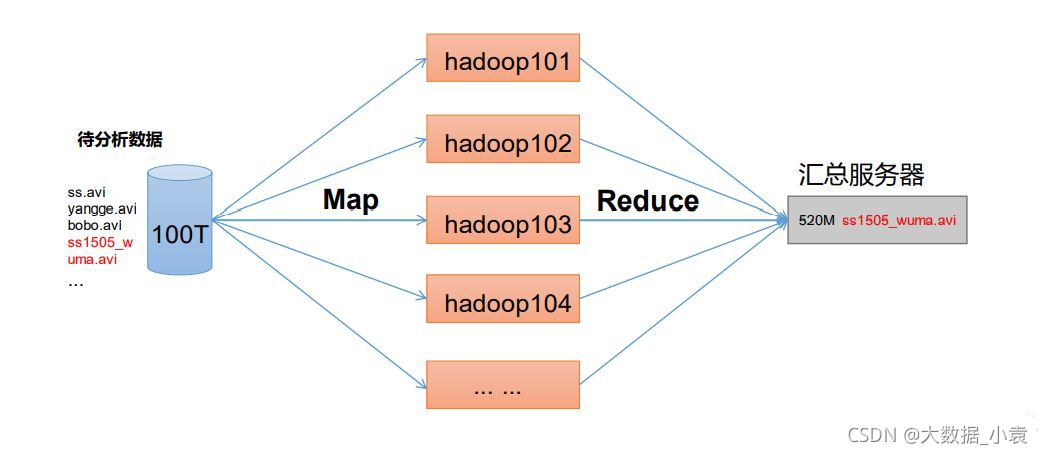
5.4 HDFS、YARN、MapReduce 三者关系
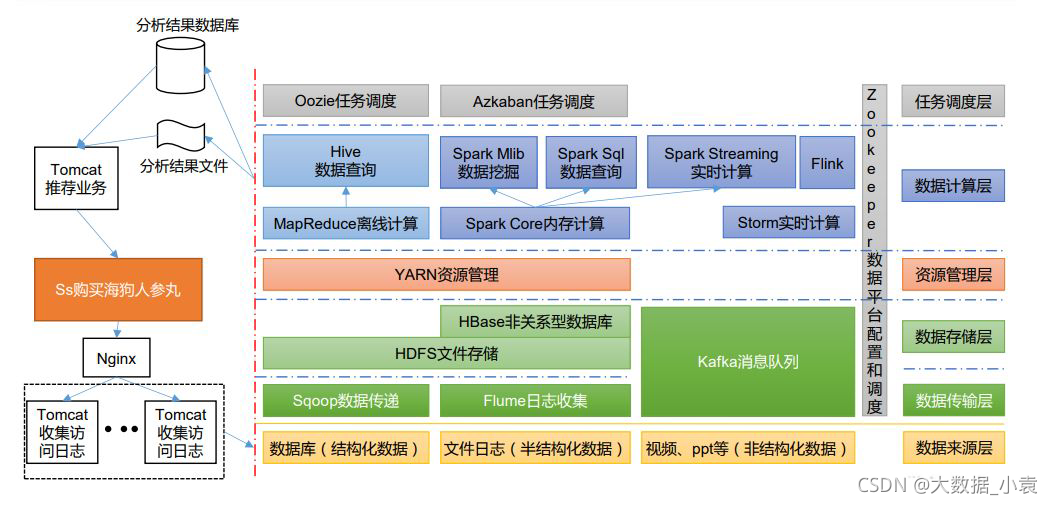
6 大数据技术生态体系
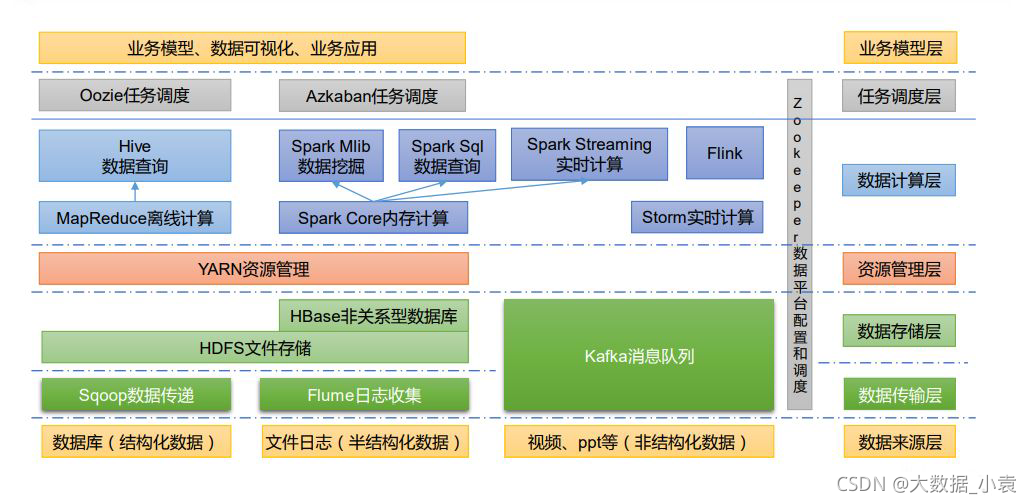
图中涉及的技术名词解释如下:
1)Sqoop:Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
2)Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统;
4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数据进行计算。
5)Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
6)Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,
它是一个适合于非结构化数据存储的数据库。
8)Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
7 推荐系统框架图
8 大数据简历模板和大厂面试真题下载
智能推荐
python语言中1010的二进制表示_Python语言中的按位运算-程序员宅基地
文章浏览阅读2.3k次。(转)位操作是程序设计中对位模式或二进制数的一元和二元操作. 在许多古老的微处理器上, 位运算比加减运算略快, 通常位运算比乘除法运算要快很多. 在现代架构中, 情况并非如此:位运算的运算速度通常与加法运算相同(仍然快于乘法运算).简单来说,按位运算就把数字转换为机器语言——二进制的数字来运算的一种运算形式。在计算机系统中,数值一律用补码来表示(存储)。Python中的按位运算符有:左移运算符(&..._位串1010的二进制
使用windows11 + linux 虚拟机,端口被占用_wsl 端口占用-程序员宅基地
文章浏览阅读560次。解决windows分配Linux端口太靠前的问题。_wsl 端口占用
第一章:什么是软件架构?_allocation structures-程序员宅基地
文章浏览阅读1k次。What Software Architecture Is系统的软件体系结构是指系统所需的一组结构,包括软件元素、它们之间的关系以及两者的属性。结构是由一个关系集合在一起的一组元素。We call runtime structures component-and-connector (C&C) structures.Allocation structures describe the ma..._allocation structures
求链式线性表的倒数第K项_c语言 求链式线性表的倒数第k项 分数 12 作者 ds课程组 单位 浙江大学 给定一系列-程序员宅基地
文章浏览阅读565次。求链式线性表的倒数第K项给定一系列正整数,请设计一个尽可能高效的算法,查找倒数第K个位置上的数字。输入格式:输入首先给出一个正整数K,随后是若干非负整数,最后以一个负整数表示结尾(该负数不算在序列内,不要处理)。输出格式:输出倒数第K个位置上的数据。如果这个位置不存在,输出错误信息NULL。输入样例:4 1 2 3 4 5 6 7 8 9 0 -1输出样例:7标程 单链表版#include<map>#include<list>#include<cm_c语言 求链式线性表的倒数第k项 分数 12 作者 ds课程组 单位 浙江大学 给定一系列
使用YOLOX进行物体检测_yolox 刀具-程序员宅基地
文章浏览阅读1.4k次。YOLOX 是旷视开源的高性能检测器。旷视的研究者将解耦头、数据增强、无锚点以及标签分类等目标检测领域的优秀进展与 YOLO 进行了巧妙的集成组合,提出了 YOLOX,不仅实现了超越 YOLOv3、YOLOv4 和 YOLOv5 的 AP,而且取得了极具竞争力的推理速度。其中YOLOX-L版本以 68.9 FPS 的速度在 COCO 上实现了 50.0% AP,比 YOLOv5-L 高出 1.8% AP!还提供了支持 ONNX、TensorRT、NCNN 和 Openvino 的部署版本,本文将详细介绍如_yolox 刀具
一文搞懂 UML 类图!!!_uml类图-程序员宅基地
文章浏览阅读2.9k次,点赞27次,收藏45次。统一建模语言UML类图是一种用于描述系统结构的图形化工具。它以类和对象为基础,主要用于表示系统中的类、接口、继承关系、关联关系等元素,以及它们之间的静态结构和关系。在本文中,将深入介绍UML类图的基本元素关系类型以及如何创建一个简单而有效的类图。类图以反映类的结构(属性、操作)以及类之间的关系为主要目的,描述了软件系统的结构,是一种静态建模方法。类图用来描述系统中有意义的概念,包括具体的概念、抽象的概念、实现方面的概念等,是对现实世界中事物的抽象。_uml类图
随便推点
handlebars-----if的基本用法_handlebars的if-程序员宅基地
文章浏览阅读1.1k次。1 DOCTYPE html> 2 html> 3 head> 4 META http-equiv=Content-Type content="text/html; charset=utf-8"> 5 title>if-判断的基本用法 - by 杨元title> 6 head> 7 body> 8 h1>if-判断的基本用法h1> 9 基_handlebars的if
Golang 端口复用测试_golang端口复用-程序员宅基地
文章浏览阅读4.1k次。先给出结论:同一个进程,使用一个端口,然后连接关闭,大约需要30s后才可再次使用这个端口。测试首先使用端口9001连接服务端,发送数据,然后关闭连接,接着再次使用端口9001连接服务端,如果连接失败,间隔15s后,再次尝试,最多尝试3次,。clientpackage mainimport ( "bufio" "fmt" &quo_golang端口复用
ROR笔记 1_address execution break already exists,redefine ex-程序员宅基地
文章浏览阅读859次。这段时间有空看看Ruby On Rails顺手把一些主要的东西记录下来以免忘掉了最近有点时间准备自己搞个小的网站玩玩,主要考虑过Django和ROR。考虑Django的原因是我以前用Python写过几个小程序还有点熟悉,而且Python的性能比Ruby要高,Django据说也是个性能比较高的框架。ROR不用说了,相对来说名头要大,比较流行。最终选择的原因比较多,一会儿也说不清。先说说Django吧,目前知道比较有名的Python站点就是豆瓣了,据阿北个人说只有一台服务器而且只占用了很少的资源,但并不是用的D_address execution break already exists,redefine existing breakpoint
优傲优化福特汽车装配线生产效率_汽车生产流程优化-程序员宅基地
文章浏览阅读403次。减少员工的重复性工作 快速将协作机器人集成到生产流程中 提升生产速度及效率 部署灵活, 可快速切换作业市场压力增大,产线升级需求迫在眉睫一直以来,汽车行业的自动化水平在制造业中是数一数二的。大多数汽车制造厂商在焊接、涂装、冲压等环节都已经采用自动化技术。但随着生产模式和外部环境的变化,市场对汽车制造商提出了更高的要求。在传统工业机器人无法满足柔性生产的灵活要求的情况下,汽车制造商..._汽车生产流程优化
重装Office后打开outlook和excel提示找不到VCRUNTIME140_1.dll的解决办法_打开excel提示vcruntime140-程序员宅基地
文章浏览阅读1.7w次,点赞3次,收藏8次。最近发现有的电脑重装Office后打不开outlook和excel,提示找不到VCRUNTIME140_1.dll。如下图所示VCRUNTIME140_1.dll是C++ 2015的一个组件,一般我直接用DirectX Repair运行库修复工具,开启强力修复,更新C++解决。如果不行的话直接卸载C++再重新安装也是可以的。..._打开excel提示vcruntime140
docker overlay网络详解-程序员宅基地
文章浏览阅读1w次,点赞10次,收藏36次。之前我们学习的网络是单台主机的网络通讯方案,这里我们学习的是跨跨主机。我们原生的docker跨主机方案有macvlan和overlay,这里我们重点学习overlay第三方网络插件有flannel,calico,weave网络。docker网络之所以这么活跃,是因为网络部分的代码单独抽离出来成为docker的网络库,即libnetwork。为了标准化网路驱动的开发步骤和支持各种网络驱动,libnetwork中使用了CNM(container network model),CNM定义了构建容器_docker overlay