百度 APP iOS 端包体积 50M 优化实践 (四) 代码优化_linkmap文件-程序员宅基地

一、前言
百度APP iOS端包体积优化系列文章的前三篇重点介绍了包体积优化整体方案、图片优化和资源优化,图片优化是从无用图片、Asset Catalog和HEIC格式三个角度做深度优化,资源优化包括大资源优化、无用配置文件和重复资源优化,本文重点介绍代码优化,在百度APP实践中,代码优化包括无用类优化、无用模块瘦身、无用方法瘦身、精简重复代码、工具类瘦身和AB实验固化。在代码优化过程,需要分析Mach-O和Link Map,在前面的文章我们已经针对Mach-O文件做过了分析,本文先介绍Link Map文件,然后再详细介绍代码优化方案。
百度APP iOS端包体积优化实践系列文章回顾:
《百度APP iOS端包体积50M优化实践(二) 图片优化》
《百度APP iOS端包体积50M优化实践(三) 资源优化》
二、Link Map文件详解
2.1 简介
Link Map 是 Mach-O 格式的二进制文件的一种辅助文件,它描述了可执行文件的全貌,包括编译后的每一个目标文件的信息以及它们在可执行文件中的代码段、数据段存储详情。通过Link Map文件,我们可以知道可执行文件的路径、CPU架构、目标文件、符号等信息,分析可执行文件中哪个类或库占用比较大,进行安装包瘦身,此外,我们可以清楚地了解可执行文件的内部结构和各个目标文件在其中的位置关系,这对于分析和调试非常有帮助。
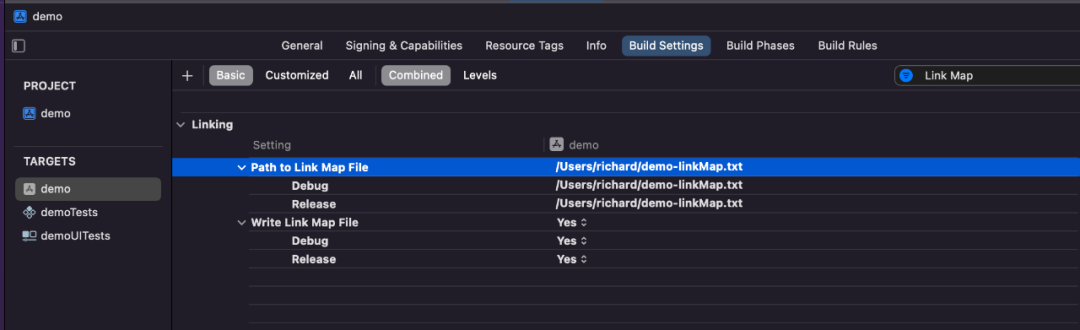
2.2 生成linkMap文件
Xcode -> Project -> Build Settings -> Write Link Map File选项值设为yes,Path to Link Map File设置为指定好的LinkMap文件存储位置。
2.3 LinkMap文件结构解析
2.3.1 基础信息
# Path: /Users/richard/Desktop/demo/DerivedData/demo/Build/Products/Debug-iphoneos/demo.app/demo
# Arch: arm64
Path是可执行文件的路径,Arch是架构类型。
2.3.2 Object文件列表
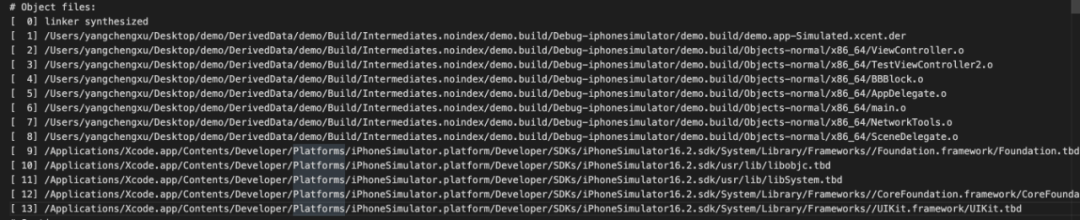
Object文件列表列出了所有编译后的目标文件,包括.o文件和dylib库。每个目标文件都有一个对应的编号,上图第一列就是,通过该编号可以对应到具体的类,在后面的Symbols部分,还会用到此编号。
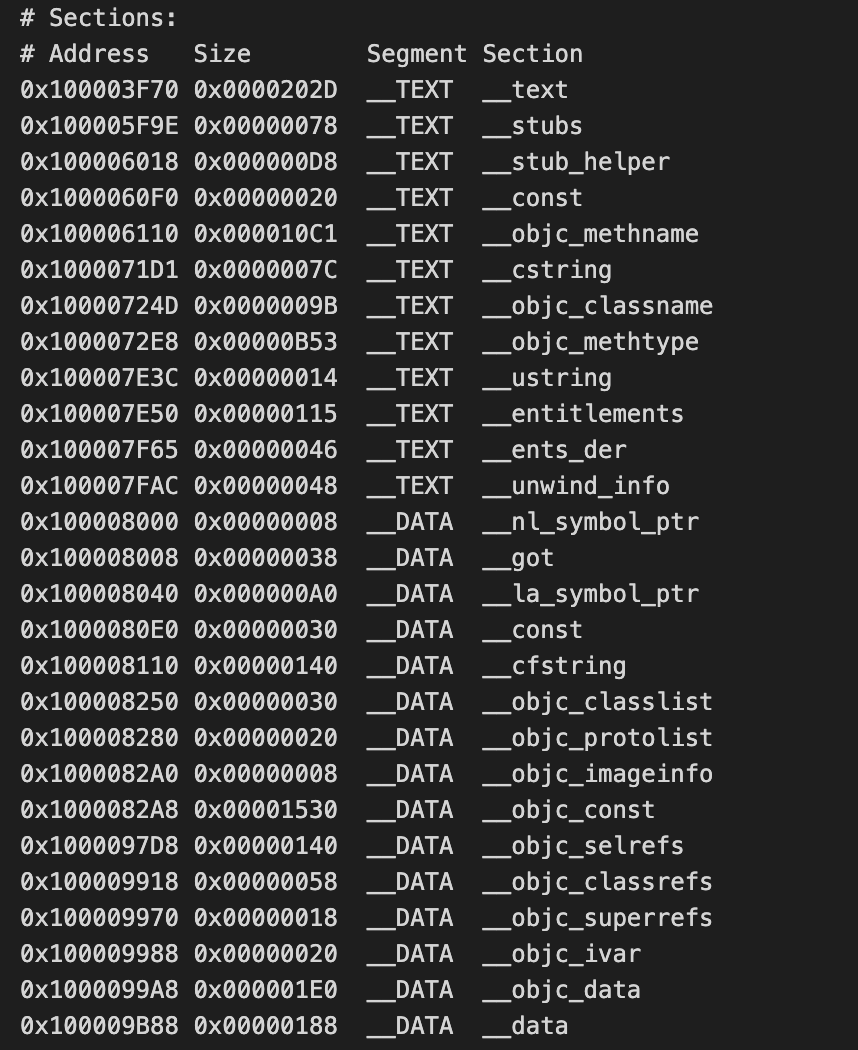
2.3.2 Section段表
Section段表描述了各个段在最终编译成的可执行文件中的偏移位置及大小,包括代码段(TEXT)和数据段(DATA)。段表中第一列是数据在文件的偏移位置,第二列是Section占用大小,第三列是Segment类型,第四列是Section类型,关于Segment和Section,在前面文章对于Mach-O详解做过介绍,这儿不再赘述。
2.3.4 Symbols
Symbols模块给出了类里面的方法在内存具体情况。其中
-
第一列是方法起始地址,通过这个地址我们可以查上面的段表;
-
第二列是大小,通过这个可以算出方法占用的大小;
-
第三列是归属的类(.o),值是具体编号,通过反查目标文件列表可以知道对应的类;
-
第四列是方法名称。
通过Symbols模块我们可以分析出来每个类对应方法的大小。

三、代码优化
3.1 无用类瘦身
3.1.1 静态检测获取无用类
方案介绍
所谓的静态检测,就是分析linkmap文件和Mach-o文件,Mach-o文件中__DATA __objc_classlist段记录了所有类的地址,__DATA __objc_classrefs段记录了引用类的地址,取差集可以得到未使用的类的地址,然后进行符号化,就可以得到未被引用的类信息。
- 第一、获取所有类地址,命令:otool -v -s __DATA __objc_classlist。
otool -v -s __DATA __objc_classlist /Users/ycx/Desktop/demo.app/demoContents of (__DATA,__objc_classlist) section0000000100008238 00009980 00000001 000099d0 000000010000000100008248 00009a48 00000001 00009a98 000000010000000100008258 00009ac0 00000001 00009b38 00000001
- 第二、获取引用类的地址,命令:otool -v -s __DATA __objc_classrefs。
otool -v -s __DATA __objc_classrefs /Users/yangchengxu/Desktop/demo.app/demoContents of (__DATA,__objc_classrefs) section000000010000990000000000 00000000 00000000 00000000000000010000991000000000 00000000 000099d0 00000001000000010000992000000000 00000000 00000000 00000000
-
第三、取差集,所有类的地址减去引用类的地址,拿到的就是未使用类的地址信息。
-
第四、符号化,遍历Linkmap和Mach-O文件可获取地址信息对应的具体类名,建立类和地址的映射关系,通过地址反解析出类名。
优缺点
优点:检测方式简单易行。
缺点:
-
对于存在引用关系但根本不会被调用的类,是无法被判断为无用类的。随着版本迭代,新老员工工作交接,很多功能的入口已经不存在了,相关的类也根本不会被调用,但是引用关系仍然保留。通过静态检测的方式,无法检测出这种情况。
-
静态检测无法适用于通过反射调用类及方法的场景。因为静态检测无法感知运行时的环境,无法预测哪些类或方法会被反射调用。因此,在这种情况下,静态检测将无法准确地检测出无用类或无用的方法。
3.1.2 动态检测获取无用类
方案介绍
我们知道OC类结构有个isa指针,指向该类的原类meta-class,通过阅读objc源代码,我们发现在meta-class的class_rw_t结构体中的一个flag标志位,flags 的1<<29位标识当前类在运行时中是否被初始化过,参考源码路径:
Values
for
// These are not emitted by the compiler and are never used in class_ro_t.
// Their presence should be considered in future ABI versions.
// class_t->data is class_rw_t, not class_ro_t
#define RW_REALIZED (1<<31)
// class is unresolved future class
#define RW_FUTURE (1<<30)
// class is initialized
#define RW_INITIALIZED (1<<29)
// class is initializing
#define RW_INITIALIZING (1<<28)
// class_rw_t->ro is heap copy of class_ro_t
#define RW_COPIED_RO (1<<27)
// class allocated but not yet registered
#define RW_CONSTRUCTING (1<<26)
// class allocated and registered
#define RW_CONSTRUCTED (1<<25)
// available for use; was RW_FINALIZE_ON_MAIN_THREAD
// #define RW_24 (1<<24)
// class +load has been called
#define RW_LOADED (1<<23)
由此,检测类是否被初始化的方法如下所示:
#define W_INITIALIZED (1<<29)bool isinitialized() { return getMeta() -›data()-›flags & W_INITIALIZED;}
优缺点
优点:
-
对于业务线代码没有侵入性;
-
没有性能损耗;
-
可以针对线上实际运行环境做检测;
缺点:
仅支持OC,无法覆盖Swift和C、C++。
3.1.3 手百采用的技术方案
通过动态和静态两种方式结合提高准确度。详细方案我们后面会有文章重点介绍。
3.2 无用模块瘦身
没有任何依赖关系即不会被其他库引用的无用模块,比较容易识别,还有一种类型的无用模块是需要关注的,它们虽然还有代码引用关系,但从逻辑上已经不再被使用。例如一些过时的活动代码(如北京冬奥会等)、业务改版后的老代码以及被废弃使用的开源库等。随着版本的迭代,这类无用模块的数量会逐渐增加。
在百度APP包体积优化实践中,我们采用无用类占比这个指标来快速识别不再被使用的模块。具体来说,这个指标的计算方式是统计模块中所有无用类的数量,然后将其除以模块中总类的数量,再乘以100%。如果这个指标的值比较高,就说明该模块中有较多的无用代码,需要进行优化和清理。
经过前面的无用类瘦身环节,我们已经知道了百度APP中所有的无用类,从而可以从LinkMap文件中获取每个模块包含的具体类和数量,并计算出每个组件中无用类占比。如果一个库的占比为100%,就说明这个库已经完全不再被使用,可以直接下线。对于占比超过90%的库,可以进行适当关停并转,将无用类删除,仅保留有用的几个类并将其迁移到其他库中,从而降低组件数量。
通过遍历LinkMap文件中的Object files字段,可以获取每个组件包含的具体类。你可以参考以下的脚本代码来实现这个功能:
def find_class(base_link_map_file): link_map_file = open(base_link_map_file, 'rb') reach_files = 0 reach_sections = 0 reach_symbols = 0 files_map = {} while 1: line = link_map_file.readline() line = line.decode('utf-8', errors='ignore') if not line: break if line.startswith("#"): if line.startswith("# Object files:"): reach_files = 1 if line.startswith("# Sections"): reach_sections = 1 if line.startswith("# Symbols"): reach_symbols = 1 else: if reach_files == 1 and reach_sections == 0 and reach_symbols == 0: index = line.find("]") if index != -1: tmpfile = line[index + 2:-1] file = tmpfile.split("/")[-1] frameworkIndex = file.find("(") if frameworkIndex!= -1: frameworkName = file[0: frameworkIndex] className = file[frameworkIndex + 1:len(file)-1] if files_map: if frameworkName in files_map: files_map[frameworkName] = files_map[frameworkName] + " , " + className else: files_map[frameworkName] = className else: files_map[frameworkName] = className link_map_file.close() return files_map
3.3 无用方法瘦身
关于无用方法检查,业内常用的方法是结合Mach-O和LinkMap文件,分析二者结构来获取无用方法。首先Mach-O中的__objc_selrefs代表所有引用到的方法集合,Mach-O中__objc_classlist代表Objective-C 类列表,然后拆解其结构获取其中BaseMethods、InstanceMethods以及ClassMethods中的数据,作为所有方法的集合,最后和第一步获取的引用方法做差值从而得到无用方法,为了获取每个无用方法的包体积收益,还需要结合linkmap文件做分析。这是目前为止看到可行方案,但是该方案存在的问题是准确率不高,实测不超过40%,这也是某些大厂放弃无用方法瘦身的原因。
百度在这方面做了一些技术创新,从编译角度解决这个业界难题,简单来说,首先编写LLVM插件获取静态编译阶段所有方法,然后获取方法调用关系,做diff可初步获取无用方法,然后排除如下特殊case:分类方法识别异常、继承链子类调用父类方法、实现系统类协议方法、协议继承链方法识别问题、硬编码调用问题、反射调用问题、通知调用方法识别为无用方法问题,详细方案我们后面会有文章重点介绍。
3.4 精简重复代码
在软件开发过程中,尤其是不同部门多人开发项目,存在复制粘贴的代码,还有一些特殊情况,如项目重构时,为了不影响已有逻辑,程序员会复制一份老代码然后在此基础上重新开发,此时重复代码更有可能大量出现,随着版本迭代上述情况会愈演愈烈导致重复代码越来越多,因此,不论是减少包体积,还是降低历史包袱,精简重复代码非常有必要。
在百度APP包体积优化方案中,我们采用了开源工具PMD来扫描重复代码,然后再结合实际情况来从逻辑上重构这些代码达到精简的目的,PMD是一个开源工具,官网地址:https://pmd.github.io/,简单易用,通过静态分析可获知代码错误,在不运行程序的情况下报告错误,其中PMD 附带的CPD工具可以直接检测重复代码,支持Java, C, C++, C#, Groovy, PHP, Ruby, Fortran, JavaScript, PLSQL, Objective C, Matlab, Python, Go, Swift语言,并且检测规则可以自由定制,使用方法参考:https://pmd.sourceforge.io/pmd-5.5.1/usage/cpd-usage.html
用brew 命令安装
brew install pmd
用如下命令做重复代码检测
//其中,--files 用于指定文件目录,--minimum-tokens 用于设置最小重复代码阈值,--format 用于指定输出文件格式,支持 xml/csv/txt 等格式,这里建议使用 xml,方便查看 //生成的 XML 文件内容如下,根据 file 标签信息就能定位到重复代码位置。pmd cpd --files 扫描文件目录 --minimum-tokens 70 --language objectivec --encoding UTF-8 --format xml > repeat.xml
检测结果如下所示,其中duplication标签中的lines表示重复内容的行数,file标签表示从那一行开始重复及具体重复文件路径,codefragment标签表示重复的代码。
<pmd-cpd> <duplication lines="16" tokens="162"> <file begintoken="16933" column="33" endcolumn="4" endline="28" endtoken="17094" line="13" path="path1"> <file begintoken="23979" column="47" endcolumn="4" endline="26" endtoken="24140" line="11" path="path2" /> <codefragment> *************************** </codefragment> </duplication></pmd-cpd>
3.5 工具方法瘦身
日常开发工程中我们都要使用各种工具方法,常用的实现方式有如下两种
-
实现系统类的Category,如NSDate、UIImage、NSArray、NSDictionary的分类方法实现;
-
独立封装;
App在初始开发阶段都有commonTools模块,用来存放各种工具方法,但是随着版本迭代和人员变动,业务也越来越复杂,新来的同学不知道底层模块已经实现了类似方法,为了开发方便会在自己的模块再集成一套,这样导致的结果是工具方法重复建设,此模块瘦身主要目的就是挖掘重复工具方法并优化,百度APP实践过程中主要从以下两个角度入手。
- 遍历LinkMap文件,挖掘出重复的Category,参考以下的脚本代码来实现此功能:
def get_files_map(base_link_map_file): link_map_file = open(base_link_map_file, 'rb') reach_files = 0 reach_sections = 0 reach_symbols = 0 files_map = {} while 1: line = link_map_file.readline() line = line.decode('utf-8', errors='ignore') if not line: break if line.startswith("#"): if line.startswith("# Object files:"): reach_files = 1 if line.startswith("# Sections"): reach_sections = 1 if line.startswith("# Symbols"): reach_symbols = 1 else: if reach_files == 1 and reach_sections == 0 and reach_symbols == 0: # files index = line.find("]") if index != -1: symbol = {"file": line[index + 2:-1]} key = int(line[1: index]) files_map[key] = symbol pass link_map_file.close() return files_map
- 对于非Category的工具方法,进行排查和合并,最终下沉到统一工具库里面。
3.6 AB实验固话
在APP开发过程中,为了更加有效地验证新开发功能的实际效果,我们会进行AB实验,通常会将实验组和对照组分开,并在实验组中进行某种操作,而在对照组中不进行该操作,我们会观察这个操作对实验变量的影响,以确定该操作是否对实验结果产生显著影响。
像百度APP这种日活过亿的应用,每个版本会有10个左右AB实验,一年有240个AB实验,随着长时间的版本迭代,会积累大量AB实验代码,但实际上只有一个分支的代码是线上生效的,另一个分支代码是不会被执行的,所以推进AB实验固化,去除无效分支的代码可以实现减少包体积的目的。
百度APP推进AB实验固化分为三个步骤,第一 、从AB实验平台获取已经固化的开关;第二、开发工具判断此实验对应的开关是否在代码中存在;第三、分发给负责的开发同学固化AB实验,删除不用的代码。
其中第二步的实现非常关键,就是判断一个开关是否仍有对应的代码逻辑,百度APP采用的方案是获取所有可能使用开关的字符串集合,然后判断第一步拿到的开关是否在集合中,若在说明该开关的对应的实验需要做固化操作。
在Objective-C的.h和.m文件中,我们经常用如下代码来定义一个AB开关,然后再后续代码中引用。
#define kFaceverifyResourceOptimizeABTestKey @"face_verify_resource_optimize_enable"
针对Objective-C的.h和.m的文件内容,用正则过滤,匹配表达式为 @“(.*?)”,即可获取所有可能加载开关的字符串集合。
同样道理,在Swift文件我们通常通过如下代码来定义一个AB开关,然后再后续代码中引用,加载方式完全一样,针对Swift这种文件,正则表达式应为"(.?)"。
static let verifyResourceOptimizeABTestKey: String = "face_verify_resource_optimize_enable"
四、总结
代码优化同样也是包体积优化的重头戏,但跟图片和资源优化相比较,代码修改影响范围大,再加上OC语言动态调用方式多种多样,这导致代码的删除操作更容易引起质量问题,所以优化收益落地难度比较大。百度APP在优化实践过程中挖掘出20M的收益,经过两个季度仅落地8M左右,剩余部分还需要继续推动。
本文首先对LinkMap文件格式做了详细介绍,然后对百度APP代码优化方案(无用类优化、无用模块瘦身、无用方法瘦身、精简重复代码、工具类瘦身和AB实验固化)做了系统阐释,后续我们会针对其他优化详细介绍其原理与实现,敬请期待。
——END——
参考资料:
[1]、PMD介绍:https://pmd.github.io/
[2]、PMD CPD使用方法:https://pmd.sourceforge.io/pmd-5.5.1/usage/cpd-usage.html
[3]、XNU源码:https://github.com/apple/darwin-xnu
[4]、objc源码:https://github.com/apple-oss-distributions/objc4/tags
推荐阅读:
智能推荐
手把手教你安装Eclipse最新版本的详细教程 (非常详细,非常实用)_eclipse安装教程-程序员宅基地
文章浏览阅读4.4k次,点赞2次,收藏16次。写这篇文章的由来是因为后边要用这个工具,但是由于某些原因有部分小伙伴和童鞋们可能不会安装此工具,为了方便小伙伴们和童鞋们的后续学习和不打击他们的积极性,因为80%的人都是死在工具的安装这第一道门槛上,这门槛说高也不高说低也不是太低。所以就抽时间水了这一篇文章。_eclipse安装教程
分享11个web前端开发实战项目案例+源码_前端项目实战案例-程序员宅基地
文章浏览阅读4.1w次,点赞12次,收藏193次。小编为大家收集了11个web前端开发,大企业实战项目案例+5W行源码!拿走玩去吧!1)小米官网项目描述:首先选择小米官网为第一个实战案例,是因为刚开始入门,有个参考点,另外站点比较偏向目前的卡片式设计,实现常见效果。目的为学者练习编写小米官网,熟悉div+css布局。学习资料的话可以加下web前端开发学习裙:600加上610再加上151自己去群里下载下。项目技术:HTML+CSS+Div布局2)迅雷官网项目描述:此站点特效较多,所以通过练习编写次站点,学生可以更多练习CSS3的新特性过渡与动画的实_前端项目实战案例
计算质数-埃里克森筛法(间隔黄金武器)-程序员宅基地
文章浏览阅读73次。素数,不同的质数,各种各样的问题总是遇到的素数。以下我们来说一下求素数的一种比較有效的算法。就是筛法。由于这个要求得1-n区间的素数仅仅须要O(nloglogn)的时间复杂度。以下来说一下它的思路。思路:如今又1-n的数字。素数嘛就是除了1和本身之外没有其它的约数。所以有约数的都不是素数。我们从2開始往后遍历,是2的倍数的都不是素数。所以我们把他们划掉然后如...
探索Keras DCGAN:深度学习中的创新图像生成-程序员宅基地
文章浏览阅读532次,点赞9次,收藏14次。探索Keras DCGAN:深度学习中的创新图像生成项目地址:https://gitcode.com/jacobgil/keras-dcgan在数据驱动的时代,图像生成模型已经成为人工智能的一个重要领域。其中,Keras DCGAN 是一个基于 Keras 的实现,用于构建和训练 Deep Convolutional Generative Adversarial Networks(深度卷积生...
org.apache.ibatis.binding.BindingException: Invalid bound statement (not found):_spring-could org.apache.ibatis.binding.bindingexce-程序员宅基地
文章浏览阅读116次。今天在搭建springcloud项目时,发现如上错误,顺便整理一下这个异常:1. mapper.xml的命名空间(namespace)是否跟mapper的接口路径一致<mapper namespace="com.baicun.springcloudprovider.mapper.SysUserMapper">2.mapper.xml接口名是否和mapper.java接..._spring-could org.apache.ibatis.binding.bindingexception: invalid bound state
四种高效数据库设计思想——提高查询效率_数据库为什么能提高效率-程序员宅基地
文章浏览阅读1.1k次。四种高效数据库设计思想——提高查询效率:设计数据库表结构时,我们首先要按照数据库的三大范式进行建立数据。1. 1NF每列不可拆分2. 2NF确保每个表只做一件事情3. 3NF满足2NF,消除表中的依赖传递。三大范式的出现是在上世纪70年代,由于内存资源比较昂贵,所以严格按照三大范式进行数据库设计。而如今内存变得越来越廉价,在考虑效率和内存的基础上我们可以做出最优选择以达到最高效率。_数据库为什么能提高效率
随便推点
什么是配置_基于配置是什么意思-程序员宅基地
文章浏览阅读1.6k次。应用程序在启动和运行的时候往往需要读取一些配置信息,配置基本上伴随着应用程序的整个生命周期,比如:数 据库连接参数、启动参数等。配置主要有以下几个特点:配置是独立于程序的只读变量配置对于程序是只读的,程序通过读取配置来改变自己的行为,但是程序不应该去改变配置配置伴随应用的整个生命周期配置贯穿于应用的整个生命周期,应用在启动时通过读取配置来初始化,在运行时根据配置调整行为。比如:启动时需要读取服务的端口号、系统在运行过程中需要读取定时策略执行定时任务等。配置可以有多种加载方式常见的有程序内部_基于配置是什么意思
二、使用GObject——一个简单类的实现-程序员宅基地
文章浏览阅读170次。Glib库实现了一个非常重要的基础类--GObject,这个类中封装了许多我们在定义和实现类时经常用到的机制: 引用计数式的内存管理 对象的构造与析构 通用的属性(Property)机制 Signal的简单使用方式 很多使用GObject..._
golang 定时任务处理-程序员宅基地
文章浏览阅读6.3k次,点赞2次,收藏9次。在 golang 中若写定时脚本,有两种实现。一、基于原生语法组装func DocSyncTaskCronJob() { ticker := time.NewTicker(time.Minute * 5) // 每分钟执行一次 for range ticker.C { ProcTask() }}func ProcTask() { log.Println("hello world")}二、基于 github 中封装的 cron 库实现package taskimport (_golang 定时任务
VC获取精确时间的方法_vc 通过线程和 sleep 获取精准时间-程序员宅基地
文章浏览阅读2.1k次。 来源:http://blog.csdn.net/clever101/archive/2008/10/18/3096049.aspx 声明:本文章是我整合网上的资料而成的,其中的大部分文字不是我所为的,我所起的作用只是归纳整理并添加我的一些看法。非常感谢引用到的文字的作者的辛勤劳动,所参考的文献在文章最后我已一一列出。 对关注性能的程序开发人员而言,一个好的计时部件既是益友,也_vc 通过线程和 sleep 获取精准时间
wml入门-程序员宅基地
文章浏览阅读58次。公司突然说要进行wap开发了,以前从没了解过,但我却异常的兴奋,因为可以学习新东西了,呵呵,我们大家一起努力吧。首先说说环境的搭建。可以把.wml的文件看做是另一种的html进行信息的展示,但并不是所有的浏览器都支持,好用的有Opera,还有WinWap。编写wml文件语法比较严格,不好的是我还没有找到好的提示工具,就先用纯文本吧。我找到了一个很好的学习网站:http://w3sc..._winwap学习
计算机考研怎么给老师发邮件,考研复试前,手把手教你怎么给导师发邮件!4点要注意...-程序员宅基地
文章浏览阅读504次。考研成绩出来后,第一件事是干什么?当然不只是高兴,而是马上给心仪的导师发邮件,先露个“名字熟”。不要以为初试考了高分或者过线了,一切都稳妥了,一时得意忘形,居然没联系导师,等想起时,导师已经属于他人了。对于一些大佬,热门导师一定要趁早发邮件咨询,一是表示尊重;二是这类老师可能已经没有统招名额,所以越早知道,越有利于下一步计划。但是,在给导师发邮件中,要注意以下4点,不求一步成功,但求先留下个好印象..._跨考计算机怎么给导师发邮件