OpenAI的人工智能语音识别模型Whisper详解及使用_ai虚拟老师语音识别-程序员宅基地
技术标签: 音视频处理 深度学习 pytorch whisper AI数字人技术 语音识别
1 whisper介绍
拥有ChatGPT语言模型的OpenAI公司,开源了 Whisper 自动语音识别系统,OpenAI 强调 Whisper 的语音识别能力已达到人类水准。
Whisper是一个通用的语音识别模型,它使用了大量的多语言和多任务的监督数据来训练,能够在英语语音识别上达到接近人类水平的鲁棒性和准确性。Whisper还可以进行多语言语音识别、语音翻译和语言识别等任务。Whisper的架构是一个简单的端到端方法,采用了编码器-解码器的Transformer模型,将输入的音频转换为对应的文本序列,并根据特殊的标记来指定不同的任务。
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。OpenAI 认为使用这样一个庞大而多样的数据集,可以提高对口音、背景噪音和技术术语的识别能力。除了可以用于语音识别,Whisper 还能实现多种语言的转录,以及将这些语言翻译成英语。OpenAI 开放模型和推理代码,希望开发者可以将 Whisper 作为建立有用的应用程序和进一步研究语音处理技术的基础。
代码地址:代码地址
2 whisper模型
2.1 使用数据集
Whisper模型是在68万小时标记音频数据的数据集上训练的,其中包括11.7万小时96种不同语言的演讲和12.5万小时从”任意语言“到英语的翻译数据。该模型利用了互联网生成的文本,这些文本是由其他自动语音识别系统(ASR)生成而不是人类创建的。该数据集还包括一个在VoxLingua107上训练的语言检测器,这是从YouTube视频中提取的短语音片段的集合,并根据视频标题和描述的语言进行标记,并带有额外的步骤来去除误报。
2.2 模型
主要采用的结构是编码器-解码器结构。
重采样:16000 Hz
特征提取方法:使用25毫秒的窗口和10毫秒的步幅计算80通道的log Mel谱图表示。
特征归一化:输入在全局内缩放到-1到1之间,并且在预训练数据集上具有近似为零的平均值。
编码器/解码器:该模型的编码器和解码器采用Transformers。
- 编码器的过程
编码器首先使用一个包含两个卷积层(滤波器宽度为3)的词干处理输入表示,使用GELU激活函数。
第二个卷积层的步幅为 2。
然后将正弦位置嵌入添加到词干的输出中,然后应用编码器 Transformer 块。
Transformers使用预激活残差块,编码器的输出使用归一化层进行归一化。
- 模型结构
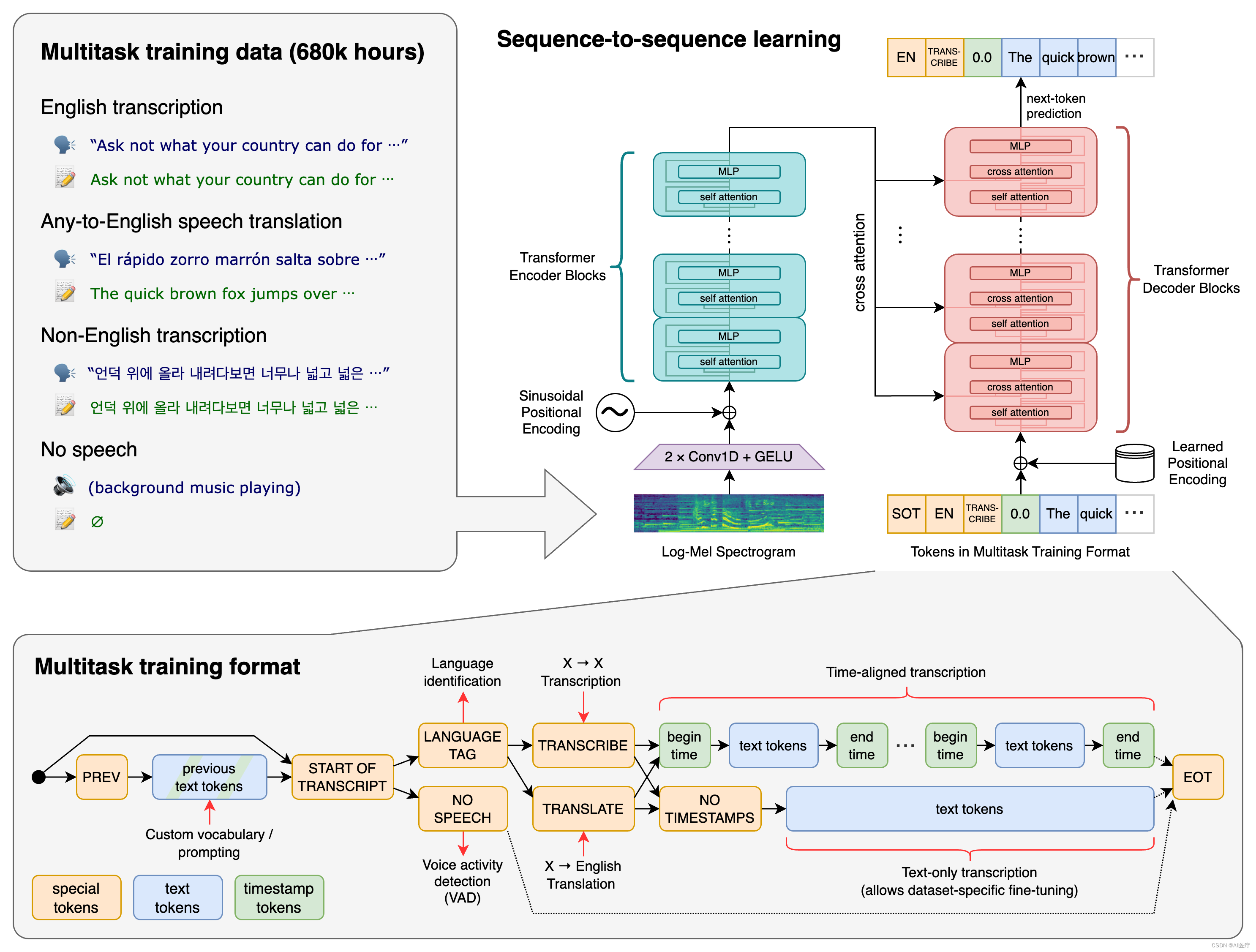
- 解码的过程
在解码器中,使用了学习位置嵌入和绑定输入输出标记表示。
编码器和解码器具有相同的宽度和数量的Transformers块。
2.3 训练
输入的音频被分割成 30 秒的小段、转换为 log-Mel 频谱图,然后传递到编码器。解码器经过训练以预测相应的文字说明,并与特殊的标记进行混合,这些标记指导单一模型执行诸如语言识别、短语级别的时间戳、多语言语音转录和语音翻译等任务。
相比目前市面上的其他现有方法,它们通常使用较小的、更紧密配对的「音频 - 文本」训练数据集,或使用广泛但无监督的音频预训练集。因为 Whisper 是在一个大型和多样化的数据集上训练的,而没有针对任何特定的数据集进行微调,虽然它没有击败专攻 LibriSpeech 性能的模型(著名的语音识别基准测试),然而在许多不同的数据集上测量 Whisper 的 Zero-shot(不需要对新数据集重新训练,就能得到很好的结果)性能时,研究人员发现它比那些模型要稳健得多,犯的错误要少 50%。
为了改进模型的缩放属性,它在不同的输入大小上进行了训练。
- 通过 FP16、动态损失缩放,并采用数据并行来训练模型。
- 使用AdamW和梯度范数裁剪,在对前 2048 次更新进行预热后,线性学习率衰减为零。
- 使用 256 个批大小,并训练模型进行 220次更新,这相当于对数据集进行两到三次前向传递。
由于模型只训练了几个轮次,过拟合不是一个重要问题,并且没有使用数据增强或正则化技术。这反而可以依靠大型数据集内的多样性来促进泛化和鲁棒性。
Whisper 在之前使用过的数据集上展示了良好的准确性,并且已经针对其他最先进的模型进行了测试。
2.4 优点
-
Whisper 已经在真实数据以及其他模型上使用的数据以及弱监督下进行了训练。
-
模型的准确性针对人类听众进行了测试并评估其性能。
-
它能够检测清音区域并应用 NLP 技术在转录本中正确进行标点符号的输入。
-
模型是可扩展的,允许从音频信号中提取转录本,而无需将视频分成块或批次,从而降低了漏音的风险。
-
模型在各种数据集上取得了更高的准确率。
Whisper在不同数据集上的对比结果,相比wav2vec取得了目前最低的词错误率
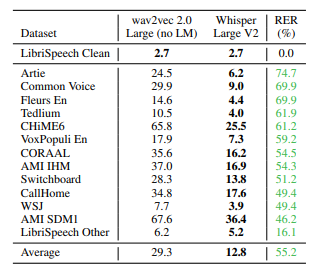
模型没有在timit数据集上进行测试,所以为了检查它的单词错误率,我们将在这里演示如何使用Whisper来自行验证timit数据集,也就是说使用Whisper来搭建我们自己的语音识别应用。
2.5 whisper的多种尺寸模型
whisper有五种模型尺寸,提供速度和准确性的平衡,其中English-only模型提供了四种选择。下面是可用模型的名称、大致内存需求和相对速度。

模型的官方下载地址:
"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt",
"tiny": "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt",
"base.en": "https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt",
"base": "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt",
"small.en": "https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt",
"small": "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt",
"medium.en": "https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt",
"medium": "https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt",
"large-v1": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large-v1.pt",
"large-v2": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
"large": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",3 whisper环境构建及运行
3.1 conda环境安装
参见:annoconda安装
3.2 whisper环境构建
conda create -n whisper python==3.9
conda activate whisper
pip install openai-whisper
conda install ffmpeg
pip install setuptools-rust3.3 whisper命令行使用
whisper /opt/000001.wav --model base输出内容如下:
[00:00.000 --> 00:02.560] 人工智能识别系统。执行命令时,会自动进行模型下载,自动下载模型存储的路径如下:
~/.cache/whisper也可以通过命令行制定本地模型运行:
Whisper /opt/000001.wav --model base --model_dir /opt/models --language Chinese支持的文件格式:m4a、mp3、mp4、mpeg、mpga、wav、webm
3.4 whisper在代码中使用
import whisper
model = whisper.load_model("base")
result = model.transcribe("/opt/000001.wav")
print(result["text"])智能推荐
【计算机毕业设计】springboot党员之家服务系统小程序-程序员宅基地
文章浏览阅读342次,点赞6次,收藏8次。党员之家服务系统小程序的功能已基本实现,主要包括首页、个人中心、学生管理、教师管理、任务信息管理、报名信息管理、任务排名管理、学习资料管理、每日打卡管理、交流信息管理、回复信息管理、积极分子管理、党员信息管理、交流论坛、系统管理等。论文主要从系统的分析与设计 、数据库设计和系统的详细设计等几个方面来进行论述,系统分析与设计部分主要论述了系统的功能分析、系统的设计思路,数据库设计主要论述了数据库的设计,系统的详细设计部分主要论述了几个主要模块的详细设计过程。
Failed to discover available identity versions when contacting http://controller:35357/v3. 错误解决方式_caused by newconnectionerror('<urllib3.connection.-程序员宅基地
文章浏览阅读8.3k次,点赞5次,收藏12次。作为 admin 用户,请求认证令牌,输入如下命令openstack --os-auth-url http://controller:35357/v3 --os-project-domain-name default --os-user-domain-name default --os-project-name admin --os-username admin token issue报错Failed to discover available identity versions whe._caused by newconnectionerror('
学校机房统一批量安装软件的方法来了_教室电脑 一起装软件-程序员宅基地
文章浏览阅读4.5k次。可以在桌面安装云顷还原系统软件,利用软件中的网络对拷功能部署批量对拷环境,进行电脑教室软件的批量对拷安装与增量对拷安装。_教室电脑 一起装软件
消息队列(kafka/nsq等)与任务队列(celery/ytask等)到底有什么不同?_任务队列和消息队列-程序员宅基地
文章浏览阅读3.1k次,点赞5次,收藏7次。原文链接:https://www.ikaze.cn/article/43写这篇博文的起因是,我在论坛宣传我开源的新项目YTask(go语言异步任务队列)时,有小伙伴在下面回了一句“为什么不用nsq?”。这使我想起,我在和同事介绍celery时同事说了一句“这不就是kafka吗?”。那么YTask和nsq,celery和kafka?他们之间到底有什么不同呢?下面我结合自己的理解。简单的分析一..._任务队列和消息队列
Java调KT类_java 调用kt 对象-程序员宅基地
文章浏览阅读1.5k次。1,MyUtuils.kt将被调用的文件class MyUtils { fun show(info:String){ println(info) }}fun show(info:String){ println(info)}2,Java文件调用该类,ClientJava.javapublic class ClientJava { public static void main(String[] args) { /** _java 调用kt 对象
UDP报文最大长度_最大请求报文大小-程序员宅基地
文章浏览阅读6.6k次,点赞4次,收藏4次。在进行UDP编程的时候,我们最容易想到的问题就是,一次发送多少bytes好? 当然,这个没有唯一答案,相对于不同的系统,不同的要求,其得到的答案是不一样的,我这里仅对 像ICQ一类的发送聊天消息的情况作分析,对于其他情况,你或许也能得到一点帮助: 首先,我们知道,TCP/IP通常被认为是一个四层协议系统,包括链路层,网络层,运输层,应用层. UDP属于运输层_最大请求报文大小
随便推点
uni-app,uni-table表格操作_uniapp table-程序员宅基地
文章浏览阅读8.5k次,点赞2次,收藏11次。使用uni-ui UI框架实现表格加分页功能,uni-table 和uni-pagination 组件的使用示例加完整代码。_uniapp table
HTML5本地存储账号密码
【代码】HTML5本地存储账号密码。
vue.js知识点-transition的钩子函数应用(实例展示)_transition 钩子-程序员宅基地
文章浏览阅读1.6k次。本小结通过transition的钩子函数实现小球半场动画头条-静敏的编程秘诀-vue教程合集知识点1:入场、出厂方法beforeEnter表示动画入场之前,此时,动画尚未开始,可以在beforeEnter中设置元素开始动画之前的起始样式enter表示动画开始之后的样式,这里可是设置小球完成动画之后的,结束状态enter(el,done)el:动画钩子函数的第一个参数:el,..._transition 钩子
MyBatis 多表映射及动态语句
主要梳理mybatis多表及动态使用
Qt 多线程基础及线程使用方式-程序员宅基地
文章浏览阅读2.9w次,点赞98次,收藏777次。文章目录Qt 多线程操作2.线程类QThread3.多线程使用:方式一4.多线程使用:方式二5.Qt 线程池的使用Qt 多线程操作应用程序在某些情况下需要处理比较复杂的逻辑, 如果只有一个线程去处理,就会导致窗口卡顿,无法处理用户的相关操作。这种情况下就需要使用多线程,其中一个线程处理窗口事件,其他线程进行逻辑运算,多个线程各司其职,不仅可以提高用户体验还可以提升程序的执行效率。Qt中使用多线程需要注意:Qt的默认线程为窗口线程(主线程):负责窗口事件处理或窗口控件数据的更新;子线程负责后台的业_qt 多线程
GQA分组注意力机制
【代码】GQA分组注意力机制。