【语义分割】深度学习中常见概念回顾(全大白话解释,一读就能懂!)_epoch/iter-程序员宅基地
技术标签: 深度学习
记录一下常见的术语!
一、epoch、batch size和iteration
1.1 Epoch
定义:一个epoch指代所有的数据送入网络中完成一次前向计算及反向传播的过程。简而言之:训练集中的全部样本/数据 “喂” 给网络一次,就叫做一个epoch
补充1:在训练时,将所有数据迭代训练一次是不够的,需要反复多次才能拟合收敛,即:需要把数据集多放入网络训练几次。简而言之:看书看一遍是不够的的,需要多看几遍,神经网络也是。
补充2: 由于一个epoch常常太大,一次全 “喂” 给网络,计算机无法负荷,我们会将它分成几个较小的batch,即引出了batch size这个概念
1.2 Batch Size
定义:所谓Batch就是每次送入网络中训练的一部分数据,而Batch Size就是每个batch中训练样本的数量。其取值通常为:2^N,如:32、64、128…
作用: Batch Size 如果过小,训练数据就收敛困难;如果过大,虽然相对处理速度加快,但所需内存容量增加。使用中需要根据计算机性能和训练次数之间平衡Batch Size,其中一个epoch中的训练次数又叫做:iteration,迭代
1.3 Iteration
定义: iterations就是完成一次epoch所需的batch个数。
举个例子:我们有2000个数据,分成4个batch,那么batch size就是500。运行所有的数据进行训练,完成1个epoch,需要进行4次iterations。
1.4 其他版本
定义:
(1)batchsize:批大小,即:每次训练在训练集中取batchsize个样本训练;
(2)iteration:1个iteration等于使用batchsize个样本训练一次;
(3)epoch:1个epoch等于使用训练集中的全部样本训练一次;
举个例子:训练集有1000个样本,batchsize=10,则训练完一次整个样本集需要:
iteration = 1000 / 10 = 100 次
epoch = 1 个
参考
- 深度学习中的Epoch,Batchsize,Iterations,都是什么鬼?
- 机器学习基本概念:batch_size、epoch、 iteration
- 神经网络中epoch、batch size和iteration的区别
- 神经网络中Epoch、Iteration、Batchsize相关理解和说明
- 【调参炼丹】 Batch_size和Epoch_size
二、Softmax
简而言之,一个主要用于多分类求概率的函数,常应用:
(1)用于神经网络输出层
(2)和argmax函数合作用
示意图如下: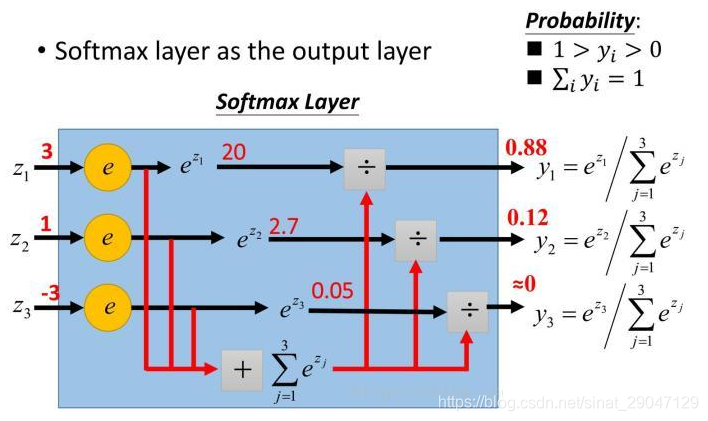
参考: 小白都能看懂的softmax详解
三、激活函数和卷积核
3.1 激活函数
概念:对数据进行映射。
(1)微观理解:若网络不使用激活函数,则只能处理线性数据;使用激活函数后,网络可处理非线性数据。如Relu函数,把直线(线性)“掰弯”(非线性):
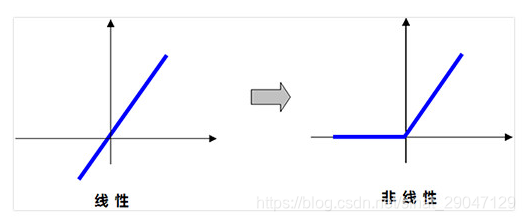
(2)宏观理解:使用激活函数,便于更好的提取图像特征
更多激活函数介绍详见:
3.2 卷积核
单一神经元模型如下图:
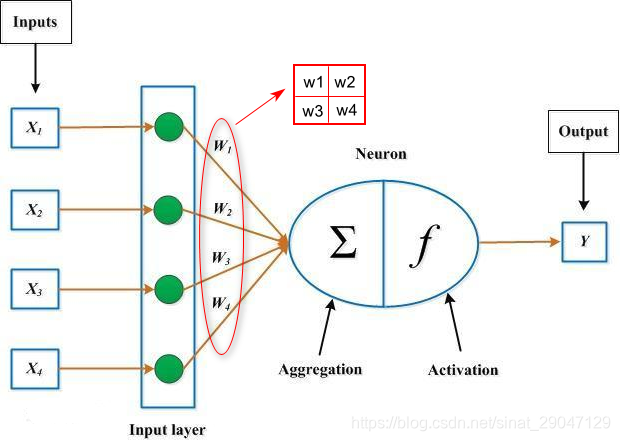
其中,
卷积核的大小:
(1)大小是提前预设的,常见的是3x3,但为什么是3x3,并没有理论依据,通过大量的实践测试得来的,这个大小最好用。
(2)还有一个特殊的是1x1的,一般做降维或者线性变换的时候用
卷积核内的每个参数值(权重):
(1)核中每个参数的值是通过训练得来的,训练网络的过程,也就是训练这些参数的过程
(2)核中的权重(参数:W和b),最初都被初始化为随机值,最终不断优化训练网络、不断调整权重。
(3)在使用训练数据对网络进行BP训练时,W和b的值都会往局部最优的方向更新,直至算法收敛。所以卷积神经网络中的卷积核是从训练数据中学习得来的。(详情参考请点击)
那么,卷积核中的权重值是怎样进行修正的呢?用到了什么技术呢?请参考下述的:损失函数和优化器。
四、损失函数和优化器
背景介绍:
深度神经网络中的的损失用来度量我们的模型得到的的预测值和数据真实值之间差距,也是一个用来衡量我们训练出来的模型泛化能力好坏的重要指标。(损失函数)
对模型进行优化的最终目的是尽可能地在不过拟合的情况下降低损失值。(优化器)
两者关系:
先用损失函数计算出损失值,再基于损失值优化模型参数(卷积核参数)
4.1 损失函数
常见的有:均方误差函数、均方根误差函数、平均绝对误差函数等等。
详细的损失函数介绍,请参考:
4.2 优化器
优化器的鼻祖是:梯度下降(Gradient Descent,GD),其涉及:梯度和学习率。
GD是参数优化的基础方法,虽然已广泛应用,但是其自身存在许多不足,所以在其基础上改进的优化函数也非常多,比如:梯度下降最常见的三种变形 BGD,SGD,MBGD。
详细的优化器介绍,请参考:
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
- 损失函数和优化函数
- 深度学习笔记(五)—损失函数与优化器
五、上采样
常见的上采样方法有:双线性插值、转置卷积、上采样(unsampling)和上池化(unpooling)。其中前两种方法较为常见,后两种用得较少。
详情参考:上采样方法原理简介
六、归一化
6.1 归一化
概念:
传统机器学习中归一化也叫做标准化,其一般是将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位。如:有的特征取值范围[10<sup>9</sup>,10<sup>99</sup>],另一些特征取值范围为[0,01, 0.1],通过归一化可将这些不同取值范围的特征值映射到相同的范围,如将上述两个范围映射到[-1, 1]之间。
作用:
数据标准化让机器学习模型看到的不同取值范围的样本彼此之间更加形似,有助于模型的学习与对新数据的泛化。
6.2 批归一化
概念:Batch Normalization,批归一化和普通的数据归一化类似,是将分散的数据统一到某一特定区间的一种方法,也是优化神经网络的一种方法。
应用:
(1)在数据预处理时进行批归一化,可以加速网络收敛;
(2)在神经网络中进行批归一化,即:在网络的每一次变换之后进行数据归一化,也可加速网路收敛。为什么要在训练过程中批归一化?答:训练过程中均值和方差随时间发生变化,需重新对数据进行批归一化,这样网络每一层看到的数据都属于同一分布。
(3)批标准化一般放在:卷积层后,即:先卷积,后批标准化,再卷积,再批标准化
作用:
(1)批标准化解决的问题是梯度消失和梯度爆炸
(2)批标准化是一种训练优化方法
(3)具有正则化效果,可抑制过拟合
(4)可提高模型的泛化能力。因为:它可使同一神经网络的每一层看到的数据都属于同一分布范围,无论什么范围的数据过来,都能很好的处理。
(5)允许更高的学习速率从而加速网络收敛
(6)批标准化有助于梯度传播,因此可基于批标准化创建更深的网络,如:ResNet50、Inception V3和Xception等。
其他:
(1)BatchNormalization层通常在卷积层或密集连接层后使用,tf 2.0中对应函数:Tf.keras.layers.Batchnormalization()
七、过拟合问题解决
当网络训练后出现过拟合,如:训练集上准确率上升,验证集上准确率恒定,可采用:
(1)dropout层
(2)l1、l2正则化
解决过拟合问题。
智能推荐
Django-Redis-程序员宅基地
文章浏览阅读554次,点赞10次,收藏10次。NoSQL:(不支持sql语句)RedisMongoDBkey-value数据库(非关系性数据库)
蓝桥杯实战应用【算法知识篇】-快速排序算法(附Java、Python和C++代码)_蓝桥杯快速排序蓝桥杯java-程序员宅基地
文章浏览阅读189次。快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。快速排序又是一种分而治之思想在排序算法上的典型应用。_蓝桥杯快速排序蓝桥杯java
SQLAlchemy关联表一对多关系的详解_sqlalchemy 一对多-程序员宅基地
文章浏览阅读695次。SQLAlchemy关联表一对多关系的详解_sqlalchemy 一对多
“反向传播算法”过程及公式推导(超直观好懂的Backpropagation)_反向传播算法(过程及公式推导)-程序员宅基地
文章浏览阅读10w+次,点赞1.7k次,收藏4.9k次。自己学习机器学习,深度学习也有好长一段时间了,一直以来都想写点有价值的技术博客,以达到技术分享及记录自己成长的目的,奈何之前一直拖着,近来算是醒悟,打算以后不定时写一写博客,也算是作为自己不断学习,不断进步的记录。既然是写博客,希望自己的博客以后要做到“准确、生动、简洁、易懂”的水平,做到对自己、对读者负责,希望大家多交流,共同进步!言归正传,想起当时自己刚入门深度学习的时候,当时对神经网络的“..._反向传播算法(过程及公式推导)
Unity Shader - 水体交互_unity 水体-程序员宅基地
文章浏览阅读6.4k次,点赞10次,收藏87次。水体交互效果在游戏中是一个很常见的需求,这里简单实现一个可交互的水体。本篇文章主要是介绍水体交互的实现思路,水体的渲染这里就不再详细介绍,网上很多关于水体的渲染方法很多,可以自己百度、Google了解一下,这里不会过多提及。效果图。先放一张最终的GIF效果图!实现思路原理其实非常简单,就是通过粒子系统不断发射带有波纹法线贴图的面片,然后把这些法线渲染一张RenderTexture传输到Water Shader中,然后和Water Normal 叠加即可形成水波效果。实现步骤可以简单分为:简_unity 水体
SQL Server性能调教的小实验(2)-程序员宅基地
文章浏览阅读585次。上次说到当数据量提高之后,查询效率急剧下降,经过分析后,得到这个查询语句的效率是最低的。SELECT IDFROM Specimen_admin_specimen_TWHERE (Species_ID IN (SELECT DISTINCT (Species_ID) FROM View_All_Tree WHERE...
随便推点
用linux脚本插入10w级的数据数据库为mysql-程序员宅基地
文章浏览阅读177次。插入大量数据到MySQL数据库可以使用以下步骤:准备数据:你需要一个数据文件,包含需要插入的所有数据。每行都是一条记录,字段之间使用适当的分隔符分开。创建数据库:如果没有相应的数据库,请先创建一个。创建表:创建一个表来存储数据。导入数据:使用MySQL的"LOAD DATA INFILE"命令导入数据。该命令可以从文件中快速加载大量数据到MySQL表中。以下是使用bash脚本..._linux sql插入大量数据
腾讯云域名免费SSL证书怎么获取?HTTPS免费配置_腾讯 域名证书-程序员宅基地
文章浏览阅读316次,点赞5次,收藏4次。总之,通过腾讯云免费SSL证书申请教程,您可以轻松为自己的域名获取免费SSL证书,并实现HTTPS的安全配置。同时,结合腾讯云的服务器购买优惠政策,您还可以以更经济的成本搭建起安全、高效的网站环境。腾讯云将为您的域名生成免费的SSL证书,并通过您提供的邮箱发送相关通知。这样,您就成功获取了免费的SSL证书,为您的网站加上了一把安全锁。那么,如何在腾讯云上为自己的域名免费获取SSL证书,并实现HTTPS的安全配置呢?此外,如果您在配置SSL证书的过程中需要购买服务器,不妨关注腾讯云的促销活动。_腾讯 域名证书
R语言ggplot2包绘制双坐标轴图(双Y轴图)实战:两个Y轴分别使用不同的刻度范围_ggplot双侧轴,两侧轴起始高度不一样,数值刻度也不一样-程序员宅基地
文章浏览阅读146次。R语言ggplot2包绘制双坐标轴图(双Y轴图)实战:两个Y轴分别使用不同的刻度范围_ggplot双侧轴,两侧轴起始高度不一样,数值刻度也不一样
优化图像处理中均值和方差计算_图像方差-程序员宅基地
文章浏览阅读7.2k次。图像处理中均值和方差计算优化一、均值和方差的普通优化图像处理中,有时候会需要计算图像某区域的均值和方差。在我之前的博客中《图像比较之模板匹配》,对计算方差有做简化计算的介绍。详细介绍可以参考我之前的博文。在此,我简单的介绍下计算方差的简化方法:按照上述方式计算均值和方差,很多应用场景下都比较合适。但是有两个缺陷:如果均值远大于标准差,意味着方差计算中相减的两个数非常接近,将引入过度舍入的问题; 对于新增加一个统计变量重新计算其均值和方差的时候,需要对所有统计变量再重新计算,做了大量的重_图像方差
openwrt单线多拨_家庭宽带单线多拨VS多线多拨,有啥区别,100M变1000M-程序员宅基地
文章浏览阅读1.9w次,点赞6次,收藏23次。经常折腾网络的人可能都知道多拨,今天就主要来说说多拨这个话题,以及结合自己的一些尝试,给大家做一些分享。喜欢的朋友们、小伙伴们可以关注我,不定时更新家庭网络相关技术,有疑问或者问题都可以评论留言,看到就回复;多拨也就是我们的宽带账号多次PPPOE拨号,拿到多个IP地址。相当于一条宽带变成了很多条。作用:1、可以实现多外网IP,上行和下行网速叠加,使我们的上网更加快速。100M变1000M网。2、使..._单线多拨
Unity常见框架探索-ET框架探索-程序员宅基地
文章浏览阅读6.7k次,点赞5次,收藏20次。本文简单介绍一下ET框架入口,UI系统和网络模块,可以对基础使用有一个简单认识_et框架