吴恩达(Andrew Ng)《机器学习》课程笔记(3) 第3周——逻辑回归_2.吴恩达(andrew ng)的机器学习课程里介绍过一种用 logistic回归训练图像二分 类(-程序员宅基地
技术标签: 吴恩达 机器学习 人工智能 吴恩达 机器学习笔记

第3周 课程内容有点多,分两个博客。
吴恩达(Andrew Ng)《机器学习》课程笔记(4)第3周——正则化
目录
6.2 假设表示(Hypothesis Representation)
6.5 简化的代价函数和梯度下降(Simplified Cost Function and Gradient Descent)
6.6 高级优化(Advanced Optimization)
6.7 多元分类:一对多(Multiclass Classification: One-Vs-All)
六、逻辑回归(Logistic Regression)
6.1 分类(Classification)
分类问题(Classification problems),也就是你想预测的值是一个离散的值。
我们会使用逻辑回归(Logistic Regression)算法来解决分类问题。
之前,我们讨论的垃圾邮件分类实际上就是一个分类问题。类似的例子还有很多,例如一个在线交易网站判断一次交易是否带有欺诈性。再如,之前判断一个肿瘤是良性的还是恶性的,也是一个分类问题。
在以上的这些例子中,属于二元分类,我们想预测的是一个二值的变量,或者为0,或者为1;或者是一封垃圾邮件,或者不是;或者是带有欺诈性的交易,或者不是;或者是一个恶性肿瘤,或者不是。
我们可以将因变量可能属于的两个类分别称为负向类(Negative Class)和正向类(Positive Class)。可以使用“0”来代表负向类,“1”来代表正向类。现在,我们的分类问题仅仅局限在两类上:0或者1。之后会讨论多分类问题,也就是说,预测的变量可以取多个值,例如0,1,2,3。
那么,我们如何来解决一个分类问题呢?首先从二元分类问题开始讨论,看以下例子:
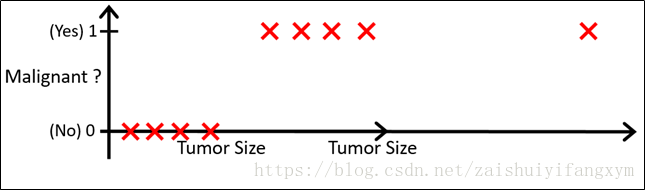
现在有一个分类任务,需要根据肿瘤大小来判断肿瘤的良性与否。训练集如上图所示,横轴代表肿瘤大小,纵轴表示肿瘤的良性与否,注意,纵轴只有两个取值,“1”(代表恶性肿瘤)和“0”(代表良性肿瘤)。
对于以上数据集使用线性回归来处理,实际上就是用一条直线去拟合这些数据。因此,你得到的 直线可能如下图所示:
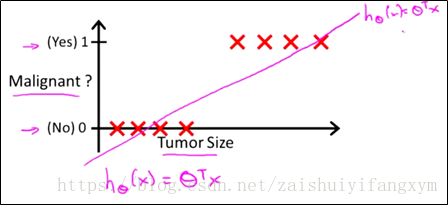
根据线性回归模型我们只能预测连续的值,然而对于分类问题,我们只需要离散值“0”或“1”。我们可以这样预测:

对于上面的数据,我们使用一个线性回归模型做出了预测分类,似乎很好地完成了分类任务。难道真的就这么简单吗? 现在,我们对以上问题稍作一些改动。将横轴向右扩展,并且增加一个训练样本,如下图所示:
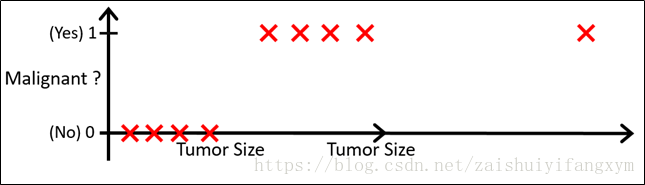
那么,使用刚才的线性回归模型,会得到一条新的直线:
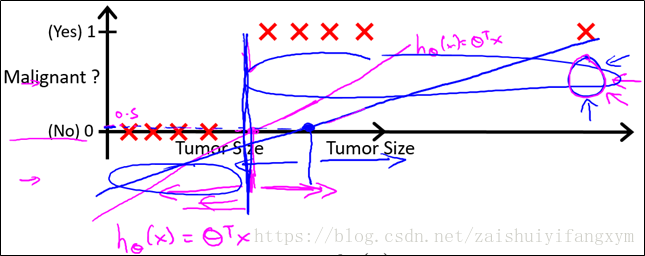
此时,我们再用刚才所用的0.5作为阈值来预测肿瘤的良性还是恶性,就不合适了。可以看出,线性回归模型,因为其预测的值可以超过[0,1]的范围,并不适合解决分类问题。
所以,针对分类问题,我们将使用新的模型:逻辑回归(Logistic Regression)。下一节我们将展开叙述。
6.2 假设表示(Hypothesis Representation)
对于分类问题,我们引入新的模型:逻辑回归(Logistic Regression) 该模型的输出变量范围始终在[0,1]之间。
我们在之前的线性回归模型的假设表示(Hypothesis Representation):
而现在的逻辑回归模型的假设表示(Hypothesis Representation) : ,其中:x表示特征向量;
g(.)表示逻辑函数(Logistic function):是一个常用的逻辑函数:S形函数(Sigmoid function),一般逻辑函数就等同于S形函数。
这里的逻辑回归(Logistic function)是一种分类算法,不要与线性回归弄混淆。
S形函数(Sigmoid function)表达式和曲线如下:
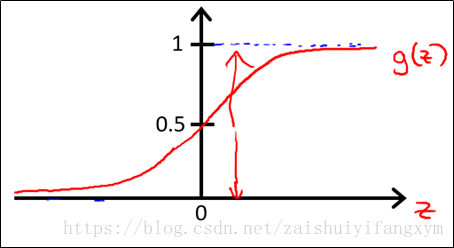
则逻辑回归模型为:
可以看出预测值y的取值范围是[0,1],对于,模型预测值输出y=1;
,模型预测值输出y=0。
值得注意的是:属于y=1分类的概率,即:
此外由于y只能取“0”或“1”两个值,换句话说,一个数据要么属于0分类要么属于1分类,假设已经知道了属于1分类的概率是p,那么当然其属于0分类的概率则为1-p,这样我们有以下结论:
例如:如果对于给定的x,通过已经确定的参数计算得到,则表示70%的概率y=1,则
,所以y=1。相应的y=0的概率为0.3。
6.3 决策边界(Decision Boundary)
在逻辑回归中,我们预测:
,模型预测值输出y=1;
,模型预测值输出y=0。
那么:

现在举个例子方便我们理解:
已知下图的数据,现要将其分类,需要用到逻辑回归模型。
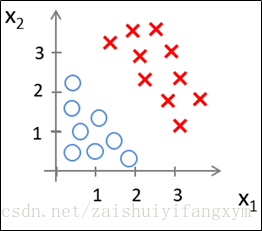
假设现在有一个逻辑回归模型:
,并且参数θ为:向量:[-3 1 1]。
将参数θ带入到假设模型中得到:
那么,根据上面的式子:
得到上面的参数,现在可以绘制的图像了,如下图所示:
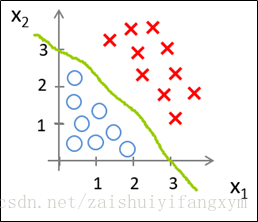
从上图可以看出,合适的参数θ将数据成功的分开,这条绿色线就是模型的分界线,就是决策边界(Decision Boundary),将预测为1的区域和预测为0 的区域分开。
下面再看一个例子:如下图的数据,用逻辑回归模型,参数怎样设置,才能适应决策边界?
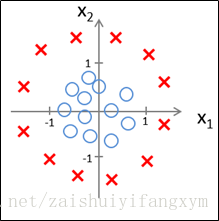
因为要用曲线才能分开y=0的区域和y=1的区域,我们需要借助二次方参数特征:假设参数:
, 其中,参数θ为:向量[-1 0 0 1 1]。
根据以上参数,我们得到决策边界恰好是以原点为中心,半径为1的圆。如下图所示:
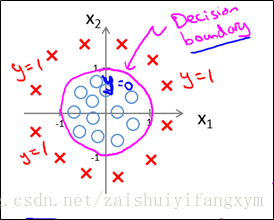
则,这个问题就转化为:
这只是一个例子,恰好可以简单地求出决策边界,并且我们对决策的边界是非常熟悉的曲线方程。
当然,我们参数θ设置越复杂,得到的决策边界会变得复杂。
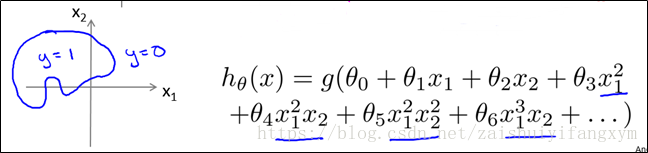
6.4 代价函数(Cost Function)
对于线性回归问题,使用线性回归模型,我么定义代价函数是误差的平方和。同样的,理论上说,我们对分类问题,使用逻辑回归模型的也定义代价函数的误差的平方和,但是这里有个问题出现了。
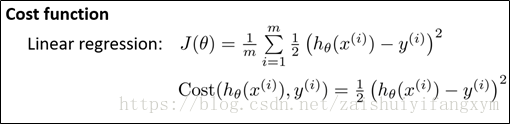
我们将假设(Hypothesis) : ,带入到代价函数中,我们得到的代价函数是一个非凸函数(non-convex function),其曲线图下图所示,这意味着我们的代价函数有许多局部最小值,这将对在使用梯度下降法求全局最小值影响很大。
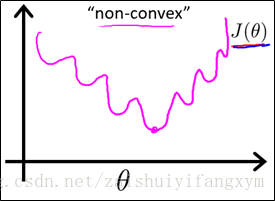
凸函数(convex function),只有一个最小值,也是我们最想要得到的,在梯度下降法中,将很快的寻找到全局最小值,凸函数曲线如下图所示:
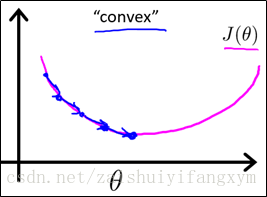
因此,要是能使代价函数转化为凸函数,问题就迎刃而解了。那么问题来了,用什么方法将非凸函数转化为凸函数呢?
现在,我们重新定义逻辑回归模型的代价函数(Cost Function):
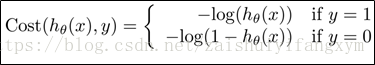
如下图所示,使用对数函数,对数函数是一个单调函数,并且:
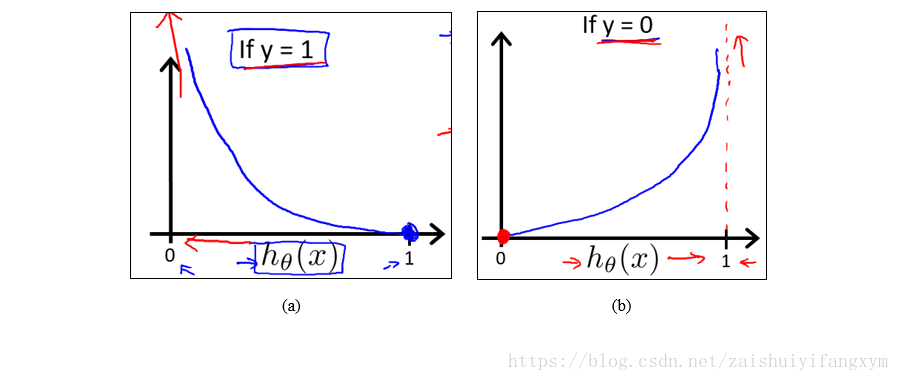
可以看到,当y=1,时,则代价函数为0;
反之,y=0,时,则代价函数为无穷大,符合我们的预期想要的结果(在[0,1]区间内可以找到全局最小值,这个最小值就是0)。
6.5 简化的代价函数和梯度下降(Simplified Cost Function and Gradient Descent)
前面,我们构建了逻辑回归代价函数,其表达式为:
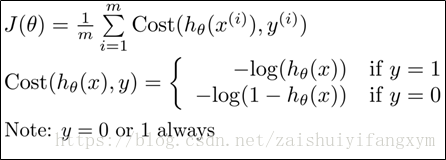
这样构建的代价函数特点是:
当y=1且 时,代价函数为0;当y=0且
时,代价函数随着
增大而减小;
当y=0且时,代价函数为0;当当y=0且
时,代价函数随着
增大而增大。
前面的代价函数是分段函数,为了使得计算起来更加方便,可以将分段函数写成一个函数的形式,即:
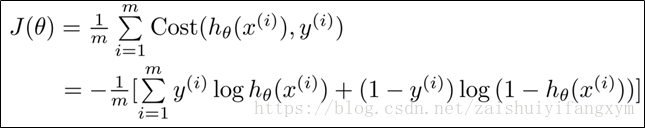
根据代价函数,我们的目的是找到使得代价函数取得全局最小值时的参数θ,最后根据这个参数,在逻辑回归预测模型中,预测得到 的值。值得注意的是:得到的值就是y=1出现的概率,即:
。
所以,最关键的一步就是如何找到最小值,前面说过,用梯度下降法求最小值。

求导,化简得到:

注意:这里的求解方法和线性回归求解方法看起来类似。其实这里的与线性回归中不同。所以与线性回归不同。另外,在使用梯度下降法前,特征缩放(归一化)是非常重要的。
6.6 高级优化(Advanced Optimization)
当然,求出代价函数的最小值的方法有很多,不仅仅只有梯度下降法一个。 除了梯度下降算法,可以采用高级优化算法,例如:共轭梯度(Conjugate Gradient),局部优化法(BFGS),有限内存局部优化法(L-BFGS)等。这些算法优点是不需要手动选择α,比梯度下降算法更快;缺点是算法更加复杂。这些算法Matlab中都有。下面举例进行说明:


6.7 多元分类:一对多(Multiclass Classification: One-Vs-All)
多分类例子,例如:
(1)邮箱自动将邮件进行,分组类别有:同事,朋友,家人,同学等,可以用数字1,2,3,4…分类;
(2)去诊所看病,其分类可以有:正常,感冒,流感等,可以用数字1,2,3,…分类;
(3)预测天气情况,其分类可以有:晴天,多云,下雨,下雪等,可以用数字1,2,3,4…分类;
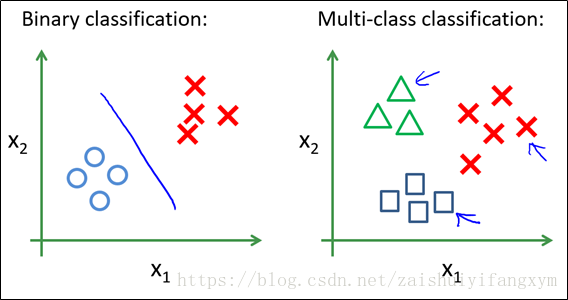
下图是一个二分类和多分类的数据,多分类可以借助二分类的思想依次做分类。
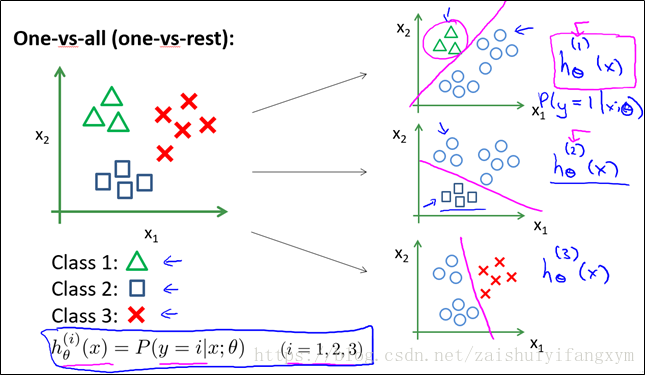

将数据分别进行两两分类,使用二元分类方法得到3个训练好的模型。最后将测试数据输入到模型中去,分别计算其预测值,选择预测值最大的作为其预测分类即可。
一般的:
Logistic回归可以用于多元分类,采用所谓的One-Vs-All方法,具体来说,假设有K个分类{1,2,3,...,K},我们首先训练一个逻辑回归模型将数据分为属于1类的和不属于1类的,接着训练第二个逻辑回归模型,将数据分为属于2类的和不属于2类的,一次类推,直到训练完K个逻辑回归模型。
对于新的数据,我们将其带入K个训练好的模型中,分别其计算其预测值(预测值的大小表示属于某分类的概率),选择预测值最大的那个分类作为其预测分类即可。
参考资料
[1] Andrew Ng Coursera 机器学习 第三周 PPT
[2] https://blog.csdn.net/mydear_11000/article/details/50865094
[3] https://www.cnblogs.com/python27/p/MachineLearningWeek03.html
智能推荐
The MySQL server is running with the --secure-file-priv option so it cannot execute this statement-程序员宅基地
文章浏览阅读2.8k次。在MySQL执行数据导出时遇到以下报错,16:06:16 SELECT * FROM actor into outfile 'e:/tmp/act.csv' fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n' Error Code: 1290. The MySQL server..._he mysql server is running with the --secure-file-priv option so it cannot e
unity3D烟花制作-来放烟花吧!_unity particle pack-程序员宅基地
文章浏览阅读9.2k次,点赞13次,收藏62次。3D游戏第八次作业-烟花粒子效果实现结果展示先来个结果镇楼如果链接未显示,可打开以下链接https://gitee.com/wangyuwen2020/picture/raw/master/firework.gif_unity particle pack
Unicdoe【真正的完整码表】对照表(二)汉字Unicode表_孩怮交vⅰdeos乱叫√-程序员宅基地
文章浏览阅读10w+次,点赞99次,收藏383次。注意:下面这两段是代理区。即第1——16平面的间接表示,四个字节的汉字就在这里表示D800-DBFF:High-half zone of UTF-16 DC00-DFFF:Low-half zone of UTF-16 本篇中包含了所有常用汉字27973个,剩余汉字使用代理区标识欢迎查看字符编码相关博客专栏比如:由iPhone emoji问题牵出的UTF-16编码,UTF-8编码探究_孩怮交vⅰdeos乱叫√
Linux driver coding (1) --------Hello kernel_chealsa-driver cking for kernel linux/version.h ..-程序员宅基地
文章浏览阅读619次。source codeMakefiledmesg_chealsa-driver cking for kernel linux/version.h ... no
C语言MYSQL库,C++轻量级封装(函数式编程)_mysql c封装-程序员宅基地
文章浏览阅读274次。DB2_ExecuteNonQuery 执行数据库命令,返回值:-1、SQL问题/链接故障、0、无数据改变、>= 1 命令影响数据库行数。DB2_ParameterStatement 参数声明(支持:字符串、BLOB、各种C/C++基础语法值类型)DB2_ExecuteQuery 执行数据库查询。DB2_FetchRowValue 获取行的列数据。C/C++ DB2.h 轻量级数据库操作函数封装。支持BLOB类型CURD(增删改查)_mysql c封装
计算机视觉的定义,应用及整个系统-程序员宅基地
文章浏览阅读7k次。定义: 计算机视觉是使用计算机及相关设备对生物视觉的一种模拟。它的主要任务就是通过对采集的图片或视频进行处理以获得相应场景的三维信息,就像人类和许多其他类生物每天所做的那样。 计算机视觉是一门关于如何运用照相机和计算机来获取我们所需的,被拍摄对象的数据与信息的学问。形象地说,就是给计算机安装上眼睛(照相机)和大脑(算法),让计算机能够感知环境。我们中国人的成语"眼见为实"和西方_计算机视觉
随便推点
分层图最短路--最通俗易懂的讲解_分层最短路-程序员宅基地
文章浏览阅读1w次,点赞47次,收藏91次。分层图最短路是指在可以进行分层图的图上解决最短路问题。分层图:可以理解为有多个平行的图。一般模型是:在一个正常的图上可以进行k次决策,对于每次决策,不影响图的结构,只影响目前的状态或代价。一般将决策前的状态和决策后的状态之间连接一条权值为决策代价的边,表示付出该代价后就可以转换状态了。一般有两种方法解决分层图最短路问题:建图时直接建成k+1层。 多开一维记录机会信息。当然具..._分层最短路
Apache Spark【从无到有从有到无】【编程指南】【AS6】Spark Streaming编程指南_as6 编程-程序员宅基地
文章浏览阅读275次。目录1.概观2.一个简单的例子3.基本概念3.1.链接3.2.初始化StreamingContext3.3.离散流(DStreams)3.4.输入DStreams和Receivers3.4.1.基本来源3.4.2.高级资源3.4.3.自定义来源3.4.4.接收器可靠性3.5.DStreams的转换3.5.1.UpdateStateByKey操作..._as6 编程
http请求 405错误_http 405-程序员宅基地
文章浏览阅读8.4w次,点赞45次,收藏27次。http请求 405错误 方法不被允许 (Method not allowed)405错误常常伴随着POST请求,所有有好多人会告诉你这些:But 时候他并不能解决你的问题。所以我说一点不一样的。假如你有一个user类,里面有两个属性userName,password 数据类型分别为int 和 String。前台表单提交并且是post请求。后台用user接受参数,也是post请求同样也会报405。可能原因是你输入的参数与user所需要的参数类型不匹配。请仔细排查。如果能帮到你,请不要吝啬_http 405
Day04.循环结构_```import randomanswer = random.randint(1, 100)gue-程序员宅基地
文章浏览阅读145次。循环结构文章目录循环结构前言一.for-in循环二.While循环三.练习3.1 输入一个正整数判断是不是素数。3.2 输入两个正整数,计算它们的最大公约数和最小公倍数。3.3 打印如下所示的三角形图案。总结前言我们在写程序的时候,一定会遇到需要重复执行某条或某些指令的场景。例如用程序控制机器人踢足球,如果机器人持球而且还没有进入射门范围,那么我们就要一直发出让机器人向球门方向移动的指令。在这个场景中,让机器人向球门方向移动就是一个需要重复的动作,当然这里还会用到上一课讲的分支结构来判断机器_```import randomanswer = random.randint(1, 100)guess_num = 0guess_count
C++ 学习笔记6--set和multiset、map和multimap(key-value)结构_c++ set 下标-程序员宅基地
文章浏览阅读762次。目录:set初始化、遍历、查找、插入、下标1.1 set的初始化1.2 set的遍历1.3 set的查找1.4 set的插入1.5 set的下标访问1.6 set的修改map初始化、遍历、查找、插入、下标2.1 map的初始化2.2 map的遍历2.3 map的查找2.4 map的插入2.5 map的下标访问1. set初始化、遍历、查找、插入、下标set的特点:1、关键字必须唯一,不能重复2、默认情况下,set中的key会按照升序进行排序3、set的底层实现是_c++ set 下标
客户端与服务器的数据表的同步问题_从服务端获取到的列表 同步在客户端的数据库-程序员宅基地
文章浏览阅读4.6k次。图片来源参见水印。文章参考http://a52071453.iteye.com/blog/1978498。美团二面中面试官问了这样的一个问题,在传输有限的情况下,如何保证多个客户端与服务器保持的数据表的一致性?其实解决的方法很简单。先说一下整体的思路:首先由于客户端可能存在很多,而且不可能每个客户端都时时的和服务器保持连接,因此有服务器主导的同步机制是存在问题的。那_从服务端获取到的列表 同步在客户端的数据库