Python批量操作文件写入数据库及从数据库取数据_python脚本写入数据库 取出在执行-程序员宅基地
写在前面
博主工作长期需使用到数据库查询数据,因而接触到了数据库的一些皮毛知识。但是数据库和办公网不能互通,远端访问也没法实现,所以长期以来查询数据都相当麻烦。近期博主在自己的工作电脑上搭建了一个的MySQL数据库,并尝试导入一些数据进去,顺便自己查询,其中遇到了各种各样的问题,才深刻领悟到后端操作的艰难,写篇博客记录一下其中的艰难过程。
- 编译环境:Python3.7
- 编译器:pycharm
- 数据库可视化软件:Navicat premium 15
- 数据库:MySQL 8.0.20
注:以下内容,仅供用于学习交流,而且博主也对相关内容进行的打码处理,文件名和数据库名都是用的XXX来表示的。
数据库搭建
博主的数据库是用的MySQL,用的是CMD命令行方式安装和配置的,网上有很多教程,但是良莠不齐,有空了我专门写一篇博客记录安装过程,这边博客就不说了。不过在安装时,一定要牢记系统给你默认设置的连接密码,如果没记住的话,会让你崩溃,网上教程一堆,能实际解决问题的没两个,这个密码是关键,切记、切记。
数据库可视化软件
博主用的是Navicat premium 15,界面如下:
为什么需要这个软件呢,这个软件可以让你方便的连接你的数据库,也可以在里面写一些查询语句,甚至可以将数据导入到数据库,而且还支持批量导入,总之,非常方便,可以理解为数据库的前端操作软件。但实际使用过程却没有那么友好,比如我导入数据到我的数据库时,经常出现下面的问题:
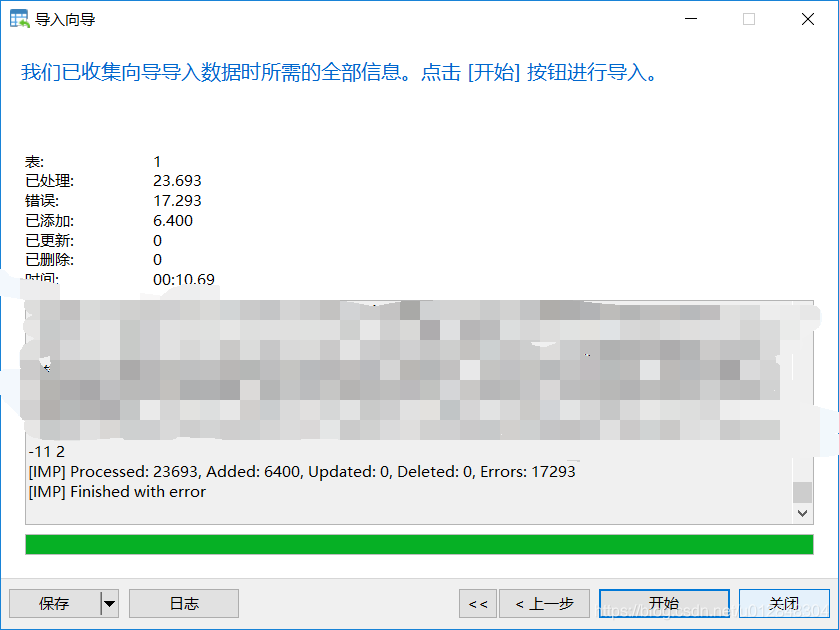
finished with error
也不告诉你那里出了错,反正就是数据不全,大概只导入了1/4的数据。当然也不是所有的数据导入都会出现这个问题,但是确实头疼,博主网上搜了一堆教程没一个能解释明白的,所以才有了后面用Python导入数据库的尝试。不过用Navicat写查询语句确实方便,你的数据库需要这么个数据库可视化软件,不然你操作数据库,就永远像个黑客一样在CMD里写命令行来操作了。
批量合并数据文件
博主这边有很多txt文件,但都是同一批字段的数据,至于为什么会这样,博主也懒得解释。反正现在的工作是,把这些txt文件合并到一个文件里去,这样导入数据库也方便点不是吗?
当然你也可以自己在excel里面一个个的复制粘贴,但是感觉一是工作量太大,十来个文件还好,几百个文件你要这么操作,能让人抓狂,而且逼格也太低了,现在流行自动化办公。
直接上代码:
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 14 15:25:44 2020
@author: HP
"""
#合并一个文件夹下的多个txt文件
#coding=utf-8
import os
import pandas as pd
#获取目标文件夹的路径
filedir = r'C:\xxx\xxx'
#获取当前文件夹中的文件名称列表
filenames=os.listdir(filedir)
i=0
data = pd.read_csv(r'C:\xxx\xxx\xxx.txt',sep = '\t')
col = list(data)
data = pd.DataFrame(columns=col)
#先遍历文件名
for filename in filenames:
i+=1
print(i)
if i>0:
filepath = filedir+'\\'+filename
print(filepath)
#遍历单个文件,读取行数
# datai = pd.read_csv(filepath, sep='\t', dtype=str)
datai = pd.read_csv(filepath, sep='\t', converters={
'item': str})
data = data.append(datai)
'''
for line in open(filepath, 'r', encoding='utf-8-sig', errors='ignore'):
# print(str(line))
f.writelines(line)
# f.write('\n')
'''
#关闭文件
# f.close()
data.to_excel('XXX.xlsx', index=False)
来解释一下代码
filedir = r’C:\xxx\xxx’ 我把所有的文件放在这个文件夹里,注意是一个绝对的路径
filenames=os.listdir(filedir) 获取这个文件夹里面所有的文件列表
data = pd.read_csv(r'D:\xxx\xxx.txt',sep = '\t')
col = list(data)
data = pd.DataFrame(columns=col)
这里几行代码呢,目的是创建一个空的dataframe,这个空的dataframe的列就是上面那个文件夹里面某个文件的列名
后面就是写循环,往列表里面添加数据,然后将列表转换为excel文件了。
'''
for line in open(filepath, 'r', encoding='utf-8-sig', errors='ignore'):
# print(str(line))
f.writelines(line)
# f.write('\n')
'''
博主注释起来的这块代码,是写入txt的方式,看需求,当然,这里f没定义,可以在循环外面定义一下f,比如:
# f=open('result.txt','w')
将数据写入数据库
直接上代码了再解释吧
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 14 17:34:23 2020
@author: HP
"""
"""
功能:将Excel数据导入到MySQL数据库
"""
import xlrd
import MySQLdb
import pandas as pd
d = pd.read_csv('xxx.txt',sep = '\t')
col = list(d)
cols = ','.join(col)
# Open the workbook and define the worksheet
book = xlrd.open_workbook("XXX.xlsx") # excel文件名
# book = xlrd.open_workbook("1.xlsx")
sheet = book.sheet_by_index(0) # excel文件中的sheet名
# 建立一个MySQL连接
database = MySQLdb.connect(host="xxxxxxx", user="xxxx", passwd="xxxxxx", db="xxxxx", charset="utf8")
# 获得游标对象, 用于逐行遍历数据库数据
cursor = database.cursor()
# 创建插入SQL语句
# query = """INSERT INTO acd_file (%s) VALUES (%s)""" %(cols, ss)
# 创建一个for循环迭代读取xls文件每行数据的, 从第二行开始是要跳过标题
data_list = []
for r in range(1, sheet.nrows):
row_list = []
for t in range(len(col)):
value_rt = sheet.cell(r,t).value
type_rt = sheet.cell(r,t).ctype
if type_rt == 2:
value_rt = str(int(value_rt))
row_list.append(value_rt)
data_list.append(row_list)
# values = ','.join(data_list)
# query = """INSERT INTO acd_file (%s) VALUES (%s)""" %(cols, s)
# 执行sql语句
# cursor.execute(query, values)
val = ''
for i in range(0, len(col)):
val = val + '%s,'
result =cursor.executemany("insert into xxx (%s) values(" %(cols) + val[:-1] + ")", data_list)
print(result)
# 关闭游标
cursor.close()
# 提交
database.commit()
# 关闭数据库连接
database.close()
# 打印结果
print("")
print("Done! ")
print("")
columns = str(sheet.ncols)
rows = str(sheet.nrows)
print("我刚导入了 ", columns, " 列 and ", rows, " 行数据到MySQL!")
真的挺复杂,也不知道博主能不能讲明白,我挑一些自己认为比较晦涩的代码来解释吧
基础数据导入
d = pd.read_csv('xxx.txt',sep = '\t')
col = list(d)
cols = ','.join(col)
这里主要是把文件的列名变成一串字符串,join函数可以将列表转化为字符串,分割符号是’,'这个逗号
# Open the workbook and define the worksheet
book = xlrd.open_workbook("XXX.xlsx") # excel文件名
# book = xlrd.open_workbook("1.xlsx")
sheet = book.sheet_by_index(0) # excel文件中的sheet名
把上面合并的那个excel文件读进来,并且获取这个excel的sheet名,从上面批量合并数据文件这一步来看,博主其实只有一个sheet。
链接数据库
database = MySQLdb.connect(host="xxxxxxx", user="xxxx", passwd="xxxxxx", db="xxxxx", charset="utf8")
这行代码非常关键,关系到你能否把数据写到数据库里去,connect函数就是用来链接数据库的,里面的参数我来解释一下:
- host:主机名,如果是访问本机数据库的话,一般是localhost,如果是访问网络数据库的话,就要写服务器的网络地址了
- user:用户名,你数据库的用户名,这里就与自己当初搭建的数据库密切相关了
- passwd:这个数据库用户名对应的密码,就是我前面提到的那个密码,很重要、很重要、很重要
- db:你要讲数据写入的数据库名称
- charset:这玩意儿很坑,字符格式,主要看你的数据库是什么样的,我的是utf-8,所以这里我写上了,但很多教程并没有这个,所以经常报错,没写上之前,我也是各种报错
数据处理
data_list = []
for r in range(1, sheet.nrows):
row_list = []
for t in range(len(col)):
value_rt = sheet.cell(r,t).value
type_rt = sheet.cell(r,t).ctype
if type_rt == 2:
value_rt = str(int(value_rt))
row_list.append(value_rt)
data_list.append(row_list)
这段代码的目的是将表中所有的数据全部取出来,并写入到data_list这个列表中
type_rt = sheet.cell(r,t).ctype用于获取每个字符的类型
ctype : 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
我将所有数字型的数据全部转换为字符串,便于完整的写入数据,至于到哪里去把字符串修改回来,这个可以到Navicat里面去设置。当然,这不是最佳的数据处理方式,只是比较适合博主的数据而已
写入数据库
val = ''
for i in range(0, len(col)):
val = val + '%s,'
result =cursor.executemany("insert into xxx (%s) values(" %(cols) + val[:-1] + ")", data_list)
变量val用来生成一串’%s’这个玩意儿,val[:-1]用切片切掉最后一个逗号,其实这里有更简单的写法,像前面一样用join函数
s =['%s']*len(col)
ss = ','.join(s)
这里的ss和val[:-1]是等价的。
executemany是批量写入函数,“insert into xxx (%s) values(” %(cols) + val[:-1] + ")"中的xxx是数据表。还有另外一种写法,不用批量导入,而是用execute函数,每读一行,就写一行,写在循环里面,但是当时老是报错,我就没继续下去了。
后面就是常规的数据库操作了
当然,整个过程不断的报错,比如报错说我的字符串长度太长了,等等,要在数据库里面修改一些参数,可能每个人遇到的问题不一样,遇到了就去网上搜索教程,基本都能解决。
至此完成了数据的写入,接下来看看怎么在Python里查询数据
Python操作数据库查询数据
还是先上代码
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 16 09:33:42 2020
@author: HP
"""
import MySQLdb
import pandas as pd
conn = MySQLdb.connect(
host="xxxx",
user="xxxx",
passwd="xxxxx",
db="xxxxx",
charset="utf8")
cur = conn.cursor()
query = """ select x1, x2, x3, x4
from table1
where x1 >= 1
and x1 < 100 """
cur.execute(query)
result = cur.fetchall()
df_result = pd.DataFrame(list(result), columns=['x1','x2','x3','x4'])
第一步,链接数据库并登陆
第二步,写查询语句,select from where基本查询语法
第三步,执行查询语句
顺利出结果
相对来说,要简单的多
写在后面
从博主决定搭建数据库到最后打通数据库,总体来说,感觉很费劲,也走了很多弯路,给我的感觉就是后端的东西要比前端复杂一点,当然,博主水平有限,也就目前的认知水平这样,前端的东西其实也很复杂,只是我个人接触的相对多一点而已。
不过还是很开心的,毕竟又get了个新技能。
智能推荐
Selenium使用技巧_selenium firfox add_experimental_option-程序员宅基地
文章浏览阅读248次。浏览器会出现“受自动化测试软件”控制的提示。执行代码时不出现浏览器窗口。_selenium firfox add_experimental_option
ubuntu16.04安装ros-kinetic彻底解决sudo rosdep init报错_ubuntu mate 16.04 ros init-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏10次。ubuntu16.04安装ros-kinetic,解决rosdep init报错。从源头解决rosdep init和rosdep update报错_ubuntu mate 16.04 ros init
RIA是什么东西?-程序员宅基地
文章浏览阅读662次。RIA(Rich Internet Applications)丰富互联网程序,具有高度互动性、丰富用户体验以及功能强大的客户端。简介编辑RIA是Rich Internet Applications的缩写,翻译成中文为丰富的因特网应用程序(Macromedia中文网站翻译为Rich Internet应用程序)传统网络程序的开发是基于页面的、服务器端数据传递的模式,把网络程序的表..._ria 1960 胰岛素
(超详细避坑)实现服务器的代码与Gitee的代码同步更新:通过宝塔的WebHook、Git、Gitee的WebHooks_宝塔同步git-程序员宅基地
文章浏览阅读4.6k次,点赞6次,收藏27次。实现服务器的代码与Gitee的代码同步更新:通过宝塔的WebHook、Git、Gitee的WebHooks。(超详细避坑)前言一、效果展示二、实现步骤2.1 使用宝塔git生成公钥2.2 创建Gitee仓库,添加公钥2.3 宝塔安装WebHook并配置2.4 配置Gitee的WebHooks2.5 将Gitee仓库clone到服务器的本地目录中总结前言提示:内容中的服务器环境为centos7,配置了宝塔的LNMP。 本篇文章最好需要已掌握Git,Gitee操作,宝塔操作的相关知识。一、效果展示._宝塔同步git
说说MAC系统的VNC远程控制-程序员宅基地
文章浏览阅读1w次。有的时候我们可能需要用一台电脑去控制MAC系统的机器。正好现在的MAC系统都自带了VNC协议的远程桌面控制的服务端,我们只需要稍稍设置一下就可以了。1.服务端设置:进入“系统偏好设置”,进入“共享”,勾选“屏幕共享”,这样就打开了VNC的服务端,点击“电脑设置”可以设置VNC客户端连入的密码。2.客户端设置:如果你是linux系统用户,只需要先安装VNC库(比如ubuntu系统可以
url链接拆解/分析/分解/解剖/提取/...?_把一个url拆解成origin、文件名、hash拆解成示例的格式-程序员宅基地
文章浏览阅读3.2k次。url链接拆解/分析/分解/解剖/提取/…?场景:在某个请求中,需要使用到一个参数,但目前server端只能给到一个链接,且需要的参数就在其中,暂时也不单独提供该参数,那么就从url中提取吧。暂时就这么写来实现功能,优化该功能待完善。先看下执行效果url拆解成两个串:https://tswes.suff.xrd.com/h5i/home/paperDeul.html accTok=b21f-d_把一个url拆解成origin、文件名、hash拆解成示例的格式
随便推点
泛型特殊用法 java,Java泛型:特殊用法< T扩展了对象&界面>-程序员宅基地
文章浏览阅读41次。I often find code which uses generics in Java like this:public static foo(T object) {...}Since in Java every class inherites from object class I'm not sure if extends Object gives a special meaning o..._泛型的特殊t
WordPress表结构说明_wordpress posts表menu_order-程序员宅基地
文章浏览阅读944次。WordPress一共有以下11个表。这里加上了默认的表前缀 wp_ 。wp_commentmeta:存储评论的元数据wp_comments:存储评论wp_links:存储友情链接(Girl is coding)wp_options:存储WordPress系统选项和插件、主题配置wp_postmeta:存储文章(包括页面、上传文件、修订)的元数据wp_posts:存储文章(包括页面、上传文_wordpress posts表menu_order
用原生js+HTML+CSS实现一个弹幕的效果-程序员宅基地
文章浏览阅读1.9k次。2019独角兽企业重金招聘Python工程师标准>>> ..._js 带表情的评论输入框 原生html
AndroidStudio断点调试和高级调试_android studio 真機調試設置斷點-程序员宅基地
文章浏览阅读1.3k次。我们程序员在写程序的时候,Bug是不可避免的,在这种情况下,除了日志外最常用的就是Debug了。除了写程序,当我们接手一个旧的程序,熟悉代码最常用的手段也是调试,以前没有总结过Android Studio的调试,现在来总结一下Android Studio的调试技巧!AS调试面板介绍点击顶部工具栏的进入断点调试,例如下面红色方框区:进入断点调试之后,就会唤出调试面板,我们介绍一下调试面板,调试面板如下_android studio 真機調試設置斷點
iOS 开发人才市场饱和了吗?-程序员宅基地
文章浏览阅读452次。自己技术提升的经历送给你, 希望对你有帮助!一,工作经历1,毕业四年,第一家公司就是做iOS开发,一直到现在,做了四年多iOS开发。前后换了四家公司,第一家是外包公司,那个时候我刚入门,在公司的项目中边学习边参与项目开发。后面的几家公司,都是一个新的项目,我过来从零开发,一个人独立负责项目框架搭建、业务功能开发、测试发布、项目的后期维护等流程。工作很忙,但也都能应付过来。2,做时间久了,就慢慢发现,做业务功能的开发越来越没意思了,又都是一个人就能搞定的小项目,并没有太多技术含量。主要工作就是寻找
算法总结:DFA(自动机)算法是什么,怎么用-程序员宅基地
文章浏览阅读5.8k次,点赞8次,收藏54次。算法总结:高手们常说的DFA(自动机)算法是什么简介一:从一个C++语言程序开始1.基础C语言解法2.DFA(自动机)算法思想3.自动机编程题解二:Leetcode实战注简介自动机编程(英语:Automata-based programming)是编程典范中的一种,是指程式或其中的部份是以有限状态机(FSM)为模型的程式,有些程式则会用其他型式(也更复杂)的自动机为其模型。自动机程序在每个时刻有一个状态 s,每次经过一个行动 f,转移到下一个状态 s’。这样,只需要建立一个覆盖所有情况的从 s 与 f_dfa