Python爬虫超详细讲解(零基础入门,老年人都看的懂)-程序员宅基地
如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。
利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:
1.爬取数据,进行市场调研和商业分析。
爬取知乎优质答案,为你筛选出各话题下最优质的内容。 抓取房产网站买卖信息,分析房价变化趋势、做不同区域的房价分析。爬取招聘网站各类职位信息,分析各行业人才需求情况及薪资水平。
2.作为机器学习、数据挖掘的原始数据。
比如你要做一个推荐系统,那么你可以去爬取更多维度的数据,做出更好的模型。
3.爬取优质的资源:
图片、文本、视频爬取知乎钓鱼贴\图片网站,获得福利图片。
这些事情,原本我们也是可以手动完成的,但如果是单纯地复制粘贴,非常耗费时间,比如你想获取100万行的数据,大约需忘寝废食重复工作两年。而爬虫可以在一天之内帮你完成,而且完全不需要任何干预。
对于小白来说,爬虫可能是一件非常复杂、技术门槛很高的事情。比如有的人认为学爬虫必须精通 Python,然后哼哧哼哧系统学习 Python 的每个知识点,很久之后发现仍然爬不了数据;有的人则认为先要掌握网页的知识,遂开始 HTML\CSS,结果入了前端的坑,瘁……
但掌握正确的方法,在短时间内做到能够爬取主流网站的数据,其实非常容易实现。但建议你从一开始就要有一个具体的目标,你要爬取哪个网站的哪些数据,达到什么量级。
在目标的驱动下,你的学习才会更加精准和高效。那些所有你认为必须的前置知识,都是可以在完成目标的过程中学到的。这里给你一条平滑的、零基础快速入门的学习路径。
1.了解爬虫的基本原理及过程
2.Requests+Xpath 实现通用爬虫套路
3.了解非结构化数据的存储
4.学习scrapy,搭建工程化爬虫
5.学习数据库知识,应对大规模数据存储与提取
6.掌握各种技巧,应对特殊网站的反爬措施
7.分布式爬虫,实现大规模并发采集,提升效率
1.了解爬虫的基本原理及过程
大部分爬虫都是按“发送请求——获得页面——解析页面——抽取并储存内容”这样的流程来进行,这其实也是模拟了我们使用浏览器获取网页信息的过程。
简单来说,我们向服务器发送请求后,会得到返回的页面,通过解析页面之后,我们可以抽取我们想要的那部分信息,并存储在指定的文档或数据库中。
在这部分你可以简单了解 HTTP 协议及网页基础知识,比如 POST\GET、HTML、CSS、JS,简单了解即可,不需要系统学习。
2.学习 Python 包并实现基本的爬虫过程
Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,建议你从requests+Xpath 开始,requests 负责连接网站,返回网页,Xpath 用于解析网页,便于抽取数据。
如果你用过 BeautifulSoup,会发现 Xpath 要省事不少,一层一层检查元素代码的工作,全都省略了。掌握之后,你会发现爬虫的基本套路都差不多,一般的静态网站根本不在话下,小猪、豆瓣、糗事百科、腾讯新闻等基本上都可以上手了。
来看一个爬取豆瓣短评的例子:
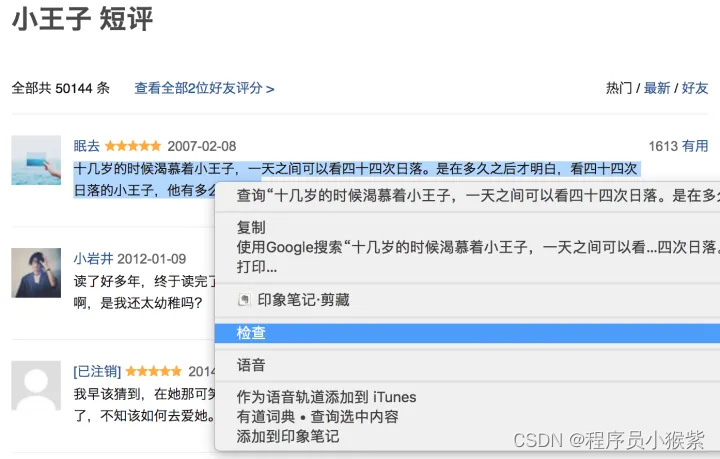
选中第一条短评,右键-“检查”,即可查看源代码
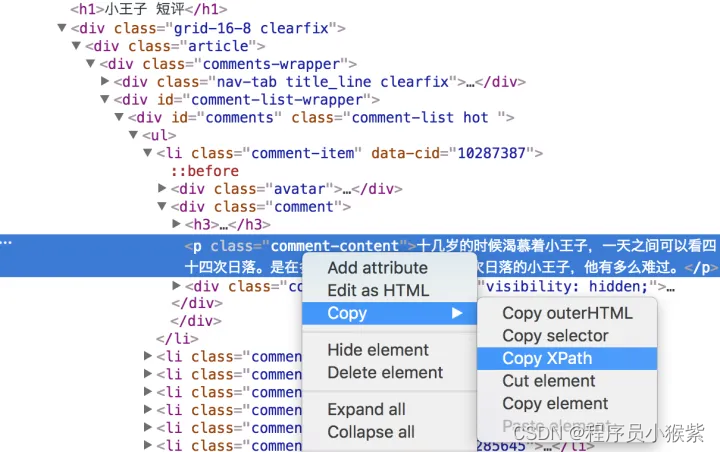
我们通过定位,得到了第一条短评的XPath信息:
//*[@id="comments"]/ul/li[1]/div[2]/p
但是通常我们会想爬取很多条短评,那么我们会想获取很多这样的XPath信息:
//*[@id="comments"]/ul/li[1]/div[2]/p
//*[@id="comments"]/ul/li[2]/div[2]/p
//*[@id="comments"]/ul/li[3]/div[2]/p
………………………………
观察1、2、2条短评的XPath信息,你会发现规律,只有
-
后面的序号不一样,恰好与短评的序号相对应。那如果我们想爬取这个页面所有的短评信息,那么不要这个序号就好了呀。
-
通过XPath信息,我们就可以用简单的代码将其爬取下来了:
import requests from lxml import etree #我们邀抓取的页面链接 url='https://book.douban.com/subject/1084336/comments/' #用requests库的get方法下载网页 r=requests.get(url).text #解析网页并且定位短评 s=etree.HTML(r) file=s.xpath('//*[@id="comments"]/ul/li/div[2]/p/text()') #打印抓取的信息 print(file)
爬取的该页面所有的短评信息当然如果你需要爬取异步加载的网站,可以学习浏览器抓包分析真实请求或者学习Selenium来实现自动化,这样,知乎、时光网、猫途鹰这些动态的网站也基本没问题了。
这个过程中你还需要了解一些Python的基础知识:
文件读写操作:用来读取参数、保存爬下来的内容
list(列表)、dict(字典):用来序列化爬取的数据
条件判断(if/else):解决爬虫中的判断是否执行
循环和迭代(for ……while):用来循环爬虫步骤
3.了解非结构化数据的存储
爬回来的数据可以直接用文档形式存在本地,也可以存入数据库中。
开始数据量不大的时候,你可以直接通过 Python 的语法或 pandas 的方法将数据存为text、csv这样的文件。还是延续上面的例子:用Python的基础语言实现存储:
with open('pinglun.text','w',encoding='utf-8') as f: for i in file: print(i) f.write(i)用pandas的语言来存储:
#import pandas as pd #df = pd.DataFrame(file) #df.to_excel('pinglun.xlsx')这两段代码都可将爬下来的短评信息存储起来,把代码贴在爬取代码后面即可。

存储的该页的短评数据当然你可能发现爬回来的数据并不是干净的,可能会有缺失、错误等等,你还需要对数据进行清洗,可以学习 pandas 包的基本用法来做数据的预处理,得到更干净的数据。以下知识点掌握就好:
- 缺失值处理:对缺失数据行进行删除或填充
- 重复值处理:重复值的判断与删除
- 空格和异常值处理:清楚不必要的空格和极端、异常数据
- 分组:数据划分、分别执行函数、数据重组
4.掌握各种技巧,应对特殊网站的反爬措施
爬取一个页面的的数据是没问题了,但是我们通常是想爬取多个页面啊。
这个时候就要看看在翻页的时候url是如何变化了,还是以短评的页面为例,我们来看多个页面的url有什么不同:https://book.douban.com/subject/1084336/comments/ https://book.douban.com/subject/1084336/comments/hot?p=2 https://book.douban.com/subject/1084336/comments/hot?p=3 https://book.douban.com/subject/1084336/comments/hot?p=4 ……………………通过前四个页面,我们就能够发现规律了,不同的页面,只是在最后标记了页面的序号。我们以爬取5个页面为例,写一个循环更新页面地址就好了。
for a in range(5): url="http://book.douban.com/subject/1084336/comments/hot?p={}".format(a)当然,爬虫过程中也会经历一些绝望啊,比如被网站封IP、比如各种奇怪的验证码、userAgent访问限制、各种动态加载等等。
遇到这些反爬虫的手段,当然还需要一些高级的技巧来应对,常规的比如访问频率控制、使用代理IP池、抓包、验证码的OCR处理等等。
比如我们经常发现有的网站翻页后url并不变化,这通常就是异步加载。我们用开发者工具取分析网页加载信息,通常能够得到意外的收获。

通过开发者工具分析加载的信息比如很多时候如果我们发现网页不能通过代码访问,可以尝试加入userAgent 信息。

浏览器中的userAgent信息

在代码中加入userAgent信息往往网站在高效开发和反爬虫之间会偏向前者,这也为爬虫提供了空间,掌握这些应对反爬虫的技巧,绝大部分的网站已经难不到你了。
5.学习爬虫框架,搭建工程化的爬虫
掌握前面的技术一般量级的数据和代码基本没有问题了,但是在遇到非常复杂的情况,可能仍然会力不从心,这个时候,强大的 scrapy 框架就非常有用了。
scrapy 是一个功能非常强大的爬虫框架,它不仅能便捷地构建request,还有强大的 selector 能够方便地解析 response,然而它最让人惊喜的还是它超高的性能,让你可以将爬虫工程化、模块化。
学会 scrapy,你可以自己去搭建一些爬虫框架,你就基本具备爬虫工程师的思维了。6.学习数据库基础,应对大规模数据存储
爬回来的数据量小的时候,你可以用文档的形式来存储,一旦数据量大了,这就有点行不通了。所以掌握一种数据库是必须的,学习目前比较主流的 MongoDB 就OK。
MongoDB 可以方便你去存储一些非结构化的数据,比如各种评论的文本,图片的链接等等。你也可以利用PyMongo,更方便地在Python中操作MongoDB。
因为这里要用到的数据库知识其实非常简单,主要是数据如何入库、如何进行提取,在需要的时候再学习就行。7.分布式爬虫,实现大规模并发采集
爬取基本数据已经不是问题了,你的瓶颈会集中到爬取海量数据的效率。这个时候,相信你会很自然地接触到一个很厉害的名字:分布式爬虫。
分布式这个东西,听起来非常吓人,但其实就是利用多线程的原理让多个爬虫同时工作,需要你掌握 Scrapy + MongoDB + Redis 这三种工具。
Scrapy 前面我们说过了,用于做基本的页面爬取,MongoDB 用于存储爬取的数据,Redis 则用来存储要爬取的网页队列,也就是任务队列。
所以不要被有些看起来很高深的东西吓到了。当你能够写分布式的爬虫的时候,那么你可以去尝试打造一些基本的爬虫架构了,实现一些更加自动化的数据获取。
你看,这一条学习路径下来,你已然可以成为老司机了,非常的顺畅。所以在一开始的时候,尽量不要系统地去啃一些东西,找一个实际的项目(开始可以从豆瓣、小猪这种简单的入手),直接开始就好。
因为爬虫这种技术,既不需要你系统地精通一门语言,也不需要多么高深的数据库技术,高效的姿势就是从实际的项目中去学习这些零散的知识点,你能保证每次学到的都是最需要的那部分。
当然唯一困难的是,刚开始没有经验的时候,在寻找资源、搜索解决问题的方法时总会遇到一些困难,因为往往在最开始,我们去描述清楚具体的问题都很难。如果有大神帮忙指出学习的路径和解答疑问,效率会高不少。
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

Python学习视频600合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
Python70个实战练手案例&源码
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

Python大厂面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


Python副业兼职路线&方法
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】

智能推荐
PCB设计--PCB画图技巧_pcb怎么画斜线-程序员宅基地
文章浏览阅读7.1k次,点赞7次,收藏37次。1、原理图库可以随便画,只要相应的相应的管脚有就可以2、原理图库的管脚标数和pcb图库的管脚是一一对应的3、画pcb图库的时候,元件的长宽要适当,可以设置格子的大小来便于设置画出pcb图库的大小。管脚的标数是和原理图库是一一对应的。4、画原理图库的时候,元件必须摆放在画板中心,再保存。否则话pcb原理图的时候,器件总是拖不进去。5、画pcb图库的时候要设置参考点,否则在生成的印制电..._pcb怎么画斜线
Mask-RCNN出现的问题_valueerror: dimension 1 in both shapes must be equ-程序员宅基地
文章浏览阅读630次。出现问题:ValueError: Dimension 1 in both shapes must be equal, but are 28 and 324. Shapes are [1024,28] and [1024,324]. for ‘Assign_682’ (op: ‘Assign’) with input shapes: [1024,28], [1024,324].这是由于维度的原因不同所造成。修改了train.py 的第60行成功!如果还未成功,看几个地方是否一样:1 train._valueerror: dimension 1 in both shapes must be equal, but are 324 and 12. sh
将Ajax请求返回的json数据,转换成json对象-程序员宅基地
文章浏览阅读1.1w次。var json = eval("("+data+")");//将json类型字符串转换为json对象注:https://www.cnblogs.com/yuxiaona/p/5853732.html
线性空间(也叫向量空间)、线性运算_线性空间定义-程序员宅基地
文章浏览阅读793次,点赞7次,收藏9次。线性空间(也叫向量空间)、线性运算_线性空间定义
pychram中更换pip源_pycharm更换pip源-程序员宅基地
文章浏览阅读1.1k次。2、pip config set global.index-url http://mirrors.aliyun.com/pypi/simple/ #修改配置文件。原本的pip源一般为国外源,在下载第三方库的速度很慢,更改pip源可以快速提高下载速度。清华大学:https://pypi.tuna.tsinghua.edu.cn/simple。阿里云:http://mirrors.aliyun.com/pypi/simple。豆瓣:http://pypi.douban.com/simple。_pycharm更换pip源
vue项目中(vue-cli3)代理配置不成功 及 axios的 baseUrl 设置无效问题_axios加上baseurl反向代理就不生效-程序员宅基地
文章浏览阅读1.3w次,点赞9次,收藏35次。最近开发项目时配置代理过程中遇到一个非常低级的错误,导致配置完代理后,项目运行请求接口一直是404;并同时因为这个低级错误,自己对前端vue项目的代理配置又混乱,直至发现问题后才对代理配置清晰明了起来。本文简单记录问题解决方式及自己对vue项目中的代理配置一点小理解,避免日后再次踩坑。vue项目中涉及的文件简单描述:1、该项目的后台的服务地址为:http://10.10.10.10/aa2、现在请求一个后台的验证码接口为: /code/img3、vue项目中环境配置(.env.developme._axios加上baseurl反向代理就不生效
随便推点
C语言常见程序讲解,适合初学者快速入门!_简单的c语言代码解析-程序员宅基地
文章浏览阅读936次。之前发了很多有关C/C++项目的文章。但是对于C语言的学习,需要自己亲自敲一些代码才能够学好C语言。在这里讲解一下简单的C语言程序(代码),希望自己能够在自己的电脑上敲几遍。a与b的算术运算描述:输出a和b的初始化值的简单算术运算。代码:输出结果:分析:printf函数是将双引号中的内容输出到弹出框中,其中因为a和b的数据类型都是int型,所以运算结果都要用%d的形式输..._简单的c语言代码解析
python中kmeans求到类中心的平均距离_k-means算法python实现-程序员宅基地
文章浏览阅读3.8k次。1.k-means算法的思想k-means算法是一种非监督学习方式,没有目标值,是一种聚类算法,因此要把数据划分成k个类别,那么一般k是知道的。那么假设k=3,聚类过程如下:随机在数据当中抽取三个样本,当做三个类别的中心点(k1,k2,k3);计算其余点(除3个中心点之外的点)到这三个中心点的距离,每一个样本应该有三个距离(a,b,c),然后选出与自己距离最近的中心点作为自己的标记,形成三个簇群;..._kmeans 计算类内平均距离
CSS Material+Icons 本地下载使用 国内解决方案_material icons 无法访问-程序员宅基地
文章浏览阅读1.7k次。前端使用<link href="https://fonts.googleapis.com/css2?family=Material+Icons" rel="stylesheet">由于访问fonts.googleapis.com不稳定,所以经常出现图标访问不到_material icons 无法访问
java中使用mysql查询 条件中含有中文时查询不到结果_Mybatis使用MySQL模糊查询时输入中文检索不到结果怎么办...-程序员宅基地
文章浏览阅读647次。项目开发中,在做mybatis动态查询时,遇到了一个问题:mysql在进行like模糊查询时,输入英文可以正常检索出结果,但是输入中文后检索得到的结果为空。由于是使用get方式请求,所以为了确保中文不乱码,在控制台接收到请求参数后,对中文进行了一次编码。try {realname = new string(realname.getbytes("gbk"), "utf-8");} catch (un..._通过java查询mysql 模糊查询中文失效
MFC中线程间通信--主线程与子线程间的通信_mfc中主进程和子线程共享数据-程序员宅基地
文章浏览阅读1.8k次。第0步:声明一个线程、一个事件CWinThread* m_hThread; //接收线程的句柄HANDLE hStartEven; //第一步:定义自己的消息#define MY_MESSAGE WM_USER+100第二步:在发送消息的线程中//得到需要传输的数据 CString str; GetDlgItemText..._mfc中主进程和子线程共享数据
2020年第二届“网鼎杯”网络安全大赛 白虎组 部分题目Writeup_网鼎杯网络安全大赛比赛题目-程序员宅基地
文章浏览阅读7.7k次,点赞3次,收藏12次。2020年第二届“网鼎杯”网络安全大赛 白虎组 部分题目Writeup2020年网鼎杯白虎组赛题.zip下载https://download.csdn.net/download/jameswhite2417/124212670x00 签到操作内容:完成游戏,通过第7关,让提交队伍token值提交后获得flag通过qq截图,文字识别FLAG值:flag{f6e5************************3112}0x01 hidden操作内容:.._网鼎杯网络安全大赛比赛题目