哈工大深度学习体系结构课程 |实验3:基于LSTM的MNIST手写数字识别加速-程序员宅基地
点击蓝字关注我们
关注、星标公众号,精彩内容每日送达
来源:网络素材文档为哈尔滨工业大学(深圳)《深度学习体系结构》2021年秋季课程的实验指导材料。
原文档地址 :
https://hitsz-cslab.gitee.io/dla
示例工程地址 :
https://gitee.com/hitsz-cslab/dla
实验3:基于LSTM的MNIST手写数字识别加速
实验目的
1. 加深对循环神经网络RNN基本原理的理解;
2. 了解LSTM识别手写数字的基本原理;
3. 掌握使用HLS设计实现LSTM硬件加速器的基本流程和方法。
实验内容
本实验要求设计实现LSTM的硬件加速器,具体包括:
1. 使用HLS编写LSTM Cell、Sigmoid函数、Tanh函数、向量加法等函数,并综合、打包生成
RNN加速IP核;
2. 在Vivado中构建Block Design电路图,生成比特流并导出Overlay;
3. 上板测试,观察并对比分析RNN软件推导和硬件推导的差别。
实验原理
循环神经网络(Recurrent Neural Network, RNN)是一类专门用于处理序列型数据(如文本、语音等)的神经网络。传统的RNN因为梯度弥散等问题对长序列的预测结果不甚理想,各方学者对此展开了研究和优化。其中,最具代表性的就是长短期记忆(Long Short-Term Memory, LSTM)神经网络。接下来将从传统RNN到LSTM,介绍循环神经网络的基本原理和网络结构。
1. RNN简介
1.1 RNN原理简介
假设有一个多层感知机(Multi-Layer Perceptron, MLP),现在将一个时间上连续的输入序列依次添加到MLP的每一个隐藏层,得到图1-1(a)所示的网络。此时,如果令所有隐藏层的权值和参数都相同,如图1-1(b)所示,则可以将所有隐藏层在时间上“折叠”起来,形成循环层,于是得到如图1-1(c)所示的循环神经网络。
 (a) MLP (b) 隐藏层的参数都相同 (c) 形成循环层图1-1 从MLP到RNN
(a) MLP (b) 隐藏层的参数都相同 (c) 形成循环层图1-1 从MLP到RNN
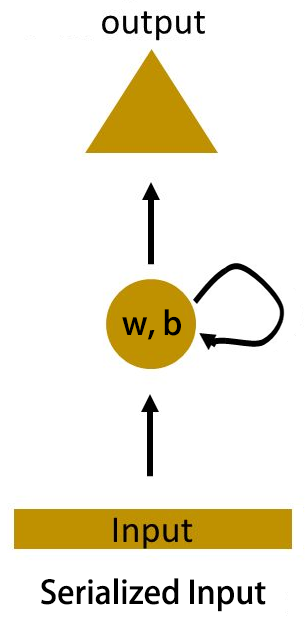
图1-1(c)中的循环层也被称作是RNN的循环神经元或Cell。一般地,可用图1-2所示的结构来简化表示RNN的网络结构。
 图1-2 RNN网络结构
图1-2 RNN网络结构
图1-2所示的RNN神经网络,其Cell所产生的输出随着输入的变化而变化。若输入随时间变化而变化,则Cell的输出也随着时间发生相应的变化。假设Cell在t时刻接收的输入是xxt���,产生的输出是hhtℎℎ�,则可得式(1-1)所示的简单模型:

其中,hht−1ℎℎ�−1是Cell在上一个时刻的输出。
进一步地,假设输入hht−1ℎℎ�−1的权值是WWhh��ℎℎ、输入xxt���的权值是WWxh���ℎ,偏置量是bb��,激活函数记为activation(),则可将式(1-1)改写为式(1-2):
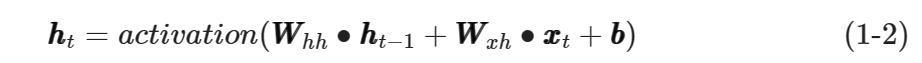
输入结束后,RNN网络也随之计算得出最终的输出结果。假设Cell的输出hhtℎℎ�的权值是WWhy��ℎ�,则RNN的输出yyt���如式(1-3)所示。

总结RNN的计算步骤如下:
Step1: 将待预测数据xxt���输入到RNN网络当中;
Step2: 基于式(1-2),利用输入xxt���和Cell在前一时刻的输出hht−1ℎℎ�−1,计算hhtℎℎ�;
Step3: 若数据输入完毕,基于式(1-3)计算网络输出;否则,t=t+1,转Step1。
1.2 RNN的反向传播
为了方便理解RNN的通过时间的反向传播(Back Propagation Through Time, BPTT),首先将RNN展开,如图1-3所示。
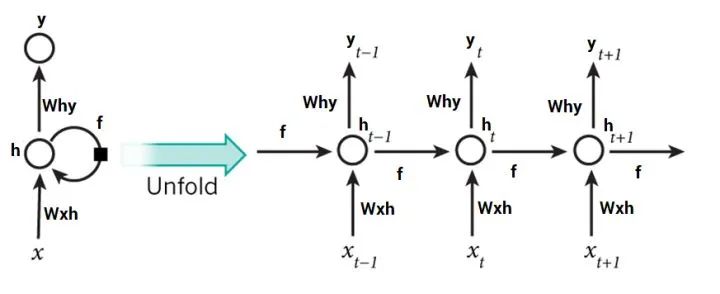
将RNN展开后,图1-3右侧的每一个圆圈都代表了左侧的RNN Cell在不同时间节点的状态。
前向传播时,RNN按照输入序列的内部顺序,在每个时间节点处读取并处理序列中的一个数据。反向传播时,需要反过来对各个时间节点上的网络权值进行更新,故而将RNN的反向传播称为通过时间的反向传播。
假设yyt���是RNN网络在t时刻输出的预测值,而yŷt��̂�是实际真实值,则可用交叉熵来计算误差,如式(1-4)所示。
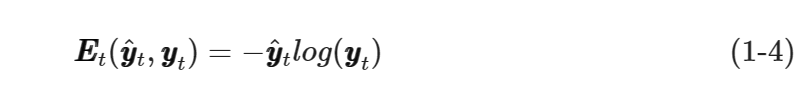
)
将所有时间节点的误差进行累加,即可得到总体误差,如式(1-5)所示。

基于式(1-4)和式(1-5),可将RNN的BPTT过程简述为:
Step1: 基于式(1-5)所示的交叉熵公式计算误差;
Step2: 将RNN按照时间节点完全展开;
Step3: 计算展开后每个时间节点上Cell的网络权值梯度;
Step4: 使用Step3计算得到的梯度更新Cell的权值。
1.3 梯度消失与梯度爆炸问题
RNN的原理使得其预测结果依赖于RNN Cell在所有时间节点上的状态。时间节点数越多,网络权值的更新越难。现在,考虑一个具有三个时间节点的RNN Cell,其网络权值梯度的计算需要使用链式求导,如式(1-6)所示。
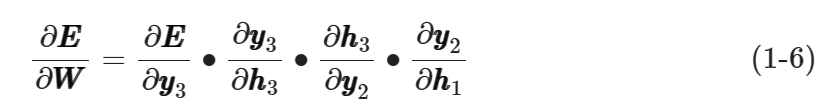
如果式(1-6)中存在某个接近0的乘积项,则计算出的所有梯度都会接近于0,而其他时间节点的梯度更是以指数速率降低为0,于是便出现了梯度消失问题,如图1-4所示。显然,梯度消失问题不利于RNN网络对较长输入序列的学习。
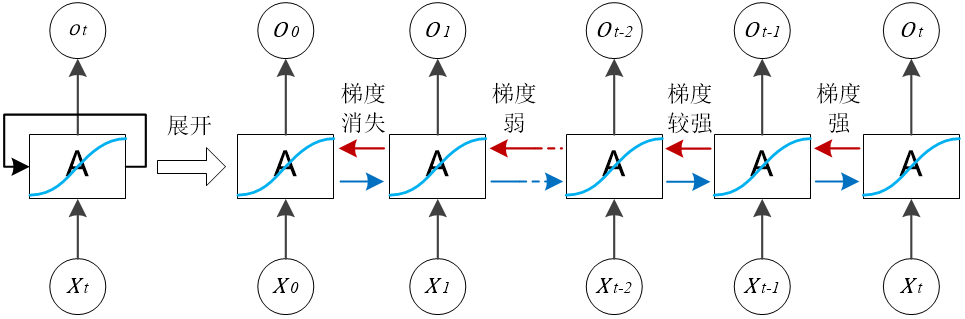 图1-4 梯度消失示意图
图1-4 梯度消失示意图
类似地,梯度爆炸问题是梯度值因为时间节点增多而容易变得非常大的问题。一般地,可以通过设定阈值的方法解决梯度爆炸问题,因此对RNN的训练而言,如何解决梯度消失问题显得更为关键。
为了解决梯度消失问题,Sepp Hochreiter和Ju ̈rgen Schmidhuber在1997年提出了LSTM,为人工智能领域作出了教科书级的贡献。
2. LSTM原理简述
在图1-2所示的RNN网络结构中,Cell只能存储当前时刻的输出hhtℎℎ�,因而对短期的输入比较敏感。为了增加RNN对长期输入(或长序列输入)的预测效果,现在给Cell增加一个变量CCt���,用于存储Cell的当前状态,并由此形成LSTM Cell,如图1-5所示。其中,CCt���被称为单元状态(Cell State)。
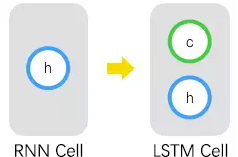 图1-5 RNN Cell的改进
图1-5 RNN Cell的改进
同样地,可将图1-5所示的LSTM Cell按时间展开,得到如图1-6所示的结构。
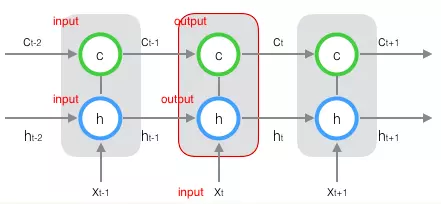 图1-6 展开的LSTM Cell
图1-6 展开的LSTM Cell
观察图1-6中时刻t所对应的LSTM Cell,可知在时刻t,Cell接受三个输入,分别是当前时刻的外部输入xxt���、前一时刻的输出hht−1ℎℎ�−1与单元状态CCt−1���−1;产生两个输出,分别是当前时刻的对外输出hhtℎℎ�与单元状态CCt���。
传统的RNN Cell只能存储当前时刻的输出hhtℎℎ�。LSTM Cell在RNN Cell的基础上增加了遗忘门、输入门、输出门等子结构,如图1-7所示。
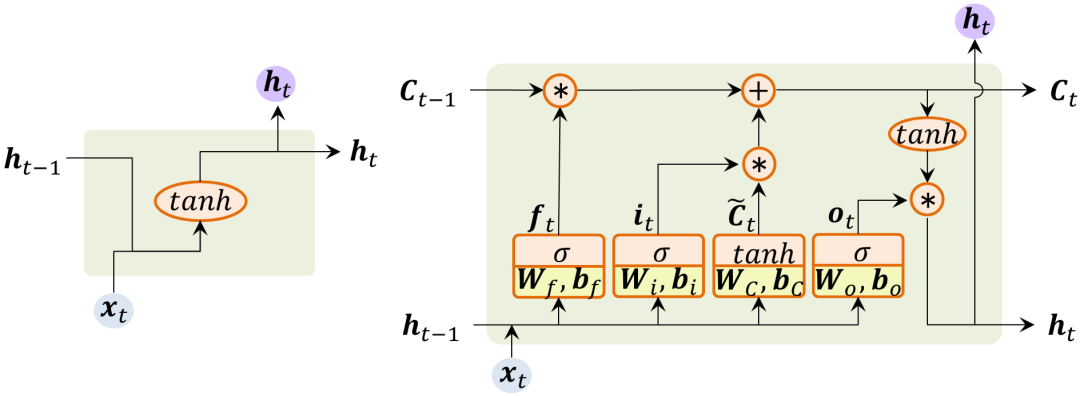 (a) 传统RNN Cell的结构 (b) LSTM Cell的结构 图1-7 RNN结构的演化
(a) 传统RNN Cell的结构 (b) LSTM Cell的结构 图1-7 RNN结构的演化
接下来,逐一介绍LSTM Cell的遗忘门、输入门、输出门以及状态产生逻辑和输出逻辑,如图1-8所示。
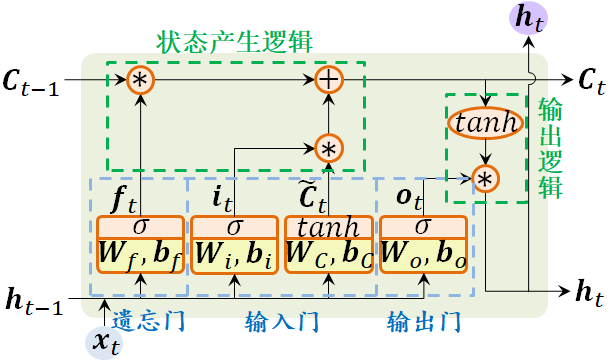 图1-8 LSTM Cell结构组成
图1-8 LSTM Cell结构组成
遗忘门(Forget Gate)
遗忘门的输入是hht−1ℎℎ�−1与xxt���拼接后得到的向量[hht−1,xxt][ℎℎ�−1,���],输出fft���被称为遗忘门的输出控制向量,用于控制Cell对上一个单元状态CCt−1���−1的遗忘程度。
根据图1-8中的遗忘门结构,可得到遗忘门输出向量fft���的计算公式如式(1-7)所示。
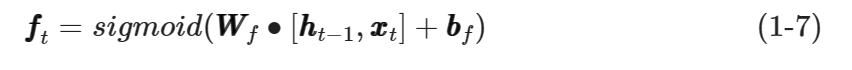
其中,WWf���和bbf���分别是遗忘门的权值矩阵和偏置向量。
输入门(Input Gate)
输入门的输入是hht−1ℎℎ�−1与xxt���拼接后得到的向量[hht−1,xxt][ℎℎ�−1,���],输出iit���被称为输入门的输出控制向量,用于控制Cell的新状态的产生。
根据图1-8中的输入门结构,可得到输入门输出向量iit���的计算公式如式(1-8)所示。
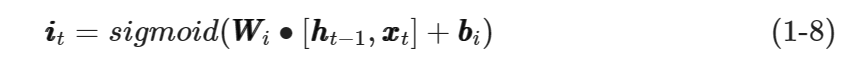
其中,WWi���和bbi���分别是输入门的权值矩阵和偏置向量。
此外,输入门根据向量[hht−1,xxt][ℎℎ�−1,���]产生候选状态向量CC̃t��̃�,用于给Cell产生新的单元状态。
根据图1-8中的输入门结构,可得到输入门产生的候选状态向量CC̃t��̃�的计算公式如式(1-9)所示。
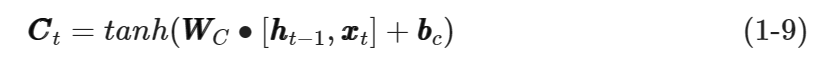
其中,WWC���和bbc���分别是候选状态向量的权值矩阵和偏置向量。
输出门(Output Gate)
输出门的输入是hht−1ℎℎ�−1与xxt���拼接后得到的向量[hht−1,xxt][ℎℎ�−1,���],输出oot���被称为输出门的输出控制向量,用于控制Cell输出向量hhtℎℎ�的产生。
根据图1-8中的输出门结构,可得到输出门输出向量oot���的计算公式如式(1-10)所示。
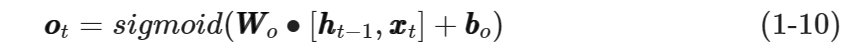
其中,WWo���和bbo���分别是输入门的权值矩阵和偏置向量。
状态产生逻辑
状态产生逻辑根据Cell的上一个单元状态CCt−1���−1、遗忘门产生的控制向量fft���、输入门产生的控制向量iit���以及候选状态向量CC̃t��̃�,产生新的单元状态CCt���。
根据图1-8中的状态产生逻辑,可得到新的单元状态CCt���的计算公式如式(1-11)所示。

其中,∗∗表示向量的 Hadamard 积。
补充说明
向量 Hadamard 积的定义:
设有维度相同的向量aa={
a1,a2,⋯,an}��={�1,�2,⋯,��}和向量bb={
b1,b2,⋯,bn}��={�1,�2,⋯,��},则有:
输出逻辑
输出逻辑根据Cell的新状态CCt���和输出门的控制向量oot���,产生LSTM Cell的对外输出向量hhtℎℎ�。
根据图1-8所示的输出逻辑,可得到Cell的输出向量hhtℎℎ�的计算公式如式(1-12)所示。

观察式(1-7)至式(1-12),可以发现向量fft���、iit���、CC̃t��̃�、oot���、CCt���和hhtℎℎ�都具有相同的维度,从而权值矩阵WWf���、WWi���、WWC���和WWo���维度相同,偏置向量bbf���、bbi���、bbc���和bbo���也维度相同。
为方便描述,将n维向量aa��的维度记为dim(aa��),即dim(aa��) = n。
一般地,将hhtℎℎ�的维度称为hidden_size或num_units,表示LSTM Cell所等效的隐藏层节点数目,即dim(hhtℎℎ�) = hidden_size或dim(hhtℎℎ�) = num_units。由此可将各个权值矩阵的维度表示为hidden_size×(dim(xxt���) + hidden_size),而各偏置向量的维度就是hidden_size。
3. 基于LSTM的手写数字识别
3.1 MNIST手写数字数据集
MNIST数据集是28×28像素的灰度手写数字图片,其中数字的范围从0到9,具体如表1-1所示(参考自http://yann.lecun.com/exdb/mnist/)。
表1-1 MNIST数据集描述| 文 件 | 内 容 |
|---|---|
| train-images-idx3-ubyte.gz | 训练集图片(训练集55000张,验证集5000张) |
| train-labels-idx1-ubyte.gz | 训练集图片所对应的数字标签 |
| t10k-images-idx3-ubyte.gz | 测试集图片(10000张) |
| t10k-labels-idx1-ubyte.gz | 测试集图片所对应的数字标签 |
每一张图片都有对应的标签,也就是图片所对应的数字。例如,图1-9所示的图片显示的是数字1,即其标签为1。
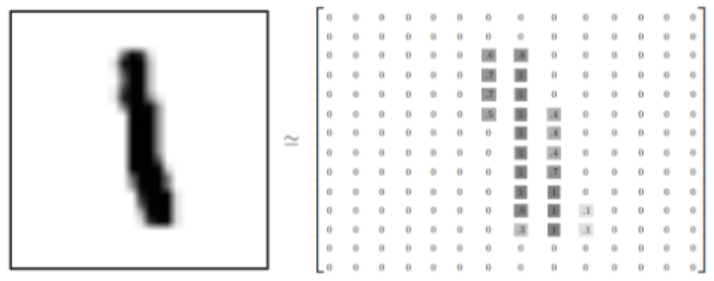 图1-9 MNIST数据集图片范例
图1-9 MNIST数据集图片范例
MNIST数据集包含训练集和测试集2部分。其中,训练集共60000张手写数字图片(55000张作为训练集,剩余5000张作为验证集);而测试集则包含10000张手写数字图片。训练集是一个维度为[60000, 784]的张量——第1个维度表示训练集图片的数量,第2个维度表示每张图片的像素点个数。此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。
每一张训练集图片都有一个与之对应的0到9之间的数字标签,用来表示训练集图片所显示的数字。此处使用独热向量(One-hot Vector)来记录训练集图片的标签。独热向量由若干个独热编码(One-hot Code)组成。每一个独热编码的位宽均为10(因为0-9共有10个数字),且独热编码中只有一位是1,其余位均是0。例如,图1-9所示的图片,其标签为1,且对应的独热编码是[0,1,0,0,0,0,0,0,0,0]。由此,可将训练集所对应的标签集看作是一个[60000, 10]的二进制矩阵,如图1-10所示。
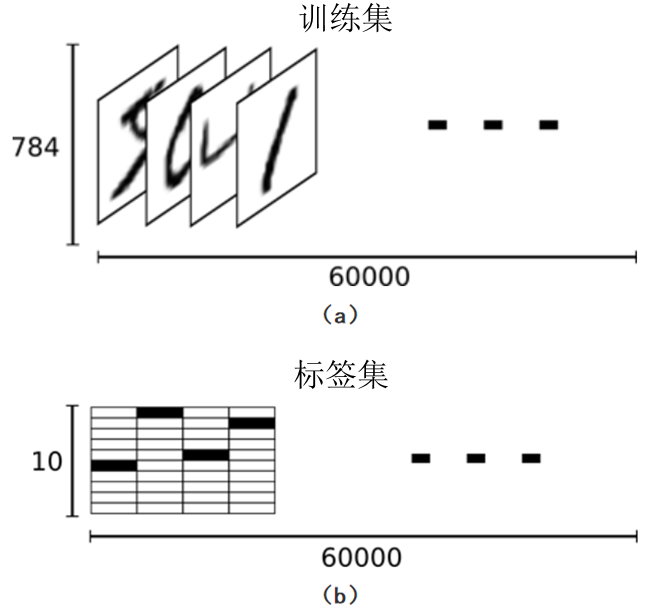 图1-10 MNIST数据集与标签集
图1-10 MNIST数据集与标签集
3.2 LSTM识别手写数字
MNIST数据集的每一张手写数字图片都是一个28×28的二维矩阵。为此,可采用包含输入层、LSTM Cell和输出层的RNN网络,且输入层包含28个神经元,隐藏层的LSTM Cell包含128个神经元(num_units为128,即dim(hhtℎℎ�) = 128),而输出层则包含10个神经元,代表手写数字图片所具有的10个分类结果。该RNN的网络结构如图1-11所示。
 图1-11 本实验的RNN网络结构
图1-11 本实验的RNN网络结构
接下来,讨论如何使用图1-11所示的RNN网络对手写数字图片进行预测。
不妨将输入的手写数字图片的每一行看作是一个行向量,则每一张手写数字图片都可以表示成一个包含28个行向量的列向量,如图1-12所示。
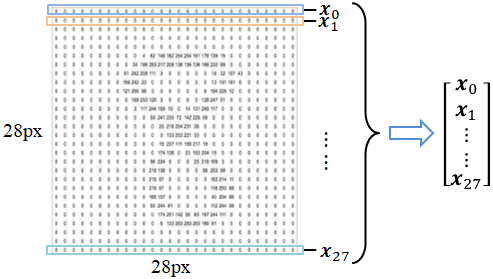 图1-12 MNIST手写数字图片示意图
图1-12 MNIST手写数字图片示意图
由此,可以得到一个长度为28的输入序列。利用RNN进行前向推导时,每次向网络中输入一个行向量xxi(0≤i<28)���(0≤�<28),此时RNN网络会产生相应的输出hhiℎℎ�;当行向量xx27��27被输入RNN进行前向推导时,RNN产生的输出hh27ℎℎ27就是LSTM Cell的最终输出向量,该向量包含了所输入图片的预测分类信息,如图1-13所示。
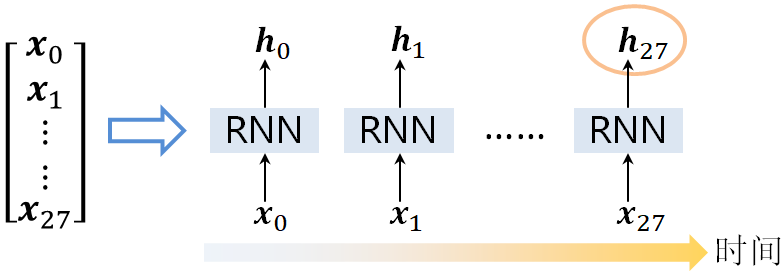 图1-13 RNN识别手写数字图片的示意图
图1-13 RNN识别手写数字图片的示意图
接下来,使用全连接层作为的线性分类器对LSTM Cell输出的hh27ℎℎ27向量进行分类,其计算公式如式(1-13)所示。
最后,找到分类向量yy27��27的最大分量所对应的下标,即为输入图片的预测值。
4. RNN加速器架构
本实验设计的RNN加速器架构如图1-14所示。
 图1-14 RNN加速器架构图
图1-14 RNN加速器架构图
在图1-14中,RNN加速器主要由PS端的ARM CPU、PL端的RNN加速IP核、PL端的DMA控制器和DDR控制器组成。PS端的ARM CPU用于对加速系统进行必要的初始化,比如在运行时加载Overlay、配置DMA控制器等;此外还负责对RNN网络推导所需的数据进行预处理,比如对MNIST数据集进行解析等。DDR控制器用于解析PS和PL对板上DDR存储器的访问请求,并向DDR存储芯片发出相应的读写信号。DMA控制器用于实现PS与PL之间的快速数据传输,以提高加速器的整体性能。RNN硬件IP核用于实现RNN网络前向推导的硬件加速,是整个硬件加速系统的核心运算部件。
增设了DMA控制器后,ARM CPU可通过DMA方式与RNN IP核进行快速的数据交互。在总线频率为150MHz、总线数据位宽为32bit的前提下,PS与PL之间的实测通信带宽可以达到550MB/s以上(理论最大带宽为600MB/s)。
需要注意的是,单次DMA传输的数据批量越大,能够获得的带宽越大,数据传输速率越高。当数据批量达到阈值后,带宽不再增大,进入饱和状态。
实验步骤
1. 编写LSTM IP核
本实验提供了LSTM IP核的HLS模板工程。模板工程共含有3个源文件和3个头文件,如表2-1所示。
表2-1 HLS模板工程的源文件和头文件| 源文件/头文件 | 备 注 |
|---|---|
| weight.h | 存放已训练好的RNN网络的权值和偏置 |
| utils.h | 将RNN的输入/输出转换为总线接口格式的数据流 |
| rnn.h | RNN网络的头文件 |
| rnn.cpp | RNN网络的实现 |
| rnn_top.cpp | HLS顶层函数 |
| main.cpp | TestBench |
同学们在实验时,只需补全rnn.cpp或修改rnn.h的相关代码即可,其余源文件和头文件可直接使用。
编写LSTM IP核的具体步骤为:
Step1:补全LSTM IP核关键代码
打开实验包lstm_hls目录中的HLS工程,根据LSTM Cell的原理图和源文件中的代码注释提示,补全rnn.cpp中的LSTM前向推导相关代码。
Step2:对LSTM IP核进行C仿真/CSim
打开rnn.h的头文件,将CSIM_ON的宏从0修改为1,从而打开仿真开关,如图2-1所示。
 图2-1 打开仿真开关
图2-1 打开仿真开关
点击HLS工具栏的![]() 按钮,开始C仿真。此时,TestBench将调用rnn.cpp中的infer函数对MNIST的测试集数据进行测试。
按钮,开始C仿真。此时,TestBench将调用rnn.cpp中的infer函数对MNIST的测试集数据进行测试。
如果编写的LSTM IP核功能正确,则仿真输出将形如图2-2所示。
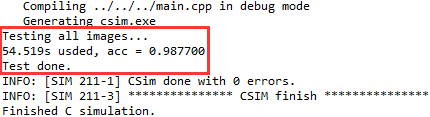 图2-2 仿真输出结果参考
图2-2 仿真输出结果参考
由图2-2可知,测试集的预测准确率为98.77%。
Step3:综合/Synthesis
点击HLS工具栏的![]() 按钮,对编写的RNN加速器进行综合,生成RTL电路。
按钮,对编写的RNN加速器进行综合,生成RTL电路。
综合成功后,可查看HLS生成的综合报告,必要时需要根据综合报告对IP核代码进行优化和改写。
注意!!!
在综合前,必须将rnn.h头文件中的CSIM_ON宏关闭。
Step4:打包IP核
点击HLS工具栏的![]() 按钮,对综合后的RTL电路进行打包,生成IP核。
按钮,对综合后的RTL电路进行打包,生成IP核。
2. 构建Block Design
Step1:新建Vivado工程
打开Vivado,选择正确的器件型号,新建名为mnist_lstm的工程。
Step2:导入LSTM IP核
在工程设置项中,把生成的LSTM IP核导入到当前的工程当中。
Step3:新建Block Design
点击“Create Block Design”,创建Block Design电路模块图。
Step4:添加IP核
在Block Design中,依次添加PS IP核、LSTM IP核与DMA控制器IP核,如图2-3所示。
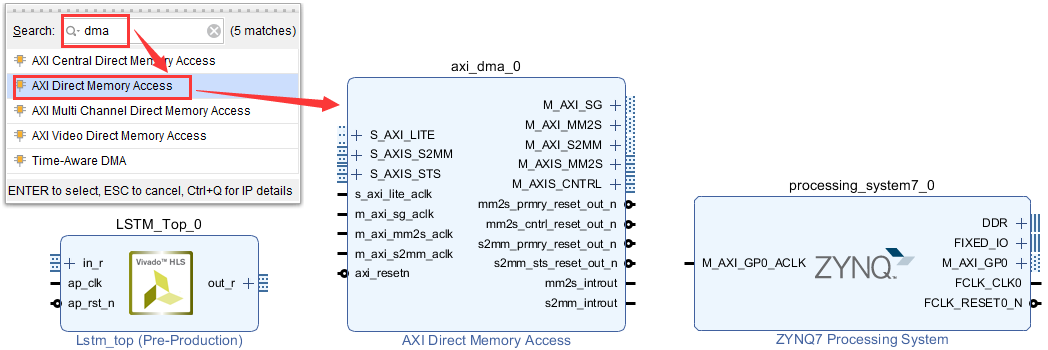 图2-3 添加LSTM IP核与DMA IP核
图2-3 添加LSTM IP核与DMA IP核
Step5:配置IP核
首先对PS的ZYNQ IP核进行配置:
点击“Run Block Automation”完成自动配置后,打开ZYNQ IP核的配置窗口,添加S_AXI_HP0总线接口,用于实现与LSTM IP核的数据交互。
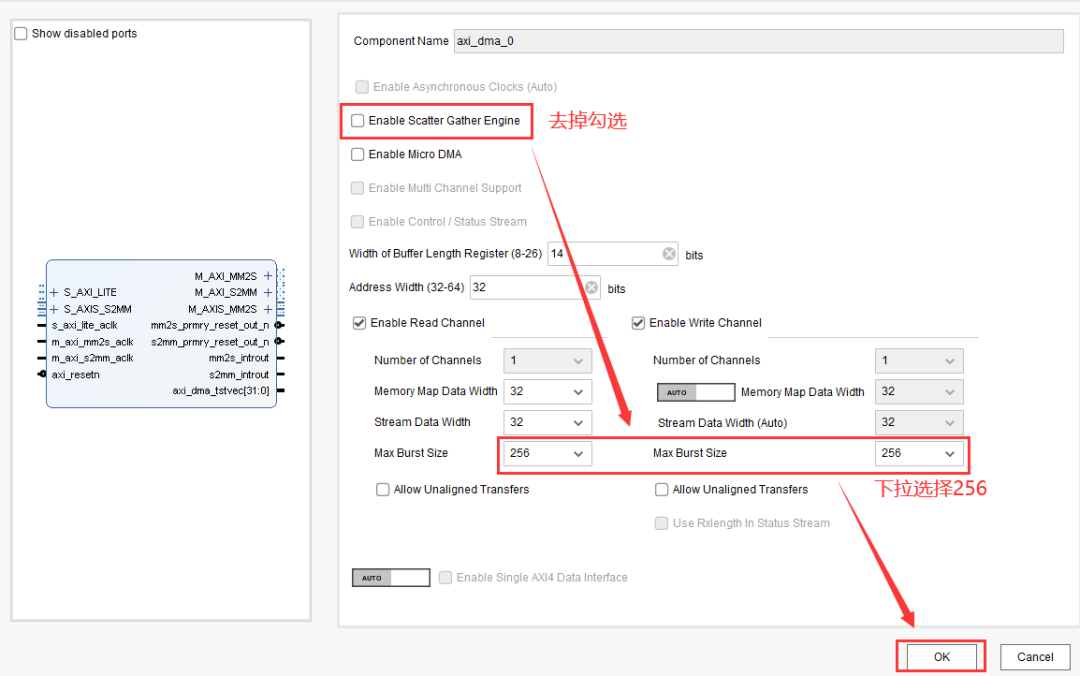
然后对DMA控制器的IP核进行配置:
打开DMA控制器IP核的配置窗口,按图2-4设置DMA控制器。
Step6:连接IP核
点击“Run Connection Automation”,勾选全部复选框,如图2-5所示。
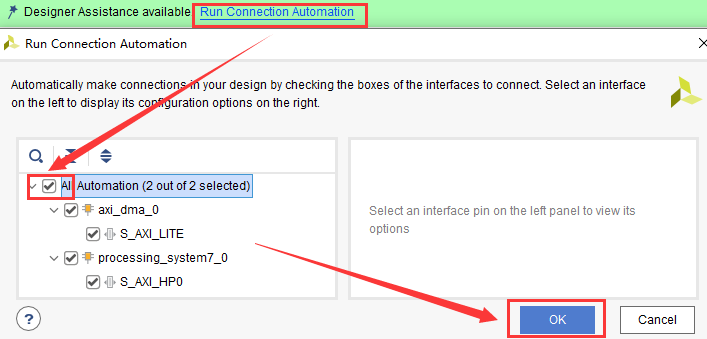 图2-5 自动连接所有IP核
图2-5 自动连接所有IP核
此时,Vivado将尝试自动连接所有已添加的IP核。连接完成后,点击“Diagram”工具栏的![]() 按钮以重新布局电路。
按钮以重新布局电路。
点击LSTM IP核的“in_r”接口,将其与DMA IP核的“M_AXIS_MM2S”接口连接起来,如图2-6所示。
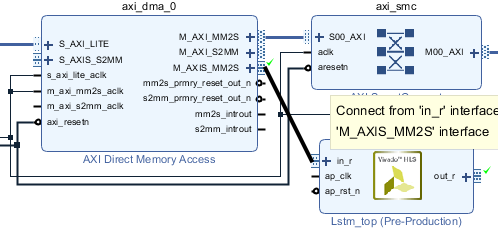 图2-6 将LSTM IP核的数据输入接口与DMA IP核连接起来
图2-6 将LSTM IP核的数据输入接口与DMA IP核连接起来
类似地,将LSTM IP核的“out_r”接口与DMA IP核的“S_AXIS_S2MM”接口连接起来。
连接完成后,再次点击“Run Connection Automation”以完成剩余线路的连接。
点击保存按钮保存Block Design。至此,Block Design构建完毕。
Step7:生成比特流
点击“Create HDL Wrapper”以创建Block Design的HDL顶层封装文件,然后点击Vivado工具栏的![]() 按钮以生成比特流。
按钮以生成比特流。
Step8:导出Overlay
比特流生成完毕后,将.bit拷贝出来,重命名为mnist_lstm.bit。
此外,打开Block Design电路图,导出Overlay所需的.tcl脚本文件,并重命名为mnist_lstm.tcl。
将mnist_lstm.bit和mnist_lstm.tcl拷贝到实验包的lstm_app.zip中。
3. 上板测试
将实验包中的lstm_app.zip上传到Jupyter并在解压。
随后点击进入lstm_app目录。点击打开mnist_lstm.ipynb,点击Cell->Run All进行测试。观察RNN的软硬件推导结果和推导时间的差别,如图2-7、图2-8所示。
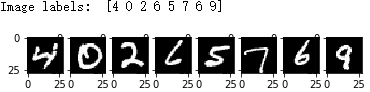 图2-7 待测试图片及其标签
图2-7 待测试图片及其标签
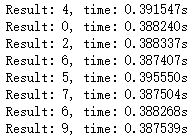
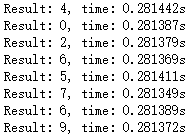 (a) 软件运行时间 (b) 硬件运行时间图2-8 观察软硬件推导的运行结果差异
(a) 软件运行时间 (b) 硬件运行时间图2-8 观察软硬件推导的运行结果差异
附加题
题目1:HLS优化(+1分)
使用HLS Directives对RNN IP核进行优化,可使用循环展开、数组划分、流水线等优化策略,具体要求如下:
(1)使用HLS指导语句优化RNN IP核性能,对比分析优化前后的综合报告,写入实验报告;
(2)至少使用循环展开、数组划分、流水线、数据流、内联等至少2种优化策略;
(3)生成Overlay并上板测试,对比分析优化前后的性能,计算平均加速比,写入实验报告;
(4)优化后的RNN前向推导性能要明显比必做题高;
(5)提交作业时,需把本题的Overlay(mnist_lstm.tcl和mnist_lstm.bit)、源程序文件和运
行结果(RNN IP核的源文件、优化前后的资源使用截图、优化前后的运行时间截图)也一并提交。
题目2:DMA传输优化(+2.5分)
在必做题所设计的RNN加速器中,每次DMA仅传输一张图片到IP核,或仅从IP核读取一个维度为10的FP32向量,如图3-1所示。前者的单次DMA传输数据批量为28*28*8bit = 784B,而后者则仅仅只有40B。
 (a) 通过DMA与IP核进行数据通信的Python实现
(a) 通过DMA与IP核进行数据通信的Python实现
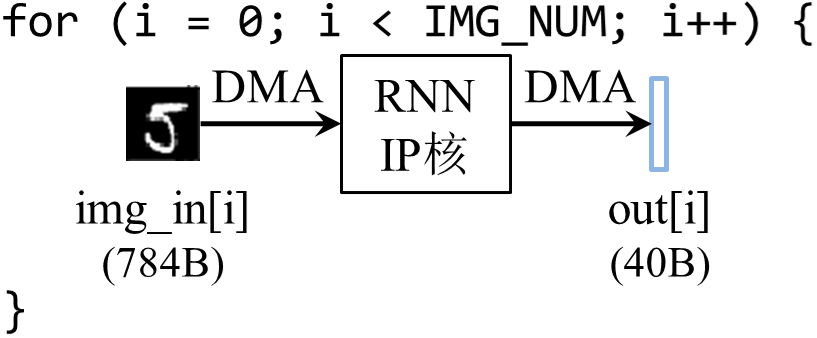 (b) 对(a)中代码的形象化描述图3-1 必做题的DMA通信方案
(b) 对(a)中代码的形象化描述图3-1 必做题的DMA通信方案
已知在DMA的实际带宽达到饱和之前,单次DMA传输的数据批量越大,PS和PL之间进行数据通信能够获得的带宽就越大,加速器整体性能就越高。因此,如果可以将待预测的所有手写数字图片合并成一个大批量数据,一次性传输到RNN IP核进行前向推导,并一次性返回所有图片的预测结果,那么DMA的带宽将得到更充分的利用,如图3-2所示。
 图3-2 增大单次DMA传输的数据批量以提高数据传输效率
图3-2 增大单次DMA传输的数据批量以提高数据传输效率
基于以上分析,本题目要求:
(1)改写RNN硬件IP核的代码,使其支持多图片连续预测;
(2)生成比特流,导出Overlay并上板测试;
(3)修改mnist_lstm.ipynb,增加send_buf数组以存放多张待测试的图片;增加recv_buf数组
以存放IP核返回的多张图片的预测结果;
(4)计算每张测试图片的平均前向推导时间,并计算DMA传输优化后,RNN加速器相对软件推导的加速比;
(5)对比分析DMA传输优化前后的加速器推导性能差别,并将DMA传输优化前后的运行结果
和运行时间截图,在课程报告中进行对比分析;
(6)提交作业时,需把本题的Overlay(mnist_lstm.tcl和mnist_lstm.bit)、源程序文件和运
行结果(RNN IP核的源文件、优化前后的运行结果和运行时间截图、mnist_lstm.ipynb)也一并提交。
参考结果
优化效果参考:在图3-2中,当n=8�=8时,加速比从1.4提高到10。
题目3:RNN量化(+3.5分)
在必做题中,我们利用PyTorch训练RNN网络,并将训练好的网络参数导出后保存在HLS工程的weight.h头文件中,如图3-3所示。
 图3-3 导出的RNN网络参数
图3-3 导出的RNN网络参数
由图3-1可知,RNN的网络参数是以FP32格式存储的,因而最终生成的RNN加速器消耗了PYNQ-Z2的大量Block RAM存储资源,如图3-4所示。
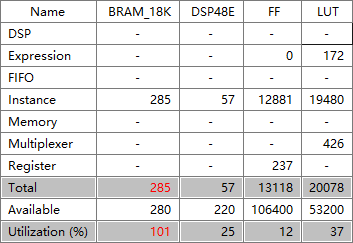 (a) HLS综合报告中的资源消耗估计表
(a) HLS综合报告中的资源消耗估计表
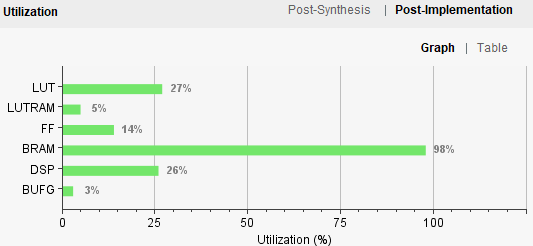 (b) Vivado实现后的资源使用图表图3-4 必做题RNN加速器的资源使用情况
(b) Vivado实现后的资源使用图表图3-4 必做题RNN加速器的资源使用情况
其中,HLS综合报告和Vivado综合后的资源使用情况图表都是基于代码分析得出的估计值,而Vivado实现后的资源使用图表则更接近实际值。
基于以上分析,本题目要求:
(1)绘制RNN网络参数的分布图,观察其对称性;
(2)根据RNN网络参数的分布情况,选择合适的量化策略,对RNN的网络参数进行量化;
(3)修改RNN IP核的HLS代码,使得该IP核支持参数量化后的定点运算;
(4)添加量化运算后的反量化代码;
(5)为修改后的代码添加TestBench,以测试量化网络的正确性;
(6)生成Overlay并上板测试,观察和对比量化前后的存储资源使用量、预测准确率和前向推
导性能差别,并将量化前后的资源使用量和运行结果截图,在课程报告中进行对比分析;
(7)提交作业时,需把本题的Overlay(mnist_lstm.tcl和mnist_lstm.bit)、源程序文件和运 行结果(RNN IP核的源文件、HLS仿真源文件、量化前后的资源使用截图、量化前后的运行时间截图)也一并提交。

想要了解FPGA吗?这里有实例分享,ZYNQ设计,关注我们的公众号,探索
智能推荐
源代码图纸文档防泄密场景方案分析-程序员宅基地
文章浏览阅读161次,点赞5次,收藏3次。财务数据、员工信息、工资信息、客户和业务数据等被员工非法获取、外泄
React学习记录-程序员宅基地
文章浏览阅读936次,点赞22次,收藏26次。React核心基础
Linux查磁盘大小命令,linux系统查看磁盘空间的命令是什么-程序员宅基地
文章浏览阅读2k次。linux系统查看磁盘空间的命令是【df -hl】,该命令可以查看磁盘剩余空间大小。如果要查看每个根路径的分区大小,可以使用【df -h】命令。df命令以磁盘分区为单位查看文件系统。本文操作环境:red hat enterprise linux 6.1系统、thinkpad t480电脑。(学习视频分享:linux视频教程)Linux 查看磁盘空间可以使用 df 和 du 命令。df命令df 以磁..._df -hl
Office & delphi_range[char(96 + acolumn) + inttostr(65536)].end[xl-程序员宅基地
文章浏览阅读923次。uses ComObj;var ExcelApp: OleVariant;implementationprocedure TForm1.Button1Click(Sender: TObject);const // SheetType xlChart = -4109; xlWorksheet = -4167; // WBATemplate xlWBATWorksheet = -4167_range[char(96 + acolumn) + inttostr(65536)].end[xlup]
若依 quartz 定时任务中 service mapper无法注入解决办法_ruoyi-quartz无法引入ruoyi-admin的service-程序员宅基地
文章浏览阅读2.3k次。上图为任务代码,在任务具体执行的方法中使用,一定要写在方法内使用SpringContextUtil.getBean()方法实例化Spring service类下边是ruoyi-quartz模块中util/SpringContextUtil.java(已改写)import org.springframework.beans.BeansException;import org.springframework.context.ApplicationContext;import org.s..._ruoyi-quartz无法引入ruoyi-admin的service
CentOS7配置yum源-程序员宅基地
文章浏览阅读2w次,点赞10次,收藏77次。yum,全称“Yellow dog Updater, Modified”,是一个专门为了解决包的依赖关系而存在的软件包管理器。可以这么说,yum 是改进型的 RPM 软件管理器,它很好的解决了 RPM 所面临的软件包依赖问题。yum 在服务器端存有所有的 RPM 包,并将各个包之间的依赖关系记录在文件中,当管理员使用 yum 安装 RPM 包时,yum 会先从服务器端下载包的依赖性文件,通过分析此文件从服务器端一次性下载所有相关的 RPM 包并进行安装。_centos7配置yum源
随便推点
【方位估计】基于MUSIC算法、加权MUSIC算法和ROOT-MUSIC算法方位估计附Matlab代码-程序员宅基地
文章浏览阅读921次,点赞17次,收藏19次。方位估计是信号处理领域中一个重要的问题,它涉及到了信号的方向和角度的估计。在无线通信、雷达、声呐等领域,方位估计都有着重要的应用。本文将介绍三种常用的方位估计算法:MUSIC算法、加权MUSIC算法和ROOT-MUSIC算法。首先我们来介绍MUSIC算法。MUSIC算法是一种基于信号子空间的方法,它利用信号子空间的特性来实现方位估计。
DZMFullPage - 前端分页动画插件,兼容IE9+,支持Vue-程序员宅基地
文章浏览阅读73次。分页指定DOM页页页页页页导入插件。
【图像分割】基于Crow搜索优化模糊聚类算法的医学图像分割研究附matlab代码-程序员宅基地
文章浏览阅读1.1k次,点赞30次,收藏24次。图像分割是医学图像分析中的关键步骤,它可以将图像中的不同组织或结构区分开来。模糊聚类算法是一种常用的图像分割方法,但其聚类中心的选择对分割结果有很大的影响。本文提出了一种基于 Crow 搜索优化(CSO)算法的模糊聚类算法,用于医学图像分割。CSO 是一种新型的群智能优化算法,具有收敛速度快、鲁棒性强等优点。本文将 CSO 应用于模糊聚类算法的聚类中心优化,以提高分割精度。
Android开发-Android常用组件-TextView文本框-程序员宅基地
文章浏览阅读1k次。04 常用组件4.1 TextViewTextView (文本框),用于显示文本的一个控件。文本的字体尺寸单位为sp :sp: scaled pixels(放大像素). 主要用于字体显示。文本常用属性:属性名作用id为TextView设置一个组件id,根据id,我们可以在Java代码中通过findViewById()的方法获取到该..._
STM32单片机示例:多个定时器同步触发启动_stm32 定时器同步-程序员宅基地
文章浏览阅读3.7k次,点赞3次,收藏14次。多个定时器同步触发启动是一种比较实用的功能,这里将对此做个示例说明。_stm32 定时器同步
android launcher分析和修改10,Android Launcher分析和修改9——Launcher启动APP流程(转载)...-程序员宅基地
文章浏览阅读348次。出处 : http://www.cnblogs.com/mythou/p/3187881.html本来想分析AppsCustomizePagedView类,不过今天突然接到一个临时任务。客户反馈说机器界面的图标很难点击启动程序,经常点击了没有反应,Boss说要优先解决这问题。没办法,只能看看是怎么回事。今天分析一下Launcher启动APP的过程。从用户点击到程序启动的流程,下面针对WorkSpa..._回调bubbletextview