基于LSTM的股票预测模型_python实现_超详细-程序员宅基地
技术标签: 时间序列 计算智能 LSTM模型 股票预测 python实现
一、背景
近年来,股票预测还处于一个很热门的阶段,因为股票市场的波动十分巨大,随时可能因为一些新的政策或者其他原因,进行大幅度的波动,导致自然人股民很难对股票进行投资盈利。因此本文想利用现有的模型与算法,对股票价格进行预测,从而使自然人股民可以自己对股票进行预测。
理论上,股票价格是可以预测的,但是影响股票价格的因素有很多,而且目前为止,它们对股票的影响还不能清晰定义。这是因为股票预测是高度非线性的,这就要预测模型要能够处理非线性问题,并且,股票具有时间序列的特性,因此适合用循环神经网络,对股票进行预测。
虽然循环神经网络(RNN),允许信息的持久化,然而,一般的RNN模型对具备长记忆性的时间序列数据刻画能力较弱,在时间序列过长的时候,因为存在梯度消散和梯度爆炸现象RNN训练变得非常困难。Hochreiter 和 Schmidhuber 提出的长短期记忆( Long Short-Term Memory,LSTM)模型在RNN结构的基础上进行了改造,从而解决了RNN模型无法刻画时间序列长记忆性的问题。
综上所述,深度学习中的LSTM模型能够很好地刻画时间序列的长记忆性。
二、主要技术介绍
1、RNN模型
在传统的RNN(循环神经网络)中,所有的w都是同一个w,经过同一个cell的时候,都会保留输入的记忆,再加上另外一个要预测的输入,所以预测包含了之前所有的记忆加上此次的输入。所有RNN都具有一种重复神经网络模块的链式的形式。在标准的RNN中,这个重复的模块只有一个非常简单的结构,例如一个tanh层。
当权中大于1时,反向传播误差时,误差将会一直放大,导致梯度爆炸;当权中小于1时,误差将会一直缩小,导致梯度消失,进而导致网络权重更新缓慢,无法体现出RNN的长期记忆的效果,使得RNN太过健忘。RNN模型的结构如图:

2、LSTM模型
长短期记忆模型(long-short term memory)是一种特殊的RNN模型,是为了解决反向传播过程中存在梯度消失和梯度爆炸现象,通过引入门(gate)机制,解决了RNN模型不具备的长记忆性问题,LSTM模型的结构如图:
具体来说,LSTM模型的1个神经元包含了1个细胞状态(cell)和3个门(gate)机制。细胞状态(cell)是LSTM模型的关键所在,类似于存储器,是模型的记忆空间。细胞状态随着时间而变化,记录的信息由门机制决定和更新。门机制是让信息选择式通过的方法,通过sigmoid函数和点乘操作实现。sigmoid取值介于0~1之间,乘即点乘则决定了传送的信息量(每个部分有多少量可以通过),当sigmoid取0时表示舍弃信息,取1时表示完全传输(即完全记住)[2]。
LSTM 拥有三个门,来保护和控制细胞状态:遗忘门(forget gate)、更新门(update gate)和输出门(output gate)。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
如图:
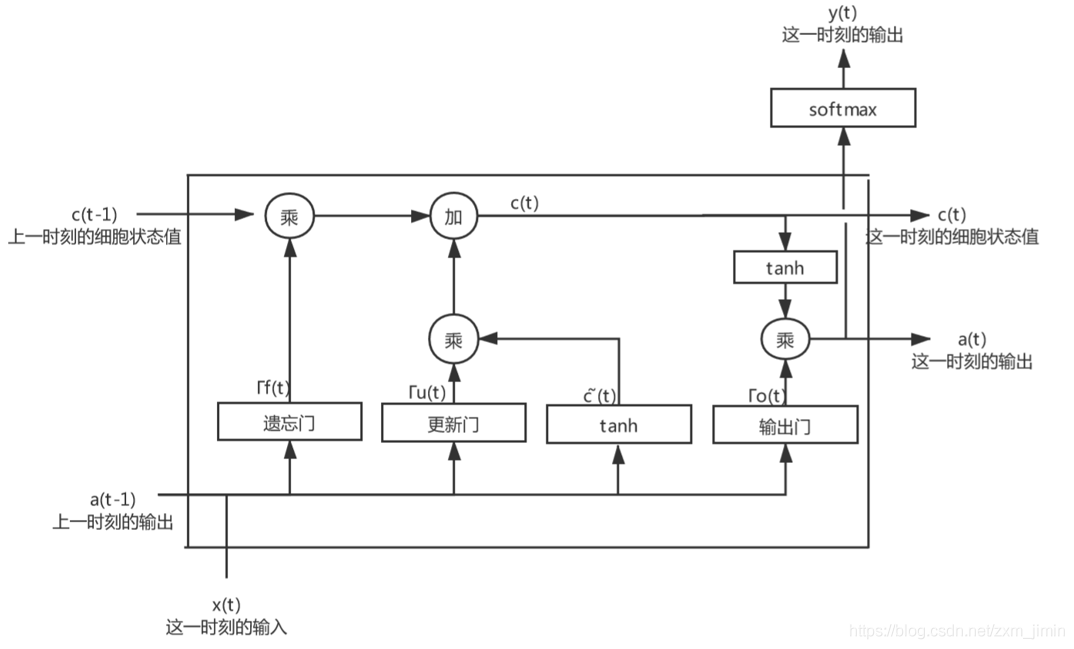

3、控制门工作原理
遗忘门
更新门



输出门

四、代码实现
UI
demo.py
import tensorflow as tf
import numpy as np
import tkinter as tk
from tkinter import filedialog
import time
import pandas as pd
import stock_predict as pred
def creat_windows():
win = tk.Tk() # 创建窗口
sw = win.winfo_screenwidth()
sh = win.winfo_screenheight()
ww, wh = 800, 450
x, y = (sw - ww) / 2, (sh - wh) / 2
win.geometry("%dx%d+%d+%d" % (ww, wh, x, y - 40)) # 居中放置窗口
win.title('LSTM股票预测') # 窗口命名
f_open =open('dataset_2.csv')
canvas = tk.Label(win)
canvas.pack()
var = tk.StringVar() # 创建变量文字
var.set('选择数据集')
tk.Label(win, textvariable=var, bg='#C1FFC1', font=('宋体', 21), width=20, height=2).pack()
tk.Button(win, text='选择数据集', width=20, height=2, bg='#FF8C00', command=lambda: getdata(var, canvas),
font=('圆体', 10)).pack()
canvas = tk.Label(win)
L1 = tk.Label(win, text="选择你需要的 列(请用空格隔开,从0开始)")
L1.pack()
E1 = tk.Entry(win, bd=5)
E1.pack()
button1 = tk.Button(win, text="提交", command=lambda: getLable(E1))
button1.pack()
canvas.pack()
win.mainloop()
def getLable(E1):
string = E1.get()
print(string)
gettraindata(string)
def getdata(var, canvas):
global file_path
file_path = filedialog.askopenfilename()
var.set("注,最后一个为label")
# 读取文件第一行标签
with open(file_path, 'r', encoding='gb2312') as f:
# with open(file_path, 'r', encoding='utf-8') as f:
lines = f.readlines() # 读取所有行
data2 = lines[0]
print()
canvas.configure(text=data2)
canvas.text = data2
def gettraindata(string):
f_open = open(file_path)
df = pd.read_csv(f_open) # 读入股票数据
list = string.split()
print(list)
x = len(list)
index=[]
# data = df.iloc[:, [1,2,3]].values # 取第3-10列 (2:10从2开始到9)
for i in range(x):
q = int(list[i])
index.append(q)
global data
data = df.iloc[:, index].values
print(data)
main(data)
def main(data):
pred.LSTMtest(data)
var.set("预测的结果是:" + answer)
if __name__ == "__main__":
creat_windows()
stock_predict.py
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import pandas as pd
import math
def LSTMtest(data):
n1 = len(data[0]) - 1 #因为最后一位为label
n2 = len(data)
print(n1, n2)
# 设置常量
input_size = n1 # 输入神经元个数
rnn_unit = 10 # LSTM单元(一层神经网络)中的中神经元的个数
lstm_layers = 7 # LSTM单元个数
output_size = 1 # 输出神经元个数(预测值)
lr = 0.0006 # 学习率
train_end_index = math.floor(n2*0.9) # 向下取整
print('train_end_index', train_end_index)
# 前90%数据作为训练集,后10%作为测试集
# 获取训练集
# time_step 时间步,batch_size 每一批次训练多少个样例
def get_train_data(batch_size=60, time_step=20, train_begin=0, train_end=train_end_index):
batch_index = []
data_train = data[train_begin:train_end]
normalized_train_data = (data_train - np.mean(data_train, axis=0)) / np.std(data_train, axis=0) # 标准化
train_x, train_y = [], [] # 训练集
for i in range(len(normalized_train_data) - time_step):
if i % batch_size == 0:
# 开始位置
batch_index.append(i)
# 一次取time_step行数据
# x存储输入维度(不包括label) :X(最后一个不取)
# 标准化(归一化)
x = normalized_train_data[i:i + time_step, :n1]
# y存储label
y = normalized_train_data[i:i + time_step, n1, np.newaxis]
# np.newaxis分别是在行或列上增加维度
train_x.append(x.tolist())
train_y.append(y.tolist())
# 结束位置
batch_index.append((len(normalized_train_data) - time_step))
print('batch_index', batch_index)
# print('train_x', train_x)
# print('train_y', train_y)
return batch_index, train_x, train_y
# 获取测试集
def get_test_data(time_step=20, test_begin=train_end_index+1):
data_test = data[test_begin:]
mean = np.mean(data_test, axis=0)
std = np.std(data_test, axis=0) # 矩阵标准差
# 标准化(归一化)
normalized_test_data = (data_test - np.mean(data_test, axis=0)) / np.std(data_test, axis=0)
# " // "表示整数除法。有size个sample
test_size = (len(normalized_test_data) + time_step - 1) // time_step
print('test_size$$$$$$$$$$$$$$', test_size)
test_x, test_y = [], []
for i in range(test_size - 1):
x = normalized_test_data[i * time_step:(i + 1) * time_step, :n1]
y = normalized_test_data[i * time_step:(i + 1) * time_step, n1]
test_x.append(x.tolist())
test_y.extend(y)
test_x.append((normalized_test_data[(i + 1) * time_step:, :n1]).tolist())
test_y.extend((normalized_test_data[(i + 1) * time_step:, n1]).tolist())
return mean, std, test_x, test_y
# ——————————————————定义神经网络变量——————————————————
# 输入层、输出层权重、偏置、dropout参数
# 随机产生 w,b
weights = {
'in': tf.Variable(tf.random_normal([input_size, rnn_unit])),
'out': tf.Variable(tf.random_normal([rnn_unit, 1]))
}
biases = {
'in': tf.Variable(tf.constant(0.1, shape=[rnn_unit, ])),
'out': tf.Variable(tf.constant(0.1, shape=[1, ]))
}
keep_prob = tf.placeholder(tf.float32, name='keep_prob') # dropout 防止过拟合
# ——————————————————定义神经网络——————————————————
def lstmCell():
# basicLstm单元
# tf.nn.rnn_cell.BasicLSTMCell(self, num_units, forget_bias=1.0,
# tate_is_tuple=True, activation=None, reuse=None, name=None)
# num_units:int类型,LSTM单元(一层神经网络)中的中神经元的个数,和前馈神经网络中隐含层神经元个数意思相同
# forget_bias:float类型,偏置增加了忘记门。从CudnnLSTM训练的检查点(checkpoin)恢复时,必须手动设置为0.0。
# state_is_tuple:如果为True,则接受和返回的状态是c_state和m_state的2-tuple;如果为False,则他们沿着列轴连接。后一种即将被弃用。
# (LSTM会保留两个state,也就是主线的state(c_state),和分线的state(m_state),会包含在元组(tuple)里边
# state_is_tuple=True就是判定生成的是否为一个元组)
# 初始化的 c 和 a 都是zero_state 也就是都为list[]的zero,这是参数state_is_tuple的情况下
# 初始state,全部为0,慢慢的累加记忆
# activation:内部状态的激活函数。默认为tanh
# reuse:布尔类型,描述是否在现有范围中重用变量。如果不为True,并且现有范围已经具有给定变量,则会引发错误。
# name:String类型,层的名称。具有相同名称的层将共享权重,但为了避免错误,在这种情况下需要reuse=True.
#
basicLstm = tf.nn.rnn_cell.BasicLSTMCell(rnn_unit, forget_bias=1.0, state_is_tuple=True)
# dropout 未使用
drop = tf.nn.rnn_cell.DropoutWrapper(basicLstm, output_keep_prob=keep_prob)
return basicLstm
def lstm(X): # 参数:输入网络批次数目
batch_size = tf.shape(X)[0]
time_step = tf.shape(X)[1]
w_in = weights['in']
b_in = biases['in']
# 忘记门(输入门)
# 因为要进行矩阵乘法,所以reshape
# 需要将tensor转成2维进行计算
input = tf.reshape(X, [-1, input_size])
input_rnn = tf.matmul(input, w_in) + b_in
# 将tensor转成3维,计算后的结果作为忘记门的输入
input_rnn = tf.reshape(input_rnn, [-1, time_step, rnn_unit])
print('input_rnn', input_rnn)
# 更新门
# 构建多层的lstm
cell = tf.nn.rnn_cell.MultiRNNCell([lstmCell() for i in range(lstm_layers)])
init_state = cell.zero_state(batch_size, dtype=tf.float32)
# 输出门
w_out = weights['out']
b_out = biases['out']
# output_rnn是最后一层每个step的输出,final_states是每一层的最后那个step的输出
output_rnn, final_states = tf.nn.dynamic_rnn(cell, input_rnn, initial_state=init_state, dtype=tf.float32)
output = tf.reshape(output_rnn, [-1, rnn_unit])
# 输出值,同时作为下一层输入门的输入
pred = tf.matmul(output, w_out) + b_out
return pred, final_states
# ————————————————训练模型————————————————————
def train_lstm(batch_size=60, time_step=20, train_begin=0, train_end=train_end_index):
# 于是就有了tf.placeholder,
# 我们每次可以将 一个minibatch传入到x = tf.placeholder(tf.float32,[None,32])上,
# 下一次传入的x都替换掉上一次传入的x,
# 这样就对于所有传入的minibatch x就只会产生一个op,
# 不会产生其他多余的op,进而减少了graph的开销。
X = tf.placeholder(tf.float32, shape=[None, time_step, input_size])
Y = tf.placeholder(tf.float32, shape=[None, time_step, output_size])
batch_index, train_x, train_y = get_train_data(batch_size, time_step, train_begin, train_end)
# 用tf.variable_scope来定义重复利用,LSTM会经常用到
with tf.variable_scope("sec_lstm"):
pred, state_ = lstm(X) # pred输出值,state_是每一层的最后那个step的输出
print('pred,state_', pred, state_)
# 损失函数
# [-1]——列表从后往前数第一列,即pred为预测值,Y为真实值(Label)
#tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值
loss = tf.reduce_mean(tf.square(tf.reshape(pred, [-1]) - tf.reshape(Y, [-1])))
# 误差loss反向传播——均方误差损失
# 本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
# Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳.
train_op = tf.train.AdamOptimizer(lr).minimize(loss)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=15)
with tf.Session() as sess:
# 初始化
sess.run(tf.global_variables_initializer())
theloss = []
# 迭代次数
for i in range(200):
for step in range(len(batch_index) - 1):
# sess.run(b, feed_dict = replace_dict)
state_, loss_ = sess.run([train_op, loss],
feed_dict={X: train_x[batch_index[step]:batch_index[step + 1]],
Y: train_y[batch_index[step]:batch_index[step + 1]],
keep_prob: 0.5})
# 使用feed_dict完成矩阵乘法 处理多输入
# feed_dict的作用是给使用placeholder创建出来的tensor赋值
# [batch_index[step]: batch_index[step + 1]]这个区间的X与Y
# keep_prob的意思是:留下的神经元的概率,如果keep_prob为0的话, 就是让所有的神经元都失活。
print("Number of iterations:", i, " loss:", loss_)
theloss.append(loss_)
print("model_save: ", saver.save(sess, 'model_save2\\modle.ckpt'))
print("The train has finished")
return theloss
theloss = train_lstm()
# ————————————————预测模型————————————————————
def prediction(time_step=20):
X = tf.placeholder(tf.float32, shape=[None, time_step, input_size])
mean, std, test_x, test_y = get_test_data(time_step)
# 用tf.variable_scope来定义重复利用,LSTM会经常用到
with tf.variable_scope("sec_lstm", reuse=tf.AUTO_REUSE):
pred, state_ = lstm(X)
saver = tf.train.Saver(tf.global_variables())
with tf.Session() as sess:
# 参数恢复(读取已存在模型)
module_file = tf.train.latest_checkpoint('model_save2')
saver.restore(sess, module_file)
test_predict = []
for step in range(len(test_x) - 1):
predict = sess.run(pred, feed_dict={X: [test_x[step]], keep_prob: 1})
predict = predict.reshape((-1))
test_predict.extend(predict) # 把predict的内容添加到列表
# 相对误差=(测量值-计算值)/计算值×100%
test_y = np.array(test_y) * std[n1] + mean[n1]
test_predict = np.array(test_predict) * std[n1] + mean[n1]
acc = np.average(np.abs(test_predict - test_y[:len(test_predict)]) / test_y[:len(test_predict)])
print("预测的相对误差:", acc)
print(theloss)
plt.figure()
plt.plot(list(range(len(theloss))), theloss, color='b', )
plt.xlabel('times', fontsize=14)
plt.ylabel('loss valuet', fontsize=14)
plt.title('loss-----blue', fontsize=10)
plt.show()
# 以折线图表示预测结果
plt.figure()
plt.plot(list(range(len(test_predict))), test_predict, color='b', )
plt.plot(list(range(len(test_y))), test_y, color='r')
plt.xlabel('time value/day', fontsize=14)
plt.ylabel('close value/point', fontsize=14)
plt.title('predict-----blue,real-----red', fontsize=10)
plt.show()
prediction()
五、案例分析
1、数据说明
本实验分析了两种股票种类,为某单支股票(6109个连续时间点)数据data2上证综合指数前复权日线(6230个连续时间点,1991年到2016年)数据作为data2,分别保存在两个文件中,将两个数据集的最后一列设定为label。前90%数据作为训练集,后10%作为测试集。
Data1:
Data2:
本次实验所采用的为LSTM模型:
输入神经元个数 input_size = 选取列数
输出神经元个数 output_size = 1 (预测值个数)
学习率 lr = 0.0006
随机初始化初始化网络权重

2、数据预处理
零-均值规范化(z-score标准化):
标准化值,是讲集合中单个数与集合的均值相减的结果除以集合的标准差得到的标准化的结果,该方法类似与正态分布标准化转换,转换函数公式为:
公式中x为需要被标准化的原始值,μ为均值,σ为标准差,σ不等于0。
Z分数标准化处理后的值代表原始值和集合均值之间的举例,以标准差为单位计算。该值存在正负值,低于均值均为辅助,反之则为证书,其范围为[-∞,+∞],数据均值为0,方差为1。
3、损失函数
损失函数(Loss function)是用来估量网络模型的预测值X与真实值Y的不一致程度,它是一个非负实值函数,通常用 L(Y,f(x))来表示。损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数的重要组成部分。
本实验采取十分常用的均方误差损失:
平方损失也可以理解为是最小二乘法,一般在回归问题中比较常见,最小二乘法的基本原理是:最优拟合直线是使各点到回归直线的距离和最小的直线,即平方和最。同时在实际应用中,均方误差也经常被用为衡量模型的标准:
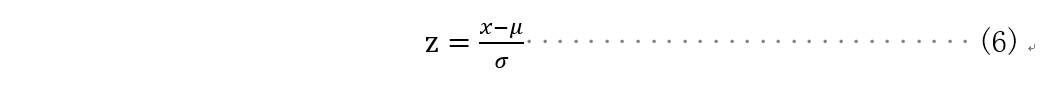
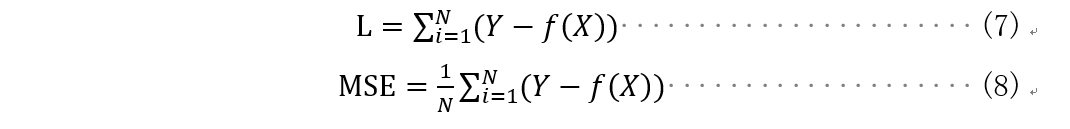
4、误差标准
相对偏差是指某一次测量的绝对偏差占平均值的百分比。
5、可视化UI



六、参数设置
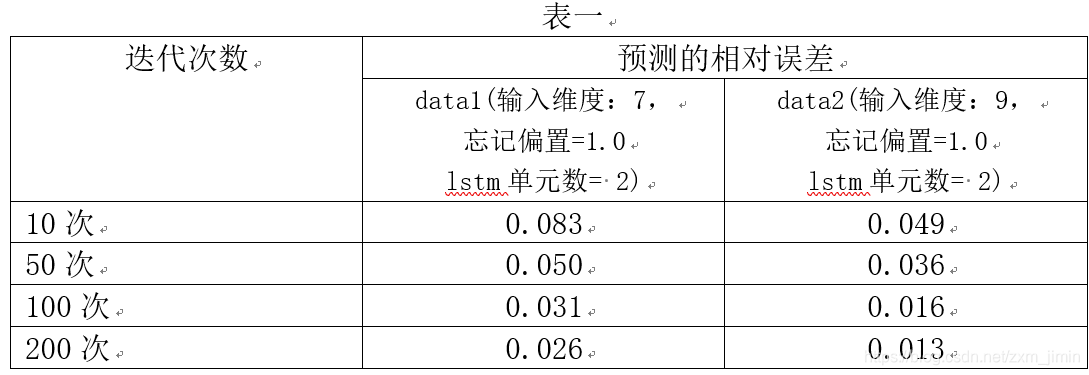
1、输入维度及迭代次数
由表一可见,输入维度越多,网络训练效果越好;迭代次数在100次时,网络已经比较稳定。
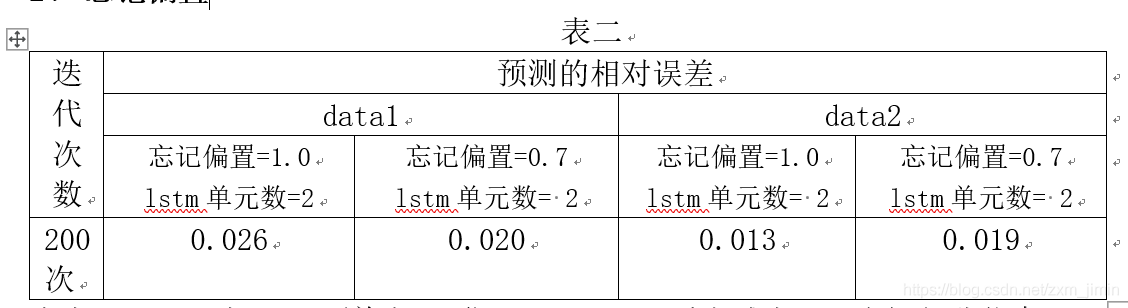
2、忘记偏置
由表二可见,在data1(单支股票)forget_bias适当减小,即忘记部分信息,网络训练效果有些许提高,但在data2(大盘)中,网络训练效果却有所下滑。个人认为,可能是因为对于单支股票来说,近2天的数据相关程度比较小,而在大盘中,因为近2天的数据相关程度比较大,毕竟有多方面因素影响股价。
3、LSTM单元数
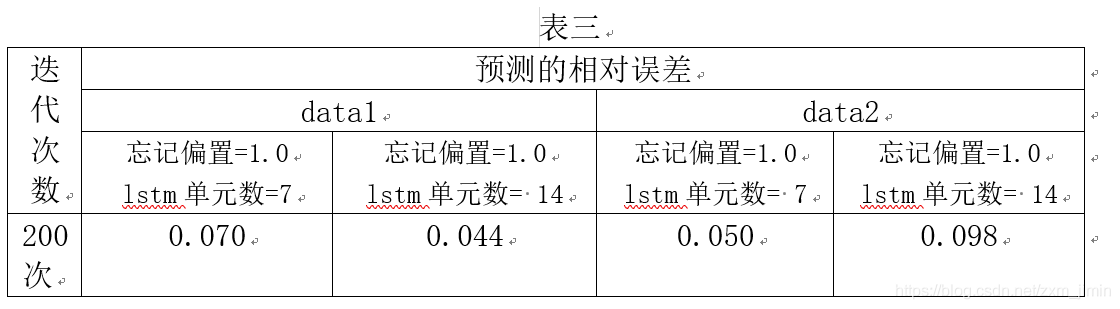
由表三可见,两个数据集中,LSTM单元数增加的情况下时,网络训练效果反而下降,可以看出,其实股票行情在7天内的的相关联程度比在14天内的情况高,但是有可能是因为forget_bias过大。因此,在进行一组实验,调整forget_bias值进行比较。
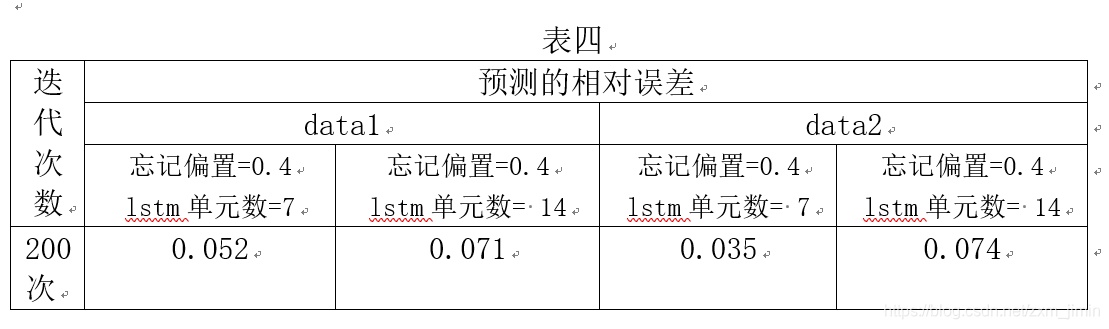
由表四可以看出,在相同LSTM单元数的情况下,forget_bias较小时,预测效果较好,我们可以看出,在LSTM单元数较大的情况下,forget_bias应选取比较小的,以免记忆太多无效信息。
由表五可以看出,在data1和data2两个数据集中,LSTM单元数较小的情况下,forget_bias比较大时,预测效果较好,记忆更多相关信息。因此LSTM单元数较小的情况下,forget_bias应选取比较大的,记忆更多相关信息。
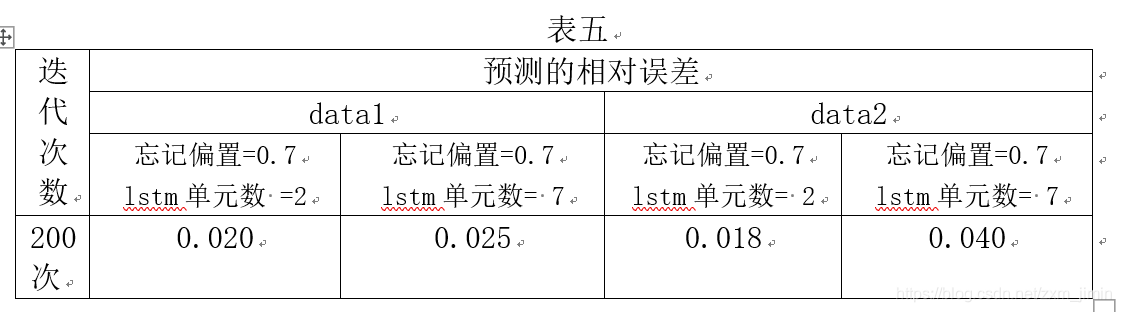
4、可视化结果
选取数据集data1,迭代次数为200次
(1)、忘记偏置=1.0 , LSTM单元数 = 2
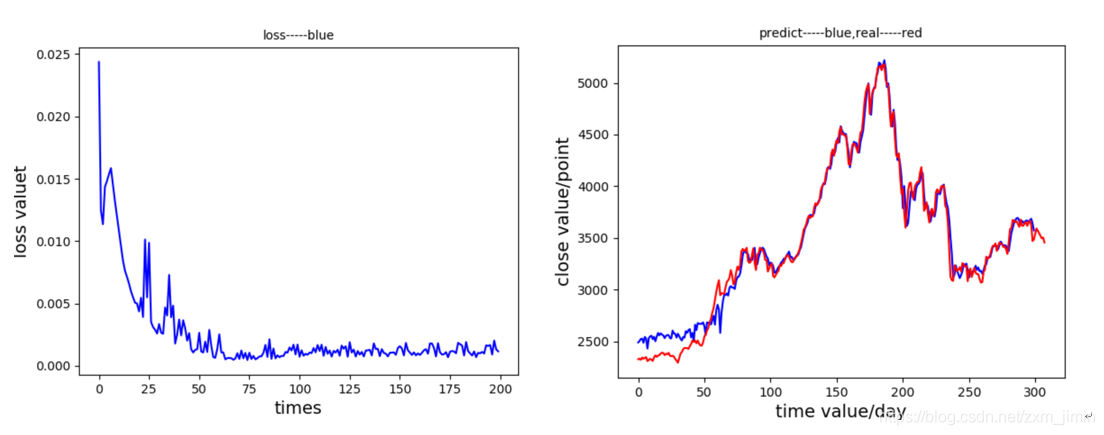
(2)、忘记偏置=0.7 , LSTM单元数 = 2(表现最好)
(3)、忘记偏置=1.0 , LSTM单元数 = 7
(4)、忘记偏置=1.0 , LSTM单元数 = 14


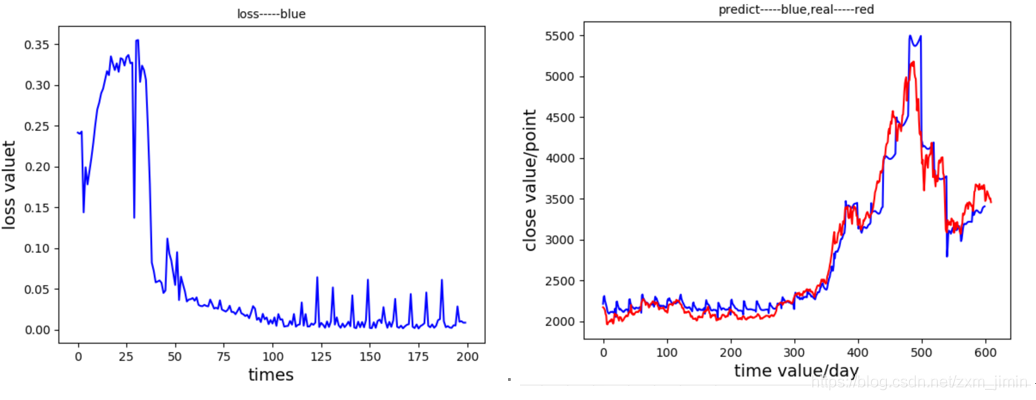
(5)、忘记偏置=0.7, LSTM单元数 = 7
(6)、忘记偏置=0.4 , LSTM单元数 = 7
(7)、忘记偏置=0.4 , LSTM单元数 = 14
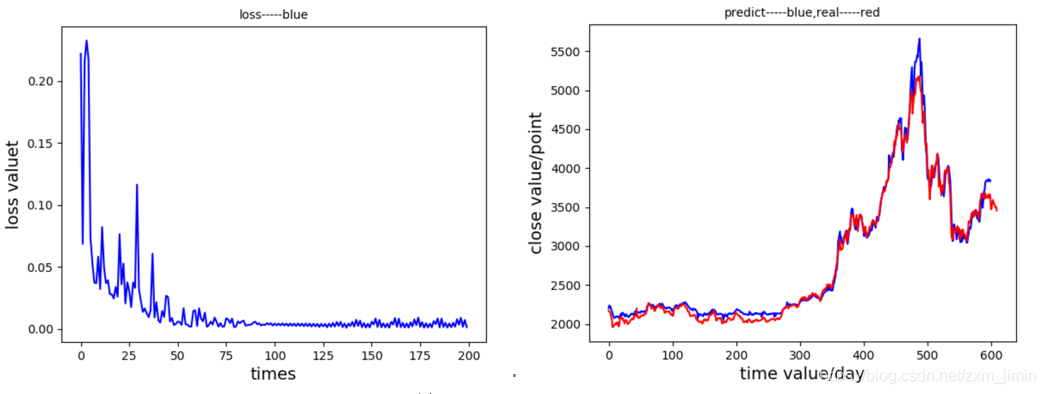
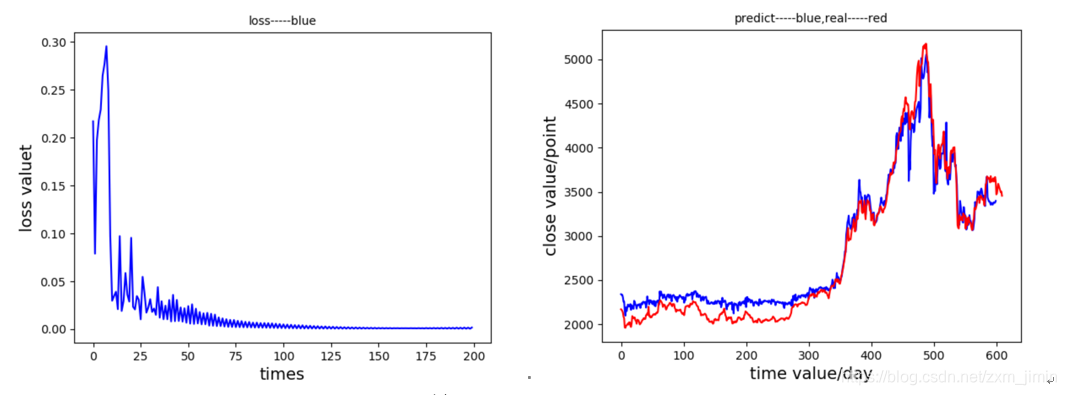

七、结论
针对以上实验,可以得知,在LSTM模型下的对股票收盘价预测值较为准确和稳定。对LSTM模型进行参数调整,发现迭代次数在100次后,网络模型趋于稳定,说明其是一个较轻量级的网络;在LSTM单元数较大的情况下,forget_bias应选取比较小的,以免记忆太多无效信息;LSTM单元数较小的情况下,forget_bias应选取比较大的,记忆更多相关信息。当然,这和本身的数据集有关。就股票数据集来说,本实验中表现的最优秀的是,忘记偏置为0.7,LSTM神经单元数取2时,网络预测效果最好,说明,在2天内股票序列是比较有价值的,与最后预测值有一定程度的联系。
运行环境

完整程序下载
注意,代码下载后仍需自行调试~
积分值为5(如果有变为csdn自行修改)——完整代码其实和上面贴出的差别不大,酌情下载~
https://download.csdn.net/download/zxm_jimin/12126063
参考文献
[1] 陈卫华. 基于深度学习的上证综指波动率预测效果比较研究[D].统计与信息论坛,2018.
[2] Hochreiter & Schmidhuber. Long short-term memory[ J]. Neural Computation, 1997, 9( 8).
参考博客
https://blog.csdn.net/jiaoyangwm/article/details/79725445
https://blog.csdn.net/mylove0414/article/details/56969181
感谢各位大佬看到最后~
本文为原创。转载请注明出处。
注:原理部分,参考了一些文章,博客,如有侵权请联系,我附上原出处。
智能推荐
在Google使用Borg进行大规模集群的管理 7-8-程序员宅基地
文章浏览阅读606次。为什么80%的码农都做不了架构师?>>> ..._google trace batch job
python加密字符串小写字母循环后错两位_python学习:实现将字符串进行加密-程序员宅基地
文章浏览阅读2.6k次,点赞3次,收藏3次。'''题目描述1、对输入的字符串进行加解密,并输出。2加密方法为:当内容是英文字母时则用该英文字母的后一个字母替换,同时字母变换大小写,如字母a时则替换为B;字母Z时则替换为a;当内容是数字时则把该数字加1,如0替换1,1替换2,9替换0;其他字符不做变化。s'''#-*-coding:utf-8-*-importre#判断是否是字母defisLetter(letter):iflen..._编写函数fun2实现字符串加密,加密规则为:如果是字母,将其进行大小写转换;如果
【Java容器源码】集合应用总结:迭代器&批量操作&线程安全问题_迭代器是否可以保证容器删除和修改安全操作-程序员宅基地
文章浏览阅读4.4k次,点赞6次,收藏8次。下面列出了所有集合的类图:每个接口做的事情非常明确,比如 Serializable,只负责序列化,Cloneable 只负责拷贝,Map 只负责定义 Map 的接口,整个图看起来虽然接口众多,但职责都很清晰;复杂功能通过接口的继承来实现,比如 ArrayList 通过实现了 Serializable、Cloneable、RandomAccess、AbstractList、List 等接口,从而拥有了序列化、拷贝、对数组各种操作定义等各种功能;上述类图只能看见继承的关系,组合的关系还看不出来,比如说_迭代器是否可以保证容器删除和修改安全操作
养老金融:编织中国老龄社会的金色安全网
在科技金融、绿色金融、普惠金融、养老金融、数字金融这“五篇大文章”中,养老金融以其独特的社会价值和深远影响,占据着不可或缺的地位。通过政策引导与市场机制的双重驱动,激发金融机构创新养老服务产品,如推出更多针对不同年龄层、风险偏好的个性化养老金融产品,不仅能提高金融服务的可获得性,还能增强民众对养老规划的主动参与度,从而逐步建立起适应中国国情、满足人民期待的养老金融服务体系。在人口老龄化的全球趋势下,中国养老金融的发展不仅仅是经济议题,更关乎社会的稳定与进步。养老金融:民生之需,国计之重。
iOS 创建开源库时如何使用图片和xib资源
在需要使用图片的地方使用下面的代码,注意xib可以直接设置图片。将相应的图片资源文件放到bundle文件中。
R语言学习笔记9_多元统计分析介绍_r语言多元统计分析-程序员宅基地
文章浏览阅读3.6k次,点赞4次,收藏66次。目录九、多元统计分析介绍九、多元统计分析介绍_r语言多元统计分析
随便推点
基于psk和dpsk的matlab仿真,MATLAB课程设计-基于PSK和DPSK的matlab仿真-程序员宅基地
文章浏览阅读623次。MATLAB课程设计-基于PSK和DPSK的matlab仿真 (41页) 本资源提供全文预览,点击全文预览即可全文预览,如果喜欢文档就下载吧,查找使用更方便哦!9.90 积分武汉理工大学MATLAB课程设计.目录摘要 1Abstract 21.设计目的与要求 32.方案的选择 42.1调制部分 42.2解调部分 43.单元电路原理和设计 63.1PCM编码原理及设计 63.1.1PCM编码原理 ..._通信原理课程设计(基于matlab的psk,dpsk仿真)(五篇模版)
腾讯微搭小程序获取微信用户信息_微搭 用微信号登录-程序员宅基地
文章浏览阅读3.5k次,点赞6次,收藏28次。腾讯微搭小程序获取微信用户信息无论你对低代码开发的爱与恨, 微信生态的强大毋庸置疑. 因此熟悉微搭技术还是很有必要的! 在大多数应用中, 都需要获取和跟踪用户信息. 本文就微搭中如何获取和存储用户信息进行详细演示, 因为用户信息的获取和存储是应用的基础.一. 微搭每个微搭平台都宣称使用微搭平台可以简单拖拽即可生成一个应用, 这种说法我认为是"夸大其词". 其实微搭优点大致来说, 前端定义了很多组件, 为开发人员封装组件节省了大量的时间,这是其一; 其二对后端开发来说, 省去了服务器的部署(并没有省去后_微搭 用微信号登录
sql中索引的使用分析
sql中索引的使用分析
termux安装metasploit()-程序员宅基地
文章浏览阅读8.9k次,点赞16次,收藏108次。因为呢,termux作者,不希望让termux变成脚本小子的黑客工具,于是把msf , sqlmap等包删了。至于如何安装metasploit呢。apt update -y && apt upgrade -y #更新升级更新升级之后要安装一个叫 git 的安装包apt install git -y然后我们就开始//这里的话建议把手机放到路由器旁边,保持网络的优良。或者科学上网。//git clone https://github.com/gushmazuko/metaspl_termux安装metasploit
armbian docker Chrome_一起学docker06-docker网络-程序员宅基地
文章浏览阅读141次。一、Docker支持4种网络模式Bridge(默认)--network默认网络,Docker启动后创建一个docker0网桥,默认创建的容器也是添加到这个网桥中;IP地址段是172.17.0.1/16 独立名称空间 docker0桥,虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。host容器不会获得一个独立的network namespace,而是与宿主..._armbian 172.17.0.1
Ansible-Tower安装破解
Ansible-Tower安装破解。